Chapter 9. Intrusion Detection
In this chapter we will see how container intrusion detection operates with the new low-level eBPF interface, what forensics looks like for a container, and how to catch attackers who have evaded all other controls.
Defense in depth means limiting the trust you place in each security control you deploy. No solution is infallible, but you can use intrusion detection systems (IDS) to detect unexpected activity in much the same way that motion sensors detect movement. Your adversary has already accessed your system and may even have viewed confidential information already, so an IDS reviews your system in real time for unexpected behavior and observes or blocks it. Alerts can trigger further defensive actions from an IDS, like dumping compromised memory or recording network activity.
Intrusion detection can inspect file, network, and kernel reads and writes to verify or block them with an allowlist or a denylist (as seccomp-bpf configuration does). If Captain Hashjack’s Hard Hat Hacking Collective has remote access to your servers, an IDS might be triggered by their use of malware with known behavioral signatures, scan of networks or files for further targets, or any other program access that deviates from the expected “stable” baseline the IDS has learned about the process.
Some attackers’ campaigns are only discovered after the adversary has been on the system for weeks or months and finally inadvertently tripped the IDS detection.
Defaults
Stable behavior is what we’d expect our container process to do normally, when running as intended, and not compromised. We can apply the same thing to any data we collect: access and audit logs, metrics and telemetry, and system calls and network activity.
Intrusion detection to identify deviance from this behavior requires installation, maintenance, and monitoring. By default most systems do not have any intrusion detection unless configured to do so.
Threat Model
Intrusion detection can detect threats to BCTL’s systems. If an attacker gets remote code execution (RCE) into a container they may be able to control the process, changing its behavior. Potentially nonstable behaviors that could indicate compromise might include:
-
New or disallowed system calls (perhaps fork or exec system calls to create a shell like Bash or sh)
-
Any unexpected network, filesystem, file metadata, or device access
-
Application usage and order
-
Unexplained processes or files
-
Changes to users or identity settings
-
System and kernel configuration events
Any of a process’s properties and behaviors when interacting with the wider system may also be subject to scrutiny.
Tip
Attack tools like ccat and dockerscan can poison images in registries and install backdoors in container images that an attacker may use to gain entry to your pods at runtime. This sort of unexpected behavior should be noticed and alerted on by your IDS.
Of course, you don’t want to be alerted to legitimate activity, so you authorize expected behavior. It’s either preconfigured with rules and signatures or learned while the process is under observation in a nonproduction environment.
These threats should be identified and configured to alert your IDS system. We’ll see how in this chapter.
Traditional IDS
Before we get into cloud native IDS, let’s have a look at a few of the other intrustion detection applications that have been prominent over the years.
Traditional intrusion detection systems are classed as Network- or Host-based IDS (NIDS or HIDS), and some tools offer both. Historically these used signals from the host kernel or network adapter, and were not aware of the Linux namespaces that containers use.
Linux has auditd built in for system call events, but this
doesn’t correlate activity nicely across nodes in a distributed system. It’s also considered heavyweight (it generates a
great volume of logs) and can’t distinguish by namespace due to “complex and incomplete” ID tracking of namespaced
processes.
Tools like Suricata, Snort, and Zeek inspect network traffic against a rule and scripting engine, and may be run on the same host or (as they tend to be resource intensive) on dedicated hardware attached to the network under observation. Encrypted or steganographic payloads may escape such NIDS undetected. To further guard against these slippery assailants, the old-but-effective Tripwire tool watches files on the host for unauthorized changes.
An IDS detects threats by either using preknown information about them or detecting deviance from an expected baseline. Information known in advance can be considered a “signature,” and signatures can relate to network traffic and scans, malware binaries, or memory. Any suspicious patterns in packets, “fingerprints” of application code or memory usage, and process activities are verified against an expected ruleset derived from the application’s “known good” behavior.
Once a signature pattern is identified (for example, the SUNBURST traffic back to command and control servers), the IDS creates a relevant alert.
Note
FireEye released IDS configurations to detect SUNBURST. These configurations support various IDS tools including Snort, Yara, IOC, and ClamAV.
