1 Introduction and Background
Scientific workflows are an increasingly common tool for high performance computing (HPC) based scientific efforts. As performance and system size increase in HPC systems, the numbers of single, static computing problems that can utilize the entire machine efficiently are decreasing. Meanwhile, the feasibility, efficiency, and appeal of multiple simultaneous but heterogeneous calculations, including simulations, data analysis, model re-parameterization, and incorporation of machine learning on leadership resources, is increasing. In the HPC environment there is a need for workflow software that can handle account allocations, schedulers, and multiple levels of parallelism within each component, and can scale to thousands of nodes.
Recently, groups in many areas of computational science have realized that a need for HPC-specific workflow managers exists [28]. However, currently no such platform supports a dynamically adaptable workflow with interactive steering at run-time. In fact, in a recent overview of existing workflow management systems, the ability to externally steer the workflow was not a supported feature in any of the commonly used programs studied [23]. With designs that use the Message Passing Interface (MPI), the directed acyclic graph (DAG) that represents the workflow is relatively rigid, as the allocated hardware resources are fixed for a given instance. In addition, there may be limitations of fault tolerance handling: the entire workflow may terminate when one task fails [6].
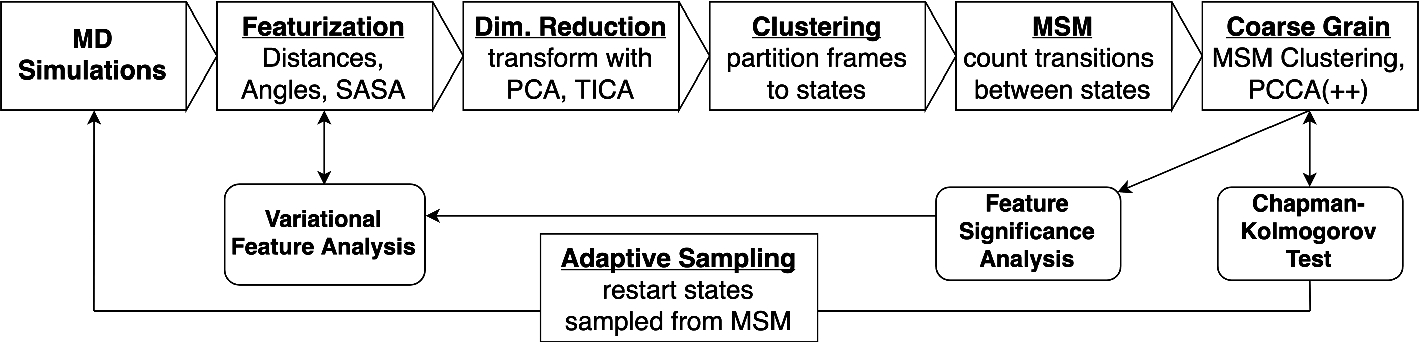
Flowchart of the iterative analyses used to determine the degree of sampling of an Markov-state model (MSM)-based ensemble MD simulation, leading to adaptive selection of restart states targeted to simulate poorly sampled regions.
Adaptive sampling from Markov-state models (MSM) is one such technique. MSMs describe a dynamical phenomenon as a Markovian process on some time-scale [17, 21]. The appropriate timescale can be determined by a statistical analysis of time-correlations of features of the system, chosen to best describe the temporal evolution of the process of interest [4, 19].
