Memory consistency is not an esoteric concept if we want to be good parallel programmers. It is a critical piece of our puzzle, helping us to ensure that data is where we need it when we need it and that its values are what we are expecting. This chapter brings to light key things we need to master in order to ensure our program hums along correctly. This topic is not unique to SYCL or to DPC++.
Having a basic understanding of the memory (consistency) model of a programming language is necessary for any programmer who wants to allow concurrent updates to memory (whether those updates originate from multiple work-items in the same kernel, multiple devices, or both). This is true regardless of how memory is allocated, and the content of this chapter is equally important to us whether we choose to use buffers or USM allocations.
In previous chapters, we have focused on the development of simple kernels, where program instances either operate on completely independent data or share data using structured communication patterns that can be expressed directly using language and/or library features. As we move toward writing more complex and realistic kernels, we are likely to encounter situations where program instances may need to communicate in less structured ways—understanding how the memory model relates to DPC++ language features and the capabilities of the hardware we are targeting is a necessary precondition for designing correct, portable, and efficient programs.
Reason about which types of memory allocation can be accessed by which devices in the system: using buffers and USM.
Prevent unsafe concurrent memory accesses (data races) during the execution of our kernels: using barriers and atomics.
Enable safe communication between program instances executing the same kernel and safe communication between different devices: using barriers, fences, atomics, memory orders, and memory scopes.
Prevent optimizations that may alter the behavior of parallel applications in ways that are incompatible with our expectations: using barriers, fences, atomics, memory orders, and memory scopes.
Enable optimizations that depend on knowledge of programmer intent: using memory orders and memory scopes.
Memory models are a complex topic, but for a good reason—processor architects care about making processors and accelerators execute our codes as efficiently as possible! We have worked hard in this chapter to break down this complexity and highlight the most critical concepts and language features. This chapter starts us down the path of not only knowing the memory model inside and out but also enjoying an important aspect of parallel programming that many people don’t know exists. If questions remain after reading the descriptions and example codes here, we highly recommend visiting the websites listed at the end of this chapter or referring to the C++, SYCL, and DPC++ language specifications.
What Is in a Memory Model?
Data races and synchronization
Barriers and fences
Atomic operations
Memory ordering
Understanding these concepts at a high level is necessary to appreciate their expression and usage in C++, SYCL, and DPC++. Readers with extensive experience in parallel programming, especially using C++, may wish to skip ahead.
Data Races and Synchronization
- 1.
Load data[i] from memory into a temporary (register).
- 2.
Compute the result of adding x to data[i].
- 3.
Store the result back to data[i].
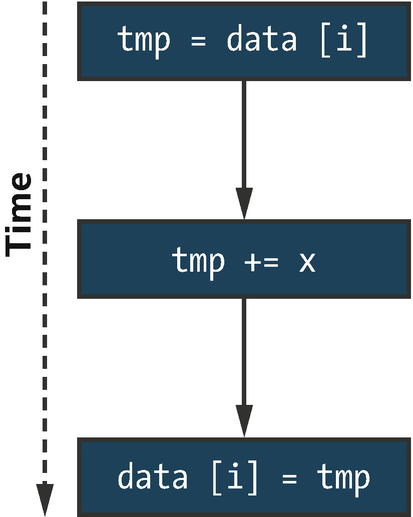
Sequential execution of data[i] += x broken into three separate operations
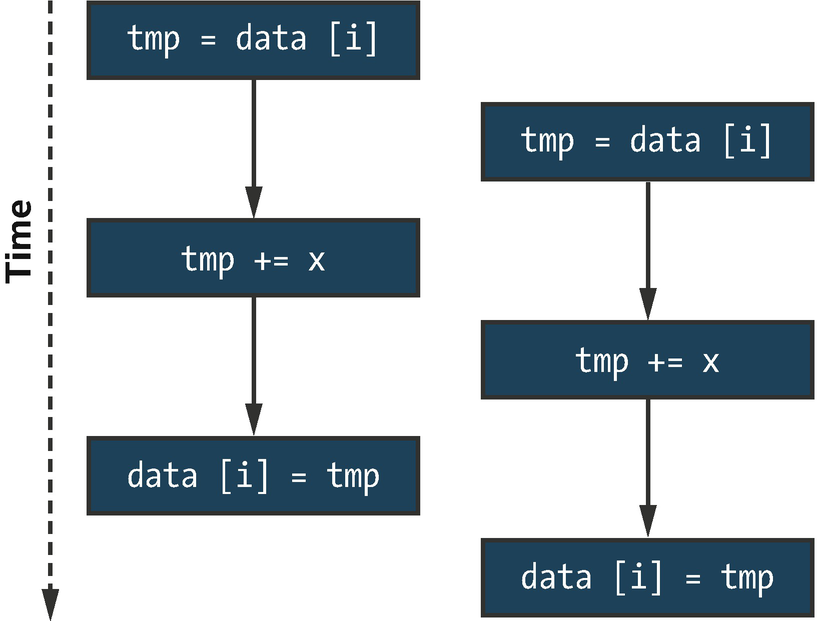
One possible interleaving of data[i] += x executed concurrently

Kernel containing a data race

Sample output of the code in Figure 19-3 for small values of N and M
In general, when developing massively parallel applications, we should not concern ourselves with the exact order in which individual work-items execute—there are hopefully hundreds (or thousands!) of work-items executing concurrently, and trying to impose a specific ordering upon them will negatively impact both scalability and performance. Rather, our focus should be on developing portable applications that execute correctly, which we can achieve by providing the compiler (and hardware) with information about when program instances share data, what guarantees are needed when sharing occurs, and which execution orderings are legal.
Massively parallel applications should not be concerned with the exact order in which individual work-items execute!
