17.2 Relational Databases and Structured Query Language (SQL)
Databases are crucial, especially for big data. In Chapter 9, “Files and Exceptions,” we demonstrated sequential text-file processing, working with data from CSV files and working with JSON. Both are useful when most or all of a file’s data is to be processed. On the other hand, in transaction processing it is crucial to locate and, possibly, update an individual data item quickly.
A database is an integrated collection of data. A database management system (DBMS) provides mechanisms for storing and organizing data in a manner consistent with the database’s format. Database management systems allow for convenient access and storage of data without concern for the internal representation of databases.
Relational database management systems (RDBMSs) store data in tables and define relationships among the tables. Structured Query Language (SQL) is used almost universally with relational database systems to manipulate data and perform queries, which request information that satisfies given criteria.2
Popular open-source RDBMSs include SQLite, PostgreSQL, MariaDB and MySQL. These can be downloaded and used freely by anyone. All have support for Python. We’ll use SQLite, which is bundled with Python. Some popular proprietary RDBMSs include Microsoft SQL Server, Oracle, Sybase and IBM Db2.
Tables, Rows and Columns
A relational database is a logical table-based representation of data that allows the data to be accessed without consideration of its physical structure. The following diagram shows a sample Employee table that might be used in a personnel system:
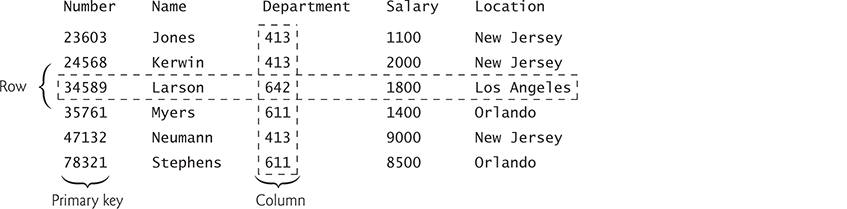
The table’s primary purpose is to store employees’ attributes. Tables are composed of rows, each describing a single entity. Here, each row represents one employee. Rows are composed of columns containing individual attribute values. The table above has six rows. The Number column represents the primary key—a column (or group of columns) with a value that’s unique for each row. This guarantees that each row can be identified by its primary key. Examples of primary keys are social security numbers, employee ID numbers and part numbers in an inventory system—values in each of these are guaranteed to be unique. In this case, the rows are listed in ascending order by primary key, but they could be listed in descending order or no particular order at all.
Each column represents a different data attribute. Rows are unique (by primary key) within a table, but particular column values may be duplicated between rows. For example, three different rows in the Employee table’s Department column contain number 413.
Selecting Data Subsets
Different database users are often interested in different data and different relationships among the data. Most users require only subsets of the rows and columns. Queries specify which subsets of the data to select from a table. You use Structured Query Language (SQL) to define queries. For example, you might select data from the Employee table to create a result that shows where each department is located, presenting the data sorted in increasing order by department number. This result is shown below. We’ll discuss SQL shortly.

SQLite
The code examples in the rest of Section 17.2 use the open-source SQLite database management system that’s included with Python, but most popular database systems have Python support. Each typically provides a module that adheres to Python’s Database Application Programming Interface (DB-API), which specifies common object and method names for manipulating any database.
 Self Check
Self Check
(Fill-In) A table in a relational database consists of and .
Answer: rows, columns.(Fill-In) The key uniquely identifies each record in a table.
Answer: primary.(True/False) Python’s Database Application Programming Interface (DB-API) specifies common object and method names for manipulating any database.
Answer: True.
17.2.1 A books Database
In this section, we’ll present a books database containing information about several of our books. We’ll set up the database in SQLite via the Python Standard Library’s sqlite3 module, using a script provided in the ch17 example’s folder’s sql subfolder. Then, we’ll introduce the database’s tables. We’ll use this database in an IPython session to introduce various database concepts, including operations that create, read, update and delete data—the so-called CRUD operations. As we introduce the tables, we’ll use SQL and pandas DataFrames to show you each table’s contents. Then, in the next several sections, we’ll discuss additional SQL features.