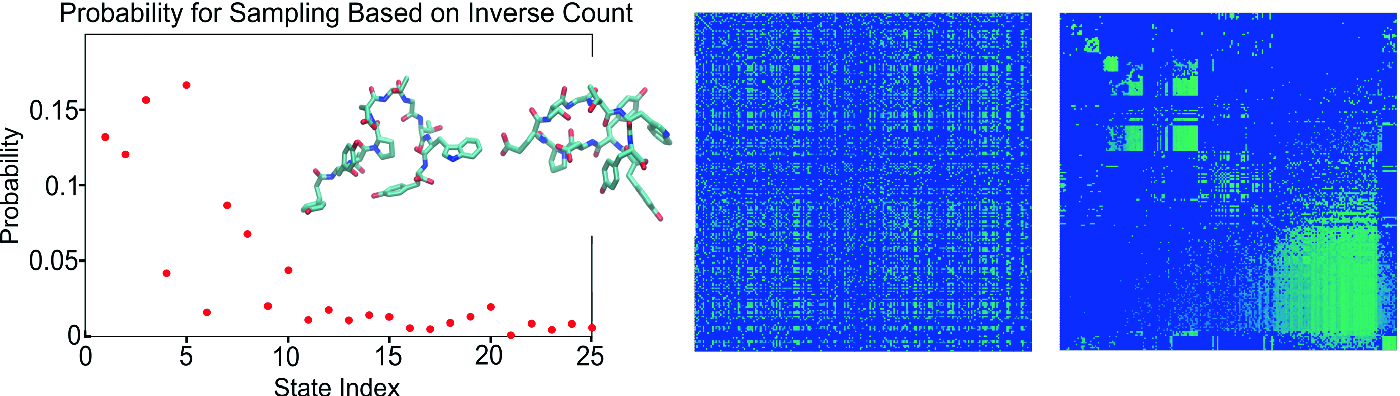
Left panel: Discrete probability distribution for sampling of starting positions for second round of ensemble simulations in an MSM-driven adaptive sampling workflow; Inset: Two macrostates of chignolin protein determined by an adaptive sampling workflow, the stable and the metastable state. Right panel: Markov matrix of preliminary transition probabilities for microstates before (left side) and after (right side) grouping into macrostates using PCCA+, during a particular iteration of the workflow cycle. Heat map goes from low probability, dark blue, to high probability, light green. Light-colored blocks in the sorted matrix correspond to transition probabilities between distinct macrostates determined at that analysis step.
Figure 2 illustrates the results of some analyses that were performed within an MSM simulation workflow on a small protein, chignolin, using the Titan computer, a Cray XK7 machine at the Oak Ridge Leadership Computing Facility (OLCF). With an interactive workflow this analysis would be performed in-situ and output could be displayed to enable user interactions that ultimately steer the DAG. Workflow tools have been used by our team to run ensemble MSM molecular dynamics simulations using the OpenMM program [7] as the MD simulation engine, and statistical analysis done with the PyEMMA library [22]. Workflows were executed over multiple instances of resource allocation, for example, over several HPC jobs that use the (often short) allowable job time limits on many HPC systems, using a Python-based workflow tool with the MongoDB NoSQL database management system (DBMS) providing a database-centric architecture [18] for synchronization of analysis data and workflow state. While not a new concept [1], use of DBMS programs within scientific workflow platforms has recently increased: several scientific workflow management solutions have incorporated both SQL and NoSQL DBMSs into their software design. For instance, Copernicus uses a Python interface with sqlite [20], and the Fireworks workflow program uses MongoDB [13].

Example of an interactive steering action. Given a limited HPC allocation, a researcher would like to find regions of conformation space of a protein closest to a folded state. Left panel: RMSD from unfolded starting state. Middle panel: RMSD from folded crystal structure. This folded structure may not be available. However, the increased RMSD away from the starting state is seen to correspond to smaller RMSD distance from folded state in this dataset. Right panel: A choice can be made during run-time to launch fewer, longer trajectories vs. more numerous, shorter trajectories to use a fixed HPC allocation in the next round of simulations.
Figure 3 illustrates run-time steering, with a DAG adaptation that can be employed for resource-use optimization in particle-simulation workflows. In this case, a user would like to maximize the efficient use of a limited allocation on a supercomputer, by determining the best compute task configuration for ensemble simulations of protein folding using the same total node hours: many short simulations, or fewer, longer simulations. The example shows how a measurement can be made on the dataset, in this case, each simulation frame’s “distance” from the starting state measured by the root-mean-square deviation (RMSD) of atomic positions. We see in Fig. 3 that an increased RMSD distance between the unfolded starting structure and the structures sampled over the longer simulations corresponds with a decrease in RMSD to the final folded state. While the final state may not be known, the increased RMSD from starting state may provide one of many heuristics that can be used to steer the initial phases to more efficient exploration. This RMSD analysis informs the choice of trajectory layout for the next round of simulations (indicated by the right panel).
