On May 6, 2010, the U.S. capital markets experienced a tremendous crash, with the Dow Jones Industrial Average losing more value than on any other day in its entire 110-year history. But within minutes, the market rebounded, and after major company stocks had dropped to pennies a share they returned to normal pricing. The entire episode seemed to fade away as quickly as it appeared, leaving a series of hanging questions about the forces shaping world financial markets. At the root of this radical instability is a highly specialized and lucrative form of algorithmic arbitrage.
Over the past ten years, computational systems have become increasingly important to the markets, gradually replacing the familiar sight of men in bright-colored vests yelling across a crowded trading floor with the tenebrous world of server cabinets and proprietary code. As financial journalist Michael Lewis describes in Flash Boys, the transactional role of algorithms has grown from the simple execution of trades into a kind of micro-tax on the entire market system.1 This is a classic example of arbitrage, or the leveraging of different markets to create profit, like traders who buy cheap wheat in the country to sell at a profit in the city. Ultimately arbitrage is always about time—capturing the difference in price before someone else does it for you—and for algorithms, time is measured in microseconds. On Wall Street, this is now known as high frequency trading (HFT).
When stock exchanges began to process trades digitally and to proliferate in the 1990s and 2000s, expanding from the dominance of NYSE and NASDAQ to thirteen public exchanges by 2008, enterprising market actors realized that they could carve out a new kind of competitive advantage.2 By observing trades occurring on one exchange that would “move the market” and changing the price of a particular commodity elsewhere, they could use the temporal advantage of a few microseconds to create a small window of opportunity. For example, if a major pension fund asked its broker to buy, say, 100,000 shares of Microsoft, HFT firms might detect the signals of this trade as it moved through one exchange and act to profit from it on others by buying up Microsoft stock with the intention of immediately selling it at a slightly higher price to the pension fund. For the pension fund, the trade would be just a little more expensive than anticipated, but iterated over millions of transactions a day the taxes become substantial.
HFT offers one of the purest examples of algorithms that are fundamentally altering an existing culture machine, that venerable assemblage of math, social practices, faith-based communities, and arbitrage that we call “the market.” The introduction of high-speed trading and algorithms that are effectively fully automated engines of commerce has done more than eliminate humans from the trading floor: these systems operate in open competition with humans and one another, and they are gradually transforming the broader movement of capital. HFT arbitrageurs build their advantage through complex geographical maneuvers, by locating their servers and fiber-optic lines a few feet closer to the exchanges’ central servers than their competitors, or leasing communication lines that shave a few miles off the best direct signal pathway between two points on the financial grid. While they are traders, they almost never lose money, since their form of arbitrage always depends on superior information and they do not arbitrage risk like more traditional brokers. They never hold stocks at the end of the day, only cash.3
This is a form of cultural arbitrage, not just computation, because HFT takes advantage of our assumptions about the fundamental purpose of buying and selling securities. The proliferation of market order types (well over 100, ranging far beyond the familiar “buy,” “sell,” and “limit” types), the incentives for buyers and sellers willing to use particular trading protocols, and even the growing number of exchanges in operation have all contributed to an increased volume and pace of trading.4 Much more than securities, these systems trade information, which has always been an essential role of the markets. But they atomize and encrypt that information in a new series of black boxes—the switching systems, trade-matching engines, and algorithms themselves—that allow HFT firms and the major Wall Street firms that deal with them to create a kind of subaltern skim economy. The algorithms that generate billions in profits for their keepers operate at the margins by capitalizing on special knowledge of network latency, or the lag-time between when a signal originates at one node and arrives at another. Finding ways to get a little bit ahead of the next guy, even at the level of thousandths of a second, allows companies to create closely guarded financial shortcuts and ambush-points where more traditional modes of commerce can be exploited as they move through financial networks.
Considered on its own terms, HFT allows us a way to imagine a familiar culture machine—the market—in its translation to a truly computational space. The volume and stochasticity of the financial markets themselves are the primary canvas for these algorithms, with decisions coded along tightly constrained abstractions about pricing, inherent value, and the pace of information. The speed and volume at which these systems operate, and their increasing cooption by investment titans like Goldman Sachs, are beginning to change the fundamental behavior of the markets.5
The heroes of Lewis’s story are those trying to eliminate the “unfair” predation of HFT algorithms and create an equal playing field for the trading of securities as they imagine such things ought to be traded. Their solution is not the elimination of algorithms but instead of the human intermediaries who might find new ways to game the system. “There was no longer any need for any human intervention. … The goal had to be to eliminate any unnecessary intermediation.”6 For the players on Wall Street, the problem with HFT was not its position in computational space, but its troubling ties back to the material world.
Lewis describes two charts his reformers created to demonstrate the changing nature of the market: the first shows activity as humans perceive it, with a crowded series of trading events marked second-by-second over the space of ten minutes. The second chart demonstrates an algorithmic view of a single second, marked off by milliseconds:
All the market activity within a single second was so concentrated—within a mere 1.78 milliseconds—that on the graph it resembled an obelisk rising from the desert. In 98.22 percent of all milliseconds, nothing at all happened in the U.S. stock market. To a computer, the market in even the world’s most actively traded stock was an uneventful, almost sleepy place. …
“What’s that spike represent?” asked one of the investors, pointing to the obelisk.
“That’s one of your orders touching down,” said Brad.7
The sudden spike represented a large institutional investor placing an order, which then caused the waiting financial algorithms to leap into a frenzy of front-running, counter-bidding, and positioning, all conducted at a pace that is impossibly fast for human processing. Yet it was languidly slow for these algorithms, which spent 98 percent of that second waiting for someone to make a move: 1.78 milliseconds is more or less incomprehensible as a temporal span. By contrast, the typical human reaction time is something on the order of 200 milliseconds. The algorithmic contemporary has outpaced our capacity to manage it without computational help.
This visual narrative neatly captures the space of computation, highlighting the essential feature of its radically different time scale but also signaling how difficult it is for us to imagine the consequences of that temporality. The spike of activity represents orders, but behind those orders are financial signal traps and sensors, algorithmic decision trees to determine a course of action, trading tools to implement them, and, somewhere in the unimaginably distant future, perhaps minutes or hours later (if it happens at all), a human to review the activity. The obelisk in the desert is a reminder of what Her’s Samantha would mournfully call “the space between the trades,” if Theodore had an investment account. But it also demonstrates how algorithms are colonizing the margins of human activity. Scott McCloud wonderfully captures the extradiegetic space of a narrative with the comic book term “the gutter.”8 The gutter is the blank space between panels, largely ignored by the reader as she stitches static images into a compelling, animated narrative that feels seamless. It is where we infer events and actions that often are only obliquely referenced in the surface discourse of a narrative. You might argue that consciousness is the act of constructing a narrative from the inaccessible gutter of human cognition—the ways that we stitch together a personal history from fragments of sensory input and inference.