Creating the books Database
In your Anaconda Command Prompt, Terminal or shell, change to the ch17 examples folder’s sql subfolder. The following sqlite3 command creates a SQLite database named books.db and executes the books.sql SQL script, which defines how to create the database’s tables and populates them with data:
sqlite3 books.db < books.sqlThe notation < indicates that books.sql is input into the sqlite3 command. When the command completes, the database is ready for use. Begin a new IPython session.
Connecting to the Database in Python
To work with the database in Python, first call sqlite3’s connect function to connect to the database and obtain a Connection object:
In [1]: import sqlite3In [2]: connection = sqlite3.connect('books.db')
authors Table
The database has three tables—authors, author_ISBN and titles. The authors table stores all the authors and has three columns:
id—The author’s unique ID number. This integer column is defined as autoincremented—for each row inserted in the table, SQLite increases theidvalue by 1 to ensure that each row has a unique value. This column is the table’s primary key.first—The author’s first name (a string).last—The author’s last name (a string).
Viewing the authors Table’s Contents
Let’s use a SQL query and pandas to view the authors table’s contents:
In [3]: import pandas as pdIn [4]: pd.options.display.max_columns = 10In [5]: pd.read_sql('SELECT * FROM authors', connection,...: index_col=['id'])...:Out[5]:first lastid1 Paul Deitel2 Harvey Deitel3 Abbey Deitel4 Dan Quirk5 Alexander Wald
Pandas function read_sql executes a SQL query and returns a DataFrame containing the query’s results. The function’s arguments are:
a string representing the SQL query to execute,
the SQLite database’s
Connectionobject, and in this casean
index_colkeyword argument indicating which column should be used as theDataFrame’s row indices (the author’sidvalues in this case).
As you’ll see momentarily, when index_col is not passed, index values starting from 0 appear to the left of the DataFrame’s rows.
A SQL SELECT query gets rows and columns from one or more tables in a database. In the query:
SELECT * FROM authorsthe asterisk (*) is a wildcard indicating that the query should get all the columns from the authors table. We’ll discuss SELECT queries in more detail shortly.
titles Table
The titles table stores all the books and has four columns:
isbn—The book’s ISBN (a string) is this table’s primary key. ISBN is an abbreviation for “International Standard Book Number,” which is a numbering scheme that publishers use to give every book a unique identification number.title—The book’s title (a string).edition—The book’s edition number (an integer).copyright—The book’s copyright year (a string).
Let’s use SQL and pandas to view the titles table’s contents:
In [6]: pd.read_sql('SELECT * FROM titles', connection)Out[6]:isbn title edition copyright0 0135404673 Intro to Python for CS and DS 1 20201 0132151006 Internet & WWW How to Program 5 20122 0134743350 Java How to Program 11 20183 0133976890 C How to Program 8 20164 0133406954 Visual Basic 2012 How to Program 6 20145 0134601548 Visual C# How to Program 6 20176 0136151574 Visual C++ How to Program 2 20087 0134448235 C++ How to Program 10 20178 0134444302 Android How to Program 3 20179 0134289366 Android 6 for Programmers 3 2016
author_ISBN Table
The author_ISBN table uses the following columns to associate authors from the authors table with their books in the titles table:
id—An author’s id (an integer).isbn—The book’s ISBN (a string).
The id column is a foreign key, which is a column in this table that matches a primary-key column in another table—in particular, the authors table’s id column. The isbn column also is a foreign key—it matches the titles table’s isbn primary-key column. A database might have many tables. A goal when designing a database is to minimize data duplication among the tables. To do this, each table represents a specific entity, and foreign keys help link the data in multiple tables. The primary keys and foreign keys are designated when you create the database tables (in our case, in the books.sql script).
