Intelligent transportation systems have been developed throughout the years mainly for the purpose of improving road safety. The so-called “intelligent” vehicles were thus equipped with sensors that assist the driving for the antiblocking system in case of braking (Anti-lock braking system (ABS)), route guiding, collision detection or the antiskidding mechanism (ESP – electronic stability program). Subsequently, vehicles were equipped with radio communication, which enabled them to communicate either with one another via (vehicle-to-vehicle (V2V) communication), or with the road side unit (RSU) installed along the road via vehicle-to-infrastructure (V2I) communication [PET 11]. In the field of road safety, communications help extend the detection range of embedded radar sensors. For example, a vehicle that detects the presence of black ice will be able to communicate this information to the vehicles that follow it. Having been warned, the drivers will thus be able to slow down earlier and therefore avoid skidding.
By generalizing intervehicular communications, we can constitute vehicular ad hoc networks (VANETs), which are a particular case of mobile ad hoc networks (MANETs). The VANETs thus facilitate the exchange of information between several vehicles, regarding the state of the road or the traffic in a given geographical area. However, it has been established that in the case of low vehicular density, a VANET has not always been a connected graph [SCH 06, WIS 07] and that it has been partitioned into several groups of vehicles disconnected from one another [MAB 06]. On the contrary, if the density becomes significant such as in a traffic jam, the network performance – in terms of offered traffic and delay – plummets. Finally, if the network extends upon several kilometers on the highway, the delay and the rate of packet loss increase with distance. These last two problems are strongly related to the issue of scalability, which we will discuss later on.
Besides intelligent transportation system (ITS) applications, user-oriented applications involving vehicular networks have also been developed. They include classic Internet applications (Web surfing, e-mail, computer games, Internet Protocol television (IPTV), etc.) as well as geolocalization applications for guidance or tourism. Using V2I communications, these applications need to access an operated infrastructure network, such as a long-distance mobile network, 3G or LTE (Long Term Evolution). However, the capacity of these mobile networks is often quite limited on the rural areas that traverse the highways. In addition, because the vehicles drive at high speed, the communications suffer from frequent handovers and run at a great risk of breaking up radio links. VANETs can thus be used to fix these problems by extending the coverage of operated mobile networks with an ad hoc part, we will therefore refer to as V2V2I for Vehicle-to-Vehicle-to-Infrastructure.
In this study, we are mainly interested in V2V2I communications, with a focus on organizing the ad hoc part of the network into groups of vehicles or clusters, each of them organized around a main cluster called a clusterhead. We aim to decrease the handover overhead for the mobile network. Indeed, we propose that the communications within the group be done in an ad hoc manner, whereas the communications between the groups should pass through the mobile network. The clusterhead therefore works as a gateway between its group and the mobile network. Being the only mobile that has access to a mobile network, the handover overhead reaching the base will be diminished. By using these principles, we have developed a self-organization protocol, which we will present in section 3.5.
The formation of groups is a problem of self-organization in ad hoc networks, known as clustering or network partitioning. Numerous works have been published on the subject, for ad hoc networks, sensors or MANETs [YU 05, AGA 09]. The main objective of the partitioning of an ad hoc network is to improve the protocol scalability. Thus, by dividing the space, the network becomes easier to manage and the coordination messages are no longer exchanged between all the nodes of the network, but only between the nodes of the group. If the nodes are mobile, they can change groups throughout time, which triggers the need for structural updates. Too frequent updates can make the performance of the hierarchical approach plummet, so it becomes a less interesting approach. We will therefore try to build groups that are as stable as possible, by choosing effective regrouping criteria. The partitioning approaches are well adapted to vehicular networks because the dynamics of road traffic triggers the formation of “natural” clusters at the intersections, or of convoys on the highway. For vehicular networks, as for ITS applications, the spatial or geographical dimension is an important factor. We show that the geographical position of vehicles is one of the important criteria in cluster-based protocols for vehicular networks. Since vehicles move in a space constrained by routes, other criteria are also significant such as speed and direction. Furthermore, in the context of radio communication, the quality of a connection or its stability is also important.
This chapter begins with an overview of the basic notions of partitioning in ad hoc networks as well as a presentation of the best well-known clustering algorithms. We will then review several proposals that are specific to vehicular networks. Then, we will present in detail CONVOY, our convoy formation protocol and its different algorithms. Finally, we will present an performance study of this protocol via simulations.
The organization of an ad hoc network into node groups is known as clustering or network partitioning [YU 05]. The partitioning of the network organizes the network into node groups or clusters. Within the node group thus built, one particular node plays a special role: the clusterhead, or the leader of the group, organizes the communications within the cluster, serves as a gateway for communication with the other groups and connects them with one another.
Partitioning presents us with several advantages; the first one is the scalability of protocols. The division of the space indeed makes the network easier to manage and decreases the coordination messages exchanged between all the nodes. For example, the hierarchical routing uses a routing that is internal to the cluster, and a different type of routing between the clusters. The second advantage is the reduction of the execution charge of high level protocols on all the individual nodes. Finally, from the point of view of radio transmission, the partitioning while limiting the interactions between nodes also allows us to limit access collisions and interferences.
The first stage of partitioning is the clustering algorithm. The clustering algorithms can be classified depending on their way of controlling:
The clusterhead is determined by a choosing algorithm, called clusterhead election, that can constitute the initialization of the cluster. Because the vehicle moves, periodic cluster reformations are needed and membership updates are performed using node adding functions or node retrieval functions.
In an ad hoc network, the partitioning approaches are naturally distributed and need numerous message exchanges for the formation and the maintenance of clusters. This cost of the partitioning is called “clustering overhead”. The objective of a clustering algorithm will therefore be to limit this overhead as much as possible while ensuring the stability of the formed structure. Another desirable property that is researched in the case of node mobility is the capacity for quickly adapting to the structural changes that take place when the clusterhead or one of the nodes leaves the group, or when the radio connections are cut.
