Open-Source Libraries, Application Frameworks, and Workflow Systems for NLP
Venkat N. Gudivada1; Kamyar Arbabifard East Carolina University, Greenville, NC, United States
1 Corresponding author: email address: gudivadav15@ecu.edu
Keywords
Natural language processing; Natural language understanding; Information retrieval; Open-source libraries; Workflow systems; Annotated corpora
1 Introduction
Natural language processing (NLP) is an interdisciplinary domain which is concerned with understanding natural languages as well as using them to enable human–computer interaction. Natural languages are inherently complex and many NLP tasks are ill-posed for mathematically precise algorithmic solutions. With the advent of big data, data-driven approaches to NLP problems ushered in a new paradigm, where the complexity of the problem domain is effectively managed by using large datasets to build simple but high quality models.
The overarching goal of this chapter is to provide an annotated listing of various resources for NLP research and applications development. Given the rapid advances in the field and the interdisciplinary nature of NLP, this is a daunting task. Furthermore, new datasets, software libraries, applications frameworks, and workflow systems will continue to emerge. Nonetheless, we expect that this chapter will serve as starting point for readers’ further exploration by using the conceptual roadmap provided in this chapter.
The chapter is organized as follows: corpus datasets are discussed in Section 2. In Section 3, we list datasets that are essential for developing statistical and machine learning models for performing various NLP tasks. Treebanks are listed in Section 4 and software libraries and frameworks for machine learning are presented in Section 5. Task-specific NLP tools are discussed in Section 7. A typical NLP application requires core NLP tasks to be performed in certain sequence. An NLP workflow system provides a unified interface to stringing together core tasks and executing them. NLP workflow systems are discussed in Section 8. Section 9 concludes the chapter.
2 Corpus Datasets
A corpus is a large collection of texts of written or spoken language, stored in a machine-readable format. Such corpora are created for a range of purposes. Corpora are used for linguistic analysis, especially in the field of computational linguistics. They also provide evidence of how a language is used in real situations. Corpora collected at different points of time are used to study language change and evolution. Lexicographers use corpora to create accurate and meaningful dictionary entries. Corpora-enabled linguistic analysis subdiscipline is referred to as corpus linguistics (Aijmer and Rühlemann, 2014). Table 1 lists names of some corpus datasets and describes them briefly. This table lists only a very small subset of available corpora.
Table 1
| Corpus Name | Corpus Description |
|---|---|
| Brown University Standard Corpus of Present-Day American English (Brown corpus) | The Brown corpus was the first text corpus of American English published in 1963–1964 by W. Nelson Francis and Henry Kuc˘era of Department of Linguistics, Brown University, Providence, RI, United States. It was compiled from a selection of American English, and the total number of words exceed one million. The corpus is revised in 1971, and again revised and expanded in 1979. The corpus is annotated with Part-of-Speech (PoS) tags using the Penn TreeBank tagset. |
| Lancaster/Oslo-Bergen (LOB) Corpus of British English | This corpus is British counterpart of the Brown corpus. LOB matches with Brown in terms of size and genre. Both LOB and Brown consists of 500 samples each, and a sample contains about 2000 words. LOB is also annotated with PoS tags. |
| Web 1T 5-gram Version 1 | This is a one trillion n-gram data with their frequency counts. The dataset is contributed by Google and is well suited for language modeling research. The n-grams range from unigrams to 5-grams. |
| The International Corpus of English (ICE) (The ICE Project, 2018) | The ICE project began in 1990 with the goal of preparing electronic corpora that reflect national/regional varieties of English, to facilitate comparative studies of English worldwide. To promote compatibility between the component corpora of ICE, each team followed a common corpus design theme and a common scheme for grammatical annotation. There are country-specific versions, for example, ICE-GB is the British component of ICE. |
| Corpus of Contemporary American English (COCA) | COCA is the largest and freely available corpus of American English. It contains more than 560 million words of text representing spoken, fiction, popular magazines, newspapers, and academic texts equally. COCA also enables users to create a personalized corpus within COCA. |
| iWeb Corpus | This 14 billion word corpus is developed using 22 million web pages, which were drawn from a systematically chosen 95,000 websites. The websites have an average of 240 pages, and each page is about 145,000 words. Both iWeb and COCA are part of a very large corpora created by Mark Davies at Brigham Young University, Provo, UT, United States (Davies, 2018). |
2.1 Corpus Tools
Given the volume of corpus text, software tools for corpus exploration and analysis are essential. Numerous tools, both commercial and open-source, are available for this task (Corpus-Analysis.com, 2018). Typically, the tools are specialized for specific tasks as it is neither desirable nor practical to have just one all-encompassing tool. Some tools work on raw corpus text and others depend on corpus annotations. For example, ShinyConc (http://shinyconc.de/) is a framework for generating custom web-based concordancers that work on raw corpus text. A concordance is a sorted list of principal words used in a document. The words are listed along with their immediate context—the words that immediately precede and follow the principal word.
