Introduction
Imagine that a critical application in your company is having performance issues. This application is available to customers 24-7, and during business hours, the CPU and memory utilization reaches 100%. This is resulting in an increased response time for customers.
Around 10 years ago, a good migration plan to solve this issue would involve the procurement and deployment of new hardware resources for both the application and its databases, the installation of all required software and application code, performing all functional and performance quality analysis work, and finally, migrating the application. The cost of this would run into millions. However, nowadays, this issue can be resolved with new technologies that offer different approaches to customers – going Serverless is definitely one of them.
In this chapter, we'll start with an explanation of the serverless model, and get started with AWS and Lambda, the building blocks of a serverless applications on AWS. Finally, you'll learn how to create and run Lambda functions.
The Serverless Model
To understand the serverless model, let's first understand how we build traditional applications such as mobile applications and web applications. Figure 1.1 shows a traditional on-premises architecture, where you would take care of every layer of application development and the deployment process, starting with setting up hardware, software installation, setting up a database, networking, middleware configuration, and storage setup. Moreover, you would need a staff of engineers to set up and maintain this kind of on-premises setup, making it very time-consuming and costly. Moreover, the life cycle of these servers was no longer than 5-6 years, which meant that you would end up upgrading your infrastructure every few years.
The work wouldn't end there, as you would have to perform regular server maintenance, including setting up server reboot cycles and running regular patch updates. And despite doing all the groundwork and making sure that the system ran fine, the system would actually fail and cause application downtime. The following diagram shows a traditional on-premises architecture:

Figure 1.1 : Diagram of traditional on-premises architecture
The serverless model changes this paradigm completely, as it abstracts all the complexity attached with provisioning and managing data centers, servers, and software. Let's understand it in more detail.
The serverless model refers to applications in which server management and operational tasks are completely hidden from end users, such as developers. In the serverless model, developers are dedicated specifically to business code and the application itself, and they do not need to care about the servers where the application will be executed or run from, or about the performance of those servers, or any restrictions on them. The serverless model is scalable and is actually very flexible. With the serverless model, you focus on things that are more important to you, which is most probably solving business problems. The serverless model allows you to focus on your application architecture without you needing to think about servers.
Sometimes, the term "serverless" can be confusing. Serverless does not mean that you don't need any servers at all, but that you are not doing the work of provisioning servers, managing software, and installing patches. The term "the serverless model" just means that it is someone else's servers. Serverless architectures, if implemented properly, can provide great advantages in terms of lowering costs and providing operational excellence, thus improving overall productivity. However, you have to be careful when dealing with the challenges imposed by serverless frameworks. You need to make sure that your application doesn't have issues with performance, resource bottlenecks, or security.
Figure 1.2 shows the different services that are part of the serverless model. Here, we have different services for doing different kinds of work. We have the API Gateway service, a fully managed REST interface, which helps to create, publish, maintain, monitor, and secure APIs. Then, we have the AWS Lambda service that executes the application code and does all the computation work. Once computation is done, data gets stored in the DynamoDB database, which is again a fully managed service that provides a fast and scalable database management system. We also have the S3 storage service, where you can store all your data in raw formats that can be used later for data analytics. The following diagram talks about the serverless model:
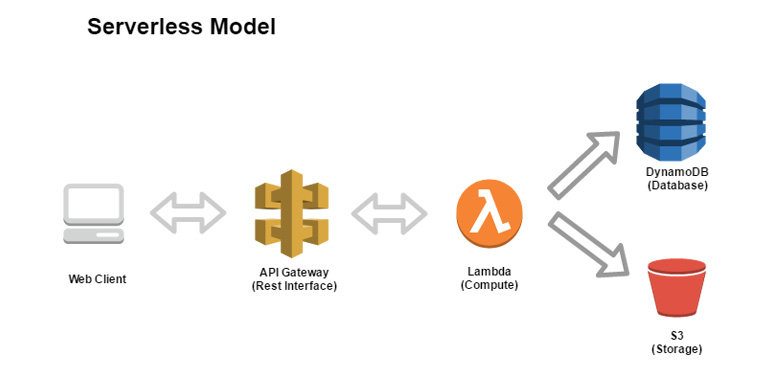
Figure 1.2 : The serverless model (using AWS services)
Serverless models have become quite popular in recent times, and many big organizations have moved their complete infrastructure to serverless architectures and have been running them successfully, getting better performance a much a lower cost. Many serverless frameworks have been designed, making it easier to build, test, and deploy serverless applications. However, our focus in this book will be on serverless solutions built on Amazon Web Services (AWS). Amazon Web Services is a subsidiary of Amazon.com that provides on-demand cloud service platforms.
Benefits of the Serverless Model
There are a number of benefits to using a serverless model:
- No server management: Provisioning and managing servers is a complex task and it can take anything from days to months to provision and test new servers before you can start using them. If not done properly, and with a specific timeline, it can become a potential obstacle for the release of your software onto the market. Serverless models provide great relief here by masking all the system engineering work from the project development team.
- High availability and fault tolerance: Serverless applications have built-in architecture that supports high availability (HA). So, you don't need to worry about the implementation of these capabilities. For example, AWS uses the concept of regions and availability zones to maintain the high availability of all AWS services. An availability zone is an isolated location inside a region and you can develop your application in such a way that, if one of the availability zones goes down, your application will continue to run from another availability zone.
- Scalability: We all want our applications to be successful, but we need to make sure that we are ready when there is an absolute need for scaling. Obviously, we don't want to spawn very big servers in the beginning (since this can escalate costs quickly), but we want to do it as and when the need occurs. With serverless models, you can scale your applications very easily. Serverless models run under the limits defined by you, so you can easily expand those limits in the future. You can adjust the computing power, the memory, or IO needs of your application with just a few clicks, and you can do that within minutes. This will help you to control costs as well.
- Developer productivity: In a serverless model, your serverless vendor takes all the pain of setting up hardware, networking, and installing and managing software. Developers need to focus only on implementing the business logic and don't need to worry about underlying system engineering work, resulting in higher developer productivity.
- No idle capacity: With serverless models, you don't need to provision computing and storage capacity in advance. And you can scale up and down based on your application requirements. For example, if you have an e-commerce site, then you might need higher capacity during festive seasons than other days. So, you can just scale up resources for that period only.
Moreover, today's serverless models, such as AWS, work on the "pay as you go" model, meaning that you don't pay for any capacity that you don't use. This way, you don't pay anything when your servers are idle, which helps to control costs.
- Faster time to market: With serverless models, you can start building software applications in minutes, as the infrastructure is ready to be used at any time. You can scale up or down underlying hardware in a few clicks. This saves you time with system engineering work and helps to launch applications much more quickly. This is one of the key factors for companies adopting the serverless model.
- Deploy in minutes: Today's serverless models simplify deployment by doing all the heavy lifting work and eliminating the need for managing any underlying infrastructure. These services follow DevOps practices.
Introduction to AWS
AWS is a highly available, reliable, and scalable cloud service platform offered by Amazon that provides a broad set of infrastructure services. These services are delivered on an "on-demand" basis and are available in seconds. AWS was one of the first platforms to offer the "pay-as-you-go" pricing model, where there is no upfront expense. Rather, payment is made based on the usage of different AWS services. The AWS model provides users with compute, storage, and throughput as needed.
The AWS platform was first conceptualized in 2002 and Simple Queue Service (SQS) was the first AWS service, which was launched in 2004. However, the AWS concept has been reformulated over the years, and the AWS platform was officially relaunched in 2006, combining the three initial service offerings of Amazon S3 (Simple Storage Service): cloud storage, SQS, and EC2 (Elastic Compute Cloud). Over the years, AWS has become a platform for virtually every use case. From databases to deployment tools, from directories to content delivery, from networking to compute services, there are currently more than 100 different services available with AWS. More advanced features, such as machine learning, encryption, and big data are being developed at a rapid pace. Over the years, the AWS platform of products and services has become very popular with top enterprise customers. As per current estimates, over 1 million customers trust AWS for their IT infrastructure needs.
AWS Serverless Ecosystem
We will take a quick tour of the AWS serverless ecosystem and briefly talk about the different services that are available. These services will be discussed in detail in future chapters.
Figure 1.4 shows the AWS serverless ecosystem, which is comprised of eight different AWS services:
- Lambda: AWS Lambda is a compute service that runs code in response to different events, such as in-app activity, website clicks, or outputs from connected devices, and automatically manages the compute resources required by the code. Lambda is a core component of the serverless environment and integrates with different AWS services to do the work that's required.
- Simple Storage Service (S3): Amazon S3 is a storage service that you can use to store and retrieve any amount of information, at any time, from anywhere on the web. AWS S3 is a highly available and fault-tolerant storage service.
- Simple Queue Service (SQS): Amazon SQS is a distributed message queuing service that supports message communication between computers over the internet. SQS enables an application to submit a message to a queue, which another application can then pick up at a later time.
- Simple Notification Service (SNS): Amazon SNS is a notification service that coordinates the delivery of messages to subscribers. It works as a publish/subscribe (pub/sub) form of asynchronous communication.
- DynamoDB: Amazon DynamoDB is a NoSQL database service.
- Amazon Kinesis: Amazon Kinesis is a real-time, fully managed, and scalable service.
- Step Functions: AWS Step Functions make it easy to coordinate components of distributed applications. Suppose you want to start running one component of your application after another one has completed successfully, or you want to run two components in parallel. You can easily coordinate these workflows using Step Functions. This saves you the time and effort required to build such workflows yourself and helps you to focus on business logic more.
- Athena: Amazon Athena is an interactive serverless query service that makes it easy to use standard SQL to analyze data in Amazon S3. It allows you to quickly query structured, unstructured, and semi-structured data that's stored in S3. With Athena, you don't need to load any datasets locally or write any complex ETL (extract, transform, and load), as it provides the capability to read data directly from S3. We will learn more about AWS Athena in Chapter 4, Serverless Amazon Athena and the AWS Glue Data Catalog.
Here's a diagram of the AWS serverless ecosystem:

Figure 1.3 : The AWS serverless ecosystem Ecosystem
AWS Lambda
AWS Lambda is a serverless computing platform that you can use to execute your code to build on-demand, smaller applications. It is a compute service that runs your backend code without you being involved in the provisioning or managing of any servers in the background.
The Lambda service scales automatically based on your usage and it has inbuilt fault-tolerance and high availability, so you don't need to worry about the implementation of HA or DR (disaster recovery) with AWS Lambda. You are only responsible for managing your code, so you can focus on the business logic and get your work done.
Once you upload your code to Lambda, the services handles all the capacity, scaling, patching, and infrastructure to run your code and provides performance visibility by publishing real-time metrics and logs to Amazon CloudWatch. You select the amount of memory allocation for your function (between 128 MB and 3 GB). Based on the amount of memory allocation, CPU and network resources are allocated to your function. You could also say that AWS Lambda is a function in code that allows stateless execution to be triggered by events. This also means that you cannot log in to actual compute instances or customize any underlying hardware.
With Lambda, you only pay for the time that your code is running. Once execution is completed, the Lambda service goes into idle mode and you don't pay for any idle time. AWS Lambda follows a very fine-grained pricing model, where you are charged for compute time in 100 ms increments. It also comes with a Free Tier, with which you can use Lambda for free until you reach a certain cap on the number of requests. We will study AWS Lambda pricing in more detail in a later section.
AWS Lambda is a great tool for triggering code in the cloud that functions based upon events. However, we need to remember that AWS Lambda (in itself) is stateless, meaning that your code should run as you develop it in a stateless manner. However, if required, a database such as DynamoDB can be used. Over the years, AWS Lambda has become very popular for multiple serverless use cases, such as web applications, data processing, IoT devices, voice-based applications, and infrastructure management.
Supported Languages
Lambda is stateless and serverless. You should develop your code so that it runs in a stateless manner. If you want to use other third-party services or libraries, AWS allows you to zip up those folders and libraries and give them to Lambda in a ZIP file, which in turn enables other supportive languages that you would like to use.
AWS Lambda supports code written in the following six languages:
- Node.js (JavaScript)
- Python
- Java (Java 8 compatible)
- C# (.NET Core)
- Go
- PowerShell
Note
AWS Lambda could change the list of supported languages at any time. Check the AWS website for the latest information.
Exercise 1: Running Your First Lambda Function
In this exercise, we'll create a Lambda function, specify the memory and timeout settings, and execute the function. We will create a basic Lambda function to generate a random number between 1 and 10.
Here are the steps for completion:
- Open a browser and log in to the AWS console by going to this URL: https://aws.amazon.com/console/.

