Kernel programming originally became popular as a way to program GPUs. As kernel programming is generalized, it is important to understand how our style of programming affects the mapping of our code to a CPU.
The CPU has evolved over the years. A major shift occurred around 2005 when performance gains from increasing clock speeds diminished. Parallelism arose as the favored solution—instead of increasing clock speeds, CPU producers introduced multicore chips. Computers became more effective in performing multiple tasks at the same time!
While multicore prevailed as the path for increasing hardware performance, releasing that gain in software required non-trivial effort. Multicore processors required developers to come up with different algorithms so the hardware improvements could be noticeable, and this was not always easy. The more cores that we have, the harder it is to keep them efficiently busy. DPC++ is one of the programming languages that address these challenges, with many constructs that help to exploit various forms of parallelism on CPUs (and other architectures).
This chapter discusses some particulars of CPU architectures, how CPU hardware executes DPC++ applications, and offers best practices when writing a DPC++ code for a CPU platform.
Performance Caveats
The underlying performance of the single invocation and execution of kernel code
The percentage of the program that runs in a parallel kernel and its scalability
CPU utilization, effective data sharing, data locality, and load balancing
The amount of synchronization and communication between work-items
The overhead introduced to create, resume, manage, suspend, destroy, and synchronize the threads that work-items execute on, which is made worse by the number of serial-to-parallel or parallel-to-serial transitions
Memory conflicts caused by shared memory or falsely shared memory
Performance limitations of shared resources such as memory, write combining buffers, and memory bandwidth
In addition, as with any processor type, CPUs may differ from vendor to vendor or even from product generation to product generation. The best practices for one CPU may not be best practices for a different CPU and configuration.
To achieve optimal performance on a CPU, understand as many characteristics of the CPU architecture as possible!
The Basics of a General-Purpose CPU
Emergence and rapid advancements in multicore CPUs have driven substantial acceptance of shared memory parallel computing platforms. CPUs offer parallel computing platforms at laptop, desktop, and server levels, making them ubiquitous and exposing performance almost everywhere. The most common form of CPU architecture is cache-coherent Non-Uniform Memory Access (cc-NUMA), which is characterized by access times not being completely uniform. Even many small dual-socket general-purpose CPU systems have this kind of memory system. This architecture has become dominant because the number of cores in a processor, as well as the number of sockets, continues to increase.
In a cc-NUMA CPU system, each socket connects to a subset of the total memory in the system. A cache-coherent interconnect glues all of the sockets together and provides a single system view for programmers. Such a memory system is scalable, because the aggregate memory bandwidth scales with the number of sockets in the system. The benefit of the interconnect is that an application has transparent access to all of the memory in the system, regardless of where the data resides. However, there is a cost: the latency to access data and instructions, from memory is no longer consistent (e.g., fixed access latency). The latency instead depends on where that data is stored in the system. In a good case, data comes from memory directly connected to the socket where code runs. In a bad case, data has to come from a memory connected to a socket far away in the system, and that cost of memory access can increase due to the number of hops in the interconnect between sockets on a cc-NUMA CPU system.
In Figure 16-1, a generic CPU architecture with cc-NUMA memory is shown. This is a simplified system architecture containing cores and memory components found in contemporary, general-purpose, multisocket systems today. Throughout the remainder of this chapter, the figure will be used to illustrate the mapping of corresponding code examples.
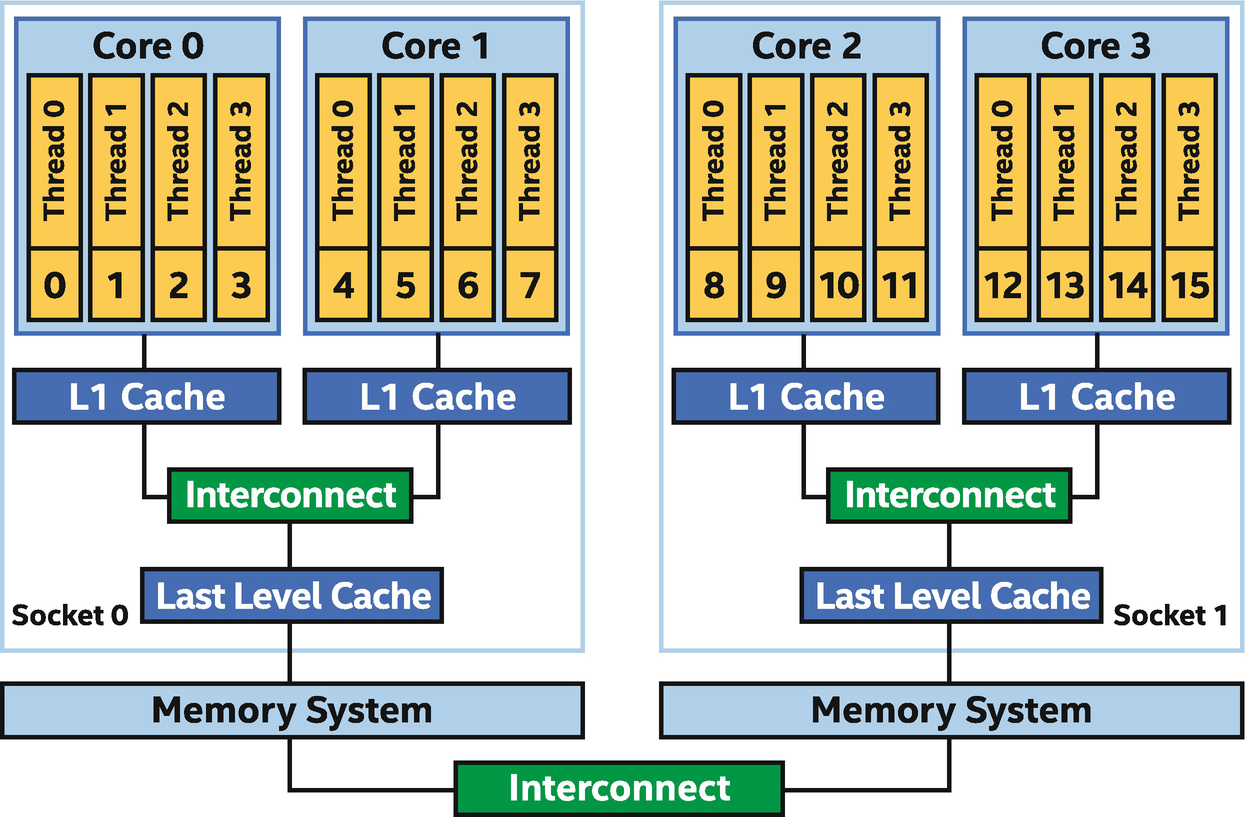
Generic multicore CPU system
The system in Figure 16-1 has two sockets, each of which has two cores with four hardware threads per core. Each core has its own level 1 (L1) cache. L1 caches are connected to a shared last-level cache, which is connected to the memory system on the socket. The memory access latency within a socket is uniform, meaning that it is consistent and can be predicted with accuracy.
The two sockets are connected through a cache-coherent interconnect. Memory is distributed across the system, but all of the memory may be transparently accessed from anywhere in the system. The memory read and write latency is non-uniform when accessing memory that isn’t in the socket where code making the access is running, which means it imposes a potentially much longer and inconsistent latency when accessing data from a remote socket. A critical aspect of the interconnect, though, is coherency. We do not need to worry about data becoming inconsistent across the memory system (which would be a functional problem) and instead need to worry only about the performance impact of how we’re accessing the distributed memory system.
Hardware threads in CPUs are the execution vehicles. These are the units that execute instruction streams (a thread in CPU terminology). The hardware threads in Figure 16-1 are numbered consecutively from 0 to 15, which is a notation used to simplify discussions on the examples in this chapter. Unless otherwise noted, all references to a CPU system in this chapter are to the reference cc-NUMA system shown in Figure 16-1.
The Basics of SIMD Hardware
In 1996, the first widely deployed SIMD (Single Instruction, Multiple Data according to Flynn’s taxonomy) instruction set was MMX extensions on top of the x86 architecture. Many SIMD instruction set extensions have since followed both on Intel architectures and more broadly across the industry. A CPU core carries out its job by executing instructions, and the specific instructions that a core knows how to execute are defined by the instruction set (e.g., x86, x86_64, AltiVec, NEON) and instruction set extensions (e.g., SSE, AVX, AVX-512) that it implements. Many of the operations added by instruction set extensions are focused on SIMD instructions.
SIMD instructions allow multiple calculations to be carried out simultaneously on a single core by using a register and hardware that is bigger than the fundamental unit of data being processed. Using 512-bit registers, we can perform eight 64-bit calculations with a single machine instruction.