Sketch Engine is a corpus manager and text analysis software, which supports and provides corpora for over 90 languages (Lexical Computing Ltd., 2018). One of its key features is word sketch, which is a one-page summary of a word's grammatical and collocational behavior. It is a proprietary software and offers both commercial and freeware editions. NoSketch Engine is a limited version of the Sketch Engine and is an open-source software.
3 NLP Datasets
NLP datasets are used for constructing, improving, and evaluating machine learning models for various NLP tasks. Some datasets are simply plain raw text, whereas others are enhanced with annotations. The following are general linguistic data resources, some of which contain other datasets in addition to the ones for NLP and machine learning tasks:
- • Kaggle (https://www.kaggle.com/) provides numerous datasets for Data Science competitions.
- • UIC Machine Learning Repository (https://archive.ics.uci.edu/ml/) provides a large number of datasets for developing and validating machine learning algorithms. For example, the Bag of Words Dataset (https://archive.ics.uci.edu/ml/datasets/bag+of+words) is well suited for document clustering and topic modeling (TM) experiments. This dataset's components include Enron emails, Neural Information Processing Systems (NIPS) full papers, New York Times news articles, and PubMed abstracts. The Bag of Words Dataset for PubMed abstracts features 8,200,000 documents, 141,043 distinct words (aka vocabulary), and 730,000,000 total words.
- • Linguistic Data Consortium (https://www.ldc.upenn.edu/) provides a large number of datasets and software tools for linguistics/NLP research and language applications development. LDC was established in 1992. It is a consortium of universities, libraries, corporations, and government research laboratories. LDC started off as a repository and distribution point for linguistic resources. Now it has evolved into an organization which also creates various language resources through contributions from its members. A fee-based subscription is required to use LDC datasets. Anyone can request a guest account, and guest users are provided access to limited portions of LDC online.
- • The World Atlas of Language Structures (WALS Online) (http://wals.info/) is a large database which provides structural (i.e., phonological, grammatical, lexical) properties for world languages.
- • European Language Resources Association (ELRA) (http://www.elra.info/en/) produces and distributes language resources required for Human Language Technologies (HLT).
- • Project Gutenberg (http://www.gutenberg.org/) provides over 57,000 copyright-free books in various formats for free.
Other NLP datasets include
- • The Enron Email Dataset is a collection of about a half million email messages of 150 Enron senior management. This dataset is useful for various tasks including improving current email tools, natural language generation for automating responses to emails, and sentiment analysis. The May 7, 2015 version of this dataset is downloadable from https://www.cs.cmu.edu/~enron/enron_mail_20150507.tar.gz.
- • The BC3: British Columbia Conversation Corpora (https://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/bc3.html) is comprised of the following: BC3—Email Corpus, BC3—Email Corpus—Polarity, BC3—Blog Corpus, and BC3—Email and Blog Corpus Annotated with Topics. For example, the BC3—Email Corpus consists of 40 email threads totaling over 3200 sentences. Each email thread is annotated by three different annotators. A thread annotation include an extractive summary, an abstractive summary with linked sentences, and for each sentence: speech acts (propose, request, commit, meeting), meta sentence, and subjectivity.
- • CELEX2 corpus contains ASCII versions of the CELEX lexical databases of English, Dutch, and German. For each language, this dataset contains detailed information on: orthography—variations in spelling, and hyphenation; phonology—phonetic transcriptions, variations in pronunciation, syllable structure, and primary stress; morphology—derivational and compositional structure, and inflectional paradigms; syntax—word classes, word class-specific subcategorizations, and argument structures; and word and lemma frequency counts.
- • BOLT Chinese-English Word Alignment and Tagging—Discussion Forum Training corpus consists of 448,094 words of Chinese and English parallel text enhanced with linguistic tags to indicate word relations.
- • The New York Times Annotated Corpus includes 1.8 million articles published in New York Times (NYT) between January 1987 and June 2007. Over 650,000 of these articles include a summary written by NYT library scientists. Over 1,500,000 articles manually tagged by library scientists and another 75,000 articles are algorithmically tagged.
- • 1B Word Language Modeling Benchmark is a standard corpus of 0.8 billion words. This corpus is primarily intended for training and evaluating language models (Chelba et al., 2013).
- • The Europarl parallel corpus is extracted from the proceedings of the European Parliament, which includes versions corresponding to 21 European languages (Europarl, 2018). This corpus is intended for machine translation (MT) research.
- • Reuters Corpora (RCV1, RCV2, TRC2). These datasets were created using a large collection of Reuters News stories to promote research in NLP, information retrieval (IR), and machine learning.
Reuters Corpus Volume 1 (RCV1) contains about 810,000 English language news stories from August 20, 1996 through August 19, 1997. Each story is manually categorized into a hierarchical taxonomy. RCV1 is intended for text classification research (Lewis et al., 2004).
