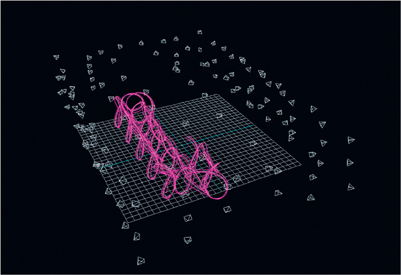
Figure 4.1 Motion Capture at House of Moves.
(Image courtesy of House of Moves.)
Motion capture is the process of measuring motions in the physical world and then encoding them into the digital medium. Once recorded, motion can be used to drive a digital character or breathe life into inanimate objects. Performance Capture is a term that usually refers to a subcategory of Motion Capture where an actor’s face and body performance are recorded simultaneously.
Motion capture has become a widely used technique in visual effects for its ability to deliver high-fidelity character motion in a time frame not practically achieved through other methods. While many technologies fall under the umbrella of motion capture, including piezoelectric, magnetic, inertial, radio-frequency, resistance, and a wide range of computer vision techniques, the most prevalent is a form of computer vision called passive optical, retroreflective, discrete point capture, or usually just “optical” for short.
The term passive optical refers to the white spheres that are being captured by high-speed digital cameras. These balls, called markers, are passive in that they do not emit light or any other information. Retroreflective means that the markers are coated with a substance that makes them highly reflective and discrete point capture refers to the fact that the system is returning three-axis, positional information for each marker on each captured frame. The practical upshot being that a motion capture system can record the position in space of the markers on the motion capture stage.
This chapter focuses primarily on the most prevalent form of motion capture, optical. Where possible it will cover alternate and variant technologies.
Figure 4.1 Motion Capture at House of Moves.
(Image courtesy of House of Moves.)
Motion capture is best known for its ability to quickly deliver realistic animation. When considering whether or not motion capture is right for a project, the aesthetic expectations, technical specifications, scope and budget of the project should all be carefully considered.
Aesthetically speaking, motion capture has a look that may not be appropriate for all projects. This is achieved by recording the translations and/or rotations directly from an actor and using them to drive a digital character.
This realism can be eye catching both for its uncanny accuracy as well as its inaccuracy. That is to say, because motion capture can achieve such a high quality bar, animation consistency can become a concern. Poorly done motion capture, mixing keyframe animation with motion capture, bending a performance to something other than what was captured and heavy retargeting can all result in artifacts that distract viewers from the performance. While far from impossible, mixing and bending in this way should be carefully considered for these reasons.
Motion Capture is not specifically limited to human animation. Done creatively it can be used to puppeteer fantastic characters, animate vehicles, props, set decorations, particle fields or to deliver any number of never before seen effects.
Technically, some projects are better for motion capture than others because what can be captured and how the data can be used often comes with limitations. On the acquisition side, traditional optical capture is limited to line of sight. This means that a marker needs to be seen by some number of cameras in order for its position to be recorded. This can put unfortunate restrictions on the amount and type of set decoration, props, and clothing that can be used. As an example it would be difficult to capture a person inside a car using a traditional optical system. Different technologies have different limitations. Combinations of technologies can be deployed to overcome such limitations but usually with complication and expense.
On the back end, motion capture data can be heavy as it typically comes in the form of key-per-frame data. Without proper preparation, this can make the data very difficult to edit. If editing is required, animation rigs should be set up to accept this data, Animators skilled in using such rigs will be required to edit this data and be part of the process.
Traditional optical motion capture hardware takes up a lot of space, involves lots of delicate, expensive hardware and trained technicians. For this reason, most projects choose to outsource their motion capture needs. Larger companies with many projects or projects broader in scope, such as feature films, will often purchase their own system and hire these individuals.
In recent years there has been an explosion of lower cost capture methods capable of yielding reasonably high fidelity data within certain limitations. As well, the larger and more established vendors are now offering lower cost systems with limitations.
Although less often used there are still many online stock motion libraries available. Many of the larger service providers have a back catalog of stock motions they can provide.
Outsourced motion capture is usually billed per character second. The price per second is primarily dictated by the extent to which the provider will take the data. This price can range wildly dependent on the provider. Additional factors that can affect the price are location, volume size, real-time, stunt rigging, number of actors, audio, turnaround time, etc. Price for traditional optical motion capture data could range from half to double the following:
| Data Type | Body per second | With Face |
| Tracked Data | $10 | +20 |
| Solved Animation | $15 | +40 |
| Retargeted Animation | $20 | +45 |
| Edited Final Animation | $45 | +75 |
Note: Some providers will have a per-day charge and lower per-second charges
*Data circa 2012 based on U.S. firms
Different projects have different needs and therefore traditional optical motion picture technology is not necessarily the best technology for a given project. However, there are so many technologies to choose from that it can be difficult to decide which one is best for a project. Making an informed decision can make the difference between a useless mess and a great visual effect. To make the best decision, the project’s needs and constraints need to be carefully considered.
There is a lot to consider when deciding which technology is best for a project. Very often it is actually a combination of technologies or choosing none that is actually the best answer.
Budget—What can the project afford?
Data quality—How good does the data need to be?
Turnaround time—How quickly is the data needed?
Real-time—Is on set visualization desired?
Types of things being captured—Bodies, faces, props, set decoration, vehicles, animals?
Capture environment—Indoor, outdoor, green screen, underwater, moving, flying?
Actor considerations—What will the actor be doing? Who are the actors?
Scalability—How many actors? How much area is required? How much accuracy?
Almost all constraints and needs can be overcome with a large enough budget be it by scaling a particular technology or by combining multiple technologies to overcome the deficiencies of any single technology. As with just about anything in the visual effects world, the projects budget will often make the decision clear.
Motion capture can be used for many things. Some of those things require extremely accurate measurements. A general rule of thumb is that the more accurate the measurements, the more expensive and time consuming the data will be. One of the first questions to answer when deciding which technology to use, is “How good does the data need to be?”
Some technologies are capable of overcoming very difficult constraints at the expense of labor or processor intensive post-processing. If the production requires that the data be immediately available, then some technologies might be better than others.
Real-time motion capture is an invaluable tool for previs, camera, blocking, live performance, and many other emerging needs. If a project needs real-time response, it can immediately dismiss many technologies.
Some technologies cannot capture certain things. Most technologies can record the motions of a human subject; however, they cannot capture the complex motion of cloth, facial deformations, or reflective surfaces.
Motion capture usually takes place on a motion capture stage. However, it is becoming increasingly common for motion capture to happen outdoors, on set, or even underwater! Similarly, a motion capture stage might not be big enough, quiet enough, or provide the number of requirements for the other needs of the production.
There are a number of ways to capture the motions of an actor, some of which an actor may not be comfortable with. Even with traditional optical motion capture, the requirements of tight suits and white balls can make some actors very uncomfortable. Further, when it comes to children, animals or special ability actors, some technologies can be ruled out immediately.
It is becoming increasingly common to combine multiple technologies to achieve more complex results. This is to overcome a lack of scalability in a given technology.
For the sake of choosing which technology is right for a project, traditional passive retroreflective optical motion capture will be considered as the medium by which other technologies will be measured. Because this chapter covers mostly optical motion capture, it is not discussed in detail here. The other technologies listed here are generally being discussed “in comparison to” optical motion capture.
| Vicon | www.vicon.com |
| Motion Analysis | www.motionanalysis.com |
| Standard Deviation | www.sdeviation.com |
| NaturalPoint | www.naturalpoint.com |
| Giant | www.giantstudios.com |
Active optical differs from passive optical by incorporating Light Emitting Diodes (LEDs) that emit a burst of high intensity light. LEDs emit light with about 30 to 40% efficiency with a spread of about 5 to 30 nanometers from the peak wavelength making them very narrow and efficient compared to other light sources. In a typical body capture scenario, active markers are often smaller than their retroreflective counterparts; however, they require power so are typically tethered to a battery worn by the actor. While the battery can be as small as a hearing aid battery, this adds bulk and complexity that ideally are hidden from the user.
Since reflectors only reflect a fraction of the light from a ring of LEDs at the camera, LED markers are brighter and more visible to the camera sensors. Even under ideal conditions, a one square inch reflector 200 inches from the camera only has a fractional surface area of 1/(200 × 200 × 2pi) (remember ½ sphere for forward facing wide angle LEDs) so the reflector captures only four parts in a million of the light from the ring of LEDs around the camera. An LED with this same brightness requires very little power and can be modulated to give IDs as well as turned off to measure background light levels, improving noise cancellation. LEDs can be synchronized to the electronic shutter reducing the contribution of even sunlight by a factor of 10 or more. The brightness of the active marker allows a higher f-stop affording a deeper depth of field, and the ability to perform outdoor capture in broad daylight where reflective systems have a hard time competing with the sunlight. This allows the ability to shoot on a regular sound stage or outdoors so other actors, parts of the performer or surrounding environment can be image captured at the same time.

Figure 4.02 Pendulum Studio’s PhaseSpace Capture Volume.
(Image courtesy of Pendulum Studios.)
Some active optical systems modulate or blink the LEDs in unique patterns that can be detected by extremely fast cameras operating at almost 1000 frames per second. By doing so, any given marker can be more easily identified and the post process of labeling made obsolete; this in turn enables real-time visualization. However, at any given frame rate, there are only so many combinations of blink patterns that can practically yield data there by limiting the maximum number of markers on the stage.
Key Players in the Active Optical Arena
| PhaseSpace | www.phasespace.com |
| Standard Deviation | www.sdeviation.com |
Inertial capture has gained favor in the motion capture world for a variety of reasons. Chief among them is that it requires no line of sight to cameras. This means that it can be worn under a costume, used outdoors, or in very large capture environments. Additionally it is easy to use, relatively inexpensive and can provide reasonable data in real-time. For these reasons, inertial systems are often used for previs and skeletal reference. An often cited weakness of inertial systems however is that by themselves they do not yield positional data and can suffer from drift over long captures.
At the heart of an inertial system are Microelectromechanical sensors (MEMS). These sensors benefit from Moore’s Law by becoming smaller, more accurate and more affordable and have gone from single axis devices to two and three axis devices. The two main types of inertial sensors are Accelerometers and Gyros. Both these devices use similar manufacturing techniques to create a cantilever or diving board structure where the mass causes the beam to deflect and the relative gap distance can be measured from the rest position.
