6.2 Dictionaries
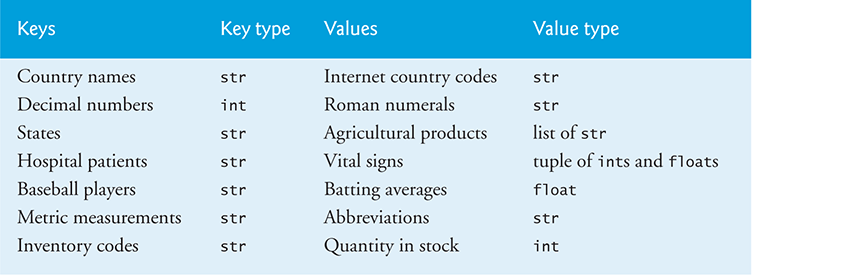
A dictionary associates keys with values. Each key maps to a specific value. The following table contains examples of dictionaries with their keys, key types, values and value types:
Unique Keys
A dictionary’s keys must be immutable (such as strings, numbers or tuples) and unique (that is, no duplicates). Multiple keys can have the same value, such as two different inventory codes that have the same quantity in stock.
6.2.1 Creating a Dictionary
You can create a dictionary by enclosing in curly braces, {}, a comma-separated list of key–value pairs, each of the form key: value. You can create an empty dictionary with {}.
Let’s create a dictionary with the country-name keys 'Finland', 'South Africa' and 'Nepal' and their corresponding Internet country code values 'fi', 'za' and 'np':
In [1]: country_codes = {'Finland': 'fi', 'South Africa': 'za',...: 'Nepal': 'np'}...:In [2]: country_codesOut[2]: {'Finland': 'fi', 'South Africa': 'za', 'Nepal': 'np'}
When you output a dictionary, its comma-separated list of key–value pairs is always enclosed in curly braces. Because dictionaries are unordered collections, the display order can differ from the order in which the key–value pairs were added to the dictionary. In snippet [2]’s output the key–value pairs are displayed in the order they were inserted, but do not write code that depends on the order of the key–value pairs.
Determining if a Dictionary Is Empty
The built-in function len returns the number of key–value pairs in a dictionary:
In [3]: len(country_codes)Out[3]: 3
You can use a dictionary as a condition to determine if it’s empty—a non-empty dictionary evaluates to True:
In [4]: if country_codes:...: print('country_codes is not empty')...: else:...: print('country_codes is empty')...:country_codes is not empty
An empty dictionary evaluates to False. To demonstrate this, in the following code we call method clear to delete the dictionary’s key–value pairs, then in snippet [6] we recall and re-execute snippet [4]:
In [5]: country_codes.clear()In [6]: if country_codes:...: print('country_codes is not empty')...: else:...: print('country_codes is empty')...:country_codes is empty
 Self Check
Self Check
(Fill-In) can be thought of as unordered collections in which each value is accessed through its corresponding key.
Answer: Dictionaries.(True/False) Dictionaries may contain duplicate keys.
Answer: False. Dictionary keys must be unique. However, multiple keys may have the same value.(IPython Session) Create a dictionary named
statesthat maps three state abbreviations to their state names, then display the dictionary.
Answer:
In [1]: states = {'VT': 'Vermont', 'NH': 'New Hampshire',...: 'MA': 'Massachusetts'}...:In [2]: statesOut[2]: {'VT': 'Vermont', 'NH': 'New Hampshire', 'MA': 'Massachusetts'}
6.2.2 Iterating through a Dictionary
The following dictionary maps month-name strings to int values representing the numbers of days in the corresponding month. Note that multiple keys can have the same value:
In [1]: days_per_month = {'January': 31, 'February': 28, 'March': 31}In [2]: days_per_monthOut[2]: {'January': 31, 'February': 28, 'March': 31}
Again, the dictionary’s string representation shows the key–value pairs in their insertion order, but this is not guaranteed because dictionaries are unordered. We’ll show how to process keys in sorted order later in this chapter.
