Chapter 9 Field Experiments in Political Science
After a period of almost total absence in political science, field experimentation has become a common research design. In
this chapter, I discuss some of the reasons for the increasing use of field experiments. Several chapters in this volume provide
comprehensive introductions to specific experimental techniques and detailed reviews of the now extensive field experimental
literatures in multiple areas. This chapter does not duplicate these contributions, but instead provides background, arguments,
opinions, and speculations. I begin by defining field experiments in Section 1. In Section 2, I discuss the intellectual context
for the emergence of field experimentation in political science, beginning with the recent revival of field experimentation
in studies of voter turnout. In Section 3, I describe the statistical properties of field experiments and explain how the
approach addresses many of the common methodological deficiencies identified in earlier observational research on campaign
effects and voter participation. Section 4 reviews the range of applications of field experimentation. In Section 5, I answer
several frequently asked questions about the limitations and weaknesses of field experimentation. In Section 6, I briefly
discuss some challenges that field experimentation faces as it becomes a more frequently employed methodological approach
in political science. This includes a discussion of the external validity of field experimental results and consideration
of how difficulties related to replication and bias in experimental reporting might affect the development of field experiment
literatures.
1. Definition
In social science experiments, units of observation are randomly assigned to groups, and treatment effects are measured by comparing outcomes across groups.1 Random assignment permits unbiased comparisons because randomization produces groups that, prior to the experimental intervention,
differ with respect to both observable and unobservable attributes only due to chance. Field experiments seek to combine the
internal validity of randomized experiments with increased external validity, or generalizability, gained through conducting the experiment in real-world settings. Field experiments aim to reproduce the environment in which the phenomenon of interest naturally occurs and thereby enhance
the external validity of the experiment.
Experiments have many dimensions, including type of subjects, experimental environment, treatments, outcome measurements,
and subject awareness of the experiment. The degree to which each dimension parallels the real-world phenomenon of interest
may vary, leading to a blurring of the distinction between what is and is not a field experiment. The economists Harrison and List (2004) propose a system for classifying studies according to their varying degrees of naturalism. Per their taxonomy, the least
naturalistic experimental study is the conventional lab experiment. This familiar study involves an abstract task, such as playing a standard game (e.g., prisoner's dilemma, dictator game), and employs the typical student subject pool. The artefactual field experiment is a conventional laboratory study with nonstandard subjects. That is, the study features subjects that more closely parallel
the real-world actors of interest to the researcher rather than a subject pool drawn from the university community. Examples
of this work include Habyarimana and colleagues (2007), who investigate ethnic cooperation through an exploration of the degree of altruism displayed in dictator games. This study
was conducted in Africa and drew its subjects from various ethnic groups in Kampala, Uganda. The framed field experiment is the same as the artefactual field experiment, except that the task is more naturalistic. An example is Chin, Bond, and Geva's (2000) study of the effect of money on access to members of Congress through an experiment in which congressional staffers made
scheduling decisions after being told whether the meeting is sought by a political action committee representative or a constituent.
The natural field experiment, which is the design often referred to in political science as a “field experiment,” is the same as the framed field experiment,
except that it involves subjects who naturally undertake the task of interest in its natural environment and who are unaware
they are participating in a study. Research in which political campaigns randomly assign households to receive campaign mailings
to test the effect of alternative communications on voter turnout is one example of a natural field experiment.
This chapter focuses on natural field experiments. Although the degree of naturalism in field experiments is the distinctive strength of the method, it is important to keep
in mind that the goal of most experimental interventions is to estimate a causal effect, not to achieve realism. It might
appear from the classification system that the movement from conventional lab experiment to natural field experiment is similar
to “the ascent of man,” but that is incorrect. The importance of naturalism along the various dimensions of the experimental
design will depend on the research objectives and whether there is concern about the assumptions required for generalization.
Consider the issue of experimental subjects. If the researcher aims to capture basic psychological processes that may be safely
assumed to be invariant across populations, experimental contexts, or subject awareness of the experiment, then nothing is
lost by using a conventional lab experiment. That said, understanding behavior of typical populations in natural environments
is frequently the ultimate goal of social science research, and it is a considerable, if not impossible, challenge to even
recognize the full set of threats to external validity present in artificial contexts, let alone to adjust the measured experimental
effects and uncertainty to account for these threats (Gerber, Green, and Kaplan 2004).
2. Intellectual Context for Emergence of Field Experiments
General Intellectual Environment
The success of randomized clinical trials in medicine provided a general impetus for exploring the application of similar
methods to social science questions. The first large-scale randomized experiment in medicine – the landmark study of the effectiveness
of streptomycin in treating tuberculosis (Medical Research Council 1948) – appeared shortly after World War II. In the years since then, the use of randomized trials in clinical research has grown to where this method now plays a central role in the evaluation of medical
treatments.2 The prominence of randomized trials in medicine led to widespread familiarity with the method and an appreciation of the
benefits of using random assignment to measure the effectiveness of interventions.
With some important exceptions, such as the negative income tax experiments of the late 1960s and 1970s, there were relatively
few social science field experiments prior to the 1990s. The increased use of field experimentation in the social sciences
emerged from an intellectual climate of growing concern about the validity of the key assumptions supporting observational research designs and growing emphasis on research designs in which exogeneity assumptions were more plausible.
By the late 1980s, the extreme difficulty in estimating causal effects from standard observational data was increasingly appreciated
in the social sciences, especially in economics (e.g., LaLonde 1986). In the field of labor economics, leading researchers began searching for natural experiments to overcome the difficulties
posed by unobservable factors that might bias regression estimates. The result was a surge in studies that investigated naturally
occurring randomizations or near-randomized applications of a “treatment.” Examples of this work include Angrist's (1990) study of the effect of serving in the Vietnam War on veteran's earnings, where the draft lottery draw altered the likelihood
of military service, and Angrist and Krueger's (1991) use of birthdates and minimum age requirements for school attendance to estimate the effect of educational attainment on
wages.
Development of Field Experimentation in Political Science
The earliest field experiments in political science were performed by Harold Gosnell (1927), who investigated the effect of get out the vote (GOTV) mailings in the 1924 presidential election and 1925 Chicago mayoral election.3 In the 1950s, Eldersveld (1956) conducted a randomized field experiment to measure the effects of mail, phone, and canvassing on voter turnout in Ann Arbor, Michigan. These pioneering experiments had only a limited effect on the trajectory of subsequent
political science research. Field experimentation was a novelty and, when considered at all, was dismissed as impractical
or of limited application (Gerber and Green 2008). In fact, the method was so rarely used that there were no field experiments published in any major political science journals
in the 1990s.
The recent revival of field experiments in political science began with a series of experimental studies of campaign activity
(Gerber and Green 2000; Green and Gerber 2004). The particular focus of the latest generation of field experimentation on measuring the effect of political communications
can be traced to persistent methodological and substantive concerns regarding the prior work in this area. To provide the
intellectual context for the revival of field experimentation in political science, I briefly review the literature on campaign
effects at the time of the Gerber and Green (2000) New Haven experiment. This prior literature includes some of the best empirical political science studies of their time. However, although the
research designs used to study campaign spending effects and voter mobilization were often ingenious, these extensive literatures
suffered from important methodological weaknesses and conflicting findings. Many of the methodological difficulties are successfully
addressed through the use of field experimentation.
Consider first the work on the effect of campaign spending on election outcomes circa 1998, the date of the first modern voter
mobilization experiment (Gerber and Green 2000). This literature did not examine the effects of specific campaign activities, but rather the relationship between overall
Federal Election Commission reported spending levels and candidate vote shares.4 There were three main approaches to estimating the effect of campaign spending on candidate vote shares. In the earliest
work, Jacobson and others (e.g., Jacobson 1978, 1985, 1990, 1998; Abramowitz 1988) estimated spending effects using ordinary least squares regressions of vote shares on incumbent and challenger spending levels.
This strategy assumes that spending levels are independent of omitted variables that also affect vote share. Concern that
this assumption was incorrect was heightened by the frequently observed negative correlation between incumbent spending and incumbent vote share. In response to this potential difficulty, there were two
main alternative strategies. First, some scholars proposed instrumental variables for candidate spending levels (e.g., Green and Krasno 1988; Ansolabehere and Snyder 1996; Gerber 1998).5 Second, Levitt (1994) examined the performance of pairs of candidates who faced each other more than once. The change in vote shares between the
initial contest and rematch were compared to the changes in candidate spending between the initial contest and rematch, a
strategy that serves to difference away difficult to measure district- or candidate-level variables that might be lurking
in the error term.
Table 9.1: Approximate Cost of Adding One Vote to Candidate Vote Margin
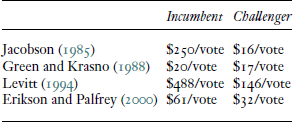
Notes: 2008 dollars. Calculations are based on 190,000 votes cast in a typical House district. For House elections, this implies
that a 1% boost in the incumbent's share of the vote increases the incumbent's vote margin by 3,800 votes.
Source: Adapted from Gerber (2004).