In an Accelerometer, if there are no forces acting, there is still a small amount of noise in sampling measurements which can be mistaken for small motions. Larger motions are easily measured as they generally contain more signal than noise. However, after a significant deflection, the device either hits its limits or becomes non-linear and can no longer measure deflections or the causing forces accurately. Within its limits, which are defined by the stiffness of the cantilever and the mass, these devices are able to measure about one part in a thousand typically between a dynamic range 0.1 Gravity (G) and 10 G. For short measurement periods or with enough filtering by taking multiple samples and averaging them together, these devices can be extremely useful for measurements of forces which can be integrated to provide velocities and positions relative to the rest pose.
By using gravity as a reference, accelerometers can be used to provide inclination and measure rotations by centripetal forces but will drift over a period of several seconds to minutes.
MEMS Gyros use similar techniques in a tuning fork or other arrangement where the mass is driven in a vibratory manner and the deflection forces alter the path or frequency of vibration. These use more power than accelerometers since the mass must be driven, and measure rotations in degrees per second with a range of 0.01 degree per second to several hundreds of degrees per second, but noise values up to 0.2 degrees per second, requiring external measurements of vibration, temperature and absolute position.
Combining these low cost devices with optical or other motion capture systems will produce hybrids that have reduced occlusion problems. Since optical systems often suffer momentary occlusions usually under a second, and MEMS devices are very accurate for such short periods, the combined systems will be much more productive in reducing manual labor in “fixing” motion capture data.
Key Players in the Inertial Arena
| XSens | www.xsens.com |
| Animazoo | www.animazoo.com |
| Polhemus | www.polhemus.com |
| MEMSense | www.memsense.com |
| PhaseSpace | www.phasespace.com |
Structured light has been a staple of the computer graphics world for its ability to generate very detailed scans. It works by combining a calibrated projector and camera to triangulate known light patterns that are projected onto the actor. In the case of the Microsoft Kinect, a projector is casting an infrared pattern out into the environment. The perturbation of that pattern by the actor/environment is viewed by the camera and converted by the processor into 3D geometry. This geometry is then statistically evaluated and a skeleton is derived. Structured light is traditionally done from a single camera perspective and therefore the resulting data can contain missing information, for instance about the back side of the actor.
A typical high resolution, structured light scan can take as long as two or three seconds to acquire. The Kinect’s ability to generate real-time animation at 30 fps comes at the expense of accuracy (around 10–20mm) Recent advancements in the field have seen multiple structured light systems used simultaneously to offset some of the shortcomings of a single view and limited resolution.
With perhaps the lowest entry point of all motion capture devices, the Kinect has become popular for students and previs.
Key Players in the Structured Light Arena
| Microsoft Kinect | www.xbox.com/KINECT |
| PrimeSense | www.primesense.com |
| Asus Xtion PRO | www.asus.com/multimedia/motion_Sensor/xtion_pro |
| iPi Soft | www.ipisoft.com |
By viewing an object from multiple calibrated views, similar features detected in multiple views can be triangulated and reconstructed as points in 3D space. Dense Stereo Reconstruction or “DSR” is a technique by which this process is done at the per-pixel level. DSR is most commonly found in scanning but is making headway in the world of surface capture. Surface capture is the per-frame reconstruction of a mesh rather than discrete points like markers.
The upsides to DSR are its ability to instantly capture with the single snap of the cameras and its scalability. With regards to scalability, more cameras and/or resolution generally yield better results. Its downside is that it can be difficult to find corresponding features on clear featureless skin, reflective surfaces, and in varying lighting conditions. Another downside to DSR is that the frame-to-frame correspondence of the found features can be difficult to correlate.
| Mova Contour | www.mova.com |
| Depth Analysis | depthanalysis.com |
| Agisoft | www.agisoft.ru |
| Dimensional Imaging | www.di3d.com |
Bend Sensors refers to any technology that measures the amount a joint (usually a finger) instrumented with a sensor is bent. They can measure a single axis of bend (such as a hinge) so multiple bend sensors are required to record the complex rotations of a thumb or shoulder. In the case of the index finger, at least two sensors would be needed to record the base of the finger with an additional sensor for each knuckle giving a total of four sensors. There are many kinds of bend sensing technologies—potentiometer, capacitive, piezoelectric, and light.
Potentiometer technologies include any type of resistive element that changes with the flexing of the device. As the sensor enters a state of compression it becomes more conductive to electricity. Concurrently, as it enters a state of tension, it becomes less conductive. This difference can be measure and converted to a rotation.
Capacitive sensors require two elements that slide and change the capacitance relative to their positions like an analog nomograph.
Piezoelectric sensors work by generating a small electric charge that can be measured. They do this by taking advantage of properties of certain crystal and ceramic compounds that will generate a small electrical charge when pressure is applied to them.
Fiber optic sensors use a technique where the amount of light that leaks from one fiber to the next is dependent on the bend angle for the fiber. They work by exposing a small section of two fibers, and measuring the leakage.
Because of their small size and not requiring any line of sight to cameras, bend sensors are often used for finger capture but can also scale up to full body capture. This also makes them ideal for being worn under a costume or outdoors. However they are not known for their accuracy as the relative angles can be off by many degrees and they do not calculate position, but simply joint angles.
Key Players in the Bend Sensor Arena
| Measurand | www.motion-capture-system.com |
| CyberGlove Systems | www.cyberglovesystems.com |
Motion capture is not yet a turnkey solution for acquiring high fidelity animation. It still requires skilled artisans, an understanding of the process and detailed preparation. Walking on to a motion capture stage without these things will almost certainly yield less than ideal data and result in many more painstaking hours and days of post processing than needed. To be properly prepared for motion capture, consider the following.
One very often overlooked item in the preparation process is the actor. It is a good idea to brief the actor on the basics of motion capture. Each of the various capture technologies comes with its limitations and informing the actor of those limitations will help them from having to retake a scene for the sake of the technology.
For instance, in optical motion capture, a marker’s position from the joint it is measuring is a very carefully measured and calibrated distance. If the actor should tug or adjust the suit without notifying a technician, the resulting animation will look wrong. Similarly, should an actor decide to lean against a camera tripod or truss, the results to the calibration of the system could be catastrophic! A few simple words can really save the day here.
The motion capture suit is a fitted suit to which the markers or sensors will be attached. To allow flexibility in the attachment locations, suits are usually made from materials that can act as loop Velcro (the furry side) such that markers can be placed and adhere anywhere on the suit. Materials include Lycra, Neoprene or Nylon UBL. Suits are ideally as tight fitting as an actor will allow but not so tight that it would inhibit performance. Most motion capture stages will have a variety of suit sizes available. Custom fitting a suit for each individual actor can add hundreds of dollars to the production budget but is absolutely worth the extra cost as it will increase comfort and decrease marker slip. It can take weeks to have a custom suit made.
Traditional optical motion capture systems will return the position in space of any given marker in the capture volume. Each marker is strategically placed to measure a rotation and/or translation of an actor. While the system will only return positional information, with enough points rotations can be inferred. Biomechanically and mathematically speaking, there is a best place to measure each of the motions of interest; however, the software and practical limitations of the set may require adjustments and modifications.
While there are many methods for converting positional information into rotational information, it can best visualized by the notion that any three points in space define a plane and from a plane, a rotation can be inferred. However, optical data typically contains some amount of noise. In the triangle example, a small triangle with a marker jittering will result in rotational error. If that same marker were part of a larger triangle that jitter will result in much less rotational error. For this reason it is ideal to place a marker as far from the joint it is measuring as possible before it starts to pick up any motion from the next successive joint.
Markers should be placed such that they are as rigid as possible to the joints they are measuring. This means that they should be placed on or near bone. For instance, placing a marker on the bicep to measure the orientation of the humerus will be less than ideal as muscle bulge could be falsely interpreted as bone rotation.1
Probably the biggest single problem with traditional optical motion capture is occlusion.2 The result of occlusion is that a marker’s position cannot be known if it cannot be seen by at least two cameras. To counter occlusion, a marker which cannot be seen can be “filled” by assuming it to be at some rigid or biomechanical offset to other seen measurements. To accommodate this technique, it is good practice to add additional markers that may be less than ideally placed, but can help fill sporadically missing data in a pinch. Additional cameras may also be placed to minimize occlusions.
Marker placement for the face is highly dependent on the acquisition and subsequent post-processing methodologies. For instance, some technologies might allow fewer markers than desired but deliver much more accuracy positionally or temporally in exchange. Facial marker placement is used to measure the under lying muscles and the percent to which they are engaged from the resulting surface deformation on to which the markers are attached. For instance, placing a marker just above the eyebrow and measuring its distance to another placed on the forehead is a reasonable approach to gather information about the frontalis3 muscles. In this example, it would be ideal to find the point along the eyebrow that moves the most when the brow is raised and then another point above it whose motion the eyebrow will be measured relative to. However, given that marker data can contain errors, it is ideal to place many markers along the brow and forehead.
Often, however, it is not so straightforward how a marker’s motion correlates to the measurement of the underlying muscles. Such is the case around the mouth and lips where many muscles engage simultaneously to deliver even the simplest of surface deformations. Determining what the markers mean is in fact one of the hardest problems in facial motion capture when considering that the information contained within them is often rife with errors and instability. Some popular methods for determining this are discussed later in the section entitled Facial Motion Capture.

Figure 4.4 A medium-resolution, 57-marker body placement.
(Image courtesy of John Root.)
Determining the exact best location to place facial markers can take hours of precious time, time that is often at a premium on a stage. Ideally these locations need to match exactly from day to day such as to minimize the work needed in post. Marker Masks can be an effective solution to both of these issues.
A Marker Mask is a clear plastic mold of an actor’s face with holes drilled at the location where each marker is to be placed. By creating such a mask the markers can be placed very close to their original location on a day-to-day basis.
Body motion capture data is usually delivered as skeletal animation on a rig. A rig is a set of deformation and animation controls that allows a 3D model to animate. One such deformation technique is a skeleton. Comprised of hierarchically connected joints, a skeleton can deform large groups of vertices by moving a single pivot (a joint). Data delivered on a skeleton will typically be further adjusted by animators so it is preferable that the skeleton be set up with controls that are friendly for animators to work with, such as Inverse Kinematics. These and other controls benefit greatly from a skeleton that is a reduced approximation of a real human skeleton. For instance, in rigging it is common to express an arm as three one dimensional pivots, the shoulder, elbow, and wrist, whereas in reality the elbow comprises two separate pivots and the wrist as many more pivots. Because motion capture is coming from a real skeleton and being reduced down to this approximation, errors can and do occur.
