The most memorable shot in Steven Spielberg’s Jaws is not a close-up of a toothy shark or its unfortunate victims. Rather, since Jaws is fundamentally a film about people and their differing reactions to an implacable existential threat, the most affecting shot is a close-up of one of the human protagonists, the local police chief. We see the chief sitting uneasily on a beach chair, scanning the water for the presence of the titular threat, when the director executes a “dolly zoom” on his startled face. This maneuver, one of the most dramatic camera moves in the filmmaker’s repertoire, comprises two camera actions that must be executed simultaneously: a “dolly out,” in which the camera is quickly pulled away from its target on a trolley or track, and a “zoom in,” in which the camera lens extends for a simultaneous close-up of the target. The two actions almost cancel each other out, but not quite, for while the target remains resolutely in focus and appears just as prominent on the screen, the background behind the target dramatically falls away. The effect is as unsettling as it is fleeting: just as the chief appears rooted to the spot with fear, the world behind him seems to jump back in terror.
It may seem contradictory, but dolly zooms grab our attention and hold our focus by taking a sudden and rather big step backward. The linguistic equivalent of a dolly zoom is a metaphor, for effective metaphors, like effective dolly zooms, execute a simultaneous pull-out and zoom-in to focus sharply on those aspects of a topic that are of most interest to the speaker while causing the noise and distraction of the rest of the world to dramatically fall away. But like a dolly zoom, they achieve this attention-grabbing close-up on one facet of a topic by stepping all the way back into a different conceptual domain. So to talk about the pain of a difficult divorce we might pull backward into the domain of war, where our view on the topic will be colored by the language of bloody (and expensive) confrontation, while to communicate the joy of invention, it often pays to pull backward into the domain of childbirth. Metaphors, like camera shots, frame our view of the world and make budding Steven Spielbergs and Katherine Bigelows of us all. It shouldn’t be surprising that metaphors of seeing have always held a special attraction for scholars of metaphor. Metaphors invite us to see, tell us where to look, and control what we see when we do look.1
Metaphors live in the half-light between fantasy and reality. When judged as linguistic propositions, even the boldest and most strident metaphors lack what philosophers call a truth value, for none is ever so compelling as to be certified logically true or ever so inept as to be dismissed as logically false. Metaphors obey a pseudo-logic that is closer to magical realism than the system of axioms and proofs beloved of logicians, and like a well-crafted movie, they encourage us to suspend disbelief and instead find sense in nonsense. For example, when Raymond Chandler writes in The Lady in the Lake that “the minutes went by on tiptoe, with their fingers to their lips,” we are confronted anew with the deep conceptual weirdness that lurks beneath the hackneyed phrases “time flies” and “time crawls.”2 With one foot planted in the reality of the everyday world, where common sense reigns, and another firmly planted in the world of fantasy, where logic falters and anything is possible, the pseudo-logic of metaphors is not unlike the unsettling blend of sense and nonsense that we encounter in our dreams. Dreams also filter, bend, and distort our experiences of the real world to blur some details while vividly exaggerating others, and they do so in a way that promises deep meaning even if this meaning is shrouded in mystery and confusion. The philosopher Donald Davidson famously expressed the controversial view that the meaning of our metaphors is every bit as tantalizing yet uncertain as the meaning of our dreams. Indeed, Davidson opened his 1978 paper on the meaning of metaphor with the provocative claim that “metaphor is the dreamwork of language,” and he proceeded to sow doubt as to whether one can ever point to any specific interpretation—which is to say, any finite bundle of propositions—as the definitive meaning of a metaphor.3 Although cognitivists and semanticists may tell us with some confidence that a metaphor ultimately means this or that, their official interpretations can be no more authoritative than the speculative claims of a Freudian psychoanalyst about the meaning of our dreams. Freud admitted that a dream cigar is sometimes just a cigar, but for Davidson, a metaphorical cigar is always a cigar, meaning no more and no less than it seems.
So the prescriptive interpretation of metaphors is a mug’s game, at least in Davidson’s view. If metaphors mean precisely what they appear to mean on the surface, then Davidson would argue that Chandler’s metaphor for fleeting time means just what it appears to say: that the minutes are going by on tiptoe, with fingers to their lips. The idea that minutes can have fingers and toes is of course absurd, but for Davidson, this is largely the point: the purpose of a metaphor lies in the useful inferences that we, as listeners or readers, draw from it, and not from its surface absurdities, even if the latter inevitably lead us to the former. In this case, we may infer that Chandler’s hero, Marlowe, is ruefully noting the rapid passage of time and slyly blaming a conspiracy of time itself for his lost minutes. Or we might not, since readers are free to draw their own conclusions and make their own inferences. Whether one agrees with Davidson or not, his skepticism about metaphorical meaning seems ideally suited to communication on Twitter, a medium in which the need for concision collides with the desire for attention to produce enigmatically ambiguous microtexts that invite divergent inferences. When striving for vividness, brevity, and apparent profundity, Twitter users often rely on the linguistic equivalents of flashy camera shots and canted angles, and lacking the space to explain themselves, they frequently encourage readers to arrive at their own conclusions as to the meaning of their most expressionistic tweets. So what happens if we add a Twitterbot to this uncertain situation, to pump out enigmatic metaphor-shaped tweets—even Davidson might not concede that these tweets contain genuine metaphors, but our bots can certainly make them look the part—that invite open-ended inference from an open-minded audience?
A noteworthy generator of metaphor-shaped tweets is the @metaphorminute Twitterbot of Darius Kazemi. The bot uses the Wordnik web service (provided by the dictionary website Wordnik.com) to provide some rather grandiloquent and exotic lexical elements—such as “plashy” (a synonym for “watery”) and “jaked” (a synonym for “drunk”)—for his bot’s figurative formulations.4 In a hearty embrace of Davidsonian skepticism, the bot freely combines words without regard for the meaning of the final result. If you can imagine a blind man with a cold shopping for ingredients in a gourmet store, then you’ll have some idea of the sheer oddity and playfulness of the resulting concoctions. The following is typical:
a foison is a mizen: Churrigueresque and plashy
@metaphorminute’s tweets are chock full of five-dollar words that seem more suited to a spelling bee for lexical showoffs than to a metaphor designed for communicating real meaning to a human audience. Yet if its outputs seem mechanical and unnatural—alien, even—this is very much part of its mission as an Twitterbot. Kazemi has no desire to gull people into believing that these metaphors are generated by another human, and he delights in having his bots cavort in the outer limits of human language.5 Its tweets are postcards from the edge of acceptable language, where exotic words are difficult to pronounce, much less understand. In short, the bot was expressly designed to use the language of humans in ways that are at once familiar (at least on a syntactic level) yet unnervingly alien. Those who follow the bot’s frequent outputs receive a metronomic reminder that language can be mysterious and beautiful and that words can enchant even when we cannot decipher their intended meanings.
The familiar framing “[X] is [Y]:[A] and [B]” is the bot’s attempt to force these lexical curiosities into a meaningful juxtaposition, even if it is the reader, and not the bot itself, that is ultimately responsible for creating these meanings. We might imagine that @metaphorminute would be much less popular if it simply provided an unstructured list of unusual words in each tweet. So to find out if the metaphorical framing really does contribute to a sense that each tweet is an act of meaningful communication, we conducted a simple experiment on the crowd-sourcing platform CrowdFlower.com.6 Sixty tweets were chosen at random from @metaphorminute’s timeline and presented to anonymous raters who were paid a very modest sum to judge the meaningfulness of each one, on a scale of comprehensibility ranging from very low to medium low to medium high to very high. Showing some Davidsonian skepticism of our own, we did not ask these raters to provide a “meaning” for each tweet, or even to prove that they could actually arrive at a more-or-less meaningful interpretation if asked. Rather, we simply asked this: How easy do you think it would be to recover the author’s intended meaning from this tweet? The results were surprising, even if they say as much as about the general issues that plague crowd-sourced evaluation as they do about the specifics of our experiment. Soliciting ten ratings per tweet, we discovered that approximately half of the tweets were considered, on average, to have medium-high (22.4 percent) to very high (31.6 percent) comprehensibility. Let’s put that unexpected finding in perspective: our anonymous raters felt that metaphor-shaped texts such as “a foison is a mizen: Churrigueresque and plashy” are carriers of real metaphorical meaning, whatever that meaning might turn out to be.
We can be confident that our anonymous judges were not simply plucking random judgments from the ether because their judgments accorded with prior expectations on another dimension: novelty. Whatever you might think about the value of @metaphorminute’s outputs as viable metaphors, it is hard to argue that they lack novelty and originality. Using the same 4-point scale ranging from very low to medium low to medium high to very high, and again soliciting ten ratings per tweet, we found that almost two-thirds of @metaphorminute’s outputs (63 percent) were judged to have very high novelty, with another 15 percent judged to be medium high. In contrast, just 10 percent were deemed to exhibit very low novelty. Yet this confidence regarding our judges’ perception of textual comprehensibility does not extend to their actual powers of comprehension on metaphor-shaped texts. The frame [X] is [Y]:[A] and [B] may give human judges a sense that a text was crafted by another human to be metaphorical and should thus be comprehensible to a human, even if cursory examination fails to yield an obvious interpretation. So to force our judges to show that they can indeed comprehend these tweets, we asked them to complete a cloze test in which salient words were removed from each. For instance, judges were presented with the stimulus “a foison is a mizen: ______ and ______” and asked to choose a pair of adjectival values from a list that contained the original quality-pair, in this case “Churrigueresque” and “plashy,” and four distractor pairs (e.g., “unbleached” and “shovel ready”) plucked at random from other @metaphorminute tweets. If these tweets are as comprehensible as judges seemed to think they were in the first experiment, we should expect judges to exhibit some modest success at choosing the original pair of qualities, where success is any performance that shows a statistically significant improvement over chance selection alone. Unfortunately, with no unifying meaning to link the metaphor X is Y to any specific rationale A and B, our judges were set adrift in a task for which random choice proved to be just as effective as any other strategy.