The distributed clustering algorithm (DCA) and distributed mobility-adaptive clustering (DMAC) algorithm [BAS 99] allow the formation of one-hop clusters, whose members neighbor at least one clusterhead. Lowest ID clustering was generalized to a weight-based clustering technique, referred to as DCA in [ALM 10]. In DCA, each node is assumed to have a unique weight (hence the weights are totally ordered) instead of just the node ID, and the clustering algorithm uses the weights instead of the IDs for the selection of clusterheads. However the technique of weight assignment has not been discussed. In DCA, each node is assumed to have a unique weight that can represent the degree of a node, the inverted value of its average speed, an identifier, etc. Hence, the clusterhead is defined as the heaviest weight node. This algorithm is well adapted to ad hoc networks whose topology is static or quasi-static. The DMAC algorithm is better adapted to dynamic networks, because it introduces an algorithm for the maintenance of the cluster, which reacts to the changes of medium access control (MAC) level topologies: new links and link failures. Moreover, it authorizes a larger number of clusters, thus ensuring a greater stability of the hierarchical structure. With a one-hop cluster, the intracluster communications do not need any routing and are extremely simplified. However, these algorithms can lead to a large number of clusters. Finally, a one-hop cluster will have limited coverage, which will trigger frequent updates of the cluster in case of mobility. To minimize the number of clusters, the authors of [NOC 03] have generalized the one-hop algorithm to k-hops clustering. To discover the proximity to k-hops, the cluster update messages are broadcast with a maximum number of hops or Time To Live delay (TTL) equal to k.
It is also possible to limit the size of a cluster by defining the maximum number of nodes in a cluster. Indeed, maintaining clusters of a balanced size facilitates the balance of communications between the nodes and reduces the collisions within the cluster. The algorithm presented in [OHT 03] limits the size of the cluster. If the cluster is too small, a node from the outskirts of a neighboring larger node is then recruited.
The formation of clusters in an ad hoc network is not an end in itself but a means of improving the ad hoc routing by limiting its research time or its signaling overhead. Thus, Niu et al. [NIU 06] propose an ad hoc routing protocol based on a cluster formation algorithm with k-hops. The ad hoc network is hierarchized upon two levels: the higher level (the level of the clusters) and the lower level (the level of the nodes). At the cluster level, the routing is proactive: each clusterhead keeps a graph of the set of clusterheads of network clusterheads and a list of the members of the associated cluster. Another strategy for improving the performance of a reactive routing is proposed in [OHT 07] with the formation of clusters according to [OHT 03]. A clusterhead builds a minimum spanning tree based on the topology information of its cluster, information obtained from the messages sent periodically by the members of its cluster. The messages are disseminated throughout the tree and not by inundation, thus reducing the overhead.
The partitioning of the network has two levels of communication: intracluster communication and intercluster communication. The intercluster communications are often long-distance and federate the clusters among themselves. Most often, they are carried out due to a single node per cluster called a clusterhead. We usually consider the following communication scenario: the messages for a node of the same cluster are broadcast in the cluster whereas those for a faraway node are transmitted to the clusterhead that will further transmit them to the target cluster. The choice of the clusterhead within a cluster can be made due to certain characteristics (i.e. double radio interface and throughout), which justifies this gateway role, or by a distributed election algorithm between the nodes that discerns between these characteristics based on one of such criteria: identifier, remaining power, the shortest distance, etc. In the state of art that we will soon present, we specify the way in which the clusterhead is chosen according to the regrouping criterion. We will now specify the differences between a VANET and a fixed or little mobile ad hoc network.
As we have already mentioned, clustering approaches are well adapted to vehicular networks because of the formation of “natural” groups at the intersections or of convoys on the highway. The difficulty in clustering on vehicular networks is to ensure the stability of the constituted groups. If we build a group according to the single criterion of geographical localization, the difference of speed between the vehicles runs the risk of immediately triggering an update, with adding and retrieving members in the group. Too frequent updates increase the clustering overhead and also diminish its interest. This is why a lot of hierarchical protocols for VANET not only consider spatial information such as the position or the quality of radio communication, but also temporal information regarding the behavior of the vehicles, such as the direction of their movement and their speed. The result is a lower updating rate, that is a property that certain works refer to as the “resilience” property of the network [SOU 10]. These clustering protocols allow us to introduce stable structures in a very unstable environment.
In the following section we present the main spatial and temporal regrouping criteria as well as several routing protocols called “mobility-based clustering”, which have used or combined these criteria in order to build stable clusters.
In a highly dynamic network such as VANET, the mobility of the nodes jumbles up the hierarchical structure and triggers frequent reorganizations of the groups [GHO 08]. This instability results in a larger number of exchanged messages and in poor performances. The stability property of the clusters is of primary importance for these dynamic networks. In [LEE 10], the comparison of the routing protocols for the VANETs shows the superiority of the geographical or position-based protocols. To maintain the stability of clusters, the position of the vehicles is not enough and many propositions use both spatial and temporal information, which allows us to represent the particular dynamic of the moving vehicles and to build clusters that have a longer lifetime. The main objective of the protocols called “clustering mobility-based” protocols is then to group together the vehicles that have the same dynamics, whether they are spatial or temporal. The spatial dependencies are represented by the position of the vehicle and its distance from another point, its moving direction or the quality of its radio link with another vehicle. The temporal dependencies are the moving speed of the vehicle and, above all, the relative speed between two vehicles.
For several years now, vehicles have often been equipped with global positioning system (GPS) receivers, which give the latitude and longitude coordinates of the vehicle. However, the precision of this mainstream equipment is only 5–10 m. The technologies integrated in intelligent vehicles now allow us to improve the positioning accuracy especially due to map positioning, and the sensors embedded in the vehicle such as distance radars and the odometer [CAP 06, DEA 09]. Different propositions of clusters based on the position or mobility use these precise localization techniques.
We also assume that the neighbor discovery procedure is always available in considered vehicular ad hoc protocols. Thus, each node is able to inform its neighbors while periodically disseminating HELLO messages throughout its radio coverage area, and therefore is able to know all of its neighbors. These HELLO messages contain at least the node’s identifier, but also state information, such as its position and the list of its neighbors. The position of the vehicle is therefore known due to its embedded GPS device but this position cannot, by itself, act as a regrouping criterion because vehicles change their position very quickly and therefore, change their cluster just as quickly. In the following sections, we present clustering algorithms based on spatial or temporal criteria that have been proposed for improving the routing protocols of vehicular networks.
Almalag and Weigle [ALM 10] refine the position of the vehicle with the exact knowledge of the lane that the vehicle drives on. The lane is obtained by checking the position of the vehicle against a precise map of the streets. A cluster is built for each lane depending on its future direction after an intersection “turn left, turn right or straight ahead”; this is also helpful for emergency brake applications.