Barriers and Fences
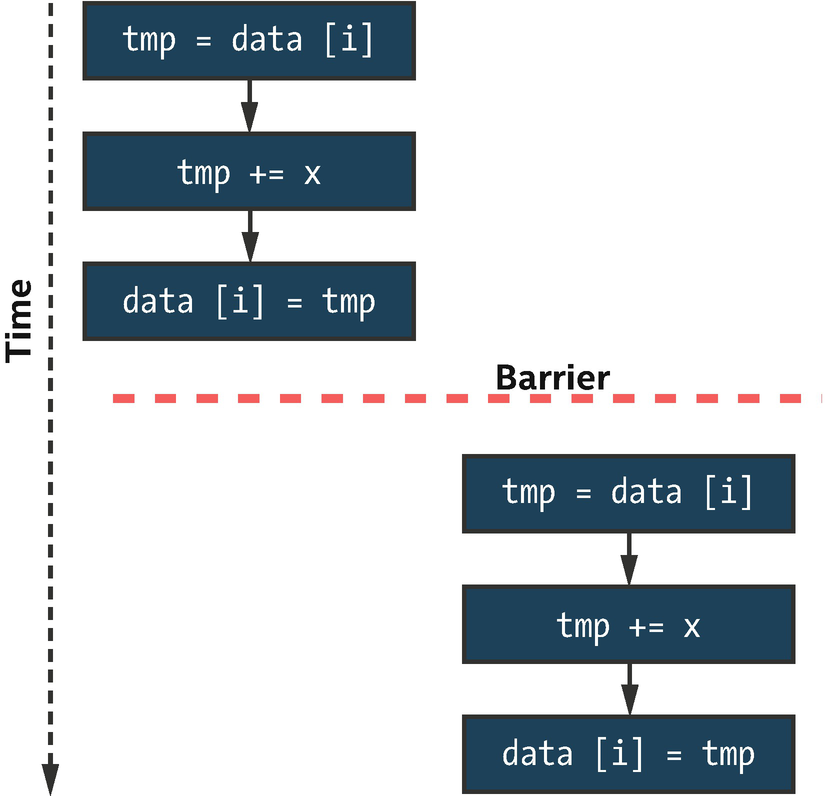
Two instances of data[i] += x separated by a barrier

Avoiding a data race using a barrier
Although using a barrier to implement this pattern is possible, it is not typically encouraged—it forces the work-items in a group to execute sequentially and in a specific order, which may lead to long periods of inactivity in the presence of load imbalance. It may also introduce more synchronization than is strictly necessary—if the different program instances happen to use different values of i, they will still be forced to synchronize at the barrier.
Barrier synchronization is a useful tool for ensuring that all work-items in a work-group or sub-group complete some stage of a kernel before proceeding to the next stage, but is too heavy-handed for fine-grained (and potentially data-dependent) synchronization. For more general synchronization patterns, we must look to atomic operations.
Atomic Operations
Atomic operations enable concurrent access to a memory location without introducing a data race. When multiple atomic operations access the same memory, they are guaranteed not to overlap. Note that this guarantee does not apply if only some of the accesses use atomics and that it is our responsibility as programmers to ensure that we do not concurrently access the same data using operations with different atomicity guarantees.
Mixing atomic and non-atomic operations on the same memory location(s) at the same time results in undefined behavior!

Avoiding a data race using atomic operations
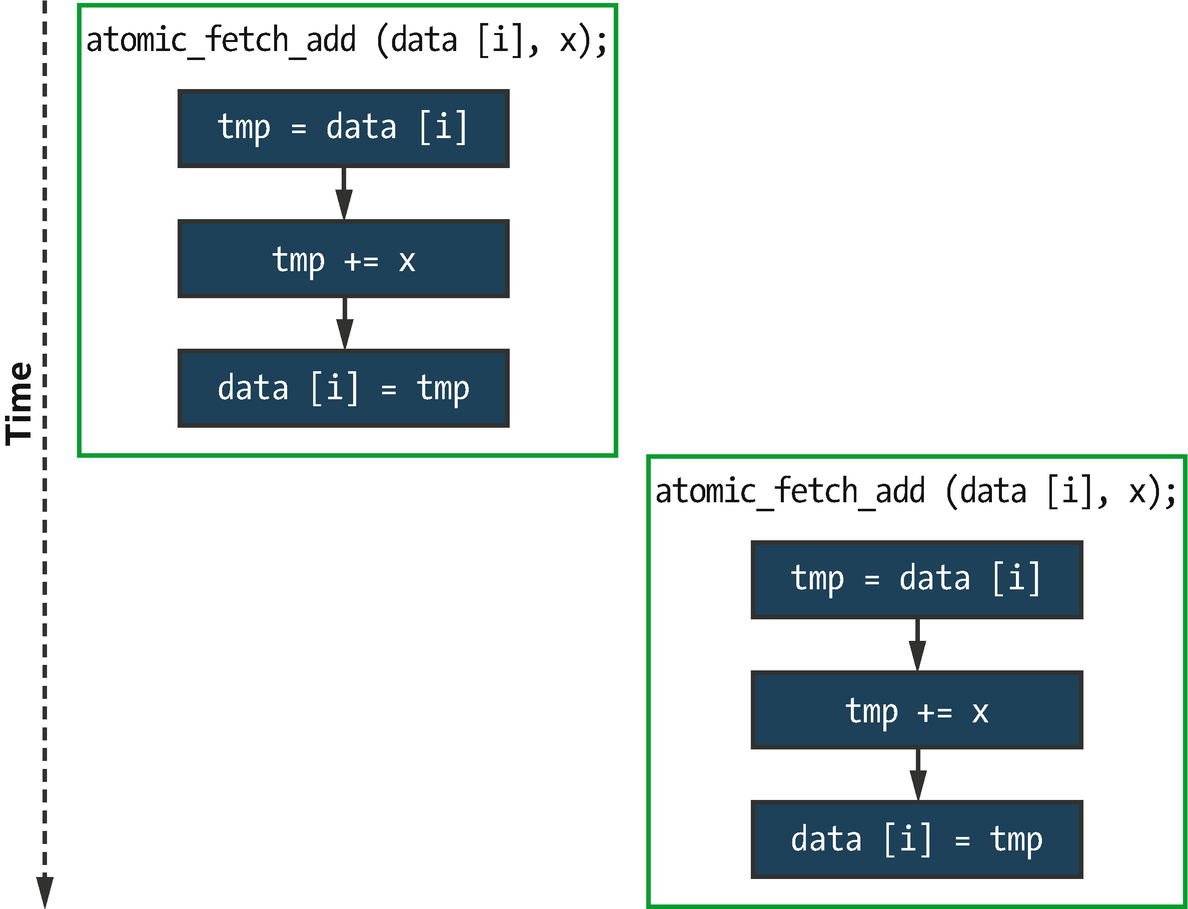
An interleaving of data[i] += x executed concurrently with atomic operations
However, it is important to note that this is still only one possible execution order. Using atomic operations guarantees that the two updates do not overlap (if both instances use the same value of i), but there is still no guarantee as to which of the two instances will execute first. Even more importantly, there are no guarantees about how these atomic operations are ordered with respect to any non-atomic operations in different program instances.