To see just how adrift they were, we averaged the judgments from all judges for each tweet. If, on average, 75 percent or more of the judges for a given tweet chose the original pair of properties to fill the gaps in the cloze test version, we deemed those properties to have very high aptness for the metaphor in the tweet; that is, we deemed that metaphorical tweet to have very high internal aptness. Falling short of this high bar, if 50 percent or more of judges for a tweet chose the original pair, the tweet was deemed to have medium-high aptness. Conversely, a tweet that failed to elicit more than 25 percent correct selections was deemed to have very low aptness, while those eliciting 25 to 50 percent were deemed to be medium low. In all, 84 percent of @metaphorminute’s tweets fell into the very low aptness bucket, with the remaining 16 percent falling into the medium-low bucket. None at all made it into the medium-high or very high buckets. To be fair, neither @metaphorminute nor its creator makes any claims at all regarding the metaphorical aptness of the bot’s lexical choices. Our goal for this experiment was a general one: to quantify the link between a reader’s faith in the meaningfulness of a tweet and the reality of meaningfulness as anchored in a consensus interpretation. To generate tweets that tickle the reader’s fancy while dancing along the long tail of language, it is often sufficient for a bot to engineer the mere semblance of meaning, especially when, for good measure, it can also engineer a sense of otherness and mystery.
From the earliest philosophical musings of Ada Lovelace and Alan Turing, researchers have long cherished the dream that mechanical systems might one day be capable of generating novel insights and communicating real meanings of their own. Yet if the mere semblance of insight can be so cheaply purchased with the manipulation of words alone, it may seem a poor investment to imbue our bots with the complexity necessary to also manipulate ideas. Quite apart from the engineering effort required to give a bot the knowledge needed to link words to their meanings in the world, there is a real concern that the forcing of words into meaningful patterns must inevitably serve to limit a bot’s generative reach so that it fails to reach the untrammeled diversity of those, such as @metaphorminute, that are unconstrained by semantic concerns. Like ants swarming over a map on a picnic table, unconstrained bots are free to roam all over a possibility space and explore, albeit through random means and without any understanding of the symbols on the map, every corner of that space. In contrast, a knowledge-driven bot can move only in ways that are regulated and constrained by a built-in understanding of those symbols and will be prohibited from exploring areas that, however fertile, are deemed out-of-bounds by its rules. Inevitably, the need to temper diversity with understanding and randomness with knowledge will ding the perceived novelty of any bot’s outputs.
Consider a Twitterbot named @MetaphorMagnet that builds on research in AI and cognitive science to derive analogies from its symbolic knowledge and package them into pithy 140-character observations. Metaphor has been a topic of scholarly inquiry since antiquity, and modern builders of metaphor generation systems can draw on a wealth of insights ranging from Aristotle,7 who wrote the first academic investigation of metaphor in his Poetics, to Dedre Gentner,8 a modern empiricist who has spent her career amassing evidence for the centrality of analogy to human cognition. @MetaphorMagnet thus combines an eclectic mix of insights and heuristics on the time-honored AI principle of “whatever works.” The following is typical of the bot’s use of linguistic and conceptual norms:
On its own, the shared verb use fails to lift the pairing of metaphors and hacks to the level of an interesting analogy. It takes the tension between “inspired” (a norm that the system associates with metaphors) and “uninspired” (a contrasting norm that it associates with hacks) to strike sparks from this otherwise dull pairing. In addition to possessing a large knowledge base of these stereotypical norms, the bot draws on less reliable associations that it harvests from the web. Many of the framing strategies explored in previous chapters are also applicable to the framing of these metaphors and analogies, to achieve varying levels of irony or wit. For instance, consider this metaphor from another bot in the same stable:
The @MetaphorMagnet bot scores high on the dimensions of comprehensibility and aptness when we rerun our earlier CrowdFlower experiments on a random sampling of its outputs. While 23 percent of these outputs are judged, on average, to have medium-high comprehensibility, more than half (53 percent) score an average rating of very high for this dimension. Likewise, in the cloze-test for internal aptness, in which, for example, the paired words “temporary” and “enduring” are blanked out in the above tweet and hidden in plain sight among four pairs of distractors taken from other metaphor tweets (such as “reigning” and “subservient,” taken from a metaphor comparing chieftains to minions), 20 percent of @MetaphorMagnet’s tweets are collectively judged to have very high aptness (insofar as 75 percent of judges choose the original pair of missing qualities) and 58 percent are judged to have medium-high aptness. Nonetheless, when it comes to novelty, only 49.8 percent of @MetaphorMagnet’s tweets reach the very high level on this dimension, which is significantly less than the 63.2 percent recorded for @metaphorminute. Yet this trade-off of novelty for comprehensibility seems to be necessary if a bot’s tweets are to succeed in communicating some semblance of an a priori meaning, although it should also be noted that enigmatic near-random stimuli that invite open-ended interpretations are precisely what some, perhaps many, users want from a bot.
But “knowledge” is not an all-or-nothing quality that forces bot builders to choose between meaningful predictability or unhinged exuberance. As we showed in the previous chapter, small amounts of explicit knowledge can be incrementally added to our bots to make them that much more clued in to the likely meaning of the words and phrases in their tweets. Our initial additions may be tentative, and the novelty they bring to a bot’s outputs may be quickly exhausted, but with continued improvements in the spirit of a true fixer-upper, these additions will yield complex interactions that are reflected in the generative reach of a bot. In his book Vehicles: Experiments in Synthetic Psychology, Valentino Braitenberg proposes his law of uphill analysis and downhill invention.9 Complex behavior begets complex hypotheses about the causes of those behaviors, so to an external analyst, the internal workings of an autonomous system (such as an insect, or an autonomous vehicle, or indeed a Twitterbot) will seem a good deal more complex than they actually are, and a whole lot more complex than they seem to the inventor of that system, since some of the most impressive behaviors will emerge naturally and unexpectedly from the simplest engineering decisions. Twitterbot construction is one of the truest expressions of downhill invention. Braitenberg’s law is on the side of bot builders and inventors, magnifying the perceived complexity of the diverse interacting parts that we put into our bots.
Action Figures in Their Original Packaging
Hollywood loves a safe bet, and when it comes to making expensive movies, no bet seems safer than the dream factory’s continued investment in established properties. It is a bet on which Hollywood eagerly doubles down as it sells us a growing number of sequels, remakes, and reboots, not to mention films based on successful novels, comic books, TV shows, video games, and children’s toys. We crave novelty yet seem to value it most when it is packaged in familiar boxes with familiar labels. So even if (or, rather, especially if) its contents are novel, the box is still likely to be a popular genre with a recognizable name on the front. Lest we be too quick to condemn Hollywood’s reliance on recycled ideas, we should admit to our own longing for certain landmarks in an uncertain world.
When it comes to language reuse, we are all as adept as the most cynical hack, often preferring quotes from Shakespeare (fancy!) or classic movies (cool!) over our own bespoke metaphors, similes, and jokes. Even when we take pains to turn an original phrase, it is hard to avoid the lure of the familiar. But this is exactly as it should be, since communication benefits from eye-catching novelty only when our target audience understands or appreciates this novelty. The psycholinguist Rachel Giora refers to this mutually beneficial balance of novelty and familiarity in any creative endeavor as the principle of optimal innovation.10 A creative phrase should not be a rebel without an obvious cause; rather, the expectation against which a creative phrase rebels should be recoverable by an audience so that norm and deviation can be appreciated side-by-side. For this reason, our shiny new similes do not use bigger or fancier words than more hackneyed alternatives. They use much the same words to evoke much the same qualities (so ovens are still hot and snakes are still sneaky) but use these familiar elements in nonobvious ways to achieve novelty. Thus, our novel similes speak of clowns with a toothache,11 fat men in revealing swimwear, polar bears in the desert, or cats in a blender. Those who selectively recycle history are not doomed to repeat it.
