Figure 11.1 File and Storage Services

Shared storage and clustering in Windows Server 2012 R2 deliver arguably the most significant functionality that any large enterprise or datacenter infrastructure design requires. Ensuring that resources such as applications, services, files, and folders are delivered in a highly available, centralized, and scalable offering should be paramount to every IT administrator and consultant. Utilizing shared storage and clustering gives organizations the ability to scale out storage on demand, create centralized locations for resources, and make them highly available (HA) to the business.
The concepts of shared storage and clustering aren’t new or exclusive to Windows Server 2012 R2, but gaining a clear understanding of each will allow you to confidently deploy the enhanced HA offerings that come out of the box with the operating system. In this chapter you will learn to:
In its most basic form, shared storage offers a central location inside an organization’s IT infrastructure to host a specific set of files or applications so that multiple users can have simultaneous access to them. Many different storage devices can be utilized for this technology, examples of which are storage area networks (SANs), Network Attached Storage (NAS), and Serial Attached SCSI (SAS). Depending on your requirements (and budget), which of these options you deploy is up to you. Ultimately, when combined with clustering, they all achieve the same goal of enabling people to keep working with their applications and files in the event of a server outage. A simple example of this is a person named Sarah in Human Resources. Sarah needs to make sure that she has a location to securely store critical documents related to employees, which could include their Social Security numbers. With a properly designed and implemented shared storage solution, Sarah can place these files on a shared location that is encrypted and backed up and could potentially have rights management or other security measures enabled. Other employees with the associated rights to this location have access to these files, and Sarah doesn’t have to worry about trying to share the files from her own workstation or even risk losing them if it was to crash.
Storage, and the ability to provide controlled access to it, is one of the most common requirements of any organization. Many different storage options are available. Before we get into the options available in Windows Server 2012 R2, let’s review the basic components:
With the feature advancements in Windows Server 2012 R2 specific to storage, you can start utilizing these components on the infrastructure you already own. Let’s dig into these technologies for a brief overview.
A storage area network is a network-connected entity that is dedicated to storage. SAN technology is just a basic framework, and each type of SAN solution presents storage in its own unique way. What we are really talking about is block-level storage that is available to resources over the network. The SAN is typically a large device with numerous hard disk drives, and you divide and format them to present to servers and computers on the network.
In addition, a SAN doesn’t have to be a traditional network; it could be over Fiber Channel, for example. With Fiber Channel, the same basic principal applies: it’s a device filled with disks but the network is fiber optic. In most organizations the storage network has a network switch dedicated and optimized for a SAN. The data transfer network that a SAN communicates on is typically known as the storage fabric. The main purpose of a SAN is to allow different types of servers, applications, and users from multiple places to access a storage pool, which can be accessed from any devices that interconnect with that storage fabric. Part of the storage fabric is the host bus adapter (HBA); HBAs are the network interface cards (NICs) that connect the storage fabric to the resources on your network that need to access the storage.
Many organizations and IT pros believe that a SAN provides them the flexibility to deploy and redeploy servers and storage in a much more dynamic fashion. Servers can boot directly from a SAN, giving them the operating system and its configurations in a larger, more highly available location. If the physical server goes down, a new one can be put in its place, and the operating system and the associated disks can be pointed to the new server much faster than rebuilding and restoring from tape.
We recommend that you spend some time investigating these topics at a much deeper level, and if your organization has an existing SAN, you should start by reading through the deployment and administration guides that accompany it.
Internet Small Computer System Interface (iSCSI) has been around for many years and has been used as a way to allow computers or servers to communicate with disk drives or other storage devices such as tape libraries. As SCSI has advanced, so has the network infrastructure connecting your servers and computers. Gigabit-based networks are much more commonplace and allow you to run storage connections natively through these higher-bandwidth connections. iSCSI is used to facilitate the transfer of data over a TCP/IP (Ethernet) network. The iSCSI protocol lets you present the disk drives located in your SAN over an existing network to your servers.
Microsoft’s iSCSI Initiator is a software component built into all Windows Server operating systems since 2008 and is also included in Windows 7 and Windows 8. The iSCSI Initiator enables the connections on your Windows devices to utilize this technology.
As with the other storage technologies we are going to talk about here, we won’t get into great detail about all of the scaling and performance options available. The purpose of this chapter is to introduce the topics.
Fiber Channel (FC) is a high-speed connectivity network link running over twisted-pair copper wire or fiber-optic cable. The connection to your servers and storage is handled through the host bus adapter (HBA) using a protocol similar to TCP, called Fiber Channel Protocol (FCP).
The HBAs communicate in a grouping of zones with specific worldwide names, which essentially act like IP addresses. The Fiber Channel connection to your drives and storage is through a fiber switch and is managed in zones that are allocated to specific network interfaces. This has long been the fastest type of network storage connectivity option available to organizations, but it doesn’t come cheap!
Serial Attached SCSI is a way to access devices that employ a serial connection over locally connected cables. Unlike iSCSI and FC, there is no network connectivity in SAS enclosure solutions. The SAS technology supports earlier SCSI technologies, including printers, scanners, and other peripherals. SAS enclosures are large devices similar to a SAN that have multiple disks configured using different RAID levels to provide redundancy in the event of disk failure.
