Haar cascades are cascade classifiers that are based on Haar features. What is a cascade classifier? It is simply a concatenation of a set of weak classifiers that can be used to create a strong classifier. What do we mean by weak and strong classifiers? Weak classifiers are classifiers whose performance is limited. They don't have the ability to classify everything correctly. If you keep the problem really simple, they might perform at an acceptable level. Strong classifiers, on the other hand, are really good at classifying our data correctly. We will see how it all comes together in the next couple of paragraphs. Another important part of Haar cascades is Haar features. These features are simple summations of rectangles and differences of those areas across the image. Let's consider the following diagram:
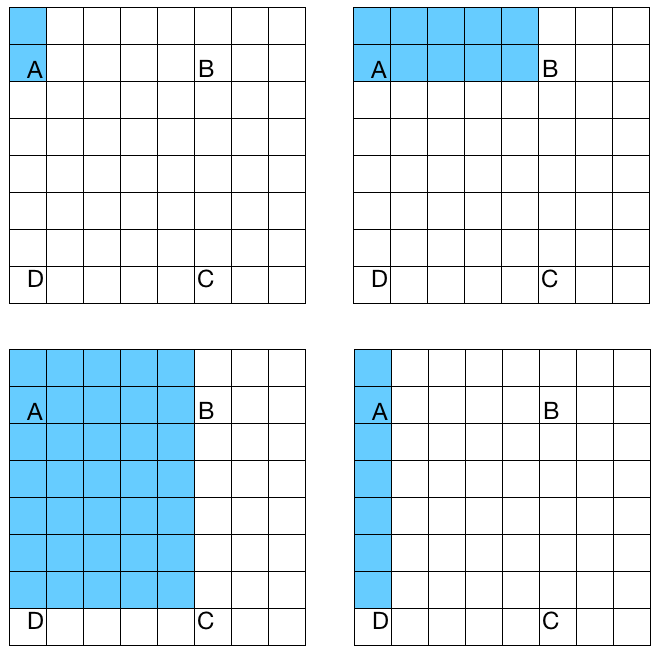
If we want to compute the Haar features for region ABCD, we just need to compute the difference between the white pixels and the blue pixels in that region. As we can see from the four diagrams, we use different patterns to build Haar features. There are a lot of other patterns that are used as well. We do this at multiple scales to make the system scale-invariant. When we say multiple scales, we just scale the image down to compute the same features again. This way, we can make it robust against size variations of a given object.
Let's dive deeper into it to understand what they actually did. They basically described an algorithm that uses a boosted cascade of simple classifiers. This system is used to build a strong classifier that can perform really well. Why did they use these simple classifiers instead of complex classifiers, which can be more accurate? Well, using this technique they were able to avoid the problem of having to build a single classifier that can perform with high precision. These single-step classifiers tend to be complex and computationally intensive. The reason their technique works so well is because the simple classifiers can be weak learners, which means they don't need to be complex. Consider the problem of building a table detector. We want to build a system that will automatically learn what a table looks like. Based on that knowledge, it should be able to identify whether there is a table in any given image. To build this system, the first step is to collect images that can be used to train our system. There are a lot of techniques available in the machine learning world that can be used to train a system such as this. Bear in mind that we need to collect a lot of table and non-table images if we want our system to perform well. In machine learning lingo, table images are called positive samples and the non-table images are called negative samples. Our system will ingest this data and then learn to differentiate between these two classes. In order to build a real-time system, we need to keep our classifier nice and simple. The only concern is that simple classifiers are not very accurate. If we try to make them more accurate, then the process will end up being computationally intensive, and hence slow. This trade-off between accuracy and speed is very common in machine learning. So, we overcome this problem by concatenating a bunch of weak classifiers to create a strong and unified classifier. We don't need the weak classifiers to be very accurate. To ensure the quality of the overall classifier, Viola and Jones have described a nifty technique in the cascading step. You can go through the paper to understand the full system.
Now that we understand the general pipeline, let's see how to build a system that can detect faces in a live video. The first step is to extract features from all the images. In this case, the algorithms need these features to learn and understand what faces look like. They used Haar features in their paper to build the feature vectors. Once we extract these features, we pass them through a cascade of classifiers. We just check all the different rectangular sub-regions and keep discarding the ones that don't have faces in them. This way, we arrive at the final answer quickly to see whether a given rectangle contains a face or not.