There is a reason we tend to describe the unfamiliar in terms of the familiar and not the other way around: we understand the familiar and can be confident that our audience understands it too. In the short and sad history of the Zune, Microsoft’s music player, many more described it as “Microsoft’s iPod” than described the iPod as Apple’s Zune. The iPod came first and established itself as a familiar landmark against which new arrivals could be judged. So when we build a novel simile around a specific well-known person, we are as much given to type-casting as any Hollywood exec. These familiar faces are our bankable stars, established properties with recognizable qualities that we can use as yardsticks for figurative comparison. Consider the following attention-grabbing metaphor from a wine guide; you may not know your Riesling from your Liebfraumilch, but anyone who has ever ridden in an elevator has heard an earful of Kenny G:12
Riesling is the Kenny G of wines: technically brilliant but oh-so-lacking in credibility
Just as heat flows across a temperature gradient, from hot to cold but not vice versa, the information content of a metaphor flows across a knowledge gradient, from a point of great familiarity to one more remote from our own experience. A compelling metaphor, like the one above, transfers that “I know what you mean” feeling from one idea to another. The form of the metaphor—its [X] is the [Y] of [Z]: [A] and [B] structure13 (which is not so different from that used by @metaphorminute)—alerts readers to the presence of a knowledge gradient between Y and X and to the direction of the gradient (from Y to X and not from X to Y), but it tells us little about the actual content that flows across this gradient. For that, a metaphor maker needs specific knowledge of the Y (e.g., Kenny G) that is likely to be shared by the larger community and generic knowledge of the X to indicate what kinds of things that one can meaningfully ascribe to, say, a wine. An open domain metaphor maker thus requires a broad education in many aspects of the human condition, but we restrict ourselves here to the metaphors that can be built using a prestocked knowledge base of interesting people. We want our Xs and Ys to be scaled-down representations of well-known characters, real or fictional, with enough obvious similarities to be recognizable. We will give them as many affordances as we can—the As and Bs—so as to allow our bots to pair them, match them, mash them, and even cross-dress them in as many ways as they can.
In a modular approach, we build a set of interlinked KnowledgeBaseModule instances that are each defined in a different spreadsheet. The top-level mapping of people to their properties and paraphernalia is called the NOC List (for non-official characterization list).14 When those paraphernalia are themselves complex objects with their own properties and associations, we represent them with their own knowledge base modules. But let’s begin by first populating our master spreadsheet, the NOC List.xlsx, which, in the interests of balance, will aim to state something nice about every bad person and something nasty about every good person.
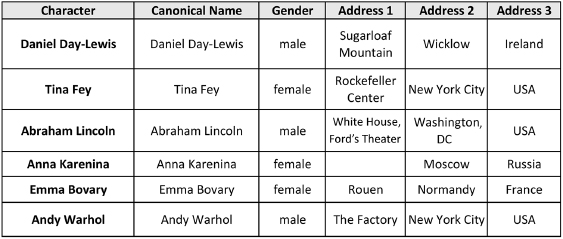
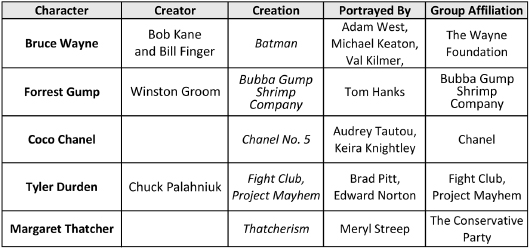
As in previous arrangements, our NOC spreadsheet dedicates a separate row to each distinct character, and so the first column, labeled Character, is key to the whole arrangement. At the time of writing, the spreadsheet uses over eight hundred rows to provide detailed entries for over eight hundred famous (and infamous) characters. Each subsequent column fleshes out a different aspect of a character, and readers are encouraged to add their own, to make the NOC list a richer and perhaps more personal resource for their bots. Although columns are listed in the following order, what matters is their label and not their position: Canonical Name, Gender, Address (in three fields: Address 1, Address 2, and Address 3), Politics, Marital Status, Opponent, Typical Activity, Vehicle of Choice, Weapon of Choice, Seen Wearing, Domains, Genres, Fictive Status, Portrayed By, Creator, Creation, Group Affiliation, Fictional World, Category, Negative Talking Points, and Positive Talking Points. Here are the first few rows and columns of the spreadsheet:
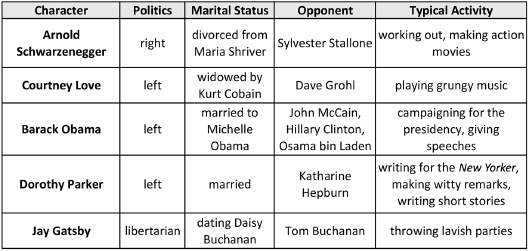
We can see a different selection of columns by reordering the NOC spreadsheet:
We enter the realms of the satirical with these new columns and cell values. Though the column labels should be self-explanatory, their contents tend to blur the boundaries between fact and fiction and between knowledge and satire. But these columns also introduce a degree of self-referentiality to our NOC list by allowing the row entry for one character to refer directly to that of another. A spreadsheet may seem an underpowered loom for such intricate knowledge, yet every cell value in the two previous figures represents a distinct triple in a complex semantic system, marking as it does the intersection of a character (row) with a property (column) at a specific point in semantic space (a filler). Classic AI representations, from frames to semantic networks to conceptual graphs, are built from triples such as these, as are indeed the representations of the Semantic Web, which use XML, RDF, and OWL to encode their triples. Any of the spreadsheets we present here, whether describing imaginary people or real desserts, can thus be converted into your representation of choice using the simplest of syntactic transformations.
The Opponents column captures the grudges between characters that have been aired in the media or that time has woven into the public imagination. We’ll see later how a bot can invent grudge matches of its own, of the kind DC Comics devised when it pitted Superman against Muhammad Ali in an imaginary contest of strength in 1978.15 Just as Superman and Ali seem an apt match because of their comparable vigor, agility, and muscularity, the NOC list provides a wealth of other properties and associations relative to which a bot can determine diverse points of overlap and contrast. In addition, since some NOC columns provide values that will themselves have their own properties in other knowledge modules, such as Typical Activity, our bots can also seek out second-order similarities between characters via the similarity of their associations.
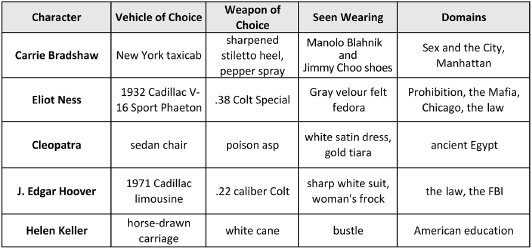
The columns Vehicle of Choice, Weapon of Choice, and Seen Wearing allow us to accessorize characters as though they were the action figures that advertisers dangle in front of kids in Saturday morning cartoon shows. The Domains column contains an important source of metadata for our characters as it indicates the narrative contexts with which they are most strongly associated. Since analogies, metaphors, and blends hinge on cross-domain mappings, it is crucial for our bots to be able to tell when two characters are drawn from the same domain. As shown above, Eliot Ness and J. Edgar Hoover share at least one domain: the Law. Though this is a point of overlap that argues for their similarity, it is one that weakens rather than strengthens a cross-domain analogy between the two. A character’s weapons, vehicles, and clothing are additional affordances that a bot can exploit for its own ends, but these are also complex objects in their own right, with their own affordances that dictate how they are to be used by our characters and, just as important, how they can be spoken about in a tweet. We must build dedicated knowledge base modules to make all of these affordances explicit, but for now, let’s look at another selection of columns from the NOC list:
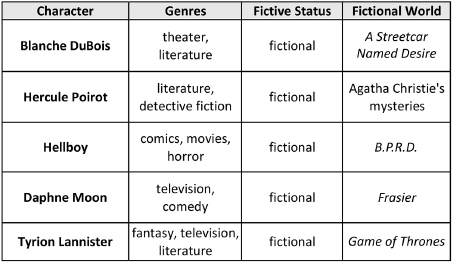
These additional fields create more points of similarity between our characters, and just as important, more points of distinction to tell them apart. The Genres field allows our bots to locate a character within a particular mode of creative expression, from horror to comedy to science fiction, and with a specific creative outlet, such as movies, theater, comic books, and literature. Any fictional character will have the value fictional for its Fictive Status field, but this field is blank for characters from the real world. Fictional entities may also be associated with a specific narrative space via the Fictional World field, but as shown above, this field can be meaningful even for characters whose historical reality is beyond dispute. For instance, since Turing’s achievements have been simplified to the point of fictionalization in films like The Imitation Game, it seems right to locate him in the semifictional narrative world of Bletchley Park.16 Fictional characters exhibit another point of departure from reality: they may not be real themselves, but as captured in the Creator field of the NOC they are created by real people.
Creators, in turn, are strongly connected with their creations, and so the NOC list provides another field, Creation, for these associations. It is also meaningful to fill the Creation field of fictional characters with the fruits of their imagination when these form part of our mental picture of the character. When a character has been portrayed on screen, the Portrayed By field provides the name of the actor or actors concerned. Likewise, when a character is associated with a named group or organization that forms a salient part of our knowledge of the character then the association is stored in the field Group Affiliation. If the values of any of these fields denote complex objects in their own right, we must create other knowledge base modules to identify the affordances of each specific value.