Memory Ordering
Even within a sequential application, optimizing compilers and the hardware are free to re-order operations if they do not change the observable behavior of an application. In other words, the application must behave as if it ran exactly as it was written by the programmer.
Unfortunately, this as-if guarantee is not strong enough to help us reason about the execution of parallel programs. We now have two sources of re-ordering to worry about: the compiler and hardware may re-order the execution of statements within each sequential program instance, and the program instances themselves may be executed in any (possibly interleaved) order. In order to design and implement safe communication protocols between program instances, we need to be able to constrain this re-ordering. By providing the compiler with information about our desired memory order, we can prevent re-ordering optimizations that are incompatible with the intended behavior of our applications.
- 1.
A relaxed memory ordering
- 2.
An acquire-release or release-acquire memory ordering
- 3.
A sequentially consistent memory ordering
Under a relaxed memory ordering, memory operations can be re-ordered without any restrictions. The most common usage of a relaxed memory model is incrementing shared variables (e.g., a single counter, an array of values during a histogram computation).
Under an acquire-release memory ordering, one program instance releasing an atomic variable and another program instance acquiring the same atomic variable acts as a synchronization point between those two program instances and guarantees that any prior writes to memory issued by the releasing instance are visible to the acquiring instance. Informally, we can think of atomic operations releasing side effects from other memory operations to other program instances or acquiring the side effects of memory operations on other program instances. Such a memory model is required if we want to communicate values between pairs of program instances via memory, which may be more common than we would think. When a program acquires a lock, it typically goes on to perform some additional calculations and modify some memory before eventually releasing the lock—only the lock variable is ever updated atomically, but we expect memory updates guarded by the lock to be protected from data races. This behavior relies on an acquire-release memory ordering for correctness, and attempting to use a relaxed memory ordering to implement a lock will not work.
Under a sequentially consistent memory ordering, the guarantees of acquire-release ordering still hold, but there additionally exists a single global order of all atomic operations. The behavior of this memory ordering is the most intuitive of the three and the closest that we can get to the original as-if guarantee we are used to relying upon when developing sequential applications. With sequential consistency, it becomes significantly easier to reason about communication between groups (rather than pairs) of program instances, since all program instances must agree on the global ordering of all atomic operations.