2 Design of an Interactive, Externally-Steered DBMS-Based Workflow Tool
Requirements for externally steered interactive workflow program using a DBMS
Requirement | Function |
|---|---|
Multiple live connections | Direct signaling activity |
Mirrored objects | Continual state synchronization |
Controller object | Signal propagation, resource management |
Heartbeat signal | Robust resource control |
Locales | Resolved everywhere in distributed application |
2.1 Requirements for Workflow Interactivity
In order to determine design requirements for an interactive DBMS-based workflow tool, we created a modular, minimal working example of a steerable and run-time interactive scientific workflow platform. This allows us to test the performance and scaling in a systematic, building-block manner.
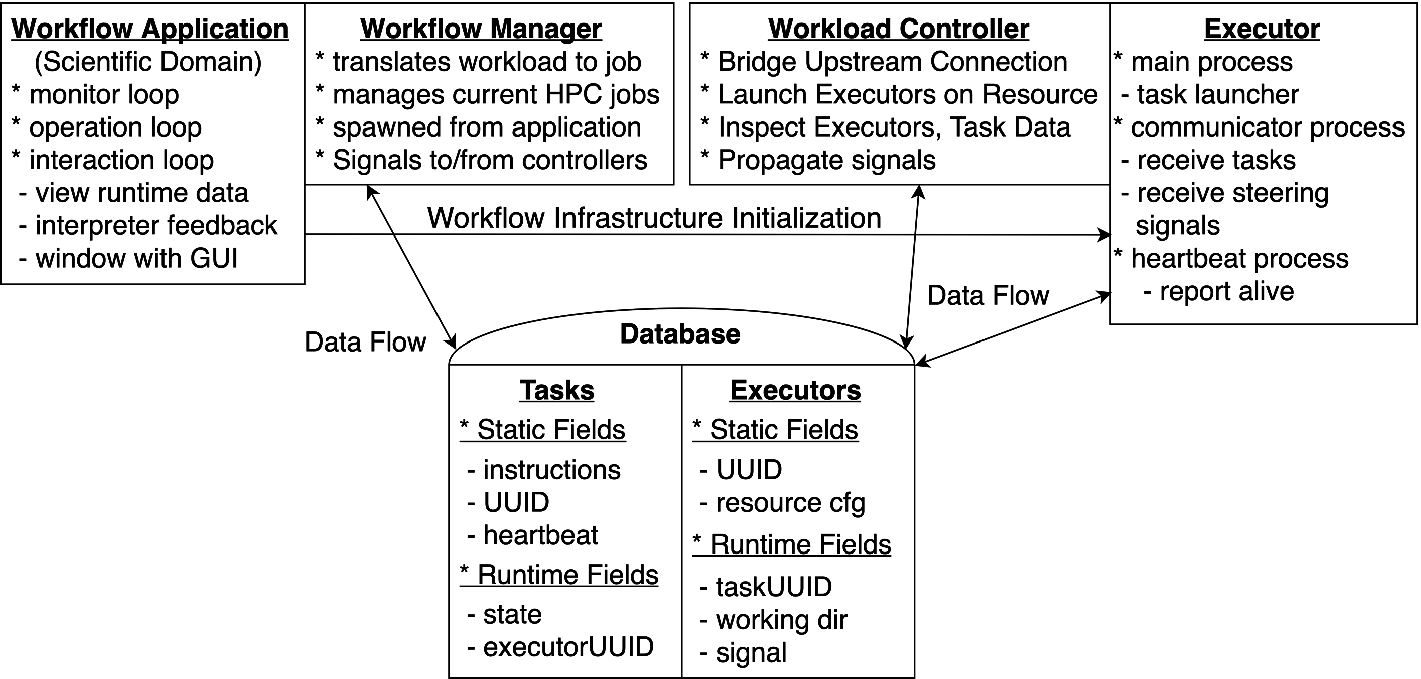
Design of a complete, interactive workflow application, with top panel showing programmatic infrastructure, and bottom panel indicating essential data fields for information flow resulting in steering. Requirements include live mapping of output data to the application for interactive visualization (GUI or text), a connection for input to and feedback from the task-management (workflow) infrastructure, and universal locale fields for targeting specific components and/or their data.
a scientific workflow application generates the workflow instructions (i.e. tasks and the DAG),
a workflow manager submits workloads, i.e. batches of tasks, to possibly multiple HPC Local Resource Management Systems (LRMS),
a workload controller propagates instructions and manages workload execution in an HPC job at run-time,
executors, distributed on the compute resource, acquire task instructions and execute them,
a DBMS stores fields used to compose workflow object instances, including static object data and stateful run-time data, and
tasks, each consisting of a set of instructions, are executed using a share-nothing dataflow programming model.