We do this by creating a model simulation of the past, interpolating temporal continuity from those experiential fragments. We pretend the gutters aren’t there, paving them over with personal narratives and memories that feel complete. Arbitrage is another form of interpolation where we simulate forward in time instead of backward, effectively predicting the future and capitalizing on it. But trying to understand computational space is a different challenge entirely, requiring us to voyage not forward but deeper into time. McCloud’s notion of the gutter reveals how the ground rules, even the physics, of implementation have epistemological implications. The current transformation of global finance largely depends on the arbitrage of money and information between two temporal universes that are almost completely mutually exclusive. The obelisk that Lewis describes is a human metaphor for algorithmic trading, almost like a stylized postcard from a computational universe where time is everything. HFT algorithms translate the gutter—the gaps between placing an order and executing it, for example—into an arena for competitive computation. In both the narrative and financial examples, the gutter is the place where time is translated into meaning and value.
By saying that HFT algorithms perform a simple comparative arbitrage between stock prices at different geographic locations is to say that they value time, but, more important, that they value the temporal process. In these transactions, the intrinsic worth of the securities in question, their leadership, their price-to-earnings ratios, are all meaningless. The meaning of the exercise is derived from the temporal gap between point A and point B, and the odds of executing a trade that capitalizes on someone else’s. Their efficiency at modeling a particular ideology of time and space, denominated in microseconds, is gradually reshaping the entire ecosystem they inhabit. In this way HFT algorithms replace the original structure of value in securities trading, the notion of a share owned and traded as an investment in future economic success, with a new structure of value that is based on process.
Valuing Culture
The arbitrage of process is central to Google’s business model; one of the world’s largest companies (now in the form of Alphabet Corporation) is built on the valuation of cultural information. The very first PageRank algorithms created by Larry Page and Sergei Brin at Stanford in 1996 marked a new era in the fundamental problem of search online. Brin and Page’s innovation was to use the inherent ontological structure of the web itself to evaluate knowledge. Pages on university websites were likely to be better sources of information than those on commercial sites; a news article that had already been linked to by hundreds of others was a stronger source of information than one that had only a few references elsewhere. By viewing the rapidly expanding Internet less like a haystack and more like a subway system (where some stations are much busier and more convenient than others), Google established an algorithmic model of the digital universe that now shapes almost every aspect of digital culture.
The first primitive efforts to navigate the web relied on human intervention: a “cool site of the day” or the first blogs that curated content like a digital Wunderkammer, creating an idiosyncratic, aesthetically grounded response to those largely unmapped networks.9 But our relationship with the Internet gradually evolved from something like a bulletin board or a newspaper, where we might browse for information serendipitously, to an essential utility that provides financial, industrial, and personal services ranging from bank accounts to online dating. When we turn on the faucet, we expect a reliable stream of something that is, we hope, recognizable as (nontoxic) water, not a “cool liquid of the day.” So too, we now expect the Internet to serve as a utility that provides dependable, and perhaps fungible, kinds of information.
PageRank and the complementary algorithms Google has developed since its launch in 1998 started as sophisticated finding aids for that awkward, adolescent Internet. But the company and the web’s spectacular expansion since then has turned their assumptions into rationalizing laws, just as Diderot’s framework of interlinked topics has shaped untold numbers of encyclopedias, indexes, and lists. At some point during the “search wars” of the mid-2000s, when Google cemented its dominance, an inversion point occurred where the observational system of PageRank became a deterministic force in the cultural fabric of the web. Google now runs roughly two-thirds of searches online, and a vibrant industry of “search engine optimization” exists to leverage and game Google’s algorithms to lure traffic and advertising.10
At its heart, PageRank catalogs human acts of judgment, counting up the links and relative attention millions of people have paid to different corners of the web. The patent for PageRank describes the algorithm as “a method [that] assigns importance ranks to nodes in a linked database, such as any database of documents containing citations, the World Wide Web or any other hypermedia database.”11 In short, this is a tool for creating hierarchy in the world, sorting information not merely by its inherent qualities but by a certain definition of importance or popularity. It is not too much to argue that the transition from more primitive search engines to the algorithmic weighting of PageRank and its imitators has shifted the role of knowledge in society as profoundly as Diderot and d’Alembert did when they debated which ordering schema to use for the Encyclopédie.
That transformation is shrouded in the modesty of the list, that simple intellectual construct that the semiotician, philosopher, and literary critic Umberto Eco once identified as “the origin of culture”:
What does culture want? To make infinity comprehensible. It also wants to create order—not always, but often. And how, as a human being, does one face infinity? How does one attempt to grasp the incomprehensible? Through lists, through catalogs, through collections in museums and through encyclopedias and dictionaries.12
Both the encyclopédistes and Google would argue that their projects do not create hierarchy but model it—that their knowledge ontologies are simply more effective maps for structures that already existed in culture. And yet, as Eco suggests, in both instances the structure they created quickly became an ordering mechanism of its own, shaping the cultural space it was designed to observe. One of the most vital functions of the encyclopedia was to compress knowledge for the sake of time, distilling millions of person-years of insight into a reference text that would accelerate the pace of research and discovery. For Diderot and d’Alembert, it was the book that politically, philosophically, and perhaps epistemologically paved the way for the French Revolution. For Google, it is a future of machines that understand, converse, and anticipate—a future of a complete computational ontology of knowledge.
These were the two projects’ ambitions, now largely fulfilled. But they were also systems implemented in historical moments where they achieved something different: a reframing of cultural value and temporality. Just as the HFT algorithms exploit gaps in the technical and cultural construction of trading, PageRank arbitrages a rich field of latent information—the network of connections making up the global Internet—and distills it into an immediately accessible resource. Google Search saves us time in the long run by tracking down the most useful resources relevant to our query, a first-order form of anticipation. But it also saves us time in the short run by providing its search results with startling immediacy: Google realized early on that delays of even a tenth of a second would reduce user engagement, and built its infrastructure accordingly.13 The arbitrage of time at the level of knowledge synthesis and immediate gratification are crucial factors in promoting both encyclopedias and search engines.