SIMD execution in a CPU hardware thread
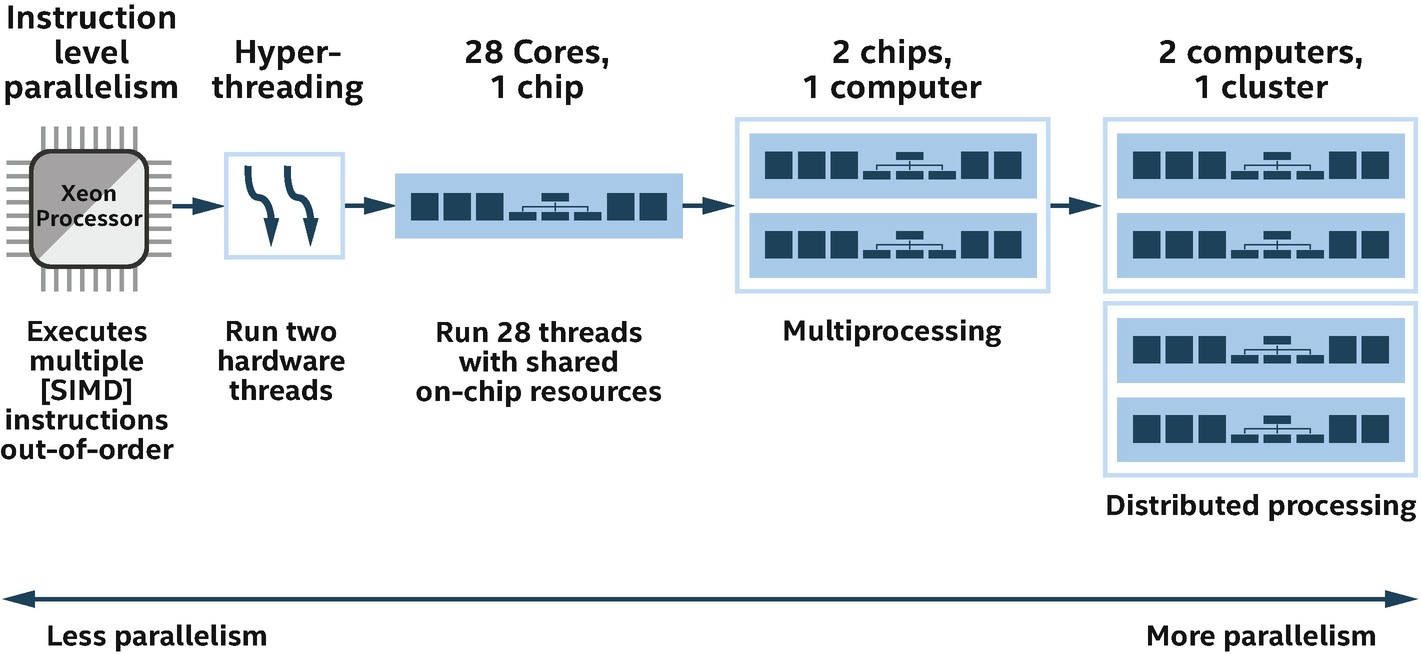
Five ways for executing instructions in parallel
Modern CPU architectures allow one core to execute the instructions of two or more threads simultaneously.
Multicore architectures that contain two or more brains within each processor. The operating system perceives each of its execution cores as a discrete processor, with all of the associated execution resources.
Multiprocessing at the processor (chip) level, which can be accomplished by executing completely separate threads of code. As a result, the processor can have one thread running from an application and another thread running from an operating system, or it can have parallel threads running from within a single application.
Distributed processing , which can be accomplished by executing processes consisting of multiple threads on a cluster of computers, which typically communicate through message passing frameworks.
In order to fully utilize a multicore processor resource, the software must be written in a way that spreads its workload across multiple cores. This approach is called exploiting thread-level parallelism or simply threading.
As multiprocessor computers and processors with hyper-threading (HT) technology and multicore technology become more and more common, it is important to use parallel processing techniques as standard practice to increase performance. Later sections of this chapter will introduce the coding methods and performance-tuning techniques within DPC++ that allow us to achieve peak performance on multicore CPUs.