Unfortunately, the alternative research designs produce dramatically different results. Table 9.1 reports, in dollar per vote terms, the cost per additional vote implied by the alternative approaches. The dollar figures listed are the cost of changing the vote margin by one vote.6 Table 9.1 illustrates the dramatic differences in the implications of the alternative models and underscores how crucial modeling assumptions
are in this line of research. Depending on the research design, it is estimated to cost as much as $500 or as little as $20
to improve the vote margin by a single vote (Gerber 2004). However, it is not clear which estimates are most reliable because each methodological approach relies on assumptions that
are vulnerable to serious critiques.7 The striking diversity of results in the campaign spending literature, and the sensitivity of the results to statistical assumptions, suggested
the potential usefulness of a fresh approach to measuring the effect of campaign activity on voter behavior.
Table 9.2. Voter Mobilization Experiments Prior to 1998 New Haven Experiment
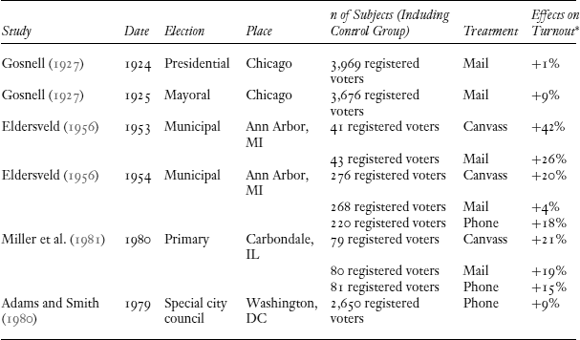
* These are the effects reported in the tables of these research reports. They have not been adjusted for contact rates.
Notes: In Eldersveld's 1953 experiment, subjects were those who opposed or had no opinion about charter reform. In 1954, subjects
were those who had voted in national but not local elections. This table includes only studies that use random experimental
design (or near random, in the case of Gosnell [1927]).
Source: Adapted from Gerber, Green, and Nickerson (2001).
One feature of the campaign spending literature is that it typically uses overall campaign spending as the independent variable.
Overall campaign spending is an amalgamation of spending for particular purposes, and so the effectiveness of overall spending
is determined by the effectiveness of particular campaign activities, such as voter mobilization efforts. This suggests the
value of obtaining a reasonable dollar per vote estimate for the cost of inducing a supporter to vote. Indeed, as the campaign
spending literature progressed, a parallel and independent literature on the effects of campaign mobilization on voter turnout was developing. What did these observational and experimental studies say about the effectiveness of voter mobilization
efforts?
As previously mentioned, at the time of the 1998 New Haven study (Gerber and Green 2000), there was already a small field experimental literature on the effect of campaigns on voter turnout. Table 9.2 summarizes the field experiment literature prior to the 1998 New Haven experiment. By far, the largest previous study was
from Gosnell (1927), who measured the effect of nonpartisan mail on voter turnout in Chicago. In this pioneering research, 8,000 voters were
divided by street into treatment (GOTV mailings) and control group. Three decades later, Eldersveld conducted a randomized
intervention during a local charter reform vote to measure the effectiveness of alternative campaign tactics. He later analyzed the effect of a drive to mobilize apathetic voters in an Ann Arbor municipal election (Eldersveld and Dodge 1954; Eldersveld 1956). These experiments measured the turnout effects of a variety of different modes of communications. In the following years,
only a handful of scholars performed similar research. Miller, Bositis, and Baer (1981) examined the effects of a letter sent to residents of a precinct in Carbondale, Illinois, prior to the 1980 general election.
Adams and Smith (1980) conducted an investigation of the effect of a single thirty-second persuasion call on turnout and candidate choice in a
special election for a Washington, DC, city council seat. In sum, prior to 1998, only a few field experiments on mobilization – spread across a range of political contexts and over many decades – had been conducted. Nevertheless, these
studies formed a literature that might be taken to support several tentative conclusions. First, the effects of voter contacts
appeared to be extremely large. Treatment effects of twenty percentage points or more are common in these papers. Thus, we might conclude that voters can
be mobilized quite easily, and because mobilizing supporters is a key task, by implication even modest campaign resource disparities
will play an important role in election results. Second, there is no evidence that the effect of contacts had changed over
the many years that separated these studies – the effectiveness of mailings in the 1980s was as great as what had been found
in earlier decades.
In addition to these early field experiments, another important line of work on campaign effects used laboratory experiments
to investigate how political communications affect voter turnout. A leading example is the study by Ansolabehere and Iyengar (1996), which finds that exposure to negative campaign advertisements embedded in mock news broadcasts reduced subjects’ reported
intention to vote, with effects particularly large among independent voters. As with field experiments, these laboratory studies
use random assignment. However, integrating the results of these important and innovative laboratory studies into estimates
of voter mobilization effects is challenging. Although the internal validity of such studies is impressive, the magnitude
of the laboratory effects may not provide a clear indication of the magnitude of treatment effects in naturalistic contexts.
More generally, although it is often remarked that a laboratory experiment will reliably indicate the direction but not the magnitude of the effect that would be observed in a natural setting, to my knowledge this has not been demonstrated,
and it is not obviously correct in general or specific cases.8 Furthermore, despite the careful efforts of researchers such as Ansolabehere and Iyengar to simulate a typical living room
for conducting the experiment, the natural environment differs from the laboratory environment in many obvious and possibly
important ways, including the subject's awareness of being monitored.
Complementing the experimental evidence, there is a large amount of observational research on campaigns and voter turnout. As of 2000, the most influential work on turnout was survey-based analyses
of the causes of participation. Rosenstone and Hansen's (1993) book is a good example of the state of the art circa 1998 (see also Verba, Schlozman, and Brady 1995). This careful study is an excellent resource that is consulted and cited by nearly everyone who writes about turnout (according
to Google Scholar, as of June 30, 2010, more than 1,500 times), and the style of analysis employed is still common in current
research. Rosenstone and Hansen use the American National Election Studies (ANES) to measure the effect of campaign contacts
on various measures of political participation. They report the contribution of many different causes of participation in
presidential and midterm years (see tables 5.1 and 5.2 in Rosenstone and Hansen 1993) based on estimates from a pooled cross-sectional analysis of ANES survey data. The estimated effect of campaign contact on reported voter turnout is approximately an eight
to ten percentage point boost in turnout probability.
This sizable turnout effect from campaign contact is of similar magnitude to many of those reported in the field experiments
from the 1920s through the 1980s. The sample size used in the Rosenstone and Hansen (1993) study is impressive (N is 11,310 for presidential years, 5,124 for mid-term elections), giving the estimation results the
appearance of great precision. However, there are several methodological and substantive reasons why the findings might be
viewed as unreliable. First, the results from the survey-based voter mobilization research appear to be in tension with at
least some of the aggregate campaign spending results. If voters can be easily mobilized by a party contact, then it is difficult to understand why a campaign would have to spend
so much to gain a single vote (Table 9.1). Rather, modest amounts of spending should yield large returns. This tension could perhaps be resolved if there are large
differences between average and marginal returns to mobilization expenditures or if campaign spending is highly inefficient.
Nevertheless, taking the survey evidence and the early field experiments on voter mobilization seriously, if a campaign contact
in a presidential year boosts turnout by eight percentage points and a large share of partisans in the ANES report not being
contacted, then it is hard to simultaneously believe both the mobilization estimates and the findings (summarized in Table 9.1), suggesting that campaigns must spend many hundreds of dollars per vote.9 More important, the survey work on turnout effects is vulnerable to a number of methodological criticisms. The key problem
in the survey-based observational work is the possibility that those who report campaign contact are different from those
who do not report contact in ways that are not adequately captured by the available control variables. The Gerber and Green (2000) study and subsequent field experiments were in many ways an attempt to address this selection bias and other possible weaknesses of the earlier work.
3. How Do Experiments Address Problems in Prior Research?
In this section, I present a framework for analyzing causal effects and apply the framework to describe how field experiments eliminate some of the possible bias in observational studies. For concreteness, I use the Rosenstone and
Hansen (1993) study as a running example. In their participation study, some respondents are contacted by campaigns and others are not.
In the language of experiments, some subjects are “treated” (contacted) and others are “untreated” (not contacted). The key
challenge in estimating the causal effect of the treatment is that the analyst must somehow use the available data to construct an estimate of a counterfactual: what outcome
would have been observed for the treated subjects had they not been treated? The idea that for each subject there is a “potential
outcome” in both the treated and the untreated state is expressed using the notational system termed the “Rubin causal model” after Rubin (1978, 1990).10 To focus on the main ideas, I initially ignore covariates. For each individual i, let Yi0 be the outcome if i does not receive the treatment (in this example, contact by the mobilization effort) and Yi1 be the outcome if i receives the treatment. The treatment effect for individual i is defined as
 |
(1) |
The treatment effect for individual i is the difference between the outcomes for i in two possible, although mutually exclusive, states of the world – one in which i receives the treatment and another in which i does not. Moving from a single individual to the average for a set of individuals, the average treatment effect for the treated (ATT) is defined as
where E stands for a group average and Ti = 1 when a person is treated. In words, Yi1|Ti = 1 is the post-treatment outcome among those who are treated, and Yi0|Ti = 1 is the outcome for i that would have been observed if those who are treated had not been treated. Equation (2) suggests why it is difficult to estimate a causal effect. Because each individual is either treated or not, for each individual
we observe either Y1 or Y0. However, to calculate Equation (2) requires both quantities for each treated individual. In a dataset, the values of Y1 are observed for those who are treated, but the causal effect of the treatment cannot be measured without an estimate of
what the average Y would have been for these individuals had they not been treated. Experimental and observational research designs employ different
strategies for producing estimates of this counterfactual. Observational data analysis forms a comparison group using those
who remain untreated. This approach generates selection bias in the event that the outcomes in the untreated state for those who are untreated are different from the outcomes
in the untreated state for those who are treated. In other words, selection bias occurs if the differences between those who
are and are not treated extend beyond exposure to the treatment. Stated formally, the observational comparison of the treated
and the untreated compares:
A comparison of the average outcomes for the treated and the untreated equals the average treatment effect for the treated
plus a selection bias term. The selection bias is due to the difference in the outcomes in the untreated state for those treated
and those untreated. This selection bias problem is a critical issue addressed by experimental methods. Random assignment forms groups without reference to either observed or unobserved attributes of the subjects and, consequently,
creates groups of individuals that are similar prior to application of the treatment. When groups are formed through random
assignment, the group randomly labeled the control group has the same expected average outcome in the untreated state as the
set of subjects designated at random to receive the treatment. The randomly assigned control group can therefore be used to
produce an unbiased estimate of what the outcome would have been for the treated subjects, had the treated subjects remained
untreated, thereby avoiding selection bias.