The following for statement iterates through days_per_month’s key–value pairs. Dictionary method items returns each key–value pair as a tuple, which we unpack into month and days:
In [3]: for month, days in days_per_month.items():...: print(f'{month} has {days} days')...:January has 31 daysFebruary has 28 daysMarch has 31 days
Self Check
(Fill-In) Dictionary method returns each key–value pair as a tuple.
Answer:items.
6.2.3 Basic Dictionary Operations
For this section, let’s begin by creating and displaying the dictionary roman_numerals. We intentionally provide the incorrect value 100 for the key 'X', which we’ll correct shortly:
In [1]: roman_numerals = {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 100}In [2]: roman_numeralsOut[2]: {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 100}
Accessing the Value Associated with a Key
Let’s get the value associated with the key 'V':
In [3]: roman_numerals['V']Out[3]: 5
Updating the Value of an Existing Key–Value Pair
You can update a key’s associated value in an assignment statement, which we do here to replace the incorrect value associated with the key 'X':
In [4]: roman_numerals['X'] = 10In [5]: roman_numeralsOut[5]: {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 10}
Adding a New Key–Value Pair
Assigning a value to a nonexistent key inserts the key–value pair in the dictionary:
In [6]: roman_numerals['L'] = 50In [7]: roman_numeralsOut[7]: {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 10, 'L': 50}
String keys are case sensitive. Assigning to a nonexistent key inserts a new key–value pair. This may be what you intend, or it could be a logic error.
Removing a Key–Value Pair
You can delete a key–value pair from a dictionary with the del statement:
In [8]: del roman_numerals['III']In [9]: roman_numeralsOut[9]: {'I': 1, 'II': 2, 'V': 5, 'X': 10, 'L': 50}
You also can remove a key–value pair with the dictionary method pop, which returns the value for the removed key:
In [10]: roman_numerals.pop('X')Out[10]: 10In [11]: roman_numeralsOut[11]: {'I': 1, 'II': 2, 'V': 5, 'L': 50}
Attempting to Access a Nonexistent Key
Accessing a nonexistent key results in a KeyError:
In [12]: roman_numerals['III']-------------------------------------------------------------------------KeyError Traceback (most recent call last)<ipython-input-12-ccd50c7f0c8b> in <module>()----> 1 roman_numerals['III']KeyError: 'III'
You can prevent this error by using dictionary method get, which normally returns its argument’s corresponding value. If that key is not found, get returns None. IPython does not display anything when None is returned in snippet [13]. If you specify a second argument to get, it returns that value if the key is not found:
In [13]: roman_numerals.get('III')In [14]: roman_numerals.get('III', 'III not in dictionary')Out[14]: 'III not in dictionary'In [15]: roman_numerals.get('V')Out[15]: 5
Testing Whether a Dictionary Contains a Specified Key
Operators in and not in can determine whether a dictionary contains a specified key:
In [16]: 'V' in roman_numeralsOut[16]: TrueIn [17]: 'III' in roman_numeralsOut[17]: FalseIn [18]: 'III' not in roman_numeralsOut[18]: True
Self Check
(True/False) Assigning to a nonexistent dictionary key causes an exception.
Answer: False. Assigning to a nonexistent key inserts a new key–value pair. This may be what you intend, or it could be a logic error if you incorrectly specify the key.(Fill-In) What does an expression of the following form do when the key is in the dictionary?
dictionaryName[key] = value
It updates the value associated with the key, replacing the original value.
(IPython Session) String dictionary keys are case sensitive. Confirm this by using the following dictionary and assigning
10to the key'x'—doing so adds a new key–value pair rather than correcting the value for the key'X':roman_numerals = {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 100}
Answer:In [1]: roman_numerals = {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 100}In [2]: roman_numerals['x'] = 10In [3]: roman_numeralsOut[3]: {'I': 1, 'II': 2, 'III': 3, 'V': 5, 'X': 100, 'x': 10}
6.2.4 Dictionary Methods keys and values
Earlier, we used dictionary method items to iterate through tuples of a dictionary’s key–value pairs. Similarly, methods keys and values can be used to iterate through only a dictionary’s keys or values, respectively:
In [1]: months = {'January': 1, 'February': 2, 'March': 3}In [2]: for month_name in months.keys():...: print(month_name, end=' ')...:January February MarchIn [3]: for month_number in months.values():...: print(month_number, end=' ')...:1 2 3
Dictionary Views
Dictionary methods items, keys and values each return a view of a dictionary’s data. When you iterate over a view, it “sees” the dictionary’s current contents—it does not have its own copy of the data.
