Assembling Perceptrons
The perceptron is a great building block for more complex systems. In a sense, we have been assembling multiple perceptrons since the very beginning. Let’s see how.
During training, our system reads all the examples together, rather than one example at a time. In a way, that operation is like “stacking” multiple perceptrons, sending one example to each perceptron, and then collecting all the outputs into a matrix, like this:
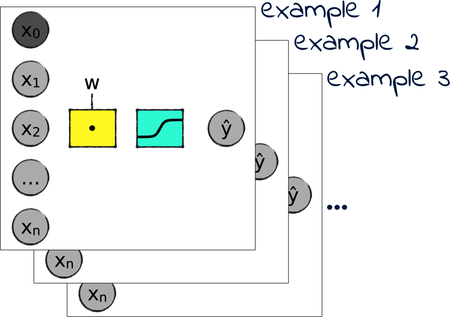
In Chapter 7, The Final Challenge, we also assembled perceptrons in a different way. A perceptron is a binary classifier—it classifies things as either 0 or 1. To classify ten digits, we used ten matrix columns, each dedicated to classifying one digit against all the others. Conceptually, that’s like using ten perceptrons in parallel as shown here:
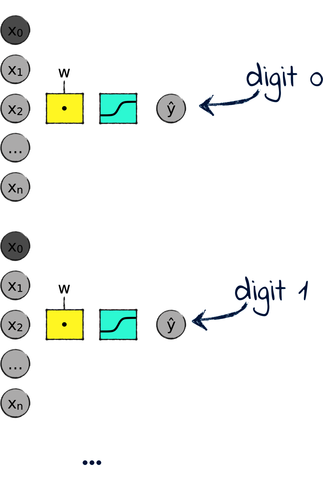
Each parallelized perceptron classifies one class, from 0 to 9. During classification, we pick the class that outputs the most confident prediction.
So we stacked perceptrons, and we parallelized perceptrons. In both cases, we did it with matrix operations, which was easier and faster than running the same classifier multiple times—once per example, and then once per class.
There is one more way to combine perceptrons: serialize them, using the output of one perceptron as input to the next. The result is called a multilayer perceptron. We didn’t use multilayer perceptrons yet, but we will… a lot. For now, just keep this idea at the back of your mind.