Understanding which memory orders are supported by a combination of programming model and device is a necessary part of designing portable parallel applications. Being explicit in describing the memory order required by our applications ensures that they fail predictably (e.g., at compile time) when the behavior we require is unsupported and prevents us from making unsafe assumptions.
The Memory Model
How to express the memory ordering requirements of our kernels
How to query the memory orders supported by a specific device
How the memory model behaves with respect to disjoint address spaces and multiple devices
How the memory model interacts with barriers, fences, and atomics
How using atomic operations differs between buffers and USM
The memory model is based on the memory model of standard C++ but differs in some important ways. These differences reflect our long-term vision that DPC++ and SYCL should help inform future C++ standards: the default behaviors and naming of classes are closely aligned with the C++ standard library and are intended to extend standard C++ functionality rather than to restrict it.
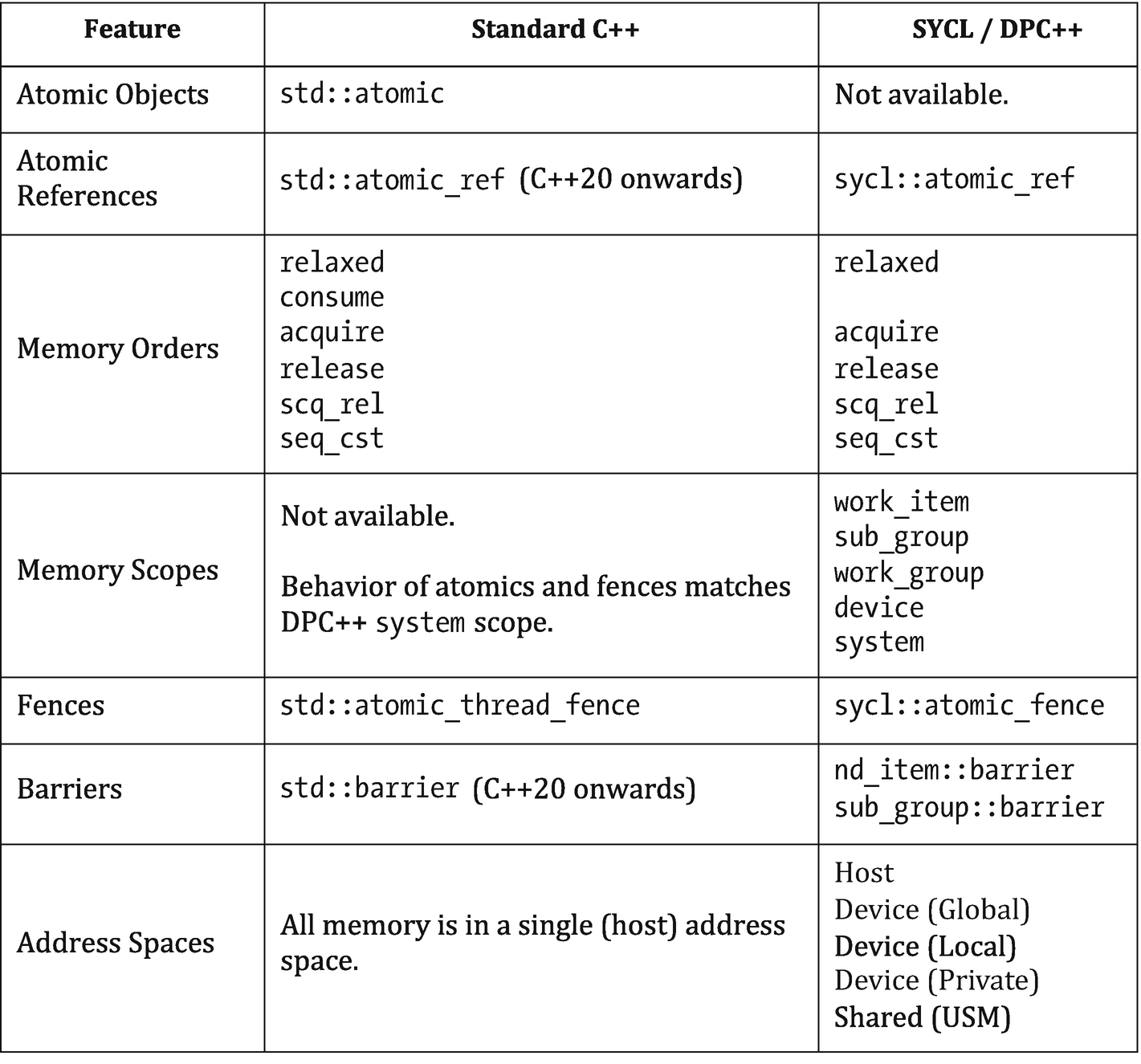
Comparing standard C++ and SYCL/DPC++ memory models
The memory_order Enumeration Class
memory_order::relaxed
Read and write operations can be re-ordered before or after the operation with no restrictions. There are no ordering guarantees.
memory_order::acquire
Read and write operations appearing after the operation in the program must occur after it (i.e., they cannot be re-ordered before the operation).
memory_order::release
Read and write operations appearing before the operation in the program must occur before it (i.e., they cannot be re-ordered after the operation), and preceding write operations are guaranteed to be visible to other program instances which have been synchronized by a corresponding acquire operation (i.e., an atomic operation using the same variable and memory_order::acquire or a barrier function).
memory_order::acq_rel
The operation acts as both an acquire and a release. Read and write operations cannot be re-ordered around the operation, and preceding writes must be made visible as previously described for memory_order::release.
memory_order::seq_cst
The operation acts as an acquire, release, or both depending on whether it is a read, write, or read-modify-write operation, respectively. All operations with this memory order are observed in a sequentially consistent order.
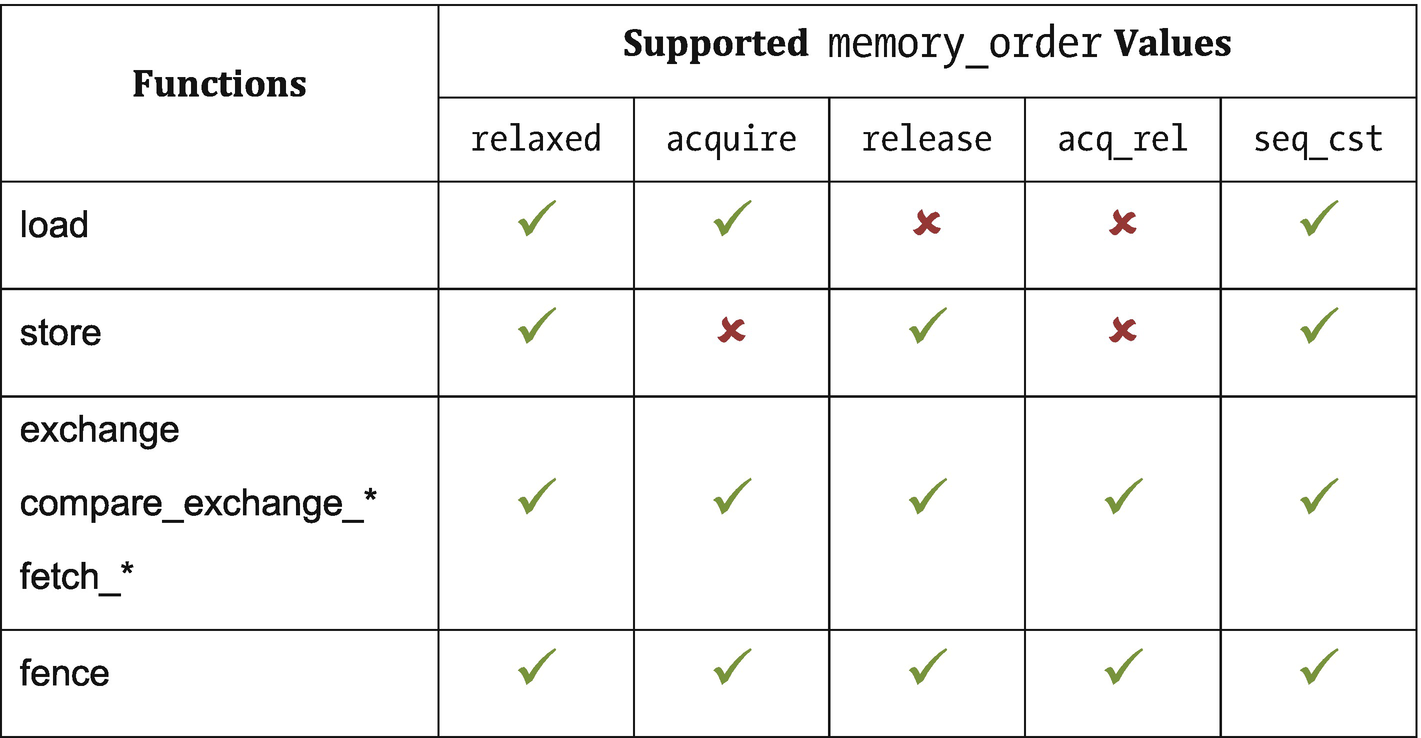
Supporting atomic operations with memory_order
Load operations do not write values to memory and are therefore incompatible with release semantics. Similarly, store operations do not read values from memory and are therefore incompatible with acquire semantics. The remaining read-modify-write atomic operations and fences are compatible with all memory orderings.