Together the id and isbn columns in this table form a composite primary key. Every row in this table uniquely matches one author to one book’s ISBN. This table contains many entries, so let’s use SQL and pandas to view just the first five rows:
In [7]: df = pd.read_sql('SELECT * FROM author_ISBN', connection)In [8]: df.head()Out[8]:id isbn0 1 01342893661 2 01342893662 5 01342893663 1 01354046734 2 0135404673
Every foreign-key value must appear as the primary-key value in a row of another table so the DBMS can ensure that the foreign-key value is valid. This is known as the Rule of Referential Integrity. For example, the DBMS ensures that the id value for a particular author_ISBN row is valid by checking that there is a row in the authors table with that id as the primary key.
Foreign keys also allow related data in multiple tables to be selected from those tables and combined—this is known as joining the data. There is a one-to-many relationship between a primary key and a corresponding foreign key—one author can write many books, and similarly one book can be written by many authors. So a foreign key can appear many times in its table but only once (as the primary key) in another table. For example, in the books database, the ISBN 0134289366 appears in several author_ISBN rows because this book has several authors, but it appears only once as a primary key in titles.
Entity-Relationship (ER) Diagram
The following entity-relationship (ER) diagram for the books database shows the database’s tables and the relationships among them:

The first compartment in each box contains the table’s name, and the remaining compartments contain the table’s columns. The names in italic are primary keys. A table’s primary key uniquely identifies each row in the table. Every row must have a primary-key value, and that value must be unique in the table. This is known as the Rule of Entity Integrity. Again, for the author_ISBN table, the primary key is the combination of both columns—this is known as a composite primary key.
The lines connecting the tables represent the relationships among the tables. Consider the line between authors and author_ISBN. On the authors end there’s a 1, and on the author_ISBN end there’s an infinity symbol (∞). This indicates a one-to-many relationship. For each author in the authors table, there can be an arbitrary number of ISBNs for books written by that author in the author_ISBN table—that is, an author can write any number of books, so an author’s id can appear in multiple rows of the author_ISBN table. The relationship line links the id column in the authors table (where id is the primary key) to the id column in the author_ISBN table (where id is a foreign key). The line between the tables links the primary key to the matching foreign key.
The line between the titles and author_ISBN tables illustrates a one-to-many relationship—one book can be written by many authors. The line links the primary key isbn in table titles to the corresponding foreign key in table author_ISBN. The relationships in the entity-relationship diagram illustrate that the sole purpose of the author_ISBN table is to provide a many-to-many relationship between the authors and titles tables—an author can write many books, and a book can have many authors.
SQL Keywords
The following subsections continue our SQL presentation in the context of our books database, demonstrating SQL queries and statements using the SQL keywords in the following table. Other SQL keywords are beyond this text’s scope:

Self Check
(Fill-In) A(n) key is a field in a table for which every entry has a unique value in another table and where the field in the other table is the primary key for that table.
Answer: foreign.(True/False) Every foreign-key value must appear as another table’s primary-key value so the DBMS can ensure that the foreign-key value is valid—this is known as the Rule of Entity Integrity.
Answer: False. This is known as the Rule of Referential Integrity. The Rule of Entity Integrity states that every row must have a primary-key value, and that value must be unique in the table.