 |
(2) |
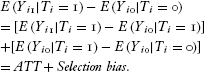 |
(3) |
The critical assumption for observational work to produce unbiased treatment effect estimates is that, controlling for covariates (whether through regression or through matching), E(Yi0|Ti = 1) = E(Yi0|Ti = 0) (i.e., apart from their exposure to the treatment, the treated and untreated group outcomes are on average the same
in the untreated state). Subject to sampling variability, this will be true by design when treatment and control groups are
formed at random. In contrast, observational research uses the observables to adjust the observed outcomes and thereby produce
a proxy for the treated subject's potential outcomes in the untreated state. If this effort is successful, then there is no
selection bias. Unfortunately, without a clear rationale based on detailed knowledge of why some observations are selected
for treatment and others are not, this assumption is rarely convincing. Consider the case of estimating the effect of campaign
contact on voter turnout. First, there are likely to be important omitted variables correlated with campaign contact that
are not explained by the included variables. Campaigns are strategic and commonly use voter files to plan which households
to contact. A key variable in many campaign targeting plans is the household's history of participation, and households that do not vote tend to be ignored. The set of control variables available in the
ANES data, or other survey datasets, does not commonly include vote history or other variables that might be available to
the campaign for its strategic planning. Second, past turnout is highly correlated with current turnout. Therefore, E(Yi0|Ti = 1) may be substantially higher than E(Yi0|Ti = 0). Moreover, although it may be possible to make a reasonable guess at the direction of selection bias, analysts rarely
have a clear notion of the magnitude of selection bias in particular applications, so it is uncertain how estimates may be
corrected.11
In addition to selection bias, field experiments address a number of other common methodological difficulties in observational
work, many of these concerns related to measurement. In field experiments, the analyst controls the treatment assignment, so there is no error in measuring who is
targeted for treatment. Although observational studies could, in principle, also measure the treatment assignment accurately,
in practice analysis is frequently based on survey data, which relies on self-reports. Again, consider the case of the voter
mobilization work. Contact is self-reported (and, for the most part, so is the outcome, voter turnout). When there is misreporting,
the collection of individuals who report receiving the treatment are in fact a mix of treated and untreated individuals. By
placing untreated individuals in the treated group and treated individuals in the untreated group, random misclassification
will tend to attenuate the estimated treatment effects. In the extreme case, where the survey report of contact is unrelated
to actual treatment status or individual characteristics, the difference in outcomes for those reporting treatment and those
not reporting treatment will vanish. In contrast, systematic measurement error could lead to exaggeration of treatment effects.
In the case of survey-based voter mobilization research, there is empirical support for concern that misreporting of treatment
status leads to overestimation of treatment effects. Research has demonstrated both large amounts of misreporting and also
a positive correlation between misreporting having been contacted and misreporting having voted (Vavreck 2007; Gerber and Doherty 2009).
There are some further difficulties with survey-based observational research that are addressed by field experiments. In addition to the uncertainty regarding who
was assigned the treatment, it is sometimes unclear what the treatment was because survey measures are sometimes not sufficiently
precise. For example, the ANES item used for campaign contact in the Rosenstone and Hansen study asks respondents: “Did anyone
from one of the political parties call you up or come around and talk to you about the campaign?” This question ignores nonpartisan
contact; conflates different modes of communication, grouping together face-to-face canvassing, volunteer calls, and commercial
calls (while omitting important activities such as campaign mailings); and does not measure the frequency or timing of contact.
In addition to the biases discussed thus far, another potential source of difference between the observational and experimental estimates is
that those who are treated outside the experimental context may not be the same people who are treated in an experiment. If
those who are more likely to be treated in the real world (perhaps because they are likely to be targeted by political campaigns)
have especially large (or small) treatment effects, then an experiment that studies a random sample of registered voters will
underestimate (or overestimate) the ATT of what may often be the true population of interest – those individuals most likely
to be treated in typical campaigns. A partial corrective for this is weighting the result to form population proportions similar
to the treated population in natural settings, although this would fail to account for differences in treatment effects between
those who are actually treated in real-world settings and those who “look” like them but are not treated.
Finally, although this discussion has focused on the advantages of randomized experiments over observational studies, field
experimentation also has some advantages over conventional laboratory experimentation in estimating campaign effects. Briefly,
field experiments of campaign communications typically study the population of registered voters (rather than a student population or other volunteers),
measure behavior in the natural context (versus a university laboratory or a “simulated” natural environment; also, subjects
are typically unaware of the field experiment), and typically estimate the effect of treatments on the actual turnout (rather
than on a surrogate measure such as stated vote intention or political interest).
4. Development and Diffusion of Field Experiments in Political Science
The details of the 1998 New Haven study are reported in Gerber and Green (2000). Since this study, which assessed the mobilization effects of nonpartisan canvassing, phone calls, and mailings, more than
100 field experiments have measured the effects of political communications on voter turnout. The number of such studies is
growing quickly (more than linearly), and dozens of researchers have conducted voter mobilization experiments. Some studies
essentially replicate the New Haven study and consider the effect of face-to-face canvassing, phone, or mail in new political
contexts, including other countries (e.g., Guan and Green 2006; Gerber and Yamada 2008; John and Brannan 2008). Other work looks at new modes of communication or variations on the simple programs used in New Haven, including analysis
of the effect of phone calls or contacts by communicators matched to the ethnicity of the household (e.g., Michelson 2003), repeat phone calls (Michelson, García Bedolla, and McConnell 2009), television and radio (Panagopoulos and Green 2008; Gerber, Gimpel et al. in press), and new technologies, such as e-mail and text messaging (Dale and Strauss 2007). Field experiments have also measured the effect of novel approaches to mobilization, such as Election Day parties at the
polling place (Addonizio, Green, and Glaser 2007).
The results of these studies are compiled in a quadrennial review of the literature, Get Out the Vote!, the latest version of which was published in 2008 (Green and Gerber 2008). A detailed review of the literature over the past ten years is also contained in Nickerson and Michelson's chapter in this
volume. A meta-analysis of the results of dozens of canvassing, mail, and phone studies shows that the results from the initial New
Haven study have held up fairly well. Canvassing has a much larger effect than do the less personal modes of communication,
such as phone and mail. The marginal effect of brief commercial calls, such as those studied in New Haven, and nonpartisan
mailings appears to be less than one percentage point, whereas canvassing boosts turnout by about seven percentage points
in a typical electoral context.12
In recent years, field experimentation has moved well beyond the measurement of voter mobilization strategies and has now
been applied to a broad array of questions. Although the first papers were almost entirely by American politics specialists,
comparative politics and international relations scholars are now producing some of the most exciting work. Moreover, the
breadth of topics in American politics that researchers have addressed using field experiments has grown immensely. A sense
of the range of applications can be gained by considering the topics addressed in a sampling of recent studies using field
experiments:
• Effect of partisanship on political attitudes: Gerber, Huber, and Washington (2010) study the effect of mailings informing unaffiliated, registered voters of the need to
affiliate with a party to participate in the upcoming closed primary. They find that the mailings increase formal party affiliation and, using a post-treatment survey, they find a shift in partisan identification, as well as a shift in political
attitudes.
• Influence of the media on politics: Gerber, Karlan, and Bergan (2009) randomly provide Washington Post and Washington Times newspaper subscriptions to respondents prior to a gubernatorial election to examine the effect of media slant on voting behavior.
They find that the newspapers increase voter participation and also shift voter preference toward the Democratic candidate.
• Effect of interpersonal influence: Nickerson (2008) analyzes the effect of a canvassing effort on household members who are not directly contacted by the canvasser. He finds
that spouses and roommates of those who are contacted are also more likely to vote following the canvassing treatment.
• Effect of mass media campaigns: Gerber, Gimpel, et al. (in press) analyze the effect of a multimillion-dollar partisan television advertising campaign. Using
tracking polls to measure voter preferences each day, they find a strong but short-lived boost in the sponsor's vote share.
• Effect of candidate name recognition: Panagopoulos and Green (2008) measure the effect of radio ads that boost name recognition in low salience elections. They find that ads that provide equal
time to both the incumbent's name and challenger's name have the effect of boosting the (relatively unknown) challenger's
vote performance.
• Effect of political institutions and policy outcomes and legitimacy: Olken (2010) compares the performance of alternative institutions for the selection of a public good in Indonesia. He finds that, although
more participatory institutions do not change the set of projects approved, participants are more satisfied with the decision-making
process.