The C++ memory model additionally includes memory_order::consume, with similar behavior to memory_order::acquire. However, the C++17 standard discourages its use, noting that its definition is being revised. Its inclusion in DPC++ has therefore been postponed to a future version.
The memory_scope Enumeration Class
The standard C++ memory model assumes that applications execute on a single device with a single address space. Neither of these assumptions holds for DPC++ applications: different parts of the application execute on different devices (i.e., a host device and one or more accelerator devices); each device has multiple address spaces (i.e., private, local, and global); and the global address space of each device may or may not be disjoint (depending on USM support).
memory_scope::work_item
The memory ordering constraint applies only to the calling work-item. This scope is only useful for image operations, as all other operations within a work-item are already guaranteed to execute in program order.
memory_scope::sub_group, memory_scope::work_group
The memory ordering constraint applies only to work-items in the same sub-group or work-group as the calling work-item.
memory_scope::device
The memory ordering constraint applies only to work-items executing on the same device as the calling work-item.
memory_scope::system
The memory ordering constraint applies to all work-items in the system.
- 1.
If an atomic operation updates a value in work-group local memory, any scope broader than memory_scope::work_group is narrowed (because local memory is only visible to work-items in the same work-group).
- 2.
If a device does not support USM, specifying memory_scope::system is always equivalent to memory_scope::device (because buffers cannot be accessed concurrently by multiple devices).
- 3.
If an atomic operation uses memory_order::relaxed, there are no ordering guarantees, and the memory scope argument is effectively ignored.
Querying Device Capabilities
atomic_memory_order_capabilities
atomic_fence_order_capabilities
Return a list of all memory orderings supported by atomic and fence operations on a specific device. All devices are required to support at least memory_order::relaxed, and the host device is required to support all memory orderings.
atomic_memory_scope_capabilities
atomic_fence_scope_capabilities
Return a list of all memory scopes supported by atomic and fence operations on a specific device. All devices are required to support at least memory_order::work_group, and the host device is required to support all memory scopes.
- 1.
Develop applications with sequential consistency and system fences.
Only consider adopting less strict memory orders during performance tuning.
- 2.
Develop applications with relaxed consistency and work-group fences.
Only consider adopting more strict memory orders and broader memory scopes where required for correctness.
The first approach ensures that the semantics of all atomic operations and fences match the default behavior of standard C++. This is the simplest and least error-prone option, but has the worst performance and portability characteristics.
The second approach is more aligned with the default behavior of previous versions of SYCL and languages like OpenCL. Although more complicated—since it requires that we become more familiar with the different memory orders and scopes—it ensures that the majority of the DPC++ code we write will work on any device without performance penalties.
Barriers and Fences
All previous usages of barriers and fences in the book so far have ignored the issue of memory order and scope, by relying on default behavior.
Every group barrier in DPC++ acts as an acquire-release fence to all address spaces accessible by the calling work-item and makes preceding writes visible to at least all other work-items in the same group. This ensures memory consistency within a group of work-items after a barrier, in line with our intuition of what it means to synchronize (and the definition of the synchronizes-with relation in C++).
The atomic_fence function gives us more fine-grained control than this, allowing work-items to execute fences with a specified memory order and scope. Group barriers in future versions of DPC++ may similarly accept an optional argument to adjust the memory scope of the acquire-release fences associated with a barrier.
Atomic Operations in DPC++
DPC++ provides support for many kinds of atomic operations on a variety of data types. All devices are guaranteed to support atomic versions of common operations (e.g., loads, stores, arithmetic operators), as well as the atomic compare-and-swap operations required to implement lock-free algorithms. The language defines these operations for all fundamental integer, floating-point, and pointer types—all devices must support these operations for 32-bit types, but 64-bit-type support is optional.
The atomic Class
The std::atomic class from C++11 provides an interface for creating and operating on atomic variables. Instances of the atomic class own their data, cannot be moved or copied, and can only be updated using atomic operations. These restrictions significantly reduce the chances of using the class incorrectly and introducing undefined behavior. Unfortunately, they also prevent the class from being used in DPC++ kernels—it is impossible to create atomic objects on the host and transfer them to the device! We are free to continue using std::atomic in our host code, but attempting to use it inside of device kernels will result in a compiler error.
The SYCL 1.2.1 specification included a cl::sycl::atomic class that is loosely based on the std::atomic class from C++11. We say loosely because there are some differences between the interfaces of the two classes, most notably that the SYCL 1.2.1 version does not own its data and defaults to a relaxed memory ordering.
The cl::sycl::atomic class is fully supported by DPC++, but its use is discouraged to avoid confusion. We recommend that the atomic_ref class (covered in the next section) be used in its place.
The atomic_ref Class
The std::atomic_ref class from C++20 provides an alternative interface for atomic operations which provides greater flexibility than std::atomic. The biggest difference between the two classes is that instances of std::atomic_ref do not own their data but are instead constructed from an existing non-atomic variable. Creating an atomic reference effectively acts as a promise that the referenced variable will only be accessed atomically for the lifetime of the reference. These are exactly the semantics needed by DPC++, since they allow us to create non-atomic data on the host, transfer that data to the device, and treat it as atomic data only after it has been transferred. The atomic_ref class used in DPC++ kernels is therefore based on std::atomic_ref.

