Chapter 12
Adapting for Future Technologies
IN THIS CHAPTER
 Using the power of artificial intelligence
Using the power of artificial intelligence
Looking at machine learning
Considering chat bots
Assessing alternative data sources
FinTech has already dramatically changed the financial industry, and even more changes are still to come. In this chapter, we tell you about some of the exciting new technologies that have recently started finding their way into the industry and started shaking things up, including artificial intelligence, machine learning, chat bots, and alternative data sources.
Harnessing the Power of Artificial Intelligence
Artificial intelligence (AI) has in recent years captured the public imagination with compelling demonstrations of both novel and practical applications. Voice recognition in virtual assistant devices and apps, facial recognition on social media, self-driving cars — these are but a few of the more prominent examples. For FinTech firms, the use cases include AI-enabled investment management, credit analytics, anomaly detection, data de-noising, data generation, and autonomous decision-making, among others.
The following sections define AI, describe artificial neural networks used in AI, and explain how AI works in FinTech.
Defining AI
 The definition of AI is fairly straightforward: automation of a task believed to require “natural intelligence” to complete. AI research and development has traditionally focused on these five areas:
The definition of AI is fairly straightforward: automation of a task believed to require “natural intelligence” to complete. AI research and development has traditionally focused on these five areas:
- Robots: Robots used in manufacturing were some of the earliest commercially successful applications of AI that represent an interdisciplinary approach incorporating information processing, mechanical engineering, power engineering, and material science. Today, robots are routinely employed in healthcare, law enforcement, extraction (for example, oil and gas discovery and drilling), surveillance drones, interplanetary exploration, toys, and education (for example, LEGO Mindstorms), to name just a few applications.
- Computer vision: This complements robotics but has its own specialized applications in surveillance, facial recognition, video motion tracking, and autonomous vehicles.
- Natural language processing (NLP): Most people have probably experienced NLP through telephone customer service help, in which it’s possible to use usually simple speech commands and requests to navigate the menu system. This same technology also powers virtual assistant devices (such as Alexa, Google Assistant, and Siri), email reading, and contract/content analysis.
- Expert systems: These typically provide some level of decision support that emulates human decision-making in interpreting data sets that may incorporate, for instance, digital imagery. An obvious application is in computer aided diagnosis (CAD) for healthcare, but CAD systems also exist for automotive servicing, equipment troubleshooting, workflow processing, and command and control operations.
- Artificial life: Artificial life is a broad range of techniques that look to nature for inspiration and clues on how to tackle difficult problems. There are many use cases that include transportation scheduling, circuit design, training robots, code breaking, forensic construction of facial composites, and so on. Of particular interest for FinTech firms are valuation of real options, portfolio optimization, design of automated trading systems, and representing rational agents in economic models like the cobweb model, which seeks to explain price fluctuations in a given market.
Breaking down artificial neural networks
Figure 12-1 is a simplified depiction of a biological neural network (BNN) that you may find in the central nervous system. Neurotransmitters bind to specific sites of the dendrite, causing voltage changes in the cell. Those voltage changes travel through the cell body, down the axon, to the synaptic terminal. The synaptic terminal releases neurotransmitters that bind to the dendrites of nearby interneurons. These networks learn by potentiating connections between neurons.

© John Wiley & Sons, Inc.
FIGURE 12-1: An interneuron in the central nervous system.
Artificial neural networks (ANNs) are mathematical models of BNNs and are core to many machine learning applications (we discuss machine learning later in this chapter). The way that ANNs replicate the behaviors seen in BNNs has long been a source of enthusiasm and speculation about AI’s potential.
Figure 12-2 shows a type of ANN known as a feedforward multilayer perceptron. The ANN receives data from the world via the input layer (the X1, X2 … Xn nodes), integrates the inputs at the hidden layer (H1, H2 … Hk nodes), and forwards the final results to the output layer (Y1, Y2 … Ym nodes). The ANN learns by changing numerical values of weights represented by the lines between nodes of the layers. This class of feedforward multilayer perceptron is among the simplest ANN and forms the basis of many other ANNs such as deep-learning architectures that have complex (“deep”) hidden layers.