Signatures are distributed and update files, so you must regularly update them to ensure new and recent threats are detected. A signature-based approach is usually less resource intensive and less prone to false positives, but it may not detect zero-days and novel attacks. Attackers have access to defensive tooling and can determine how to circumvent controls in their own test systems.
Without predefined signatures to trip the IDS, anomalous behavior may be detected. This relies on a “known good state” of the application.
The derivation of a normal application behavior state defines “secure,” which puts the onus on defenders to ensure application correctness, rather than on the tool to enforce a generic ruleset.
This observational approach is more powerful than signatures as it can act autonomously against new threats. The price for this more general protection is greater resource utilization, which may impact the performance of the system being protected.
Signature and anomaly detection can be fooled, circumvented, and potentially disabled by a skilled adversary, so never rely entirely upon one control.
Note
VirusTotal is a library of malicious files. When a defender discovers an attack, they upload the files retrieved by forensics (for example, malware, implants, and C2 binaries or encrypted files), allowing researchers to correlate techniques across targets and helping defenders to understand their adversary, the attacks being used, and (with any luck) how they can best defend themselves. Antivirus vendors ensure their products have signatures for every malicious file on VirusTotal, and new submissions are scanned by existing virus detection engines for matches.
Attackers use these same tools to ensure their payloads will bypass antivirus and malware signature scanners. Red Teams have been retrospectively discovered leaking tooling and signatures onto VirusTotal once their attacking campaigns have been decloaked.
eBPF-Based IDS
Running IDS for every packet or system call can incur overhead and slow down the system.
We introduced eBPF in “eBPF” as a mechanism to safely and efficiently extend the Linux kernel. eBPF avoids some of these issues by being very fast indeed: it was designed for fast packet handling, and now kernel developers use it to observe runtime behavior for everything in the kernel. Because it runs inside the kernel as trusted code it is less restricted than other IDS and tracing technologies.
However, running in the kernel poses its own set of possible risks, and the eBPF subsystem and JIT compiler have had a number of breakouts, but these are considered less dangerous than slow, incomplete kernel developer tracing solutions or more fallible IDS.
Note
Jeff Dileo’s “Evil eBPF In-Depth Practical Abuses of an In-Kernel Bytecode Runtime” is a good primer on BPF and its attacks, and “Kernel Pwning with eBPF: A Love Story” by Valentina Palmiotti is a walkthrough of the various components of eBPF.
Since eBPF’s powers have been extended and integrated more deeply into the kernel, a number of CNIs and security products now use eBPF for detection and networking including Cilium, Pixie, and Falco (which we detail in the following section).
Warning
As with all container software, bugs can lead to container breakout, as in CVE-2021-31440, where an incorrect bounds calculation in the Linux kernel eBPF verifier allowed an exploitable verifier bypass.
Let’s move on to some applications of eBPF in Kubernetes.
Kubernetes and Container Intrusion Detection
There are signature and anomaly detection systems available for Kubernetes workloads at runtime. Kubernetes and container IDS systems support namespaced workload, host, and network IDS.
By splitting processes into namespaces, you can use more well-defined metadata to help an IDS make decisions. This more granular data can give greater insight into an attack, which is vital when the decision to kill a running container may affect your production workloads.
This gives container IDS an advantage: the behavior it is monitoring is just a single container, not a whole machine. The definition of allowed behavior is much smaller in a single-purpose container, so the IDS has a far greater fidelity of policy to block unwanted behavior. With this in mind, let’s now have a look at a few container-specific IDS.
Falco
Falco is an open source, cloud native IDS that can run in a container or on a host. Traditionally, Falco required a dedicated kernel module to run (with its code loaded into the kernel) so that it could interact with system calls. Since 2019, Falco has also supported eBPF. The eBPF interface allows general-purpose code to be loaded by Falco, from userspace, into the kernel’s memory. This means less custom code, fewer kernel modules, and the ability to use the kernel monitoring and enforcement techniques through a well-known interface.
When run in a container, it requires privileged access to the host or use of the CAP_BPF capability with host PID
namespace access.
