In this chapter, we look back at the entire history of C#, leading up to the latest version. We will not be able to cover everything, but we will touch on the major features, especially the ones which are historically relevant. Each release brought unique features that would serve as the building blocks for innovations in versions yet to come.
When C# was introduced, Microsoft wanted to take the best features of many other languages and runtimes. It was an object oriented language, with a runtime that actively manages memory for you. Some of the features of this language (and framework) are:
- Object oriented
- Managed memory
- Rich base class library
- Common Language Runtime
- Type safety
Regardless of your technology background, there was something in C# that you could relate to.
It is impossible to talk about C#, without first talking about the runtime, called the Common Language Runtime (CLR). One of the major underpinnings of the CLR was the ability to interoperate with multiple languages, which meant that you would be able to write your program in a number of different languages, and it would run on the same runtime. This interoperability was accomplished by agreeing to a common set of data types, referred to as the common type system.
Before the .NET Framework, there was really no clear mechanism for different languages to talk to each other. A string in one environment may not match the concept of a string in another language and would they be null terminated? Are they encoded in ASCII? How is that number represented? There was simply no way to know, because each language did its own thing. Of course people tried to come up with solutions to this problem.
In the Windows world, the most well-known solution was to use the Component Object Model (COM), which used a type library to describe the types contained therein. By exporting this type library, a program could talk to other processes that may or may not have been written using another technology, because you were sharing details about how to communicate. However this was not without complexity, as anyone who wrote COM libraries using Visual Basic 6 could tell you. Not only was the process generally somewhat opaque because the tool abstracted out the underlying technology, but deployment was a nightmare. There was even a well-known phrase for working with it, DLL Hell.
The .NET Framework was, in part, a response to this problem. It introduces the common type system into the picture, which are rules that every language running on the CLR needs to adhere to, including common data types such as strings and numeric types, the way object inheritance works, and type visibility.
For maximum flexibility, instead of compiling directly to native binary code, an intermediate representation of program code is used as the actual binary image, which is distributed and executed, called MSIL . This MSIL is then compiled the first time you run the program, so that optimizations can be put in place for the specific processor architecture that the program is being run on (the Just-In-Time (JIT) compiler). This means that a program that runs on the server and on a desktop could have different performance characteristics based on the hardware. In the past, you would have had to compile two different versions.
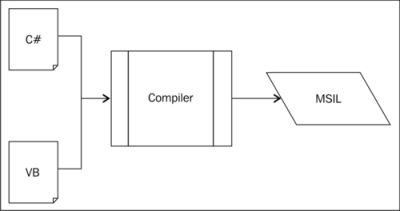
Another benefit of inherent, multilingual support, is that it served as a migration strategy. A number of different languages came out at the same time as C#. Companies that had an existing codebase in various languages could easily convert their program to a .NET friendly version, which was CLR compatible, and subsequently use it from other .NET languages such as C#. Some of the languages include the following:
While a number of these languages shipped, and were pitched as fully supported, these days the only ones that really remain of the original languages that shipped are VB.Net and C#, and to a lesser degree, C++/CLI. Many new languages such as F#, IronPython, and IronRuby have sprung up on the CLR over the years, and they remain active in development, with vibrant communities.
The Common Language Runtime provides a garbage collector , which means that memory will be collected automatically when an object is no longer referenced by other objects. This was not a new concept of course; many languages such as JavaScript and Visual Basic support garbage collection. Unmanaged languages, on the other hand, let you manually allocate memory on the heap if you so choose. And although this ability gives you way more power when it comes to the kinds of low-level solutions you can implement, it also gives you more opportunities to make mistakes.
The following are the two kinds of data types that the CLR allows for:
Every primitive data type in C#, such as int and float, is struct, while every class is a reference type. There are some semantics around how these types are allocated internally (stack versus heap), but for day-to-day use those differences are usually not important.
You can of course create your own custom types of both kinds. For example, the following is a simple value type:
public struct Person
{
public int Age;
public string Name;
}By changing a single keyword, you can change this object to a reference type as follows:
public class Person
{
public int Age;
public string Name;
}There are two major differences between struct instances and class instances. Firstly, a struct instance cannot inherit, or be inherited from. The class instances, however, are the primary vehicles for creating object oriented hierarchies.
Secondly, class instances participate in the garbage collection process, while struct instances do not, at least not directly. Many discussions on the Internet tend to generalize the memory allocation strategy of value types as being allocated on the stack, while reference types are allocated on the heap (see the following diagram), but that is not the whole story:
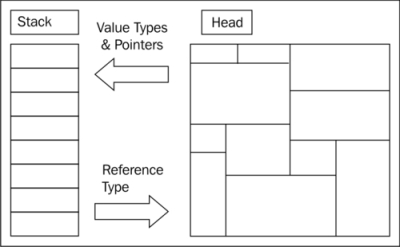
There is generally some truth to this, because when you instantiate class in a method, it will always go on the heap, while creating a value type such as an int instance will go on the stack. But if the value type is wrapped in a reference type, for example, when the value type is a field in a class instance, then it will be allocated on the heap along with the rest of the class data.
The name C# is a cheeky reference to the C language, just as C++ was C (plus some stuff), C# too is largely similar in syntax to C and C++, though with some obvious changes. Unlike C, C# is an object oriented language, but with a few interesting features that make it easier and more efficient to write than other object oriented languages.
