The curly braces define the number of existence of the preceding character or character class:
$ echo "tt" | awk '/to{1}t/{print $0}'
$ echo "tot" | awk '/to{1}t/{print $0}'
$ echo "toot" | awk '/to{1}t/{print $0}'
$ echo "tt" | sed -r -n '/to{1}t/p'
$ echo "tot" | sed -r -n '/to{1}t/p'
$ echo "toot" | sed -r -n '/to{1}t/p'
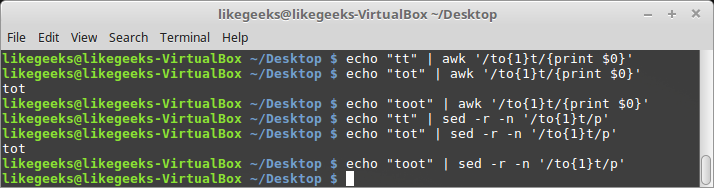
The third example doesn't contain any matches because the o character exists two times. So, what if you want to specify a more flexible number?
You can specify a range inside the curly braces:
$ echo "toot" | awk '/to{1,2}t/{print $0}'
$ echo "toot" | sed -r -n '/to{1,2}t/p'

Here, we match the o character if it exists one or two times.
Also, you can use the curly braces with the character class:
$ echo "tt" | awk '/t[oa]{1}t/{print $0}'
$ echo "tot" | awk '/t[oa]{1}t/{print $0}'
$ echo "toot" | awk '/t[oa]{1}t/{print $0}'
$ echo "tt" | sed -r -n '/t[oa]{1}t/p'
$ echo "tot" | sed -r -n '/t[oa]{1}t/p'
$ echo "toot" | sed -r -n '/t[oa]{1}t/p'
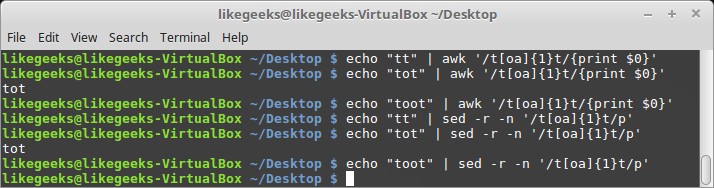
As expected, if any of the characters [oa] exists for one time, the pattern will match.