It is ideal to be solving motion capture onto a skeleton that is as close to 1:1 to the actor from which the motion has been captured as possible. That is to say, the actor and the digital character are of the same proportions. Determining the exact joint locations and bone length of an actor is no easy process. Further, human joint motion is not easily or intuitively expressed as single points in space. There do exist algorithms that attempt to determine best possible joint placement from the marker’s motion as measured relative to its parent; however, given different motion these algorithms will yield different skeletons.
Finding a balance between what is happening in the actor and what is possible in the 3D rig is a compromise. As an example a knee is not a perfect hinge; however, it is ideal from the perspective of the animator that the leg be set up with inverse kinematics which in turn greatly benefits from expressing the knee as a single degree of freedom.
In reality, human joints do not have degrees of freedom. Some do move less on certain axes than others, but explicitly creating a rule that a digital joint cannot move on certain axes will generate errors in the system as marker information will suggest joints are in fact moving on the locked out axis. Unfortunately this is common and a necessary evil for the sake of post editing of animation.
Also on the topic of “Degrees of Freedom” is the notion that, rarely are digital skeletons anatomically accurate with respect to the number of bones. The spine and neck are often expressed as far fewer joints than the reality and as such, it is ideal for the existing joints to contain additional degrees of freedom such as length translation to account for the missing pivots.
Ultimately motion capture should be driving a mesh with the best possible deformation techniques the project can afford. This might include muscles, cloth, pose-space triggered blend-shapes, and any number of complex simulations. However, the majority of motion capture software only supports linear blend skinning and for this reason it is ideal to have a version of the final rig whose deformations are simplified for the sake of the various third party software applications that are likely to be involved in the pipeline.
A shot list is a document that is prepared before the motion capture shoot. The purpose of the shot list is to predetermine everything that is going to be captured for the sake of minimizing stage time into a focused shoot. Live action filming uses shot lists in a similar manor to determine which shots need to be filmed. A good shot list will list those motion capture performances in an order that plays into the technology and the stage requirements. A great shot list will be flexible and expandable because quite often most of the information contained within a shot list is actually filled in on stage. It is typically the job of the Script Supervisor, Assistant Director, or Director to break down a script into a shot list. An Animation or VFX Supervisor may create shot lists for required actions. Motion capture shot lists generally contain file names, brief descriptions, and important technical information.
For the most part, motion capture is liberating to the shooting process. Camera, lighting, and exacting specifics can be figured out post-shoot, assuming this is a pure motion capture session. There are, however, a few things to consider:
There is commonly an upper limit to the length of a take when dealing with motion capture. Find out what this length is and be sure to take it into account when breaking out a shot list.
If actors are expected to be getting in and out of stunt gear or similar such wardrobe changes, it would be a good idea to group those takes together because the marker positions on the actor will likely change as the wardrobe changes.
Tearing down and building up a set on the motion capture stage can be time consuming, complicated, and in some cases dangerous. If possible, shoot everything in that set before moving on.
The filename is generally concatenated from the relevant information. In a feature film environment, this might follow the scene, setup, pass, take nomenclature, where each bit is separated by an underscore or dash. It is ideal to pad the individual parts such that they sort properly in a list. Such as:
002_B01_001
In this example, scene 2 is ready to be recorded using stage setup B1 (Bravo 1). This will be take 1. It might not have been known at the time the shot list is created that a setup B was even required. However, because of the concatenation this filename is flexible and expandable, but more importantly can be deconstructed in post. Also notice here that each block delimited by the underscore is exactly three characters long.
The number to the right of the setup indicates a tile. A tile is an action that is intended to be composited with other actions. For instance, technology may limit a shoot to 10 actors in the volume. Therefore, shooting a large-scale battle scene might seem impossible. In this case several tiles are invoked where the actors are playing different characters in each tile. Then, in post, all of these tiles are composited together in 3D to create the desired masses. In another example, an actor might have to run a distance that is farther than the capture volume permits. In this case tiles are invoked and the resulting animations are stitched together in post such that the actor is playing the same character only in a different time and space.
An optical motion capture system is image based and as such its primary component is digital cameras. The motion capture camera is designed for a very specific purpose: to capture a narrow spectrum of high-intensity light at very fast speeds. This light is emitted from the strobe, reflected back by the marker, and focused by the lens through the filter onto the image sensor. Then the captured image is processed, compressed, and finally offloaded to the data collection station for reconstruction. This is done typically between 60 and 240 times per second.
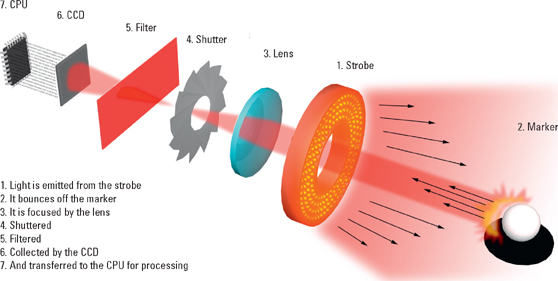
Figure 4.5 A high-level overview of the motion capture hardware pipeline.
(Image courtesy of John Root.)
The entire motion capture process hinges on collecting quality 2D images. Bad 2D images will generate bad 3D reconstructions so when considering hardware collecting quality 2D images should be a primary concern. This section is intended to give a better understanding of the camera and its various elements and how to leverage them to give the best 2D data for a given application. Primarily the information contained in this section refers to Vicon and Motion Analysis hardware, but much of this information is also applicable to other systems as well, such as PhaseSpace, Standard Deviation, and Natural Point.
Sometimes called ring lights, the strobes are the typically red, infrared, or near-infrared light-emitting diodes (LEDs) that are mounted on the front of the camera. The term strobe comes from the fact that the LEDs are flashing in unison with the camera taking pictures. This is, in most cases, happening faster than the human eye can perceive and thus they appear to be always on when in fact they are strobing. The strobes send light out that is reflected back by the marker and then captured by the image sensor. Picking the right strobe for the camera and lenses is important because they come in multiple varieties and can make a significant difference in volume setup.
Field of view (FOV) is the angular extent of a scene that is illuminated by the strobe. FOV is determined by the type of LED and the orientation at which the LED is mounted on the board. Assuming all LEDs are facing forward, the only factor to consider is the FOV of the LED itself. If the LEDs are splayed outward to gain FOV, intensity will be lost because fewer LEDs will be pointed in any one direction.
The amount of light a strobe can emit will vary in both intensity and FOV. For this reason a proper lens/strobe pairing is important. This is because precious light would be wasted in the case where the strobe’s FOV exceeded that of the lens. Concurrently, if the FOV of the strobe were narrower than that of the lens, the resulting image would appear to be poorly lit around the edges. This artifact is sometimes referred to as vignetting.
The intensity of a strobe refers to its brightness level. A strobe’s intensity is defined by the power and focus of the LEDs contained within it. The light from the strobe has to travel to the marker and reflect with enough intensity to register on the image sensor. Since light intensity follows the inverse square law (two times the distance equals ¼ the light) these strobes need to be extremely bright. The intensity required for capture depends primarily on the size and distance of the markers. Smaller volumes (capture area) generally do not require as much light as larger volumes. Strobes typically allow for brightness control and as such the brightest strobes permitted should be used.
A marker is a capture fiducial, meaning that it is a point within a captured image that can be easily identified and tracked. Sometimes referred to as jewels or ping-pong balls, markers should technically not be called sensors because there is no sensing going on in the optical marker—all of the sensing is at the camera.
Off-the-shelf solutions use one of three styles: passive, passive retroreflectors, and active. Though there are different styles of markers, the main goal of each is to provide something easy to identify and consistently track in the camera image. Markers are usually circular or spherical, which provides an easy-to-find center from all angles. The following types of markers all accomplish these goals by slightly different methods, and each has its niche, as dictated by application and the economics of scale.
A passive marker is a fiducial that offers little to no optical advantage. Passive markers are commonly used to aid in matchmoving or live-action film shoots. In recent years passive marker motion capture has been made popular for its ability to digitally record animation simultaneously with live-action footage. A passive marker is typically of high contrast compared to its surroundings. Examples of passive markers are ink dots on an actor’s face or cross-hairs on their clothing. As such, passive markers are most difficult to track and are rarely used in conventional motion capture.
When people think motion capture, this is the type of marker that most likely comes to mind. Typically these markers are small rubber spheres wrapped in Scotchlite™ tape. The nature of a retroreflective surface is that it reflects light straight back at the source with a minimal degree of scattering. This creates tiny hot spots of light in the collected images that can be easily distinguished from background information. These markers are easily separated from the rest of the image and therefore more easily tracked.
Typical sizes include 10 to 18mm spherical markers for the body and 2 to 5mm spherical or hemispherical markers for the face. A marker’s size is primarily determined by the distance and resolution of the camera but is also affected by strobe intensity, f-stop, and the subtlety of the performance being captured. Prices range around $6 per marker, and given that a single actor may wear 60 or more just for body capture, markers are not a trivial cost and should not be overlooked. The life span of a given marker depends on what it is used for, but they can lose effectiveness over time by mishandling, scuffing, rips in the tape, and general capture. Expect to replace markers fairly frequently if stunts or heavy action scenes are involved.
The less common active marker is a tiny solid-state LED that emits the same spectrum of light the cameras are looking for. Active markers require power so are typically tethered to a battery worn by the actor. Because active markers do not have to bounce light, they are brighter and more clearly visible to the cameras. This makes them ideal for outdoor or very large volume motion capture or where traditional stage lighting is required.
Active markers, however, typically emit light in a particular direction and, hence, are most visible from the direction they are facing. Light from an active marker can be diffused to cover a wider FOV but in doing so becomes less bright and can lose some of its advantages. This cone of effectiveness can induce noise in the data as cameras come in and out of view. Some hardware can detect the frequency at which active markers are strobing and automatically identify the marker’s label. This advantage makes active markers ideal for real time but with the disadvantage of an upper marker limit. It is possible, albeit impractical, to mix retroreflective and active markers in the same capture volume.
A camera’s lens is its window into the capture volume. Motion capture requires an intricate understanding of exactly how any given lens gathers light from the volume and focuses it onto the camera’s image sensor. This understanding is known as calibration and is required so that any given 2D pixel can be traced back out into 3D space. Calibration is so delicate that a mathematically perfect lens is required for mathematically perfect data. However, such lenses do not exist. A good motion capture lens will be a lens with near perfect radial symmetry, no filter coating in the spectrum in which the capture occurs, high speed, and as close to diffraction limited as possible. Hardware providers generally recommend and resell a variety of lenses for various volume configurations.