In eBPF mode, when a process interacts with a file using a system call such as open(), the eBPF program is triggered,
which can run arbitrary code in a kernel VM to make its decision. Depending on the inputs, the action will be accepted
or blocked:
user@host:~[0]$docker run --rm -i -t\-eHOST_ROOT=/\--cap-add BPF\--cap-add SYS_PTRACE\--pid=host\$(ls /dev/falco*|xargs -I{}echo--device{})\-v /var/run/docker.sock:/var/run/docker.sock\falcosecurity/falco-no-driver:latest
DEMO 13:07:48.722501295: Notice A shell was spawned in a container with an attached terminal(user=rootuser_loginuid=-1 <NA>(id=52af6056d922)shell=shparent=<NA>cmdline=sh -cunset$(env|grep -Eo'.*VERSION[^\=]*')&&execbashterminal=34816container_id=52af6056d922image=<NA>)
Note
Falco is based on Sysdig, a system introspection tool. Sysdig Cloud offers workload and Kubernetes performance monitoring, and Sysdig Secure is the commercial product built around Falco.
Falco comes with a collection of community contributed and maintained rules, including dedicated rules to manage Kubernetes clusters:
-
Unexpected inbound TCP connections:
-
Detects inbound TCP traffic to Kubernetes components from a port outside of an expected set
-
Allowed inbound ports:
-
6443(kube-apiservercontainer) -
10252(kube-controllercontainer) -
8443(kube-dashboardcontainer) -
10053,10055,8081(kube-dnscontainer) -
10251(kube-schedulercontainer)
-
-
-
Unexpected spawned processes:
-
Detects a process started in a Kubernetes cluster outside of an expected set
-
Allowed processes:
-
kube-apiserver(forkube-apiservercontainer) -
kube-controller-manager(forkube-controllercontainer) -
/dashboard(kube-dashboardcontainer) -
/kube-dns(kube-dnscontainer) -
kube-scheduler(kube-schedulercontainer)
-
-
-
Unexpected file access readonly:
-
Detects an attempt to access a file in readonly mode, other than those in an expected list of directories
-
Allowed file prefixes for readonly:
-
/public
-
-
These rules form a useful base set to extend with custom rules for your own cluster’s specific security needs.
Warning
While it’s almost always better to consume community contributed rules, no software is free of bugs. For example, Darkbit found
a Falco rule bypass that exploited a loose regex rule to deploy a custom
privileged agent container—docker.io/my-org-name-that-ends-with-sysdig/agent:
- macro: falco_privileged_containers condition:(openshift_image or user_trusted_containers or container.image.repository in(trusted_images)or container.image.repository in(falco_privileged_images)or container.image.repository startswith istio/proxy_ or container.image.repository startswith quay.io/sysdig)
Machine Learning Approaches to IDS
Machine learning (ML) replays the same signals used in other IDS systems through a model, which then predicts whether the container is compromised.
There are many examples of machine learning IDS available:
-
Aqua Security uses ML-based behavioral profiling to analyze and react to behaviors in containers, the network, and hosts.
-
Prisma Cloud’s layer 3 inter-container firewall learns valid traffic flows between app components with ML.
-
Lacework uses unsupervised machine learning for cross-cloud observability and response to runtime threats.
-
Accuknox uses unsupervised machine learning to detect instability and discern potential attacks, and “Identity as a Perimeter” for zero-trust network, application, and data protection.
Container Forensics
Forensics is the art of reconstructing data from incomplete or historical sources. In Linux this involves capturing process, memory, and filesystem contents to interrogate them offline, find the source or impact of a breach, and inspect adversarial techniques.
More advanced systems gather more information, like network connection information they were already logging. In the event of a serious break, the entire cluster or account may be cut off from the network so that the attacker cannot continue their assault, and the entire system can be imaged and explored.
Tools like kube-forensics “create checkpoint snapshots of the state of running pods for
later off-line analysis,” so malicious workloads can be dumped and killed, and the system returned to use. It runs a
forensics-controller-manager with a PodCheckpoint custom resource definition (CRD) to effectively docker inspect,
docker diff, and finally docker export. Notably, this does not capture the process’s memory, which may have
implants or attacker tools that were not saved to disk or were deleted once the process started.