That temporal arbitrage inevitably led to a renegotiation of value in financial terms as well: time is money, especially time measured by milliseconds multiplied across millions of servers. For this, Google needed AdSense. From a business perspective, PageRank creates a basic index for the circulation of ideas, an essential currency in the economy of attention.14 When Google began selling advertisements against its search results with the market bidding system AdSense, it succeeded in monetizing that attention at a previously unimaginable scale. In 2013, Google earned over $55 billion in revenue, of which more than 90 percent came from advertising.15 Now the company will help you register the domain name, build the website, analyze the traffic, and serve the ads for the site, which its algorithms will then index and rank. In 2014, Google exceeded the market capitalization of ExxonMobil, leaving it second only to Apple among the most valuable companies in the world.16
The typical Google advertisement nets the company some tiny fraction of a penny to serve up to a customer, but over the volume of the tens of billions of ads it serves each day, those fractions add up to a kind of minimal transaction cost for using the Internet, collected by its most powerful gatekeeper.17 The functionality of AdSense is in fact a kind of HFT arbitrage in its own right: every time a user navigates to a site serving advertisements via Google’s network, a rapid auction takes place for the marketers with the highest bids to serve their ads. These transactions commoditize the long trail of user data each of us leaves behind online—the detailed consumer profiles about us informed by our purchase history, demographics, and many other factors—so that advertisers can identify target markets based on user “interests” as well as the contextual space of the host website. But AdSense is also a form of temporal arbitrage, commoditizing time just as effectively as HFT systems milking profits out of a few milliseconds of lag. Google has built a tremendous business out of the immediacy of AdSense, out of commoditizing the contemporary, the moment right now when a potential customer is literally hovering at the threshold.
Internet ads, like all advertisements, are a form of cultural latency or temporal use tax, placing minor drag on the fluid market of attention. The incredible algorithmic infrastructure of these micro-auctions, the magic of cached content and highly coordinated global arbitrage, reveals a tiny but measurable point of translation: the fraction of a second that marks the gap between cultural and commercial value. That pause is noticeable, not just as a delay but as a kind of persistence, a new form of externalized memory filled with algorithmic models of consumer desire.18 We are haunted by the shoes, the cars, the vacations that we have not yet purchased much more directly than we are by the hidden shadows of our digital selves that marketing companies carefully maintain. PageRank and AdSense are really two sides of the same coin, uniting the ideal of access to universal knowledge with that of perfectly understanding each of us and our desires. They are two expressions of Google’s central mission to translate the quest for knowledge into algorithmic process.
The arbitrage of PageRank, the process of AdSense, present not just a series of discrete computational events but a pervasive narrative about cultural value. It’s a story that is fueled by our continued engagement and attention, by Google’s advertising revenues, and by its growing role as a central platform for nearly all forms of digital experience. To recast value in a different light, these interlocking arbitrage systems embody what cultural theorist Alan Liu has called an “ethos of information”: a style, in humanistic terms, or a level of abstraction in computational ones, that creates a critical superstructure over the information itself.19 In Liu’s language we might argue that the web has moved from a romantic to a rational phase, leaving behind the homebrew sublime of early hand-coded sites for the elaborate corporate order of branded, automated page serving that dominates today.20
In other words, while Google built its business on accurately mapping the cultural ontologies of the Internet, its role has gradually shifted from indexer to architect. Its core business model gained traction by effectively marrying algorithms to consumer culture, and it increasingly depends on using algorithms to define that culture in profound ways. Google’s dominance over the critical arbitrage of search has created a pressing need for new forms of literacy, most publicly in the context of the Star Trek computer and Google search itself. The company’s emergent role as chief architect of the Internet is still, at heart, a form of cultural arbitrage and therefore a temporal project. Google wants to anticipate, to predetermine, every possible resource its many users may want to tap. This requires new vocabularies of memory, of privacy, and even of forgetting as the company becomes more effective at shaping the holistic, permanent archive of digital culture.
These new literacies have been most controversial in Europe, where privacy is understood as an inherent human right rather than the child of contracts. Recent court decisions there have forced Google to remove certain search listings judged damaging to individuals because it foregrounds negative episodes from their past.21 Google’s response has been to mark each erasure with its own annotation, alerting people that some results have been censored, to maintain the ideology of total transparency memorably expressed by Eric Schmidt when he said, “If you have something that you don’t want anyone to know, maybe you shouldn’t be doing it in the first place.”22 But of course arbitrage is built on the temporal advantage of keeping certain information protected and carefully managed: advertisements, browsing behaviors, search queries. Google Now requests permission to access our search histories, physical location, and other data in order to provide its services, and in return it promises to organize not just the present but the near future temporalities of its users. It will suggest when to leave for the next meeting, factoring in traffic, creating an intimate, personal reminder system arbitraging public and private data. As we come to grips with the consequences of the deep interlacing of cultural value and algorithmic arbitrage, the ideals of anonymity and untraceable commerce have become more and more appealing.
Cryptocurrency
Google’s expanding role as a kind of central utility for arbitrage and cultural valuation online has brought some of the dot-com era’s fondest dreams to life, but in an unexpectedly quiet, backroom way. The futurists Peter Schwartz and Peter Leyden offered one of the best-known expressions of that era’s visions in 1997 with “The Long Boom,” published in that bulletin of the digital revolution, Wired magazine.23 Schwartz offered many predictions centered on five waves of technological change, but a persistent pivot point for the transcendental Wired future was a new kind of computational arbitrage for capitalism that freed commerce from the historical relics of bureaucratic regulation, physical specie, and sovereign control. The widespread adoption of what Schwartz called “electronic cash” was something Wired had covered earlier in 1994 and 1996, and the magazine championed the postmaterial, global network economy that underpinned its broader vision about the triumph of information. Early digital cash entrepreneurs recognized the growing value of information and attempted to create an algorithmic abstraction from money to information. As Google and the other major players in the contemporary technology space discovered, the abstraction is much easier to work the other way through the timeless magic of arbitrage: start with information and turn it into money.
As we’ve seen, however, that form of computational magic depends on large systems of observation and data collection: companies amass vast troves of data, from individual user profiles to deep indexes of the Internet itself. Then access to these troves becomes a commodity for both individual consumers and the marketers seeking to reach those consumers. At every stage, arbitrage nets these companies a share of every transaction, every advertising micro-auction and credit card purchase. These shifts are easy to overlook: the list of albums for sale on iTunes is not so different from the choices we might have encountered in a record store; the offerings on Netflix still appear to be a series of choices about what to watch. The dramatic changes on the algorithmic backend are packaged in relatively familiar consumer terms. In other words, what Wired imagined as a commercial revolution has instead been a reformation—not without its upheavals and casualties, but largely a transformation that has left major industries intact.
The very success of this arbitrage sea change has accentuated the objections of those who see the digital transactions we all participate in not as matters of convenience—free services provided in exchange for viewing a few targeted ads, for example—but as the radical evisceration of individual privacy and autonomy for the sake of new collective, algorithmically engineered systems of value. Perhaps the single greatest example of this ideological reaction is the rapid popularization of a new cryptocurrency called Bitcoin.
