


1 Introduction
Biomedical image analysis has been a natural area of application for deep convolutional neural networks (CNNs). Several uses of CNN-related topologies have been proposed in radiology [1, 2], histopathology [3–5] and microscopy [6–8] (for a review, see [9]). High-content screening (HCS) [10–15], the use of microscopy at scale in cellular experiments, in particular, has seen progress in applying CNN-based analysis [6, 7, 16–18]. Instead of the conventional analysis approaches where cellular objects are first segmented and then pre-defined features representing their phenotypes (characteristic image content corresponding to the underlying experimental conditions) are measured, deep learning approaches offer the promise to capture relevant features and phenotypes without a priori knowledge or significant manual parameter tuning. In deep CNNs, the deeper layers pick up high-levels of organization based on the input of many features captured in previous layers. Typically, a pooling operation (or a higher stride length in the convolution filter) is used to subsample interesting activations from one layer to the next, resulting in ever-coarser “higher-level” representations of the image content.
Despite the potential of deep learning in analyzing biomedical images, two outstanding challenges, namely the complexity of the biological imaging phenotypes and the difficulty in acquiring large biological sample sizes, have hindered broader adoption in this domain. To circumvent these challenges, architectural changes have been introduced into some models to make training easier without trading off model accuracy. One novel approach is to use wide networks, which explicitly model various levels of coarseness. In these topologies, several copies of the input image are downsampled and used to train separate, parallel convolutional layers, which are eventually concatenated together to form a single feature vector that is passed on to fully-connected layers (e.g., see Buyssens et al. [19]). A recent application of this idea to HCS is the Multiscale Convolutional Neural Network (M-CNN) architecture [16], which has been shown to be generally applicable to multiple microscopy datasets, in particular for identifying the effect of compound treatment.
The computational footprint of M-CNN, although relatively small as compared with other deep CNNs (e.g., Residual Neural Network 152), is still large when applied to high-content cellular imaging. Thus, it is important that model-related aspects of memory utilization and training performance are thoroughly understood, and that an end user knows a priori how to get maximum performance on their hardware. Commercial cloud service providers (CSPs) like Microsoft, Google, or Amazon–as well as on-premise HPC centers in academia and industry–are exploring custom hardware accelerator architectures, such as application-specific integrated circuits (ASICs) [20] or GPUs, to expedite training neural network models. In spite of the popularity of these technologies, several factors such as higher financial cost of ownership, lack of virtualization and lack of support for multi-tenancy, leading to poor hardware utilization, may be cited as reasons to consider CPU-centric performance optimizations in reducing the time-to-train for such models. Importantly, since almost all data centers, are already equipped with thousands of general-purpose CPUs, it makes a strong case for such an approach.
- 1.
Train M-CNN to achieve SOTA accuracy of 99% on multiple CPU servers without tiling or cropping of input images or splitting the model
- 2.
Use large batch sizes per CPU exploiting large memory
- 3.
Use multiple training instances/workers per CPU node to improve utilization
- 4.
Use large batches and learning rate scaling to achieve fast convergence.
 Xeon
Xeon 6148 processor nodes with 192 GB DDR4 memory connected with 100 Gbps Intel
6148 processor nodes with 192 GB DDR4 memory connected with 100 Gbps Intel Omnipath architecture.
Omnipath architecture.