To capture a process’ memory, you can use standard tools like GDB. Using these tools from inside a container is difficult as symbols may be required. From outside a container, dumping memory and searching it for interesting data is trivial, as this simple Bash script mashing together Trufflehog and GDB process dumping demonstrates:
#!/bin/bash## truffleproc — hunt secrets in process memory // 2021 @controlplaneioset-Eeuo pipefailPID="${1:-1}"TMP_DIR="$(mktemp -d)"STRINGS_FILE="${TMP_DIR}/strings.txt"RESULTS_FILE="${TMP_DIR}/results.txt"CONTAINER_IMAGE="controlplane/build-step-git-secrets"CONTAINER_SHA="51cfc58382387b164240501a482e30391f46fa0bed317199b08610a456078fe7"CONTAINER="${CONTAINER_IMAGE}@sha256:${CONTAINER_SHA}"main(){ensure_sudoecho"# coredumping pid${PID}"coredump_pidecho"# extracting strings to${TMP_DIR}"extract_strings_from_coredumpecho"# finding secrets"find_secrets_in_strings||trueecho"# results in${RESULTS_FILE}"less -N -R"${RESULTS_FILE}"}ensure_sudo(){sudo touch /dev/null}coredump_pid(){cd"${TMP_DIR}"sudo grep -Fv".so""/proc/${PID}/maps"|awk'/ 0 /{print $1}'|(IFS="-"whileread-r START END;doSTART_ADDR=$(printf"%llu""0x${START}")END_ADDR=$(printf"%llu""0x${END}")sudo gdb\--quiet\--readnow\--pid"${PID}"\-ex"dump memory${PID}_mem_${START}.bin${START_ADDR}${END_ADDR}"\-ex"set confirm off"\-ex"set exec-file-mismatch off"\-ex quit od|&grep -E"^Reading symbols from"done|awk-unique)}extract_strings_from_coredump(){strings"${TMP_DIR}"/*.bin >"${STRINGS_FILE}"}find_secrets_in_strings(){localDATE MESSAGEDATE="($(date --utc +%FT%T.%3NZ))"MESSAGE="for pid${PID}"cd"${TMP_DIR}"git init --quiet git add"${STRINGS_FILE}"git -c commit.gpgsign=falsecommit\-m"Coredump of strings${MESSAGE}"\-m"https://github.com/controlplaneio/truffleproc"\--quietecho"#${0}results${MESSAGE}${DATE}| @controlplaneio">>"${RESULTS_FILE}"docker run -i -eIS_IN_AUTOMATION=\-v"$(git rev-parse --show-toplevel):/workdir:ro"\-w /workdir\"${CONTAINER}"\bash|&commandgrep -P'\e\['|awk-unique >>"${RESULTS_FILE}"}awk-unique(){awk'!x[$0]++'}main"${@:-}"
Put this script into procdump.sh and run it against a local shell:
$procdump.sh$(pgrep -f bash)
You will see any high entropy strings or suspected secrets that were loaded into the shell:
1 # procdump.sh results for pid 5598 (2021-02-23 08:58:54.972Z) | @controlplaneio 2 Reason: High Entropy 3 Date: 2021-02-23 08:58:54 4 Hash: 699776ae32d13685afca891b0e9ae2f1156d2473 5 Filepath: strings.txt 6 Branch: origin/master 7 Commit: WIP 8 9 +SECRET_KEY=c0dd1e1eaf1e757e55e118fea7caba55e7105e51eaf1e55c0caa1d05efa57e57 10 +GH_API_TOKEN=1abb1ebab1e5e1ec7ed5c07f1abe118b0071e551005edf1a710c8c10aca5ca1d
Warning
An attacker as root in a process namespace can dump the memory of any other process in the namespace. The root user in the host process namespace can dump any process memory on the node (including child namespaces).
Avoid this type of attack in a cloud native application by retrieving secrets at time of use from a filesystem or key management system. If you can discard the Secrets from memory when not in use, you’ll be more resilient to this attack. You can also encrypt Secrets in memory, although the decryption keys suffer the same risk of being dumped and so should also be discarded when not in use.
Honeypots

Although IDS can detect and prevent almost all abuses of your systems, we cannot emphasize enough that there is no such thing as a silver bullet. It should be assumed that rogue sea dogs like Captain Hashjack will still be able to bypass any careful security configuration. A complex system offers asymmetrical advantage for an attacker: a defender only has to make one mistake to get compromised.