Reuters Corpus Volume 2 (RCV2) is a multilingual corpus, which contains 487,000 news stories from RCV1. RCV2 encompasses 13 languages and the stories are written by local reporters in each language. RCV2 is not a parallel corpus and some language versions do not cover the entire time period of RCV1.
Thomson Reuters Text Research Collection (TRC2) comprises 1,800,370 Reuters news stories from January 1, 2008 to February 28, 2009. RCV1, RCV2, and TRC2 are distributed by National Institute of Standards and Technology (https://www.nist.gov/). - • OntoNotes 5 corpus is a large multilingual (English, Chinese, and Arabic) and multigenre (news, conversational telephone speech, weblogs, usenet newsgroups, broadcast, and talk shows) corpus. This project is a collaborative effort between BBN Technologies, University of Colorado, University of Pennsylvania, and University of Southern California's Information Sciences Institute. Its annotations include syntactic structure, predicate-argument structure, word senses, named entities, and coreference. Its English portion (2.9 million tokens) is larger than the Penn TreeBank (one million).
4 Treebanks
A treebank is a parsed text corpus. Parsing is one type of annotation, which marks up a sentence's syntactic or semantic structure. There is a parse tree corresponding to each sentence. The Penn Treebank is the first large-scale treebank. Since then several treebanks have been created and used for NLP research. Initially, there were two types of treebanks: phrase structure and dependency structure. As the name implies, phrase structure treebanks annotate the phrase structure of sentences. Phrase structure parse trees are also called constituency-based parse trees. The Penn Treebank is an example of phrase structure treebank.
Another tree structure, called the dependency tree, depicts the syntactic structure in terms of grammatical relations between the words in the sentence. Labels from a fixed set are used to describe the relations between the words. For example, The Yahoo Query Treebank is a dependency treebank for a subset of Yahoo web search engine queries (Pinter et al., 2016a,b).
As a last example, the Stanford Sentiment Treebank features parse trees for 11,855 sentences (Stanford University, 2018). There are a total of 215,154 phrases in these sentences and each phrase is annotated with a sentiment label.
5 Software Libraries and Frameworks for Machine Learning
This section lists widely used general-purpose machine learning software libraries and frameworks. A software library is a set of functions that application can call, whereas a framework provides higher-level support in the form of some abstract design to speed up applications development. However, this distinction is not always clear-cut.
5.1 TensorFlow
It is an open-source library, which uses data flow graph as its computational model. This model is especially well suited for neural networks-based machine learning. The data flow graph model makes it easy for distributing computation across CPUs and GPUs. TensorFlow is comprised of three components: TensorFlow API, TensorBoard, and TensorFlow Serving. Defining, training, and validated machine learning models is enabled by TensorFlow API. Though the API is implemented using C++, a Python interface to the API is also available. TensorBoard is used for analyzing, debugging, and visualizing data flow graph models. Lastly, TensorFlow Serving enables deployment of pretrained TensorFlow models.
5.2 Deep Learning for Java
Deep Learning for Java (DL4J) is a distributed deep learning library for Java and Scala. Keras is DL4J's Python API. Using Keras, DL4J can import neural net models from other frameworks including TensorFlow, Caffe, and Theano. DL4J includes toolkits for vector space modeling and TM. It also includes implementations of term frequency-inverse document frequency (tf-idf), deep learning, and Mikolov's word2vec, doc2vec, and GloVe algorithms.
5.3 Apache MXNet
MXNet is an open-source framework for developing and deploying deep neural networks (Chen et al., 2015). It is scalable to several GPUs across multiple computers. MXNet is supported by cloud platforms including Amazon Web Services and Microsoft Azure. It provides programming interfaces to Python, R, Scala, Julia, Perl, Matlab, and JavaScript.
5.4 The Microsoft Cognitive Toolkit
Formerly known as CNTK, the Microsoft Cognitive Toolkit is an open-source, deep learning framework (Seide and Agarwal, 2016). It enables users to combine multiple models such as feed-forward deep neural networks, convolutional neural networks, and recurrent networks. It provides scalable components for reinforcement learning, generative adversarial networks, supervised and unsupervised learning.
5.5 Keras
Keras is an open-source neural network library written in Python and provides high-level building blocks for developing deep learning models. It is rather a high-level interface to other machine learning frameworks such as TensorFlow, Microsoft Cognitive Toolkit, DL4J, and Theano.
5.6 Torch and PyTorch
Torch is an open-source software comprised of a machine learning library, scientific computing framework, and script language (Collobert et al., 2018). It offers a range of deep learning algorithms and the script language is based on the Lua programming language. PyTorch is the Python version of Torch and enables building complex deep learning architectures easily.
5.7 Scikit-Learn
Scikit-learn is another open-source Python library, which builds on NumPy, SciPy, and matplotlib (Pedregosa et al., 2011). It features algorithms for data cleaning and transformation, clustering, classification, regression, dimensionality reduction, and model selection.