The steering capability itself originates from two related design choices. One of these is a multiconnection model, wherein multiple components (executors and controller in the test cases) are provided live connections to the database. These multiple live connections are required for immediate querying of task states, task locations, and the ability to change a task. The second design choice requires each connected component run a synchronization loop in a background process that continually synchronizes instances with the database. This continual synchronization results in workflow application instances containing mirrored objects, i.e. up-to-date reflections of their state in the database.
A steerable executor runs two loops in background processes. A repeated regular “heartbeat” signal is broadcast from one loop so the controller can easily validate resource use on tasks at run-time, and the second loop iterates state and signal queries to synchronize with the database and controller. To facilitate steering, the controller must be able to close down components and relinquish resources quickly but reliably at any time. One challenging scenario to manage without a heartbeat is the case of a silent executor failure; without a continual communication channel, the controller does not register that the resource has failed. To efficiently utilize an allocation in the case of failures, the controller can checkpoint job shutdown operations based on the time since a heartbeat was detected, or try to restart failed executors based on their individual heartbeat signals.
Tasks run inside executors, which are launched onto a compute resource using command-line tools provided by the system job launcher, such as mpirun. Executors are not explicitly bound to tasks until they poll the database for new tasks that match the compute resource they provide. This design offers a layer for control of operations such as stopping or releasing tasks, unexpected shutdown, or starting a new task. An individual task can itself be a parallel executable that uses a threaded or Message Passing Interface (MPI) based programming model. Executors for batches of homogeneous, non-MPI tasks can be launched using a single launch call, whereas N inhomogeneous or MPI-containing tasks require N individual calls to the task launcher.
Executors each connect to the database, thus communication to the database host(s) increases with growth in workload scale. The ability of the host hardware and the network to support the growing number of connections is the limitation on the performance of workflow activity associated with run-time interaction and steering. The controller is supported by a single connection. The controller reads and writes more data than the executors by a factor on the order of the number of live executors it controls. Performance and scaling of these communication operations for each software component on Summit is discussed below.
In a distributed workflow system, the network address, data file locations, and workflow component identities must be accessible to be utilized at run-time by controlling components and the application instance to enable the steering capability. Uniform Resource Locators (URLs) were used in the test application to navigate within local workloads. A data structure may be required for expanding the capacities of the program. Interactive requests can be made by the application, and propagated by messages to the controller/executors to alter their behavior or inspect run-time data. To accurately target these requests to the correct location within distributed resource network, locale information must be registered in the database system as each component is initialized. We assigned a universal unique identifier (uuid) to all workflow components, including output-file representations in the database, to ensure that every component can be easily and uniquely targeted with instructions, signals, and data-specific future tasks, and located by controllers for inspection.
In the general case, signalled activity may include pre-programmed workflow operations such as starting, pausing, or restarting tasks, or other functionality defined by the user. In many use-cases, these steering signals will result from user inspection of workflow/task output data synchronized at run-time by a controller with the upstream domain application. This ability to propagate both a signal and associated action defined by the user at run-time is an essential capability for a steered scientific workflow.
2.2 Implementation for Performance Testing
The minimal workflow tool used for testing the performance of workflow steering operations includes controller, executor, and task objects. The DBMS-based communication was implemented using minimal task and executor documents similar to that shown in Fig. 4. Run-time data included executor/task states and steering messages incumbent from the interaction.
Signaling messages propagate from an off-resource interaction by first assigning a value (e.g. the message) to the signal attribute of the executors. The synchronization loop then inserts the message into the database so the DMBS state reflects the updated instance. The resource-bound, live executor then synchronizes the new value to its instance to reflect the changed database state. These signals trigger a corresponding activity in the live executor and then are cleared by that executor. Synchronization loops can inspect heartbeat time-stamps when a discrepancy is encountered between an instance and the database, indicating an updated value, to accurately determine the old and updated states. Another approach would be to reserve special attributes that lists changes and their originating instances (i.e. object or database), so that the update can be correctly targeted to either the instance or database. The continual synchronization of changed values, so that the instances and corresponding database documents are mirrored, is the basis of the steering functionality.