Another regrouping criterion that results from the position of the vehicles is the relative distance between the vehicles or their pertaining to a given geographical area [BON 07, JAY 12]. The objective is to limit the message dissemination in a constrained space, whether it be for the routing or for the ITS applications whose coverage range is local. The Euclidean distance between two nodes is calculated as the difference between their respective coordinates. However, there is an oscillatory effect upon the distance between the vehicles. In [BLU 03], this effect is taken into account with a maximal (geographical) distance criterion between two clusterheads and in [JAY 12], the authors also add a criterion based on the point where the vehicle exits the road.
It has been noted very early that vehicles moving in opposite directions could not communicate for too long [DUC 07, MEN 07]. Even worse, when regrouped in the same cluster, these vehicles stay for a very short period in the cluster and make the structure unstable. The direction is obtained from the history of the vehicle’s positions, with or without a map, or due to the motion angle compared to the north. Several recent works thus use the direction as a criterion for regrouping vehicles.
In [TAL 06], the vehicle-heading-based routing protocol (VHRP) creates four groups of vehicles according to their direction, with the aim of building stable routes that preferably cross between the vehicles of the same groups. The clusterhead is the head vehicle. Inside the group, a road is established between all of the vehicles within the same group. Simulation shows that by varying the speed, VHRP reduces packet loss in comparison with classic reactive protocols. However, the analysis has not been carried out sufficiently in depth. Fan et al. [FAN 07] extend the work of [FAN 05] for considering the direction of the vehicles’ movement: two vehicles going in opposite directions cannot be in the same cluster. The election of the clusterhead is based on the previous situation of the nodes, old clusterheads being preferred over new clusterheads.
In [MEN 07], the movement prediction-based routing (MOPR) protocol predicts future positions of the vehicles for each routing pathway between a source and a destination relying on their positions, their speeds and their directions. Furthermore, MOPR is capable of estimating the lifetime of radio connections in the network and then chooses the most stable route between the source and the destination, a route that is made of the most stable links. MOPR is seen as a function that was integrated in different ad hoc routing protocols, such as ad hoc on-demand distance vector (AODV) or greedy perimeter stateless routing (GPSR). This approach was revisited and applied to the constitution of clusters with a longer lifetime in [JAY 12]. This algorithm uses not only the lifetime of the connections, but also the position, speed and direction criteria for calculating a score that allows us to select the best hop for forwarding a packet. In the beginning, all of the nodes are in the same cluster, and the cluster is then divided into smaller and smaller groups, until each group meets the distance condition (250 m) and the vehicle number condition. Within each minicluster, the score is used for choosing the node that will forward the packet.
The vehicle speed was also taken into account in order to regroup the vehicles in convoy because a convoy of vehicles with quasi-identical speed is a relatively stable structure. The mobility criterion is more precise and is called, depending on the work, aggregate mobility or relative speed. Along with direction, it is the criterion that has most improved the stability of clusters. Thus, Basu et al. [BAS 01] have introduced the concept of aggregate mobility in order to improve the stability of clusters in their MOBIC algorithm. The authors propose a relative mobility metric system for MANETs. Relative mobility is measured using the received signal strength (RSS), which is an indication of the distance between the sender and the receiver. The strength received is exchanged between the nodes by means of the neighbor discovery procedure. The relation between two successive measures provides the relative mobility metric. The election of the clusterhead is made according to the lowest ID algorithm where the identifier is the variation of the relative mobility. The changing of the clusterhead is realized if two clusterheads are within the range of each other and the two clusters are merged together. A member that is out of the range of its clusterhead leaves the cluster and can join another cluster. Other propositions have improved this basic idea. Thus, in [FAN 05], the authors take into account the speed or the position of the neighboring vehicles in the election algorithm of the clusterhead (lowest ID and highest degree k-hops), in order to increase the stability of the cluster.
Shea et al. [SHE 09] regroup the vehicles with the help of an affinity function that considers the position of the node, its direction and its speed, all at the same time. For different update intervals of the cluster and different speeds, [SHE 09] displays stability metrics such as the average lifetime of the clusterhead, the average lifetime of the members, the clusterhead change rate and the average number of clusters compared to the MOBIC protocol [BAS 01]. The results show that their approach indeed substantially improves cluster stability.
Souza et al. [SOU 10] uses the same principle but proposes a more precise mobility metric called aggregate local mobility (ALM) always with the hypothesis that every vehicle knows its geographical position. Similarly, the vehicles include their position in the HELLO messages disseminated in their neighborhood. The ratio between two successive distances defines the relative mobility between two vehicles. ALM forms coherent vehicle clusters of the same speed and the same direction whose performance analysis demonstrates their stability. In [RAW 09], the authors use the same regrouping criteria and develop a new multicriteria leader election algorithm, then show the validity of the approach via modeling.
As we have just seen, when we have a lot of information on the movement and the position of vehicles, it is possible to conceive the hierarchical protocols that are stable and that minimize the overhead of the cluster updates. However, taking into account multiple criteria leads to complex algorithms. This aspect is never mentioned in the references that we cite. In vehicle networks, the partitioning of the network is not only used for improving routing but it is also used at other levels of the protocol architecture. Thus, we find clustering techniques at MAC level and at the application level for the localization or for other applications in the field of transport. We describe these propositions in the following section.
MAC hierarchic protocols seek to alleviate several problems induced by the strong mobility of vehicles. By regrouping the vehicles of comparable speed in clusters, we can reduce the relative speed (as defined in section 3.3.6) of communicating nodes. They bring a certain improvement for a dense network of vehicles, for example during a traffic jam. The limited number of nodes that are competing in the cluster reduces the contentions and thus the congestion of the network, and minimizes the influence of the hidden terminal problem. The Quality-of-Service can, moreover, be guaranteed inside the cluster.
The cluster-based medium access control (CBMAC) protocol [GUN 07] was one of the first hierarchical MAC protocols to be proposed. The members of the cluster come inside the cluster and leave the cluster depending on a weight, which in turn depends on their speed, their distance from the clusterhead or their connectivity. The role of the clusterhead is then to allocate the shared bandwidth using the time division multiple access (TDMA) scheme to the different members of the cluster. [RAW 08] and [SHE 09] are two other examples of the use of clustering that improves the MAC protocol.