To show that views do not maintain their own copies of a dictionary’s data, let’s first save the view returned by keys into the variable months_view, then iterate through it:
In [4]: months_view = months.keys()In [5]: for key in months_view:...: print(key, end=' ')...:January February March
Next, let’s add a new key–value pair to months and display the updated dictionary:
In [6]: months['December'] = 12In [7]: monthsOut[7]: {'January': 1, 'February': 2, 'March': 3, 'December': 12}
Now, let’s iterate through months_view again. The key we added above is indeed displayed:
In [8]: for key in months_view:...: print(key, end=' ')...:January February March December
Do not modify a dictionary while iterating through a view. According to Section 4.10.1 of the Python Standard Library documentation,1 either you’ll get a RuntimeError or the loop might not process all of the view’s values.
Converting Dictionary Keys, Values and Key–Value Pairs to Lists
You might occasionally need lists of a dictionary’s keys, values or key–value pairs. To obtain such a list, pass the view returned by keys, values or items to the built-in list function. Modifying these lists does not modify the corresponding dictionary:
In [9]: list(months.keys())Out[9]: ['January', 'February', 'March', 'December']In [10]: list(months.values())Out[10]: [1, 2, 3, 12]In [11]: list(months.items())Out[11]: [('January', 1), ('February', 2), ('March', 3), ('December', 12)]
Processing Keys in Sorted Order
To process keys in sorted order, you can use built-in function sorted as follows:
In [12]: for month_name in sorted(months.keys()):...: print(month_name, end=' ')...:February December January March
Self Check
(Fill-In) Dictionary method __________returns an unordered list of the dictionary’s keys.
Answer:keys.(True/False) A view has its own copy of the corresponding data from the dictionary.
Answer: False. A view does not have its own copy of the corresponding data from the dictionary. As the dictionary changes, each view updates dynamically.(IPython Session) For the following dictionary, create lists of its keys, values and items and show those lists.
roman_numerals = {'I': 1, 'II': 2, 'III': 3, 'V': 5}Answer:
In [1]: roman_numerals = {'I': 1, 'II': 2, 'III': 3, 'V': 5}In [2]: list(roman_numerals.keys())Out[2]: ['I', 'II', 'III', 'V']In [3]: list(roman_numerals.values())Out[3]: [1, 2, 3, 5]In [4]: list(roman_numerals.items())Out[4]: [('I', 1), ('II', 2), ('III', 3), ('V', 5)]
6.2.5 Dictionary Comparisons
The comparison operators == and != can be used to determine whether two dictionaries have identical or different contents. An equals (==) comparison evaluates to True if both dictionaries have the same key–value pairs, regardless of the order in which those key–value pairs were added to each dictionary:
In [1]: country_capitals1 = {'Belgium': 'Brussels',...: 'Haiti': 'Port-au-Prince'}...:In [2]: country_capitals2 = {'Nepal': 'Kathmandu',...: 'Uruguay': 'Montevideo'}...:In [3]: country_capitals3 = {'Haiti': 'Port-au-Prince',...: 'Belgium': 'Brussels'}...:In [4]: country_capitals1 == country_capitals2Out[4]: FalseIn [5]: country_capitals1 == country_capitals3Out[5]: TrueIn [6]: country_capitals1 != country_capitals2Out[6]: True
Self Check
(True/False) The
==comparison evaluates toTrueonly if both dictionaries have the same key–value pairs in the same order.
Answer: False. The==comparison evaluates toTrueif both dictionaries have the same key–value pairs, regardless of their order.