Operations and kernels of the M-CNN model. Convolution is abbreviated CONV, and Max Pooling operations are abbreviated as MAX POOL
2 Multi-scale Convolutional Neural Network
M-CNNs capture both fine-grained cell-level features and coarse-grained features observable at the population level by using seven parallel convolution pathways (Fig. 1). As in [16], image height and width are down-sampled by 64, 32, 16, 8, 4, and 2 times in the lower six pathways in ascending order, respectively, while images processed by the top-most path are operated on at the full resolution. The output of the last layers of convolution are down sampled to the lowest resolution and concatenated into a  tensor. The concatenated signals are passed through a convolution with rectified linear activation (ReLU) and two fully connected layers. A final softmax layer transforms probabilistic per-class predictions associated with each image into a hard class prediction. In Fig. 1, the size of convolution kernels are specified below the solid colored cubes, which represent the activations. The sum of the sizes of the convolution kernels and two dense layer, which are
tensor. The concatenated signals are passed through a convolution with rectified linear activation (ReLU) and two fully connected layers. A final softmax layer transforms probabilistic per-class predictions associated with each image into a hard class prediction. In Fig. 1, the size of convolution kernels are specified below the solid colored cubes, which represent the activations. The sum of the sizes of the convolution kernels and two dense layer, which are  and
and  , respectively, is 162.2 megabytes. Weights are represented as 32-bit floating point numbers.
, respectively, is 162.2 megabytes. Weights are represented as 32-bit floating point numbers.

Activation sizes in M-CNN as a function of batch size.
3 Large Batch Training
 of the loss function with respect to the current weights W. On the basis of the gradients, weights are updated according Eq. 1, where
of the loss function with respect to the current weights W. On the basis of the gradients, weights are updated according Eq. 1, where  are the updated weights,
are the updated weights,  are the weights prior to the adjustment (or previous iteration), and
are the weights prior to the adjustment (or previous iteration), and  is a tunable parameter called the learning rate (LR).
is a tunable parameter called the learning rate (LR).

 , we updates the weights according to
, we updates the weights according to
3.1 Learning Rate Schedule
In addition to scaling the model’s learning rate parameter (LR) with respect to the batch size, others [22] have observed that gradually increasing it during initial epochs, and subsequently decaying it helps to the model to converge faster. This implies that LR is changed between training iterations, depending on the number of workers, the model, and dataset. We follow the same methodology. We start to train with LR initialized to a low value of  . In the first few epochs, it is gradually increased to the scaled value of
. In the first few epochs, it is gradually increased to the scaled value of  and then adjusted following a polynomial decay, with momentum SGD (momentum = 0.9).
and then adjusted following a polynomial decay, with momentum SGD (momentum = 0.9).
Reaching network convergence during training is not guaranteed–the process is sensitive to LR values and features in the data. Scaling this process out to large batch sizes on multiple workers concurrently has the same considerations. If the per-iteration batch size is too large, fewer updates per epoch are required (since an epoch is, by definition, a complete pass through the training data set), which can either result in the model diverging, or it requiring additional epochs to converge (relative to the non-distributed case), defeating the purpose of scaling to large batch sizes. Thus, demonstrating scaled-out performance with large batches without first demonstrating convergence is meaningless. Instead, we measure the time needed to reach state of the art accuracy or TTT. The ingestion method for each worker ensures that each minibatch contains randomly-shuffled data from the different classes.
4 Dataset
Dataset A: Images in this dataset are 1024
 1280 pixesl wide with 3 channels. They are augmented to produce five copies as 1.
1280 pixesl wide with 3 channels. They are augmented to produce five copies as 1.  rotation, 2. a horizontal mirror, 3. vertical mirror, 4.
rotation, 2. a horizontal mirror, 3. vertical mirror, 4.  rotation of horizontal mirror and 5.
rotation of horizontal mirror and 5.  rotation of vertical mirror. Total number of images in the dataset is
rotation of vertical mirror. Total number of images in the dataset is  (five rotations + original)
(five rotations + original)  . We take a 90-10 split and create a training set of 9093 images and validation set of 1011 images. The total size of the images on disk are 38 GB.
. We take a 90-10 split and create a training set of 9093 images and validation set of 1011 images. The total size of the images on disk are 38 GB.Dataset B: This is a larger dataset. The dimensions of the images in this dataset are 724
 724 pixesl with 3 channels. Similar to Dataset A, all images have 5 additional augmentations. Additionally, each image is rotated by
724 pixesl with 3 channels. Similar to Dataset A, all images have 5 additional augmentations. Additionally, each image is rotated by  to create 23 more augmentations. The total size of the images on disk are 512 GB. Among them, 313282 images are used for training and 35306 are used for validation.
to create 23 more augmentations. The total size of the images on disk are 512 GB. Among them, 313282 images are used for training and 35306 are used for validation.