STREAM Triad C++ loop
The STREAM Triad workload (www.cs.virginia.edu/stream) is an important and popular benchmark workload that CPU vendors use to demonstrate highly tuned performance. We use the STREAM Triad kernel to demonstrate code generation of a parallel kernel and the way that it is scheduled to achieve significantly improved performance through the techniques described in this chapter. The STREAM Triad is a relatively simple workload, but is sufficient to show many of the optimizations in an understandable way.
When a vendor provides a library implementation of a function, it is almost always beneficial to use it rather than re-implementing the function as a parallel kernel!
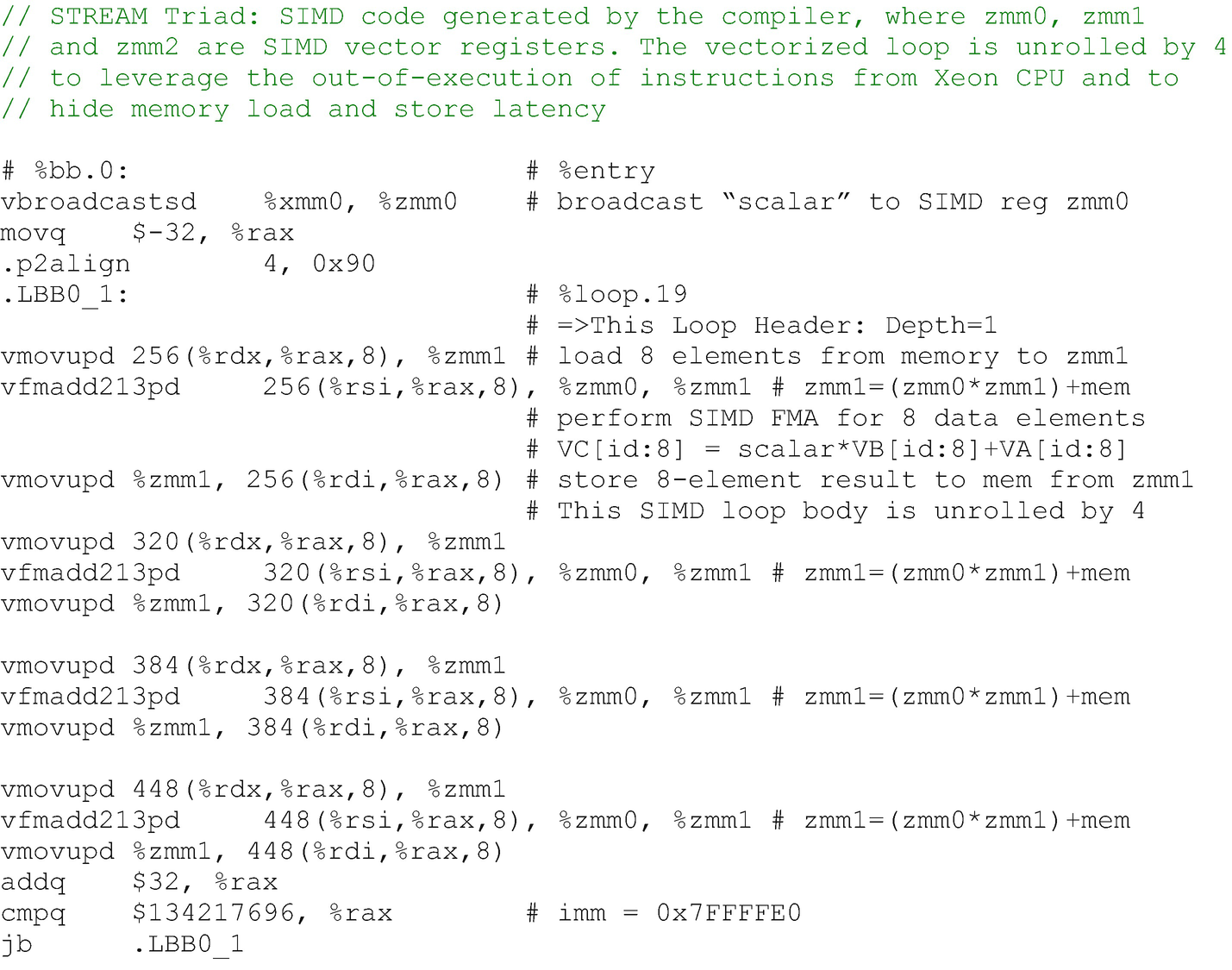
AVX-512 code for STREAM Triad C++ loop
As shown in Figure 16-5, the compiler was able to exploit instruction-level parallelism in two ways. First is through the use of SIMD instructions, exploiting instruction-level data parallelism, in which a single instruction can process eight double-precision data elements simultaneously in parallel (per instruction). Second, the compiler applied loop unrolling to get the out-of-order execution effect of these instructions that have no dependences between them, based on hardware multiway instruction scheduling.
If we try to execute this function on a CPU, it will probably run well—not great, though, since it does not utilize any multicore or threading capabilities of the CPU, but good enough for a small array size. If we try to execute this function with a large array size on a CPU, however, it will likely perform very poorly because the single thread will only utilize a single CPU core and will be bottlenecked when it saturates the memory bandwidth of that core.
Exploiting Thread-Level Parallelism
To improve the performance of the STREAM Triad kernel for both CPUs and GPUs, we can compute on a range of data elements that can be processed in parallel, by converting the loop to a parallel_for kernel.