Redundant Array of Independent Disks consists of multiple disks grouped together. The array allows you to build out fault-tolerant disks and scale disks together to get high levels of performance. Multiple types of RAID exist that offer many different methods of performance and failover. The RAID technologies are the backbone of the internal workings of iSCSI, SAS, and Fiber Channel SAN enclosures. The following link provides information evaluating the types of RAID and when to use them, plus a breakdown of the different types in more detail: http://technet.microsoft.com/en-us/library/cc786889(v=WS.10).aspx.
Server Message Block (SMB) is a protocol specifically designed for file sharing and scaling out file shares or servers. It sits on top of TCP/IP but can utilize other network protocols. SMB is used for accessing user data and applications on resources that exist on a remote server. SMB has some specific requirements for setup:
The failover cluster servers running Windows Server 2012/2012 R2 have no extra requirements or roles that need to be installed. SMB 3.0 is enabled by default.
SMB features that are new to Windows Server 2012/2012 R2 include the following:
These are just a few of the newer features available to SMB. There are many other components, such as SMB-specific PowerShell cmdlets, encryption, and performance counters.
An in-depth look at SMB and the new feature set can be found on TechNet at http://technet.microsoft.com/en-us/library/hh831795.aspx.
The File and Storage Services role in Windows Server, shown in Figure 11.1, provides all the services and functions you need to manage and create file servers and storage options with Windows Server.
Figure 11.1 File and Storage Services
As you can see, the Storage Services component of this role is installed by default and cannot be uninstalled. The other components can be installed and removed as needed.
The File and iSCSI Services component of this role provides multiple other components that will help you manage your file shares, disk size, replication, and branch offices. The following list provides an overview of each of these components and what they offer to your file and storage capabilities with Windows Server 2012 R2:
You can install all of these components through the Server Manager dashboard, which provides details of each component and any required prerequisites. In the next section we will be defining clustering and helping you build out highly available services with failover clustering.
In its most basic form, a cluster is two or more servers (physical or virtual) that are configured as a logical object and a single entity that manages shared resources and presents them to end users. Servers that are members of a cluster are known as nodes. The three most common types of clusters in Windows Server 2012 R2 are file server clusters, SQL clusters, and Hyper-V clusters.
A two-node cluster, for example, would be configured with nodes (physical or virtual), multiple network interface cards, and a shared storage solution such as iSCSI, SAN, or direct attached disks. The purpose of clustering is to allow a specific group of nodes to work together in a shared capacity with highly available resources. This gives your end users high availability for the workloads they need. Clustering provides the following benefits:
The scalability options go well beyond two host servers and can expand up to sixty-four nodes per cluster, with support for even cross-geographic locations. The complexities of geographically distributed clusters for availability and recovery are not the focus of this section, but they will become more important as you start to understand the capabilities of clustering.
Clusters are commonly used in high-capacity, high-visibility, and fault-tolerance scenarios. You design the cluster size and cluster type based on the specific needs of the service or business and on the resources to be hosted. In any scenario, always think of clustering as a solution for making your services, applications, and components more available to the end user.
Windows Server has grown as an operating system over the years, and the requirements for creating a cluster have always been the key to a successful cluster implementation. In the next section we’ll take a look at these requirements.
We’ll spend some time examining the requirements for setting up a cluster and some of the best practices involved. But before we get into the hardware specifics, make sure to review the TechNet post “Validate Hardware for a Windows Server 2012 Failover Cluster,” located at http://technet.microsoft.com/en-us/library/jj134244.aspx.
Here are at the requirements:
Clustering is a mix of software and hardware, and it can be hosted on physical servers or virtual machines. Windows Server 2012 R2 has the components and tools built in for deploying your clusters, including a handy prerequisites wizard to validate that you have all the components and configurations in place to successfully set up a cluster.
Many improvements have been made to clustering since the Windows Server 2008 R2 version. Clustering is affected by these operating system improvements, but its features are located in the same places and have the same capabilities from prior versions, but with much improvement, such as cluster scalability. Windows Server 2012 and Server 2012 R2 have an increased scalability offering in the Hyper-V Failover Clustering feature, now supporting up to 64 nodes and 8,000 VMs per cluster.
Microsoft has also introduced a concept called continuous availability. This includes network interface card teaming, support for Cluster-Aware Updating, and Scale-Out File Servers (SOFS). Continuous availability is end-to-end monitoring, with options to monitor up and down the entire cluster stack.
A well-implemented failover-clustering solution will maximize business productivity and hone in on service levels. A resilient datacenter is one that has resource pools of computing power, storage, and network resources. In building a failover-clustering environment with Windows Server 2012 R2, you begin at the physical layer, starting with the network. Figure 11.2 shows an individual server with two physical NICs and multiple virtual adapters.
Figure 11.2 Physical and virtual NICs
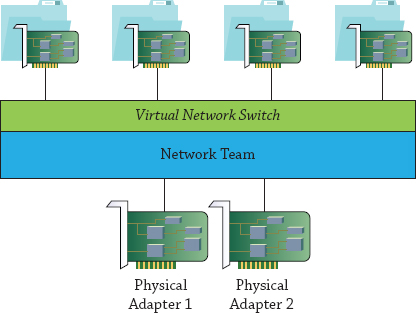
With continuous availability you get not only improved reliability but also improved performance. With this design you team multiple connects to increase the throughput available to the operating system and fault tolerance if an NIC port fails, a cable is pulled, or a physical card goes offline.