Constructors and static members of the atomic_ref class
As discussed previously, the capabilities of different DPC++ devices are varied. Selecting a default behavior for the atomic classes of DPC++ is a difficult proposition: defaulting to standard C++ behavior (i.e., memory_order::seq_cst, memory_scope::system) limits code to executing only on the most capable of devices; on the other hand, breaking with C++ conventions and defaulting to the lowest common denominator (i.e., memory_order::relaxed, memory_scope::work_group) could lead to unexpected behavior when migrating existing C++ code. The design adopted by DPC++ offers a compromise, allowing us to define our desired default behavior as part of an object’s type (using the DefaultOrder and DefaultScope template arguments). Other orderings and scopes can be provided as runtime arguments to specific atomic operations as we see fit—the DefaultOrder and DefaultScope only impact operations where we do not or cannot override the default behavior (e.g., when using a shorthand operator like +=). The final template argument denotes the address space in which the referenced object is allocated.

Basic operations with atomic_ref for all types
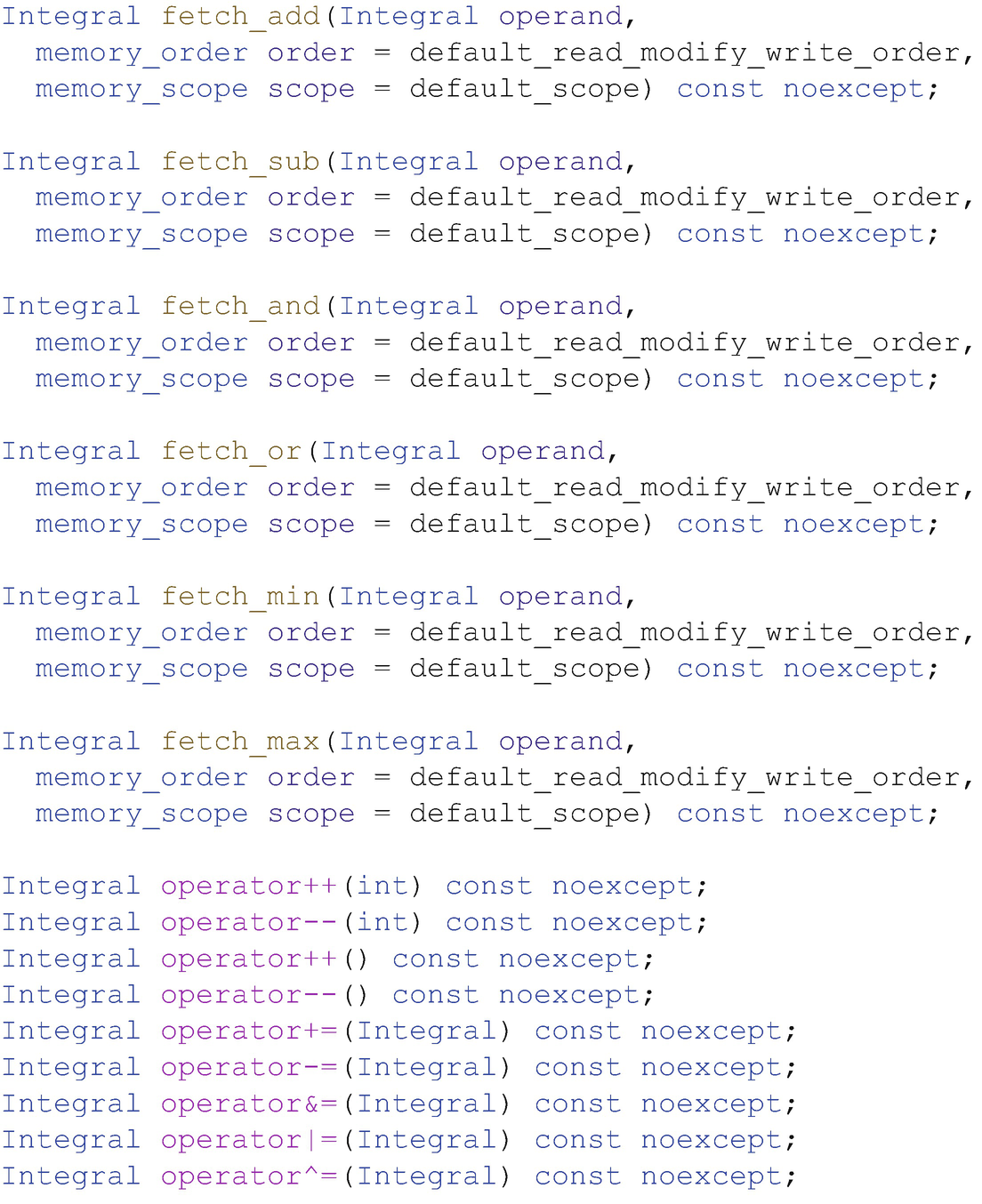
Additional operations with atomic_ref only for integral types

Additional operations with atomic_ref only for floating-point types
Using Atomics with Buffers

Accessing a buffer via an explicitly created atomic_ref
The code in Figure 19-15 is an example of expressing atomicity in DPC++ using an explicitly created atomic reference object. The buffer stores normal integers, and we require an accessor with both read and write permissions. We can then create an instance of atomic_ref for each data access, using the += operator as a shorthand alternative for the fetch_add member function.
This pattern is useful if we want to mix atomic and non-atomic accesses to a buffer within the same kernel, to avoid paying the performance overheads of atomic operations when they are not required. If we know that only a subset of the memory locations in the buffer will be accessed concurrently by multiple work-items, we only need to use atomic references when accessing that subset. Or, if we know that work-items in the same work-group only concurrently access local memory during one stage of a kernel (i.e., between two work-group barriers), we only need to use atomic references during that stage.

Accessing a buffer via an atomic_ref implicitly created by an atomic accessor
The buffer stores normal integers as before, but we replace the regular accessor with a special atomic_accessor type. Using such an atomic accessor automatically wraps each member of the buffer using an atomic reference, thereby simplifying the kernel code.