One example of this is the property getters and setters. In other languages, if you want to control how you expose access and modifications to the data of a class instance, you would have to make the field private so an outsider could not change it directly. Then you would make two methods, one prefixed with get to retrieve the value, and one prefixed with set to the value. In C#, the compiler takes care of generating those method pairs for you. Look at the following code:
private int _value;
public int Value
{
get { return _value; }
set { _value = value; }
}Another interesting innovation is how C# provides first class event support. In other languages such as Java, they approximated events by, for example, having a method called setOnClickListener(OnClickListener listener)
. To use it, you have to define a new class that implements the OnClickListener interface and pass it in. This technique definitely works, but can be kind of verbose. With C#, you can define what is called a delegate
to represent a method as a proper, self-contained object as follows:
public delegate void MyClickDelegate(string value);
This delegate can then be used as an event on a class as follows:
public class MyClass
{
public event MyClickDelegate OnClick;
}To register for notification when the event is raised, you can just create the delegate and use the += syntax to add it to the delegate list as follows:
public void Initialize()
{
MyClass obj = new MyClass();
obj.OnClick += new MyClickDelegate(obj_OnClick);
}
void obj_OnClick(string value)
{
// react to the event
}The language will automatically add the delegate to a list of delegates, which will be notified whenever the event is raised. In Java, that kind of behavior would have to be implemented manually.
There were many other interesting syntactic features when C# was launched, such as the way exceptions worked, the using statement, and others. But in the interest of brevity, let's move on.
By default, C# comes with a rich and vast framework called the Base Class Library (BCL). The BCL provides a wide array of functionality as shown in the next diagram:
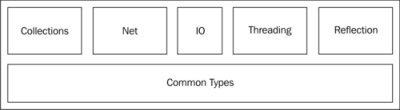
The diagram shows a few of the namespaces that are included in the base class library (emphasis on a few). While there are a large number of other namespaces, these are a few of the most important ones, which provide the infrastructure for many of the features and libraries that have been released by Microsoft and third parties.
One of the data structure types you discover when learning how to program is the one that deals with collection of information. Typically, you learn to write most of the programs and algorithms using arrays. With an array though, you have to know the size of the collection ahead of time. The System.Collections namespace comes with a set of collection of data structures that make it easy to handle an unknown amount of data.
In the very first program I ever wrote (described briefly in the previous chapter), I used an array that was pre-allocated. To keep things simple, the array was allocated with an arbitrarily large number of elements so that I would not run out of spaces in the array. Of course, that would never work in a non-trivial program written professionally because you will either run out of space if you encounter a larger than expected set of data, or it will be wasteful of memory. Here, we can use one of the most basic collection types, the ArrayList collection, to overcome that problem, as follows:
// first, collect the paycheck amount
Console.WriteLine("How much were you paid? ");
string input = Console.ReadLine();
float paycheckAmount = float.Parse(input);
// now, collect all of the bills
Console.WriteLine("What bills do you have to pay? ");
ArrayList bills = new ArrayList();
input = Console.ReadLine();
while (input != "")
{
float billAmount = float.Parse(input);
bills.Add(billAmount);
input = Console.ReadLine();
}
// finally, summ the bills and do the final output
float totalBillAmount = 0;
for (int i = 0; i < bills.Count; i++)
{
float billAmount = (float)bills[i];
totalBillAmount += billAmount;
}
if (paycheckAmount > totalBillAmount)
{
Console.WriteLine("You will have {0:c} left over after paying bills", paycheckAmount - totalBillAmount);
}
else if (paycheckAmount < totalBillAmount)
{
Console.WriteLine("Not enough money, you need to find an extra {0:c}", totalBillAmount - paycheckAmount);
}
else
{
Console.WriteLine("Just enough to cover bills");
}As you can see, an instance of the ArrayList collection was created, but no size was specified. This is because collection types manage their sizes internally. This abstraction relieves you of the size responsibility so you can worry about bigger things.
Some of the other collection types that are available are as follows:
Looking at the concrete collection, classes do not really tell the whole story though. If you follow the inheritance chain, you will notice that every collection implements an interface called IEnumerable. This will come to be one of the most important interfaces in the whole language so getting familiar with it early on is important.
IEnumerable, and the sister class, IEnumerator
, abstract the concept of enumeration over a collection of items. You will always see these interfaces used in tandem, and they are very simple. You can see this as follows:
namespace System.Collections
{
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
public interface IEnumerator
{
object Current { get; }
bool MoveNext();
void Reset();
}
}At first glance, you may wonder why collections implement IEnumerable, which has a single method that returns an IEnumerator, rather than just implementing IEnumerator directly. The enumerator is responsible for enumerating through a collection. But there is a good reason for this. If the collection itself was the enumerator, then you would not be able to iterate over the same collection concurrently. So each call to GetEnumerator()
will generally return a separate enumerator, though that is by no means a requirement.
Although the interface is very simple, it turns out that having this abstraction is very powerful. C# implements a nice shorthand syntax for iterating over a collection without having to do the regular for loop using an index variable that you have to pass in. This is explained in the following code:
int[] numbers = new int[3];
numbers[0] = 1;
numbers[1] = 2;
numbers[2] = 3;
foreach (int number in numbers)
{
Console.WriteLine(number);
}The foreach syntax works because it is shorthand for the code the compiler will actually generate. It will generate code to interact with the enumerable behind the scenes. So the loop in the previous example will look like the compiled MSIL, as follows:
IEnumerator enumerator = numbers.GetEnumerator();
while (enumerator.MoveNext())
{
int number = (int)enumerator.Current;
Console.WriteLine(number);
}Once again, we have an example of the C# compiler generating code, that is different from what you have actually written. This will be the key in the evolution of C# to make the common patterns of code that you write easier to express, allowing you to be more efficient and productive.
To some developers, C# was a cheap imitation of Java when it first came out. But to developers like me, it was a breath of fresh air, offering performance improvements over interpreted languages such as VBScript, extra safety and simplicity from languages such as C++, and more low level power than languages such as JavaScript.