• Effect of Election Day institutions on election administration: Hyde (2010) studies the effect of election monitors on vote fraud levels.
• Effect of lobbying on legislative behavior: Bergan (2009) examines the effect of a lobbying effort on a bill in the New Hampshire legislature. An e-mail from an interest group causes
a statistically significant increase in roll call voting for the sponsor's measure.
• Effect of constituency opinion on legislator behavior: Butler and Nickerson (2009) examine the effect of constituency opinion on legislative voting. They find that mailing legislators polling information
about an upcoming legislative measure results in changes in the pattern of roll call support for the measure.
• Effect of voter knowledge on legislative behavior: Humphreys and Weinstein (2007) examine the effect of legislative performance report cards on representatives’ attendance records in Uganda. They find that
showing legislators’ attendance records to constituents results in higher rates of parliamentary attendance.
• Effect of social pressure on political participation: Gerber, Green, and Larimer (2008) investigate the effect of alternative mailings, which exert varying degrees of social pressure. They find that a preelection
mailing that lists the recipient's own voting record and a mailing that lists the voting record of the recipient and his or
her neighbors caused a dramatic increase in turnout.
• Media and interethnic tension/prejudice reduction: Paluck and Green (2009) conduct a field experiment in postgenocide Rwanda. They randomly assign some communities to a condition where they are provided
with a radio program designed to encourage people to be less deferential to authorities. The findings demonstrate that listening
to the program makes listeners more willing to express dissent.
Mickelson and Nickerson's chapter and Wantchekon's chapter in this volume provide excellent discussions of recent field experiments
many further examples. In addition to addressing important substantive questions, field experiments can make methodological contributions, such as assessing the
performance of standard observational estimation methods. In this line of research, data from experimental studies are reanalyzed using observational
techniques. The performance of the observational estimation method is evaluated by comparing the estimation results from an
application of the observational method with the unbiased experimental estimates. Arceneaux, Gerber, and Green (2006) conduct one such comparison by assessing the performance of regression and matching estimators in measuring the effects
of experimental voter mobilization phone calls. The study compares the experimental estimates of the effect of a phone call
(based on a comparison of treatment and control group) and the estimates that would have been obtained had the experimental
dataset been analyzed using observational techniques (based on a comparison of those whom the researchers were able to successfully
contact by phone and those not contacted). They find that exact matching and regression analysis overestimate the effectiveness
of phone calls, producing treatment effect estimates several times larger than the experimental estimates.
Reviewing these contributions, both substantive and methodological, a collection that is only part of the vast body of recent
work, shows the depth and range of research in political science using field experimentation. The earliest studies have now
been replicated many times, and new studies are branching into exciting and surprising areas. I doubt that ten years ago anyone
could have predicted the creativity of recent studies and the range of experimental manipulations. From essentially zero studies
just more than a decade ago, field experimentation is now a huge enterprise. I draw several conclusions about recent developments.
First, voter mobilization is still studied, but the research focus has shifted from simply measuring the effectiveness of campaign communications
to broader theoretical issues such as social influence, norm compliance, collective action, and interpersonal influence. Second,
there has been a move from studying only political behavior to the study of political institutions as well. Third, field experimentation
has spread from initial application in American politics to comparative politics and international relations. Fourth, field
experiments are now used to study both common real-world phenomena (e.g., campaign television commercials or the effect of
election monitors), as well as novel interventions for which there are no observational counterparts (unusual mailings or
legislative report cards in developing countries). For these novel interventions, of course, no observational study is possible.
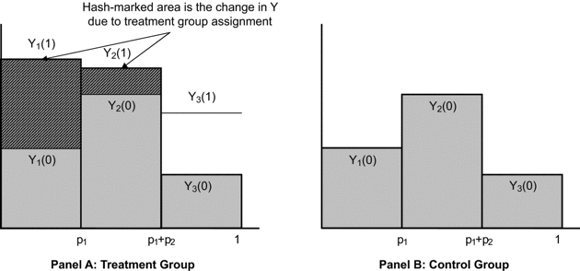
Figure 9.1. Graphical Representation of Treatment Effects with Noncompliance
Yi(X) = Potential outcome for type i when treated status is X (X = 0 is untreated, X = 1 is treated). The Y axis measures the outcome, whereas the X axis measures the proportion of the subjects of each type.
 |
5. Frequently Asked Questions
Field experiments are not a panacea, and there are often substantial challenges in the implementation, analysis, and interpretation
of findings. For an informative recent discussion of some of the limitations of field experiments, see Humphreys and Weinstein (2009) and especially Deaton (2009); for a reply to Deaton, see Imbens (2009). Rather than compile and evaluate a comprehensive list of potential concerns and limitations, I provide in this section
a somewhat informal account of how I address some of the questions I am frequently asked about field experiments.13 The issue of the external validity of field experiments is left for Section 7.
Some field experiments have high levels of noncompliance due to the inability to treat all of those assigned to the treatment group (low contact rates). Other methods,
such as lab experiments, seem to have perfect compliance. Does this mean field experiments are biased?
Given that one-sided noncompliance (i.e., the control group remains untreated, but some of those assigned to the treatment
group are not treated) is by far the most common situation in political science field experiments, the answer addresses this
case. If the researcher is willing to make some important technical assumptions (see Angrist, Imbens, and Rubin [1996] for a formal statement of the result) when there is failure to treat in a random experiment, a consistent (large sample unbiased) estimate of the average treatment effect on those treated can be estimated by differencing the mean outcome
for those assigned to the treatment and control groups and dividing this difference by the proportion of the treatment group
that is actually treated.
The consequences of failure to treat are illustrated in Figure 9.1, which depicts the population analogues for the quantities that are produced by an experiment with noncompliance.14 Figure 9.1 provides some important intuitions about the properties and limitations of the treatment effect estimate when some portion
of the treatment group is not treated. It depicts a pool of subjects in which there are three types of people (a person's
type is not directly observable to the experimenter), and in which each type has different values of Yi(0) and Yi(1), where Yi(X) is the potential outcome for a subject of type i when treated (X = 1) or untreated (X = 0). Individuals are arrayed by group, with the X axis marking the population proportion of each type and the Y axis indicating average outcome levels for subjects in each group. Panel A depicts the subjects when they are assigned to
the treatment group, and panel B shows the subjects when assigned to the control group. (Alternatively, Figure 9.1 can be thought of as depicting the potential outcomes for a large population sample, with some subjects randomly assigned
to the treatment group and others to the control group. In this case, the independence of treatment group assignment and potential
outcomes ensures that for a large sample, the proportions of each type of person are the same for the treatment and the control
group, as are the Yi(X) levels.)
Panel A shows the case where two of the three types of people are actually treated when assigned to the treatment group and
one type is not successfully treated when assigned to the treatment group (in this example, type 1 and type 2 are called “compliers”
and type 3 people are called “noncompliers”). The height of each of the three columns represents the average outcome for each
group, and their widths represent the proportion of the subject population of that type. Consider a simple comparison of the average outcome when subjects are assigned to the
treatment group versus the control group (a.k.a. the intent-to-treat [ITT] effect). The geometric analogue to this estimate
is to calculate the difference in the total area of the shaded rectangles for both treatment and control assignment. Visually,
it is clear that the difference between the total area in panel A and the total area in panel B is an area created by the
change in Y in panel A due to the application of the treatment to groups 1 and 2 (the striped rectangles). Algebraically, the difference
between the treatment group average and the control group average, the ITT, is equal to [Y1(1) – Y1(0)] p1 + [Y2(1) – Y2(0)] p2. Dividing this quantity by the share of the treatment group actually treated, (p1 + p2), produces the ATT.15 This is also called the complier average causal effect (CACE), highlighting the fact that the difference between the average outcomes when the group
is assigned to the treatment versus the control condition is produced by the changing treatment status and subsequent difference
in outcomes for the subset of the subjects who are compliers.
As Figure 9.1 suggests, one consequence of failure to treat all of those assigned to the treatment group is that the average treatment
effect is estimated for the treated, not the entire subject population. The average treatment effect (ATE) for the entire subject pool equals [Y1(1) – Y1(0)] p1 + [Y2(1) – Y2(0)] p2 + [Y3(1) – Y3(0)] p3. Because the final term in the ATE expression is not observed, an implication of noncompliance is that the researcher is only
able to directly estimate treatment effects for the subset of the population that one is able to treat. The implications of
measuring the ATT rather than the ATE depend on the research objectives and whether treatment effects vary across individuals.
Sometimes the treatment effect among those who are treated is what the researcher is interested in, in which case failure
to treat some types of subjects is a feature of the experiment, not a deficiency. For example, if a campaign is interested
in the returns from a particular type of canvassing sweep through a neighborhood, the campaign wants to know the response
of the people whom the effort will likely reach, not the hypothetical responses of people who do not open the door to canvassers
or who have moved away.