Whether it is best to use the atomic reference class directly or via an accessor depends on our use case. Our recommendation is to start with the accessor for simplicity during prototyping and initial development, only moving to the more explicit syntax if necessary during performance tuning (i.e., if profiling reveals atomic operations to be a performance bottleneck) or if atomicity is known to be required only during a well-defined phase of a kernel (e.g., as in the histogram code later in the chapter).
Using Atomics with Unified Shared Memory

Accessing a USM allocation via an explicitly created atomic_ref
There is no way of using only standard DPC++ features to mimic the shorthand syntax provided by atomic accessors for USM pointers. However, we expect that a future version of DPC++ will provide a shorthand built on top of the mdspan class that has been proposed for C++23.
Using Atomics in Real Life
- 1.
Computing a histogram
- 2.
Implementing device-wide synchronization
Computing a Histogram
The code in Figure 19-18 demonstrates how to use relaxed atomics in conjunction with work-group barriers to compute a histogram. The kernel is split by the barriers into three phases, each with their own atomicity requirements. Remember that the barrier acts both as a synchronization point and an acquire-release fence—this ensures that any reads and writes in one phase are visible to all work-items in the work-group in later phases.
The first phase sets the contents of some work-group local memory to zero. The work-items in each work-group update independent locations in work-group local memory by design—race conditions cannot occur, and no atomicity is required.
The second phase accumulates partial histogram results in local memory. Work-items in the same work-group may update the same locations in work-group local memory, but synchronization can be deferred until the end of the phase—we can satisfy the atomicity requirements using memory_order::relaxed and memory_scope::work_group.

Computing a histogram using atomic references in different memory spaces
Implementing Device-Wide Synchronization
Back in Chapter 4, we warned against writing kernels that attempt to synchronize work-items across work-groups. However, we fully expect several readers of this chapter will be itching to implement their own device-wide synchronization routines atop of atomic operations and that our warnings will be ignored.
Device-wide synchronization is currently not portable and is best left to expert programmers. Future versions of the language will address this.
The code discussed in this section is dangerous and should not be expected to work on all devices, because of potential differences in scheduling and concurrency guarantees. The memory ordering guarantees provided by atomics are orthogonal to forward progress guarantees; and, at the time of writing, work-group scheduling in SYCL and DPC++ is completely implementation-defined. Formalizing the concepts and terminology required to discuss execution models and scheduling guarantees is currently an area of active academic research, and future versions of DPC++ are expected to build on this work to provide additional scheduling queries and controls. For now, these topics should be considered expert-only.
