When you first create a new table with an index on it and insert data into it, the size of the index will grow almost linearly with the size of the table. When you have bloated indexes, that proportion will be very different. It's not unusual for a bloated index to be significantly larger than the actual data in the table. Accordingly, the first way you can monitor how bloated an index is by watching the index size relative to the table size, which is easy to check with this query:
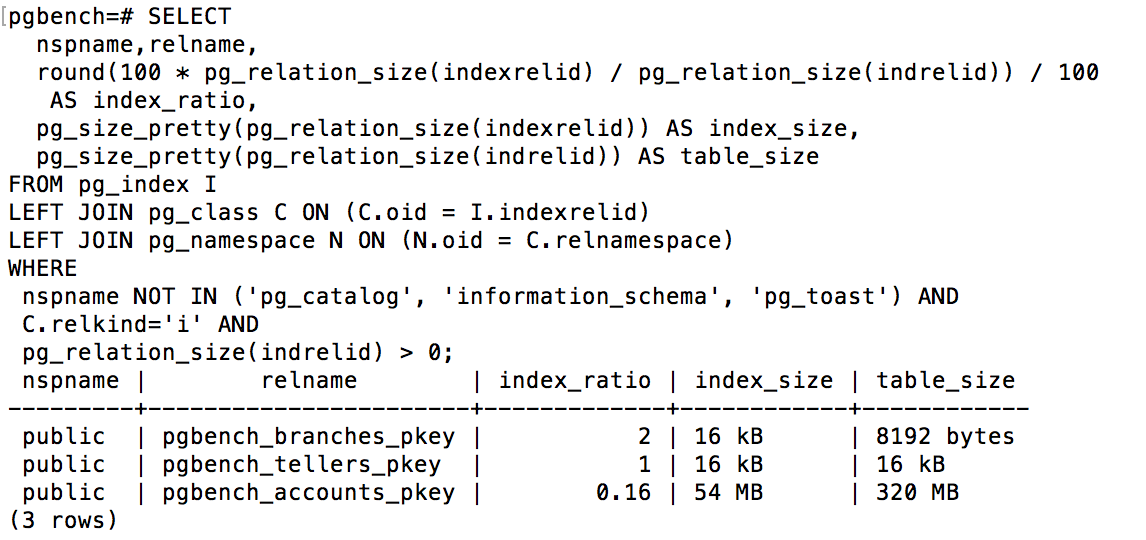
As an example of what this looks like when run, if you create a pgbench database with a scale of 25, the index will be 16% of the size of the table.
If you don't have that data available, it's possible to get a rough estimate of how much dead row bloat is in a table or an index by running some computations based on the size of various structures in the table and index. The PostgreSQL monitoring plug-in for Nagios, check_postgres, includes such an estimate, and some other sources have their own checks that are often derived from that original source. A full list of bloat checking utilities is available at http://wiki.postgresql.org/wiki/Index_Maintenance.
Note that for the case we have been looking at, the check_postgres index bloat test (as of version 2.14.3) doesn't estimate the bloat change as significant. You can see exactly what query it estimates that with by running the program in verbose mode, copying the code it executes, translating the \n characters in there to either spaces or carriage returns, and then pasting the result into psql:
$ ./check_postgres.pl --action bloat -db pgbench -v -v -v
$ psql -d pgbench -x
pgbench=# SELECT
current_database(), schemaname, tablename,
reltuples::bigint, relpages::bigint, otta
...
iname | accounts_pkey
ituples | 1250000
ipages | 5489
iotta | 16673
ibloat | 0.3
wastedipages | 0
wastedibytes | 0
wastedisize | 0 bytes
In general, so long as you have an unbloated reference point, monitoring the index to table size ratio will give you a more accurate picture of bloat over time than something working with the table statistics like check_postgres can provide.