Cluster Shared Volumes (CSV) is a component of Failover Clustering and was first introduced in Windows Server 2008 R2. CSVs were designed specifically for virtualization. Their basic use was to simplify storage for virtual machines. If you do not use a CSV with your Hyper-V servers, then your disk can be accessed by only one node at a time. Configuring a CSV allows a common shared disk to be used, simplifies the storage-management needs for Hyper-V, and allows multiple VHDs to exist. You can also minimize downtime and disconnections with fault detection and recovery over the additional connection paths between each node in your cluster (via SAN).
The design of the CSV simplifies storage so that multiple VMs can access the same disk at the same time, which obviously doesn’t require as many disk drives to be created. You will gain other abilities through this model; when you are doing a live migration of your virtual machine, the shared volumes create multiple connections between the cluster nodes and the shared disk. So if a connection is lost, the migration can continue via another connection. To utilize CSVs you need only use NTFS partitions; no special settings or configurations are required beyond that.
In Windows Server 2012, CSVs allow multiple nodes to have read/write access to the same disk. The advantage that you gain from this is the ability to quickly move any of the volumes you have from any node in a cluster to another node in the cluster. Dismounting and remounting a volume are greatly improved, which helps simplify managing large numbers of disks in your clusters. Windows Server 2012 also made some significant changes in its advanced capabilities, such as BitLocker volumes, removal of the external authentication dependencies support for storage spaces, and major improvements in validation of Hyper-V to CSV functionally for performance increases. In Windows Server 2012, there is no automatic rebalancing of node assignment for your disks, but in Windows Server 2012 R2, CSV ownership is balanced across all nodes. Previously, all disks could be owned by one or two nodes in, say, a 12-node cluster, but with Windows Server 2012 R2, the disks are evenly disturbed across the 12 nodes. If a node goes down, the cluster automatically starts the process of rebalancing the disk placement. By moving away from a single coordinator node to a distributed node, support for Scale-Out File Servers is much more effective and the risk of failure dramatically drops.
In Windows Server 2012 R2, CSVs have better diagnostics and interoperability than in previous versions. You can view the CSVs on a node-by-node basis to see if I/O is set up to be redirected and the reason for it. Windows Server 2012 R2 has a new PowerShell cmdlet, Get-ClusterSharedVolumeState. For interoperability, Windows Server 2012 R2 adds support for the following features:
The growth and acceptance of virtualization in organizations of all sizes shows that the way clustering is being used today versus even five years ago has dramatically changed. Many datacenters today are building out large-scale clusters. Microsoft has been working diligently on increasing the resiliency of CSVs as well as expanding their utilization beyond just for VMs and extending it to Scale-Out File Servers (SOFS) specifically to shared VHDX. Scale-Out File Servers are discussed in Chapter 13, “Files, Folders, and Basic Shares.” The major changes since Windows 2008 R2 in CSVs expand the possibilities for what you can use them for, as well as the scenarios and storage options for your clusters.
This section focuses on the improvements in Windows 2012 R2. Since there has been just one year between the releases of Windows Server 2012 and Windows Server 2012 R2, we’ll treat them as one release. The features that are specific to Windows Server 2012 R2 will be noted as such. First, let’s talk about the new features and how guest (virtual machine) clusters have been given some great options:
One of the most important factors to understand in clustering is the quorum—what it does, why you need one, and what improvements have been made to Windows Server 2012 R2 that improve the quorum’s resiliency. In the next subsection we’ll explain what a quorum is so that you can gain a deeper understanding of its use in clustering.
According to Webster’s New World College Dictionary, Third Edition, a quorum is “the minimum number of members required to be present at an assembly or meeting before it can validly proceed to transact business.” This definition holds true for the use of the term quorum as it pertains to a cluster. The best way to start gathering the technical needs for your cluster is to understand what a quorum is and what it’s used for.
The quorum has been around since the inception of clustering and has been a major component and an unsung hero of sorts. In each revision of Windows Server, improvements to the quorum have been made to bring us to where we are now with extremely advanced quorum capabilities in Windows Server 2012. The quorum is the setting in the failover that determines the number of failures a cluster can have or sustain and keep the cluster (services) online. Once you have exceeded the quorum’s threshold, that cluster goes offline.
The cluster does not count the nodes and resource numbers, so it doesn’t look at the current capacity and decided to shut the services down. Think of it like this: There are 100 nodes in a cluster; that does not mean that if 50 of them go down, the cluster shuts off when it reaches 51 nodes down. The cluster is completely unaware of the server count or what resources are being over- or underutilized. Instead, the responsibility of the quorum is to help prevent an anomaly called split-brain, where two servers in a cluster are attempting to write the same file or take ownership of the same resources, potentially corrupting them.
The job of the quorum in this capacity is to prevent the problem from happening and essentially decide whether the cluster can or should continue to function, stopping a problematic node’s service until it can communicate properly with the rest of the clusters. When the issue is resolved, the quorum will allow the problematic node to rejoin the cluster group and restart all the needed services. The quorum decision is done through votes; each node in a cluster has a single vote, and the cluster itself can be configured as a witness vote. The witness can be a file share or a disk (as a best practice from the Cluster team at Microsoft, you should always configure a cluster with an odd number of members). The odd number of nodes gives you the ability to have an even number of quorum votes, and the odd resource can be the witness for outages. Adding this additional node ensures that if half the cluster goes down, the witness node will keep it alive.