3 Testing the Components of the Program
Interactively-steered workflows using a DBMS and designed with many live connections increase the network traffic to and from the database server, compared to non-interactive models. Therefore the ability of a server that is launched on a single compute node to simultaneously perform many thousands of communications must be tested. In addition, it is necessary to test whether the interaction with the workflow, as well as the steering actions, affect workflow performance.
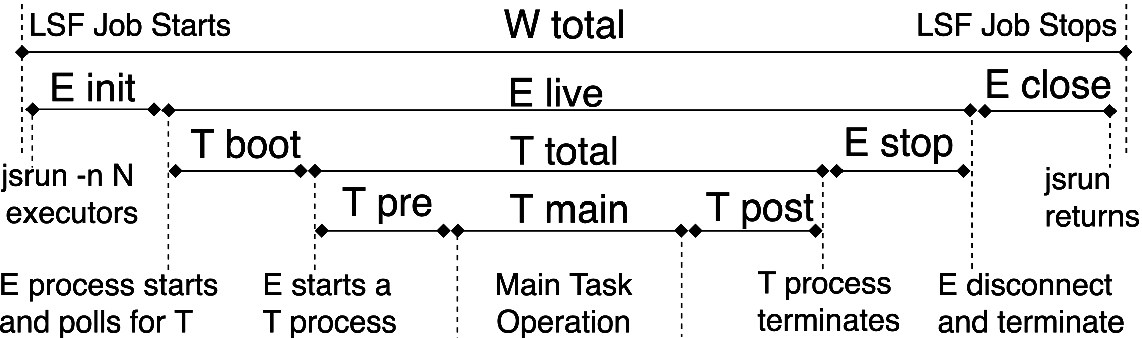
Diagram of the components of the interaction tests that were timed.
3.1 Testing the Database Program
To characterize the baseline performance of a workflow application that relies on small document transactions to propagate information flow between execution and application layers, we measured the performance of read and write operations on Summit using the Mongo database program. Communication by these document transactions constitutes the information flow resulting in interaction and steering. The majority of these documents in typical use cases will contain only small fields describing task operations, metadata, state updates, and signals to the executors. A weak-scaling experiment was used to test the performance of single instances of mass workflow communication for both reads and writes between executors and a database instance, corresponding to the cases of task initialization by the executor and feedback by executors to the application or a controller.
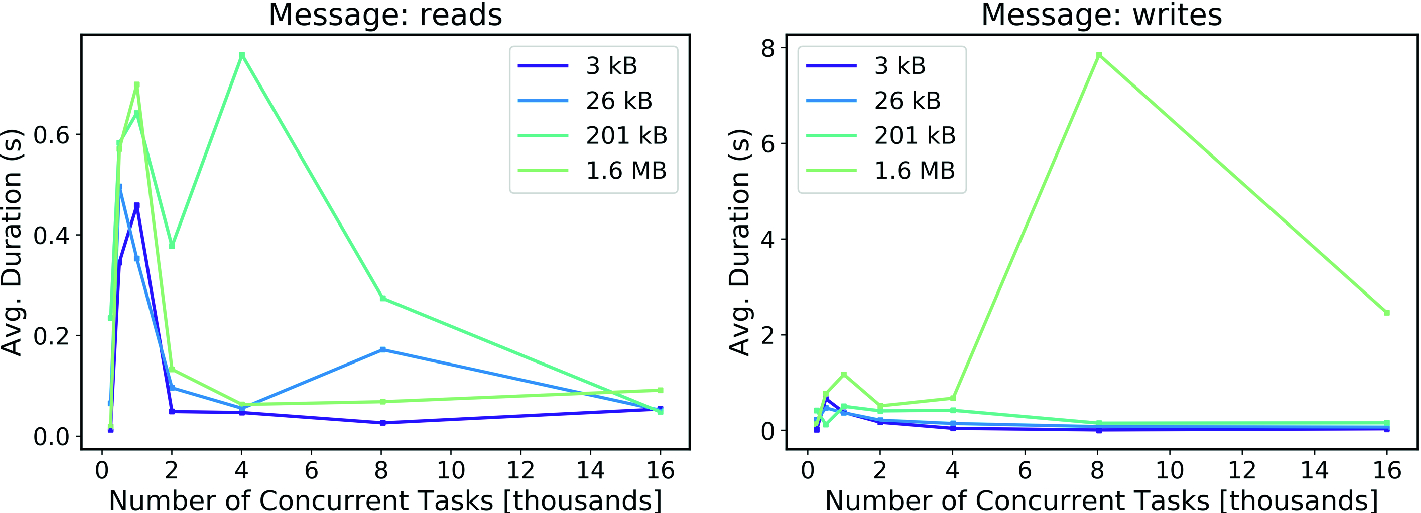
Scaling of MongoDB database communication tasks on Summit, using variable file sizes. Left panel: reads. Right panel: writes. Standard deviation for all read and most write tests was below 0.7 s. Standard deviation for writing 1.6 MB documents was approximately 2 s for 4000 and 16000 tasks, and 15 s for 8000 tasks. This variability may be a reflection of system fluctuations at the time the tests were executed.