Figure 19-19 shows a simple implementation of a device-wide latch (a single-use barrier), and Figure 19-20 shows a simple example of its usage. Each work-group elects a single work-item to signal arrival of the group at the latch and await the arrival of other groups using a naïve spin-loop, while the other work-items wait for the elected work-item using a work-group barrier. It is this spin-loop that makes device-wide synchronization unsafe; if any work-groups have not yet begun executing or the currently executing work-groups are not scheduled fairly, the code may deadlock.
Relying on memory order alone to implement synchronization primitives may lead to deadlocks in the absence of independent forward progress guarantees!
- 1.
The atomic operations must use memory orders at least as strict as those shown, in order to guarantee that the correct fences are generated.
- 2.
Each work-group in the ND-range must be capable of making forward progress, in order to avoid a single work-group spinning in the loop from starving a work-group that has yet to increment the counter.
- 3.The device must be capable of executing all work-groups in the ND-range concurrently, in order to ensure that all work-groups in the ND-range eventually reach the latch.
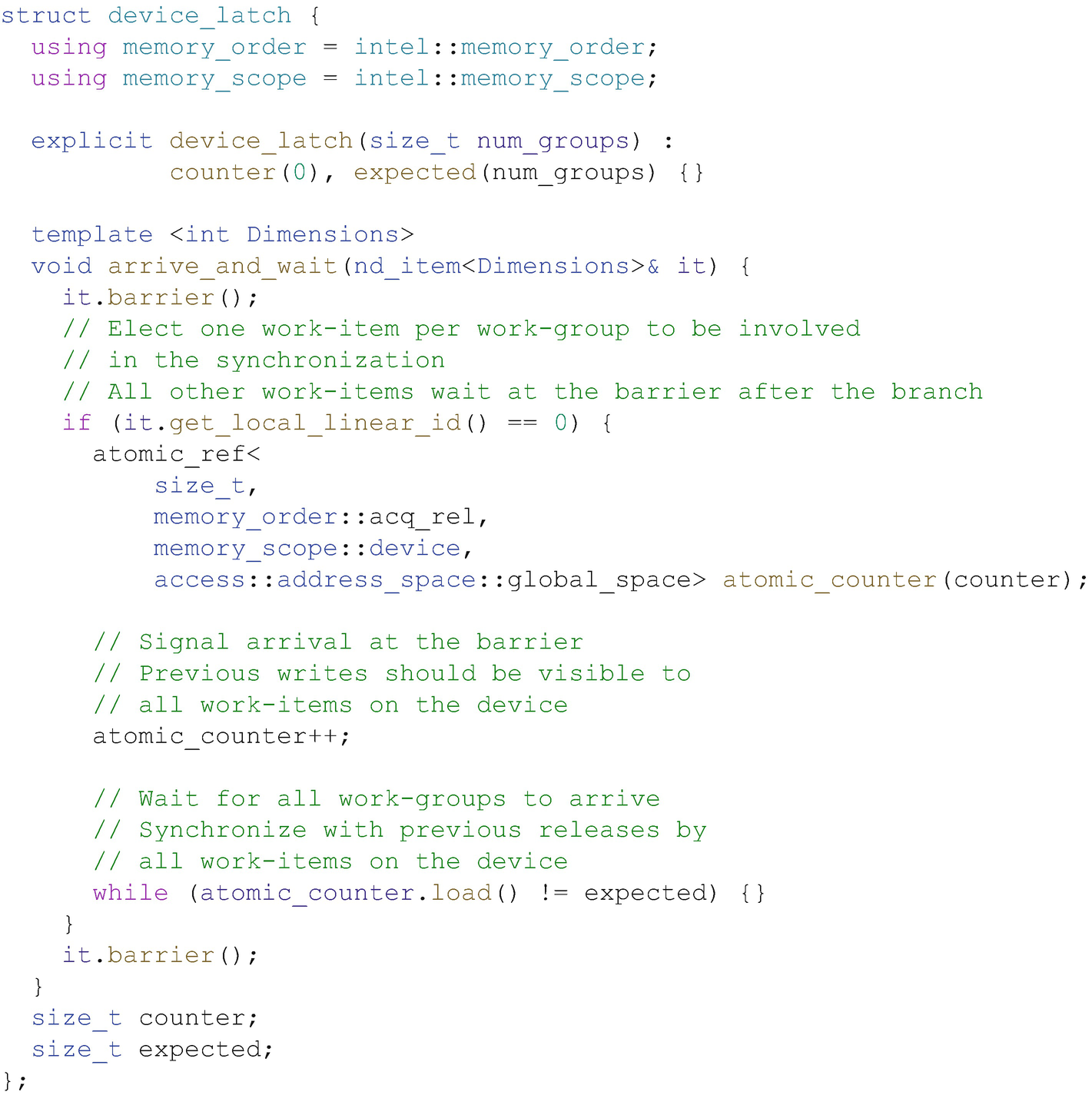 Figure 19-19
Figure 19-19Building a simple device-wide latch on top of atomic references
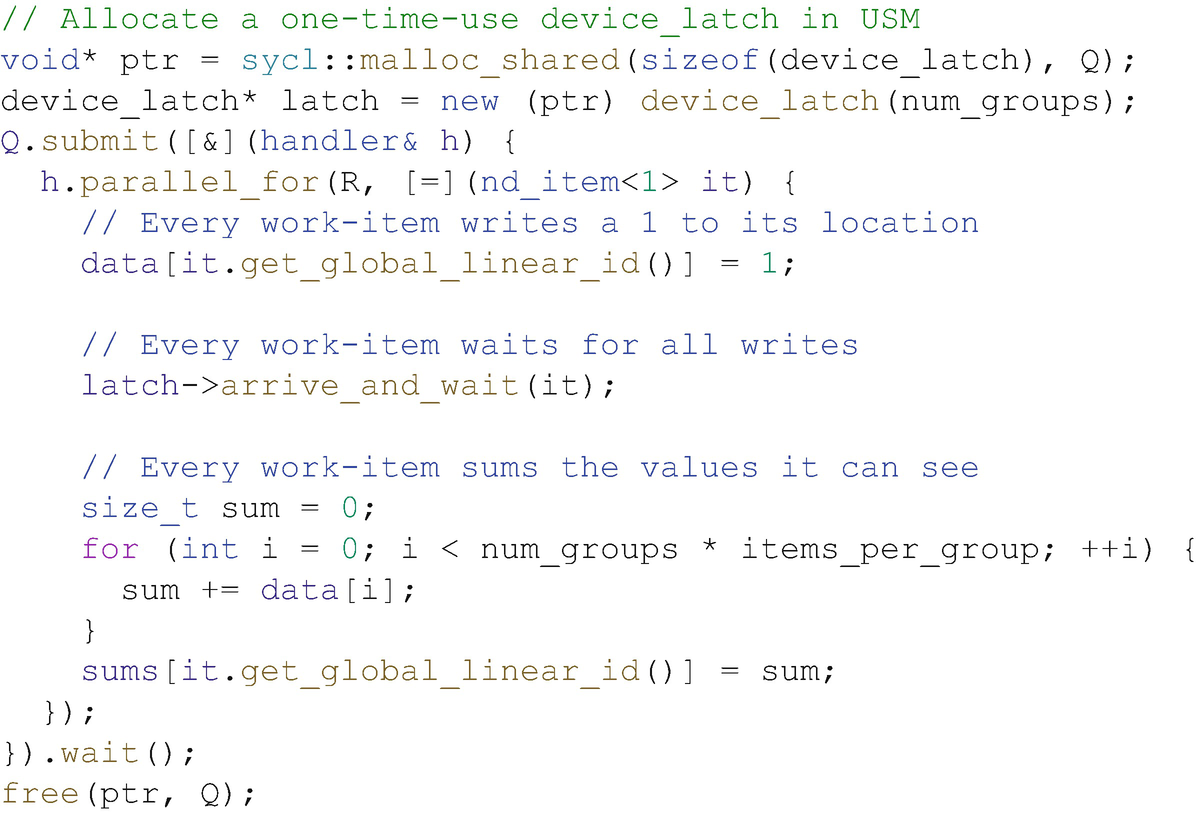 Figure 19-20
Figure 19-20Using the device-wide latch from Figure 19-19
Although this code is not guaranteed to be portable, we have included it here to highlight two key points: 1) DPC++ is expressive enough to enable device-specific tuning, sometimes at the expense of portability; and 2) DPC++ already contains the building blocks necessary to implement higher-level synchronization routines, which may be included in a future version of the language.
Summary
This chapter provided a high-level introduction to memory model and atomic classes. Understanding how to use (and how not to use!) these classes is key to developing correct, portable, and efficient parallel programs.
Memory models are an overwhelmingly complex topic, and our focus here has been on establishing a base for writing real applications. If more information is desired, there are several websites, books, and talks dedicated to memory models referenced in the following.
For More Information
A. Williams, C++ Concurrency in Action: Practical Multithreading, Manning, 2012, 978-1933988771
H. Sutter, “atomic<> Weapons: The C++ Memory Model and Modern Hardware”, https://herbsutter.com/2013/02/11/atomic-weapons-the-c-memory-model-and-modern-hardware/
H-J. Boehm, “Temporarily discourage memory_order_consume,” http://wg21.link/p0371
C++ Reference, “std::atomic,”
C++ Reference, “std::atomic_ref,”

Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.