Example images from the BBBC021 [23] dataset showing phenotypes from treatment with compound-concentration pairs with different mechanisms of action: (a) DSMO (neutral control), (b) Microtubule destabilizer, (c) Cholesterol lowering, (d) Microtubule stabilizer, (e) Actin disrupter, (f) Epithelial. DNA staining is shown in blue, the F-actin staining in red and the B-tubulin staining in green. The insets show a magnified view of the same phenotypes.
5 Performance Results
5.1 Experimental Setup
All experiments are run on two socket (2S) 2.40 GHz Intel® Xeon® Gold 6148 processors. There are 20 cores per socket with 2-way hardware multi-threading. On-chip L1 data cache is 32 KB. L2 and L3 caches are 1 MB and 28 MB respectively. For multi-node experiments, we used up to 64 Intel® Xeon® Gold connected via 100 GB/s Intel® OP Fabric. Each server has 192 GB physical memory and a 1.6TB Intel SSD storage drive. The M-CNN topology was added to the standard benchmarking scripts [25] to leverage instantiation mechanisms of distributed workers. Gradient synchronization between the workers was done using Horovod, an MPI-based communication library for deep learning training [26]. In our experiments, we used TensorFlow 1.9.0, Horovod 0.13.4, Python 2.7.5 and OpenMPI 3.0.0.
5.2 Scaling up TTT in One Node with Dataset A

Class distribution for the 1684 training images used in our experiment.
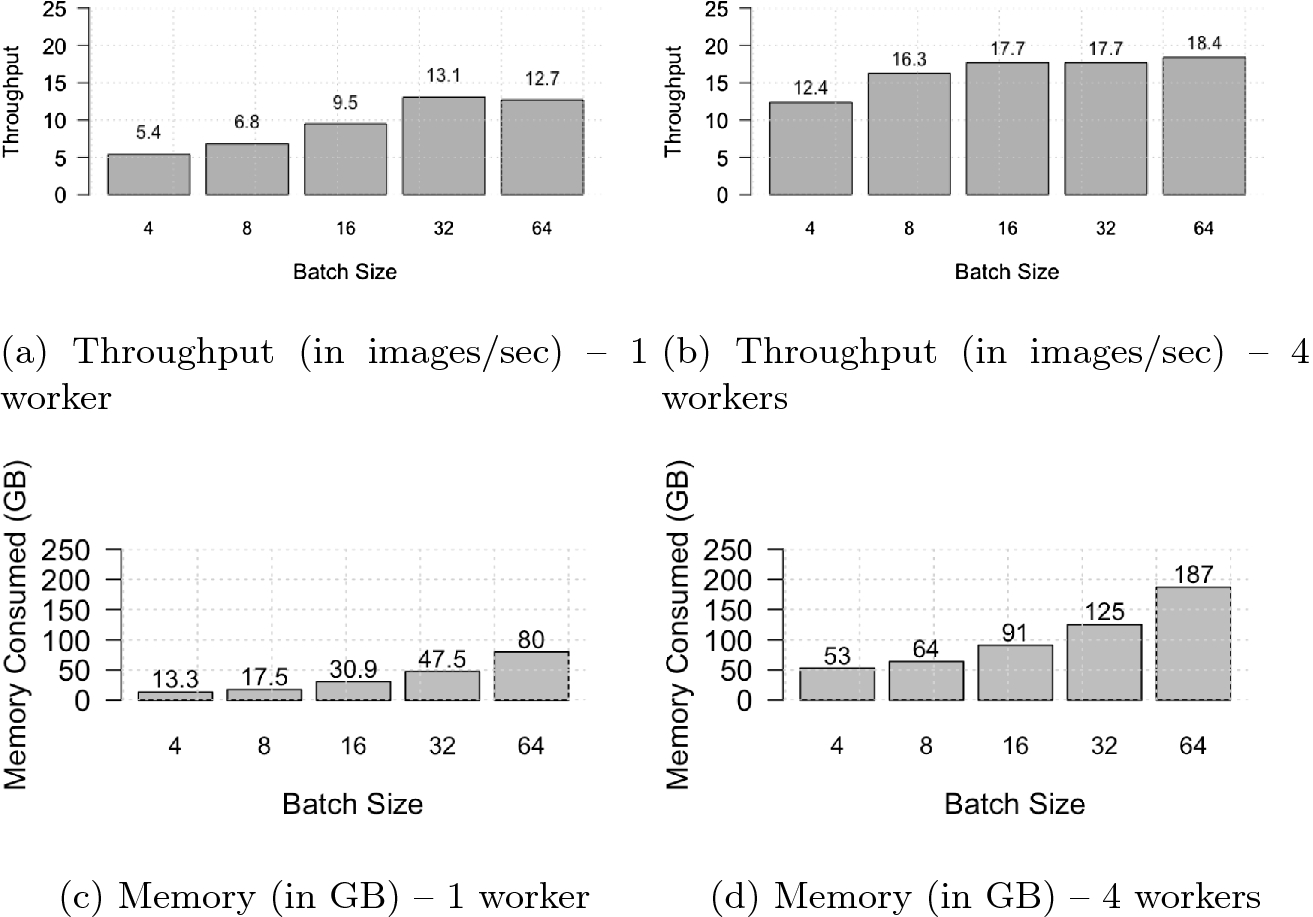
Throughput (in images/second) and memory utilized (in GB) with batch sizes 4 to 64 for 1 and 4 training workers respectively (a and b) on a single 2S Intel® Xeon® Gold 6148 processor with Dataset A.

Two socket Intel® Xeon® Gold 6148 processor NUMA configuration
