Data Come First
Before we feed data to our ML system, let’s get up close and personal with those data. This section tells you all you need to know about MNIST.
Getting to Know MNIST
MNIST is a collection of labeled images that’s been assembled specifically for supervised learning. Its name stands for “Modified NIST,” because it’s a remix of earlier data from the National Institute of Standards and Technology. MNIST contains images of handwritten digits, labeled with their numerical values. Here are a few random images, capped by their labels:

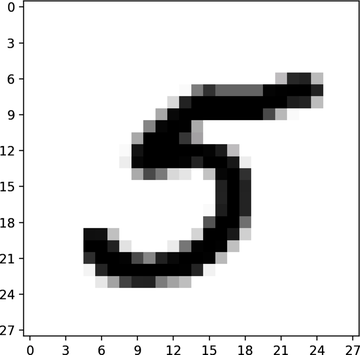
Digits are made up of 28 by 28 grayscale pixels, each represented by one byte. In MNIST’s grayscale, 0 stands for “perfect background white,” and 255 stands for “perfect foreground black.” Here’s one digit close up:
MNIST isn’t huge by modern ML standards, but it isn’t tiny either. It contains 70,000 examples, neatly partitioned into 7,000 examples for each digit from 0 to 9. Digits have been collected from the wild, so they’re quite diverse, as this random assortment of 5s proves.
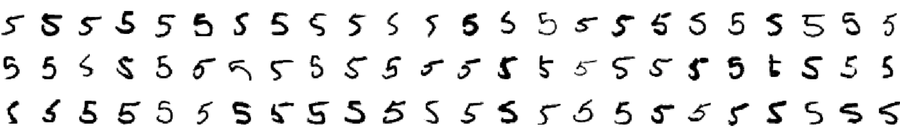
Chalk it up to my age, but I have trouble reading some of these 5s myself. Some look like barely readeable squiggles. If we can write a computer program that recognizes these digits, then we definitely win bragging rights.
Datasets such as MNIST are a godsend to the machine learning community. As cool as ML is, it involves a lot of grindwork to collect, label, clean, and pre-process data. The maintainers of MNIST did that work for us. They collected the images, labeled them, scaled them to the same size, rotated them, centered them, and converted them to the same scale of grays. You can take these digits and feed them straight to a learning program.
MNIST stores images and labels in separate files. There are plenty of libraries that read these data, but the format is simple enough that it makes sense to code our own reader. We’ll do that in a few pages.
By the way, you don’t have to download the MNIST files: you’ll find them among the book’s source code, in the data directory. Take a peek, and you’ll see that MNIST is made up of four files. Two of them contain 60,000 images and their matching labels, respectively. The other two files contain the remaining 10,000 images and labels that have been reserved for testing.
You might wonder why we don’t use the same images and labels for both training and testing. The answer to that question requires a short aside.
Training vs. Testing
Consider how we have tested our learning programs so far. First, we trained them on labeled examples. Then we used those same examples to calculate an array of predictions, and we compared the predictions to the ground truth. The closer the two arrays, the better the forecast. That approach served us well as we learned the basics, but it would fail in a real-life project. Here is why.
To make my point, let me come up with an extreme example. Imagine that you’re at the pub, chattering about MNIST with a friend. After a few beers, your friend proposes a bet: she will code a system that learns MNIST images in a single iteration of training, and then comes up with 100% accurate classifications. How ludicrous! That sounds like an easy win, but your cunning friend can beat you out in this bet easily. Can you imagine how?
Your friend writes a train function that does nothing, except for storing training examples in a dictionary—a data structure that matches keys to values. (Depending on your coding background, you might call it a “map,” a “hashtable,” or some other similar name.) In this dictionary, images are keys, and labels are values. Later on, when you ask it to classify an image, the program just looks up that image in the dictionary and returns the matching label. Hey presto, perfectly accurate forecasts in one iteration of training—and without even bothering to implement a machine learning algorithm!
As you pay that beer, you’d be right to grumble that your friend is cheating. Her system didn’t really learn—it just memorized the images and their labels. Confronted with an image that it hasn’t seen before, such a system would respond with an awkward silence. Unlike a proper learning system, it wouldn’t be able to generalize its knowledge to new data.
Here’s a twist: even if nobody is looking to cheat, many ML systems have a built-in tendency to memorize training data. This is a phenomenon known as overfitting. You can see that a system is overfitting when it performs better on familiar data than it performs on new data. Such a system could be very accurate at classifying images that it’s already seen during training, and then disappoint you when confronted with unfamiliar images.
We’ll talk a lot about overfitting in the rest of this book, and we’ll even explore a few techniques to reduce its impact. For now, a simple recommendation: never test a system with the same data that you used to train it. Otherwise, you might get an unfairly optimistic result, because of overfitting. Before you train the system, set aside a few of your examples for testing, and don’t touch them until the training is done.
Now we know how MNIST is organized, and why it’s split into separate training and testing set. That’s all the knowledge we need. Let’s write code that loads MNIST data, and massages those data into a suitable format for our learning program.