The asterisk is used to match the existence of a character or a character class zero or more times.
This can be useful when searching for a word with multiple variations or that has been misspelled:
$ echo "Checking colors" | awk '/colou*rs/{print $0}'
$ echo "Checking colours" | awk '/colou*rs/{print $0}'

If the character u doesn't exist at all or exists, that will match the pattern.
We can benefit from the asterisk character by using it with the dot character to match any number of characters.
Let's see how to use them against the following example file:
This is a sample line
And this is another one
This is one more
Finally, the last line is this
Let's write a pattern that matches any line that contains the word this and anything after it:
$ awk '/this.*/{print $0}' myfile
$ sed -n '/ this.*/p' myfile
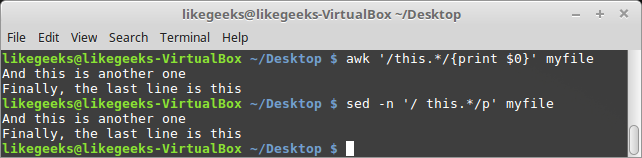
The fourth line contains the word this, but the first and third lines contain a capital T, so that it doesn't match.
The second line contains the word and text after it, whereas the fourth line contains the word and nothing after it, and in both cases, the asterisk matches zero or more instances.
You can use the asterisk with the character class to match the existence of any character inside the character class for one time or none at all.
$ echo "toot" | awk '/t[aeor]*t/{print $0}'
$ echo "tent" | awk '/t[aeor]*t/{print $0}'
$ echo "tart" | awk '/t[aeor]*t/{print $0}'
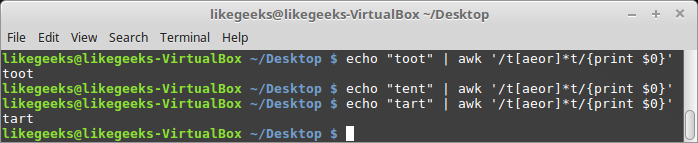
The first line contains the character o two times, so it matches.
The second line contains the n character, which doesn't exist in the character class, so there is no match.
The third line contains the characters a and r, once for each, and they exist in the character class, so that line matches the pattern too.