Attackers may still be able to escape from a container or traverse onto the host. Or, if they’re in a container governed by IDS and manipulates the expected behavior of the application (for example, by invoking the same application with different flags), they may be able to read sensitive data without triggering IDS alarms.
So the last line of defense is the humble honeypot, a simple server or file that legitimate applications never use. It innocuously nestles in a tempting or secured location and triggers an alert when an attacker accesses it. Honeypots might be triggered by a network scan, or HTTP requests that the system would never usually make.
Figure 9-1 shows BCTL’s honeypot entrapping Dread Pirate Hashjack. A honeypot such as this one is as simple as using tools like ElastAlert to monitor, audit, and access logs for pods that should never be accessed.
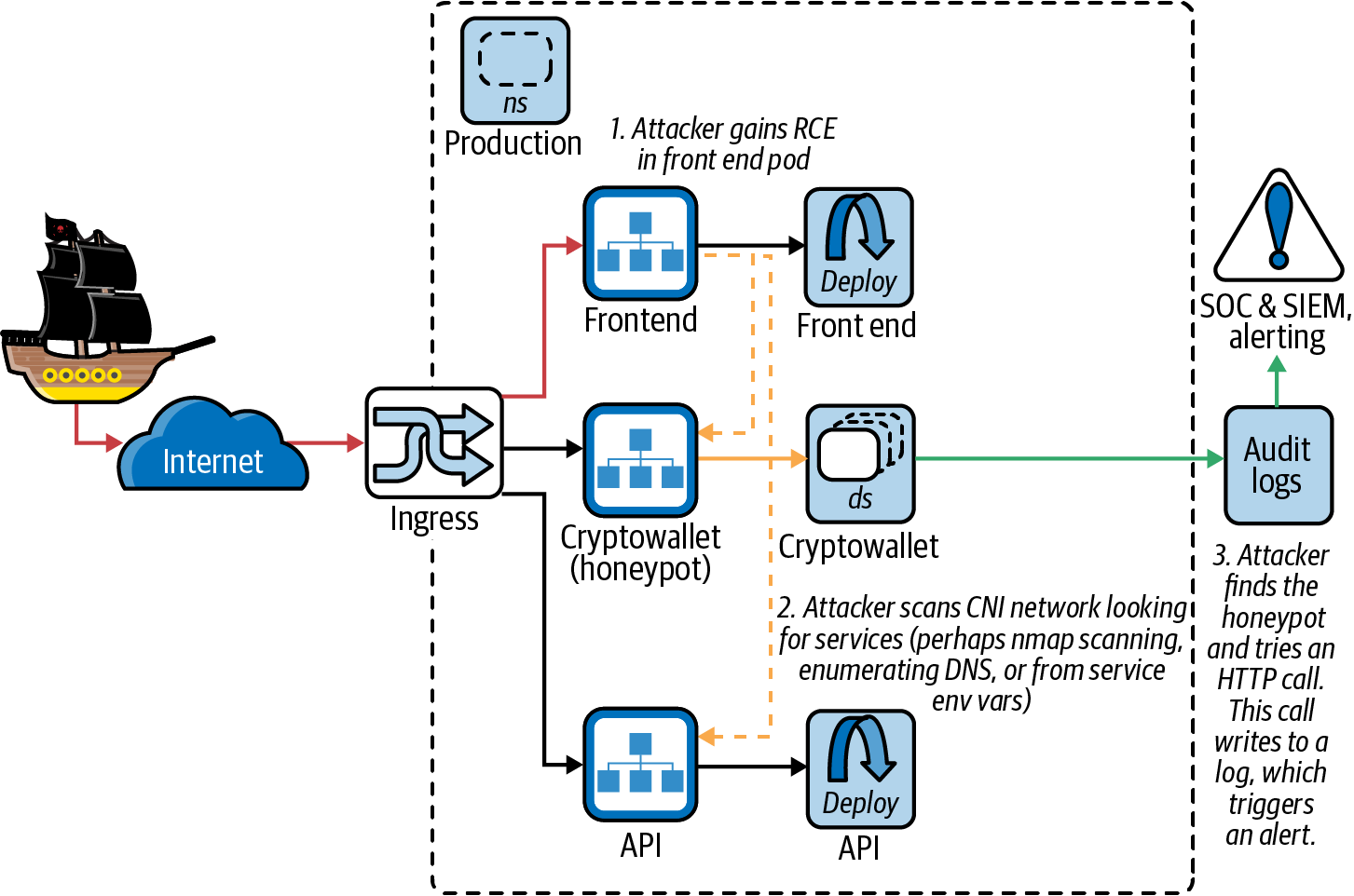
Figure 9-1. Catching an attacker in a honeypot
You are looking to catch an attacker operating inside the pod network. They may scan local IP ranges for open TCP and UDP ports. Remember that each Kubernetes workload must be identical, so we can’t run “custom” pods to deploy a single honeypot. Instead, deploy a dedicated DaemonSet so each node is defended by a honeypot pod.