Bitcoin first emerged as a paper published in November 2008 by the apparently fictional mathematician Satoshi Nakamoto (about ten years after Schwartz predicted e-cash would become mainstream). In the paper Nakamoto argued for a new financial model that would eliminate the key vulnerability of traditional financial systems: “an electronic payment system based on cryptographic proof instead of trust, allowing any two willing parties to transact directly with each other without the need for a trusted third party.”24 The straightforward paper describes a system for exchanging currency based purely on computing power and mathematics (which I describe in more detail below), with no dependence on a central bank, a formal issuing authority, or other “faith and credit” standards of traditional currencies. If this book has been dominated by black boxes so far, Bitcoin purports to be a “glass box,” a tamper-proof system whose functions are entirely transparent. Like other open source platforms, it is founded on the logic that the best security comes from allowing anyone to inspect its code and suggest improvements.
Bitcoin has received significant attention as a libertarian, even anarchist response to the restrictions on trade and currency imposed by more established financial and political actors, and it’s gained notoriety as the currency of choice for all manner of criminal activity online. But the most compelling effect of Nakamoto’s paper is just beginning to emerge: a new model of algorithmic arbitrage that inverts the equation described above. This model takes advantage of the same brisk trade between public and private, between identity and community, between culture and commercial arbitrage, but it reverses the relationship between individual agency and the construction of value.
To make this case, let me start with an algorithmic reading of Bitcoin as both a computational platform and an ideology—a system based on the cryptographer’s assumption of total paranoia and distrust. Since any security system can be compromised, relying on any kind of third party or externally trusted entity to share information inevitably introduces vulnerability into a system. Depending on a bank to transfer funds requires engaging with the global financial network, a complex thicket of regulatory data-gathering requirements, human beings, and electronic media, any of which might be manipulated, compromised, or surveilled. Bitcoin responds to these challenges with two crucial algorithmic solutions, one well-established and the second radically innovative.
Bitcoin depends first of all on asymmetric encryption algorithms, which have become the overwhelming favorite for all digital security applications. These algorithms rely on “one-way functions”—calculations that are easy to perform but extremely difficult to reverse-engineer. A well-known example (the basis of the widely used RSA encryption algorithm): it’s easy to multiply two large prime numbers together into a giant number, but much harder to factor a giant number into two constituent primes. By relying on these effectively irreversible computational processes, Bitcoin provides its users a way to authenticate that its transactions are legitimate without knowing anything about the parties to those transactions themselves. In the prime number example, a “private key” would be made up of the two prime numbers and used to digitally sign the data that a user wishes to keep secure. Then a “public key” derived from the giant number (the product of the two primes, or more generally the output of the one-way computational function, whatever it is) could be used to verify that data by ensuring that the private key was indeed used to sign it.
Up to this point, Bitcoin would simply be another payment scheme that depended on some central authority to track public keys and defend against what is called the “double spending problem”—the risk that the money you have just received in payment might also have been spent somewhere else, analogous to a sort of digital counterfeiting. But Bitcoin’s second innovation is where we discover a new form of computational arbitrage, in the consensus-driven mechanism of the blockchain.
The blockchain is the public ledger of all Bitcoin transactions in the history of the currency. It contains a detailed accounting of every transaction since the currency’s instantiation, a digital file that now exceeds 20 gigabytes in size and must be downloaded locally by every Bitcoin software client. The blockchain is the algorithm that implements the political critique of Bitcoin, a marvel of arbitrage that inverts the traditional relationship between privacy and transparency. Every transaction, every incremental unit of Bitcoin value, is traced through the blockchain, and each of those transactions is tied to one or more buyer and seller identities. The identities are simply alphanumeric strings derived from the public keys of an asymmetric encryption protocol, the Elliptic Curve Digital Signature Algorithm. The transactions annotate the movement of some quantity of Bitcoin from one identity to another. Through the blockchain, which is constantly updated and authenticated by the Bitcoin community (as I’ll discuss below), it’s possible to trace each unit of currency back to an origination point, through every single transaction it’s ever been part of. The entire Bitcoin marketplace is an open book, from the darkest recesses of terrorism financing to booking hotel rooms, purchasing virtual goods from Zynga, and ordering marijuana from the infamous digital marketplace Silk Road.25
But how does this actually work? Since the Bitcoin network has no central authority, anyone completing a transaction announces it through a peer-to-peer network. The decentralized nature of the system is meant to account for the problem that information may flow unevenly across the network, that some nodes may suddenly appear or disappear, and for the intentional design constraint of abolishing the central bank or switching station to correlate and sequence all financial activity.
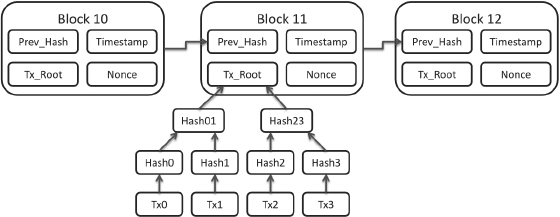
These different transaction announcements are bundled up into transaction blocks by Bitcoin “miners,” who then compete to assemble and validate these transactions against the extant communal history of the currency. The outcome of that labor is a new block for the blockchain. To do this, they must solve an arbitrary and highly complex math problem. The miner who is the first to correctly solve the problem “wins” that block. And there is a reward: the first transaction in each new block is a “generation transaction,” that creates a quantity of new Bitcoins (the number gradually decreases over time). The miner who solves the block earns this reward for throwing the most computational resources at assembling the latest block for the blockchain (figure 5.1). The miner also accepts a secondary reward by claiming a small transaction fee for processing these various trades (this fee gradually increases over time). Other nodes in the network then accept this newly minted tail for the blockchain and turn to assembling new transactions into a new block. The Bitcoin software is carefully calibrated so that the community generates a new block approximately every ten minutes (just like Nakamoto’s paper suggests), and the overall production of Bitcoin is itself carefully orchestrated. The system will gradually taper the reward for completing new blocks to zero, thereby ceasing the creation of new Bitcoins entirely, once 21 million Bitcoins have been created.26 At that point, transaction fees alone will provide the incentive for Bitcoin users to dedicate their computers to endlessly updating the blockchain.
Figure 5.1 The blockchain, a system for transparent, public accounting of Bitcoin transactions.
I am dwelling on the details of this elaborate process for delivering financial consensus because Bitcoin is not simply a decentralized currency but a revaluation of commerce in algorithmic terms. Bitcoin’s true radicalism stems from the fact that the blockchain grounds its authority on collective computation as an intrinsic form of value. To understand this shift we need to consider Bitcoin in the context of the historical value propositions of capitalism. As Karl Marx famously argued, industrial capitalism is based on a powerful mode of abstraction, one that separates individuals from the profits of their labor, creating a form of alienation that abstracts the work of individuals into fungible goods and services. Everything becomes commoditized, and the abstraction of exchange-value comes to obscure all other measures of worth. Exchange-value in many ways is capitalism: the symbolic ledger embodied by the stock exchange and the market economy. If that ledger gets usurped by the blockchain, we are not simply introducing a new currency into those markets: we are creating a new ledger, a new way of valuing goods, services, and activities.