17.2.2 SELECT Queries
The previous section used SELECT statements and the * wildcard character to get all the columns from a table. Typically, you need only a subset of the columns, especially in big data where you could have dozens, hundreds, thousands or more columns. To retrieve only specific columns, specify a comma-separated list of column names. For example, let’s retrieve only the columns first and last from the authors table:
In [9]: pd.read_sql('SELECT first, last FROM authors', connection)Out[9]:first last0 Paul Deitel1 Harvey Deitel2 Abbey Deitel3 Dan Quirk4 Alexander Wald
17.2.3 WHERE Clause
You’ll often select rows in a database that satisfy certain selection criteria, especially in big data where a database might contain millions or billions of rows. Only rows that satisfy the selection criteria (formally called predicates) are selected. SQL’s WHERE clause specifies a query’s selection criteria. Let’s select the title, edition and copyright for all books with copyright years greater than 2016. String values in SQL queries are delimited by single (') quotes, as in '2016':
In [10]: pd.read_sql("""SELECT title, edition, copyright...: FROM titles...: WHERE copyright > '2016'""", connection)Out[10]:title edition copyright0 Intro to Python for CS and DS 1 20201 Java How to Program 11 20182 Visual C# How to Program 6 20173 C++ How to Program 10 20174 Android How to Program 3 2017
Pattern Matching: Zero or More Characters
The WHERE clause may can contain the operators <, >, <=, >=, =, <> (not equal) and LIKE. Operator LIKE is used for pattern matching—searching for strings that match a given pattern. A pattern that contains the percent (%) wildcard character searches for strings that have zero or more characters at the percent character’s position in the pattern. For example, let’s locate all authors whose last name starts with the letter D:
In [11]: pd.read_sql("""SELECT id, first, last...: FROM authors...: WHERE last LIKE 'D%'""",...: connection, index_col=['id'])...:Out[11]:first lastid1 Paul Deitel2 Harvey Deitel3 Abbey Deitel
Pattern Matching: Any Character
An underscore (_) in the pattern string indicates a single wildcard character at that position. Let’s select the rows of all the authors whose last names start with any character, followed by the letter b, followed by any number of additional characters (specified by %):
In [12]: pd.read_sql("""SELECT id, first, last...: FROM authors...: WHERE first LIKE '_b%'""",...: connection, index_col=['id'])...:Out[12]:first lastid3 Abbey Deitel
Self Check
(Fill-In) SQL keyword is followed by the selection criteria that specify the records to select in a query.
Answer:WHERE.
17.2.4 ORDER BY Clause
The ORDER BY clause sorts a query’s results into ascending order (lowest to highest) or descending order (highest to lowest), specified with ASC and DESC, respectively. The default sorting order is ascending, so ASC is optional. Let’s sort the titles in ascending order:
In [13]: pd.read_sql('SELECT title FROM titles ORDER BY title ASC',...: connection)Out[13]:title0 Android 6 for Programmers1 Android How to Program2 C How to Program3 C++ How to Program4 Internet & WWW How to Program5 Intro to Python for CS and DS6 Java How to Program7 Visual Basic 2012 How to Program8 Visual C# How to Program9 Visual C++ How to Program
Sorting By Multiple Columns
To sort by multiple columns, specify a comma-separated list of column names after the ORDER BY keywords. Let’s sort the authors’ names by last name, then by first name for any authors who have the same last name:
In [14]: pd.read_sql("""SELECT id, first, last...: FROM authors...: ORDER BY last, first""",...: connection, index_col=['id'])...:Out[14]:first lastid2 Harvey Deitel3 Abbey Deitel1 Paul Deitel4 Dan Quirk5 Alexander Wald
The sorting order can vary by column. Let’s sort the authors in descending order by last name and ascending order by first name for any authors who have the same last name:
In [15]: pd.read_sql("""SELECT id, first, last...: FROM authors...: ORDER BY last DESC, first ASC""",...: connection, index_col=['id'])...:Out[15]:first lastid5 Alexander Wald4 Dan Quirk3 Abbey Deitel2 Harvey Deitel1 Paul Deitel
Combining the WHERE and ORDER BY Clauses
The WHERE and ORDER BY clauses can be combined in one query. Let’s get the isbn, title, edition and copyright of each book in the titles table that has a title ending with 'How to Program' and sort them in ascending order by title.