Second, for all batch size configurations, CPU utilization was low meaning the cores were under-utilized. Upon further investigation with system profile, we found (1) there were lots of context switches and (2) processes or threads assigned to one CPU socket are accessing data from the other CPU socket including a long latency hop over the socket-to-socket interconnect. This led to the discovery that using multiple workers or instanes per socket can yield faster TTT. The essence of using multiple workers in a single CPU is to affinitize tasks to cores and bind their memory allocation to local non-uniform memory access (NUMA) banks as shown by the shaded rectangles in Fig. 6. Memory binding is key here as it avoids redundant fetches over the interconnect to the memory channels of the adjacent CPU socket. More detailed analysis of multiple workers or instances in training and inference are described in detail by Saletore and colleagues, in [27].
While the authors mention that instantiating multiple workers boosts performance, they do not specify the optimal number of workers, which can depend on a variety of factors, including the neural network topology being trained, CPU micro-architecture, and characteristics of the input data. To find the best combination of workers and local batch size per worker, we experimented with 1, 2, 4 and 8 workers per CPU. In this case, 4 workers with 8 local mini-batch size resulted in the highest throughput per node. A detailed analysis of throughput and memory utilization for 4 workers is shown in Fig. 5(b) and (d), respectively. Note that throughput with batch sizes of 64, 128, or 256 was higher than with a batch size of 32, but these configurations did not converge any faster.