5.8 Caffe
Caffe is another open-source, deep learning framework which specifically targets image classification and segmentation problems (Jia et al., 2014). It avoids hard-coding by defining models and optimizing them through configuration parameters.
5.9 Accord.NET
It is a C#-based open-source framework for developing deep learning applications (Accord.NET Framework, 2018). It targets scalable, production-grade computer vision, computer audition, signal processing, and statistics applications.
5.10 Spark MLlib
MLlib is Apache Spark's scalable, open-source machine learning library (Meng et al., 2016). MLlib's programming language interfaces include Java, Python, Scala, and R.
6 Software Libraries and Frameworks for NLP
This section lists widely used software libraries and frameworks for NLP research and applications development. The tools are continuously evolving and make the distinction between a library and framework blurry. Furthermore, it is not appropriate to say that one framework is better than the other, since the appropriateness depends on the application domain (Pinto et al., 2016). Lastly, NLP tools in the frameworks come pretrained, and a tool's performance is tied to its training data. The tools need to be retrained with suitable data, if the pretraining and the application data are different.
6.1 Natural Language Toolkit
Natural Language Toolkit (NLTK) is a widely used, open-source Python library for NLP (NLTK Project, 2018). Several algorithms are available for text tokenization, stemming, stop word removal, classification, clustering, PoS tagging, parsing, and semantic reasoning. It also provides wrappers for other NLP libraries. A notable feature of NLTK is that it provides access to over 50 corpora and lexical resources such as the WordNet.
6.2 Stanford CoreNLP Toolset
Stanford CoreNLP is an integrated Java toolset for NLP research and applications development (The Apache Software Foundation, 2018). It is open-source, extensible and can be run as a simple web service. Its multilingual capability encompasses Arabic, Chinese, English, French, German, and Spanish. CoreNLP also provides support for annotation of arbitrary texts. It integrates several Stanford's NLP tools—PoS tagger, named entity recognizer, parsers, coreference resolution system, sentiment analyzer, bootstrapped pattern learning, and open information extraction (IE) tools.
6.3 Apache OpenNLP
The Apache OpenNLP and Stanford CoreNLP Toolset are quite similar to each other in terms of functionality and ease of use. However, the licensing terms are different. Stanford CoreNLP seems to have a slight edge in active maintenance and evolution.
6.4 General Architecture for Text Engineering
General Architecture for Text Engineering (GATE) is another integrated Java toolset for NLP (The University of Sheffield, 2018). GATE originated at the University of Sheffield and has been in development since 1995. GATE provides a broad range of functions for text processing and analytics. It can also be used for defining and creating text processing workflows.
6.5 Machine Learning for Language Toolkit
MAchine Learning for LanguagE Toolkit (MALLET) is a Java software library for statistical NLP (McCallum, 2018). MALLET is developed and maintained at the University of Massachusetts (Amherst). It features various algorithms for document classification, sequence tagging, and TM. For example, it provides efficient implementation of the following algorithms for TM: Latent Dirichlet Allocation (LDA), Pachinko Allocation, and Hierarchical LDA.
6.6 Tools for Social Media NLP
Libraries and frameworks such as OpenNLP and CoreNLP perform well on formally written documents, and not so well on short and informal documents. TwitterNLP is a Python library for performing NLP pipeline operations on short documents such as tweets. More specifically, its features include tokenization, PoS tagging, chinking (i.e., grouping of words into meaningful phrases using PoS tags), and named entity recognition (NER).
TweetNLP is a Java-based library for tokenization, PoS tagging; and identification of tweet contents, URLs, and emoticons. TwitIE is an IE plugin for GATE. TwitIE draws upon existing GATE's IE system called ANNIE.
7 Task-Specific NLP Tools
In this section, we list task-specific NLP tools. Some of these tools are part of software suites discussed in Section 6.
7.1 Language Identification
Not all web pages are written in English. Increasingly, web pages are written in other languages such as Telugu, Japanese, Korean, and Chinese. The first step for NLP and IR tasks is to identify the language used to write the web page. This task is called language identification and tools that perform this task are called language identification systems (LIDs). Most LID systems are based on character n-grams. As the accuracy of a LID increases with the size of input text, a desirable LID is one that performs well with short texts.
Table 2 summarizes information about representative LIDs. The second column indicates the algorithmic approach used, the third column denotes programming language used for developing the library, and the last column specifies the number of languages detected. Apache OpenNLP detects over 100 languages.