© John Wiley & Sons, Inc.
FIGURE 12-2: A representation of an artificial neural network (ANN) that is a feedforward multilayer perceptron. Such a system is inspired by a biological neural network (BNN).
ANNs represent a connectionist approach to AI — in other words, it’s all about the connections between nodes. There are also population approaches. For example, ant colony algorithms attempt to mimic how ants learn through decentralized control to find food and other resources. Genetic algorithms use natural selection techniques to learn through survival of the fittest. There are also Monte Carlo approaches, Bayesian approaches, decision trees, and so on, each of which learns through its own unique method. AI has many machine learning techniques, and the challenge is knowing what kinds of problems are best suited to which approaches.
Exploring how AI fits into FinTech
AI excels at problems in which it’s otherwise infeasible to enumerate all possible inputs and outputs. A lot of what goes on in banking is fixed and quantifiable, so it doesn’t benefit from AI. For instance, you wouldn’t use AI for credit card validation because it’s just a simple database lookup. The bank knows all the credit cards and numbers it has on file. The application could just look up a given credit card in the database to determine its status and credit availability.
However, AI is very helpful when the task is more subtle. For example, consider credit analytics. Suppose that the task is to monitor credit card usage for each account, looking for unusual patterns of purchases that may indicate the card has been stolen. This is a great job for AI. To make such determinations, AI considers the patterns — that is, transactions, establishments, times of year, locations, amounts, and so on. If it notices something anomalous, it queries the customer and then learns based on the customer’s approval or rejection of the transaction. Over time, the ANN (see the preceding section) becomes very good at monitoring the usage of each account and alerting customer service representatives of anything out of the ordinary for a particular customer.
Leveraging Machine Learning
Machine learning is a subdiscipline of AI. The three general classes of machine learning are supervised learning, reinforcement learning, and unsupervised learning. Each type is a specialized approach with different applications. Any one of these machine learning algorithms can easily fit into FinTech. Figure 12-3 summarizes them.
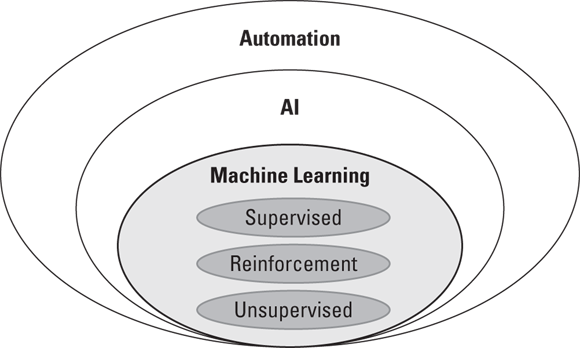
© John Wiley & Sons, Inc.
FIGURE 12-3: Three classes of machine learning.
Supervised learning
In supervised learning, developers train the AI to make an association between a label and a corresponding correct answer. The training in general can be slow, and the goal is for the AI to learn with an acceptable error tolerance. That tolerance isn’t usually 0 percent because that’s not usually mathematically feasible. A 0 percent error tolerance may even be undesirable because developers want the AI to make generalizations for labels it hasn’t been trained on instead of overfitting the data.
Any of the machine learning algorithms we mention earlier can easily fit into FinTech. Here’s an example of how supervised learning may fit. The idea for the capital markets may be to use a data-driven, model-free approach to pricing derivatives rather than a model-based approach. A model may be very specific mathematically but inaccurately measured against quoted prices. Often the model makes simplifying assumptions that leave out some unobserved or unobservable variables. An ANN could be trained using supervised learning to price derivatives based on observed quotes of how markets behave in fact rather than how they are supposed to behave in theory.
Reinforcement learning
In reinforcement learning, developers don’t have labels and answers but rather an objective — that is, they train the AI to maximize some reward. In an ideal situation, the AI learns increasingly more correct responses on the basis of optimizing the signal. The training reinforces learning by more or less positive feedback. For instance, we could train an AI to optimize data processing while pricing a set of portfolios to minimize the standard deviation of runtime. The input provided would be the number of instruments in the portfolio and tenors of the instruments in the portfolio.