Applications for the use in transport (ITS) often have geographically limited coverage, whether with regard to road safety or the state of road traffic. The coordinates of the sender (latitude and longitude) are thus transferred at the same time as this information. We have seen that it was easy to know the position of the vehicle itself by means of a geolocation device (GPS). On the contrary, it is necessary to use a location service in order to know the position of a faraway destination. This research is costly because it is most often done in a greedy manner [DAS 05]. The cluster formation techniques can improve the scaling of a geographical location protocol in a vehicular network. In [SAN 06], the authors propose a two-hop cluster formation algorithm with clusterhead election, which can serve as a gateway. The overhead of the localization is diminished because only the gateway nodes transmit the localization requests.
Another family of transport applications uses the dissemination of traffic data or security data in a limited area. For example, the floating car data (FCD) applications [LIN 06] consist of collecting the different information produced by the vehicle sensors (position, speed and direction) and of disseminating them to neighboring vehicles in such a way as to enrich global knowledge of the road scene. Among the hierarchical approaches developed for data dissemination, we have chosen to present: [MAS 11b], [OHT 12] and [REM 12]. In [MAS 11a], the authors consider a dissemination application that seeks to dynamically control the signaling lights at the intersections. This dissemination relies on two hierarchical protocols called Clustering in Direction in Vehicular Environment (C-DRIVE) and Modified C-DRIVE (MC-DRIVE) [MAS 11b], whose clusters are made of the vehicles close to the intersection and depending on their future direction after the intersection (left, right, straight ahead and U-turn). The size of the cluster is limited to a certain distance from the intersection. At this distance, each vehicle disseminates a HELLO message containing its identifier, its direction and its driving lanes provided that it seeks another vehicle in front of it. The two protocols differ in their way of choosing the clusterhead.
In [OHT 12], the authors propose a cluster-based data transfer scheme, using the position and the direction of the movement of vehicles. Inside a cluster, the data packets are disseminated epidemically starting from the clusterhead and ending with the destination vehicle. When two clusters are within range of each other, each cluster decides if it must or must not transfer its packets depending on their position, their direction and the position of the destination. The construction and the maintenance of clusters are not detailed by the authors.
In [REM 12], the authors also regard the FCD-type dissemination applications for the fourth-generation mobile network standard, LTE Advanced. Taking advantage of the fact that the LTE standard intrinsically regards the communication between the terminals (and thus of the signaling), the LTE4V2X protocol forms the groups in a centralized manner, via the base station (or e-NodeB) [REM 11]. The vehicles are supposed to dispose of an LTE interface and an IEEE 802.11p interface at the same time. The double objective is to decrease the load of the traffic going upward toward the base station and to extend the network coverage due to the local communications between vehicles. The formation of the cluster takes into account two criteria: speed and direction. The maintenance and the update of the groups is periodic, which makes the overhead insensitive to the number of vehicles or to group changing. On the contrary, the supplementary computational load on the eNode-B has not yet been studied. The stability property of the clusters or their lifetime have not been highlighted either, while each eNode-B must regularly update the clusters.
The different works that we have presented highlight the need to take into account the spatial and temporal characteristics of the vehicles for forming stable clusters. In [MAB 06] and [WIS 07], the road traffic analysis carried out on the highway shows that the vehicles have a tendency to regroup naturally in a convoy in the same direction and with the same speed. In the following sections, we propose an approach called CONVOY that is based on these natural convoys and organizes them starting from criteria such as position, relative speed, movement direction and the quality of the radio connection.
On the highway, the vehicles follow each other in a line. In [MAB 06], we have shown that the particular dynamic of vehicles in such an ad hoc network triggered the regrouping of the vehicles in clusters that are disconnected from one another. The convoy formation is thus natural in a highway context. In a convoy where the vehicles follow each other, the clusterhead is thus thoroughly designated: it is the head of the convoy. We consider that a vehicle is equipped with a single wireless interface, a highly performing geolocalization system using a GPS terminal as well as information specific to the vehicle such as its position, its actual speed and its direction. CONVOY combines more criteria, as presented in section 3.3. To ensure the stability of the convoy, the membership of a new vehicle to the convoy depends on:
Inside the convoy, the communications can be made in several hops. Our algorithm therefore forms k-hops clusters. To limit the congestion inside the cluster, we have also defined a maximum convoy length in kilometers without limiting the number of vehicles that are present in the convoy. Inside the cluster, the graph representing the network must then be connected and the intervehicle communication will be ensured by means of an intracluster routing protocol. We will not consider the lane on which the vehicle is driving, the precision of the geolocalization systems being to a few meters. However, the regrouping of vehicles on the same lane is helped by the criterion for joining a convoy, as we will discuss in the following.
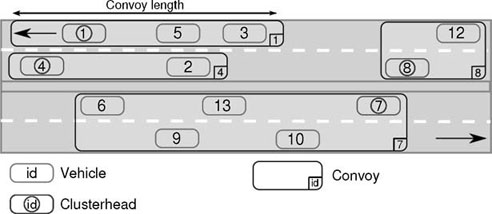
Figure 3.1 illustrates these principles: the vehicles that drive in opposite directions are not in the same convoy. However, in convoy 7, the vehicles are in the same convoy while they are on different lanes. The speed of the vehicles in convoys 1 and 4 is very different, which explains the fact that they are in different convoys.
With the aim of simplifying, we have chosen to separate the convoy formation protocol from the intervehicle communication protocol.
Figure 3.1. Vehicle convoys on a 2 × 2 way highway. The head of the convoy is the vehicle in front of all the other vehicles
Inside the convoy, the communication protocol is the simplest possible and draws inspiration from [DUC 07]. It is based on the geographical position of the vehicles and the direction of the convoy. The dissemination of a packet in the direction (respectively in the opposite direction) of the movement of the convoy allows us to deliver a message to all the vehicles in the back of the convoy (and respectively in the front of the convoy) of the vehicle that initiates the message. The CONVOY protocol therefore is not in charge of sending messages.
Our algorithm for forming convoys revisits the principles of the cluster formation algorithms. The head of the convoy, or the clusterhead, is simply the vehicle at the head of the convoy, that is the vehicle present in front of all the vehicles members of the convoy (Figure 3.1). Contrary to the algorithms described previously, which limit the size of the cluster to a certain number of hops or to a certain number of nodes, our algorithm defines the maximum size of the cluster via its geographical length (in meters), that is the maximum distance separating the head of the convoy from the queue of the convoy (Figure 3.1).