Having a highly available virtual infrastructure is a major factor in the success of your HA plan. Considerations for storage options and how to connect the storage to your virtual machines so that they run uninterrupted when hardware fails are imperative. Design considerations include how to store your VMs and what kinds of components are required to provide the benefits for fault tolerance. The following is a list of highly available storage options:
Storage Spaces is considered one of the great new features of Windows Server 2012 and Server 2012 R2. The main advantage is the ability to manage a bunch of disks as a single virtual disk drive. The virtual disk type dictates how data is written across the physical disks.
Currently there are three choices:
If you are unfamiliar with disk RAID, I recommend you look at the following site for full information on the background of RAID and RAID levels: http://en.wikipedia.org/wiki/RAID.
Storage Spaces has three basic components:
Storage Spaces offers different types of provisioning options that determine how much space is being used and how to allocate to the virtual disks. You can define the performance type and what you are willing to utilize to achieve it. Many design factors are involved in an increase or decrease in performance, such as disk speed, size, and type. Having a great plan and design will increase the performance of your system.
The provisioning type is determined by how space is allocated to the disk and your performance choices:
When you develop your clustering strategy for printers, file shares, or Hyper-V, you are giving the infrastructure a highly available solution, one that can grow and you can move your critical systems into. To the support of Windows Server 2012 R2 and guest-based clustering, you are adding the next level of HA and increasing the speed of recovery from a system failure. It’s not always the hardware that requires high availability; in many cases the software is causing a problem, resulting from memory leaks, software updates, or configuration changes. When you run your cluster-aware applications as virtual workloads, the failover time and the integration with many of the new continuous availability workloads become more enticing because consumers experience no interruption.
To understand the workloads that are capable of this type of clustering, you need to remember the golden rule: If a workload is made for clustering or recommended to cluster for HA or disaster recovery (DR) purposes, it can work in a guest cluster. Microsoft has made the Windows Server 2012 and Server 2012 R2 workloads aware of this virtual guest cluster, in such areas as these:
To use this technology you utilize a model enabled in Windows Server 2012 R2: a shared VHDX. Windows Server 2012 introduced the VHDX format, which addressed the storage, data protection, and performance needs on large disks. When you create virtual guest clusters, you are attaching a VHDX to a SCSI controller for your VM, enabling sharing to create a connection, and presenting the VHDX as an SAS drive. So you are given the option of building out an infrastructure that doesn’t necessarily require iSCSI, Fibre Channel SAN, or block-level storage, but you are getting to use SMB 3.0.
Now that you understand some of the basic building blocks, you can take your knowledge of the shared storage and clustering capabilities of Windows Server 2012 R2 into the next section and dive into setup.
In this section we will walk through the basic steps of setting up a host-based cluster. For the purpose of this example we will be creating a two-node cluster and configuring it for file shares. Clustering file shares is a great starting place to introduce you to managing a cluster. The requirements are very simple. We’ll take a basic need in any enterprise and provide immediate high availability.
To successfully set this up, you need to work through each of the following sections.
The lab we are going to use for this example is very simple. We have two servers running Windows Server 2012 R2. The servers are named as follows:
Server 1 = Cluster1
Server 2 = Cluster2
The cluster for this example is named DemoCluster, and its IP address is 192.168.1.21.
To examine the basic options of clustering we’re going to focus on clustering file services, but we’ll spend more time going over how to set up the cluster service on two nodes, step by step.
When prepping to build out a similar example cluster, the steps should be fairly straightforward, and hopefully you will see the value in getting your organization set up and using cluster services. In regard to the quorum that we discussed previously, I have created a share on a separate server; you can utilize a file share as the quorum, as we discussed. The share will be located on the Active Directory domain controller for this example, BF1. The share \\BF1\#Cluster will be utilized for the witness.
The two servers have two physical NICs. Ideally you would have a minimum of three NICs in a production environment or six if possible. You want to separate the three types of network needs. If you have five or more NICs available, then you can team two NICs for the primary services. Remember, for every NIC you use, you should always use a static IP address. DHCP is supported with clustering, but it’s not ideal or advised in most scenarios. The following list is a typical role configuration for NICs:
Once you have set up the NICs and are ready to move on, the next step is taking the host names (rename the servers to something descriptive of your clusters) and joining them to Active Directory. As shown previously, the servers we are using in this example are named Cluster1 and Cluster2.
After you have joined these devices to an Active Directory domain, you need to make sure each cluster node has Remote Desktop and Remote Management installed, and since you are going to be creating a file server cluster, setting up the File Server role is required.
Before we set up the cluster itself, let’s do a quick review of the storage options of clusters. You have several choices, and since it’s a requirement, you need to figure out what type of storage solution you want to use. Typical options for shared storage are these:
We discussed each of these storage components previously in this chapter. One of the great benefits of the storage options with Windows Server 2012 R2 is that all of the storage solutions used today are supported, so you can leverage the hardware you already have. There’s no need to run off and change your storage infrastructure just yet. Windows Server 2012 R2 provides the option, if you haven’t invested in a specific storage solution, to build it out with SMB 3.0. As discussed earlier in the chapter, SMB 3.0 was first introduced in Windows Server 2012 with Scale-Out File Servers and Hyper-V in mind, and it was the start of what is now considered continuous availability. You can read up on SMB 3.0 and see ways to leverage it in your organization at the following link: http://tinyurl.com/c11SMB30.