The focal length is the distance from the lens to the image sensor when the lens is focused on an object at infinity. The focal length and sensor size will determine the FOV. Different cameras and manufactures may have different sensor sizes so focal length would have to be determined for the specific camera. Generally speaking, however, a wide-angle lens will have a smaller focal length number, whereas a narrow-angle lens or long lens will have a high focal length value. Focal lengths typical for a motion capture volume range from 12.5 to 45mm where sensor sizes can range from ¼ to ¾ inch. However, focal lengths can go as low as 2mm in special cases such as head-mounted cameras.
Generally speaking, and assuming a list of fixed parameters, long lenses are used to capture things very far away, while wide lenses are used to capture things very close. However, distance can be traded for accuracy. A long lens focused on a close object would be more accurate, but have a smaller capture volume than if the same object were being captured by a wide lens. Inversely, a wide lens focused on a far object would be less accurate but have a very large capture volume. Given these trade-offs, balancing distance and focal length against marker size and accuracy is a delicate process.
One additional thing to consider when talking about focal length is camera handoff. Camera handoff occurs when a marker is well inside the capture volume, but leaves the view of a camera. While this marker is still being seen by other cameras, the resulting position of the marker will suffer from its number of contributing cameras having changed. For this reason, simply throwing more cameras with long lenses at a volume does not necessarily make it better.
The f-stop of a lens is focal length divided by the aperture diameter. In practical terms it defines the amount of light that is let in through the lens. This is done by adjusting the aperture, which is a mechanical iris. Closing this iris, referred to as stopping it down, reduces the amount of light captured, while opening this iris allows more light in to be captured.
It is ideal, in the world of motion capture, to be taking pictures that are a frozen instant in time. This means using very fast shutter speeds. Faster shutter speeds capture less light. For this reason it is common to open up the f-stop to let more light in. This, however, has the negative by-product of decreasing the depth of field, meaning objects are out of focus. Balancing f-stop with strobe intensity and shutter speed is a critical consideration.
While not a property of the lens, depth of field (DOF) is closely related to the lens settings. While a lens can only truly be focused on one point in space, the DOF refers to the acceptable instance from that point where an object is still considered to be in focus. Naturally, a deep DOF to increase the range where markers are in focus is preferred. To obtain this, it is typical to stop the aperture down, thereby letting less light in. However, decreasing the amount of light let into the camera makes for a darker image of the marker. Ideally, markers should be in focus to a camera at the farthest extent of the capture volume while also being fully lit. Finding this sweet spot is a balance between f-stop, strobe intensity, and shutter speed.
A prime lens is a lens whose focal length is fixed, while a zoom lens is a lens with an adjustable focal length. While the flexibility of a zoom lens is attractive, they are usually avoided because they contain many complex elements that decrease the amount of light and increase the amount of difficult-to-calibrate image artifacts. It is possible to find high-quality zoom lenses without such aberrations, but they come at an extremely high price.
Which lenses to use is going to depend primarily on the number of cameras present, their resolution, and the size and number of the markers they are trying to capture. Here are some typical system configurations:
• 20 × 20 × 10ft, 16 cameras, 16mm focal length, 15mm marker minimum, 2 actors
• 10 × 10 × 7ft, 32 cameras, 24mm focal length, 5mm marker minimum, 1 actor
• 30 × 30 × 7ft, 32 cameras, 16mm focal length, 15mm marker minimum, 4 actors
• 20 × 20 × 7ft, 64 cameras, 24mm focal length, 5mm marker minimum, 2 actors
A filter is a piece of colored glass whose purpose is to eliminate all light except that emitted from the strobe. Sometimes a filter is mounted in front of the lens, sometimes behind it. Given the retroreflective nature of the markers and the position of the strobes, the resulting filtered image should contain only bright white spots of light reflected by the markers. Filtering the image in this way affords using run-length image encoding (RLE), a simplified lossless compression of data, which is key to the fast frame rates.
Light emitted from the strobe and reflected back from the marker will be captured by image sensors and transferred to camera memory for processing. The speed and resolution of this will vary based on the camera model, but it is typically in the neighborhood of 4 megapixels at 120 fps. While quality data can be collected at 1 megapixel, some cameras offer resolutions as high as 16 megapixels. The image sensor is arguably the most important piece of the motion capture camera when recognizing that higher resolutions and faster frame rates have the biggest impact on data quality. In addition to the primary factors of resolution and frame rate, the shutter, gray scale, and sensitivity must be considered.
The resolution of the camera is determined by the number of photoelectric sensors contained within the image sensor. All things being equal, resolution will have the biggest impact on data quality. This is because the circle fitter will have more pixels to work with when attempting to fit a centroid to any “blob” of pixels returned by the sensor. More information on circle fitting is given in the reconstruction section under Software.
A higher resolution image sensor would allow a wider angle lens or finer precision with the same lens. Higher resolutions can capture smaller markers or farther distances. Higher resolution could also equate to fewer cameras. The benefits to a higher resolution are so vast that it is the single biggest factor to consider when purchasing a camera.
Frame rate is the number of images captured per second. Maximum frame rate is determined by how many times per second the sensor can be read and data offloaded to memory for processing. Beyond the obvious benefits of being able to capture high-velocity actions such as the swing of a golf club, frame rate will also improve data quality. More temporal samples of a marker’s position in space will average down to a more accurate position when filtered. More on filtering can be found in the tracking section under Software.
The image sensor is read at a specified frame rate. The sensor is electronically zeroed and the photoreceptors are allowed to charge for the duration of the exposure time and then the sensor is read. Without first zeroing the sensor, residual light information would be left on the sensor and would manifest as a motion trail in the image the next time the sensor was read. The amount of time a shutter is open before the sensor is read will affect the brightness of the image.
A global shutter is ideal for motion capture. This, as opposed to a rolling shutter, means that the entire image sensor is read simultaneously rather than one row or one pixel at a time. With a rolling shutter, the pixels at the top of the image are essentially from a different time than those at the bottom of the image.
Images taken by the camera are likely either black-and-white or gray scale. White represents the presence of the desired color spectrum, black the absence of color, and grays are the values anywhere between white and black. Black-and-white cameras take images whose pixels are either black or white, whereas gray scale cameras take images whose pixels can be one of up to 256 values (8-bit) between black-and-white. Some less common sensors are capable of more than 256 shades of gray scale while others are capable of less. An image sensor capable of delivering gray scale is ideal because it will unquestionably yield better data over just black or white.
A black-and-white camera has a threshold value. This value determines what brightness a pixel needs to be before it will be recorded by the sensor. If a pixel is determined to be bright enough, it will leave a white pixel on the image. If it is not bright enough, no pixel will be created and the image will remain black. Black-and-white cameras are binary in this regard. One possible advantage to black-and-white over gray scale is that it is faster to transfer and process than gray scale.
A gray scale camera, on the other hand, is capable of capturing pixels whose brightness ranges from nearly black to pure white as long as they are in the spectral range being sampled. Having this information allows the system to more accurately detect edges of markers during circle fitting, resulting in a more accurate centroid.
There are two kinds of sensitivity. The first is determined by how large the photoelectric sensors are. At equal resolutions a sensor with larger receptors, often called buckets, would result in a larger chip, onto which the lens would focus a larger image. The result is that more light will be absorbed by each individual bucket. The second kind of sensitivity is how many different shades of any given color that sensor can register. This is the dynamic range. The image sensor is usually tuned to be more sensitive to a particular wavelength of light, typically red, near infrared, or infrared. By ignoring some colors, the sensor can focus its spectral resolution in the narrow band of light being captured.
Most motion capture hardware providers now offer cameras with onboard image-processing capabilities. This means that the images captured can be analyzed and processed before being sent back to the data collection station. The processing power contained within a camera will vary depending on manufacturer and model. Typical image-processing tasks include feature detection, feature identification, and compression.
The process of analyzing an image in an effort to find some sort of pattern is called feature detection. Features vary based on the particular type of motion capture being deployed. However, in the case of passive optical discrete point capture, the algorithm will be looking for blobs of pixels it determines to be circular. If a blob of pixels is determined to be circular, it is probably the captured image of a marker. When a circle is detected the algorithm can discard those pixels and just retain the centroid information. By only sending a coordinate plus a radius that describes the found circle, the amount of data sent back from the camera can be dramatically reduced, affording much faster frame rates.
Once a feature has been found, it may be desirable to temporally correlate its existence with similar features found on previous frames. This is done by looking back at previously found features and over some period of time measuring things such as velocity and/or size. If a simple prediction places the previous feature at or near the location of the current feature it will be assigned the same identification.
Bus speed, network bandwidth, and disk access are limited, so to further enable high frame rates, motion capture cameras typically deploy image compression. Most pixel information is discarded in favor of the centroids; therefore, the majority of the pixels in the images collected are black. The only nonblack pixels would be those to which a centroid could not be fit. These leftover pixels are run-length encoded and sent back for a more complex circle fitting. Run-length encoding (RLE) expresses the image as long runs of data. For instance, scanning an image from left to right, top to bottom, many thousands of black pixels would be found before encountering a white or gray pixel. Run-length encoding is a type of lossless compression.
A motion capture camera will have several connections in the back, for both incoming and outgoing purposes. Incoming connections will include power, networking, and sync, while outgoing information will include network and video. In some cameras these are combined into a single cable. In motion capture systems containing hundreds of cameras, cabling can be a complex practical issue as the sheer number of cables becomes difficult to wrangle.
Cameras should be mounted in a secure fashion and preferably to the foundation of the building in which the studio is housed. A sturdy box truss in a temperature-controlled room is ideal. Motion capture cameras are delicately calibrated instruments so that the slightest nudge or shift in its position can throw the resulting data out of alignment.
A motion capture volume can be configured in a nearly infinite number of ways. With all of the variables at play, configuring a volume is more of an art than a science. There are a few guidelines, however:
• It is ideal to see at least 5 pixels of resolution for a marker in a captured image.
• Marker images should have a nice full, white center with a crisp gray outline.
• Position cameras and choose lenses such that no marker is smaller than 5 pixels when inside the volume.
• A good maximum marker size for body capture is 16mm. Any larger and they start to impede the actor. Use the smallest marker that still allows for 5 pixels of resolution.
• A good marker size for face capture is 5mm. Any larger and they start to collide with each other on the face and impede the actor. Smaller markers can be captured with very specific considerations.
• More resolution is generally better, but that does not mean that more cameras are better.
Motion capture software can be broadly divided into two categories, acquisition and post-processing. Acquisition software is typically supplied by the hardware provider for the purpose of setting up and running the system. Post-processing software, which might also be provided by the hardware vendor but can involve off-the-shelf tools, is meant to turn the acquired raw data into usable animation for the project. Some software is capable of both acquisition and post-processing activities. This section describes each of the algorithms at play by translating the complex math into plain English. This section does not cover the often necessary step of post-animation or motion editing.