5.3 Scaling Out TTT on 8 Servers with Dataset A

Training loss, top-1 and top-5 accuracy of M-CNN model with Dataset A in 30 epochs on 8x 2S Intel® Xeon® Gold 6148 processors connected with Intel® OP Fabric
5.4 Scaling Out TTT on 128 Servers with Dataset B

Scaling M-CNN training with Dataset A from 1X to 8X 2S Intel® Xeon® Gold 6148 processors connected with 100 Gbps Intel® OP Fabric
M-CNN training performance on 128 2S Intel® Xeon® Gold processors with Dataset B
# of nodes | # of epochs | Batch size | TTT (mins) | Images/sec |
|---|---|---|---|---|
1 | 6.6 | 128 | 960 | 30 |
2 | 8 | 256 | 642 | 72 |
4 | 8.7 | 512 | 320 | 141 |
8 | 12 | 1024 | 240 | 262 |
16 | 15.9 | 2048 | 150 | 553 |
32 | 14.9 | 2048 | 85 | 893 |
64 | 15 | 2048 | 61 | 1284 |
128 | 15.2 | 2048 | 50 | 1587 |
The key takeaway here is that updates per epoch is critical to acheive convergence. Global mini batch size determines the number of updates per epoch and M-CNN did not converge beyond global batch sizes of 2048. Hence, we maintained the global batch size to 2048 while scaling from 16 to 128 nodes – the idea of strong scaling taken from HPC applications. As the same amount of work is increasingly divided across more CPU cores we observe diminishing returns in speedup albeit overall TTT improves. Note that our objective is to not show linear scaling here, but to see what resources will help us acheive a TTT less than one hour.

Top-1 accuracy achieved in 20 epochs of M-CNN training and learning rate used on 1–64 2S Intel® Xeon® Gold processors. Dataset B is used for these experiments. Global minibatch size is capped at 2K from 16 to 64 nodes. The learning rate as shown in (f)–(h) is also scaled only to 0.032 to achieve convergence
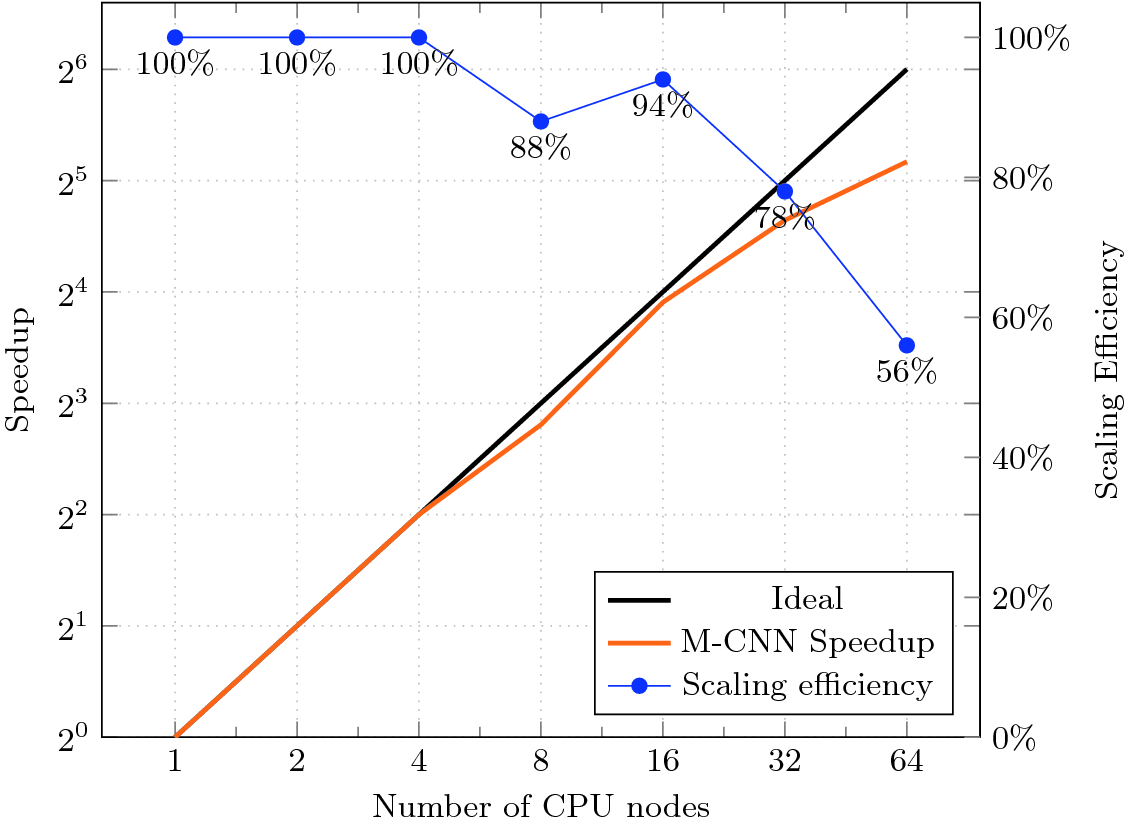
Scalability of M-CNN training performance for 20 epochs on 64 2S Intel® Xeon® Gold 6148 processors. Note that global batch size is capped at 2K from 16 – 64 nodes. Intel® OP Fabric, TensorFlow-1.9.0+Horovod, OpenMPI v3.0.0, 8 workers/node
Additionally, we show the scaling efficiency of M-CNN training from 1 to 64 nodes all running for 20 epochs. As shown in Fig. 10 time to train efficiently scales up to 16 nodes after which capping the global mini batch size shows diminishing returns.
6 Discussion
In this work, we explored training a multi-scale convolutional neural network to classify large high content screening images within one hour by exploiting large memory in CPU systems. The cellular images used are over million pixels in resolution and are 26 times larger than those in the ImageNet dataset. We used two sets of cellular images with different resolutions to analyze the performance on multiple nodes of M-CNN training. The first set contains 10K full resolution cellular images (1024  1280