Initially, every vehicle is alone in its own convoy and thus at the head of the convoy. Therefore, there are as many convoys as there are vehicles in the network. A node states its presence to its neighbors by sending a HELLO message at regular intervals, containing its identifier, the identifier of its convoy, its position, its direction and its speed.
The formation and the maintenance of the convoys are ensured by two distinct procedures: the merger and the division of convoys. Merging allows a convoy to grow by recruiting new vehicles. The division is triggered when the convoy is no longer connected: there is a node that can no longer communicate with the head of the convoy. The set of messages used by these procedures is shown in Table 3.1.
Table 3.1. List of messages used by the convoy formation algorithms
| Name of the message | Acronym | Dissemination mode |
| Join convoy request | JOINREQ | Movement direction |
| Join convoy reply | JOINREP | Towards a destination |
| Node join | NODEJOIN | Towards a destination |
| Convoy info | CONVOYINFO | Direction opposed to movement |
| Carrying out a CI | INFOACK | Movement direction |
| Hello | HELLO | Vicinity |
In the following, we describe the procedures triggered upon receipt of a HELLO message. Let us remember that in an ad hoc network, the HELLO messages are disseminated periodically through a node to its neighbors in order to inform it of its presence and to exchange information regarding the state that will be exploited by the protocols.
Algorithm 3.1 Variables, constant and initialization of a node

To initiate the merging of two convoys, Ci and Cj, the clusterhead of Ci must be the neighbor (clusterhead or not) of a vehicle contained in the cluster Cj. Starting from the information contained in the HELLO messages received from its neighbor, the clusterhead decides to become a candidate for the merger or not (algorithm 3.2).
Algorithm 3.2 Reception of a HELLO message. Parameters: identifier, position and speed of the node. Identifier of the convoy

Following are the admission conditions:
After the merger, the clusterhead being always in front of all the vehicles’ members of the convoy, the clusterhead of Ci becomes a member of the convoy Cj.
If all of these conditions are met, the proposed clusterhead Ci sends a JOINREQ message to the neighboring vehicle that sends it to its clusterhead, called the neighboring clusterhead. The neighboring clusterhead verifies the size of the two joined convoys (algorithm 3.3): if it is lower than the maximum size of the convoys, then it sends a response message JOINREP to the clusterhead candidate confirming the merger. This message is then sent toward the geographical position of the destination. If the size is higher than the maximum size, then it does not do anything and the merging process is aborted. Upon receipt of the message JOINREQ (algorithm 3.5), Cj sends a NODEJOIN message to the neighboring clusterhead Ci containing the list with the members of its convoy. Next, Cj disseminates a CONVOYINFO message in the direction opposed to the movement of the convoy and updates the identifier of the convoy to which it belongs.
Upon receipt of the NODEJOIN message (algorithm 3.4), the clusterhead adds the vehicles contained in the message from its list. Upon receipt of a message CONVOYINFO (algorithme 3.7), each vehicle updates the identifier of its convoy.
Algorithm 3.3 Receipt of a JOINREQ message. Parameters: identifier of the convoy, size of the convoy (boundaries)
| 1: procedure JCREQ (idConvoy, ConvoyLength) |
| 2: if ConvoyHead |
3: 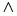 jcreq.ConvoyLength ∪ ConvoyLength < ConvoyLengthLimit then jcreq.ConvoyLength ∪ ConvoyLength < ConvoyLengthLimit then |
| 4: SEND JOINREP(jcreq.idConvoy) |
| 5: end if |
| 6: end procedure |
Algorithm 3.4 Receipt of a NODEJOIN message. Parameters: set of nodes of the convoy to be joined
| 1: procedure NJ(nodes) ClusterNodes ← ClusterNodes ∪ nj.nodes |
| 2: end procedure |
Algorithm 3.5 Receipt of a JOINREP message. Parameters: identifier of the convoy
| 1: procedure JCREP(idConvoy) |
| 2: IdConvoy ← jcrep.idConvoy |
| 3: ConvoyHead ← False |
| 4: SEND CONVOYINFO(IdConvoy) |
| 5: SEND NODEJOIN(ClusterNodes) |
| 6: end procedure |
The management of the division of convoys allows us to maintain the convoy. The detection of the link failure with a neighboring member is not enough for deducing that the vehicle leaves the convoy. Indeed, it can still communicate with all the members of the convoy and the clusterhead via the intermediary of another link. By definition, the division of a convoy takes place when a vehicle member can no longer communicate with the clusterhead, that is when there is no lane toward the clusterhead (Figure 3.2). The network being linear, none of these vehicles behind the disconnected vehicle can communicate with the clusterhead any longer. The head member thus becomes clusterhead and the set of the vehicles behind this vehicle rejoins the new convoy.
Figure 3.2. Division of convoy 7. After the division, convoy 7 leaves and a new convoy 9 is formed.
The clusterhead disseminates a message CONVOYINFO to all members of the convoy, within regular intervals, in the direction opposite to the movement of the convoy. When a member does not receive this message during a predetermined delay, it considers that there is no longer a lane with the clusterhead; the convoy being no longer connected, there is a division of the convoy. The member designates itself chief clusterhead and disseminates a CONVOYINFO message in the direction opposite to the movement of the convoy, allowing vehicles behind it to change the convoy (algorithm 3.6).
Upon receipt of a CONVOYINFO message (algorithm 3.7), a member allocates its convoy identifier to the new identifier of the clusterhead and acknowledges the reception of the message to its new clusterhead. Upon receipt of the acknowledgment, the new clusterhead adds the new member to its member list. The clusterhead in the back, not having received any acknowledgment of the CONVOYINFO message, considers that its members are no longer part of its cluster and removes them from its member list. The division procedure is thus terminated.
Algorithm 3.6 Upon convoy breaking
| 1: procedure CONVOYBREAK(idConvoy) |
| 2: IdConvoy ← Id |
| 3: ConvoyHead ← True |
| 4: SEND CONVOYINFO(idConvoy) |
| 5: end procedure |
Algorithm 3.7 Receipt of a Convoy info messages. Parameters: Convoy identifier
| 1: procedure CI(idConvoy) |
| 2: IdConvoy ← ci.idConvoy |
| 3: ConvoyHead ← False |
| 4: SEND INFOACK |
| 5: end procedure |
We have implemented the CONVOY protocol in the JIST/SWANS simulator [BAR 04]. To finely simulate the movement of the vehicles on a highway, we use the road traffic simulator developed in [MAB 07] to model the mobility of vehicles in a highway context. Besides the parameters connected to the road traffic (highway length and vehicle density), we use four parameters connected to the simulation of convoy formation whose default values are given in Table 3.2. All of the simulations were realized with a confidence interval of 95%.
