Chapter 14
Modeling Counts and Correlated Data
While inexact models may mislead, attempting to allow for every contingency a priori is impractical. Thus models must be built by an iterative feedback process in which an initial parsimonious model may be modified when diagnostic checks applied to residuals indicate the need.
—G. E. P. Box
TODAY, STATISTICAL SOFTWARE INCORPORATES ADVANCED ALGORITHMS FOR THE analysis of generalized linear models (GLMs)1 and extensions to panel data settings, including fixed-, random-, and mixed-effects models, logistic, Poisson, and negative-binomial regression, generalized estimating equation models (GEEs), and hierarichical linear models (HLMs). These models take the form
where the nature of the relationship between the outcome variable and the coefficients depend on the specified link function g() of the GLM, β is a vector of to-be-determined coefficients, X is a matrix of explanatory variables, and ε is a vector of identically distributed random variables. These variables may follow the normal, gamma, Poisson, or some other distribution depending on the specified variance function of the GLM.
In this chapter, we consider first the use of GLMs to model counts, then survival data, finish by reviewing popular approaches for modeling correlated data, and discuss model properties, assumptions, and relative strengths. We discuss the efficiency gained through correct specification of correlation and the use of alternative standard errors for regression parameters for more robust inference.
Poisson regression is appropriate when the dependent variable is a count, as is the case with the arrival of individuals in an emergency room. It is also applicable to the spatial distributions of tornadoes and of clusters of galaxies.2 To be applicable, the events underlying the outcomes must be independent in the sense that the occurrence of one event will not make the occurrence of a second event in a nonoverlapping interval of time or space any more or less likely. This model takes the loglinear form 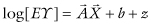 .
.
The outcome follows the Poisson distribution, not the normal, and the link function relating the outcome to the linear combination of coefficients and predictors is the logarithm.
Small errors in measurement can result in a substantial bias of the coefficients in the matrix 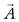 , Häggström [2006].
, Häggström [2006].
A strong assumption of the Poisson regression model is that the mean and variance are equal (equidispersion). When the variance of a sample exceeds the mean, the data are said to be overdispersed. Fitting the Poisson model to overdispersed data can lead to misinterpretation of coefficients due to poor estimates of standard errors.
Naturally occurring count data are often overdispersed due to correlated errors in time or space, or other forms of nonindependence of the observations. One solution is to fit a Poisson model as if the data satisfy the assumptions, but adjust the model-based standard errors usually employed. Another solution is to estimate a negative binomial model, which allows for scalar overdispersion.
Suppose your firm plans to bid on a contract. You hope your firm’s bid will be lower than that submitted by other firms, yet high enough to provide your firm a substantial profit if you win, a simple model of the Bernoulli outcome of success is logit[p] = log[p/(1 − p)] = μ + α$ + z, where p is the probability of success and $ represents the dollar value of the bid.
More commonly , the logistic model (which employs the logit function) is used for prediction purposes when the outcome is a binomial variable. Will the patient improve or get worse? In evaluating predictors for inclusion in the model, one begins with a univariate analysis on a variable-by-variable basis. (Of course, only variables that might have a potential cause- and effect-relationship with the outcome should be considered.) For categorical, and ordinal variables, Hosmer and Lemeshow [2001] recommend this be done via a 2 × k contingency table employing a likelihood ratio chi-square test. If there are cells with zero values, do one of the following:
When making use of all the remaining predictors in the model, avoid overmatching as in the example of the leukemia study described under the heading “Case Control Studies” in Chapter 6.
The caveats of previous chapters also apply to the specification of the link and variance functions of GLMs. The pair of functions that define a specific model should be determined on the basis of cause-and-effect relationships and not by inspecting the data.
For example, when deciding among a Poisson, negative binomial, or binomial model for counts, the wrong approach to model specification is to make function choices based on the ratio of the mean to the variance of the sample. As Bruce Tabor notes in a personal communication,
In a contagious process, such as an infectious disease outbreak, the probability of a subsequent event will increase after the occurrence of a preceding event. A person carrying an infection is likely to infect additional persons. This results in positive correlation between events and overdispersion. A negative binomial model has this property and may provide a suitable model (or may not, as the case may be).
In a count process with negative contagion (underdispersion), the occurrence of an event makes subsequent events less likely—events are negatively correlated. One example might be house burglaries in a neighborhood. After an initial burglary, residents and police are alerted to subsequent burglaries and thieves respond appropriately, targeting other neighbourhoods for a while.
The other common sources of error in applying generalized linear models are the use of an inappropriate or erroneous link function, the wrong choice of scale for an explanatory variable (for example, using x rather than log[x] ), neglecting important variables, and the use of an inappropriate error distribution when computing confidence intervals and p-values. Firth [1991; pp. 74–77] should be consulted for a more detailed analysis of potential problems.
When multiple observations are collected for each principal sampling unit, we refer to the collected information as panel data, correlated data, or repeated measures. For example, we may collect information on the likelihood that banks offer certain types of loans. If we collect that information from the same set of banks in multiple instances over time, we should expect that observations from the same bank might be correlated.