1280  3) and the second dataset contains 313K images of smaller dimensions (724
3) and the second dataset contains 313K images of smaller dimensions (724  724
724  3). With the first dataset, we were able to scale time to train linearly using 8X 2S Intel® Xeon® Gold processors. Large mini-batch sizes enabled by the large memory footprint in CPUs helped us achieve the speedup in training time. With the second data set, we were able to achieve TTT of 50 min, a 19.2X improvement in time to train using 128 Intel® Xeon® Gold processors. We learned that the updates per epoch is critical to achieve convergence and if the characteristics of the images in the dataset cannot tolerate scaling of updates per epoch beyond a certain threshold (2048 in our case), then adding more computational resources results in diminishing returns. In future work, we intend to explore larger datasets with more variation where images are chosen from different cohorts.
3). With the first dataset, we were able to scale time to train linearly using 8X 2S Intel® Xeon® Gold processors. Large mini-batch sizes enabled by the large memory footprint in CPUs helped us achieve the speedup in training time. With the second data set, we were able to achieve TTT of 50 min, a 19.2X improvement in time to train using 128 Intel® Xeon® Gold processors. We learned that the updates per epoch is critical to achieve convergence and if the characteristics of the images in the dataset cannot tolerate scaling of updates per epoch beyond a certain threshold (2048 in our case), then adding more computational resources results in diminishing returns. In future work, we intend to explore larger datasets with more variation where images are chosen from different cohorts.
Acknowledgements
We would like to acknowledge Wolfgang Zipfel from the Novartis Institutes for Biomedical Research, Basel, Switzerland; Michael Derby, Michael Steeves and Steve Litster from the Novartis Institutes for Biomedical Research, Cambridge, MA, USA; Deepthi Karkada, Vivek Menon, Kristina Kermanshahche, Mike Demshki, Patrick Messmer, Andy Bartley, Bruno Riva and Hema Chamraj from Intel Corporation, USA, for their contributions to this work. The authors also acknowledge the Texas Advanced Computing Center (TACC) at The University of Texas at Austin for providing HPC resources that have contributed to the research results reported within this paper.
Conflicts of Interest
Intel® Xeon® Gold 6148 processor, Intel® OPA and Intel® SSD storage drive are registered products of Intel Corporation. The authors declare no other conflicts of interest.