You can specify a range of characters to match between square brackets as follows:
[a-d]
This means the range of characters from a to d, so a, b, c, and d are included.
Let's use the same previous example file:
$ awk '/[a-m]ash/{print $0}' myfile
$ sed -n '/[a-m]ash/p' myfile

The character range from a to m is selected. The third line contains r before ash, which is not in our range, so only the second line doesn't match.
You can use numbers ranges as well:
$ awk '/[0-9]/'
This pattern means from 0 to 9 is matched.
You can write multiple ranges in the same bracket:
$ awk '/[d-hm-z]ash/{print $0}' myfile
$ sed -n '/[d-hm-z]ash/p' myfile
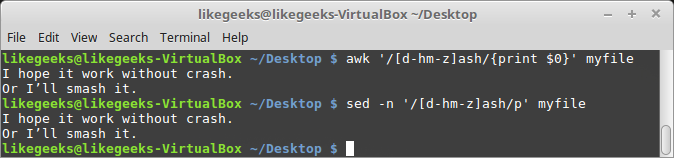
In this pattern, from d to h and from m to z are selected and since the first line contains b before ash, only the first line doesn't match.
You can use the ranges to select all uppercase and lowercase characters as follows:
$ awk '/[a-zA-Z]/'