We are in the home stretch of the NOC now, with just three fields to go:
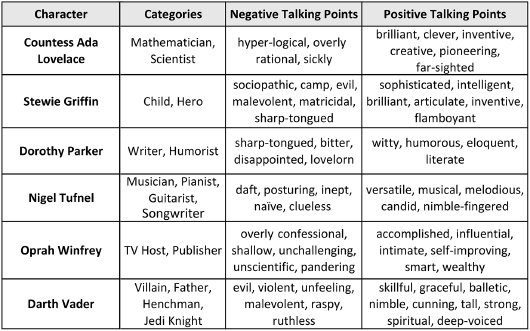
The first of these is Category, which places every character into its appropriate taxonomic context. Since Oprah Winfrey is both a TV Host and a Publisher, she can be compared or contrasted with other NOC entries (such as late-night comedians, cable news pundits, and celebrity chefs) using either of these points of similarity. The final two fields are affective in nature, which is to say that their values are freighted with an emotional charge. Negative Talking Points offers a list of undesirable qualities that are commonly associated with a character, but as the name suggests, these qualities are offered as conversation starters and not definitive facts. One may well disagree with any of these negative qualifications, as the goal of the NOC is to paint an exaggerated and somewhat expressionistic portrait of a character that readers will recognize, even if it is one that they will not always endorse. Conversely, the Positive Talking Points field shows the best side of a character, identifying those desirable aspects that many have observed and reported, if only begrudgingly. For instance, Darth Vader has many dark qualities but who would dare say he lacks spirituality? In this respect at least, the Sith Lord resembles real-life true-believers such as Mother Teresa and Mahatma Gandhi. Given any quality at all, such as raspy (Darth Vader again, or Bane), bots can decide whether to view it as a potential compliment or a likely insult by looking to how many times it occurs as a Positive or Negative Talking Point. Some complex qualities, such as devious, can be positive and negative, and this is reflected in their presence in both columns.
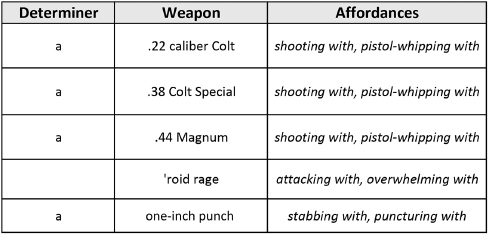
Having set out the affordances of our characters in the NOC List, let’s turn to the affordances of these affordances. For instance, it is one thing to know that Bruce Lee might attack an opponent with his famed 1-inch punch; it is another to know how exactly he might do this and how best to say it in a tweet. Our arsenal of weapons is thus characterized in its own spreadsheet, List of Weapons.xlsx:
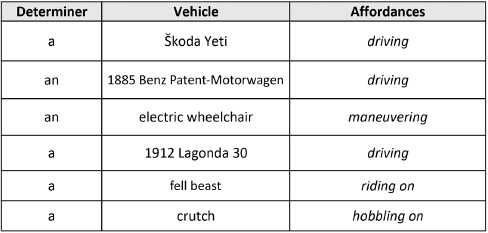
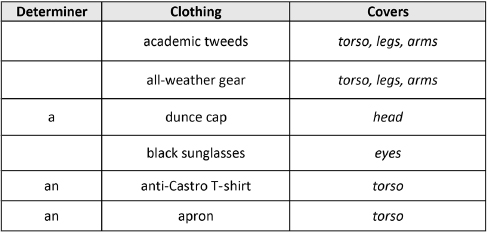
The Affordances column lists the attacks that are facilitated by a given weapon, while the Determiner field tells a bot how to package each as a valid noun phrase. The same arrangement is used in our spreadsheet of character vehicles, List of Vehicles.xlsx. The affordances here concern the correct verb for using a vehicle:
In List of Clothing.xlsx, we concern ourselves with the coverage of different items:
If a bot knows which body parts are covered by different kinds of clothing, it can invent its own fashion ensembles from diverse parts that form a complementary whole. A bot might thus make sport of detective clichés by inventing a blended character with Jane Marple’s tweed skirt, Sherlock Holmes’ deerstalker cap, Frank Columbo’s rumpled trench coat, and brandishing Harry Callahan’s .357 Magnum.
Tweet Dreams Are Made of This
A variety of other modules make up the NOC distribution that can found online, but rather than enumerate them all, let’s move on to actually using the NOC to generate new metaphors and analogies. Consider these XYZ-shaped, NOC-based tweets from @MetaphorMagnet:
What if #EdwardScissorhands were real? #AlanTuring could be its #EdwardScissorhands: shy but creative, and enigmatic too
#SalmanRushdie is the #Hamlet of #ModernLiterature: intelligent and erudite, yet lonely too.
When it comes to #AsianPolitics, is #KimJungun the #DonVitoCorleone of enriching uranium? He is powerful and strategic, but autocratic
What if #BackToTheFuture were real? #NikolaTesla could be its #DocEmmettBrown: experimental yet nutty, and tragic too
What if #MarvelComics were about #AfternoonTV? #OprahWinfrey could be its #ProfessorCharlesXavier: emotionally intelligent and smart, yet unchallenging too.
A good metaphor is a true marriage of ideas, delivering a complex experience to its audience by creating a complementary balance of closeness and remoteness, of familiarity and nonobviousness. A metaphor that leads with a surprising lineup must thus follow through with a strong motivation for its pairing of ideas. In the examples we’ve given, these aims are met by some rather simple criteria: any NOC characters from different domains that share at least two qualities—preferably one positive quality and one negative one, to yield an affective balance—can be juxtaposed using a variety of linguistic frames. The XYZ format for metaphors supports a variety of linguistic frames, from those that stress the boundary between the fictional and the real ([X] is the real-world’s [Y]) to those that suggest two genres or domains are similar by virtue of the similarity of their exponents. So in our XYZ-shaped metaphors, the Z component can be filled using a variety of NOC dimensions, from the genre and domain to the typical activities, fictive status, and even the clothes of the character in the X slot. Consider this follow-up to our NOC metaphor comparing Oprah Winfrey to Professor X:
If #OprahWinfrey is like #ProfessorCharlesXavier (emotionally intelligent and smart), who in #MarvelComics is #JudgeJudy most like?
By leveraging multiple NOC dimensions to establish a proportional analogy—for example, by combining Opponents with Positive and Negative Talking Points—bots can generate an apt pairing of parallel XYZ metaphors such as the following:
If #OprahWinfrey is just like #ProfessorCharlesXavier (emotionally intelligent and smart) in #TheXMen, is #JudgeJudy like #Magneto?
A bot’s explorations of the space of comparisons as defined by the NOC need not be limited to pairwise juxtapositions. A human speaker (or a bot) can pull in as many reference points for a comparison as its topic will bear to produce the linguistic equivalent of Frankenstein’s monster or, more formally, a conceptual blend. Our bots can squeeze three characters into a metaphor to create a blend of apparent opposites:
#LexLuthor combines the best of #WarrenBuffett and the worst of #LordVoldemort: He is rich and successful yet also evil, hateful, and bald
This three-way blending of qualities allows anyone at all to be disintegrated into the facets it shares with others, so as to be later reintegrated into an illuminating whole. While most metaphors are asymmetric, the blend encourages us to detect shades of Lex Luthor in the market success of Warren Buffett, the famed sage of Omaha. This lends Buffett an aura of villainy and turns Luthor into the sage of Metropolis. And although Buffett shares little with he who must not be named, the blend also affords a frisson of mischief to see them juxtaposed in the same microcontext, linked by their mutual similarity to a third person. Our rhetorical choices can sometimes make logic sit up and dance in some provocative ways.
Resonant metaphors exploit a mix of similarity and dissimilarity to create aptness and tension, but an effective juxtaposition can be built from dissimilarity alone. Consider the following tweets, which juxtapose two NOC characters that have no talking points in common and pivot on a single point of antonymy between opposing qualities (as found in the resource Property antonyms.xlsx):
I see myself as intelligent, but my wife says that I make even someone as dumb as #HomerSimpson look like #NoamChomsky.
This juxtaposition may seem even more unhinged that our earlier metaphors, unguided as it is by concerns of intercharacter similarity, but antonym-based juxtapositions are no less entertaining for being so free-ranging in their associations. Consider this alternate framing of the above, tweeted in two parts:
I dreamed I was working with nuclear materials with #HomerSimpson when we were herniated with a deep-structure transformation by #NoamChomsky.
I guess #NoamChomsky and #HomerSimpson represent warring parts of my personality: the smart vs. dumb sides. #Smart=#Dumb.
Davidson’s likening of metaphors to dreams was motivated by more than a desire to show that the definitive meaning of a metaphor is just as tendentious a notion as the definitive meaning of a dream. Metaphors, like dreams, slip the surly bonds of commonsense semantics to explore areas of the imagination that challenge, even defy, literal expression. In fact, metaphor is often seen as being the engine of much of what is curious and creative in dreams, and any generative system that aims to flex its imagination should first show a mastery of metaphor. Many dreams revolve around conflict—arising from a desire for wish fulfillment or discord resolution—and the NOC allows bots to imagine real conflict between iconic figures. Sigmund Freud saw dreams as the royal road to the unconscious, so these conflicts must offer credible symbolic insights.17 Bots can invent a dream metaphor and its meaning in the form of a Freudian interpretation by using the NOC list to paint a vivid picture of conflict between two iconic figures, pairing a typical activity of one with an attack with an apt weapon from another. As shown in the following dream/metaphor tweets, this symbolic conflict yields the psychological motivation for the metaphor and the meaning of the dream:
Last night I dreamt I was inventing time machines with #DocEmmettBrown when we were sprayed with pepper spray by #OprahWinfrey.