If treatment effects are homogeneous, then the CACE and the ATE are the same, regardless of the contact rate. Demonstrating
that those who are treated in an experiment have pre-treatment observables that differ from the overall population mean is
not sufficient to show that the CACE is different from the ATE, because what matters is the treatment effect for compliers
versus noncompliers (see Equation [1]), not the covariates or the level of Yi(0). Figure 9.1 could be adjusted (by making the size of the gap between Yi(0) and Yi(1) equal for all groups) so that all groups have different Yi(0) but the same values of Yi(1) – Yi(0). Furthermore, higher contact rates may be helpful at reducing any gap between CACE and ATE. As Figure 9.1 illustrates, if the type 3 (untreated) share of the population approaches zero (the column narrows), then the treatment effect
for this type would have to be very different from the other subjects in order to produce enough “area” for this to lead to
a large difference between the ATE and CACE. Although raising the share of the treatment group that is successfully treated
typically reduces the difference between ATE and CACE, in a pathological case, if the marginal treated individual has a more
atypical treatment effect than the average of those “easily” treated, then the gap between CACE and ATE may grow as the proportion
treated increases. The ATE and CACE gap can be investigated empirically by observing treatment effects under light and intensive
efforts to treat. This approach parallels the strategy of investigating the effects of survey nonresponse by using extra effort to interview and determining whether there are differences in the lower and higher response rate samples (Pew Research
Center 1998).
Although the issue of partial treatment of the target population is very conspicuous in many field experiments, it is also
a common problem in laboratory experiments. Designs such as typical laboratory experiments that put off randomization until
compliance is assured will achieve a 100-percent treatment rate, but this does not “solve” the problem of measuring the treatment
effect for a population (ATE) versus those who are treatable (CACE). The estimand for a laboratory experiment is the ATE for the particular group of people
who show up for the experiment. Unless this is also the ATE for the broader target population, failure to treat has entered
at the subject recruitment stage.
One final note is that nothing in this answer should be taken as asserting that a low contact rate does not matter. The discussion
has focused on estimands, but there are several important difficulties in estimating the CACE when there are low levels of
compliance. First, noncompliance affects the precision of the experimental estimates. Intuitively, when there is nearly 100
percent failure to treat, it would be odd if meaningful experimental estimates of the CACE could be produced because the amount
of noise produced by random differences in Y due to sampling variability in the treatment and control groups would presumably swamp any of the difference between the
treatment and control groups that was generated by the treatment effect. Indeed, a low contact rate will lead to larger standard
errors and may leave the experimenter unable to produce useful estimates of the treatment effect for the compliers. Further, estimating the CACE by dividing the observed difference in treatment and control group outcomes by the share of
the treatment group that is treated can be represented as a two-stage estimator. The first stage regression estimates observed
treatment status (treated or not treated) as a function of whether the subject is assigned to the treatment group. When treatment
group assignment produces only a small change in treatment status (e.g., the contact rate is very low in a mobilization experiment)
and the sample size is small, group assignment is a weak instrument and estimates may be meaningfully biased. The danger of
substantial bias from weak instruments is diagnosed when assignment to the treatment group does not produce a strong statistically
significant effect on treatment status. See Angrist and Pischke (2009) for an extended discussion of this issue.
Do Field Experiments Assume Homogeneous Treatment Effects?
The answer is “no.” See Figure 9.1, which depicts a population in which the compliers are divided into two subpopulations with different treatment effects.
The ITT and the CACE both estimate the average treatment effects, which may vary across individuals.
Are Field Experiments Ethical?
All activities, including research, raise ethical questions. For example, it is surprising to read that certain physics experiments
currently being conducted are understood by theoreticians to have a measurable (although very small) probability of condensing
the planet Earth into a sphere 100 meters in diameter (Posner 2004). I am not aware of any field experiments in political science that pose a remotely similar level of threat. A full treatment
of the subject of research ethics is well beyond the scope of a brief response and not my area of expertise, but I will make
several points that I believe are sometimes neglected.
First, advocates of randomized trials in medicine turn the standard ethical questions around and argue that those who treat
patients in the absence of well-controlled studies should reflect on the ethics of using unproven methods and not performing
the experiments necessary to determine whether the interventions they employ actually work. They argue that many established
practices and policies are often merely society-wide experiments (and, as such, poorly designed experiments that lack a control
group but somehow sidestep ethical scrutiny and bureaucratic review). They recount the tragedies that followed when practices were adopted without the support of experimental
evidence (Chalmers 2003). Taking this a step further, recent work has begun to quantify the lives lost due to delays imposed by institutional review
boards (Whitney and Schneider 2010).
Second, questions are occasionally raised as to whether an experimental intervention might change a social outcome, such as
affecting an election outcome by increasing turnout. Setting aside the issue of whether changing an election outcome through
increased participation or a more informed electorate (the most common mechanism for this hypothetical event, given current
political science field experiments) is problematic or praiseworthy, in the highly unlikely event that an experiment did alter
an election result, this would only occur for the small subset of elections where the outcome would have been tied or nearly
tied in the absence of the experiment. In this case, there are countless other mundane and essentially arbitrary contributions
to the outcome with electoral consequences that are orders of magnitude larger than the typical experimental intervention.
A partial list includes ballot order (Miller and Krosnick 1998); place of voting (Berger, Meredith, and Wheeler 2008); number of polling places (Brady and McNulty 2004); use of optical scan versus punch card ballots (Ansolabehere and Stewart 2005); droughts, floods, or recent shark attacks (Achen and Bartels 2004); rain on Election Day (Knack 1994); and a win by the local football team on the weekend prior to the election (Healy, Malhotra, and Mo 2009). That numerous trivial or even ridiculous factors might swing an election seems at first galling, but note that these factors
only matter when the electorate is very evenly divided. In this special case, however, regardless of the election outcome,
an approximately equal number of citizens will be pleased and disappointed with the result. As long as there is no regular
bias in which side gets the benefit of chance, there may be little reason for concern. Perhaps this is why we do not bankrupt
the treasury to make sure our elections are entirely error free.
Does the Fact That Field Experiments Do Not Control for Background Activity Cause Bias?
Background activity affects the interpretation of the experimental results but does not cause bias. Background conditions
affect Yi(0) and Yi(1), but subjects can be assigned and unbiased treatment effects can be estimated in the usual fashion. That is not to say
that background conditions do not matter, because they may affect Y(0) and Y(1) and therefore the treatment effect Y(1) – Y(0). If the treatment effect varies with background conditions, then background factors affect the generalizability of the results; the treatment effect that is estimated should be thought of as conditional on the background
conditions.
Are Field Experiments Too Expensive to Be Used in My Research?
Field experiments tend to be expensive, but there are ways to reduce the cost, sometimes dramatically. Many recent field experiments
were performed in cooperation with organizations that are interested in evaluating a program or communications effort. Fortunately,
a growing proportion of foundations are requiring (and paying for) rigorous evaluation of the programs they support, which
should provide a steady flow of projects looking for partners to assist in experimental evaluations.
What about Treatment “Spillover” Effects?
Spillover effects occur when those who are treated in turn alter their behavior in a way that affects other subjects.16 Spillover is a potentially serious issue in field experiments. It is also fair to note that spillover is typically not a problem in the controlled environment of laboratory experiments because contact among subjects can be observed and regulated.
In most applications, the presence of spillover effects attenuate estimated treatment effects by causing the control group
to be partially treated. If the researcher is concerned about mitigating the danger from spillover effects, then reducing the density of treatment is one option; this will
likely reduce the share of the control group affected by spillover. Another perspective is to consider spillover effects as
worth measuring in their own right; some experiments have been designed to measure spillover (Nickerson 2008). It is sometimes forgotten that spillover is also an issue in observational research. In survey-based observational studies
of party contact and candidate choice, for example, only those who report direct party contact are coded as contacted. If
those who are contacted in turn mobilize those who are not contacted, then this will introduce a downward bias into the observational
estimate of the causal effect of party contact, which is based on comparison of those coded treated and those coded untreated.
6. Further Issues
In this section, I sound some notes of caution regarding the development of field experiments in political science. I first
discuss the issue of how to interpret the results from field experiments. Field experiments to date have often focused on
producing accurate measurement rather than illuminating broader theoretical issues. However, in the absence of some theoretical
context, it may be difficult to judge what exactly is being measured. Second, I discuss some problems with the development
of literatures based on field experiments. These issues relate to the difficulty of replication and the potential sources
of bias in experimental reporting, especially when projects are undertaken with nonacademic partners.
Unbiased Estimates…of What?
Field experimentation is a measurement technique. Many researchers who use field experiments are content to report treatment
effects from an intervention and leave it at that, an empiricism that has led some observers to dismiss field experiments
as mere program evaluations without broader theoretical contribution. This line of criticism fails to appreciate the enormous
importance of obtaining convincing causal estimates. Throughout the history of science, new measurement technologies (e.g.,
the microscope, spectography) and reliable causal estimates (controlled experiments) have been the crucial impetus to productive
theorizing. There are also practical costs to ignoring solid empirical demonstrations because of concerns about theoretical
mechanisms. Taking an example from the history of medicine, consider the prescient findings of Semmelweis, who conducted a
pioneering experiment in the 1860s demonstrating that washing hands in a disinfectant significantly reduced death from postpartum
infection. Critics, however, claimed that his theory of how the intervention worked was flawed and incomplete (Loudon 2000). This justified critique of Semmelweis’ theoretical arguments was taken as a license by the medical community to ignore
his accurate empirical conclusions, resulting in countless unnecessary deaths over the next several decades.
Without gainsaying the value of measurement, what is lost if there is no clearly articulated theoretical context? There are
implications for both external and internal validity. First, consider external validity. There is no theoretical basis for the external validity of field experiments comparable to the statistical
basis for claims of internal validity, and it is often very plausible that treatment effects might vary across contexts. The
degree of uncertainty assigned when applying a treatment effect produced in one context (place, people, time, treatment details)
to another context is typically based on reasonable conjecture. Appeals to reasonableness are, in the absence of evidence
or clear theoretical guidance, disturbingly similar to the justifications for the assumptions on which observational approaches
often rest.