Table 3.2. Default simulation parameters
| Simulation time | 600 s |
| Hello interval | 2s |
| Lifetime limit of a convoy connection | 600 s |
| Convoy length limit | 2 km |
| Highway length | 10 km |
| Vehicle density | 10 vehicles/way/km |
| Radio coverage | 250 m |
| Bandwidth | 11 Mb/s |
We are interested in five metrics: the number of convoy breaks, the number of convoys, the partitioning rate, the length and the size of a convoy. The number of convoy breaks during a simulation allows us to evaluate the global stability of the convoys formed: the more significant the number of breaks, the less stable the convoys. The number of convoys allows us to evaluate the quality of their formation: in the worst-case scenario, there are as many convoys as there are vehicles. Each convoy thus being composed of a single vehicle, the formation of a convoy therefore does not present any interest, and the regrouping criteria are not valid. The smaller the number of convoys, the more significant the convoys and hence the more the mobility of the vehicles can trigger connection failures and convoy divisions. We are also interested in the partitioning rate defined as the number of convoys divided by the number of nodes. The partitioning rate is thus the reverse of the average size of convoys. We differentiate between convoy length and convoy size. The length of a convoy is the distance in kilometers between its head and its rear (i.e. the vehicle behind all the members of the convoy). The size of a convoy is the number of its member vehicles.
In the first stage, we seek the optimal parameters of the CONVOY. Then, we analyze the stability and the quality of the convoys formed with the optimal parameters we found.
We seek to regulate two significant parameters in CONVOY, namely the maximum convoy length in meters and the minimal lifetime of a connection for a node to be accepted in a convoy.
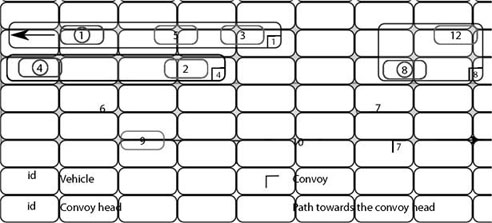
The connectivity of a convoy is directly proportional to its density. The higher the density of a convoy, the larger the size of a convoy (potentially), thus decreasing the partitioning rate. This hypothesis is verified against the results in Figure 3.3(a): the partitioning rate decreases along with the density. In this same figure, we see that the partitioning rate is equally proportional to the length limit of the convoy. Consequently, the maximum length parameter of the convoys allows us to limit the size of the convoys. The variation of the partitioning rate is weaker as soon as the length limit is higher than 2,000 m and quasi-constant starting from 3,000 m. The number of convoy breaks increases with the density and the length limit of the convoys (Figure 3.3(b)). For a density of 24 vehicles/km/lane, the number of breaks explodes starting from 2,000 m. Beyond 3,000 m and with a density of 24 vehicles/km/lane, the strength required by the simulator is too significant to be able to carry out a simulation, hence the absence of the measures. We conclude that it is not useful to fix the maximum length of a convoy beyond 2,000 m in order to satisfy the compromise of a partitioning rate close to a minimum, and of a minimum number of convoy breaks. We have therefore set the limit of the convoy length to a default 2,000 m.
Figure 3.3. Performance depending on the maximum convoy length for several densities
Having discussed the maximum length of the convoy, we must verify that it is valid. The distribution of the length of convoys is calculated at the end of the simulation. Figure 3.4 presents this distribution for a limit fixed at 2,000, 3,000 and 5,000 m. Each bar represents the number of convoys comprised between a length l and l + 500 m on a sample of approximately 100 convoys carried out in several simulations.
Figure 3.4. Convoy length distribution in meters
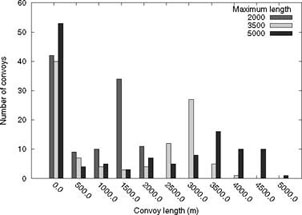
Let us note two glaring anomalies: a significant proportion of convoys of length comprised between 0 and 500 m, and convoys that are of a larger size than the set limit. When a node arrives on the highway, it is the head of the convoy and alone in the convoy (no member has yet joined it). It remains alone for a limited amount of time before merging with another convoy. Each node having been at the start in a zero length convoy, the proportion of small convoys close to the value zero in length (one single node in the convoy) is obviously important, but not significant. Indeed a convoy stays for very little time with a size less than 10, as we may observe in Figure 3.4. The second perceived anomaly is the existence of convoys of a size greater than the size limit (2,000 m). The speed of the vehicles being quite close to one another, we set the length limit of the convoy solely at the time of its formation, that is during merger. On the other hand, the topology of the convoy is dynamic: the relative distance between the vehicles varies with time. It is possible that a vehicle with a lower speed moves away from the other vehicles in the convoy and increases the length of the convoy over time. Consequently, although no new vehicle has joined the convoy, the length of the convoy can increase without causing a convoy break because the length remains close to 2 km. The distribution is in accordance with the waiting times, more so for the convoys of 2,000 and 3,000 m in length, the maximum being, respectively, for the convoys of a length comprised between 1,500 and 2,000 m and 3,000 and 3,500 m. For a limit of 5,000 m, the distribution is more widespread, maintaining the convoy higher than 3,000 m being more difficult because of the higher probability of a convoy break (Figure 3.3(b)).
Our objective is to minimize the number of convoys thus formed, which involves large-sized convoys. On the other hand, the number of convoy breaks depends on the size of the convoys (Figure 3.5(b)). The connectivity of a convoy is directly proportional to its density. The denser a convoy, the larger its potential size, thus decreasing the partitioning rate. This hypothesis is verified by the results in Figure 3.3(a): the partitioning rate decreases with the density.