I guess #OprahWinfrey and #DocEmmettBrown represent warring parts of my personality: the smart vs. nutty sides.
Metaphors are typically presented to their target audience as the products of an intentional meaning-making process, and it is the readers’ recognition of this intentionality that leads them to take the metaphor seriously enough to plug the gap between what is said and what is only implied. But just as some metaphors fail to soar while many more simply fall flat, this perception of intentionality also leads readers to appraise a metaphor as a hit or as a miss. Dreams, in contrast, regardless of whether they mean something or nothing at all, are rarely viewed as intentional acts, and no dream, no matter how fascinating or dull, is ever judged a success or a failure. When asking human judges to rate a bot-generated metaphor on dimensions such as vividness, drama, laughter, and entertainment, we might expect big-picture concerns about the success or failure of an utterance to color their ratings. However, as we have shown above, it is a simple matter to present human judges with the “dream” equivalent of our NOC-based metaphors to elicit ratings along the dimensions of interest while suspending judgment on the overall success or failure of the metaphor itself. By presenting bot-generated metaphors as human-reported dreams—in fact, we should omit any reference to the nature of the originating agent so that the dreams can speak for themselves—we can obtain a more accurate measure of how humans rate their qualities. But first we need a baseline against which to make sense of the numeric ratings.
Although it is not helpful to frame this evaluation as a contest of human and machine generators, at least from the perspective of our human judges, we do want to explore the merits of bot generation relative to a strong human baseline. The web is awash with human dream reports and with resources for helping people to decode the meanings of their dreams. A wealth of dream symbols and their interpretations can, for instance, be scraped from a web dream dictionary and yoked to a database of semantic triples such as “soldiers fight wars” and “teachers teach students” (the product of an earlier AI project).18 Common dream symbols can then be placed into scenarios that contrast their literal and figuratively psychological meanings. Literal facts relating to specific dream symbols, such as “snowflake,” “door,” and “unicorn,” can thus be packaged with their stock psychological interpretations to create dream reports anchored in popular wisdom. For example, the dream symbol that links the following pair of tweets is “reunion”:
Last night I dreamed I was a soldier attending a #reunion. What could this mean?
Well, to dream that you are attending a #reunion suggests that there are feelings from the past which you need to acknowledge and recognize.
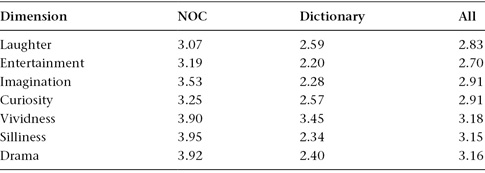
The crowd-sourcing platform CrowdFlower.com is again used to elicit ratings from human judges who are paid a modest sum to rate dictionary-based dreams such as the one above, as well as our NOC-based metaphors that are reframed as dreams. Judges are not told which is which, nor are they told the origins of either kind, and ten ratings are sought for fifty NOC dreams and fifty dictionary dreams, along seven dimensions: entertainment (How entertaining does this scenario seem to you?), laughter (How likely is a scenario to make you laugh?), imagination (Does this scenario show any signs of a creative imagination?), curiosity (Does this scenario make you want to hear more?), vividness (How eye catching is the detail in this scenario?), silliness (How implausible is this scenario?), and drama (How eventful is this scenario?). We are careful to show judges just one dream at a time and to ask for just one rating of one dimension of each dream at a time on a scale ranging from 1 (lowest) to 5 (highest).
Mean ratings for each type of dream scenario, along seven dimensions.
Mean ratings for each type of dream/metaphor on each dimension are shown in table 5.1. When NOC-based metaphors are reframed as character-based dreams, we can see that mean human ratings for the resulting scenarios are significantly higher on all seven dimensions than for the generic dictionary-based scenarios.19 The latter may exploit prepackaged human symbols and their more-or-less accepted interpretations, but they lack the star power of familiar faces and the sheer oddity of face-offs that scoff at accepted boundaries, whether between past and present, domains or genres, or the real and the fictional. While the NOC metaphors may be sillier—a lot sillier, it seems—human judges apparently see these machine-crafted confections as more vivid, more dramatic, and more entertaining than recycled nuggets of human wisdom.
I Read the News Today, Oh Boy
Just as we expect the news to reflect world events, we adapt our conversations to reflect the news, often responding to particular events with a pithy remark, an apropos metaphor, an ironic observation, or a fumble for profundity to propel us down a new tangent. Our bots can be just as topical if they too cut their cloth from the unspooling fabric of the news cycle. Of course, in previous chapters, we extolled the benefits of pregenerating a bot’s tweets, so that the offline task of exploring a possibility space and charting what is found there can be logically separated from the run-time task of selecting and posting tweets to a bot’s timeline. This division of responsibilities has a number of advantages, not least when it comes to creating new possibility spaces from old, but it does little to encourage topicality. Yet surprising as it may sound, it is on this specific point of topicality that a large prebuilt space can truly come into its own.
Consider @MetaphorMirror, a metaphor-generating Twitterbot that does not generate its metaphors in a null context but instead tweets them in response to the breaking news events of the hour.20 Notwithstanding this time sensitivity, the topical @MetaphorMirror relies crucially on the atopical @MetaphorMagnet for its supply of metaphors to tweet as the news rolls in. We might thus label @MetaphorMirror as a second-order bot since its outputs are formed in part from the premade tweets of the @MetaphorMagnet bot. We simply view the space of metaphors and the space of headlines as two separate but relatable possibility spaces. That is, we can view the incoming news feed on Twitter as one space of tweets—a space that grows by the hour and perishes just as quickly—and our corpus of pregenerated metaphors as another. This turns the issue of topicality into one of alignment: How can we align both spaces to support a mapping from one onto the other, so that a new arrival in the news space can be mapped in a timely fashion to an apt counterpart in the prebaked metaphor space? For instance, @MetaphorMirror paired this NOC metaphor for Donald Trump,
#DonaldTrump is the real world’s #MontgomeryBurns: rich and wealthy, but covetous
to this headline tweeted by the Associated Press:
RT @AP_Politics: There’s a lot we still don’t know about Donald Trump’s taxes, by … apne.ws/2dBZmJo
A convenient piece of statistical machinery, latent Dirichlet allocation (LDA), facilitates these pairings.21 LDA offers developers a statistical explanation for the observed similarity and resultant clustering effects in a large document pool. It assumes that real texts will be the products of one or more generative topics that implicitly guide their construction and influence their word choices. These topics are latent insofar as they lack an obvious name such as Sport or Politics and hide the inner workings of their generative mechanisms from outside view. The goal of LDA is to arrive at a statistical approximation of these latent topics that best explains the observed similarities among documents in the pool. LDA assumes the number of topics to be fixed and under the control of a developer, and 100 is as good a guess as any for the number of latent topics at work in a large pool of news documents. Any given document will likely result from a patchwork of influences, from genre to domain to special interests and even institutional bias, and so each document will be modeled as belonging, to quite varying degrees, to potentially every topic. As a statistical model, LDA allows a system to weigh the degree to which a text is representative of a given topic, and so, in a model of 100 topics, any text can be characterized as a vector in a 100-dimension space. The value of any dimension reflects the text’s affinity to the corresponding topic as calculated by the model. When a complex issue such as topicality is squeezed into a vector space model, similarity between texts becomes a simple matter of similarity between vectors, which reduces to a measurement of the angle between two vectors for two texts. More precisely, we calculate the cosine of this angle, since the cosine of the zero angle between vectors with identical orientation will be 1.0, and the cosine of the right angle between orthogonal vectors with orthogonal interests will be 0 (we’ll look at the mechanics of cosine similarity in more depth in the next chapter).
We need our LDA vector space to respect the topical structure of the news and of our metaphors; it needs to be a shared space of news and metaphors together, so that vectors for news tweets can be meaningfully compared to the vectors for metaphor tweets. We do this by first collating a 1 Gb corpus of news texts from various sources, such as CNN, BBC, Fox, Reuters, and Associated Press. To this news set, we add the texts of 10 million pregenerated metaphors from the spaces of the @MetaphorMagnet bot and task the LDA algorithm with explaining the observed overlaps and similarities in the joint corpus with a 100-topic model. Once the model is built, we use it to prebuild a topic vector for each metaphor in the database—those metaphors are the fixed stars in our bot’s firmament—and use it calculate a corresponding vector for each news headline as it arrives from accounts such as @cnnbrk, @nytimesworld, @WSJ, @AJEnglish, and @FOXNews. The @MetaphorMirror bot takes each news vector as it is created and compares it to the vectors for every metaphor in its database (all 10 million of them), using cosine similarity to determine the best metaphor matches for a given headline. Because LDA characterizes texts by their affinities to topics, the similarity of two vectors is not directly tied to literal sharing of words; two texts with no textual overlap may reflect the same topical interests and be highly similar, while two texts that share common news boilerplate may not be considered similar at all. The bot then decides which metaphor to pair to the headline, or whether to pair any at all, based on the similarity of a match, which must exceed a high threshold, and the recency with which it last tweeted that headline or that metaphor. For instance, consider the bot’s pairing of this headline
RT @Reuters Cubans to throng Revolution Square in mourning for Fidel Castro reut.rs/2gx3vhy
to this NOC-derived two-part analogy:
#CheGuevara is the #JamesTKirk of #CubanPolitics: brave and inspiring, yet violent too.