Acquisition is the process of triggering the cameras to take pictures. The system must be synchronized and accurately calibrated. Synchronization, or sync, is important to all forms of motion capture. Sync is the process by which all of the optical cameras are made to capture in unison. Taking synchronized pictures of an object from multiple angles and then comparing those captured images against one another is the basis of all optical and most computer vision-based motion capture technologies.
Calibration is the process by which the intrinsic and extrinsic parameters of a camera are made known. Properly calibrated cameras are essential for quality data during reconstruction. Camera extrinsic values are the values that define the camera’s position and orientation in space. Camera intrinsic values are values required to map any given pixel of the 2D image out into 3D space. Because it is not possible to know one without knowing the other, calibrating intrinsic and extrinsic values often involves a third parameter, a calibration object. A calibration object is an object whose exact dimensions are known. By placing the calibration object in the capture volume and photographing it from multiple angles, it is possible to reverse engineer the camera parameters by assuming that what is seen is the same as what is known. This is done by performing a bundle adjustment. A bundle adjustment is a mathematical process by which a best fit of the unknown parameters is found through reverse projection and optimization of the known parameters. It is ideal to use a calibration object that defines every point in the field of view of the camera including the depth axis. For this reason, a wand calibration is typical.
Calibration should be performed regularly. It is common practice to calibrate the capture system at the beginning of each capture day and at the end. Additional calibrations should be performed if any of the camera’s intrinsic or extrinsic values might have changed, for example, if a camera is bumped or moved. Most capture systems allow arbitrary assignment of calibration files to capture files. This allows users to back apply an end-of-day calibration to some earlier capture data to account for degradation in data quality due to, for example, a slip in calibration.
The extrinsic parameters of a camera are the x,y,z position and x,y,z orientation of the camera in space, relative to the zero point and world scale of the capture volume. The camera extrinsic parameters can be static or dynamic. In the case of a dynamic extrinsic parameter (where the cameras are moving), calibration is recomputed per frame by either re-projecting reconstructions from static cameras back to dynamic cameras or assuming a known calibration object in the scene to be “true.”
The intrinsic parameters of a camera are the values needed to re-project any 2D pixel out into 3D space. These values typically include a lens distortion model, focal length, and principle point, but can contain additional parameters. If it is known exactly how a lens focuses light onto the image sensor, the system can, in software, reverse project any pixel back out into virtual 3D space and assume the point to exist somewhere along that line.
Dynamic calibration is the process of capturing a moving object of known measurements, most commonly a wand. Wands come in many shapes and sizes. Typically, a calibration wand is a rigid stick with some number of markers attached to it. The exact distance of each of these markers to one another is measured and known to a high degree of accuracy. By photographing these markers from many angles, and assuming the known measurements to be true in all images, a 3D representation of the capture volume can be built and the camera intrinsic and extrinsic parameters can be calculated.
When performing a wand calibration, the wand is waved about the volume so as to completely cover each camera’s field of view, including the depth axis. It is also ideal, at any captured instant, for the wand to be seen in at least three cameras. Not doing so will result in poorly calibrated areas of the capture volume. These captured images of the wand are then digested by the software and an accurate model of the camera’s intrinsic and extrinsic parameters is established.
While the most common form of calibration is wand calibration, some systems use static calibration. Static calibration does the same thing as a wand calibration except in a single instant. Static calibrations are performed by placing a single known object in the capture volume and capturing it from all cameras simultaneously and in a single instant. The advantage of this is that the calibration is less subject to error induced by the person performing the wand wave. The disadvantage of an object calibration is that the capture volume is limited to the size and shape of the calibration object.
Some less common machine vision-based systems use a checker-board calibration. A checkerboard calibration is similar to a wand or object calibration in that an image of a known checkerboard is put before the camera and photographed from multiple angles.
Once data is acquired it must be processed in order to be made usable. With optical data this usually involves reconstruction, labeling, cleaning, and solving. Each of these steps generates data that is usable in the next step. Some systems can acquire and process data simultaneously, thereby giving the user data in real time. Real-time data often involves shortcuts or approximations that result in lesser quality data than data derived from more complex post-processing techniques. Depending on the production requirements, real-time quality data may be sufficient.
The term reconstruction as it applies to optical motion capture is the process of creating 3D data from 2D images. The software first finds all of the places in each camera’s 2D image where it detects a marker. During the marker detection phase, often referred to as circle fitting, the software is typically looking for a round blob of pixels to which it will fit a circle. Because blobs of pixels are not perfect circles the 2D position of the resulting circle’s centroid is somewhat inaccurate. Once all the circles are found across all cameras, the process of turning these centroids into 3D trajectories can begin.
Once the cameras are calibrated, the system knows how the lens projects the image onto the image sensor. By reversing this path the system can calculate an imaginary ray back out into the volume somewhere along which the marker is known to exist. By calculating many of these imaginary rays from all cameras and then looking for intersections among them, the system can begin to reconstruct 3D data in the form of discrete marker positions.
While a point can be reconstructed with a mere two intersections, more intersections are better. This is because each of these rays is somewhat inaccurate and more rays will amortize the error down to yield more accurate information. Additionally, a ray’s contribution to a marker reconstruction will be intermittent as it is occluded (no camera could see it) or leaves the camera’s view frustum. So while a marker’s position is derived from the average of its contributing rays, the number of rays contributing to this average is constantly changing, thereby inducing spikes in the trajectory.
Once marker positions are reconstructed they need to be temporally correlated such that the software can determine that a given trajectory is the same marker through time. This process, called trajectory fitting, is usually the final step of reconstruction or the first step of labeling depending on the company view of the pipeline. Trajectory fitting most commonly utilizes 3D velocity predictions but can also involve more complex 2D information from the cameras.
Labeling is the step after reconstruction where the yielded marker trajectories are assigned names. Marker trajectories will be some number of frames long depending on the quality of the trajectory fit and the accuracy of the reconstruction. The process of assigning labels is actually correlating fragmented animation curves rather than naming individual marker points. Having labeled data is essential for the solver to know what any given trajectory is measuring. Unlabeled data, often called raw or uncorrelated, is not useful because it exists sporadically in time, blipping in and out of existence.
By incorporating some biomechanical information into the labeling process, the software can make an informed guess as to where a marker should exist. For instance, it could be said that markers on the head are always a given distance away from one another or that a marker on the wrist can be found within some rigid distance of markers on the elbow. With these sorts of rules at play, should a marker on the head or wrist disappear it is possible to look for an unlabeled marker in a prescribed location. In this manner the more markers that can be identified, the easier it is to identify the entire set.
Sometimes no marker was reconstructed. This is usually because it was occluded. When this happens, the same biomechanical rules involved in labeling can be used to create a marker at the location the missing marker is thought to be. This process is called gap filling. Gap filling usually involves rigid body reconstruction but can also involve more complex biomechanical assumptions. An example of such an assumption might be informing a missing marker’s location by assuming the knee to be a hinge. In this case, there might be information about a thigh and a foot, which could be used with this assumption to reconstruct a missing marker at the knee.
A rigid body is a transform derived from three or more markers thought to be rigid with one another. Imagine that any three points in space would define a triangle and that from a triangle it is possible to extract a rotation. That rotation, plus the average position of the markers would give a rigid body transform.

Figure 4.8 Any three nonlinear points in space define a triangle. From a triangle, a rotation and translation can be extracted.
(Image courtesy of John Root.)
Optical data is unfortunately noisy. This is primarily due to inaccurate calibration, poor circle fitting, and occlusion. Whatever the cause, these errors manifest as trajectory spikes and high-frequency jitter that must be removed. This process is often referred to as cleaning. If the data is not cleaned, the spikes and noise will come through in the resulting animation.
Cleaning typically involves some amount of identification and removal of large data spikes, followed by application of a light filter, where the filter is a mathematical algorithm in which the animation is smoothed to remove noise. Many types of filters are available, but all should be used with caution because they can be destructive to the animation. Over filtered data can look mushy and lack the subtlety and nuance that makes motion capture so realistic. Most filters benefit from high frame rates. This is because the more data they have to average or analyze, the more accurately they can distinguish between noise and performance.
Solving is the process of turning processed data into usable animation. Most commonly this involves manually fitting a skeleton into marker data, defining a relationship between the markers and the skeleton, and then having the solver attempt to hold that relationship over the course of the animation. Because the physical relationship between a marker and a joint can vary due to a variety of factors including joint type, suit slide, muscle bulge, and skin stretch, holding the corresponding digital relationship can be a tricky process.
A rigid body solver takes groups of three or more markers that are assumed to be rigid to one another and extracts a 6 degree-of-freedom transform. Extracted transforms, in the form of joints, can be parented relatively to one another such that they describe a skeleton. Although a skeleton derived from rigid bodies might visually look correct, it typically contains transforms on undesirable axes that need to be rectified in a second step often involving constraints.
MotionBuilder’s Actor solver is an example of a rigid body solver.
A constraint solver is very similar to and often used in conjunction with a rigid body solver. With a constraint solver, the markers themselves are used to directly drive the skeleton’s rigging controls, which in turn drive the skeleton. Using a motion capture marker as an IK4 handle would be an example of a constraint-based solving method. MotionBuilder’s Actor solver is an example of a constraint-based solver.
A global optimization solver attempts to find a best fit for a skeleton into its marker data. The best fit is considered to be the solution with the least amount of error. Error can be described in a number of ways, but is most commonly described as variations in distance. Distance is the user-defined initial offset between a marker and a joint in the target skeleton. In this case a global optimization would attempt to animate the skeleton such that all of the distances between markers and joints are offset the same throughout time as they were in the initial user fitting. Vicon’s Blade, Motion Analysis’s Calcium, and the Peel Solver are all examples of globally optimized solvers.
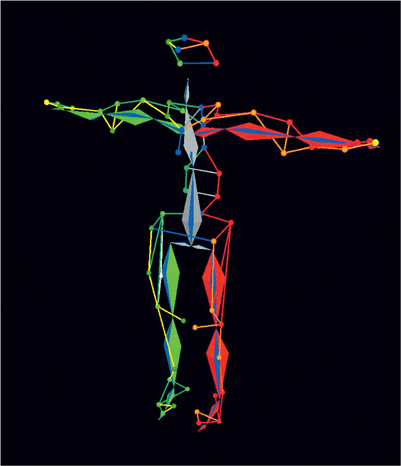
Figure 4.9 A skeleton fit into its markers using Vicon’s Blade.