DPC++ STREAM Triad parallel_for kernel code
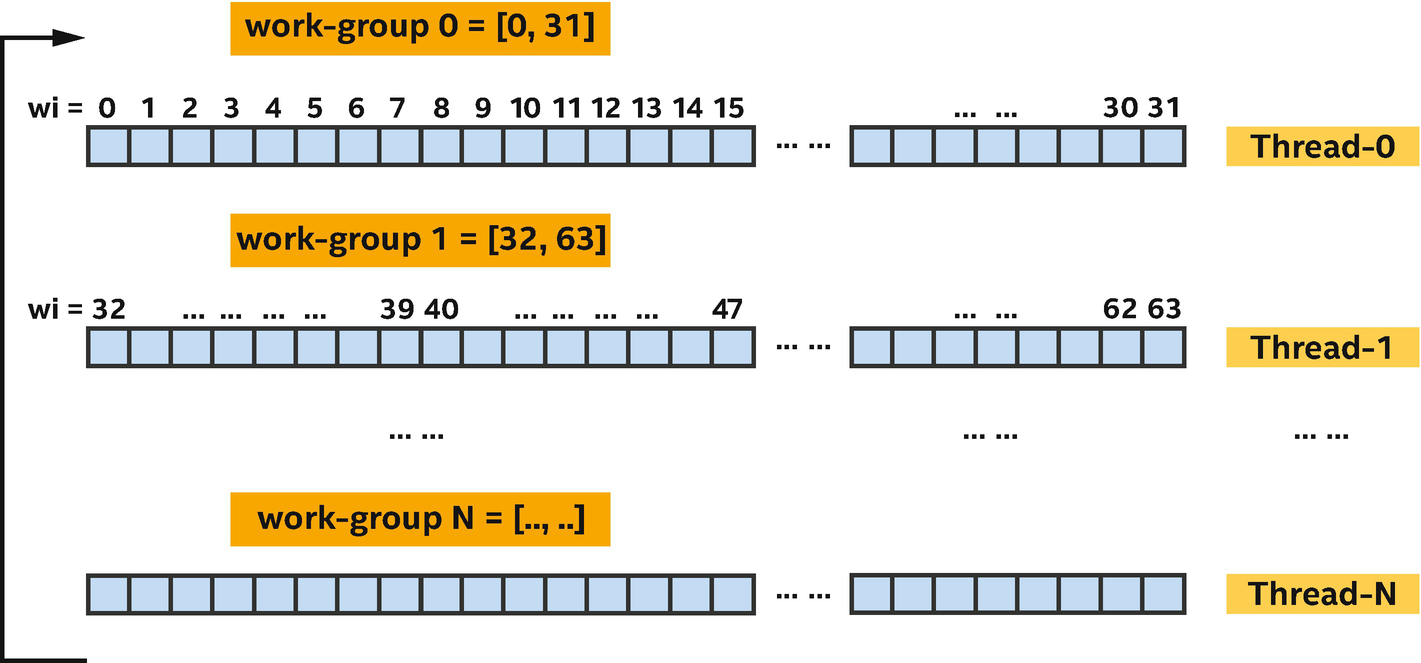
A mapping of a STREAM Triad parallel kernel
Note that in the DPC++ program, the exact way that data elements are partitioned and assigned to different processor cores (or hyper-threads) is not required to be specified. This gives a DPC++ implementation flexibility to choose how best to execute a parallel kernel on a specific CPU. With that said, an implementation can provide some level of control to programmers to enable performance tuning.
While a CPU may impose a relatively high thread context switch and synchronization overhead, having somewhat more software threads resident on a processor core is beneficial because it gives each processor core a choice of work to execute. If one software thread is waiting for another thread to produce data, the processor core can switch to a different software thread that is ready to run without leaving the processor core idle.
Choosing an effective scheme to partition and schedule the work among threads is important to tune an application on CPUs and other device types. Subsequent sections will describe some of the techniques.
Thread Affinity Insight
Thread affinity designates the CPU cores on which specific threads execute. Performance can suffer if a thread moves around among cores, for instance, if threads do not execute on the same core, cache locality can become an inefficiency if data ping-pongs between different cores.
The DPC++ runtime library supports several schemes for binding threads to core(s) through environment variables DPCPP_CPU_CU_AFFINITY, DPCPP_CPU_PLACES, DPCPP_CPU_NUM_CUS, and DPCPP_CPU_SCHEDULE, which are not defined by SYCL.

