Where Now?
You’re reaching the end of this book, but I bet you’re up for more. You have no shortage of things to learn. In fact, even if you track the field closely, it’s hard to keep up with the barrage of exciting new ideas and techniques across the many areas of deep learning.
With so many possible paths to mastery, you might wonder which one to take. The next sections describe a few of those paths, including some topics I didn’t even mention so far. See if any of these pique your interest.
The Path of Vision
Your first option is to stay on the trail that we walked in the previous 270 or so pages: computer vision and CNNs. I picked image recognition as the storyline for this book because it makes for nice concrete examples—but even then, we only scratched the surface.
There is a lot more to do and learn in computer vision beyond recognizing images. One prominent subfield of computer vision these days is object detection. While image recognition answers questions like: “Does this picture represent a platypus?”, object detection answers questions like: “Where are the platypuses in this picture?” As you can imagine, that’s a crucial technology for self-driving cars, especially Australian ones. (As this book comes to a close, I admit the quality of my jokes is degrading.)
Computer vision isn’t just about static images—it’s also about video. There are many fascinating use cases for computer vision applied to video, including pose estimation, which detects the position of a human figure, and motion estimation, which tracks the movement of objects.
If you want to delve deeper into computer vision, you should learn more about CNNs. You should also look up a technique called transfer learning, which allows you to reuse a pretrained model on a different dataset. Transfer learning allows you to download a model that might have been trained on a large cluster of GPUs, and complete the training on your home machine. That technique can be useful in all areas of supervised learning, but it’s most commonly used with CNNs.
The Path of Language
Another area of ML that’s in full bloom these days is the processing of natural language, such as speech or text. Just like computer vision has been upheaved by CNNs, natural language processing is the domain of recurrent neural networks—or RNNs for short.
Language works like a sequence of information, where the meaning of a word depends on the words before and after it. Fully connected networks don’t jive well with this kind of data because they don’t have memory. A training network takes a batch of independent examples, tweaks its weights to approximate them, and then all but forgets about them. With no memory of what’s come before, a fully connected network gets stumped in the middle of a sentence, staring at a word out of context, without hope of grokking its meaning.
By contrast, recurrent neural networks have a form of memory. While the information in a regular network only moves forward, the information in RNNs can loop back into the same layer or an earlier one, as shown in the diagram.
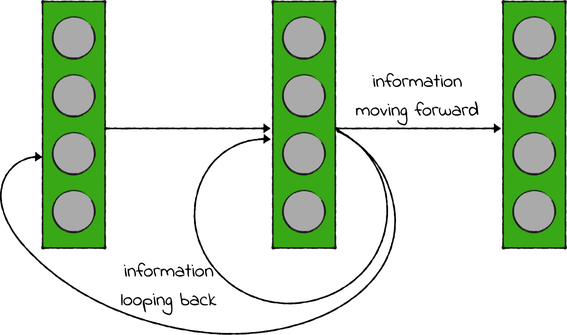
Because of those loops, an RNN can process sequence-like data. It understands a piece of information based on the information that came before it—like your brain is doing right now as you read these sentences.
Loops make a neural network more complicated. In a sense, they also make it deeper. Think about it: if a layer feeds back into itself from one iteration to the other, then you can imagine unrolling it into a sequence of regular layers, each of which represents one iteration of the original layer:
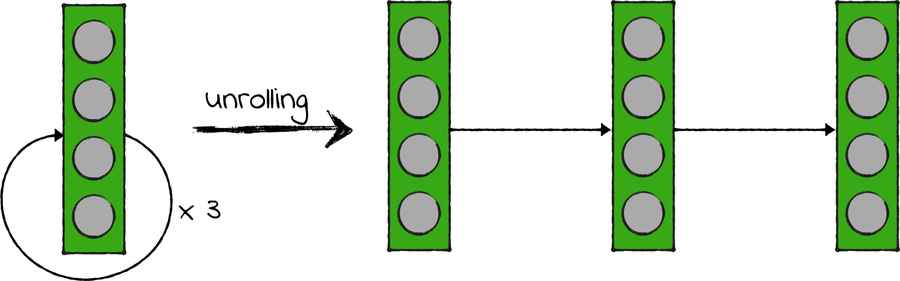
For that reason, even pretty shallow RNNs suffer from the same problems as deeper networks, like the vanishing gradient. Only in the late 1990s did researchers find a reliable a way to ameliorate those problems when they invented the weirdly named long short-term memory architecture. That architecture is the basis of today’s surprisingly accurate text processing systems, such as Google Translate.
So, in general, you should focus more on CNNs if you’re attracted by computer vision, and RNNs if you’re fascinated by natural language processing. Now let’s look at another option that’s a bit more far out.
The Path of Image Generation
Image generation is all about synthesizing images, either by modifying existing ones, or by creating new ones from scratch. To me, the most amazing invention in this field are generative adversarial networks, or GANs, invented by a young researcher called Ian Goodfellow in 2014. GANs are the technology behind those uncanny fake pictures and videos that you might have seen on the Internet.
Here is a concrete example to help you understand GANs. To experiment with this concept, I started by selecting a bunch of horse pictures from the CIFAR-10 dataset. Here are a few of those:

Imagine building a CNN to tell these horse pictures from other pictures that don’t contain a horse. Let’s call this network the discriminator, as shown in this diagram:

Now imagine a second, somewhat unusual, neural network. This network takes a random sequence of bytes as input, and passes it through its parameterized model to turn it into an image. It might use an architecture similar to a regular CNN, only tweaked to generate images as output instead of taking them as input, as shown in the next diagram:

This second network is called the generator, even though all it generates before it’s trained is random pixel jam.
Now comes the brilliant idea behind GANs. Connect the output of the generator to the input of the discriminator, and train the two networks in tandem as shown in the diagram.
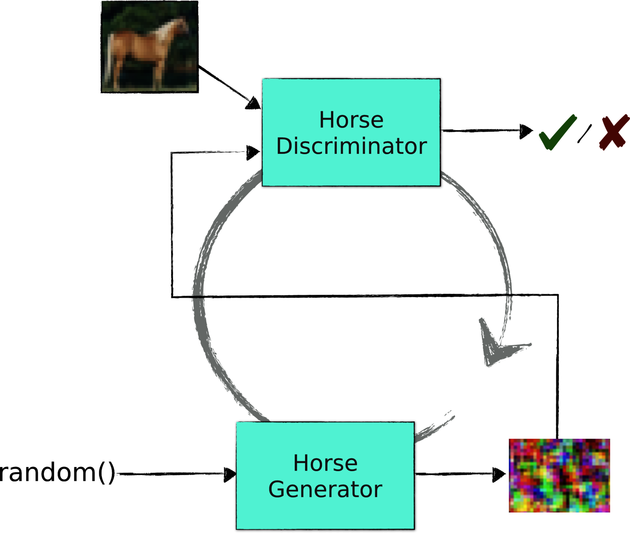
The trick of this architecture is that the loss functions of the two networks are carefully chosen to pit them against one another:
-
The discriminator is receiving a random mix of horse pictures and pictures from the generator. It gets a lower loss when it correctly tells apart the horses from the generated images.
-
On its part, the generator gets rewarded when the discriminator gets it wrong. Its loss is higher if the discriminator identifies its output as generated, and lower if the discriminator confuses it for a horse.
Do you see where this is going? The whole systems works like a competition between an expert that identifies fake images, and a forger that attempts to counterfeit them. As a result, the discriminator and the generator improve together as you train them.
I assembled such a contraption myself. Following are a few randomly chosen images from the generator, taken every 50 iterations of training:
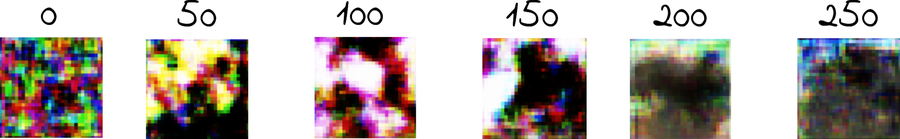
In the beginning, the generator outputs meaningless noise. After 200 iterations, it already seems to output images that are mostly green at the bottom, mostly blue at the top, and contain vague brownish shape. Those are common traits of horse pictures, which usually involve blue skies and grassy fields. At the same time, the discriminator is improving at weeding out synthetic pictures.
After a few hours and about one million iterations of training, the generator has become pretty darn good:

Just to be clear, none of these pictures are a straight copy of a CIFAR horse. Indeed, the generator has never ever seen a horse picture—it just learned what a horse looks like by learning how to cheat the discriminator. As a result, it forged these weirdly crooked, but undisputedly horse-like creatures.
These images come from my humble laptop and a pair of sloppily hacked neural networks. If you want to see the state of the art, the Internet has more generated images than you can shake a stick at. The site known as “This person does not exist,” for one, generates jaw-droppingly realistic human faces.[36] GANs also power Google’s famous Deep Dream image generator.[37]
That’s it about GANs. Before leaving the topic of image generation, I have to at least mention style transfer—another brilliant idea that became popular in the last few years. You’ve seen it before: it’s the technique that redraws photos in the style of pencil drawings, watercolor, or famous painters. Style transfer uses an algorithm similar to neural networks, but instead of optimizing the network’s weights, it works directly on an image’s pixels. Here’s my portrait as painted by Edvard Munch:

I don’t really have that red face and thick mustache, but this picture is still an artistic improvement over my original muzzle. Once again, the Internet has more examples, tutorials, and style transfer web apps than you probably need. If you’re willing to take the path of image generation, then you’re well covered.
The Broad Path
I strove to make this book feel like a straight, narrow road through the vast landscape of ML. We focused on supervised learning, and specifically on supervised learning with neural networks. If you’re a “big picture” kind of person, however, you might aim for broader knowledge, as opposed to deeper knowledge. In that case, you might want to look at other machine learning flavors and techniques off the path of this book.
For one, the field of reinforcement learning deserves more attention than I could grant it in these pages. Its recent successes compete with those of supervised learning. To mention one story that hit the front pages: AlphaGo, the program that made a sensation by beating a human at the ancient game of Go, uses reinforcement learning.[38]
Unsupervised learning is ML applied to unlabeled data, and it’s also a hot topic these days. Among other things, people are coming up with clever ways to use neural networks to compress or cluster data.
Another exciting branch of ML is called semi-supervised learning, and it uses a mixture of labeled and unlabeled data to train a machine learning system. It’s often easier to collect large amounts of unlabeled data than labeled data, and semi-supervised learning can be a brilliant way to use all those extra data.
Even if you stick to supervised learning, however, you have plenty to look at, especially if you like computer science or statistics. While this book focused on neural networks, there are other algorithms worth learning, and some of them still work better than neural networks in specific circumstances. For a couple of examples, take a look at support vector machines and random forests.
The Hands-On Path
Last but not least, here is one final path into the world of machine learning, and the one that I find most exciting as a developer. Instead of cherry-picking a subfield of ML up front, keep your options open, and join a competition on Kaggle—a popular platform that organizes ML challenges.[39]
Kaggle competitions are a great way to dip your toes into concrete problems. Some of those competitions are high-level business, targeted to academic teams armed with state of the art techniques. Others, clearly marked for beginners, are ideal introductions to pragmatic ML.
As you expect, the realities of a project tend to be twistier and messier than the streamlined story in this book. As you go through your first competition, you might feel like an absolute beginner again. You might need to prepare your data in ways that you didn’t expect. Instead of being either numerical or categorical, your input variables might be a mix of both. You’ll have to decide how to attack each problem on your own. You might need to study new techniques, and even when you don’t, those first lines of code may give you the dreaded blank page effect.
Don’t let those early difficulties frustrate you. Deep learning is huge—as vast a topic as programming—but by going through this book, you laid a foundation that you can now build upon. It might take you time to find your bearings on a real project, but keep going. You’ll soon feel comfortable dealing with a variety of data, architectures, and libraries.