(Image courtesy of ImageMovers Digital.)
A physics solver uses the marker data to actuate the skeleton in a number of ways. Once a marker is assigned to a bone, the bone might be asked to take on the velocity of that marker or to gravitate toward the marker. Endorphin is an example of a physics-based solver.
A behavioral solver reinterprets the marker data into a common language spoken by the rig. To accomplish this, data is analyzed and statistically strong patterns are extracted—be it FACS (Facial Action Coding System) values, phonemes, emotions, intentions, or some other meaningful animation data. A behavioral solver has the advantage of being able to solve and retarget simultaneously. Behavioral solvers are typically used for the face or other non-rigid deformable surfaces where joints are inappropriate. The Image-Metrics solver is an example of a behavior solver.
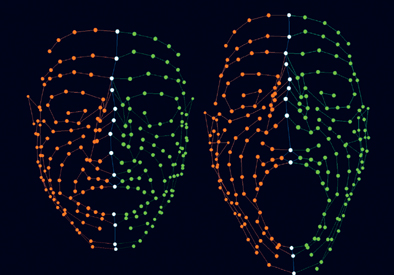
Figure 4.10 Marker-based Facial Motion Capture.
(Image courtesy of ImageMovers Digital.)
Humans are very adept at reading and understanding facial expressions. They spend so much of their daily lives reading others’ faces that they have developed an innate intuition of facial dynamics and anatomy. In fact, they are so good at this, that when they see something that falls outside of their understanding, no matter how subtle, it will catch their attention and distract them from the meaning. This is true for human, non-human, and highly stylized characters and all the aspects of color and lighting therein. Because the problems associated with re-creating a facial performance are so far reaching and complex, many would argue it is in fact the hardest task in all of computer graphics.
Facial motion capture is an area of very active research. There is new hardware and new algorithms emerging every day. No single approach has been shown to be the clear winner. Some of the best examples of great end-result lack scalability and often involve very large teams of very specialized talent burning through very large budgets. A commonly accepted and effective approach to facial motion capture is:
1. Survey an actor
2. Build a rig
3. Acquire performance data
4. Drive rig with performance data
This approach makes a lot of assumptions about the project and is not appropriate for all productions. In particular, an important consideration is whether the CG character is intended to be a representation of the actor themselves, or of a different human character, or even of a fantasy non-human character.
Contained within this section is an overview of the most common technologies and processes being deployed in the VFX community for facial motion capture.
Actor survey is the process of measuring the various aspects of an actor’s face and its motion in a high resolution, controlled environment. This data can be used directly as reference for modeling, rigging, and surfacing or indirectly to build complex statistical models of the actor’s facial motions for later use in tracking, solving, and retargeting.
Typically an actor survey yields a high resolution neutral mesh (such as those that can be acquired via a Light Stage X scan) and some additional number of frames describing the possible extremes for that mesh from its neutral state. Optionally, it might also include temporal information about the nonlinear motion between the neutral and its extremes (such as can be acquired via Mova Contour or Dimensional Imaging) as well as surfacing information such as albedo5/diffuse, specularity, normal, and subsurface.
The most prevalent form of survey being used is the Facial Action Coding System, or FACS. FACS is a set of muscle motions that can deconstruct and taxonomize human facial expressions. While not originally invented for the purposes of computer animation, when augmented and extended it can help to define a set of values that if mixed properly, and barring any external influence, can yield any given facial pose. When using FACS it is important to note that while it is a nice starting point for the inputs required to make a great facial rig and build powerful statistical data sets, it is not a complete solution. For instance, FACS does not describe how a face will bounce and sag when running, nor does it describe the effects of friction as a face is dragged across a floor or compression when poked by a finger.
Acquiring a useful FACS data set can be a tricky endeavor because very few actors can perform all the FACS poses voluntarily and even fewer can isolate the motions such that no other muscles engage simultaneously. Further, because the motions described by FACS are generally measured relative to the skull (which is not easily captured) the data needs to be stabilized. These two problems are some of the most underestimated problems associated with facial animation and facial motion capture.
Actor facial survey data is typically measured from the frame of reference of the neutral. However, it is not practical to capture data that is perfectly stable to the neutral and therefore the collected survey data usually has to be stabilized. To “stabilize” means to remove the gross motion of the head (typically the skull) leaving only the isolated motions of the face. Well-stabilized survey data is important because it often becomes the basis by which performance capture data is stabilized. While this initial stabilization usually boils down to trained artisans making frame-by-frame adjustments, there are two common methods that can yield a significant head start.
One common method for bootstrapping stabilization is to find three or more rigid points on the subject’s head. From these points a rigid body can be derived which the entire data set is expressed relative to. However, the surface of the human head does not have any rigid surfaces that can be practically measured. Even the most rigid-like points will slide as the face deforms and will cause errors to be embedded into the facial motion.
A less common method for removing gross motion is iterative closest point or ICP. With this method two clouds of data are positioned within each other such as to minimize the deviation between them. ICP-based stabilization is often aided by a human-guided selection of an area that is known to be similar between the two poses and works better with very high resolution survey data, i.e., not marker-based survey data.
It is ideal to have FACS data that is isolated. In this context, “isolated” means that at any given frame, the motion caused by the muscles of interest is separated from the involuntary motion of other muscles. This is usually accomplished by neutralizing the extraneous information or, in other words, setting it to be like the neutral frame where no muscles are engaged. This can be a somewhat subjective and time-consuming process.
There are many different technologies for acquiring facial survey data. Each comes with its pros and cons. When considering what technology is right for a project the things to consider include, resolution, frame rate, surface information, and actor comfort. The most prevalent forms of facial survey are:
One method of actor survey is simply to put markers on the face. Whether passive or reflective the idea is to capture point data from the surface of the face that is cleaner, and of higher resolution and frame rate than can be efficiently acquired in a performance capture scenario.
Survey data in the form of markers tends to yield around a few hundred points of information about the surface of the face. This resolution tends to be a bit sparse for the purpose of modeling reference; however, a marker-based survey can yield 120 or more frames per second of clean and highly accurate animation data. This information can be very useful for rigging, animation, and the various statistical models used to stabilize, solve, and retarget but is practically useless for surfacing. Marker-based survey data tends to be the cheapest.
A technology that, until recently, has been primarily associated with single frame scanning is Dense Stereo Reconstruction. This technique seeks to determine the 3D location of closely spaced (“dense”) features on an object by comparing the location at which each feature occurs in separate images, simultaneously captured by multiple calibrated cameras. One key benefit to this method is its scalability in that more cameras and more resolution will typically yield a higher fidelity result. Additional benefits include very fast acquisition time and good surface information.
Recent technologies can afford animated data sets by capturing and reconstructing a sequence of images, although they tend to be of lower resolution than that of their single frame counterparts as one might expect with DSLR vs video. Temporal data gathered in this way can be costly to track as the correspondence of features between frames is not easily recovered.

Figure 4.11 A Dimensional Imaging 4D system at work.
(Image courtesy of Dimensional Imaging.)
A tried and true method for acquiring the surface of the face and some limited color information is the Laser Scanner. Laser scanners such as the Cyberware PX work by projecting a low intensity laser on the face to create a profile. This profile is captured from a calibrated camera and can then be turned into a slice of the human face. By capturing thousands of slices in this way, a complete representation of the actor’s head can be acquired. Laser scanners suffer from slow acquisition time but deliver good bang for the buck on the quality front.
Structured light scanners work by projecting a known pattern (usually stripes) onto the face. A typical structured light scanner is made up of a projector, a camera off to the side, and software. The projected pattern will appear distorted to the camera. This distortion can be analyzed to derive the 3D shape of the face. Some structured light scanners will capture at least two conditions: one of the projected pattern and a flash condition for surface color purposes. Some scanners use an infrared pattern to capture the two conditions simultaneously (Microsoft Kinect). Structured light scanners are faster than laser scanners and several dynamic structured light scanners exist. However, it is more difficult to get dynamic ear-to-ear data because multiple projector patterns will conflict with each other.

Figure 4.13 Light Stage X with Richard Edlund, ASC, VES and high-resolution geometry and texture data from a scan.
(Images Copyright © USC Institute for Creative Technologies, courtesy of Paul Debevec.)
A Light Stage is arguably the highest quality facial scanning system currently in existence. A Light Stage device is essentially a geodesic sphere of lights. The subject sits inside the sphere while the scan takes place. Each scan is a series of photographs of the subject’s face under different lighting conditions, taken by multiple cameras in rapid succession. The lighting conditions are designed to get as much information about the shape and reflectance of the face as possible. For example, some lighting conditions are designed to capture the normals of the face, while other lighting conditions are polarized in order to capture the diffuse albedo of the skin without the specular highlights. Each scan takes about four seconds during which the subject is asked to stay still and hold a particular facial expression. (Slight involuntary movement is stabilized during processing to minimize ghosting.) The output data from the Light Stage is a set of high resolution, ear-to-ear facial scans, including geometry, diffuse albedo map, displacement map, and normal maps. Typically, a full set of FACS expressions is captured. Option ally, all the facial expression scans can be corresponded at the sub pixel level and delivered as a set of blendshapes on an animatable mesh, with all texture maps in one artist UV (Ultra Violet) space. Besides facial scanning, other uses of the Light Stage include dynamic performance capture of all the above data with high speed cameras and “one light at a time” datasets for relighting. While a Light Stage produces very high quality data, it is also relatively expensive com-pared to other scanning technologies.
The acquired survey data will be directly and obviously useful as reference. The idea being that the shapes, motions, and surface properties acquired in the survey will serve as the target for the rigs, animation and look development of the production. In this way, the better the survey data, the more information the team will have. In addition to using the survey data as reference, it can be beneficial to also collect a variety of still and video images of the actor under various lighting conditions and performance scenarios.
Given a collection of survey data (e.g., a FACS-like set of facial shapes) it can be useful to create a compact mathematical representation of the variation in this facial data. This representation, which is often referred to as a statistical model (not to be confused with a CG character model), can help to define the range of plausible shapes that a given actor’s face can adopt. A good model of plausible shapes provides a framework for computer algorithms to correctly interpret potentially noisy or unstable facial capture data, rather as a person’s knowledge of English allows them to interpret a sentence, even when some words are misspelled.