Many people perceive Bitcoin’s disruptive force to derive merely from decentralization. It does, indeed, replace the fiat currency of the state with a new fiat currency, one backed by no gold standard, no guaranteed redemption policy or intrinsic utility (burning Bitcoins won’t keep you warm, though mining them does tend to generate a lot of heat from the processors involved).27 This is by no means novel: mercantile cultures have used mutually accepted measures of value (arrowheads, seashells) for millennia without centralized authorities, often using markers or objects that are effectively valueless on their own—and replacing one such system for another when necessary. These systems depended on implicit trust in a trading community: if I accept this money in payment today, I will be able to spend it elsewhere tomorrow. Money is a symbol that we collectively infuse with belief, a technology for transmitting value through culture that depends on a layer of abstraction. The coins, pieces of paper, or cowrie shells may not have much intrinsic value as physical objects, but they are markers of a symbolic system that financial writer and activist Brett Scott described as analogous to the machine code of capitalism—a foundational abstraction so far removed from the baklava layers of bonds, boutique high-frequency securities trades, and credit default swaps as to be unquestioned and invisible.28 Money works because we all believe in it at the same time, even though history is rife with incidents of hyperinflation, financial collapse, and gross corruption where that faith can vanish overnight.
State currencies and central banks added a second layer of trust and directed management to the equation, backing the value of a coin or note with the authority of the state, what in the United States is sometimes called the “full faith and credit” of the federal government.29 Currencies could be supported intrinsically, like Isaac Newton weighing and tracking the precious metals in each British coin, or extrinsically, like a government maintaining a reserve of gold bullion to anchor the value of its paper currency. A state and its central bank might control the introduction of new specie into circulation, manipulate exchange rates, mandate fixed prices for commodities, or simply change its value by fiat (as North Korea did in 2009 by introducing a new currency overnight). In these instances, currency no longer depends solely on the community of belief supporting circulation, but also on a second intersecting community based on the power and asserted wisdom of the state.
Yet trust is exactly what Bitcoin has positioned itself against. On a human level users still transact with Bitcoin because of their faith in a community (that is, faith that they will be able to sell their Bitcoins to someone else), but the system itself is founded on a very different principle. Where normal financial transactions are ultimately backed by state actors (in the United States, for example, through institutions like the Federal Reserve and the Federal Deposit Insurance Corporation), Bitcoin’s ultimate foundational principle is computation and Nakamoto’s trust-free vision for exchange. Instead of Treasury notes or stockpiled bullion, we get the blockchain. The blockchain relies on a computational fiat by rewarding the miners who bring the most computational power to bear on calculating each new block. The system depends on solving “proof-of-work” problems that are essentially meaningless but that serve as a public competition, creating a form of value dependent on the expenditure of computer cycles in the service of the Bitcoin network. The central abstraction of capitalism has itself been abstracted into computation: an upgrade to the machine code that introduces a new foundational layer of value.
This phase change is most visible in the system’s dependence on a kind of algorithmic democracy or force majeure, depending on one’s perspective. The rules of the blockchain award “truth” status to the miner who is the first to solve each new proof-of-work problem, and that solution is then accepted as the new public record for the system as a whole. As Nakamoto’s paper argues, “As long as a majority of CPU power is controlled by nodes that are not cooperating to attack the network, they’ll generate the longest chain and outpace attackers.”30 This modifies the value proposition above: value is abstracted not merely to computational power, but to concentrated computational power—either used for the benefit of the Bitcoin community to outpace attackers, or used by attackers to overpower the platform. Whoever can solve the meaningless math problem first serves as the next authenticator of the whole system’s legitimacy.
Nakamoto’s system depends for stability on a persistent democratic majority. As a classic open source platform, Bitcoin’s active community of developers improve the code but also support the project through a kind of collective fan engagement, a mutual reinforcement of the project’s ideology through dedicated computation. The addition of each new block to the chain is the crucial intellectual fulcrum for the entire system, and it depends on the race for a proof-of-work solution to be won by one of the “good guys,” a system that is not trying to fraudulently alter the official record of transactions. To make this work, most Bitcoin miners pool their computational resources, dividing up the proof-of-work problem across thousands of different machines to increase their speed of computation and thereby improve their chance of “winning” a block. Indeed, even this parliamentary model of financial authentication runs risks: if any of these mining collectives grows too large, taking over more than 50 percent of the overall computational pool tackling the blockchain problem, they will become a majority faction with the power to alter the transaction record at will. Bitcoin only survives through a federated balance of computational power.
Bitcoin’s notionally trust-free system ends up demanding two different kinds of trust: first, faith in the algorithm itself, especially in its transparent underpinnings in the blockchain. And second, Bitcoin encourages participants to band together into computing collectives, creating a shared community around the arbitrary calculation of proof-of-work solutions. In many ways, this is remarkably similar to the trust-free world of HFT traders that Lewis describes in Flash Boys. A vibrant algorithmic ecology depends on a community of goodwill to compete according to established rules (however cutthroat they may be) and discourage any changes to those rules. HFT companies may find ways to execute trades more and more quickly, but it is in nobody’s interest to slow markets down or change the ground rules of transactions (for instance, by requiring a buyer to hold a stock for at least twenty-four hours before selling it).
The similarity arises because Bitcoin, despite its pretensions to democracy, is fundamentally a technologically elite system that inserts computational value into the capitalistic foundations of currency. Much like a traditional currency, Bitcoin is only as strong as its strongest proponent (in this case not a state, but the largest mining collectives). But the core value defining strength is now a very specific resource: computational power, silicon, electricity. While the game is open to anyone, the only players who can truly influence the outcome are those who band together in sophisticated mining collectives (which in turn requires trusting the collective to share the rewards fairly). The everyday users of Bitcoin have little idea how transactions are calculated or how this balance of power can affect their own investments and transactions.
Finally, the programmed currency that is Bitcoin also creates important externalities as it abstracts financial worth into computational value. As Edward Castronova argues, if significant numbers of people started using virtual currencies without the backing of traditional sovereign states, it could create “a general dynamic state of decline” where those still using dollars would have to take on ever-increasing tax obligations to support the infrastructure of the state.31 That, at heart, is what the dollar values: the global superpower of the United States of America with all its military might, its roads, its social programs, its prisons and pensions. Replacing that with Bitcoin would effectively create a tax system supporting an ever-expanding network of computational cycles dedicated to mining the next block in the chain.