The dependency of observations violates one of the tenets of regression analysis: that observations are supposed to be independent and identically distributed or IID. Several concerns arise when observations are not independent. First, the effective number of observations (that is, the effective amount of information) is less than the physical number of observations since, by definition, groups of observations represent the same information. Second, any model that fails to specifically address correlation is incorrect, which means that statistics and tests based on likelihood are based on a faulty specification. Third, although the correct specification of the correlation will yield the most efficient estimator, that specification is not the only one to yield a consistent estimator.
Most textbooks introduce fixed- and random-effects ANOVA models through a series of examples. Cases are presented wherein multiple observations are collected for each farm animal, or multiple observations are collected for each farm. The basic issue in deciding whether to utilize a fixed- or random-effects model is whether the sampling units (for which multiple observations are collected) represent the collection of most or all of the entities for which inference will be drawn. If so, the fixed-effects estimator is to be preferred. On the other hand, if those same sampling units represent a random sample from a larger population for which we wish to make inferences, then the random-effects estimator is more appropriate.
Fixed- and random-effects models address unobserved heterogeneity. The random-effects model assumes that the panel-level effects are randomly distributed. The fixed-effects model assumes a constant disturbance that is a special case of the random-effects model. If the random-effects assumption is correct, then the random-effects estimator is more efficient than the fixed-effects estimator. If the random-effects assumption does not hold (that is, if we specify the wrong distribution for the random-effects), then the random effects model is not consistent. To help decide whether the fixed- or random-effects models is more appropriate, use the Durbin–Wu–Hausman3 test comparing coefficients from each model.
The fixed-effects approach is sometimes referred to as the “assumption-free” method since there are no assumptions about the distribution of heterogeneity between the panels. In a meta-analysis combining results from different trials, we might analyze results assuming either fixed or random effects. However, the random-effects assumption may have no medical relevance. In particular, it may not be realistic to assume that the trials combined in our analysis represent some random sample from an underlying population of possible trials. Moreover, there could be selective factors that differ between trials as well as different therapeutic outcomes. Thus, whereas fixed-effects methods may actually be assumption-free, random-effects methods may assume representativeness that is unreasonable. It is often easier to justify application of fixed-effects methods; especially when we focus on the less stringent set of assumptions on which the methods depend.
Zeger and Liang [1986] describe a class of estimators that address correlated panel data. The user must specify both a generalized linear model specification valid for independent data and the correlation structure of the panel data.
Although fixed-effects estimators and random-effects estimators are referred to as subject-specific estimators, the GEEs available through PROC GENMOD in SAS or xtgee in Stata, are called population-averaged estimators. This label refers to the interpretation of the fitted regression coefficients. Subject-specific estimators are interpreted in terms of an effect for a given panel, whereas population-averaged estimators are interpreted in terms of an affect averaged over panels. When and whether to draw inference for average sampling units is considered in the next section.
The average human has one breast and one testicle.—Des McHale
A favorite example in comparing subject-specific and population-averaged estimators is to consider the difference in interpretation of regression coefficients for a binary outcome model on whether a child will exhibit symptoms of respiratory illness. The predictor of interest is whether or not the child’s mother smokes. Thus, we have repeated observations on children and their mothers. If we were to fit a subject-specific model, we would interpret the coefficient on smoking as the change in likelihood of respiratory illness as a result of the mother switching from not smoking to smoking.
On the other hand, the interpretation of the coefficient in a population-averaged model is the likelihood of respiratory illness for the average child with a nonsmoking mother compared to the likelihood for the average child with a smoking mother. Both models offer equally valid interpretations. The interpretation of interest should drive model selection; some studies ultimately will lead to fitting both types of models.
An approximate answer to the right question is worth a good deal more than the exact answer to an approximate problem.
—John W. Tukey
In addition to model-based variance estimators, fixed-effects models and GEEs also admit modified sandwich variance estimators. SAS calls this the empirical variance estimator. Stata refers to it as the Robust Cluster estimator. Whatever the name, the most desirable property of the variance estimator is that it yields inference for the regression coefficients that is robust to misspecification of the correlation structure.
GEEs require specification of the correlation structure, but the modified sandwich variance estimator (from which confidence intervals and test statistics are constructed) admits inference about the coefficients that is robust to misspecification of that correlation structure. Why then bother with a specification at all? The independence model is an attractive alternative to interpretation of regression coefficients within the more complicated dependence model. Why not then just assume that the observations are independent, but utilize this variance estimator in case the independence assumption is incorrect? This is not a recommended approach because the correct specification yields an estimator that is much more efficient than the estimator for an incorrect specification. This efficiency is an asymptotic property of the estimator dependent on the number of independent panels. Zeger and Liang [1986] demonstrate the advantages of correct specification of the correlation structures for GEEs.
Specification of GEEs should include careful consideration of reasonable correlation structure so that the resulting estimator is as efficient as possible. To protect against misspecification of the correlation structure, one should base inference on the modified sandwich variance estimator. This is the default estimator in SAS, but the user must specify it in Stata. Check your software documentation to ensure best practices.