A variety of mathematical techniques have been used to create statistical models. Some of the simplest (and often quite effective) methods are linear techniques such as Principal Component Analysis or eigen-shapes. These approaches reduce the large amount of variation seen in a set of examples to a lesser number of ‘basis-shapes’ which can be additively combined to produce new face shapes—the idea being that the new shapes ought only to be plausible examples of a face. Models built using linear techniques often have useful properties, such as “orthogonality,” which can make them mathematically straightforward to use in tasks such as data-cleaning. However, the downside of simple linear models is that they cannot perfectly encode the non-linear variation which is undoubtedly present in the human face, and thus the models can never be totally relied upon to simultaneously represent all possible variation and only plausible variation. There are many examples of non-linear approaches to the problem, such as mesh-based inverse kinematics. These have shown promise, but creating accurate mathematical models of complex deformable objects such as the human face remains an active area of research and is still, in the general case, far from “solved.”
Facial rigging is the process by which a face model becomes animatable. Often it is the face rig that is driven with motion capture and not the mesh directly. It is for this reason that the face rig is a critical component of the facial motion capture pipeline. If the rig cannot drive the mesh to achieve what the Director requires, there is little the animator can do to improve the performance. Because captured marker data from the face can be sparse, noisy or incomplete, it usually falls on the rig to make up the missing information. Rigs will commonly engage a number of sophisticated techniques to fill in uncaptured details such as fine wrinkles or deep skin folds. The rig should be well understood before setting foot in a capture volume. Both rigging and capture stand to benefit from finding the right balance between what should be captured and what can be algorithmically re-created. The facial rig consists of three primary components: the deformers, the user interface, and the model.
A deformer is a method by which the model is made to move. Many different types of deformers exist and new ones emerge all the time. Each deformer comes with its own advantages and disadvantages. For this reason, it is common for face rigs to contain multiple types of deformers. Some types of motion capture data are better at driving certain kinds of deformers than others. In some cases, captured data drives the deformers directly. In other cases captured data is interpreted into a common language spoken by both the data and the rig.
A blend shape deformer, sometimes referred to as a morph target, is a subset of vertices that have moved from their neutral position. A blend shape gets its name from the notion that it can be blended on or off with a multiplier value from 0 to 1. For example, a blink shape can make a character’s eyes go from neutral (0) to sleepy (0.5) to fully closed (1). In this manner, many shapes can be created so as to give the face rig a complete range of facial motion.
Note, however, that blend shapes are prone to “crashing.” This is a peculiar artifact that manifests when certain combinations of blend shapes do not work well together and the resulting mesh is “off-model,” or not character achievable. To counter this effect, corrective shapes are often added that automatically trigger when bad combinations are encountered. For this reason a high-end facial rig built from blend shapes might easily contain hundreds, or even thousands of blend shapes.
The same joints used in body rigging are often used in face rigging. While typically associated with articulated rotations, a joint is really just a method by which collections of points can be made to move through a single motion’s influence. This influence can be made to drop off over a distance such that when the joint is moved, its effect on the mesh is soft and natural. Setting up a rig with joints is fairly straightforward and results can be obtained quickly. However, rigs made with joints are typically unconstrained and prone to generating off-model shapes.
A wrap deformer is most commonly a low-resolution model that deforms a high-resolution model. In facial rigging, this allows a much more manageable number of points to control a much higher, unmanageable number of points. One method is to create a wrap deformer from motion capture data and use it to control a high-resolution model. In this manner a hundred or so points captured on an actor’s face can be made to control a high-resolution version of that same actor’s face.
There are many other different types of deformers, including clusters, lattices, wires, and muscles. New deformers come out of the research labs every day. Some are better for facial rigging than others. As new types of deformers come online, the facial rigging landscape changes as does the facial motion capture pipeline.
In regard to rigging, the user interface is a set of controls exposed to the user allowing the face to be animated in an intuitive way. With a cleverly designed user interface, it is possible to control many deformers with a single slider, dial, or control. A face rig might have 30 blend shapes, 20 bones, and a heap of special case scripts and algorithms required to simply make a face smile. Engaging all of these elements in the manner required to achieve a smile could be set to a single slider labeled “smile.” However, setting and animating these controls with motion capture data can be a tricky and highly nonlinear process.
There are many options when it comes to facial performance acquisition. The options can be broadly divided into three categories.
For years “Face Paste” was the de facto method for facial motion capture. Face paste refers to facial capture that is done separately and then pasted onto body animation. A typical face paste scenario would involve an actor sitting in a high resolution volume with many cameras aimed at his face. This as opposed to moving freely about a large stage affords cleaner and higher fidelity data. Traditionally, this was the only reliable way to get high quality marker data off the face. With recent advancements in hardware this is no longer required. However, face paste is still commonly used for dense stereo reconstructions such as with companies Dimensional Imaging, Mova Contour or Depth Analysis.
Face paste can be a very effective way to get high quality data for a shot or sequence. However it can lack proper eye and neck motion that would marry it to the body making it less than ideal for a feature.
Recent advancements in the resolution and transfer speed of traditional optical motion capture cameras have afforded more reliable acquisition of lots of tiny markers on the face in a full performance capture environment. The key benefit therein being a unified and synchronous pipeline that yields performance information about all parts of the body simultaneously. While attractive for those reasons, optical face data is known to be tedious to post process. Additionally, markers on the face can be a nuisance for the actor and invoke extra down time and costs for application and maintenance as they are time consuming to apply and tend to fall off.

Figure 4.14 MOCAP Design Helmet Mounted Camera.
(Image courtesy of MOCAP Design.)
Many productions with performance capture needs are moving towards a helmet mounted camera (HMC) based solution. Be it a single camera or multi camera solution, the idea is to use a camera(s) at the end of a tiny boom arm mounted to a helmet, worn by the actor. This approach seeks to capture video footage of the face in such a way that the actor’s face is always in view and maximizing the resolution of the camera. Its down side is that the camera assembly can limit the types of actions the actor can do. For instance, eating or kissing.
The common approach where an HMC is involved is a single color camera. This would typically yield highly distorted (very wide angle lens) video footage of the face. From this footage points or features can be tracked over time and the resulting information mapped to a digital character. The key benefit to the single color camera is that it is great reference for the animators in post that will need to be working with the resulting solves. A downside to a single camera is that it can be difficult to determine stabilization and depth information from a single 2D image.
A less common (but gaining ground quickly) approach is to mount multiple cameras on the helmet. This approach seeks to reconstruct 3D information about the face by viewing it from multiple, per frame calibrated cameras. 3D information usually comes in the form of discrete points in space that are reconstructed from ink dots painted on the actor’s face; however, some multi camera solutions are capable of dense stereo reconstruction to deliver temporal information about the entire surface of the face. While convincing arguments can be made that multi camera solutions and the 3D information they deliver are better than the 2D alternative, to date, they require significant, time-consuming, and expensive post processing.

Figure 4.15 Technoprops Helmet Mounted Cameras.
(Image courtesy of Technoprops.)
One attractive benefit to motion capture is the ability to record clean synchronous audio at the time of the performance. This ability to place boom or lavalier mics right in an actor’s face during a performance is one not always afforded by traditional live action shooting. However, a motion capture stage is typically a giant box filled with lots of people and expensive hardware. It is not an ideal situation for acquiring clean audio. To make matters worse, the motion capture suits can often produce the sound of tearing Velcro. Caution should be taken to insure a stage is capable of producing clean synchronous audio.
Similar to body motion capture, solving is the process of turning the acquired data into usable animation. Because there are so many ways to skin the proverbial cat, facial motion capture solving can mean many things. In general, however, solving falls into three categories.
Direct drive refers to solving where the captured motion is used directly to drive the mesh. Because the captured data is directly deforming the facial mesh, a direct drive solver can achieve remark-able fidelity. A downside to a direct drive solve is that there is often missing information about the fine details of the face. Another downside is that direct drive solves are not easily editable or retarget able. There are several different methods of facial solving that could be considered Direct Drive.
The most common form of Direct Drive is to constrain the rig directly to the data. This generally presumes the data is markers, that the rig contains bones and the result is to be 1:1. In this case the bones can be point constrained to the markers directly to obtain a reasonable result. Extending this method, rotations can be inferred from clusters of markers to get a better result. A direct constraint method is attractive in that all the fidelity, including motion based caused by gravity and friction comes through directly onto the mesh. A common downside however is that the resulting bone transforms can be very difficult to edit from an animator’s perspective.
With an indirect constraint, the facial rig is constrained to variation in the data using prescribed rules. For instance, the relative distance between two forehead markers might be used to drive the raising and lowering of the brow. Indirect constraints have the benefit of being able to generate animator-friendly data directly on the animation controls. However they have the downside of being limited in the number of rules they can practically maintain. That is to say, rules will quickly contradict one another and compound to a point that they get too complex.
Another method of Direct Drive is to treat the marker data as a mesh, with each marker acting as a vertex. In this case the “marker mesh” is used to wrap deform the model. This method also presumes 1:1. It is similar in principle to the direct constraint method, but can work better as part of more complex hybrid methods.
Surface fitting is a method in which the resulting deformation of the rig is made to fit into the motion capture data. With this method it is ideal that the captured data be 3D, be it as markers or surface capture. There are several types of surface fitting, the most common is the Least Squares Fit. With a least squares fit, a set of previously defined, neutralized, and stabilized shapes representing the possible extremes of the face are blended together such as to minimize the deviation between their resulting surface and the captured data. Least squares surface fitting benefits from its ability to up sample the fidelity of the motion capture. That is to say, the motion capture data is often of less fidelity than the mesh which is fit into it. The downside to this type of surface fitting is it requires a very specific type of rig and is not guaranteed to generate data that is animator friendly.
High dimensional mapping refers to the technique in which the captured data is interpreted and meaningful information is extracted on a level higher than individual markers. That is to say, the entire frame of data is analyzed and meaning extracted. In practice however this is usually done on clusters of data and over multiple frames. Once meaning is extracted, it is mapped to rig controls by a set of bindings that are set up in a training phase. High dimensional mapping is also referred to as Pose Space Retargeting or Example Based Solving.
High dimensional mapping has the advantage of being able to solve and retarget simultaneously right on to the animation rig. It also benefits from being data ambiguous in so much that it can work with data inferred from 2D, 3D or any other kind of information gleaned from the face. Its downside is that it can suffer from an over defined solution space which can manifest as artifacts in the resulting animation data.
It is possible, and perhaps best, to combine many approaches to offset the negatives of any one approach. For instance, using a direct constraint method to drive the mouth and an indirect constraint to drive the forehead. Or perhaps using a wrap deformer to drive the face with corrective shapes triggered by high dimensional mapping. Additionally, it might be worthwhile to try surface fitting a set of blend shapes and then deploy a high dimensional mapping between the resulting coefficients and the final animation rig.