7.2 Sentence Segmentation
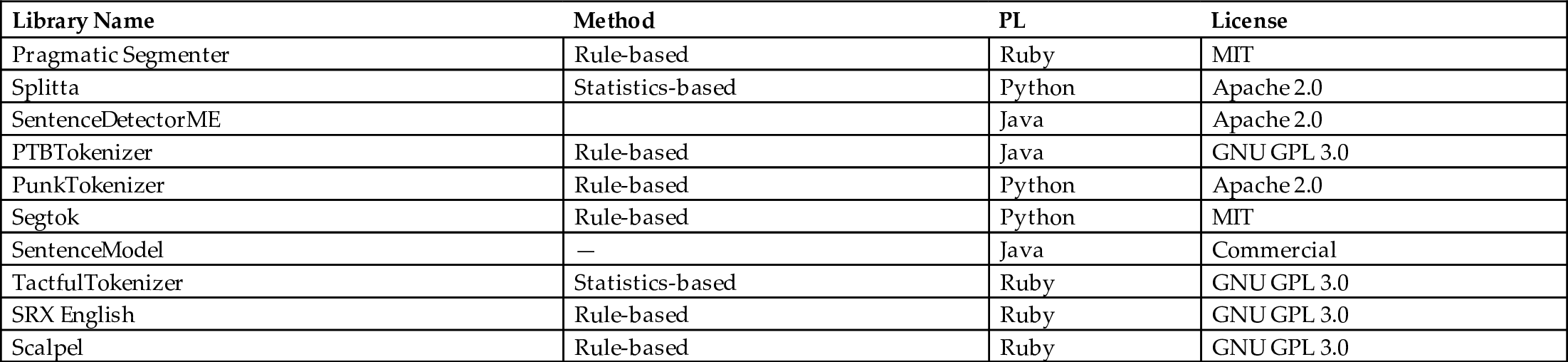
In many languages, sentence segmentation is not a trivial problem. Shown in Table 3 are open-source sentence segmenters that perform well. In general, NLTK's PunkTokenizer, CoreNLP's PTBTokenizer, and OpenNLP's SentenceDetectorME have low error rates. LingPipe's SentenceModel, which is not an open-source, is well designed and performs great.
Table 3
| Library Name | Method | PL | License |
|---|---|---|---|
| Pragmatic Segmenter | Rule-based | Ruby | MIT |
| Splitta | Statistics-based | Python | Apache 2.0 |
| SentenceDetectorME | Java | Apache 2.0 | |
| PTBTokenizer | Rule-based | Java | GNU GPL 3.0 |
| PunkTokenizer | Rule-based | Python | Apache 2.0 |
| Segtok | Rule-based | Python | MIT |
| SentenceModel | — | Java | Commercial |
| TactfulTokenizer | Statistics-based | Ruby | GNU GPL 3.0 |
| SRX English | Rule-based | Ruby | GNU GPL 3.0 |
| Scalpel | Rule-based | Ruby | GNU GPL 3.0 |
7.3 Word Segmentation
Unlike English, in languages such as Telugu, Turkish, and Chinese, word segmentation is a difficult problem as whitespace does not delimit word boundaries. Therefore, word segmentation difficulty is language-specific. Table 4 summarizes tools for word segmentation.
Table 4
| Library Name | Method | PL | License |
|---|---|---|---|
| Jieba | Python | MIT | Chinese |
| PTBTokenizer | Java | GNU GPL 3.0 | English/French/Spanish |
| Word Segmenter | Java | GNU GPL 2.0 | Arabic/Chinese |
| KyTea | C++ | Apache 2.0 | Japanese/Chinese |
| Word Segment | Python | Apache 2.0 | English |
| SentencePiece | C++ | Apache 2.0 | Independent |
| MeCab | C++ | Apache 2.0 | Japanese |
| CWS | Python | Unknown | Chinese |

7.4 Part-of-Speech Tagging
PoS tagging algorithms are of two kinds: rule-based and stochastic. Algorithms in the first category employ rules. For example, the Brill tagger uses a form of supervised learning which aims to minimize error. Initially assigned tags are changed over several iterations using a predefined set of rules. Each iteration improves on the previous iteration by correcting the incorrectly assigned tags using contextual rules. Stochastic algorithms use supervised learning using training samples. They include Hidden Markov Model (HMM), Log-linear Model (aka Maximum Entropy Markov Model (MEMM), or simply ME), and Conditional Random Field (CRF).