Unsupervised learning
Unsupervised learning has no labels, correct answers, or even objectives per se. Instead, the AI discovers extant patterns and acquires this new knowledge on its own. For instance, streaming music services initially don’t know how to serve songs to new listeners. However, through their choices, listeners provide hints or clues about their preferences, and over time the AI builds up a database of what the listener may like to hear. It may recognize that in the morning, a listener often chooses upbeat music from the ’80s and in the evening, contemporary downtempo. The AI could also play musically related songs (for example, cool jazz) based on patterns from listeners in the same age group and zip code or with similar buying habits it learns through third-party data sources.
Making the Most of Chat Bots
FinTech firms mostly employ long-established, simple machine learning algorithms rather than complex solutions. These could be as basic as regression analysis, cluster analysis, and time-series forecasting. However, in 1950, Alan Turing, a British mathematician, proposed the idea of sophisticated software that engages users through interactive conversation. The “Turing test” asks users whether they’re conversing with a real person or a machine. If the user can’t distinguish the difference, the bot passes the test for being “intelligent.”
Some software embodiments of the Turing test are websites that “chat” with users for customer support. Some client sites provide Level 1 support via a free chat bot service, reserving premium service through a human agent for customers with a paid subscription. Whether the chat bot support option is convincing and worthwhile, free or otherwise, is beyond the scope of this chapter. Suffice it to say that virtual assistants represent the state of the art in chat bot natural language processing (NLP).
Chat bots hold promise to readily dovetail with FinTech. For instance, Payjo provides AI-powered “conversational banking” through messaging (for example, text messaging and Facebook Messenger) to enhance the digital banking experience. Chat bots offer reduced operational and support costs for the enterprise by answering basic questions, hassle-free operations, cross-selling, and real-time, natural communication with customers. These bots also hold potential to widen the customer base by providing differently abled consumers with speech transcription and synthesis services. A well-designed chat bot is channel agnostic, can seamlessly interpret in different languages, is available 24/7, is instantaneously cognizant of customer preferences, and learns continuously from customer feedback.
 For the latest information about chat bots, check out Chat Bots Magazine (
For the latest information about chat bots, check out Chat Bots Magazine (https://chatbotsmagazine.com).
Checking Out Alternative Data Sources
For much of the modern history of AI, data sets were varied but mostly small in volume and complexity. For instance, the iris flower data set, which is a benchmark for machine learning often taught to students, has only 150 records each with just five features: the sepal length and width, the petal length and width, and the flower species classification. Data of this nature could be handled on single-code machines.
With the advent of big data, however, new approaches have become necessary that often require parallel and distributed systems (such as Hadoop) to process the data. Here are just a few examples of big data sets:
- The Landsat-8 satellite photographs the Earth’s complete land surface every five days, generating high-resolution optical data that is freely available online.
- There are IRS 990 records that include 3 million files and hundreds of features on nonprofit organizations’ finances.
- In 2019, there were more than 200 million active websites in the world, and an estimated 200 billion tweets were active and all freely available online.
 Data Science Central maintains a list of the top 20 free resources for big data that include data.gov, the United States Census Bureau, the European Union Open Data Portal, data.gov.uk, Amazon Web Services public data, Facebook Graph, Google Trends, and so forth. For FinTech, there is Google Finance, Financial Times Market Data, the UN Comtrade Database containing international trade statistics, World Bank Open Data, IMF Data — the list is long.
Data Science Central maintains a list of the top 20 free resources for big data that include data.gov, the United States Census Bureau, the European Union Open Data Portal, data.gov.uk, Amazon Web Services public data, Facebook Graph, Google Trends, and so forth. For FinTech, there is Google Finance, Financial Times Market Data, the UN Comtrade Database containing international trade statistics, World Bank Open Data, IMF Data — the list is long.