Real-time motion capture refers to the capture, processing, and visualization of motion capture in a time frame that is, or appears to be, instant. It usually manifests as one or more large display screens displaying solved and possibly retargeted data on a digital character, in a digital environment. Because real-time motion capture forgoes complex post-processing, it usually comes with some limitations and or artifacts. Most often real-time is used as a powerful previsualization tool for directors and DPs to immerse them in the virtual world.
Real-time can be a very useful tool on the motion capture stage. Its uses include, but are not limited to:
It is common when using motion capture that an actor is playing a character very different than himself. Almost surely in costume but very probably in proportion and style as well. For this reason it can be invaluable as an actor to see a performance as it will look on the character. By doing so, the actor can work with the Director to account for the differences between himself and the character and incorporate those differences into the performance.
By deploying a virtual camera and/or pointing device the Director or DP can virtually fly around in the 3D set and play with camera, composition, and lighting. The freedom of the virtual environment means that cameras can be placed and moved in ways not possible on a live action set. In fact, the set itself can be rearranged instantaneously for composition. Light, color, time of day, and a variety of other factors are all completely under the control of the Director while the performance takes place.
A motion capture stage is often sparse with regards to props and set decoration. For this reason, it can be useful for an actor to see himself in the virtual environment. This allows for a sense of space and an awareness of one’s surroundings.
Expounding on Virtual Cinematography, with the click of a button and a move of the mouse, the digital character can be instantly transported from location to location in a way that would be impossible in the live action world.
Aside from the many benefits real-time affords to motion capture and virtual production, it can also be used as a final product. Real-time puppeteering of characters and stage performances is becoming more and more common.
Real-time motion capture is an emerging field. It gets better every year. To date, however, significant compromises must be made to achieve real time. While some hardware providers are able to achieve remarkable real-time data, passive optical-based motion capture is inherently bad at real time.
Optical motion capture is computer vision based and therefore the cameras must have an unobstructed view of the markers. In post, it is common for the tracking team to sort out artifacts induced by cameras losing line of sight or markers having been occluded. Because real-time MoCap forgoes this post-processing, it is common to reduce the number of actors, limit the props, and govern the performance to maximize marker visibility. It would be a very hard, for instance, to generate real-time data for 13 actors rolling around on the floor.
Trying to make sense of the markers on the stage in real time is a daunting task. Beyond simply using fewer markers, inducing asymmetry into the marker placement will make them easier to identify. When the labeler is measuring the distance between markers, it is less likely to get confused and swap markers when the markers are placed asymmetrically. An asymmetrical marker placement, however, may be less than ideal for solving.
Some methods of solving are very processor intensive. As such they might not yet be possible in real time. Solving methods that are currently possible in real time often involve approximations and limitations that will yield a resulting solve that does not look as good as an offline solve. Given this, plus the compromises induced by marker placement modifications and performance alterations, what comes through in the real-time previsualization might not be indicative of the final quality of the animation.
Real-time rendering technology is catching up with offline rendering technology at a radical pace. Some of the games on the shelves these days look nearly as good as the movies in the theaters. Using real-time game rendering technology to previs a film is becoming a common practice but one that requires significant investment. Off-the-shelf solutions such as Autodesk’s MotionBuilder offer a complete turnkey package to visualizing motion capture in real time. Expect that real-time-rendered characters and environments will come with compromises to visual quality, most notably in lighting and lookdev (look development).
If real time is a requirement, passive optical technology might not be the best choice. Passive optical is known for its accuracy, not for its real-time ability. Some optical systems such as Giant and Motion Analysis are quite good at real time considering the limitations inherent in the technology. At the expense of quality, alternate technologies can deliver more reliable real time. Refer to the section What Technology is Right for a Project? for alternate technologies that may be better suited for real-time capture.
Full Service Providers
| Animatrik Film Design | Audiomotion | The Capture Lab |
| Burnaby, Canada | Oxford, United Kingdom | Vancouver, Canada |
| www.animatrik.com | www.audiomotion.com | www.capturelab.com |
| Centroid | Giant Studios | House of Moves |
| London, United Kingdom | Manhattan Beach, CA, USA | Los Angeles, CA, USA |
| www.centroid3d.com | www.giantstudios.com | www.moves.com |
| Imaginarium Studios | Imagination Studios | Just Cause Productions |
| London, United Kingdom | Upsala, Sweden | Los Angeles, CA, USA |
| www.theimaginariumstudios.c om |
www.imaginationstudios.com | www.for-the-cause.com |
| KnighT VisioN | Motek Entertainment | Motion Analysis Studios |
| Los Angeles, CA, USA | Amsterdam, The Netherlands | Los Angeles, CA, USA |
| www.knightvisionmocap.com | www.motekentertainment.com | www.mastudios.com |
| Motus Digital | Origami Digital | Pendulum Studios |
| Plano, TX, USA | Hawthorne, CA, USA | Los Angeles, CA, USA |
| www.motusdigital.com | www.origamidigital.com | www.studiopendulum.com |
| Red Eye Studio | SCEA Motion Capture | Universal Virtual Stage 1 |
| Hoffman Estates, IL, USA | San Diego, CA, USA | Los Angeles, CA, USA |
| www.redeye-studio.com | Motioncapture.playstation. com |
www.filmmakersdestination. com |
Facial Motion Capture Hardware/Software Specialists
| Captivemotion | Cubic Motion | Dimensional Imaging |
| Chandler, AZ, USA | Manchester, United Kingdom | Glasgow, Scotland |
| www.captivemotion.com | www.cubicmotion.com | www.di3d.com |
| Dynamixyz | ImageMetrics/Faceware | Mocap Design |
| France | Santa Monica, CA, USA | Los Angeles, CA, USA |
| www.dynamixyz.com | www.facewaretech.com | www.mocapdesign.com |
| Mova Contour | Technoprops | |
| San Francisco, CA, USA | Los Angeles, CA, USA | |
| www.mova.com | www.technoprops.com |
| Animation Vertigo | Firebolt Entertainment | Movicap Studios |
| Irvine, CA, USA | Hyderabad, India | Hyderabad, India |
| www.animationvertigo.com | www.fireboltentertainment.com | www.movicap.com |
| Sparkle Frame | ||
| Hyderabad, India | ||
| www.sparkleframe.com |
Additional Resources (suits, markers, etc.)
| 3×3 Design | MoCap Solutions | |
| British Columbia, Canada | Los Angeles, CA, USA | |
| www.3x3.bc.ca | www.mocapsolutions.com |
The origin of Virtual Production lies in techniques adapted from motion capture that allows an artist, such as a director, to engage with CGI in real-time in a manner which is similar to shooting live action. Starting with filming a character’s performance the practice expanded to encompass a virtual camera, and Simulcam.
In its early incarnation, virtual production saw popularity in previs for on-set visualization and for virtual cinematography, leading to the development of the initial definition of the practice as “computer graphics on stage,” or the process of shooting a movie with real-time computer graphics, either for all-CG movies (such as Christmas Carol [2009], or Tintin [2011]) or visual effects movies with live action (such as Avatar [2009], or Real Steel [2011]).
As the understanding of virtual production has developed and evolved, consideration has been given to the development of a shared asset pipeline, where digital assets created at the start of the filmmaking process are reused throughout production. This assumes the assets are built according to the needs in the rest of pipeline or at least a good starting point to build. The benefits of this are twofold: It removes the need to re-create assets at each stage of the filmmaking process, and it maintains the integrity of the creative intent as decisions are carried through rather than interpreted and re-created.
In tandem with the developing asset pipeline, virtual production techniques are seeing adoption outside the context of a stage or set. This has led to a revision of the virtual production definition to encompass a broader scope. The broad definition states that “Virtual Production is a collaborative and interactive digital film-making process which begins with Virtual Design and digital asset development and continues in an interactive, nonlinear process throughout the production.”6
In this context virtual production encompasses world building, previs, on-set visualization, virtual cinematography, character development and a digital asset pipeline that bridges all these practices.
World Building describes the design and iterative process that imagines and actualizes the narrative space. In the context of virtual production, World Building utilizes CGI tools to visualize this space and through this it provides new ways to explore and iterate on a story.
Previsualization is covered in detail in a different section of this book (see the section entitled Previs).
On-set Visualization encompasses performance capture (see Motion Capture section), On-set Previs (see On-Set previs section) and real-time capture and playback of computer graphics, which support three modes of operation. The first is a live record mode where an actor’s performance is recorded in real-time; applied to the CG character(s); and simultaneous CG playback visualizes the applied performance while shooting is taking place. The second is a review mode where a recorded performance is replayed and displayed to the cast and crew on set. The third is a hybrid of both, where a performance is replayed, while another is recorded and layered over the recorded performances.
Virtual Cinematography is the application of cinematographic principles to a computer graphics scene, providing solutions for cinematographers to compose and shoot as if it were live action. Components of Virtual Production include:
• A Virtual Camera, which is a physical interface device with a set of controls that emulates functions found in a physical camera. The device outputs instructions which are used to drive a Computer Graphics Camera in a 3D scene.
• Real-time camera tracking, that records the position and movement of a physical camera in 3D space. It can utilize position information from cranes, dollies, Steadicams, or motion capture systems and apply the resulting XYZ position information to a CG camera in a 3D scene.
• Simulcam, which combines a Virtual Camera, with real-time tracking and live compositing. The resulting system is capable of combining real world actors and sets with computer graphics actors or sets, allowing the cinematographer to evaluate the interaction of CG with live action in real-time during a shoot.
Virtual production is a new way of producing media that is currently in the making. At the time of publication, this section of the VES Handbook must be qualified as “in progress.” A future milestone on this topic should be achieved when the Virtual Production Committee, an assembly of multiple Hollywood organizations including the VES, delivers its findings and recommendations.
In the meantime, some of the best creative minds in the motion picture industry are continuing to experiment and define this next step in the evolution of computer graphics that promises the ability for everyone to see visual effects as if they were live on set.
1 From a triangle a plane of rotation can be inferred. In the case of the upper arm joint, three markers would want to be placed as rigidly to one another as possible such as to not disturb the triangle and yield false information about the rotation of the shoulder.
2 Occlusion is when a marker cannot be seen by a camera or enough cameras to yield good data.
3 Frontalis—muscles above the eyebrows.
4 IK is short for Inverse Kinematics. This is where some number of hierarchically connected joints are transformed on their prescribed degrees of freedom to reach a target destination. In this case, the algorithm would compute the necessary rotations to reach a motion capture marker.
5 Albedo—reflecting power of a surface.
6 Created by the Virtual Production Committee, 2012, under David Morin and John Scheele, as part of their mission to define and set best practices for Virtual Production.