To be concrete, consider the case of canvassing to mobilize voters where the treatment effect is the effect of the intervention on the subject's turnout. In the
most rudimentary framework, the size of this effect might depend on how the intervention affects his or her beliefs about the costs and benefits of voting in the upcoming election. Beliefs about the costs and benefits of participation may
depend in turn on, among other things, how the intervention affects subject knowledge about or the salience of the upcoming
election, expectations about the closeness of the election, beliefs about the importance of the election, and the perceived
social desirability of voting. The intervention's effect on these variables might depend on the political context, such as
the political history or political norms of the place in which the experiment occurs. Additional factors affecting the size
of the treatment effect might include which subset of the population is successfully treated and how near the subjects are
to the threshold of participation. The treatment effect estimated by a given experiment might conceivably be a function of
variables related to any and all of these considerations.17
Understanding the mechanism by which the treatment is working may be critical for accurate predictions about how the treatment
will perform outside the initial experimental context. Consider the challenge of extrapolating the effectiveness of face-to-face
canvassing. Alternative theories have very different implications. One way this intervention may increase participation is
if contact by a canvasser increases the subject's perception of the importance of the election (changing the subject's beliefs
about the benefits of participation). However, a subject's beliefs may be less affected by canvassing in a place where canvassing
is routine than in a place where it occurs only under the most extreme political conditions. Turning to the long-term effectiveness
of canvassing, if canvassing works by causing subjects to update their perceptions of the importance of voting, the link between
canvassing and turnout effects may not be stable. If, following an intensive canvassing effort, the election turns out to
be a landslide or the ballot has no important contests, a voter might ignore subsequent canvassing appeals as uninformative.
In a similar vein, interventions may fail on repetition if they work in part due to their novelty. Alternatively, if the effect
of canvassing works through social reciprocity, where the canvasser exerts effort and the subject exchanges a pledge of reciprocal
effort to vote, then the voter's experience at the polls may not alter the effectiveness of the intervention. That is, the
estimate of canvassing effects in today's election might apply well to subsequent interventions. What matters is the voter's
perception that the canvasser has exerted effort – perhaps canvassing in a snowstorm would be especially effective. This discussion
of the effect of canvassing suggests the value of delineating and adjudicating among the various possible mechanisms. More
generally, being more explicit about the theoretical basis for the observed result might inspire some caution and provide
guidance when generalizing findings.
Reflecting on the theoretical context can also assist in establishing the internal validity of the experiment. For example, it might
be useful to reflect on how the strategic incentives of political actors can alter treatment effect estimates. Continuing
with the example of a canvassing experiment, suppose some local organization is active in a place where a canvassing experiment
is (independently) being conducted. Consider how the canvassing intervention might affect the behavior of such an independent
group that expends a fixed amount of effort making calls to people and asking them if they intend to vote. Suppose that the
group operates according to the rule: if the voter says he or she will vote, then there is no further attempt to encourage
him or her, whereas if the voter says he or she will not vote, then the group expends substantial time and effort to encourage
the subject to vote. If the canvassing treatment took place prior to the independent group's efforts and it was effective,
this will result in a share of their limited mobilization resources being diverted from the treatment group to the control
group (who are less likely to say they plan to vote), depressing the estimated treatment effect. Less subtly, if an experimental
canvassing effort is observed, then this might alter the behavior of other campaigns. More common violations of the requirement that treatment group assignment of one subject not affect potential outcomes of other
subjects may occur if a treated subject communicates directly with other subjects. The importance of these effects may vary
with context and treatment. For example, if the treatment is highly novel, then it is much more likely that subjects will
remark on the treatment to housemates or friends.
Finally, careful consideration of the complete set of behavioral changes that might follow an intervention may also suggest
new outcome measures. Theorizing about how the intervention alters the incentives and capabilities of subjects may affect which outcome measures
are monitored. It is common to measure the effect of a voter mobilization intervention on voter turnout. However, it is unclear
how and whether political participation in elections is related to other forms of political involvement. If citizens believe
that they have fulfilled their civic responsibility by voting, then voting may be a substitute for attending a Parent-Teacher
Association meeting or contributing to the Red Cross. Alternately, the anticipation of voting may lead to enhanced confidence
in political competence and a stronger civic identity, which may then inspire other forms of political and community involvement
or information acquisition.
Publication Process: Publication Bias, Proprietary Research, Replication
One of the virtues of observational research is that it is based on public data. The ANES data are well known and relatively transparent. People would notice if, for some reason, the ANES data were not released.
In contrast, experimental data are produced by the effort of unsupervised scholars, who then must decide whether to write
up results and present the findings to the scholarly community. These are very different situations, and it is unclear what
factors affect which results are shared when sharing depends on the choices of researchers and journal editors. The process
by which experimental results are disclosed or not affects how much one's priors should move as a result of an experimental
report. Though it will always be a challenge to know how to combine experimental findings given the diversity of treatments,
contexts, subjects, and so on, under ideal circumstances, updating is a mundane matter of adjusting priors using the new reported
effect sizes and standard errors. However, the uncharted path from execution of the experiment to publication adds an additional
source of uncertainty because both the direction and magnitude of any bias incorporated through this process are unknown.18 Although any given experiment is unbiased, the experimental literature may nevertheless be biased if the literature is not
a representative sample of studies. This issue is especially vexing in the case of proprietary research. A significant amount
of experimental research on campaign effects is now being conducted by private organizations such as campaigns, unions, or
interest groups. This type of work has the potential to be of immense benefit because the results are of theoretical and practical
interest, the studies numerous and conducted in varying contexts, and the cost of the research is borne by the sponsoring
organization. This benefit might not be realized, however, if only a biased subset of experiments are deemed fit for public
release.
It is often suggested that the scholarly publication process may be biased in favor of publicizing arresting results. However,
anomalous reports have only a limited effect when there is a substantial body of theory and frequent replication. The case
of the “discovery” of cold fusion illustrates how theory and replication work to correct error. When it was announced that
nuclear fusion could be achieved at relatively low temperatures using equipment not far beyond that found in a well-equipped
high school lab, some believed that this technology would be the solution to the world's energy problems. Physicists were
quite skeptical about this claim from the outset because theoretical models suggested it was not very plausible. Well-established
models of how atoms interact under pressure imply that the distance between the atoms in the cold fusion experiments would be billions of times greater than what is necessary
to cause the fusion effects claimed.
Physics theory also made another contribution to the study of cold fusion. The famous cold fusion experiment result was that
the experimental cell produced heat in excess of the heat input to the cell. Extra heat was, in fact, the bottom line measurement
of greatest practical importance because it suggested that cold fusion could be an energy source. Theoretical work on fusion,
however, pointed to a number of other outputs that could be used to determine if fusion was really occurring. These included
gamma rays, neutrons, and tritium. These fusion by-products are easier to measure than is excess heat, which requires a careful
accounting of all heat inputs and outputs to accurately calculate the net change. It was the absence of these by-product measurements
(in both the original and replication studies), in addition to the theoretical implausibility of the claim, that led many
physicists and chemists to doubt the experimental success from the outset. Replication studies began within twenty-four hours
of the announcement. In a relatively short period of time, the cold fusion claim was demolished.19
Compare this experience to how a similar drama would unfold in political science field experimentation. The correctives of
strong theory and frequent replication are not available in the case of field experimental findings. Unfortunately, field
experiments tend to be expensive and time consuming. There would likely be no theory with precise predictions to cast doubt
on the experimental result or provide easy-to-measure by-products of the experimental intervention to lend credence to the
experimental claims. The lack of theoretically induced priors is a problem for all research, but it is especially significant
when replication is not easy. How long would it take political science to refute “cold fusion” results? If the answer is “until
a series of new field experiments refute the initial finding,” then it might take many years.
7. Conclusion
After a generation in which nonexperimental survey research dominated the study of political behavior, we may now be entering the age of experimentation. There was not
a single field experiment published in a major political science journal in the 1990s, whereas scholars have published dozens
of such papers in the past decade. The widespread adoption of field experimentation is a striking development. The results
accumulated to date have had a substantial effect on what we know about politics and have altered both the methods used to
study key topics and the questions that are being asked. Furthermore, field experimentation in political science has moved
well beyond the initial studies of voter mobilization to consider the effects of campaign communications on candidate choice;
the political effects of television, newspapers, and radio; the effects of deliberation; tests of social psychology theories;
the effects of political institutions; and measurement of social diffusion. The full impact of the increased use of field
experiments is difficult to know. It is possible that some small part of the recent heightened attention to causal identification
in observational research in political science may have been encouraged by the implicit contrast between the opaque and often
implausible identification assumptions used in observational research and the more straightforward identification enjoyed
by randomized interventions.
Although the past decade has seen many exciting findings and innovations, there are important areas for growth and improvement.
Perhaps most critically, field experimentation has not provoked the healthy back and forth between theory and empirical findings
that is typical in the natural sciences. Ideally, experiments would generate robust empirical findings, and then theorists
would attempt to apply or produce (initially) simple models that predict the experimental results and, critically, make new
experimentally testable predictions. For the most part, though not in all cases, the field experiment literature in political
science has advanced by producing measurements in new domains of inquiry rather than addressing theoretical puzzles raised by initial results. This shows something about the tastes of the current crop of field experimenters, however,
the relatively slight role of theory in the evolution of the political science field experiment literature so far may also
reflect a lack of engagement by our more theoretically inclined colleagues.