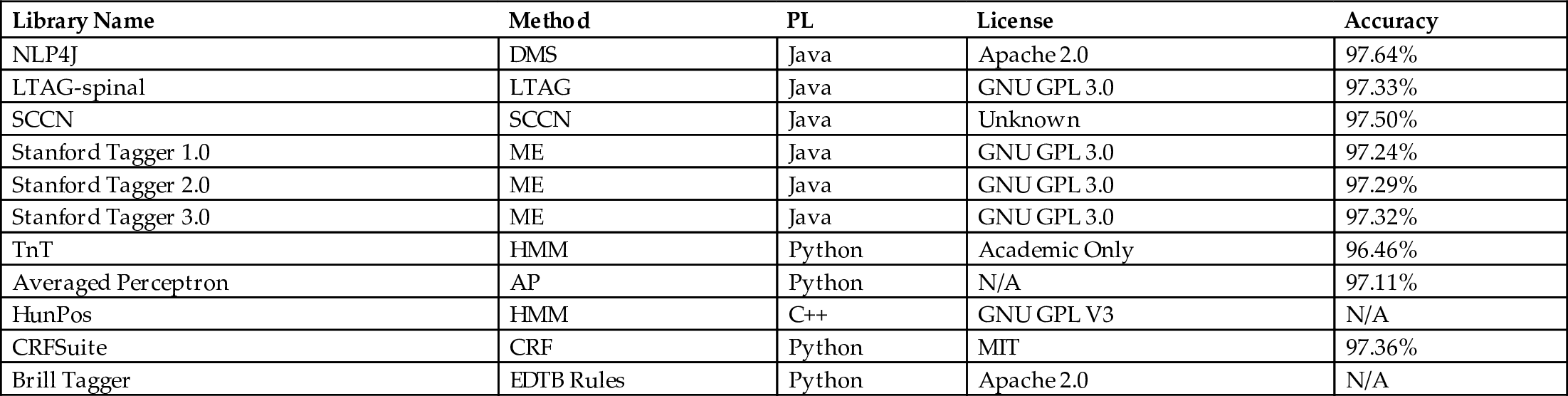
Shown in Table 5 are tools used for PoS tagging. The acronyms used in column 2 are: dynamic model selection (DMS), lexicalized tree adjoining grammar (LTAG), semisupervised condensed nearest neighbor (SCCN), maximum entropy (ME), hidden Markov model (HMM), averaged perceptron (AP), conditional random field (CRF), and error-driven transformation-based (EDTB). The last column indicates the performance of the taggers on the Wall Street Journal corpus data.
Table 5
| Library Name | Method | PL | License | Accuracy |
|---|---|---|---|---|
| NLP4J | DMS | Java | Apache 2.0 | 97.64% |
| LTAG-spinal | LTAG | Java | GNU GPL 3.0 | 97.33% |
| SCCN | SCCN | Java | Unknown | 97.50% |
| Stanford Tagger 1.0 | ME | Java | GNU GPL 3.0 | 97.24% |
| Stanford Tagger 2.0 | ME | Java | GNU GPL 3.0 | 97.29% |
| Stanford Tagger 3.0 | ME | Java | GNU GPL 3.0 | 97.32% |
| TnT | HMM | Python | Academic Only | 96.46% |
| Averaged Perceptron | AP | Python | N/A | 97.11% |
| HunPos | HMM | C++ | GNU GPL V3 | N/A |
| CRFSuite | CRF | Python | MIT | 97.36% |
| Brill Tagger | EDTB Rules | Python | Apache 2.0 | N/A |
7.5 Parsing
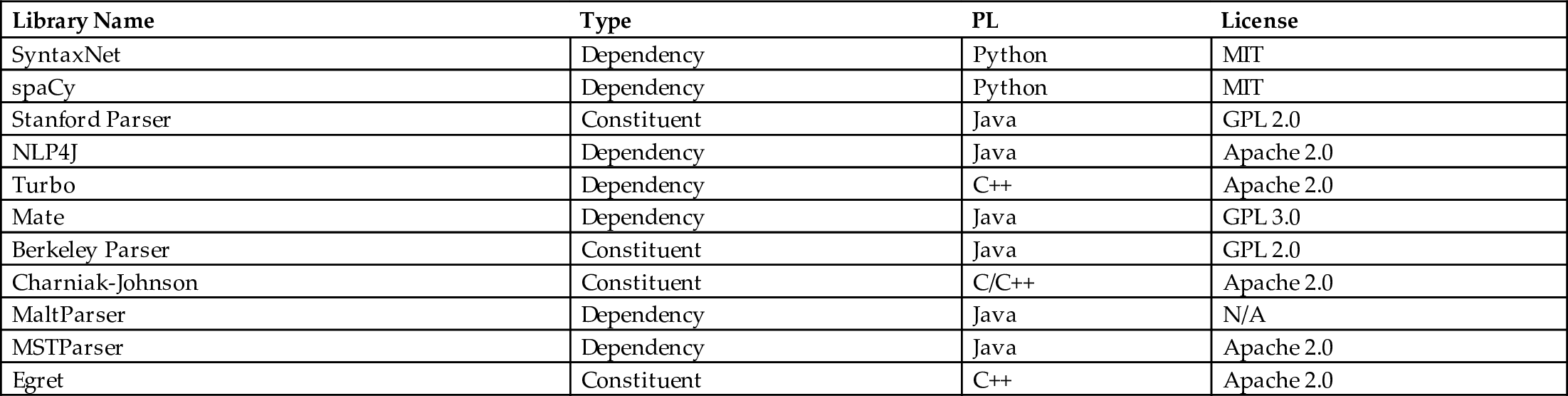
There are a number of open-source parsers that are fast and also perform accurately. Choi et al. (2015) provide a comparative analysis of 10 leading statistical dependency parsers on a multigenre corpus of English. As discussed earlier in Section 4, there are two types of parsers: constituent and dependency. Tradeoffs between speed and accuracy in parsers are discussed in Cer et al. (2010). Table 6 lists well-known parsers.