One of the first things you need to do is install the Failover Clustering feature, and you have a couple options for doing this. As noted many times in this book, you can use PowerShell to install it. You can find information on installing any Windows feature with PowerShell at the following link: http://tinyurl.com/c11ClusterInstall. For this feature, enter the following command from an administrative PowerShell console:
Install-WindowsFeature -Name Failover-ClusteringYou can include the -IncludeManagmentTools switch at the end of the command if you have not installed the administrative tools already.
For this example we will be going through Server Manager and adding the File Server role and the Failover Clustering feature. Follow the basic prompts; since the wizard is pretty basic and doesn’t ask you any questions when you add the feature, we will jump right to configuring your cluster. If you need assistance in adding roles and features, please see Chapter 7, “Active Directory in windows Server 2012 R2.”
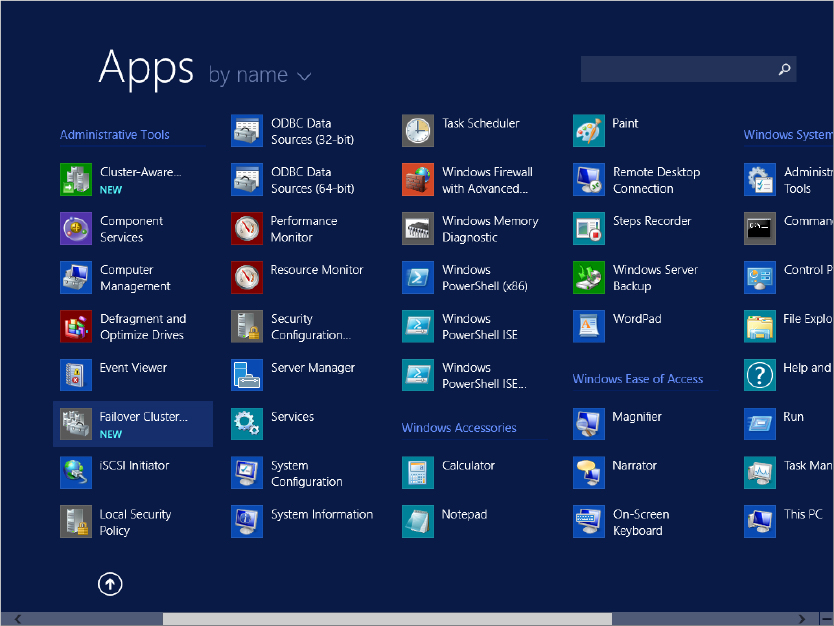
Once the Failover Clustering feature is installed, it will appear on the Apps section of your Start screen, as shown in Figure 11.3.
Figure 11.3 Apps section of the Start screen
Double-click Failover Cluster Manager to open it. As you can see in Figure 11.4, all of the major components you need to create, validate, and manage your cluster are listed in a single window.
Figure 11.4 Failover Cluster Manager
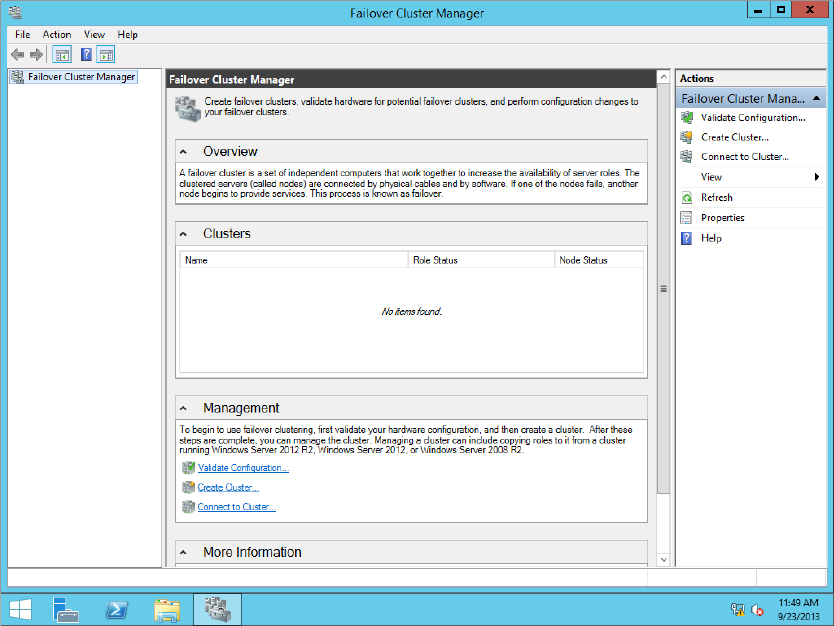
Take some time to examine the console; expand the More Information section and find some of the basic topics on the web that are updated in the console. Since the web links in the console are updated frequently, you can find links to any major changes or updates there. Exploring the cluster console is very important if you have never done this before.
The next step is to create a new cluster; you do this by following these steps:
Figure 11.5 Choose Create Cluster.