Figure 3.5. Performance per node depending on the density
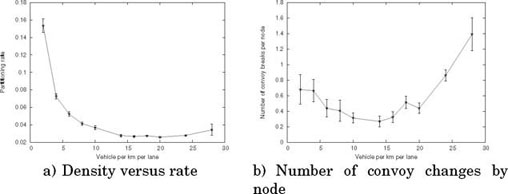
In this same figure, we see that the partitioning rate is also proportional to the length limit of the convoy (Figure 3.3(a)). Consequently, the maximum length parameter of the convoys allows us to limit the size of convoys. The variation of the partitioning rate is lower since the length limit is higher than 2,000 m and quasi-constant starting from 3,000 m. We have found a compromise with a convoy limited at 2,000 m.
We are therefore interested in the length of a convoy with a size n, and a length limit of 2,000 m. In Figure 3.6, we measure the distribution of the lifetime of a convoy depending on its size. Here, the lifetime is expressed in a simulation percentage, namely the period of time during which the convoy has a size comprised in the interval. The repartition of the size of the convoy depends on its density:
Figure 3.6. Distribution of the lifetime of the convoys depending on their size

Let us also note that the large size convoys are those that last the longest, especially with the densities of 4 and 10 vehicles per kilometer and per lane. This property is very helpful for obtaining stable convoys of a size sufficiently large in order to justify convoy formation in a network of vehicles.
The organization in clusters is well adapted to VANETs because natural groups form at the intersections or on the highway. However, VANETs are very dynamic networks and the partitioning of the network must be made according to representative criteria of the spatial and temporal behavior of the vehicles in motion. The objective is to introduce stable structures in a globally unstable system. Among the criteria used in the different protocols and clustering algorithms that we have presented, it is worth highlighting: the geographical position, the distance between vehicles, the speed and the average speed within the group and the direction of the movement. We have then presented propositions in each of the different frameworks of use such as the MAC level or the ITS applications.
Finally, we have presented CONVOY, an original convoy formation protocol adapted to the vehicular network. The formation of convoys is based on considering several criteria such as the position, the movement direction of vehicles and the relative speed inside the convoy. The convoy is formed while taking into account the quality of the connections between the nodes and its maximum length in order to form convoys that are as stable as possible. We have proposed two merging and convoy division algorithms. The simulations we have carried out via a vehicular network simulator in a highway context have allowed us to study the distributions of the size and the length of the convoys. They have shown good stability for the convoys of 2 km in length. Since the vehicles are regrouped according to their speed, they remain together and there are few convoy breaks. Our next stage will be to complete this study with an implementation of CONVOY on a real platform, and then to carry out tests on the road, in order to test our simulation results in the field.
[AGA 09] AGARWAL R., MOTWANI M., “Survey of clustering algorithms for MANET”, Computing Research Repository, vol. abs/0912.2303, 2009.
[ALM 10] ALMALAG M., WEIGLE M., “Using traffic flow for cluster formation in vehicular ad hoc networks”, Proceedings of the IEEE 35th Conference on Local Computer Networks (LCN 2010), Denver, CO, pp. 631–636, October 2010.
[BAR 04] BARR R., HAAS Z. J., Jist/Swans: Java in simulation time and scalable wireless ad hoc network simulator, 2004.
[BAS 99] BASAGNI S., “Distributed clustering for ad hoc networks”, Proceedings of the 4th International Symposium on Parallel Architectures, Algorithms, and Networks, (I-SPAN ’99), Perth, Australia, 1999.
[BAS 01] BASU P., KHAN N., LITTLE T., “A mobility based metric for clustering in mobile ad hoc networks”, Proceedings of the 21st International Conference on Distributed Computing Systems Workshops (ICDCS 2001 Workshops), Phoenix, AZ, pp. 413–418, 2001.
[BLU 03] BLUM J., ESKANDARIAN A., HOFFMAN L., “Mobility management in IVC networks”, Proceedings of the IEEE Intelligent Vehicles Symposium, Baltimore, MD, pp. 150–155, 2003.
[BON 07] BONONI L., DI FELICE M., “A Cross Layered MAC and clustering scheme for efficient broadcast in VANETs”, Proceedings of the IEEE Internatonal Conference on Mobile ad hoc and Sensor Systems (MASS 2007), Pisa, Italy, pp. 1–8, 2007.
[CAP 06] CAPPELLE C., POMORSKI D., YANQIN Y., “GPS/INS data fusion for land vehicle localization”, IMACS Multiconference, Computational Engineering in Systems Applications (CESA’2006), Beijing, China, pp. 21–27, 2006.
[DAS 05] DAS S.M., PUCHA H., HU Y.C., “Performance comparison of scalable location services for geographic ad hoc routing”, Proceedings of the 24th Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM 2005), vol. 2, Miami, FL, 2005.
[DEA 09] DEAN A., BRENNAN S., “Terrain-based road vehicle localization on multi-lane highways”, Proceedings of the American Control Conference (ACC’09), Saint Louis, USA, pp. 707–712, 2009.
[DUC 07] DUCOURTHIAL B., KHALED Y., SHAWKY M., “Conditional transmissions: performance study of a new communication strategy in VANET”, IEEE Transactions on Vehicular Technology, vol. 56, no. 6, pp. 3348–3357, 2007.
[FAN 05] FAN P., HARAN J.G., DILLENBURG J., et al., “Cluster-based framework in vehicular ad hoc networks”, Proceedings of the 4th International Conference on Ad-Hoc, Mobile, and Wireless Networks (ADHOC-NOW’05), LNCS 3738, Springer, New York, pp. 32–42, 2005.
[FAN 07] FAN P., MOHAMMADIAN A.K., NELSON P.C., et al., “A novel direction based clustering algorithm in vehicular ad hoc networks”, Proceedings of the TRB 86th Annual Meeting Compendium of Papers CD-ROM, Transportation Research Board Business Office, Washington DC, 2007.
[GHO 08] GHOSH R., BASAGNI S., “Mitigating the impact of node mobility on ad hoc clustering”, Wireless Communications and Mobile Computing, vol. 8, no. 3, pp. 295–308, 2008.
[GUN 07] GUNTER Y., WIEGEL B., Grossmann H., “Cluster-based medium access scheme for VANETs”, Proceedings of the 10th International IEEE Conference on Intelligent Transportation Systems (ITSC’07), Seattle, WA, pp. 343–348, 2007.
[JAY 12] JAYASUDHA K., CHANDRASEKAR C., “Hierarchical clustering based greedy routing in vehicular ad hoc networks”, European Journal of Scientific Research (EURASIP), vol. 67, no. 4, pp. 580–594, 2012.