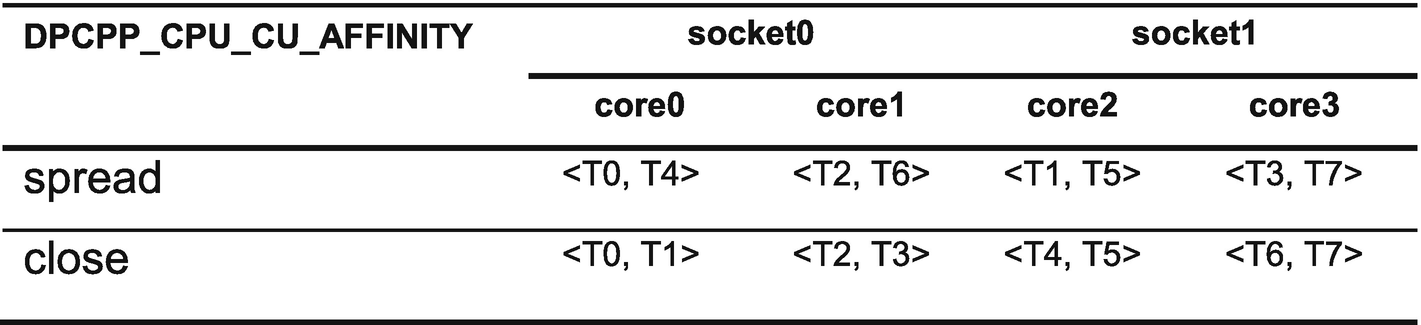
DPCPP_CPU_CU_AFFINITY environment variable


