We saw how to use data fields such as $1 and $2. Also, we saw the NR field, which holds the number of processed lines, but there are more built-in variables that AWK offers to simplify work more and more.
- FIELDWIDTHS: Specifies the field width
- RS: Specifies the record separator
- FS: Specifies the field separator
- OFS: Specifies the output separator, which is a space by default
- ORS: Specifies the output separator
- FILENAME: Holds the processed file name
- NF: Holds the line being processed
- FNR: Holds the record which is processed
- IGNORECASE: Ignores character case
These variables can help you a lot in many cases. Let's assume that we have the following file:
John Doe
15 back street
(123) 455-3584
Mokhtar Ebrahim
10 Museum street
(456) 352-3541
We can say that we have two records for two persons and each record contains three fields. Let's assume that we need to print the name and the phone number. So how do we make AWK process them correctly?
In this case, the fields are separated by a newline (\n) and the records are separated by empty lines.
So if we set the FS to (\n) and the RS to empty text, the fields will be identified correctly:
$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' myfile

The result appears valid and appropriate.
In the same way, you can use the OFS and ORS for the output report:
$ awk 'BEGIN{FS="\n"; RS=""; OFS="*"} {print $1,$3}' myfile

You can use any text that fits your needs.
We know that NR holds the number of the processed line and FNR looks the same from the definition, but let's explore the following example to see the difference:
Assume that we have the following file:
Welcome to AWK programming This is a test line And this is one more
Let's process this file using AWK:
$ awk 'BEGIN{FS="\n"}{print $1,"FNR="FNR}' myfile myfile
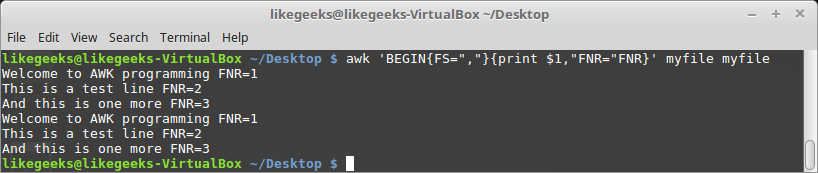
Here we processed the file twice for testing purposes only to see what the value of the FNR variable is.
As you can see, the value starts from 1 for every processing cycle.
Let's see the whether NR variable is used in the same way:
$ awk 'BEGIN {FS="\n"} {print $1,"FNR="FNR,"NR="NR} END{print "Total lines: ",NR}' myfile myfile

The NR variable preserves its value during the entire processing while FNR started from 1.