6.2.6 Example: Dictionary of Student Grades
The script in Fig. 6.1 represents an instructor’s grade book as a
dictionary that maps each student’s name (a string) to a list of integers containing that student’s grades on three exams. In each iteration of the loop that displays the data (lines 13–17), we unpack a key–value pair into the variables name and grades containing one student’s name and the corresponding list of three grades. Line 14 uses built-in function sum to total a given student’s grades, then line 15 calculates and displays that student’s average by dividing total by the number of grades for that student (len(grades)). Lines 16–17 keep track of the total of all four students’ grades and the number of grades for all the students, respectively. Line 19 prints the class average of all the students’ grades on all the exams.
Fig. 6.1 | Instructor’s gradebook dictionary.
1 # fig06_01.py 2 """Using a dictionary to represent an instructor's grade book.""" 3 grade_book = { 4 'Susan': [92, 85, 100], 5 'Eduardo': [83, 95, 79], 6 'Azizi': [91, 89, 82], 7 'Pantipa': [97, 91, 92] 8 } 9 10 all_grades_total = 0 11 all_grades_count = 0 12 13 for name, grades in grade_book.items(): 14 total = sum(grades) 15 print(f'Average for {name} is {total/len(grades):.2f}') 16 all_grades_total += total 17 all_grades_count += len(grades) 18 19 print(f"Class's average is: {all_grades_total / all_grades_count:.2f}")
Average for Susan is 92.33 Average for Eduardo is 85.67 Average for Azizi is 87.33 Average for Pantipa is 93.33 Class's average is: 89.67
6.2.7 Example: Word Counts2
The script in Fig. 6.2 builds a dictionary to count the number of occurrences of each word in a string. Lines 4–5 create a string text that we’ll break into words—a process known as tokenizing a string. Python automatically concatenates strings separated by whitespace in parentheses. Line 7 creates an empty dictionary. The dictionary’s keys will be the unique words, and its values will be integer counts of how many times each word appears in text.
Fig. 6.2 | Tokenizing a string and producing word counts.
1 # fig06_02.py 2 """Tokenizing a string and counting unique words.""" 3 4 text = ('this is sample text with several words ' 5 'this is more sample text with some different words') 6 7 word_counts = {} 8 9 # count occurrences of each unique word 10 for word in text.split(): 11 if word in word_counts: 12 word_counts[word] += 1 # update existing key-value pair 13 else: 14 word_counts[word] = 1 # insert new key-value pair 15 16 print(f'{"WORD":<12}COUNT') 17 18 for word, count in sorted(word_counts.items()): 19 print(f'{word:<12}{count}') 20 21 print('\nNumber of unique words:', len(word_counts))
WORD COUNT different 1 is 2 more 1 sample 2 several 1 some 1 text 2 this 2 with 2 words 2 Number of unique words: 10
Line 10 tokenizes text by calling string method split, which separates the words using the method’s delimiter string argument. If you do not provide an argument, split uses a space. The method returns a list of tokens (that is, the words in text). Lines 10–14 iterate through the list of words. For each word, line 11 determines whether that word (the key) is already in the dictionary. If so, line 12 increments that word’s count; otherwise, line 14 inserts a new key–value pair for that word with an initial count of 1.
Lines 16–21 summarize the results in a two-column table containing each word and its corresponding count. The for statement in lines 18 and 19 iterates through the dictionary’s key–value pairs. It unpacks each key and value into the variables word and count, then displays them in two columns. Line 21 displays the number of unique words.
Python Standard Library Module collections
The Python Standard Library already contains the counting functionality that we implemented using the dictionary and the loop in lines 10–14. The module collections contains the type Counter, which receives an iterable and summarizes its elements. Let’s reimplement the preceding script in fewer lines of code with Counter:
In [1]: from collections import CounterIn [2]: text = ('this is sample text with several words '...: 'this is more sample text with some different words')...:In [3]: counter = Counter(text.split())In [4]: for word, count in sorted(counter.items()):...: print(f'{word:>12}{count}')...:different 1is 2more 1sample 2several 1some 1text 2this 2with 2words 2In [5]: print('Number of unique keys:', len(counter.keys()))Number of unique keys: 10
Snippet [3] creates the Counter, which summarizes the list of strings returned by text.split(). In snippet [4], Counter method items returns each string and its associated count as a tuple. We use built-in function sorted to get a list of these tuples in ascending order. By default sorted orders the tuples by their first elements. If those are identical, then it looks at the second element, and so on. The for statement iterates over the resulting sorted list, displaying each word and count in two columns.