Figure 1.4 : The AWS console
- Click on Services at the top-left of the page. Either look for Lambda in the listed services or type Lambda in the search box, and click on the Lambda service in the search result:

Figure 1.5 : AWS services
- Click on Create a function to create your first Lambda function on the AWS Lambda page:

Figure 1.6 : The Get started window
- On the Create function page, select Author from scratch:

Figure 1.7 : The Create function page
- In the Author from scratch window, fill in the following details:
Name: Enter myFirstLambdaFunction.
Runtime: Choose Node.js 6.10. The Runtime window dropdown shows the list of languages that are supported by AWS Lambda, and you can author your Lambda function code in any of the listed options. For this exercise, we will author our code in Node.js.
Role: Choose Create new role from one or more template. In this section, you specify an IAM role.
Role name: Enter lambda_basic_execution.
Policy templates: Select Simple Microservice permissions:

Figure 1.8 : The Author from scratch window
- Now, click on Create function. You should see the message shown in the following screenshot:

Figure 1.9 : Output showing Lambda function creation
So, you have created your first Lambda function, but we have yet to change its code and configuration based on our requirements. So, let's move on.
- Go to the Function code section:

Figure 1.10 : The Function code window
- Use the Edit code inline option to write a simple random number generator function.
- The following is the required code for our sample Lambda function. We have declared two variables: minnum and maxnum. Then, we are using the random() method of the Math class to generate a random number. Finally, we call "callback(null, generatednumber)". If an error occurs, null will be returned to the caller; otherwise, the value of the generatednumber variable will be passed as an output:
//TODO implement
let minnum = 0;
let maxnum = 10;
let generatednumber = Math.floor(Math.random() * maxnum) + minnum
callback(null, generatednumber);
- In the Basic settings window, write myLambdaFunction_settings in the Description field, select 128 MB in the Memory field, and have 3 sec in the Timeout field:

Figure 1.11 : The Basic settings window
- That's it. Click on the Save button in the top-right corner of the screen. Congratulations! You have just created your first Lambda function:

Figure 1.12 : Output of the Lambda function created
- Now, to run and test your function, you need to create a test event. This allows you to set up event data to be passed to your function. Click on the dropdown next to Select a test event in the top-right corner of the screen and select Configure test event:

Figure 1.13 : Lambda function Test window
- When the popup appears, click on Create new test event and give it a name. Click on Create and the test event gets created:

Figure 1.14 : The Configure test event window
- Click on the Test button next to test events and you should see the following window upon successful execution of the event:

Figure 1.15 : The Test execution window
- Expand the Details tab and more details about the function execution appear, such as actual duration, billed duration, actual memory used, and configured memory:
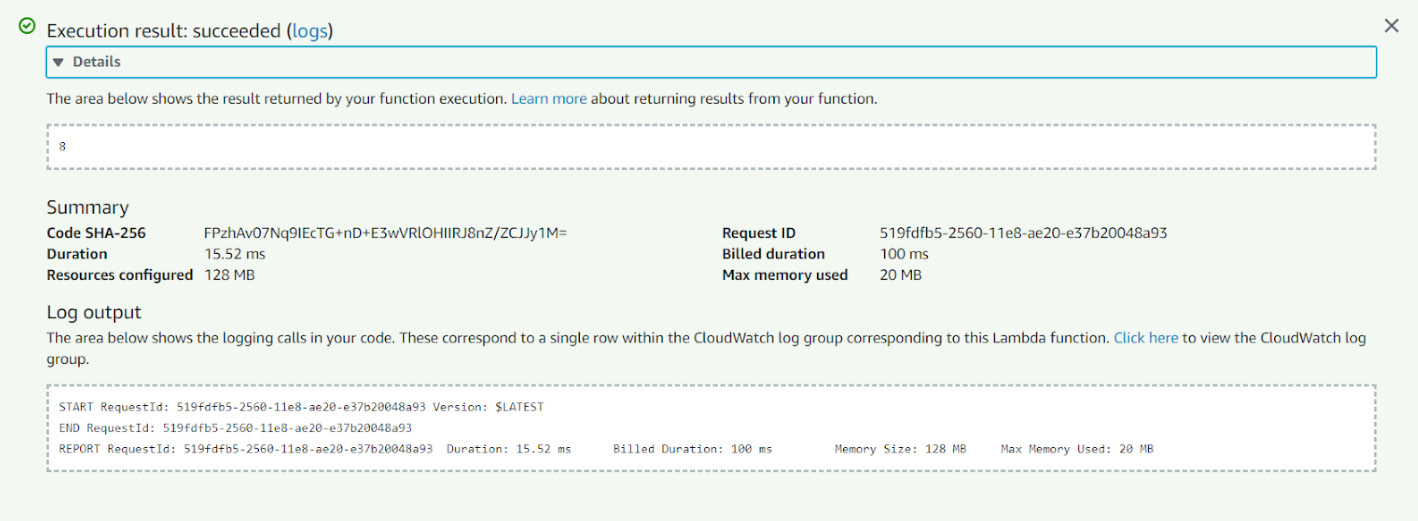
Figure 1.16 : The Details tab
You don't need to manage any underlying infrastructure, such as EC2 instances or Auto Scaling groups. You only have to provide your code and let Lambda do the rest of the magic.
Activity 1: Creating a New Lambda Function that Finds the Square Root of the Average of Two Input Numbers
Create a new Lambda function that finds the square root of the average of two input numbers. For example, the two numbers provided are 10 and 40. Their average is 25 and the square root of 25 is 5, so your result should be 5. This is a basic Lambda function that can be written using simple math functions.
Here are the steps for completion:
- Follow the exercise that we just completed before this activity.
- Go to the AWS Lambda service and create a new function.
- Provide the function name, runtime, and role, as discussed in the previous exercise.
- Under the section on Function code, write the code to find the square root of the average of two input numbers. Once done, save your code.
- Create the test event and try to test the function by executing it.
- Execute the function.
Note
The solution for this activity can be found on page 152.
Limits of AWS Lambda
AWS Lambda imposes certain limits in terms of resource levels, according to your account level. Some notable limits imposed by AWS Lambda are as follows:
- Memory Allocation: You can allocate memory to your Lambda function with a minimum value of 128 MB and a maximum of 3,008 MB. Based on memory allocation, CPU and network resources are allocated to the Lambda function. So, if your Lambda function is resource-intensive, then you might like to allocate more memory to it. Needless to say, the cost of a Lambda function varies according to the amount of memory allocated to the function.
- Execution Time: Currently, the Lambda service caps the maximum execution time of your Lambda function at 15 minutes. If your function does not get completed by this time, it will be automatically be timed out.
- Concurrent Executions: The Lambda service allows up to 1000 total concurrent executions across all functions within a given region. Depending on your usage, you may want to set the concurrent execution limit for your functions, otherwise the overall costs may escalate very soon.
Note
If you want to learn more about other limits of Lambda functions, go to https://docs.aws.amazon.com/lambda/latest/dg/limits.html#limits-list.
AWS Lambda Pricing Overview
AWS Lambda is a serverless compute service and you only pay for what you use, not for any idle time. There is a Free Tier associated with Lambda pricing. We will discuss the Lambda Free Tier in the next section.
To understand the AWS billing model for Lambda, you first need to understand the concept of GB-s.
1 GB-s is 1 Gigabyte of memory used per second. So, if your code uses 5 GB in 2 minutes, and then 3 GB in 3 minutes, the accumulated memory usage would be 5*120 + 3*180 = 1140 GB seconds.
Note
The prices for the AWS services discussed in this section and in this book are current at the time of writing, as AWS prices may change at any time. For the latest prices, please check the AWS website.
Lambda pricing depends on the following two factors:
- Total Request Count: This is the total number of times the Lambda function has been invoked to start executing in response to an event notification or invoke call. As part of the Free Tier, the first 1 million requests per month are free. There is a charge of $0.20 for 1 million requests beyond the limits of the Free Tier.
- Total Execution Time: This is the time taken from the start of your Lambda function execution until it either returns a value or terminates, rounded up to the nearest 100 ms. The price for execution time varies with the amount of memory allocated to your function. If you want to understand how the cost of total execution time varies with the total amount of memory allocated to the Lambda function, go to https://aws.amazon.com/lambda/pricing:

Figure 1.17 : Lambda pricing
Lambda Free Tier
As part of the Lambda Free Tier, you can make 1 million free requests per month. You can have 400,000 GB-seconds of compute time per month. Since function duration costs vary with the allocated memory size, the memory size you choose for your Lambda functions determines how long they can run in the Free Tier.
Note
The Lambda Free Tier gets adjusted against monthly charges, and the Free Tier does not automatically expire at the end of your 12-month AWS Free Tier term, but is available to both existing and new AWS customers indefinitely.
Activity 2: Calculating the Total Lambda Cost
We have a Lambda function that has 512 MB of memory allocated to it and there were 20 million calls for that function in a month, with each function call lasting 1 second. Calculate the total Lambda cost.
Here's how we calculate the cost:
- Note the monthly compute price and compute time provided by the Free Tier.
- Calculate the total compute time in seconds.
- Calculate the total compute time in GB-s.
- Calculate the monthly billable compute in GB- s. Here's the formula:
Monthly billable compute (GB- s) = Total compute – Free Tier compute
- Calculate the monthly compute charges in dollars. Here's the formula:
Monthly compute charges = Monthly billable compute (GB-s) * Monthly compute price
- Calculate the monthly billable requests. Here's the formula:
Monthly billable requests = Total requests – Free Tier requests
- Calculate the monthly request charges. Here's the formula:
Monthly request charges = Monthly billable requests * Monthly request price
- Calculate the total cost. Here's the formula:
Monthly compute charge + Monthly request charges
Note
The solution for this activity can be found on page 153.
Additional Costs
While estimating Lambda costs, you must be aware of additional costs. You will incur costs as part of Lambda integration with other AWS services such as DynamoDB or S3. For example, if you are using the Lambda function to read data from an S3 bucket and write output data into DynamoDB tables, you will incur additional charges for read from S3 and writing provisioned throughput to DynamoDB. We will study more about S3 and DynamoDB in Chapter 2, Working with the AWS Serverless Platform.
In summary, it may not seem like running Lambda functions costs a lot of money, but millions of requests and multiple functions per month tend to escalate the overall cost.
Summary
In this chapter, we focused on understanding the serverless model and getting started with AWS and Lambda, the first building block of a serverless application on AWS. We looked at the main advantages and disadvantages of the serverless model and its use cases. We explained the serverless model, and worked with AWS serverless services. We also created and executed the AWS Lambda function.
In the next chapter, we'll look at the capabilities of the AWS Serverless Platform and how AWS supports enterprise-grade serverless applications, with and without Lambda. From Compute to API Gateway and from storage to databases, the chapter will cover the fully managed services that can be used to build and run serverless applications on AWS.