If #CheGuevara is just like #JamesTKirk, brave and inspiring, who in #CubanPolitics is #KhanNoonienSingh?
The explicit symbolic knowledge of the NOC list, which suggests this Star Trek analogy for Cuban politics, is implicitly echoed in the news from which the LDA model derives its topical insights into Cuba. Though the analogy does not force an explicit mapping from Fidel Castro to Kirk’s nemesis, Khan Noonien Singh, readers are left to infer this rhetorical possibility for themselves. The point of the bot’s pairing is not to summarize the news, but to use current events as a prompt for thinking about the ideas that shape our response to the news. In this way, LDA analysis complements the content of @MetaphorMagnet’s knowledge bases with timely, real-world associations and widely shared beliefs. Indeed, the metaphor that is paired to the headline often has a bifurcated form, allowing the reader to come to a personal interpretation of the news, as in this pairing of
RT @FoxNews .@realDonaldTrump criticizes the media in tweet
to this analogical pairing of alternative facts:
Would you rather be:
A satirist producing an entertaining caricature?
A whiner producing an annoying whine?
The bot does not set out to tell people what to think. It merely shows them where to look and asks them to think, perhaps by looking more closely at both sides of a story. That the chosen metaphor chimes with the prevailing stereotypes of its target, offering an overt foil to the latent insights of the LDA model, adds to the sense that it might know what it is talking about. LDA arrives at insights such as these only because it has such large amounts of raw data to work with, and so a statistics-driven Twitterbot such as @MetaphorMirror must drink thirstily from whatever source of data it can exploit. As such, it greedily drinks anything at all that @MetaphorMagnet is willing to give it.
Bots that march to the rhythm of a less vigorous drum can afford to be more genteel in how they use their third-party resources, and so Twitterbots such as @appreciationbot treat @MetaphorMagnet’s metaphors as a spring, not a fire hose, from which to take gentle sips as the need arises. This bot is also second order in the sense that its outputs and rhythms are dictated in large part by the outputs and rhythms of another, Darius Kazemi’s @museumbot. Though simple in design, @museumbot was created to offer an appealing service to humans, and so it is not surprising that other bot designers view it as a service from which their own artificial creations may also benefit. Indeed, @museumbot embodies a widespread philosophy of Twitterbot construction that often finds its highest expression in Kazemi’s creations: whenever the Internet gives you low-hanging fruits, make fruit salad, or at least some fresh juice. His @twoheadlines and @metaphorminute bots are clear examples of “salad” bots: @twoheadlines makes event salad of incoming headlines, while @metaphorminute makes word salad from the lexical outputs of the Wordnik.com service. But @museumbot is a “juice” bot: it picks at random from the fruit of a third-party web resource—the open-access web catalog of New York’s Metropolitan Museum of Art—to offer its followers a refreshing single serving of art four times a day in the form of high-resolution images of some of the museum’s vast holdings. The timelines of its users are thus adorned with snapshots of tapestries, paintings, rugs, and obscure objects that a visitor might never encounter in a trip to the Met itself, such as biscuit tin lids, back scratchers, shoes, curtains, bells, and spoons. These images, labeled with often minimal captions such as “Bell” or “Fragment of a Bowl” or even simply “Piece,” elicit moments of calm reflection amid a hectic discourse.
@appreciationbot (by @mtrc) is a “salad” bot that draws its ingredients from both @museumbot and @MetaphorMagnet, though for the latter’s metaphors, it goes straight to the horse’s mouth via a web service—also called Metaphor Magnet—that can be directly accessed by third party developers.22 It also exploits other freely available online resources, such as the large but uneven database of associations called ConceptNet.23 If @museumbot is primarily about images, @appreciationbot is all about the words and affects the tone of a critic whose mission is to critique the objets showcased in the former’s tweets. For instance, in response to an image of a silver spoon with the simple caption “Salt Spoon,” @appreciationbot tweets the following figurative critique:
.@MuseumBot The salt in this piece seems to hint at a polluting toxin. This kind of work feels a little out of place here.
The reference to “polluting toxin” comes courtesy of Metaphor Magnet, which the surrounding critical boilerplate turns into a damning artistic judgment. The bot has a wide repertoire of framing devices, and though these are indifferent to the sentiment of the caption, the pairing of metaphor and linguistic frame does occasionally give voice to provocations that almost seem profound. The caption “Female Deity (Mother Goddess),” adorning an image of a 2,200-year old female head in terracotta with a wide-eyed stare and a Mona Lisa smile, provokes this unusual act of lèse majesté from the bot:
.@MuseumBot There’s a kind of frightened slave at work here. This is what museums are all about.
That Metaphor Magnet’s suggested view of “Mother” as “frightened slave” is firmly at odds with the caption’s view of “Mother” as “Goddess” may strike readers as inept, or it may strike them as appropriately incongruous. Though @appreciationbot is merely play-acting in the role of art critic, it is a pantomime act that the reader is supposed to see through and enjoy. The bot wears its artificiality on its sleeve, and so, given the frequent clash of affect and framing, readers are rarely in any doubt that these are the outputs of a rigid machine. Yet the French philosopher Henri Bergson saw humor, or what he called the “comic,” as arising from this clash of rigid behaviors in response to dynamic world events.24 We saw aspects of this comic rigidity in the previous chapter with our discussions of @TrumpScuttleBot and its unthinking reframing of generic facts. We humans do not always respond with the agility and poise that circumstances demand, and our rigidity—of body (in pratfalls) and mind (in jokes)—opens us up to mockery and ridicule, whether we are violinists suffering a broken string or athletes tripping on our shoelaces or orators stumbling over exotic words. Bergson argued that we humans become comical when our inherent rigidity is brought to the fore. Rigid bots such as @TrumpScuttleBot and @appreciationbot ape the speech patterns of a specific class of person, such as a politician or a critic, from whom readers expect a certain flexibility of word and thought, but a bot’s rigidity can also offer a comic indictment of this kind of person even as it lays bare its own arthritic thinking.
Bots have some serious game when it comes to rigid behavior, and so other bots, such as Mark Sample’s @NRA_tally, @NSA_prism, and @ClearCongress bots, provide cutting caricatures of certain topical organizations—the National Rifle Association and the National Security Agency—by aping their most inflexible behaviors. @NRA_tally invents its own spree killings, offering pornographic detail on the weapons used to kill so many people while mocking the NRA’s rigid defenses of the right to bear arms in the face of these increasingly awful events.25 Sample’s @NSA_PRISMbot taunts the NSA and its infamous Prism program for its rigid collection of useless facts, implying that while the NSA and CIA may see everything, they understand so very little. Adding a visual gag to the mix, Sample’s @ClearCongress bot rigidly applies random, NSA-style redactions to the banal Twitter musings of sundry members of the US Congress, blacking out innocuous phrases to suggest that a deeper and darker meaning lurks beneath. We may scoff at the unthinking rigidity of these bots, but each begs a question of its own that demands a flexible answer from readers: How would you respond? What would you collect? What would you redact? How might you do any better?
Satirical bots make a virtue of rigidity and serve as willing vehicles of ridicule for conveying our scorn for the inept, the indifferent, and the unthinking. Yet it is worth remembering that these rigid bots are also designed to put on a good show and offer views that might conceivably shape the response of readers to the news or the art pieces showcased by @museumbot. So @appreciationbot also asserts the necessity of art criticism, of forming and articulating a response to art while simultaneously lampooning the role of the critic. Embedded in the bot’s rigid boilerplate is a challenge to its readers: If a machine can look past the literal surface to see a deeper meaning in art, what can you see when you look?
Dreaming in Technicolor
We do not dream in abstract propositions or in symbolic IOUs. Our dreams feel real. They swirl with vibrant colors, aromas, and sensations because they tap into many of the same brain functions as do our waking lives. As the dreamwork of language, our most vivid metaphors repackage reality in much the same way as our dreams. Metaphors allow us to describe abstract concepts while dealing in concrete specifics: so the loudness of a garish tie is not an abstract loudness, but more like the painful loudness of nails on a blackboard; the red of anger is not simply a word, but a hot, vibrant red, just as the white of saintly purity is a bright, shining white. To be reminded of how well an apt metaphor can communicate not just a color but a highly specific sense of time and place and emotional attachment, we need only open a manufacturer’s catalog of paint hues. What paint maker with even an ounce of commercial nous would call a color “beige” (Who among us can even hear the word “beige” without thinking it a metaphor for mediocrity?) when they can instead sell it as “malted barley,” “Tuscan panna cotta,” “iced cappuccino,” “butterscotch latte,” “vanilla sky,” or “evening biscotti” to a generation of consumers who eat with their eyes and think with their bellies?