Table 6
| Library Name | Type | PL | License |
|---|---|---|---|
| SyntaxNet | Dependency | Python | MIT |
| spaCy | Dependency | Python | MIT |
| Stanford Parser | Constituent | Java | GPL 2.0 |
| NLP4J | Dependency | Java | Apache 2.0 |
| Turbo | Dependency | C++ | Apache 2.0 |
| Mate | Dependency | Java | GPL 3.0 |
| Berkeley Parser | Constituent | Java | GPL 2.0 |
| Charniak-Johnson | Constituent | C/C++ | Apache 2.0 |
| MaltParser | Dependency | Java | N/A |
| MSTParser | Dependency | Java | Apache 2.0 |
| Egret | Constituent | C++ | Apache 2.0 |
7.6 Named Entity Recognition
The goal of NER is to label names of people, places, organizations, and other entities of interest in text documents. There are three major approaches to NER: lexicon-based, rule-based, and machine learning based. However, a NER system may combine more than one of these categories (Keretna et al., 2014). Some approaches to NER rely on POS tagging. Also, NER is a preprocessing step for tasks such as information or relationship extraction (Atdağ and Labatut, 2013; Jiang et al., 2016).
Shown in Table 7 are tools used for NER tagging. All the tools are based primarily on statistical approaches. While Stanford's CoreNLP NER (aka CRFClassifier) uses linear chain CRFs, Apache OpenNLP uses ME. CogComp-NLP is a suite of tools and its NER component uses hidden Markov models, multilayered neural networks, and other statistical methods.
7.7 Semantic Role Labeling
Syntactic analysis is inadequate to represent the full meaning of sentences (Gildea and Jurafsky, 2002). The primary goal of semantic role labeling (SRL) is to detect and label events, participants, and role of participants in the events. In other words, SRL helps to specify who did what to whom, when, where, and how (Palmer et al., 2010). Shown in Table 8 are tools used for SRL.

7.8 Information Extraction
The goal of IE is to extract structured data from unstructured data sources. GATE, Apache OpenNLP, NLTK, and MALLET provide open-source tools for IE. MIT information extraction (MITIE) is another open-source tool for IE. MITIE is built using dlib, a high-performance machine-learning library (King, 2009). It is written in C++ and provides language bindings Python, R, Java, C, and MATLAB®.
ReVerb is an open-source system for extracting binary relationships from English sentences. ReVerb handles arbitrary relationships and is designed for web-scale IE (Fader et al., 2011).
7.9 Machine Translation
Warren Weaver was the first to propose in 1949 the idea of using computers to translate text from one natural language to another (Weaver, 1955). Classical approaches to MT were rule-based, some of which are still widely used. Statistical machine learning approaches to MT started in the 1990s and some of the seminal work was done at IBM.
The first step in the early MT systems was word-by-word translation by employing a large bilingual dictionary. Next, simple reordering rules were applied. This approach has several limitations including word translation without disambiguation of its syntactic role, and inherent difficulty in capturing long-range reorderings via rules.
The second generation approaches to MT are transfer-based, which use a three-step process. First, some syntactic analysis (e.g., building a parse tree) is performed on the source text. Second, the syntactic structure is converted (aka transferred) into a corresponding structure in the target language. Finally, output is generated from the syntactic structure of the target language. An advantage of this approach over the word-by-word translation systems is the ability to effect long-range reorderings.
Another approach to MT is called interlingua-based translation, which involves two phases: analyzing the source language text and representing its meaning using a language-independent formalism; and generating the output in target language using the language-independent formalism. The major challenge for this approach is representing the concepts in an interlingua given that different languages break down concepts in quite different ways.
Recent approaches to MT employ statistical models and view MT as a supervised learning problem using parallel corpora. The most recent approaches are based on neural networks. In neural machine translation, a large artificial neural network is used to predict the likelihood of a sequence of words in the target language for a given sentence in the source language. Some open-source MT systems include
- • Moses is a statistical MT framework for training MT systems for any language pair (Koehn et al., 2007). It offers two types of translation models: phrase-based and tree-based. It enables integration of linguistic and other information at the word level.
- • Phrasal is another statistical phrase-based MT system, written in Java. Its functionality is similar to Moses, but also provides several additional unique features such as an easy to use API for implementing new decoding model features, and conditional extraction of phrase-tables and lexical reordering models (Green et al., 2014).
- • Joshua is a statistical decoder for phrase-based, hierarchical, and syntax-based MT (Li et al., 2009).
- • Jane is another phrase-based MT decoder developed using C++. It supports phrase-based and hierarchical phrase-based MT models. The code is extensible and is available under an open-source noncommercial license.
- • Others include cdec, Thot, Phramer, and Pharaoh.