Programmable Culture
Bitcoin’s recent mainstream success, from Overstock and Amazon to a variety of hotels, travel sites, and smaller businesses, indicates that its logic of computational value is catching on, particularly with other algorithmically driven businesses. As Stanford entrepreneur Balaji Srinivasan argues: “If the Internet was programmable communication, Bitcoin is programmable money.”32 It is not so much a new unit of exchange as a new platform for financial computation. More profoundly, it is an ideology for making computation the universal solvent, the universal metric of value, extending the digitization of commerce Wired imagined to its logical conclusion. Like Google’s PageRank algorithm, Bitcoin defines value through particular, temporally constrained processes that implement forms of algorithmic arbitrage. Bitcoin’s proof of work creates an inversion mechanism between public and private that precisely reverses what PageRank does. For Bitcoin the network of links, the intricate architecture of financial transactions, is public record, while the significance of that network is obscured: it’s easy to trace the history of every Bitcoin, to identify it block by block, but extremely difficult to find out what that unit of exchange was used to purchase. PageRank does the opposite, assembling a carefully guarded, secret map of the network that is then interpreted into meaningful answers for users. That mirrored relationship hints at a broader set of changes that seem to be emerging as we incorporate algorithms more deeply into central machinery of human culture.
In this context, we can read Bitcoin not just as an implementation of the ideology of “programmable money,” but as an allegory for the sea change toward what we might call programmable culture. The central tenets of Bitcoin’s system for creating value epitomize similar shifts in all corners of cultural production, where daily business seems the same but the majority votes, central authorities, and validation structures are being subsumed by algorithmic processes. From HFT to Google Search, we see intrinsic value being transmuted into a kind of network value that rewards context, access, and interlinking. In parallel, the quest for knowledge is subservient to the quest for methods, for better technical systems. Our growing path dependency on the black boxes at Facebook, Google, Apple, and other tech companies pushes a huge range of cultural fields to produce work optimized for those systems, creating the belletristic equivalent of monoculture crops that have limited resilience to major changes in the ecosystem.
Consider journalism. The recently dethroned founder of the Gawker Media blogging empire, Nick Denton, wrote candidly in 2015 about missteps at his company: “We—the freest journalists on the planet—were slaves to the Facebook algorithm.”33 Denton was arguing that his company had lost sight of its central mission to break compelling news stories, growing obsessed with the algorithmic game of attracting traffic and attention instead. That problem has only gotten more serious now that media companies like the New York Times are allowing Facebook to host their copy directly, keeping users even more entrenched in a stream of content that Facebook’s algorithms control. As technology journalist Adrienne LaFrance argued in The Atlantic, “Facebook is America’s news editor,” driving a huge and growing percentage of the traffic to news sites.34
In 2016 it emerged that even as Denton was lamenting the impact of Facebook on his journalists, the social network had hired its own cadre of young journalists to select stories for promotion through “Trending Topics,” a prominent widget for drawing user attention to top stories of the day. These contract workers were relegated to an unused conference room and asked to perform a kind of algorithmic judgment, selecting stories according to a carefully defined set of instructions laid out in a memo titled “Trending Review Guidelines.”35 Both the algorithm-like instructions and the humans enacting them were accused of introducing liberal bias into Trending Topics, and Facebook has since announced plans to completely overhaul how Trending Topics functions. The revelation underscores the now-familiar idea of humans hiding within a supposedly algorithmic black box, but it also reveals how solipsistic our cultural systems have become. The Facebook memo instructed contractors to track just ten news sites, including CNN, the BBC, Fox News, and the Guardian, in evaluating whether a story merits “national” importance. Meanwhile, editors at all of those places closely monitored Facebook (which, remember, is not a news organization) to see what news was getting traction with the digital public. News directors trying to decipher the Trending Topics algorithm were really peering into an editorial funhouse mirror.36 Later in 2016, yet another illustration of programmable culture and new ground rules for value erupted into the headlines when PayPal co-founder Peter Thiel drove Gawker Media into bankruptcy by supporting a third-party lawsuit. Thiel argued this was “less about revenge and more about specific deterrence”—and his correct interpretation that as an algorithmic billionaire he had the power to censor a news organization whose salacious coverage he despised.37
The sea change in what counts does not stop with Wall Street or the news. The stakes of cultural success are increasingly driven by algorithmic metrics. In Hollywood special effects studios, at campaign offices, police headquarters, and in countless other nodes of power, the players who can best leverage concentrated computation to a set of abstracted problems win the prize. For Bitcoin this means adding a new block to the blockchain; for other fields it can be contributions to other relatively transparent, publicly accessible contests—blockbuster films, elections, hit musical singles—but the algorithmic arbitrage used to get there depends on similar forms of data-driven abstraction, black box analysis, and intensive processing.
Computationalism makes cultural practices not just computational but programmable—susceptible to centralized editing and revision. Perhaps this is the inevitable consequence of our gradual shift from an Internet organized according to the ad hoc “cool site of the day” model to one with stable hierarchies and revenue streams. As the systems for disseminating and filtering content become more elaborate, more complex, the tools necessary for producing content have become more automated as well. Bloggers for companies like Gawker Media churn out short articles that are often driven by search engine traffic and web analytics software, with bonuses for pieces that gain rapid traction. Because of the changing nature of social media and the broader Internet, they are writing first for the algorithms that will choose whether or not to disseminate their work on sites like Facebook, and only second for the readers who will then read and share it with others.
Denton’s lament serves as an example of how cultural values like the function of journalistic free enterprise can be gradually altered by revising the algorithmic platforms that distribute content and measure success. Under the regime of process, the production of value comes from iteration: the persistent output of short, topical blog posts is far more important than the content of any one of those posts. The application of algorithms to data trumps the data itself; the navigation, synthesis, and manipulation of information becomes more important than simply accessing it. The Bitcoin protocol elegantly encodes this principle in the notion of mining, explicitly linking the computational work of authenticating transactions with the production of new currency. Indeed, performing this public computational process is the only way to create more Bitcoins, making the process of computation equivalent to the alchemical magic of a government mint turning pieces of paper into specie. The mythological equivalent of a Fort Knox-style mountain of gold “backing” the dollar is the mountain of servers dedicated to churning through the blockchain.
In the context of bloggers writing ten or twelve posts a day for companies like Gawker Media, the methods for mining value are different but the governing abstraction remains the same. The online ad revenue systems these bloggers interact with create another kind of processing or “proof of work,” the content itself. A blogger writes a new post that then gets circulated by Facebook algorithms and users, generating ad revenue for Facebook, for Gawker Media, and sometimes a narrow slice of that pie for the blogger. The process monetizes eyeballs and human attention, not ideas. Those who can consistently produce a high volume of clickable material are rewarded most greatly. This is how the process of blogging becomes much more important than the content of the posts, and how writers can become slaves to the algorithms that determine what virality, shareability, and human interest really mean.