tid denotes a software thread identifier.
boundHT denotes a hyper-thread (logical core) that thread tid is bound to.
numHT denotes the number of hyper-threads per socket.
numSocket denotes the number of sockets in the system.
Mapping threads to cores with hyper-threads
DPCPP_CPU_NUM_CUS = [n], which sets the number of threads used for kernel execution. Its default value is the number of hardware threads in the system.
DPCPP_CPU_PLACES = [ sockets | numa_domains | cores | threads ], which specifies the places that the affinity will be set similar to OMP_PLACES in OpenMP 5.1. The default setting is cores.
- DPCPP_CPU_SCHEDULE = [ dynamic | affinity | static ], which specifies the algorithm for scheduling work-groups. Its default setting is dynamic.
dynamic: Enable the TBB auto_partitioner, which usually performs sufficient splitting to balance the load among worker threads.
affinity: Enable the TBB affinity_partitioner, which improves cache affinity and uses proportional splitting when mapping subranges to worker threads.
static: Enable the TBB static_partitioner, which distributes iterations among worker threads as uniformly as possible.
The TBB partitioner uses a grain size to control work splitting, with a default grain size of 1 which indicates that all work-groups can be executed independently. More information can be found at spec.oneapi.com/versions/latest/elements/oneTBB/source/algorithms.html#partitioners.
By using numa_domains as the places setting for affinity, the TBB task arenas are bound to NUMA nodes or sockets, and the work is uniformly distributed across task arenas. In general, the environment variable DPCPP_CPU_PLACES is recommended to be used together with DPCPP_CPU_CU_AFFINITY. These environment variable settings help us to achieve a ~30% performance gain on a Skylake server system with 2 sockets and 28 two-way hyper-threading cores per socket, running at 2.5 GHz. However, we can still do better to further improve the performance on this CPU.
Be Mindful of First Touch to Memory

STREAM Triad parallel initialization kernel to control first touch effects
Exploiting parallelism in the initialization code improves performance of the kernel when run on a CPU. In this instance, we achieve a ~2x performance gain on an Intel Xeon processor system.
The recent sections of this chapter have shown that by exploiting thread-level parallelism, we can utilize CPU cores and hyper-threads effectively. However, we need to exploit the SIMD vector-level parallelism in the CPU core hardware as well, to achieve peak performance.
DPC++ parallel kernels benefit from thread-level parallelism across cores and hyper-threads!
SIMD Vectorization on CPU
While a well-written DPC++ kernel without cross-work-item dependences can run in parallel effectively on a CPU, we can also apply vectorization to DPC++ kernels to leverage SIMD hardware, similarly to the GPU support described in Chapter 15. Essentially, CPU processors may optimize memory loads, stores, and operations using SIMD instructions by leveraging the fact that most data elements are often in contiguous memory and take the same control flow paths through a data-parallel kernel. For example, in a kernel with a statement a[i] = a[i] + b[i], each data element executes with same instruction stream load , load, add, and store by sharing hardware logic among multiple data elements and executing them as a group, which may be mapped naturally onto a hardware’s SIMD instruction set. Specifically, multiple data elements can be processed simultaneously by a single instruction.

Instruction stream for SIMD execution
CPU processors are not the only processors that implement SIMD instruction sets. Other processors such as GPUs implement SIMD instructions to improve efficiency when processing large sets of data. A key difference with Intel Xeon CPU processors, compared with other processor types, is having three fixed-size SIMD register widths 128-bit XMM, 256-bit YMM, and 512-bit ZMM instead of a variable length of SIMD width. When we write DPC++ code with SIMD parallelism using sub-group or vector types, we need to be mindful of SIMD width and the number of SIMD vector registers in the hardware.
Ensure SIMD Execution Legality
Semantically , the DPC++ execution model ensures that SIMD execution can be applied to any kernel, and a set of work-items in each work-group (i.e., a sub-group) may be executed concurrently using SIMD instructions. Some implementations may instead choose to execute loops within a kernel using SIMD instructions, but this is possible if and only if all original data dependences are preserved, or data dependences are resolved by the compiler based on privatization and reduction semantics.
A single DPC++ kernel execution can be transformed from processing of a single work-item to a set of work-items using SIMD instructions within the work-group. Under the ND-range model, the fastest-growing (unit-stride) dimension is selected by the compiler vectorizer on which to generate SIMD code. Essentially, to enable vectorization given an ND-range, there should be no cross-work-item dependences between any two work-items in the same sub-group, or the compiler needs to preserve cross-work-item forward dependences in the same sub-group.