7.10 Topic Modeling
Intuitively, TM is about discovering topics manifested in a document. One approach to discovering the presence of a topic in a document is based on the co-occurrence of terms in the document. For example, the topic personalized learning is associated with the presence of terms such as pedagogy, personalization, scaffolding, feedback, inclusive, and innovative. Multiple topics may be present in a document. Some open-source MT systems include
- • MALLET is a Java-based suite for statistical NLP including TM. MALLET provides a scalable implementation of Gibbs sampling, and efficient methods for document-topic hyperparameter optimization. A good tutorial on Mallet TM is presented in Graham et al. (2018).
- • Gensim implements several TM algorithms. It is written in Python and also provides distributed implementations for some TM algorithms.
- • topicmodels is an R package for TM, which is based on data structures from the text mining package tm (another R package) (Grun¨ and Hornik, 2018).
- • jLDADMM is a Java implementation of topic models for short texts. jLDADMM provides implementations of the LDA topic model and the one-topic-per-document Dirichlet Multinomial Mixture (DMM) model.
- • Other LDA implementations include lda-c (a C implementation of variational expectation maximization for LDA); class-slda (a C++ implementation of supervised Latent Dirichlet Allocation (sLDA) for classification); and Online LDA (a Python implementation for streaming document environments) (Hoffman et al., 2010).
- • BigARTM is a TM tool, which is based on a semi-probabilistic technique called Additive Regularization of Topic Models.
- • Stanford Topic Modeling Toolbox (TMT) enables building topic models using the following algorithms: LDA, labeled LDA, and Parallel Latent Dirichlet Allocation (PLDA). TMT appears to be an inactive project.
8 Workflow Systems
Typically, NLP applications require many processing steps/tasks and these steps constitute a NLP workflow/pipeline. For example, some of the tasks include language identification, sentence detection, word segmentation, PoS tagging, syntactic and dependency parsing. Given the data volumes, it is desirable to parallelize computations. Furthermore, failed computations should be recovered and reexecuted from the failure point rather than from the beginning. Finally, a mechanism should be provided so that application developers and end-users can specify an NLP workflow without writing code. Some open-source NLP workflow systems include
- • KNIME is implemented using Java and offers several machine learning and data mining components. Users can create NLP pipelines using a drag-and-drop graphical environment, and execute the pipeline partially or completely. KNIME interfaces with other open-source tools such as Weka (Holmes et al., 1994), the R project, LIBSVM (Chang and Lin, 2011), JFreeChart, ImageJ, and Chemistry Development Kit (Beisken et al., 2013).
- • LuigiNLP is another open-source NLP workflow system based on SciLuigi (Lampa et al., 2016). LuigiNLP runs on both single computers and clusters. There is a clear separation between the pipeline components. Extensibility, automatic parallelization of tasks, and recovery from failure are key features of LuigiNLP. Given the target workflow component and the initial input file, LuigiNLP will automatically determine the sequence of intermediate components to generate the target. Each component is comprised of one or more input slots, one or more output slots, and user-specifiable parameters to control processing within the component.
- • zymake is a workflow system that can be used for both NLP and machine learning (Breck, 2008). Its distinguishing features are reproducibility and scalability of experiments. Zymake enables parallel execution based on the direct acyclic graph (DAG) of dependency.
- • TextFlows is a collaborative workflow system for NLP and interactive text mining. It is implemented using Python. TextFlows enables graphically composing complex tasks that involve methods of NLP, IE, machine learning, IR, text mining, and knowledge management. Its cloud-based architecture ensures scalability and performance.
- • Cloud Machine Learning Engine (Cloud ML Engine) is a machine learning worflow component of the Google Cloud Platform. Cloud ML Engine is used to train TensorFlow applications in the cloud.
- • Orange for Web Services (Orange4WS) is a data mining workflow system which uses web services to execute workflows. Orange4WS draws upon the Orange data mining toolbox, Python web services, and a visual programming environment (Podpečan et al., 2012). A knowledge discovery ontology is used to describe the data, knowledge, and data mining services. Orange4WS features a collection of data mining and machine learning algorithms implemented in C++. Workflows are designed using a graphical user interface. The workflow elements are called widgets, which are of two kinds: flow-through and on-demand. A flow-through widget is executed as soon as all the required input data are available, whereas an on-demand widget is manually executed. A web service widget code generator automatically creates the widgets for web services (Demšar et al., 2013).
- • Pachyderm is a distributed, collaborative, data versioned workflow system. It automatically shards data for distributed processing. Pachyderm's unique features are data provenance and reproducibility of experimental results.
9 Conclusions
In this chapter, we provided an annotated list of resources available for NLP core tasks and applications development. Given the rapid advances in the field, we expect new resources will become available on a regular basis. We expect the roadmap provided in this chapter will help the reader to identify, explore, and evaluate these new resources.
Acknowledgment
This work is supported in part by the National Science Foundation IUSE/PFE:RED award #1730568.