The migration of value from end result to process marks the culmination of a long evolution that began with what Jürgen Habermas famously called the bourgeois public sphere. Habermas argued that the emergence of a propertied middle class in the eighteenth century (parallel to the rise of the Encyclopédie) created a new space for disinterested public discourse founded on the truth values of the private, intimate sphere of bourgeois life. Men could gather in coffeehouses to read newspapers and discuss the events of the day, practicing civic engagement anchored in their collective investment in the emerging system of modern capitalism. As men of property, citizens, and readers, they could ignore status and personal interest in the protected space of the public sphere for the sake of a vibrant, critically energetic conversation. The public sphere emerged in codependence with a free press and a stable political space for discussion, allowing for the shared understanding and evaluation of what Habermas called areas of “common concern.”38
The intimate connection between capitalism and the public sphere provides a useful contrast to the accelerating evolution of journalism in the era of programmable culture. Habermas’s idealized public sphere is part of what Gawker Media and Denton find to have disappeared beneath their feet. Investigative journalism and the independent press serve as the cultural scaffolding for the kind of civic community that Habermas idealizes, providing the ideas and opinions that reflect and advance the shared values of the reading public. While the methods of analysis might evolve, the data itself in this public sphere was dependable, hard-coded: a system of truth beliefs rooted in state and religious institutions, in capitalism and coffee shops. The public sphere was a contentious idea from the beginning because it painted a rosy picture about who got to participate in this bourgeois Enlightenment and what they got to talk about. But even accepting its flaws, the notion of a modern-day agora for societal discussion and debate has remained critically compelling, particularly as the Internet seems to promise new forms of public engagement that mirror the key features of Habermas’s historical interpretation. Social media, anonymous forums, and even Wikipedia seem at times to rival the first public offices of the Enlightenment, creating a space for disinterested, critical public speech.
Denton’s fall is a cautionary tale illustrating how that scaffolding for disinterested public discourse is turning into a very different sort of structure. In the era of programmable culture, publicity and the ethics of discourse can be as fungible as Bitcoin, fundamentally changing the social contract on which the public sphere depends. What rules do bloggers follow about protecting sources, or acknowledging conflicts of interest? On Facebook, the ombudspeople of the New York Times and the Washington Post disappear behind the opaque gatekeeping of algorithms. Thiel argues that his grudge against Gawker originated in their abuse of the mantle of journalism to bully and humiliate individuals. For him, the ethics of property ownership and a privacy derived from that ownership trumped any notion of a public sphere.
Programmable culture turns the public sphere inside out: the cultural data that used to make up the arena of “common concern” is increasingly privatized. The private life of the average citizen becomes public, commercially accessible to data brokers, social media companies, and others who trade access to the newly privatized sphere of online community (through sites like Facebook and Twitter) in exchange for commercial access to users’ private lives. Members of the algorithmic elite retreat from public view, some of them echoing Thiel’s libertarian sentiment: “I no longer believe that freedom and democracy are compatible.”39 Finance was the most private of registers in bourgeois capitalism, but Bitcoin turns it into a public sphere for money. By placing financial transactions into the glass box, the creators of Bitcoin invert the public sphere’s model of scrutiny, allowing public inspection of commercial exchange but keeping cultural positions and identities private. Consensus gathers around financial transactions rather than critical judgments, and money becomes, to extend the logic of the U.S. Supreme Court in Citizens United, the only real form of political speech.
At its dystopian extreme, this new financial public sphere makes bank accounts into citizens: SuperPACs and venture capitalists have the important conversations about events of the day, joined by those individuals wealthy enough to speak and be heard: not just Thiel but Warren Buffett, Bill Gates, and Jeff Bezos, for example. On a more positive note, we can see the public sphere of cash transforming the arts through fundraising sites like Kickstarter and Indiegogo, which allow for the collective approval of new projects through crowdfunding, or a kind of financial voting. The algorithmic process of crowdfunding rewards those who master the methods of privatized publicity: a strong introductory video, frequent updates, tiered reward structures, and effective use of social media to raise awareness.
Read in this light, Denton’s post is a diatribe against the seductions of the public sphere of money as it undermines the public sphere of journalism. When bloggers and reporters are given audience metrics and goals, they are grappling with a new model of public attention denominated in dollars, but really measured in CPU cycles, links, hovers, and clicks. The old journalistic enterprise had interposed a set of Enlightenment abstractions—the notion of the fourth estate, a free and independent press serving the public good—between the business of selling newspapers and the marketplace for ideas. The valuation of process in the age of algorithms deletes those mediating layers, allowing writers and editors to see the market response to their work in real time. Direct engagement with that feedback loop can lead to changing headlines and angles for stories, pursuing new topics entirely, and continually adapting to the normative effects of social media algorithms (and, in Gawker’s case, to Chapter 11 bankruptcy).
Habermas was quick to point out that the bourgeois public sphere faded away with the rise of mass media and modern advertising, but the ideal vision of disinterested public discourse persists in the aspirations of journalists, social entrepreneurs, Wikipedians, and many others who see the Internet as a new platform for collective engagement around “common concerns.” The shift to processual value has also shifted the epistemological floor beneath our feet. Despite Thiel’s classically capitalistic intervention in the Gawker lawsuit, it is clear that shared, objective truths grounded in capitalism, personal property, and ultimately the Enlightenment itself have given way to a new objectivity founded on fungible data and processual truths—what we might cynically call culture as a service. As we invest more of our lives, our public and private conversations, our faith and beliefs, in algorithmic culture machines, we invest in the idea that truth resides in analytics, abstraction, and data-mining.
Mining Value
The valorization of data processing has provocative implications for cultural production. As cultural consumers, we now evaluate the meaning of text through its connections more than its substance. The critic is no longer celebrated primarily for narrowing the field, eliminating bad links, and performing an exclusive model of intellectual taste. Figures like Pauline Kael or Harold Bloom who built their careers telling us what to ignore as much as what to celebrate are being replaced by curators who provide an ongoing service (or process) of inclusive, networked culture. The inspired curation of Maria Popova’s Brain Pickings, for example, offers a wide-ranging, serial feast of intellectual pleasures. Its status as a persistent stream of content, one that Popova “obsessively” maintains, makes the stream more valuable than the individual works she cites.40 The performance of her creative process, the complex human-computational culture machine that is Brain Pickings, becomes the object of interest for her readers. She is, in her own way, mining value in a particular kind of aesthetic arbitrage that we often call curation. She assembles these pieces in a way that captures attention, that transmutes disparate elements into a compelling new experience. Great bloggers do the same, gleaning nuggets of content for sites that are celebrated primarily for their consistent, timely production of a media stream.