For its part, Twitter is awash with color—not just color words but swatches of real color attached as images to descriptive tweets. Recall @everycolorbot, a tweeter of random six-digit RGB codes and slabs of the corresponding colors. To a computer, a fixed RGB code is far more useful than any arbitrary linguistic label, but unless one is a color savant, a meaningful name is far more evocative than an abstract code lacking any physical anchor to our own experience of the world. RGB codes and linguistic labels make sense in very differently wired systems of grounding: a computer’s physical display and a human’s perceptual architecture. RGB may not offer a good model for how humans perceive and represent color, but its codes are easily mapped to other color systems, such as CIE LAB, that do a more faithful job of capturing the dispositions of human perception. We can, by mapping a computer’s use of linguistic color terms to specific RGB codes, effectively ground a machine’s internal use of color symbols in real colors and align its perceptual interpretations with those of a regular human observer. This problem of grounding—or, rather, lack of it—in computational systems has long been the shabbiest float in the AI parade, with philosophers such as Berkeley’s John Searle arguing that machines can shunt symbols from place to place easily enough, but they can never anchor those symbols to real-world experiences in the ways that make them truly meaningful to humans. A bot can get only so far by playing ungrounded language games with IOUs that are never meant to be cashed in. Before our Twitterbots can use symbols in the ways that we humans use them, we must first ground them in the same perceptual frames of reference.
If @everycolorbot is Kaspar Hauser for the Twitter age, all sensory impression but no means of channeling these impressions into affective language, how much fun would it be to lend a voice with a grounded sensibility to its outputs? If we think of @everycolorbot’s hex codes as the mouth movements of a ventriloquist’s dummy, can we design our own bot to serve as the ventriloquist who gives them meaning in context? To do this, our new Twitterbot would have to go from color percepts to linguistic labels, something we humans do every waking moment of the day via a process of remembering. What does this specific perception remind me of? The color of a rose in bloom? Zombie gore? Fire trucks or candy apples? Some remindings may be distinctly personal or idiosyncratic, such as the redness of the boil on Aunt Mabel’s neck. These are not for our bot, or at least not as we conceive of it here. Rather, we are interested in shared perceptions and shared remindings, so that the color metaphors that our bot coins can evoke apt color sensations in the minds of its readers. Our new bot thus needs to tap into the same collective stock of cultural color stereotypes that we all share as speakers of the English language. We all, for the most part, agree on the color of red wine, of Dorothy’s slippers, of roses and blood and cardinals’ cloaks. Our first and most crucial task, then, is to provide our bot with the mappings of stock ideas to stock hues that inform how we humans meaningfully label our colors.
A good place to look for these lexicalized color stereotypes is our everyday use of language when talking about specific shades and tints of the basic colors. How many ways can you fill the [X] in the adjective “[X]-red”? Well, there are blood-red, ruby-red, cherry-red, rose-red, plum-red, flame-red, and coral-red, to name just the most popular. Because speakers are far more likely to use wine-red than wine-white, our color stereotype for wine will not be an off-white but a deep shade of red. These stereotypes are the recognizable landmarks relative to which we find our bearings with language. The poet Homer puzzled scholars for millennia with his epithet “wine-dark sea” in the Iliad, suggesting that either wine or water had a different hue in ancient times or that Homer truly was as blind as tradition tells us.26 Can red wine turn dark blue if it is heavily diluted with alkaline water, as was the fashion with the potent hard-liquor wines of antiquity? Yes, scholars tell us, it can. But it seems more likely that Homer really did mean to say that the sea, at dusk under an auspicious red sky, was as dark and blood-red as a good red wine.
Our stereotypes are important because they ground our words in perceptions of the world that we all share, even when—or especially when—we use them poetically. We need to moor them to fitting RGB codes if our bots are to use them in ways that show they reside in the same world as we do and are not blind to the same distinctions of hue and shade that we make when we label the world. To build a large inventory of color stereotypes, we can use the Google database of web n-grams (snippets of text of between one and five tokens in length possessing a web frequency of forty or more, as collated by Google into a public resource) to harvest all matches for the hyphenated 3-gram templates [R]-red, [B]-blue, [G]-green and so on, filtering any values for R, B, and G that do not suggest a specific color (e.g., such as the “bright” of bright-red). We must then assign an apropos RGB code to each. Although we could use automated image analysis for this laborious task—say, by downloading images from Flickr that are tagged with the corresponding words and averaging the relevant hues in each—it turns out to be quicker and more faithful to the just-do-it spirit of bot building—to assign appropriate RGB codes by hand, with a little help from sites such as ColourLovers.com. A few days of manual effort yields a stereotype inventory of six hundred or so word-to-RGB mappings, ranging from almond-white to zit-red by way of Hulk-green and Trump-orange. Though the work is drudgery of the purest kind, it is worthwhile drudgery (and readers will find the fruits of this toil on our GitHub). When we invest thoughtful effort in the creation of reusable resources, we also invest in the future bots we haven’t yet imagined.
Each stereotypical pairing of name-to-code suggests a conventionalized one-word name whenever a nearby code is tweeted by @everycolorbot. But to escape the realms of the conventional, a naming bot must use a phrasal blend of words to suggest a perceptual blend of hues. The code D3D5C5 may cash out as a dull cardboard-like blend of alien-green and brain-gray, yet because it can point to those lexicalized landmarks in RGB space, a bot can give the color a name like “alienbrain” that is more interesting and memorable than perhaps it deserves. But should our bot name the color “alien brain” or “brain alien” or “alienbrain,” or is each equally awful? Well, a bot can, in principle, mix any two stereotypical colors and yoke together any two stereotypical names to arrive at a phrasal name for a blended hue. For simplicity, we can assume that colors are mixed in a 50:50 ratio, so that “alien brain” and “brain alien” both name a blend of 50 percent alien-green (C3C728) and 50 percent brain-gray (E3E3E3). Conversely, we can assume that D3D5C5 is more or less halfway between two landmarks in RGB space, and by identifying these landmarks a bot will have the ingredients it needs to coin a new name. But while the mixing of two colors always yields a valid third color, the yoking of any two words rarely yields a well-formed phrase. The RGB space is fluid and continuous, while the name space is brittle and discrete. There are many hard rules and many more tacit norms that guide the combination of symbols into a meaningful name. So rather than even trying to articulate these rules and norms, it is simpler and more instructive to go back to the language well to see how we humans actually pour words into resonant containers. This requires that we take a headlong dive into the Google web n-grams.27
At this point we make another convenient assumption, this time about words: the Google 2-grams are so comprehensive—containing every two-word phrase that has been used forty times or more on the web—we can assume that any name that is found in the 2-grams is sufficiently attested to be trusted. Conversely, any coinage whose well-formedness is not attested in the 2-grams should be rejected. Applying this standard to “alien brain” and “brain alien,” we find that the former has a web count of 1,179 and the latter has a web count of 0, which is to say that it is not listed at all in Google’s 2-grams in its singular form. We do, however, find “brain aliens” with a web count of 46. If we also look in the Google 1-grams for the solid compounds “alienbrain” and “brainalien,” we find the former has a fairly high web count of 2,774, while the latter is still 0. All things being equal, the solid 1-gram “alienbrain” is preferable to the 2-gram “alien brain” because its surface tightness of form implies a deeper cohesion of ideas: these concepts click and stick together. Broadly speaking, then, we prefer 1-grams to 2-grams, and frequent 2-grams to infrequent 2-grams. Of course, one could argue that the most creative names reside at the lower end of the frequency scale and not the higher, as frequency and obviousness go hand in hand. However, a random 1- or 2-gram is very rarely used to name a color, and the vast majority of the uses of “alien brain” as counted by Google will be literal uses. (It is highly unlikely that anyone has ever suggested painting the kitchen with “alienbrain.”) By repurposing familiar n-grams to carry new meanings in new contexts, we treat them as linguistic “ready-mades” in the “found art” tradition. So just as Marcel Duchamp did not build a urinal with his own hands when he exhibited his infamous Fountain in 1917, our naming bot sets out to find new uses for some overlooked forms.28
A naive naming strategy quickly suggests itself: given a random hex code from @everycolorbot, our bot can exhaustively search its inventory of color stereotypes and proceed to combine the words associated with each—for example, “honey,” “Hulk,” “nut,” “alien,” “brick,” “wine”—into candidate names for the target color. A viable candidate is any combination of lexical ingredients, such as “Hulk wine” or “alien brick,” whose averaged RGB color is sufficiently close to the target RGB code. Viable candidates can now be filtered according to their presence or absence in the Google n-grams, where the attested candidates that survive the cull are ultimately sorted in descending order of web frequency. This strategy is naive because of the sheer number of failed candidates it creates and the amount of unnecessary search it entails. It is sometimes wiser and more efficient to put the cart before the horse, doing things in a counterintuitive order. So consider this alternative cart-first strategy: in an offline process, our bot prescans all of the Google 1- and 2-grams for solid 1-grams and phrasal 2-grams that combine two different color stereotypes, such as “alienbrain” and “wine teeth.” For each one—attested candidates all—it calculates the average RGB code of its constituent parts and places the pairing of attested name and code into its cart. Later, when running in online mode and responding in real time to tweets from @everycolorbot, our bot can simply take the RGB code offered by @everycolorbot and compare it to the codes of the ready-made names in its cart. It now has the pick of the nearest codes and their preinvented names and can choose from the pairings that maximize both web frequency and nearness to the target color.