Using a sub-group to vectorize a loop with a forward dependence
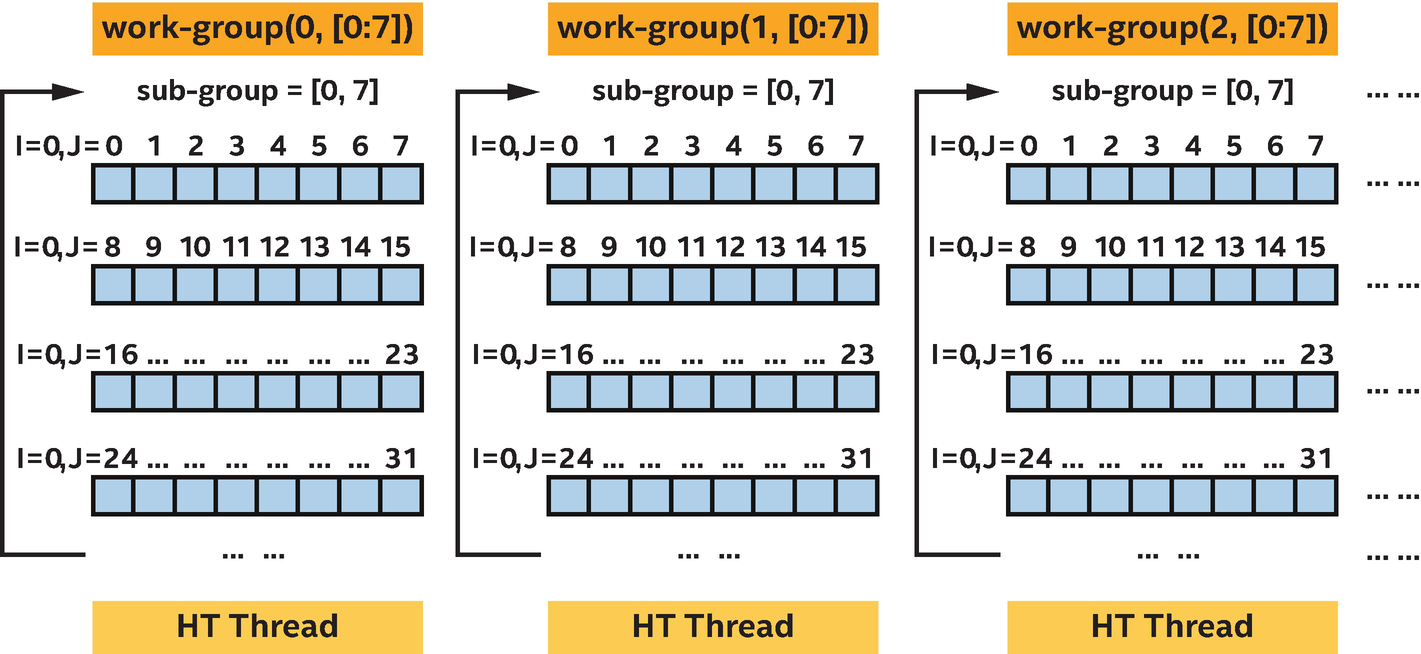
SIMD vectorization for a loop with a forward dependence
In this example, if the loop in the kernel dominates the performance, allowing SIMD vectorization across the sub-group will result in a significant performance improvement.
The use of SIMD instructions that process data elements in parallel is one way to let the performance of the kernel scale beyond the number of CPU cores and hyper-threads.
SIMD Masking and Cost
In real applications, we can expect conditional statements such as an if statement, conditional expressions such as a = b > a? a: b, loops with a variable number of iterations, switch statements, and so on. Anything that is conditional may lead to scalar control flows not executing the same code paths and, just like on a GPU (Chapter 15), can lead to decreased performance. A SIMD mask is a set of bits with the value 1 or 0, which is generated from conditional statements in a kernel. Consider an example with A={1, 2, 3, 4}, B={3, 7, 8, 1}, and the comparison expression a < b. The comparison returns a mask with four values {1, 1, 1, 0} that can be stored in a hardware mask register, to dictate which lanes of later SIMD instructions should execute the code that was guarded (enabled) by the comparison.
If a kernel contains conditional code, it is vectorized with masked instructions that are executed based on the mask bits associated with each data element (lane in the SIMD instruction). The mask bit for each data element is the corresponding bit in a mask register.
An additional mask blend operation on each load
Dependence on the destination
Masking has a cost, so use it only when necessary. When a kernel is an ND-range kernel with explicit groupings of work-items in the execution range, care should be taken when choosing an ND-range work-group size to maximize SIMD efficiency by minimizing masking cost. When a work-group size is not evenly divisible by a processor’s SIMD width, part of the work-group may execute with masking for the kernel.
With no masking, the processor executes two multiplies (vmulps) per cycle.
With merge masking, the processor executes two multiplies every four cycles as the multiply instruction (vmulps) preserves results in the destination register as shown in Figure 16-17.
Zero masking doesn’t have a dependence on the destination register and therefore can execute two multiplies (vmulps) per cycle.