In other words, the same processual logic of value that drives Bitcoin is remaking other cultural forms as well. We are learning from, or being influenced by, algorithms and computational systems that elevate process to the status of value. We are slowly replacing the very human codex model of linear attention with an eternal abundance of culture, a Netflix-like smorgasbord that integrates multiple media, paratexts, and intellectual frameworks—a cloud of ideas rather than a stream of consciousness. Curating these clouds requires human beings like Popova to work gracefully with hybrid algorithmic machines consisting of computational memory, networks of human contributors and readers, and various collaborative platforms. But just as the major fields of cultural production are adapting to the logic of processual value, we, the audience of these products, are also changing our values along with our habits as consumers of their work.
Consider the many forms of cultural information we now casually expect to find in our pocket computers: instant comparative sales rankings of every imaginable consumer good, plus popular reviews thereof; frank, public discussions of every conceivable medical topic, childrearing problem, or addiction protocol; quirky and subjective reviews of every eatery, coffee shop, and museum in the known world. None of this information was available in such persistent abundance (or, often, in even limited form) through the traditional, highly normative avenues of cultural production as French sociologist Pierre Bourdieu mapped them in the pre-algorithmic era.41 It was almost all private knowledge, deliberately shielded from the Habermasian public sphere before the great inversion. For much of the twentieth century, if a woman wanted to research birth control options and side-effects, or a man wanted to read narratives about coming out as gay, there was no search engine, no public, sanctioned source of information at all. A homeowner who wanted to replace a shower faucet stem valve or a hobbyist researching a new kind of modeling paint would have few resources at their disposal beyond local community groups, stores, and, for some questions, libraries. Before the Internet, these were private concerns, not common concerns.
This transformation is so profound, so obvious, that is has become invisible even to those of us who have lived through its recent phases. The structures that constitute the deep fabric of the web collect and store human attention, intimacy, memories, and all our other digital traces. To make use of this abundance, they all leverage algorithmic arbitrage systems like PageRank, funneling us toward the particular forum, the very specific article, that addresses some particular need. For many of us, every single question about our lives starts with a query to a search engine or another algorithmic database, and this new legibility changes our relationship to reality in a deep, epistemological way. Comforted in the knowledge that we can always Google it later, we have gradually accepted that the arbitrage of information is more significant than the information itself. The gloss and the comment have overtaken the article and the book so completely that author Karl Taro Greenfield wrote in the New York Times about our collective tendency to fake cultural literacy on the basis of paratext and metadata:
It’s never been so easy to pretend to know so much without actually knowing anything. We pick topical, relevant bits from Facebook, Twitter or emailed news alerts, and then regurgitate them. … What matters to us, awash in petabytes of data, is not necessarily having actually consumed this content firsthand but simply knowing that it exists—and having a position on it, being able to engage in the chatter about it.42
Like the HFT traders, like Google’s PageRank, like Bitcoin, we no longer care about the details of our information packets so long as we can effectively arbitrage them, transferring the data to our advantage before it loses cachet. The spectacle of cultural consumption, the public act of processing, judging, and sharing, is the new cultural economy.
Reading the system has become more important than reading the content the system was built to deliver. At their most intense, these architectures of attention create their own persistent streams of belief, a kind of cultural value blockchain. Sites like Wikipedia and even public conversations on social media offer a detailed transaction stream allowing participants to check a thread of debate against a history of contributions (with the notable exception that almost all of these platforms, aside from Wikipedia, allow the invisible removal of these traces). Like Bitcoin, the public ledger of attention is completely transparent, but the human and algorithmic computation involved in generating it is obscured. The motivations of Wikipedia contributors or Facebook commenters can be difficult to discern, but the platform itself presents an appearance of flat, democratic accessibility.43
The seduction of this public processing, the blockchain-like generation of cultural discourse, lies precisely in its visibility, its thrilling transparency. Cultural processing (whether of Bitcoin transactions, Facebook likes, click-driven political activism, or Wikipedia updates) becomes its own spectacle, distracting us from the invisible sides of the system, like a magic trick performed in a glass box. The seduction is all the more powerful because of the truth behind it: Bitcoin, Wikipedia, and even the social media newsfeeds have some utopian legitimacy. They do really have the potential to route around traditional, occasionally despotic structures for controlling information, from the Arab Spring to the rapid assembly of detailed, objective encyclopedia entries on major terrorist attacks. The spectacle is collaborative, transformative, live. The spectacle promises to make the whole world legible and mutable through the sheer ubiquity of computation. Programmable culture promises democracy, accountability, and clarity at the tap of an icon.
But of course the algorithmic notion of mining for value depends on an arbitrary grammar of action.44 The proof of work imposed by Bitcoin on its mining collectives has its analogs in other systems as well, like bloggers optimizing their stories for Facebook algorithms. And while these forms of cultural and computational labor are often arbitrary by human standards—make-work designed to filter out the messy fringes of the system—they serve important needs in normalizing otherwise haphazard communities around set algorithmic objectives. Bitcoin miners unite around their CPU cycles, propelling the system forward with a set of computational cartels that are both transparent and occult. The ritualistic use of “like” and “friend” buttons are Facebook’s proof of work, encouraging us to engage to make our contributions count … and beneath this grammar lies the platform’s second language of advertisements and commercialized user data. For PageRank, the proof of work is the most compelling: the construction of the links and references that define the Internet itself. The ultimate seductive power in each of these systems lies in the reinforcing feedback loop of refactoring and extending the chain through our own contributions. In the early 1990s, information scholar Philip Agre predicted many of the consequences of this kind of programmability, which he called information capture:
The practice of formulating these ontologies is, all disciplinary insularity aside, and regardless of anyone’s conscious understandings of the process, a form of social theorization. And this theorizing is not simply a scholastic exercise but is part of a much larger material process through which these new social ontologies, in a certain specific sense, become real.45
Our participation wears grooves deeper into the system and continually trains us in the fine arts of process-driven valuation.
Replacing the public sphere with the programmable sphere is ultimately a substitution of one form of reading for another: a new idiomatic frame to put on the world. Leaving behind the readers of the Spectator in an eighteenth-century London coffeehouse, we find the readers of algorithmic process, interpreting Twitter feeds and web traffic counts over Wi-Fi at Starbucks. The grammar of the new algorithmic sphere obscures certain operations while making others more visible, and the spectacle of the blockchain is merely one of the newer ways that we have invested these cultural systems with enormous power. We are all becoming more adept at the practice of critical arbitrage because our systems, the flooded streams of cultural data, require it. The interplay of glass boxes and black boxes demands an algorithmic attention to data processes, an algorithmic reading that we are all practicing already.