References
Abramowitz, Alan I. 1988. “Explaining Senate Election Outcomes.” American Political Science Review 82: 385–403.
Achen, Christopher H., and Larry M. Bartels. 2004. “Blind Retrospection: Electoral Responses to Droughts, Flu, and Shark Attacks.” Estudio/Working Paper 2004/199.
Adams, William C., and Dennis J. Smith. 1980. “Effects of Telephone Canvassing on Turnout and Preferences: A Field Experiment.” Public Opinion Quarterly 44: 389–95.
Addonizio, Elizabeth, Donald Green, and James M. Glaser. 2007. “Putting the Party Back into Politics: An Experiment Testing Whether Election Day Festivals Increase Voter Turnout.” PS: Political Science & Politics 40: 721–27.
Angrist, Joshua D. 1990. “Lifetime Earnings and the Vietnam Era Draft Lottery: Evidence from Social Security Administrative Records.” American Economic Review 80: 313–36.
Angrist, Joshua D., Guido Imbens, and Donald B. Rubin. 1996. “Identification of Causal Effects Using Instrumental Variables.” Journal of the American Statistical Association 91: 444–72.
Angrist, Joshua D., and Alan B. Krueger. 1991. “Does Compulsory School Attendance Affect Schooling and Earnings?” Quarterly Journal of Economics 106: 979–1014.
Angrist, Joshua D., and Jorn-Steffen Pischke. 2009. Mostly Harmless Econometrics: An Empiricist's Companion. Princeton, NJ: Princeton University Press.
Ansolabehere, Stephen D., and Alan S. Gerber. 1994. “The Mismeasure of Campaign Spending: Evidence from the 1990 U.S. House Elections.” Journal of Politics 56: 1106–18.
Ansolabehere, Stephen D., and Shanto Iyengar. 1996. Going Negative: How Political Advertising Divides and Shrinks the American Electorate. New York: Free Press.
Ansolabehere, Stephen D., and James M. Snyder. 1996. “Money, Elections, and Candidate Quality.” Typescript, Massachusetts Institute of Technology.
Ansolabehere, Stephen D., and Charles Stewart III. 2005. “Residual Votes Attributable to Technology.” Journal of Politics 67: 365–89.
Arceneaux, Kevin, Alan S. Gerber, and Donald P. Green. 2006. “Comparing Experimental and Matching Methods Using a Large-Scale Voter Mobilization Experiment.” Political Analysis 14: 1–36.
Arceneaux, Kevin, and David Nickerson. 2009. “Who Is Mobilized to Vote? A Re-Analysis of Eleven Randomized Field Experiments.” American Journal of Political Science 53: 1–16.
Bergan, Daniel E. 2009. “Does Grassroots Lobbying Work?: A Field Experiment Measuring the Effects of an E-Mail Lobbying Campaign on Legislative Behavior.” American Politics Research 37: 327–52.
Berger, Jonah, Marc Meredith, and S. Christian Wheeler. 2008. “Contextual Priming: Where People Vote Affects How They Vote.” Proceedings of the National Academy of Sciences 105: 8846–49.
Brady, Henry E., and John E. McNulty. 2004. “The Costs of Voting: Evidence from a Natural Experiment.” Paper presented at the annual meeting of the Society for Political
Methodology, Palo Alto, CA.
Butler, Daniel M., and David W. Nickerson. 2009. “Are Legislators Responsive to Public Opinion? Results from a Field Experiment.” Typescript, Yale University.
Chalmers, Iain. 2003. “Trying To Do More Good Than Harm in Policy and Practice: The Role of Rigorous, Transparent, Up-to-Date Evaluations.” Annals of the American Academy of Political and Social Science 589: 22–40.
Chin, Michelle L., Jon R. Bond, and Nehemia Geva. 2000. “A Foot in the Door: An Experimental Study of PAC and Constituency Effects on Access.” Journal of Politics 62: 534–49.
Dale, Allison, and Aaron Strauss. 2007. “Mobilizing the Mobiles: How Text Messaging Can Boost Youth Voter Turnout.” Working paper, University of Michigan.
Davenport, Tiffany C., Alan S. Gerber, and Donald P. Green. 2010. “Field Experiments and the Study of Political Behavior.” In The Oxford Handbook of American Elections and Political Behavior, ed. Jan E. Leighley. New York: Oxford University Press, 69–88.
Deaton, Angus S. 2009. “Instruments of Development: Randomization in the Tropics, and the Search for the Elusive Keys to Economic Development.” NBER Working Paper No. 14690.
Eldersveld, Samuel J. 1956. “Experimental Propaganda Techniques and Voting Behavior.” American Political Science Review 50: 154–65.
Eldersveld, Samuel J., and Richard W. Dodge. 1954. “Personal Contact or Mail Propaganda? An Experiment in Voting Turnout and Attitude Change.” In Public Opinion and Propaganda, ed. Daniel Katz. New York: Holt, Rinehart and Winston, 532–42.
Erikson, Robert S., and Thomas R. Palfrey. 2000. “Equilibria in Campaign Spending Games: Theory and Data.” American Political Science Review 94: 595–609.
Gerber, Alan S. 1998. “Estimating the Effect of Campaign Spending on Senate Election Outcomes Using Instrumental Variables.” American Political Science Review 92: 401–11.
Gerber, Alan S. 2004. “Does Campaign Spending Work?: Field Experiments Provide Evidence and Suggest New Theory.” American Behavioral Scientist 47: 541–74.
Gerber, Alan S. in press. “New Directions in the Study of Voter Mobilization: Combining Psychology and Field Experimentation.”
Gerber, Alan S., and David Doherty. 2009. “Can Campaign Effects Be Accurately Measured Using Surveys?: Evidence from a Field Experiment.” Typescript, Yale University.
Gerber, Alan S., David Doherty, and Conor M. Dowling. 2009. “Developing a Checklist for Reporting the Design and Results of Social Science Experiments.” Typescript, Yale University.
Gerber, Alan S., James G. Gimpel, Donald P. Green, and Daron R. Shaw. in press. “The Size and Duration of Campaign Television Advertising Effects: Results from a Large-Scale Randomized Experiment.”
American Political Science Review.
Gerber, Alan S., and Donald P. Green. 2000. “The Effects of Canvassing, Direct Mail, and Telephone Contact on Voter Turnout: A Field Experiment.” American Political Science Review 94: 653–63.
Gerber, Alan S., and Donald P. Green. 2008. “Field Experiments and Natural Experiments.” In Oxford Handbook of Political Methodology, eds. Janet M. Box-Steffensmeier, Henry E. Brady, and David Collier. New York: Oxford University Press, 357–81.
Gerber, Alan S., and Donald P. Green. 2011. Field Experiments: Design, Analysis, and Interpretation. Unpublished Manuscript, Yale University.
Gerber, Alan S., Donald P. Green, and Edward H. Kaplan. 2004. “The Illusion of Learning from Observational Research.” In Problems and Methods in the Study of Politics, eds. Ian Shapiro, Rogers Smith, and Tarek Massoud. New York: Cambridge University Press, 251–73.
Gerber, Alan S., Donald P. Green, and Christopher W. Larimer. 2008. “Social Pressure and Voter Turnout: Evidence from a Large-Scale Field Experiment.” American Political Science Review 102: 33–48.
Gerber, Alan S., Donald P. Green, and David W. Nickerson. 2001. “Testing for Publication Bias in Political Science.” Political Analysis 9: 385–92.
Gerber, Alan S., Gregory A. Huber, and Ebonya Washington. in press. “Party Affiliation, Partisanship, and Political Beliefs: A Field Experiment.” American Political Science Review.
Gerber, Alan S., Dean Karlan, and Daniel Bergan. 2009. “Does the Media Matter? A Field Experiment Measuring the Effect of Newspapers on Voting Behavior and Political Opinions.” American Economic Journal: Applied Economics 1: 35–52.
Gerber, Alan S., and Kyohei Yamada. 2008. “Field Experiment, Politics, and Culture: Testing Social Psychological Theories Regarding Social Norms Using a Field Experiment
in Japan.” Working paper, ISPS Yale University.
Gosnell, Harold F. 1927. Getting-Out-the-Vote: An Experiment in the Stimulation of Voting. Chicago: The University of Chicago Press.
Green, Donald P., and Alan S. Gerber. 2004. Get Out the Vote: How to Increase Voter Turnout. Washington, DC: Brookings Institution Press.
Green, Donald P., and Alan S. Gerber. 2008. Get Out the Vote: How to Increase Voter Turnout. 2nd ed. Washington, DC: Brookings Institution Press.
Green, Donald P., and Jonathan S. Krasno. 1988. “Salvation for the Spendthrift Incumbent: Reestimating the Effects of Campaign Spending in House Elections.” American Journal of Political Science 32: 884–907.
Guan, Mei, and Donald P. Green. 2006. “Non-Coercive Mobilization in State-Controlled Elections: An Experimental Study in Beijing.” Comparative Political Studies 39: 1175–93.
Habyarimana, James, Macartan Humphreys, Dan Posner, and Jeremy Weinstein. 2007. “Why Does Ethnic Diversity Undermine Public Goods Provision? An Experimental Approach.” American Political Science Review 101: 709–25.