In [16]: pd.read_sql("""SELECT isbn, title, edition, copyright...: FROM titles...: WHERE title LIKE '%How to Program'...: ORDER BY title""", connection)Out[16]:isbn title edition copyright0 0134444302 Android How to Program 3 20171 0133976890 C How to Program 8 20162 0134448235 C++ How to Program 10 20173 0132151006 Internet & WWW How to Program 5 20124 0134743350 Java How to Program 11 20185 0133406954 Visual Basic 2012 How to Program 6 20146 0134601548 Visual C# How to Program 6 20177 0136151574 Visual C++ How to Program 2 2008
Self Check
(Fill-In) SQL keyword specifies the order in which records are sorted in a query.
Answer:ORDERBY.
17.2.5 Merging Data from Multiple Tables: INNER JOIN
Recall that the books database’s author_ISBN table links authors to their corresponding titles. If we did not separate this information into individual tables, we’d need to include author information with each entry in the titles table. This would result in storing duplicate author information for authors who wrote multiple books.
You can merge data from multiple tables, referred to as joining the tables, with INNER JOIN. Let’s produce a list of authors accompanied by the ISBNs for books written by each author—because there are many results for this query, we show just the head of the result:
In [17]: pd.read_sql("""SELECT first, last, isbn...: FROM authors...: INNER JOIN author_ISBN...: ON authors.id = author_ISBN.id...: ORDER BY last, first""", connection).head()Out[17]:first last isbn0 Abbey Deitel 01321510061 Abbey Deitel 01334069542 Harvey Deitel 01342893663 Harvey Deitel 01354046734 Harvey Deitel 0132151006
The INNER JOIN’s ON clause uses a primary-key column in one table and a foreign-key column in the other to determine which rows to merge from each table. This query merges the authors table’s first and last columns with the author_ISBN table’s isbn column and sorts the results in ascending order by last then first.
Note the syntax authors.id (table_name.column_name) in the ON clause. This qualified name syntax is required if the columns have the same name in both tables. This syntax can be used in any SQL statement to distinguish columns in different tables that have the same name. In some systems, table names qualified with the database name can be used to perform cross-database queries. As always, the query can contain an ORDER BY clause.
Self Check
(Fill-In) A(n) specifies the fields from multiple tables that should be compared to join the tables.
Answer: qualified name.
17.2.6 INSERT INTO Statement
To this point, you’ve queried existing data. Sometimes you’ll execute SQL statements that modify the database. To do so, you’ll use a sqlite3 Cursor object, which you obtain by calling the Connection’s cursor method:
In [18]: cursor = connection.cursor()The pandas method read_sql actually uses a Cursor behind the scenes to execute queries and access the rows of the results.
The INSERT INTO statement inserts a row into a table. Let’s insert a new author named Sue Red into the authors table by calling Cursor method execute, which executes its SQL argument and returns the Cursor:
In [19]: cursor = cursor.execute("""INSERT INTO authors (first, last)...: VALUES ('Sue', 'Red')""")...:
The SQL keywords INSERT INTO are followed by the table in which to insert the new row and a comma-separated list of column names in parentheses. The list of column names is followed by the SQL keyword VALUES and a comma-separated list of values in parentheses. The values provided must match the column names specified both in order and type.
We do not specify a value for the id column because it’s an autoincremented column in the authors table—this was specified in the script books.sql that created the table. For every new row, SQLite assigns a unique id value that is the next value in the autoincremented sequence (i.e., 1, 2, 3 and so on). In this case, Sue Red is assigned id number 6. To confirm this, let’s query the authors table’s contents:
In [20]: pd.read_sql('SELECT id, first, last FROM authors',...: connection, index_col=['id'])...:Out[20]:first lastid1 Paul Deitel2 Harvey Deitel3 Abbey Deitel4 Dan Quirk5 Alexander Wald6 Sue Red
Note Regarding Strings That Contain Single Quotes
SQL delimits strings with single quotes ('). A string containing a single quote, such as O’Malley, must have two single quotes in the position where the single quote appears (e.g., 'O''Malley'). The first acts as an escape character for the second. Not escaping single-quote characters in a string that’s part of a SQL statement is a SQL syntax error.