The average duration of the majority of these communication tests is on the order of one second or less, with the exception of instances executing many thousands of simultaneous large-size write operations (Fig. 6, right panel). Write operations of this size and concurrency would only occur when updating raw output data from highly synchronized executors. These tests showed a total latency of 5–10 s, thus it is likely that synchronizing data output from all tasks might take seconds to propagate to the controller and application components. Notably this delay is only in the case of the DMBS receiving data from completely synchronized tasks, which is not an activity expected at high scales. As tested and discussed below, controllers local to executors at run-time can inspect on-disk task data with no such penalty.
Read and write tests with smaller documents correspond to the majority of communication activity expected in a workflow, such as repeated status and heartbeat updates from each executor. These data indicate that no appreciable latency occurred as a controller queries the moment-to-moment state of its executors at any tested scale. The low latency observed for reads of any document size and tested scale indicates that the ability to expediently poll the database is not affected by the number of simultaneous requests from other components or the size of the requested document. All connections supported successful transactions for the scales and data sizes shown in Fig. 6, indicating the resiliency of a DBMS-based workflow program. When transacting 13 MB, read operations succeeded with negligible latency at all scales, however write operations failed for 3.0% (241) of 8,000 tasks, and 33.7% (5394) of 16,000 tasks.
The total time required for up to 16,000 read or write communications, for any of the data sizes shown, is much less than the typical simulation workflow length, which can last for dozens of minutes to hours. Thus we find this design of using a DBMS to synchronize workflow components, propagate signals, and transfer workflow/task output data, provides a suitable basis for creating a low-latency run-time-interactive and steerable workflow program.
3.2 Testing the Performance of Steering Interactions
There are two modes of steering activity that we consider: interactions that change the number of executors, and interactions that steer the executors themselves. Assuming efficient use of the allocation in which resources are not left to idle, changing the number of executors results from some combination of acquiring of new compute resources to spawn new executors, and remapping existing executors to provide a different hardware configuration. This remapping capability is implemented in some programs for non-steered workflows: in a single HPC job executors can be launched multiple times and with different resource configurations, from a previously characterized DAG. The second mode of steering activity requires an executor to start a new task after stopping its current task, or modifying its current task in some way. Each case requires a component that continually interacts with the database to receive messages, achieved with background synchronization loops. This functionality may be restricted to the controller in the first mode of steering, but the second mode requires executor synchronization to change tasks that are currently running, and update state and task data for inspection and further interaction by upstream workflow components.
Executor Spawn: Acquisition of New Resources. To spawn new executors and increase the number of running tasks, a new workload is queued to acquire additional compute resources from the Local Resource Management System (LRMS). This was successfully tested on OLCF Titan and Summit by making a submission to the LRMS by the controller component (from inside an HPC job). In the case of HPC systems that do not allow job submission from within a running job, the submission would be made from a login node by the workflow manager.
Executor Steering: Check, Pause, and Restart. Results of three executor steering tests, displayed in Fig. 7, show the effect on task-execution time from: a run-time inspection of output data, a pause in the task, and a task restart. A control test used executors and a controller with no synchronization loops, and thus no interaction that might affect task execution. For each case the main task was delegated to a subprocess, and consisted of an executable repeatedly writing a string to a task data output file for 60 s. In the three steering cases, non-blocking synchronization loops were run by the executors in background processes to mitigate or eliminate any effect on the main process execution. The controller similarly ran synchronization and interaction loops in the background, which repeatedly queried the state and task properties of all executors. The output data file locations were determined by the controller from task and executor properties.