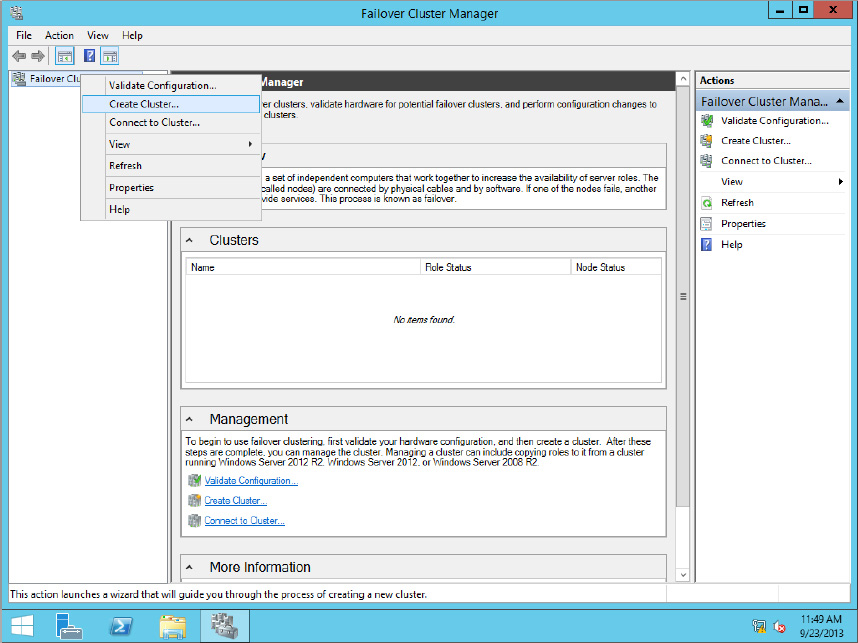
Figure 11.6 Adding a server to the cluster
Figure 11.7 Validate a Configuration Wizard
Figure 11.8 Validation Report
Figure 11.9 Validation Report Inventory screen
Figure 11.10 Entering a cluster name
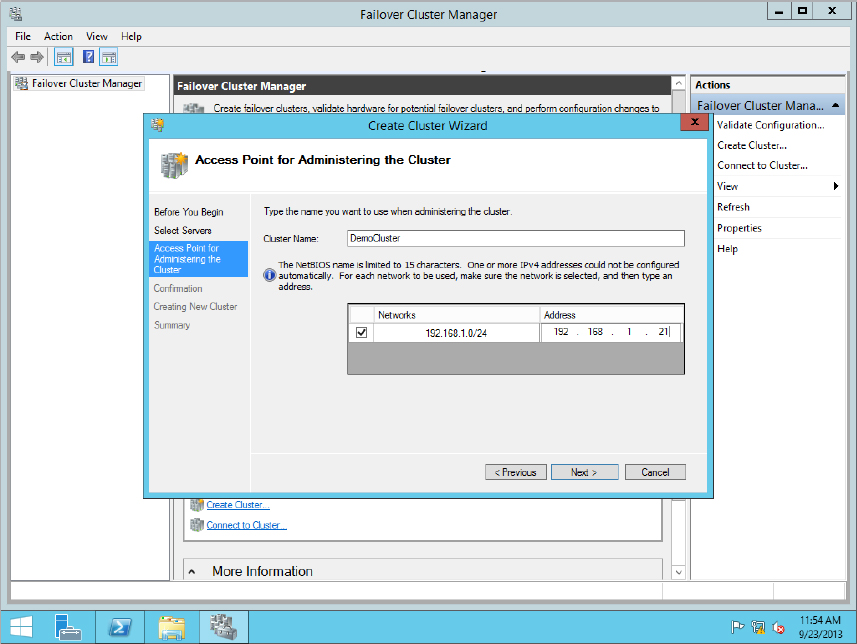
Figure 11.11 Creating a cluster name
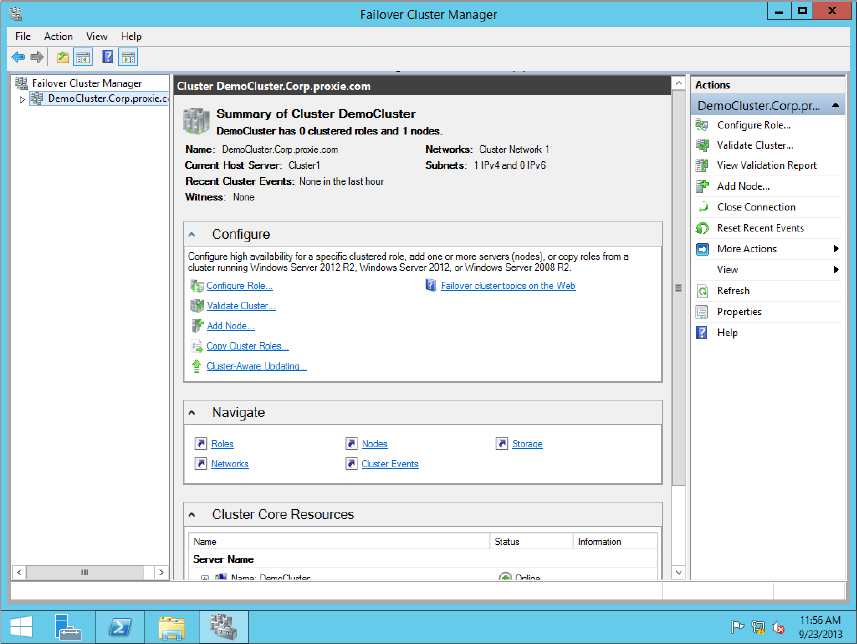
Figure 11.12 Viewing newly added nodes
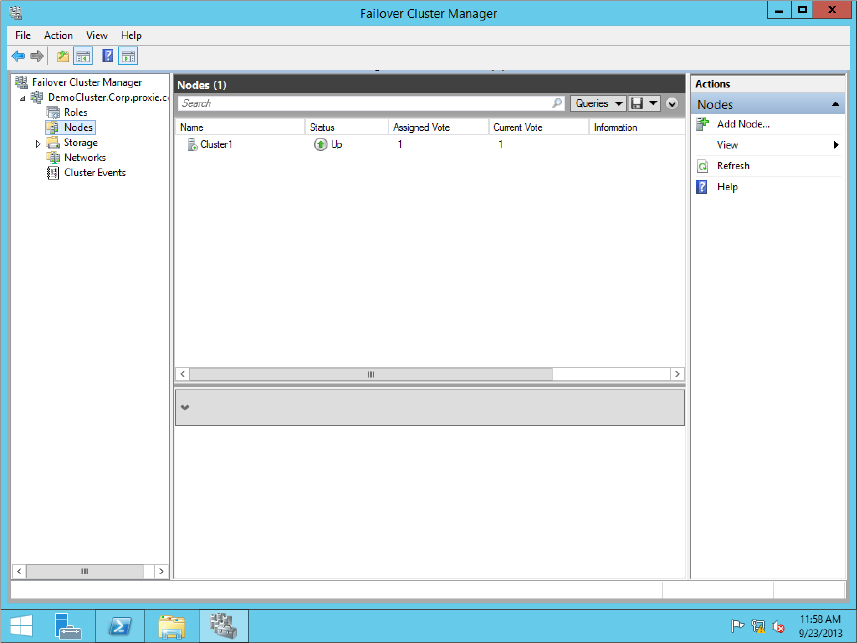
Figure 11.13 Starting the High Availability Wizard
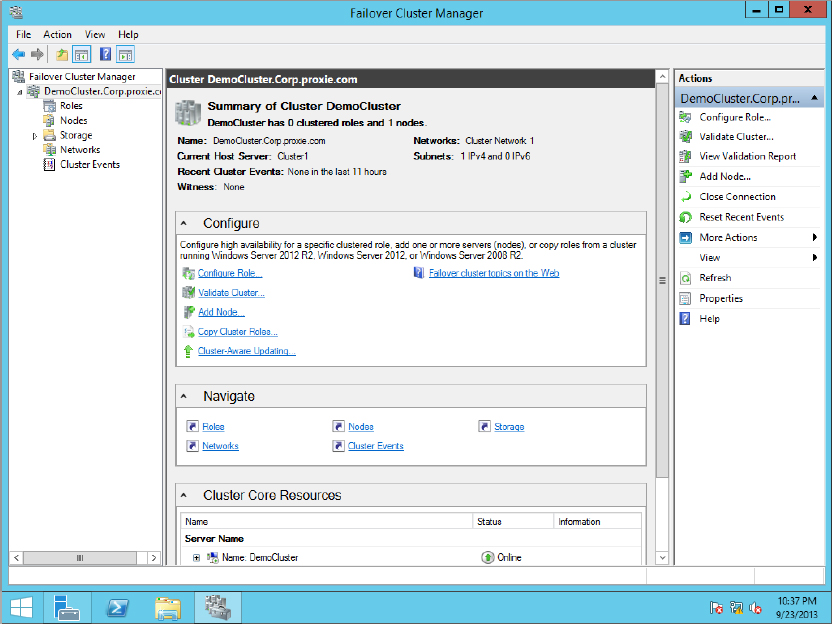
Figure 11.14 Selecting a role
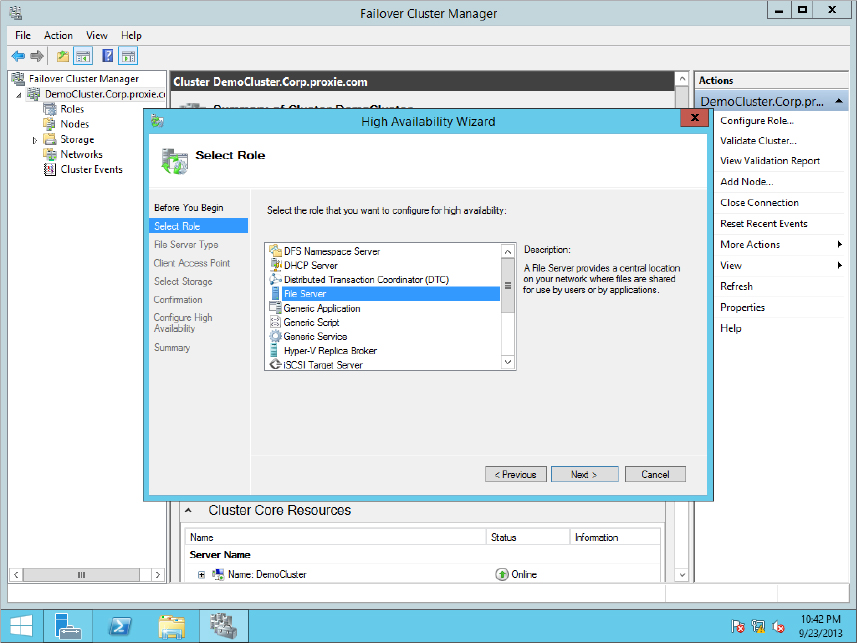
Figure 11.15 File Server Type screen
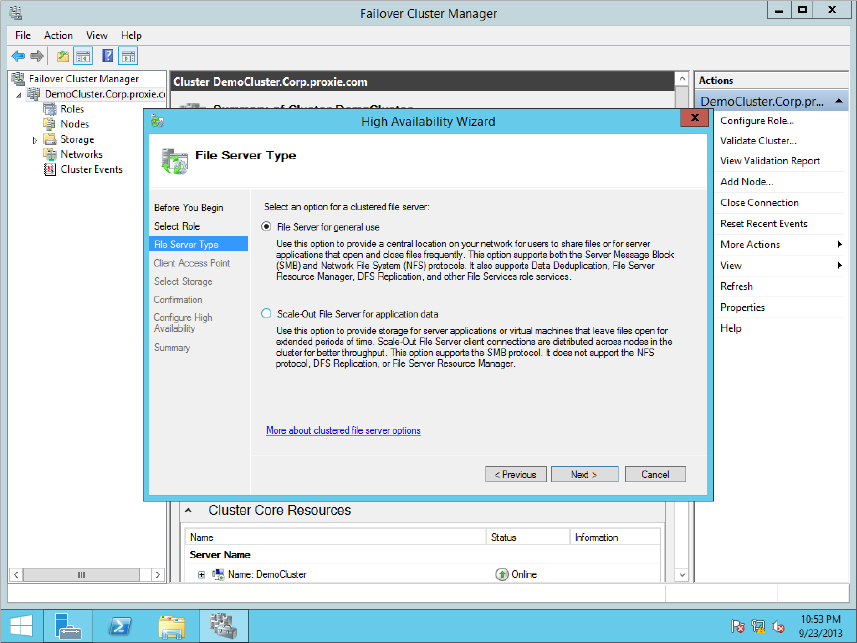
Figure 11.16 File Server clustered role

One thing that many people skip before adding the second node in the cluster is validating that the primary node is active and working. So make sure you check through the following before moving onto this next step.
Now onto adding the additional node to your cluster: the important part that may seem obvious is that now you are providing your host services failover. It is exciting to have your first cluster up and running, but without additional nodes it’s just a lonely service running on your server. The best place to start is the Failover Cluster Management console; in the Configure section you will see the option Add Node. This is shown in Figure 11.17.
Figure 11.17 Add Node option
Figure 11.18 Cluster nodes status
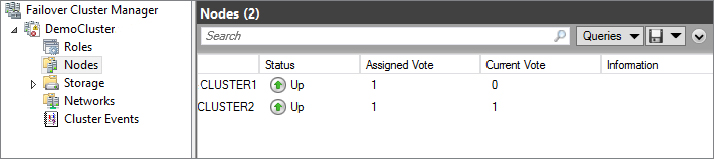
Now that you have both nodes set up, your cluster can provide failover to any of the workloads you wish to support.
You may have noticed in Figure 11.18 two other columns next to Status:
Windows Server 2012 R2 provides an advanced quorum configuration option where you can add or evict quorum votes node by node. Out of the box all nodes are assigned a vote. You may decide to remove votes from specific nodes to help with disaster recovery solutions. The most common situation is when you have a geocluster and you want to remove the votes from your recovery site; if you consider doing this, refer to Microsoft’s guide on quorum considerations for DR found here: http://tinyurl.com/c11ClusterDR.
Setting up a cluster infrastructure is usually not complex, although it can be depending on your needs and the services you wish to provide with your cluster. The more services, nodes, and sites you add, the more complex the setup becomes, but they are all worth it. The cluster hosts and guest capabilities will make all of your organization’s resources highly available, scalable, and recoverable in case of a site failure.
In the next section we will spend some time on guest clustering, why you might want to add it, and how Windows Server 2012 R2 makes things even better!
As we have mentioned a few times in this section, guest-based clustering means extending the cluster services to inside the virtual machine layer. The idea is to allow your VMs to have high-availability options inside the VM, so you can have an HA application or service sitting on top of a clustered set of hosts. You are now moving into an extremely highly available datacenter, giving all the applications physical or virtual continuous availability.
What can you cluster in your virtual guests? Anything that is supported by Windows clustering will work. You can include all of your major services and common Windows Server workloads such as these:
In Windows Server 2008 R2, guest clusters supported the standard OS health detection, application health, and application mobility options. At that point there was no support for VM mobility, so in case of a failover you would have to migrate the VM to another host and spin it up. Windows Server 2012 made great moves in recovery so that guest-level HA recovery is now possible. The clustered service will reboot the VMs if needed, and at the host level if recovery is necessary, the VM will fail over to another node.
Basically, the Role Health Service will detect a failure and automatically recover by moving the VM role to a different VM to allow the OS or applications to update. Now you can connect your VMs to all different types of storage, so you can connect to a SAN for shared storage via Fiber Channel with virtual fiber adapters.
As the health services moves into the monitoring stages, it will accept a first failure, and the applications will move to other nodes. A second or third failure will cause the cluster host to shut down and restart the VM. Configuring this is very simple and requires only that you look at the clustered service properties, set the second and third failures, and set up your application health monitors through the clustered service.
Setting up your guest-based cluster is similar to setting up a host-based cluster in that the components have the same requirements except that these can be virtual. Here are the considerations:
Configuring your guest-based clusters is essentially the same as configuring your host cluster; you want to connect and configure all the same settings with the exception of the Hyper-V role, because these are all Hyper-V guests. If you are feeling more knowledgeable now that you have gone through this introduction on shared storage and clustering, we highly recommend looking at the Clustering and High-Availability blog on TechNet at http://blogs.msdn.com/b/clustering/.