According to researchers, one of the major obstacles to AI for FinTech companies is access to data. However, the central issue goes beyond mere quantity. For instance, some data sets contain missing, invalid, and/or hacked values. What good is AI if it learns from the wrong data? There’s also provenance, trust, rights, privacy, and so on — all that may need to be assured prior to analysis for AI purposes.
Given that all these issues have been addressed, AI algorithms still can’t accept prices, zip codes, pixels, audio samples, and so on directly from the real world. Data must first be normalized or encoded on input and denormalized or decoded on output for human interpretation. Finally, if the AI is to be productionized, resources are needed to process the data on a regular basis. Whether through dedicated infrastructure or cloud services, this kind of operationalization isn’t a trivial undertaking and often requires systems and process engineers.
In the following sections, we talk about alternative data sources: companies and devices used, its role in the financial industry, and its sourcing, compliance, and regulation.
Companies and devices involved in alternative data
Many big data resources are free, but the quality and/or formats aren’t always assured or structured for ready processing. As such, hundreds of companies are lining up to provide fee-based data and/or data services, including Google, Amazon, IBM, Microsoft, Oracle, Teradata, and SAS Institute. These companies all employ AI to parse and organize the raw data into useful information.
AI techniques excel at identifying patterns and distilling insights from large, complex, interlinked data sets. The ubiquity of devices, including smartphones, cameras, GPS devices, and other Internet of Things (IOT) devices, has led to a huge increase in the amount and range of alternative data sets. Some examples include browsing activity logs, credit card transaction data, social media posts, photos, videos, point-of-sale system data, weather data, satellite images, reviews, online comments, and local news.
Using AI for image and video recognition, natural language processing, machine learning algorithms, and the power of cloud computing, many of these data sets can now be “mined” efficiently. The insights from these algorithms feed expert systems that aid decision-making.
Marketing promotions in retail and credit cards have been using such data sets for many years. Famously, a story circulated that Target was able to predict pregnancy before anyone else by examining customer transaction data sets. Although the story itself is probably apocryphal, alternative data sets and AI have been indispensable for the retail marketing business processes.
Alternative data in the financial industry
In the financial industry, alternative data sets have helped companies prepare precise, targeted promotions or prequalify individuals based on their credit history as well as alternative data sets. For example, bringing together detailed transaction history with demographic information as well as social media activity may help predict someone’s need for an investment product or a higher credit line. In the wealth management industry, robo-advisors that rely on a broad array of available data sets are helping bring personalized, data-driven investment advice at a lower cost than traditional wealth management models.
While trading models have historically relied on traditional financial data, such as stock prices and volatilities, we are now seeing increasing use of alternative data sets such as social media or news for sentiment analysis that helps generate investment alpha (return on investment in comparison to a market index). In high-frequency trading, or any trading activity involving high volumes, quants are now purchasing and sourcing alternative data sets that may aid decision-making. In an era where markets are driven heavily by policy, it can be a huge advantage to predict policy based on unofficial farm-roll statistics from transactions data or real-estate data from web platforms like Zillow before the official statistics are published.
Sourcing, compliance, and regulation
Historically, alternative data has been collected directly from the original source, such as by accessing website logs or digitally scraping news from news websites. However, alternative data sets are now available from specialist data vendors as well as many well-known data vendors such as Quandl or Lexis Nexis.
In the financial industry, it’s especially important to keep all relevant compliance standards in mind when using alternative data sets. While compliance and regulatory standards around alternative data sets are still evolving, some regulations such as the General Data Protection Regulation (GDPR) in Europe set clear restrictions around the capture, retention, and transfer of personal data. In fact, most jurisdictions have rules in place or privacy laws that cover the capture, transmission, and use of personally identifiable information (PII). We introduce the role of regulation in FinTech in Chapter 3.
Also, care must be taken to avoid the use of certain types of data that can lead to biases in the model and create the potential for ethical and legal challenges. An example of this type of issue is the use of ethnicity or religion for credit scoring during card or loan approval, which would be a clear violation of laws.