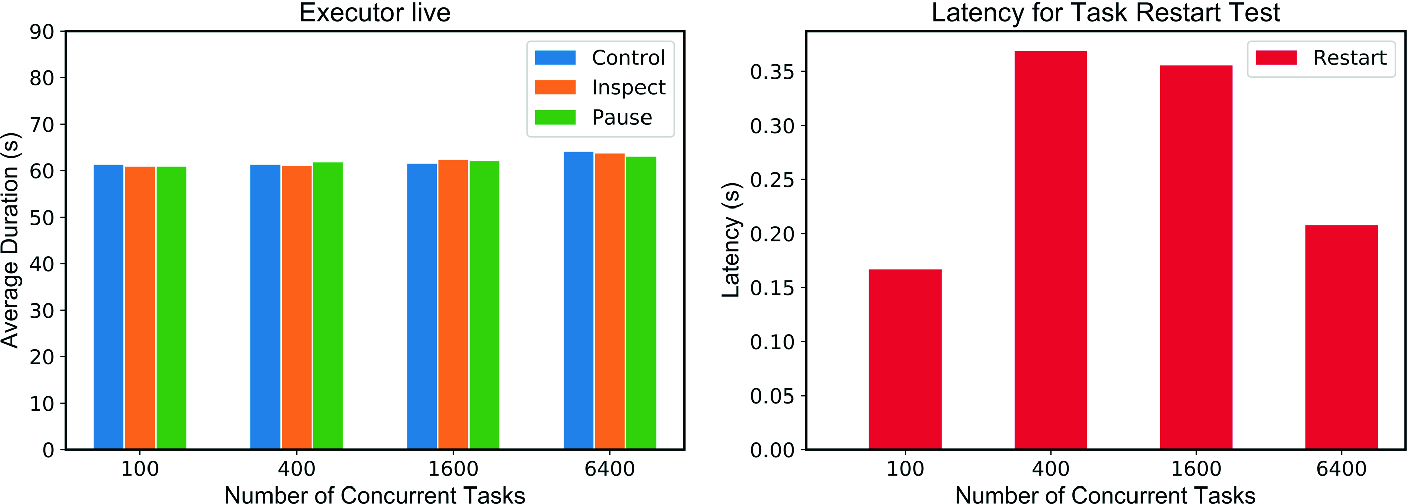
Performance testing of three steering interactions. Left: total live executor time for the inspect and pause tests, versus a control with no interaction. The total duration for pause tests excludes the 15 s pause. Right: latency incurred for task restarts. This test involves stopping running executables at unpredictable times, so latency was calculated by subtracting the total task time for the incomplete and complete tasks from the executor live time.
Pause and restart signals were propagated by the controller first modifying all executors simultaneously, and the live executors subsequently reading the signal via the synchronization loop. The executors were thus directed to execute an action by the controller’s signal. Full-scale steering of every executor was conducted here to test the limit of performance. Figure 7 shows that the total run-time (excluding time in paused state) for tasks was not affected by signal processing activity in the executor. The case of directing executors to restart a task introduces latency inherent from terminating the task process, and restarting the task in a new process. This latency was observed to be independent of the tested scales for the relatively lightweight Python scripts and C executable tested (Fig. 7, right panel).
4 Conclusions
In this paper we have shared lessons learned when designing an externally-steered, interactive scientific workflow program. We showed by testing components with a ground-up design for steered applications, that a DBMS-based scientific workflow tool can provide a highly-interactive, externally steered solution at the pre-exascale HPC level. On the Summit supercomputer it is possible to launch and manage of tens thousands of tasks with negligible latency, each supported by a live connection, from a single MongoDB server on a compute node. This can serve as a basis to create a workflow tool capable of run-time interaction, analysis, and modification of the workflow, both in terms of task details and number of tasks. In addition, the design provides location information for tasks to facilitate the movement of tasks and other workflow operations to data, and the strategic arrangement of tasks on particular resources.
Acknowledgements
An award of computer time was provided by the Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program. This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR227525. JCS acknowledges ORNL LDRD funds. The authors would like to thank Oscar Hernandez, Frank Noé and group, Cecilia Clementi and group, and Shantenu Jha and group, for valuable insight and discussions.