This same variance estimator is available for the fixed-effects estimator, but not for the random-effects estimator.
An indicator variable for each panel/subject is added and used to fit the model. Though often applied to the analysis of repeated measures, this approach has bias that increases with the number of subjects. If data include a very large number of subjects, the associated bias of the results can make this a very poor model choice.
Conditional fixed effects are commonly applied in logistic regression, Poisson regression, and negative binomial regression. A sufficient statistic for the subject effect is used to derive a conditional likelihood such that the subject-level effect is removed from the estimation.
While conditioning out the subject-level effect in this manner is algebraically attractive, interpretation of model results must continue to be in terms of the conditional likelihood. This may be difficult and the analyst must be willing to alter the original scientific questions of interest to questions in terms of the conditional likelihood.
Questions always arise as to whether some function of the independent variable might be more appropriate to use than the independent variable itself. For example, suppose X = Z2, where E(Y|Z) satisfies the logistic equation; then E(Y|X) does not.
The choice of a distribution for the random effect is driven too often by the need to find an analytic solution to the problem rather than by any scientific foundation. If we assume a normally distributed random effect when the random effect is really Laplacian, we will obtain the same point estimates (since both distributions are symmetric with mean zero), but we will compute different standard errors. We will not have any way of comparing the assumed distributions short of fitting both models.
If the true random-effects distribution has a nonzero mean, then the misspecification is more troublesome as the point estimates of the fitted model are different from those that would be obtained from fitting the true model. Knowledge of the true random-effects distribution does not alter the interpretation of fitted model results. Instead, we are limited to discussing the relationship of the fitted parameters to those parameters we would obtain if we had access to the entire population of subjects and we fit that population to the same fitted model. In other words, even given the knowledge of the true random-effects distribution, we cannot easily compare fitted results to true parameters.
As discussed in Chapter 6 with respect to group-randomized trials, if the subjects are not independent (say, they all come from the same classroom) then the true random effect is actually larger. The attenuation of our fitted coefficient increases as a function of the number of supergroups containing our subjects as members; if classrooms are within-schools and there is within-school correlation, the attenuation is even greater.
Compared to fixed-effects models, random-effects models have the advantage of using up fewer degrees of freedom, but they have the disadvantage of requiring that the regressors be uncorrelated with the disturbances; this last requirement should be checked with the Durbin–Wu–Hausman test.
Instead of trying to derive the estimating equation for GLM with correlated observations from a likelihood argument, the within-subject correlation is introduced directly into the estimating equation of an independence model. The correlation parameters are then nuisance parameters and can be estimated separately. (See also Hardin and Hilbe, 2003.)
Underlying the population-averaged GEE is the assumption that one is able to specify the correct correlation structure. If one hypothesizes an exchangeable correlation and the true correlation is time dependent, the resulting regression coefficient estimator is inefficient. The naïve variance estimates of the regression coefficients will then produce incorrect confidence intervals. Analysts specify a correlation structure to gain efficiency in the estimation of the regression coefficients, but typically calculate the sandwich estimate of variance to protect against misspecification of the correlation. This variance estimator is more variable than the naïve variance estimator and many analysts do not pay adequate attention to the fact that the asymptotic properties depend on the number of subjects (not the total number of observations).
The HLM category includes hierarchical linear models, linear latent models, and others. While previous models are limited for the most part to a single effect, HLM allows more than one. Unfortunately, most commercially available software requires one to assume that each random effect is Gaussian with mean zero. The variance of each random effect must be estimated. As we cautioned in the section on random effects, the choice of distribution should be carefully investigated. Litière, Alonso, and Mohlenberghs [2008] discuss the impact of misspecifying the random-effect distributions on inferential procedures.
Mixed models allow both linear and nonlinear mixed-effects regression (with various links). They allow you to specify each level of repeated measures. Imagine these levels: districts, schools, teachers, classes, and students. In this description, each of the sublevels is within the previous level and we can hypothesize a fixed or random effect for each level. We also imagine that observations within the same levels (any of these specific levels) are correlated.
For more on the contrast between fixed-effect “assumption-free” methods, and random-effect “assumed-representativeness” methods, see Section 5.17 of http://www.ctsu.ox.ac.uk/reports/ebctcg-1990/section5.
See Hardin and Hilbe [2003, p. 28] for a more detailed explanation of specifying the correlation structure in population-averaged GEEs. See Zeger and Liang [1986] for detailed investigations of efficiency and consistency for misspecified correlation structures in population-averaged GEEs.
See McCullagh and Nelder [1989] and Hardin and Hilbe [2007] for the theory and application of GLMs. See Skrondal and Rabe-Hesketh [2004] for extensions of GLMs to include latent variables, and to structural equation models. For more information on longitudinal data analysis utilizing specific software, Stata users should see Rabe-Hesketh and Skrondal [2008] and SAS users should see Cody [2001].
Notes
1 As first defined by Nelder and Wedderburn [1972].
2 They do not have a log-normal distribution as reported by Saslaw [2008].
3 Durbin [1954], Wu [1973], and Hausman [1978] independently discuss this test.