Harrison, Glenn W., and John A. List. 2004. “Field Experiments.” Journal of Economic Literature 42: 1009–55.
Healy, Andrew J., Neil Malhotra, and Cecilia Hyunjung Mo. 2009. “Do Irrelevant Events Affect Voters’ Decisions? Implications for Retrospective Voting.” Stanford Graduate School of Business
Working Paper No. 2034.
Humphreys, Macartan, and Jeremy M. Weinstein. 2007. “Policing Politicians: Citizen Empowerment and Political Accountability in Africa.” Paper presented at the annual meeting
of the American Political Science Association, Chicago.
Humphreys, Macartan, and Jeremy Weinstein. 2009. “Field Experiments and the Political Economy of Development.” Annual Review of Political Science 12: 367–78.
Hyde, Susan D. 2010. “Experimenting in Democracy Promotion: International Observers and the 2004 Presidential Elections in Indonesia.” Perspectives on Politics 8: 511–27.
Imbens, Guido W. 2009. “Better Late Than Nothing: Some Comments on Deaton (2009) and Heckman and Urzua (2009).” National Bureau of Economic Research
Working Paper No. 14896.
Jacobson, Gary C. 1978. “The Effects of Campaign Spending in Congressional Elections.” American Political Science Review 72: 469–91.
Jacobson, Gary C. 1985. “Money and Votes Reconsidered: Congressional Elections, 1972–1982.” Public Choice 47: 7–62.
Jacobson, Gary C. 1990. “The Effects of Campaign Spending in House Elections: New Evidence for Old Arguments.” American Journal of Political Science 34: 334–62.
Jacobson, Gary C. 1998. The Politics of Congressional Elections. New York: Longman.
John, Peter, and Tessa Brannan. 2008. “How Different Are Telephoning and Canvassing? Results from a ‘Get Out the Vote’ Field Experiment in the British 2005 General
Election.” British Journal of Political Science 38: 565–74.
Knack, Steve. 1994. “Does Rain Help the Republicans? Theory and Evidence on Turnout and the Vote.” Public Choice 79: 187–209.
LaLonde, Robert J. 1986. “Evaluating the Econometric Evaluations of Training Programs with Experimental Data.” American Economic Review 76: 604–20.
Levitt, Steven D. 1994. “Using Repeat Challengers to Estimate the Effect of Campaign Spending on Election Outcomes in the U.S. House.” Journal of Political Economy 102: 777–98.
Loudon, Irvine. 2000. The Tragedy of Childbed Fever. Oxford: Oxford University Press.
Medical Research Council, Streptomycin in Tuberculosis Trials Committee. 1948. “Streptomycin Treatment for Pulmonary Tuberculosis.” British Medical Journal 2: 769–82.
Michelson, Melissa R. 2003. “Getting Out the Latino Vote: How Door-to-Door Canvassing Influences Voter Turnout in Rural Central California.” Political Behavior 25: 247–63.
Michelson, Melissa R., Lisa García Bedolla, and Margaret A. McConnell. 2009. “Heeding the Call: The Effect of Targeted Two-Round Phonebanks on Voter Turnout.” Journal of Politics 71: 1549–63.
Miller, Joanne M., and Jon A. Krosnick. 1998. “The Impact of Candidate Name Order on Election Outcomes.” Public Opinion Quarterly 62: 291–330.
Miller, Roy E., David A. Bositis, and Denise L. Baer. 1981. “Stimulating Voter Turnout in a Primary: Field Experiment with a Precinct Committeeman.” International Political Science Review 2: 445–60.
Nickerson, David W. 2008. “Is Voting Contagious? Evidence from Two Field Experiments.” American Political Science Review 102: 49–57.
Olken, Benjamin. 2010. “Direct Democracy and Local Public Goods: Evidence from a Field Experiment in Indonesia.” American Political Science Review 104: 243–67.
Paluck, Elizabeth Levy, and Donald P. Green. 2009. “Deference, Dissent, and Dispute Resolution: An Experimental Intervention Using Mass Media to Change Norms and Behavior in
Rwanda.” American Political Science Review 103: 622–44.
Panagopoulos, Costas, and Donald P. Green. 2008. “Field Experiments Testing the Impact of Radio Advertisements on Electoral Competition.” American Journal of Political Science 52: 156–68.
Pew Research Center for the People and the Press. 1998. “Possible Consequences of Non-Response for Pre-Election Surveys: Race and Reluctant Respondents.” Survey Report, May 16.
Retrieved from http://people-press.org/report/89/possible-consequences-of-non-response-for-pre-election-surveys (November 1, 2010).
Posner, Richard A. 2004. Catastrophe: Risk and Response. Oxford: Oxford University Press.
Rosenstone, Steven J., and John Mark Hansen. 1993. Mobilization, Participation, and Democracy in America. New York: MacMillan.
Rubin, Donald B. 1978. “Bayesian Inference for Causal Effects: The Role of Randomization.” The Annals of Statistics 6: 34–58.
Rubin, Donald B. 1990. “Formal Modes of Statistical Inference for Causal Effects.” Journal of Statistical Planning and Inference 25: 279–92.
Taubes, Gary. 1993. Bad Science: The Short Life and Weird Times of Cold Fusion. New York: Random House.
Vavreck, Lynn. 2007. “The Exaggerated Effects of Advertising on Turnout: The Dangers of Self-Reports.” Quarterly Journal of Political Science 2: 287–305.
Verba, Sidney, Kay Lehman Schlozman, and Henry E. Brady. 1995. Voice and Equality: Civic Voluntarism in American Politics. Cambridge, MA: Harvard University Press.
Wantchekon, Leonard. 2003. “Clientelism and Voting Behavior: Evidence from a Field Experiment in Benin.” World Politics 55: 399–422.
Whitney, Simon N., and Carl E. Schneider. 2010. “A Method to Estimate the Cost in Lives of Ethics Board Review of Biomedical Research.” Paper presented at the “Is Medical
Ethics Really in the Best Interest of the Patient?” Conference, Uppsala, Sweden.
This review draws on previous literature reviews I have authored or coauthored, including Gerber and Green (2008); Davenport, Gerber, and Green (2010); Gerber (in press); and Gerber (2004). The author thanks Jamie Druckman, John Bullock, David Doherty, Conor Dowling, and Eric Oliver for helpful comments.
3 Gosnell assembled a collection of matched pairs of streets and selected one of the pairs to get the treatment, but it is not
entirely clear whether Gosnell used random assignment to decide which pair was to be treated. Given this ambiguity, it might
be more appropriate to use a term other than “experiment” to describe the Gosnell studies, perhaps “controlled intervention.”
6 If a campaign activity causes a supporter who would otherwise have stayed home on Election Day to vote, then this changes
the vote margin by one vote. If a campaign activity causes a voter to switch candidates, then this changes the vote margin
by two votes. For further details about these calculations, see Gerber (2004).
7 The ordinary least squares estimate relies on the questionable assumption that spending levels are uncorrelated with omitted
variables. The instrumental variables approach relies on untestable assumptions about the validity of the instruments. Levitt's
study uses a small nonrandom subset of election contests, so there is a risk that these elections are atypical. Furthermore,
restricting the sample to repeat elections may reduce, but not fully eliminate, the biases due to omitted variables because
changes in spending levels between the initial election and the rematch (which is held at least two, and sometimes more, years
later) may be correlated with unobservable changes in variables correlated with vote share changes.
8 For instance, the natural environment will provide the subject more behavioral latitude, which might reverse the lab findings.
For example, exposure to negative campaigning might create an aversion to political engagement in a lab context, but negative
information may pique curiosity about the advertising claims, which, outside the lab, could lead to increased information
search and gossiping about politics, and in turn greater interest in the campaign.
9 Compounding the confusion, the results presented in the early field experimental literature may overstate the mobilization
effects. The pattern of results in those studies suggests the possibility that the effect sizes are exaggerated due to publication-related
biases. There is a strong negative relationship between estimates and sample size, a pattern consistent with inflated reports
due to file drawer problems or publication based on achieving conventional levels of statistical significance (Gerber et al.
2001).
11 This uncertainty is not contained in the reported standard errors, and, unlike sampling variability, it remains undiminished
as the sample size increases (Gerber, Green, and Kaplan 2004). The conventional measures of coefficient uncertainty in observational research thereby underestimate the true level of
uncertainty, especially in cases where the sample size is large.
13 For more detailed treatment of these and other issues regarding field experiments, see Gerber and Green (2011).
14 Figure 9.1 and subsequent discussion incorporates several important assumptions. Writing the potential outcomes as a function of the
individual's own treatment assignment and compliance rather than the treatment assignment and compliance of all subjects employs
the stable unit treatment value assumption. Depicting the potential outcomes as independent of treatment group assignment
given the actual treatment or not of the subjects employs the exclusion restriction. See Angrist et al. (1996).
15 This estimand is also known as the complier average causal effect (CACE) because it is the treatment effect for the subset
of the population who are “compliers.” Compliers are subjects who are treated when assigned to the treatment group and remain
untreated when assigned to the control group. When there is two-sided noncompliance, some subjects are treated whether assigned
to the treatment or control group, and consequently the ATT and CACE are not the same.
16 See Sinclair's chapter in this volume for further discussion.
18 For a related point, where the target is observational research, see Gerber et al. (2004).
19 Unfortunately, I am not well trained in physics or chemistry. This account draws on Gary Taubes’ Bad Science: The Short Life and Weird Times of Cold Fusion (1993).