[LEE 10] LEE K.C., LEE U., GERLA M., “Survey of routing protocols in vehicular ad hoc networks.”, in WATFA M., (ed.), Advances in Vehicular Ad-Hoc Networks: Developments and Challenges, Chapter 8, IGI Global, pp. 149–170, 2010.
[LIN 06] LIN L., OSAFUNE T., LENARDI M., “Floating car data system enforcement through vehicle to vehicle communications”, Proceedings of the 6th International Conference on ITS Telecommunications, Chegdu, China, pp. 122–126, 2006.
[MAB 06] MABIALA M., BUSSON A., VÈQUE V., “Analyse du trafic et du routage dans un réseau ad hoc de véhicules”, Colloque Francophone sur l’Ingénierie des Protocoles (CFIP), Tunisia, 2006.
[MAB 07] MABIALA M., BUSSON A., VÉQUE V., “Performance evaluation of VANET under realistic vehicular traffic assumption”, in APPERT-ROLLAND, CÉCILE et al., eds., Traffic and Granular Flow (TGF’07), Springer Verlag, pp. 739–744, 2007.
[MAS 11a] MASLEKAR N., BOUSSEDJRA M., MOUZNA J., et al., “VANET based adaptive traffic signal control”, Proceedings of the IEEE 73rd Vehicular Technology Conference (VTC-2011 Spring), Budapest, Hungary, 2011.
[MAS 11b] MASLEKAR N., MOUZNA J., LABIOD H., et al., “Modified C-DRIVE: clustering based on direction in vehicular environment”, Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, pp. 845–850, 2011.
[MEN 07] MENOUAR H., LENARDI M., FILALI F., “Movement prediction-based routing (MOPR) concept for position-based routing in vehicular networks”, Proceedings of the IEEE 66th Vehicular Technology Conference (VTC-2007 Fall), Baltimore, MD, pp. 2101–2105, 2007.
[NIU 06] NIU X., TAO Z., WU G., et al., “Hybrid cluster routing: an efficient routing protocol for mobile ad hoc networks”, Proceedings of the IEEE International Conference on Communications (ICC), Istanbul, Turkey, 2006.
[NOC 03] NOCETTI F. G., GONZALEZ J. S., STOJMENOVIC I., “Connectivity based k-Hop clustering in wireless networks”, Telecommunication Systems, vol. 22, nos. 1–4, pp. 205–220, 2003.
[OHT 03] OHTA T., INOUE S., KAKUDA Y., “An adaptive multihop clustering scheme for highly mobile ad hoc networks”, Proceedings of the 6th International Symposium on Autonomous Decentralized Systems (ISADS’03), Pisa, Italy, pp. 293–300, 2003.
[OHT 07] OHTA T., MURAKAMI N., KAKUDA Y., “Performance evaluation of autonomous clustering for hierarchical routing protocols in mobile ad hoc networks”, Proceedings of the 27th International Conference on Distributed Computing Systems Workshops (ICDCS 2007 Workshops), Toronto, Canada, p. 56, 2007.
[OHT 12] OHTA Y., OHTA T., KAKUDA Y., “An autonomous clustering-based data transfer scheme using positions and moving direction of vehicles for VANETs”, Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC 2012), pp. 2927–2931, 2012.
[PET 11] PETRESCU A., BOC M., IBARS C., “Joint IP networking and radio architecture for vehicular networks”, Proceedings of the 11th International Conference on ITS Telecommunications, Saint Petersburg, Russia, pp. 230–236, 2011.
[RAW 08] RAWASHDEH Z.Y., MAHMUD S.M., “Media access technique for cluster-based vehicular ad hoc networks”, Proceedings of the IEEE 68th Vehicular Technology Conference (VTC-2008 Fall), Calgary, Canada, 2008.
[RAW 09] RAWSHDEH Z.Y., MAHMUD S.M., “Toward strongley connected clustering structure in vehicular ad hoc networks”, Proceedings of the IEEE 70th Vehicular Technology Conference Fall (VTC-2009 Fall), Anchorage, AK, 2009.
[REM 11] REMY G., SENOUCI S.-M., JAN F. et al., “LTE4V2X – impact of high mobility in highway scenarios”, Proceedings of the Global Information Infrastructure Symposium (GIIS), Da Nang, Vietnam, pp. 1–7, 2011.
[REM 12] REMY G., SENOUCI S.-M., JAN F., et al., “LTE4V2X – Collection, dissemination and multi-hop forwarding”, Proceedings of the IEEE International Conference on Communications (ICC), Ottawa, Canada, 2012.
[SAN 06] SANTOS R., EDWARDS A., “A reactive location routing algorithm with cluster-based flooding for inter-vehicle communication”, Computación y Sistemas, vol. 9, no. 4, pp. 297–313, 2006.
[SCH 06] SCHMILZ R., LEIGGENER A., FESTAG A., et al., “Analysis of path characteristics and transport protocol design in vehicular ad hoc networks”, Proceedings of the IEEE 63rd Vehicular Technology Conference, (VTC-2006-Spring), vol. 2, Melbourne, Australia, pp. 528–532, 2006.
[SHE 09] SHEA C., HASSANABADI B., VALAEE S., “Mobility-based clustering in VANETs using affinity propagation”, Proceedings of the IEEE Global Telecommunications Conference (GLOBECOM 2009), Hawaii, USA, pp. 1–6, 2009.
[SOU 10] SOUZA E., NIKOLAIDIS I., GBURZYNSKI P., “A new aggregate local mobility (ALM) clustering algorithm for VANETs”, Proceedings of the IEEE International Conference on Communications (ICC), Cape Town, South Africa, pp. 1–5, 2010.
[TAL 06] TALEB T., OCHI M., JAMALIPOUR A., et al., “An efficient vehicle-heading based routing protocol for VANET networks”, Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC’06), Las Vegas, NV, pp. 2199–2204, 2006.
[WIS 07] WISITPONGPHAN N., BAI F., MUDALIGE P., et al., “Routing in sparse vehicular ad hoc wireless networks”, IEEE Journal on Selected Areas in Communications, vol. 25, no. 8, pp. 1538–1556, 2007.
[YU 05] YU J.Y., CHONG P.H.J., “A survey of clustering schemes for mobile ad hoc networks”, IEEE Communications Surveys and Tutorials, vol. 7, no. 1, pp. 32–48, 2005.