17.2.7 UPDATE Statement
An UPDATE statement modifies existing values. Let’s assume that Sue Red’s last name is incorrect in the database and update it to 'Black':
In [21]: cursor = cursor.execute("""UPDATE authors SET last='Black'...: WHERE last='Red' AND first='Sue'""")
The UPDATE keyword is followed by the table to update, the keyword SET and a comma-separated list of column_name = value pairs indicating the columns to change and their new values. The change will be applied to every row if you do not specify a WHERE clause. The WHERE clause in this query indicates that we should update only rows in which the last name is 'Red' and the first name is 'Sue'.
Of course, there could be multiple people with the same first and last name. To make a change to only one row, it’s best to use the row’s unique primary key in the WHERE clause. In this case, we could have specified:
WHERE id = 6For statements that modify the database, the Cursor object’s rowcount attribute contains an integer value representing the number of rows that were modified. If this value is 0, no changes were made. The following confirms that the UPDATE modified one row:
In [22]: cursor.rowcountOut[22]: 1
We also can confirm the update by listing the authors table’s contents:
In [23]: pd.read_sql('SELECT id, first, last FROM authors',...: connection, index_col=['id'])...:Out[23]:first lastid1 Paul Deitel2 Harvey Deitel3 Abbey Deitel4 Dan Quirk5 Alexander Wald6 Sue Black
17.2.8 DELETE FROM Statement
A SQL DELETE FROM statement removes rows from a table. Let’s remove Sue Black from the authors table using her author ID:
In [24]: cursor = cursor.execute('DELETE FROM authors WHERE id=6')In [25]: cursor.rowcountOut[25]: 1
The optional WHERE clause determines which rows to delete. If WHERE is omitted, all the table’s rows are deleted. Here’s the authors table after the DELETE operation:
In [26]: pd.read_sql('SELECT id, first, last FROM authors',...: connection, index_col=['id'])...:Out[26]:first lastid1 Paul Deitel2 Harvey Deitel3 Abbey Deitel4 Dan Quirk5 Alexander Wald
Closing the Database
When you no longer need access to the database, you should call the Connection’s close method to disconnect from the database—not yet, though, as you’ll use the database in the next Self Check exercises:
connection.close()SQL in Big Data
SQL’s importance is growing in big data. Later in this chapter, we’ll use Spark SQL to query data in a Spark DataFrame for which the data may be distributed over many computers in a Spark cluster. As you’ll see, Spark SQL looks much like the SQL presented in this section. You’ll also use Spark SQL in the exercises.
Self Check for Section 17.2
(IPython Session) Select from the
titlestable all the titles and their edition numbers in descending order by edition number. Show only the first three results.
Answer:In [27]: pd.read_sql("""SELECT title, edition FROM titles...: ORDER BY edition DESC""", connection).head(3)Out[28]:title edition0 Java How to Program 111 C++ How to Program 102 C How to Program 8(IPython Session) Select from the
authorstable all authors whose first names start with'A'.
Answer:In [28]: pd.read_sql("""SELECT * FROM authors...: WHERE first LIKE 'A%'""", connection)Out[28]:id first last0 3 Abbey Deitel1 5 Alexander Wald(IPython Session) SQL’s
NOTkeyword reverses the value of aWHEREclause’s condition. Select from thetitlestable all titles that do not end with'HowtoProgram'.
Answer:In [29]: pd.read_sql("""SELECT isbn, title, edition, copyright...: FROM titles...: WHERE title NOT LIKE '%How to Program'...: ORDER BY title""", connection)Out[29]:isbn title edition copyright0 0134289366 Android 6 for Programmers 3 20161 0135404673 Intro to Python for CS and DS 1 2020