Three masking code generations for masking in kernel
Accessing cache-aligned data gives better performance than accessing non-aligned data. In many cases, the address is not known at compile time or is known and not aligned. In these cases, a peeling on memory accesses may be implemented, to process the first few elements using masked accesses, up to the first aligned address, and then to process unmasked accesses followed by a masked remainder, through multiversioning techniques in the parallel kernel. This method increases code size, but improves data processing overall.
Avoid Array-of-Struct for SIMD Efficiency

SIMD gather in a kernel
When the compiler vectorizes the kernel along a set of work-items, it leads to SIMD gather instruction generation due to the need for non-unit-stride memory accesses. For example, the stride of a[0].x, a[1].x, a[2].x and a[3].x is 4, not a more efficient unit-stride of 1.

In a kernel, we can often achieve a higher SIMD efficiency by eliminating the use of memory gather-scatter operations. Some code benefits from a data layout change that converts data structures written in an Array-of-Struct (AOS) representation to a Structure of Arrays (SOA) representation, that is, having separate arrays for each structure field to keep memory accesses contiguous when SIMD vectorization is performed. For example, consider a SOA data layout of struct {float x[4]; float y[4]; float z[4]; float w[4];} a; as shown here:


SIMD unit-stride vector load in a kernel
The SOA data layout helps prevent gathers when accessing one field of the structure across the array elements and helps the compiler to vectorize kernels over the contiguous array elements associated with work-items. Note that such AOS-to-SOA or AOSOA data layout transformations are expected to be done at the program level (by us) considering all the places where those data structures are used. Doing it at just a loop level will involve costly transformations between the formats before and after the loop. However, we may also rely on the compiler to perform vector-load-and-shuffle optimizations for AOS data layouts with some cost. When a member of SOA (or AOS) data layout has a vector type, the compiler vectorization will perform either horizontal expansion or vertical expansion as described in Chapter 11 based on underlying hardware to generate optimal code.
Data Type Impact on SIMD Efficiency
Read of a[get_global_id(0)] leads to a SIMD unit-stride vector load.
Read of a[(int)get_global_id(0)] leads to a non-unit-stride gather instruction.

Examples of integer type value wraparound
SIMD gather/scatter instructions are slower than SIMD unit-stride vector load/store operations. In order to achieve an optimal SIMD efficiency, avoiding gathers/scatters can be critical for an application regardless of which programming language is used.
Most SYCL get_*_id() family functions have the same detail, although many cases fit within MAX_INT because the possible return values are bounded (e.g., the maximum id within a work-group). Thus, whenever legal, the DPC++ compiler will assume unit-stride memory addresses across the chunk of neighboring work-items to avoid gather/scatters. For cases that the compiler can’t safely generate linear unit-stride vector memory loads/stores because of possible overflow from the value of global IDs and/or derivative value from global IDs, the compiler will generate gathers/scatters.
Under the philosophy of delivering optimal performance for users, the DPC++ compiler assumes no overflow, and captures the realty almost all of the time in practice, so the compiler can generate optimal SIMD code to achieve good performance. However, an overriding compiler macro—D__SYCL_DISABLE_ID_TO_INT_CONV__—is provided by the DPC++ compiler for us to tell the compiler that there will be an overflow and that vectorized accesses derived from the id queries may not be safe. This can have large performance impact and should be used whenever unsafe to assume no overflow.
SIMD Execution Using single_task

Using vector types and swizzle operations in the single_task kernel
In the example as shown in Figure 16-18, under single task execution , a vector with three data elements is declared. A swizzle operation is performed with old_v.abgr(). If a CPU provides SIMD hardware instructions for some swizzle operations, we may achieve some performance benefits of using swizzle operations in applications.
CPU processors implement SIMD instruction sets with different SIMD widths. In many cases, this is an implementation detail and is transparent to the application executing kernels on the CPU, as the compiler can determine an efficient group of data elements to process with a specific SIMD size rather than requiring us to use the SIMD instructions explicitly. Sub-groups may be used to more directly express cases where the grouping of data elements should be subject to SIMD execution in kernels.
Given computational complexity, selecting the code and data layouts that are most amenable to vectorization may ultimately result in higher performance. While selecting data structures, try to choose a data layout, alignment, and data width such that the most frequently executed calculation can access memory in a SIMD-friendly manner with maximum parallelism, as described in this chapter.
Summary
Be familiar with all types of DPC++ parallelism and the underlying CPU architectures we wish to target.
Exploit the right amount of parallelism, not more and not less, at a thread level that best matches hardware resources. Use vendor tooling, such as analyzers and profilers, to help guide our tuning work to achieve this.
Be mindful of thread affinity and memory first touch impact on program performance.
Design data structures with a data layout, alignment, and data width such that the most frequently executed calculations can access memory in a SIMD-friendly manner with maximum SIMD parallelism.
Be mindful of balancing the cost of masking vs. code branches.
Use a clear programming style that minimizes potential memory aliasing and side effects.
Be aware of the scalability limitations of using vector types and interfaces. If a compiler implementation maps them to hardware SIMD instructions, a fixed vector size may not match the SIMD width of SIMD registers well across multiple generations of CPUs and CPUs from different vendors.

Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.