Self Check
(Fill-In) String method tokenizes a string using the delimiter provided in the method’s string argument.
Answer:split.(IPython Session) Use a comprehension to create a list of 50 random integers in the range 1–5. Summarize them with a
Counter. Display the results in two-column format.
Answer:In [1]: import randomIn [2]: numbers = [random.randrange(1, 6) for i in range(50)]In [3]: from collections import CounterIn [4]: counter = Counter(numbers)In [5]: for value, count in sorted(counter.items()):...: print(f'{value:<4}{count}')...:1 92 63 134 105 12
6.2.8 Dictionary Method update
You may insert and update key–value pairs using dictionary method update. First, let’s create an empty country_codes dictionary:
In [1]: country_codes = {}The following update call receives a dictionary of key–value pairs to insert or update:
In [2]: country_codes.update({'South Africa': 'za'})In [3]: country_codesOut[3]: {'South Africa': 'za'}
Method update can convert keyword arguments into key–value pairs to insert. The following call automatically converts the parameter name Australia into the string key 'Australia' and associates the value 'ar' with that key:
In [4]: country_codes.update(Australia='ar')In [5]: country_codesOut[5]: {'South Africa': 'za', 'Australia': 'ar'}
Snippet [4] provided an incorrect country code for Australia. Let’s correct this by using another keyword argument to update the value associated with 'Australia':
In [6]: country_codes.update(Australia='au')In [7]: country_codesOut[7]: {'South Africa': 'za', 'Australia': 'au'}
Method update also can receive an iterable object containing key–value pairs, such as a list of two-element tuples.
6.2.9 Dictionary Comprehensions
Dictionary comprehensions provide a convenient notation for quickly generating dictionaries, often by mapping one dictionary to another. For example, in a dictionary with unique values, you can reverse the key–value pairs:
In [1]: months = {'January': 1, 'February': 2, 'March': 3}In [2]: months2 = {number: name for name, number in months.items()}In [3]: months2Out[3]: {1: 'January', 2: 'February', 3: 'March'}
Curly braces delimit a dictionary comprehension, and the expression to the left of the for clause specifies a key–value pair of the form key: value. The comprehension iterates through months.items(), unpacking each key–value pair tuple into the variables name and number. The expression number: name reverses the key and value, so the new dictionary maps the month numbers to the month names.
What if months contained duplicate values? As these become the keys in months2, attempting to insert a duplicate key simply updates the existing key’s value. So if 'February' and 'March' both mapped to 2 originally, the preceding code would have produced
{1: 'January', 2: 'March'}
A dictionary comprehension also can map a dictionary’s values to new values. The following comprehension converts a dictionary of names and lists of grades into a dictionary of names and grade-point averages. The variables k and v commonly mean key and value:
In [4]: grades = {'Sue': [98, 87, 94], 'Bob': [84, 95, 91]}In [5]: grades2 = {k: sum(v) / len(v) for k, v in grades.items()}In [6]: grades2Out[6]: {'Sue': 93.0, 'Bob': 90.0}
The comprehension unpacks each tuple returned by grades.items() into k (the name) and v (the list of grades). Then, the comprehension creates a new key–value pair with the key k and the value of sum(v) / len(v), which averages the list’s elements.
Self Check
(IPython Session) Use a dictionary comprehension to create a dictionary of the numbers 1–5 mapped to their cubes:
Answer:In [1]: {number: number ** 3 for number in range(1, 6)}Out[1]: {1: 1, 2: 8, 3: 27, 4: 64, 5: 125}