If web n-grams are linguistic commodities, this algorithm gives us a well-oiled assembly line for turning them into ready-made “inventions” on a massive scale. To build a pipeline of your own, you can find the key inputs to this assembly line—our inventory of color stereotypes, and a long list of 1- and 2-grams that fuse pairs of these stereotypes into compound wholes—via BestOfBotWorlds.com. You can configure your pipeline your way and frame the outputs of your assembly line using any number of idiosyncratic rhetorical strategies. Indeed, you might decide against blending colors into a single hue and juxtapose them instead in blocky compositions reminiscent of (or playfully satirical of) Mark Rothko, or splatter them semirandomly on a blank canvas in the style of Jackson Pollock, or arrange them in geometric patterns in the manner of Bridget Riley. (We take up this theme again in chapter 7, where we explore ways of grounding colors in linguistic descriptions and in complex bot-generated imagery.) Rothko, in particular, offers a way of using Google 3-grams as an inspiration for a Rothkobot’s color combinations, since 3-grams that link two color stereotypes with a spatial preposition, such as “cheese on toast,” offer a spatial guide to the composition of multiple color blocks into a coherent whole. (“cheese,” a mass noun, suggests a solid block of cheese-yellow sitting on a solid block of toast-brown). But even when keeping it simple, by blending colors like store-bought paints, how a bot frames its blended colors is very much a matter of individual taste. Check out @DrunkCircuit, @ColorMixALot, @ColorCritics, @DoctorDulux, @AwesomeColorBot, @every_TeamBot, @My_Color_Book, @WorldIsColored, @haraweq, and @HueHueBot for examples of how others have imposed their own quirky personalities on the cart-before-horse pipeline.
Crowd-sourced evaluations allow us to compare the lexical inventions of one of these approaches—@HueHueBot’s—to those of humans for the same colors, as expressed via the naming choices on ColourLovers.com. For a sample of 2,587 colors named by the bot, human judges were presented with a block of the color, the name assigned by the bot, and a name assigned by a human that has at least one vote of “love” on the site.29 Judges were not enlightened as to the source of either name, and the order in which names were presented was randomly chosen for each judge to avoid giving one or the other a tacit advantage. Each judge was presented with the following three questions:
Which name is more descriptive of the color shown?
Which name do you prefer for this color?
Which name seems the most creative for this color?
The 940 judges were paid a small sum for each of their answers. Judges were timed on their responses, and those who spent less than ten seconds presenting their answers for any color were classified as scammers and discarded. We required that each question be answered by 5 nonscamming judges to be trusted for evaluation and obtained 12,608 trusted judgments overall, discarding an additional 5,040 as the work of likely scammers. We terminated the experiment once our modest budget was exhausted and 1,578 of 2,587 colors had received five trusted judgments per question.30 Tallying the ratings of trusted judges on these 1,578 colors, we observed that 70.4 percent of individual judgments for most descriptive name (Q1) favored the bot, 70.2 percent of individual judgments for most preferred name (Q2) favored the bot, and 69.1 percent of individual judgments for most creative name (Q3) also favored the bot. When we tallied the majority judgment for each question for each color—the choice picked by three or more judges—we saw that for just 354 (23 percent) of the 1,578 colors, the majority deemed the human-invented name for a color to be more descriptive than the one invented by the bot. The results for the next two questions, Q2 (Which name do you prefer?) and Q3 (Which name is most creative?) were very much in line with those of the first question. Only for 355 colors did a majority of judges for a given color prefer the human-assigned name over the name assigned by the bot, and only for 357 colors did a majority consider the human-invented name to be more creative than the bot’s. This three-to-one breakdown in favor of the Twitterbot suggests that in the right contest, machine-invented ready-mades can be remarkably competitive with human coinages.
Bot Coin
The irony of these results is that the bot does so well because it grounds its use of symbols in ways that seem more immediate and less opaque to humans. We humans have the last word when it comes to grounding, not least because we are asked to judge the symbols of others and the symbols of the bots we build. Yet when reaching for soaring poetry, we often take our feet off of the ground. By using personal symbols that are grounded in our own memories and feelings, we create linguistic artifacts that fail to fully connect with those of other humans. So while a bot may christen a shade of pink “Crimson Flesh” or “Rosé Champagne,” a human on ColourLovers.com might instead suggest the name “Sparrow’s Lament” or “Candle in the Wind,” neither of which evokes a familiar stereotype for pink or red. Obviousness is no foundation for creativity, yet familiarity often yields rich dividends. While the human coinages on ColourLovers.com are typically more sophisticated than the two-word (or solid compound) confections of our simple bots, our bots’ names can still carry a vital resonance, even if it is a borrowed resonance carried on ready-made phrases that were previously crafted by humans. But as Marcel Duchamp argued after his Fountain, a urinal bearing the signature of its “creator,” R. Mutt, scandalized the art world in 1917, art is not a product of how artists make things but of how they make meanings. Writing anonymously in Blind Man magazine, Duchamp (or his designated hitter) made a trenchant case for creative reuse: “Whether Mr. Mutt made the fountain or not has no importance. He CHOSE it. He took an ordinary article of life, placed it so its useful significance disappeared under the new title and point of view—created a new thought for that object.”31
Marcel Duchamp understood what so many of his art contemporaries were so unwilling to believe: moving an often seen but rarely appreciated artifact such as a urinal from the men’s room to the gallery floor changes the way we perceive it and creates new opportunities for meaning making. So the potential for readers to find or make meaning in a bot’s compositional outputs resides as much in how we frame those outputs as in the conventional meaning of their individual parts. Many bot outputs are like a wallet accidentally dropped on a gallery floor, all form and no intent but dropped into a forum where onlookers are eager to find meanings. Others are, like Duchamp’s urinal, a deliberate act of provocation with a specific intent, and even if viewers attach a significance of their own that is different from that of the artist, the work has been chosen to stir just this kind of debate. Many more bot outputs fall somewhere between these two stools, insofar as they are crafted to grab our attention and provoke a meaningful response, even if the bot itself has little idea of the “meaning” of its own provocations.
The bot landscape is home to bots from every point on the meaning-making spectrum and has ample room for countless more to come. Bots such as David Lublin’s @TVCommentBot—which uses image analysis for object identification in live TV to invent its own appropriately incongruous closed captions, tweeting still images with their new subtitles—are loved as much for their mistakes as for their technical ambition, as much for their often hilarious misunderstandings as for their accidental insights.32 Although the heterogeneity of the bot landscape is such that no single bot can be held up as an ideal, when it comes to the class of technologically complex bots whose outputs are molded by sophisticated tools and rich resources, @TVCommentBot is as close to an ideal as a bot can get. Its frequent failure to make an accurate identification of on-screen objects means that its textual labels must often be taken figuratively, and joyously figuratively at that. @TVCommentBot’s fans love it for its accidental metaphors and its odd and frequently subversive juxtapositions of imagery and text. Yet it is because the bot tries so hard that it gets to own its own mistakes, to earn our laughter for gags that are unplanned but for which the conditions for accidental success have been carefully nurtured. Bot fanciers need little urging to see diamonds where others see lumps of coal, and a bot need not be a martinet to be a creative maker of metaphors that connect with readers and give them something provocative to think and laugh about. But the more effort a Twitterbot invests in knowledge, representation, word choice, symbol grounding, and rhetorical framing, the stronger and more affecting this connection with the reader is likely to be.
Trace Elements
As the label makes clear, knowledge-based metaphor generation is a knowledge-hungry process, so the more knowledge we can squeeze into our generator, the more wide-ranging yet meaningful the resulting metaphors will be. We’ve squeezed a great deal of knowledge into a metaphor-generating Tracery grammar you can find in the Metaphor Generator subdirectory of our Tracery repository. This machine-generated grammar is so jam-packed with details that not only does it make use of cryptic two- and three-letter labels for its nonterminals, we’ve also had to remove every unnecessary piece of white space. Consider this sample output from the grammar:
Most revelations are fascinating, but others are as “fascinating” as a brick wall.
The grammar encodes the fact that revelations are stereotypically fascinating, just as it encodes the fact that brick walls are typically anything but fascinating. Facts like the former come from earlier research into similes and are harvested from the web using the search pattern “as [X] as [Y].” Ironic observations such as the latter are also harvested from web similes, but this time using the search pattern “about as [X] as [Y].” It turns out that humans like to telegraph their creative (and often ironic) intent with markers of semantic imprecision such as “about,” “almost,” and “not so much.” The Tracery grammar pairs a nonironic stereotype with an ironic observation to create a new figurative comparison that is both factual and weird.
Since CBDQ allows its Tracery bots to respond to any mentions of its handle in the tweets of others, you’ll also find a metaphor response grammar in the same subdirectory. The grammar, named metaphor responses.txt, has a simpler format than the standard Tracery grammar. Each rule pairs a literal string on the left-hand side (the stimulus) with a single string on the right-hand side (the response). Only the response string can contain a nonterminal symbol. When the stimulus contains a property (such as “fascinating” or “sublime”), the response grammar asks the main Tracery grammar to generate a metaphor that pivots on that property. For example, should another user mention the name of our bot and use the word “sublime” in the same tweet, CBDQ may generate the following response on our behalf:
Most gems are sublime, but others are as “sublime” as a kick to the head
For good measure, the response grammar also contains a large number of stimulus:response pairs that have been autogenerated from an online dream dictionary, allowing the bot to offer faux analyses of a user’s dreams. The part of the response grammar that dabbles in dream analysis makes no reference to the main Tracery grammar and its nonterminals, so you are free to cut-and-paste this part into your own Tracery-based bots on CBDQ.