If the attacker or internal actor has cluster DNS access, can read a pod’s environment variables, or has read access to the Kubernetes API, they can see the names of the Kubernetes services in the DNS and pod names. They may be looking for a specifically named target. You can name your honeypot service with an appealingly similar name (such as “myapp-data” or “myapp-support”) to entice an attacker. Deploying honeypots as a DaemonSet will ensure one is lying in wait on any node Captain Hashjack might plunder.
Note
Canary tokens are honeypots for protocols like AWS and Slack keys, URLs, DNS records, QR codes, email addresses, documents, and binaries. They are “tiny tripwires” that you can drop in production systems and developer devices to detect compromise.
Auditing
As discussed in Chapter 8, Kubernetes generates audit logs for every API request it receives, and IDS tools can ingest and monitor that stream of information for unexpected requests. This could include requests from outside known IP ranges or expected working hours, honeytoken credentials, or attempts to use unauthorized APIs (e.g., a default service account token attempting to get all Secrets in its namespace or a privileged namespace).
Audit log level and depth is configurable, but as CVE-2020-8563 for Kubernetes v1.19.2 (and CVE-2020-8564, CVE-2020-8565, CVE-2020-8566) shows, defaults were not historically tight enough. Some sensitive request payload information was persisted to logs that could have been read from outside the cluster and then used to attack it.
Unintended data leakage into logs is being mitigated in KEP 1753:
This KEP proposes the introduction of a logging filter which could be applied to all Kubernetes system components logs to prevent various types of sensitive information from leaking via logs…Ensure that sensitive data cannot be trivially stored in logs. Prevent dangerous logging actions with improved code review policies. Redact sensitive information with logging filters. Together, these actions can help to prevent sensitive data from being exposed in the logs.
It can be used with the kubelet flag --experimental-logging-sanitization in v1.20+.
Leaking Secrets into logs and audit streams is common in all technology organizations, and is another reason to avoid environment variables for sensitive information. Developers need introspection and useful output from running programs, but sanitizing debug during development is a rare practice. These debug strings invariably make their way into production, and so searching logs for Secrets is perhaps the only practical way to detect this.
Note
The bugs that gave momentum to the log sanitization focus include:
- CVE-2020-8563
-
Secret leaks in logs for vSphere Provider kube-controller-manager
- CVE-2020-8564
-
Docker config Secrets leaked when file is malformed and
logLevel>= 4 - CVE-2020-8565
-
Incomplete fix for CVE-2019-11250 allows for token leak in logs when
logLevel>= 9 - CVE-2020-8566
-
Ceph RBD adminSecrets exposed in logs when
logLevel>= 4
You can read the disclosure on the Kubernetes Forums.
Detection Evasion
Bypassing Kubernetes audit logs was demonstrated by Brad Geesaman and
Ian Coldwater at RSA 2020.
As Figure 9-2 shows, the etcd datastore in the Kubernetes control plane is highly efficient and resillient,
however it does not support large data sizes. That means request payloads in the audit logs that exceed 256 KB will not
get stored, enabling stealthy behavior with oversized log entries.
Note
An attacker with access to the API server can blackhole, redirect, or tamper with any audit logs that are stored locally.
As a post-mortem exercise it’s useful to explore an attacker’s path, so shipping the API server’s audit logs directly to a remote
webhook backend safeguards against this. Configure the API server to use the flag
--audit-webhook-config-file to ship logs remotely, or use a managed service that configures this for you.
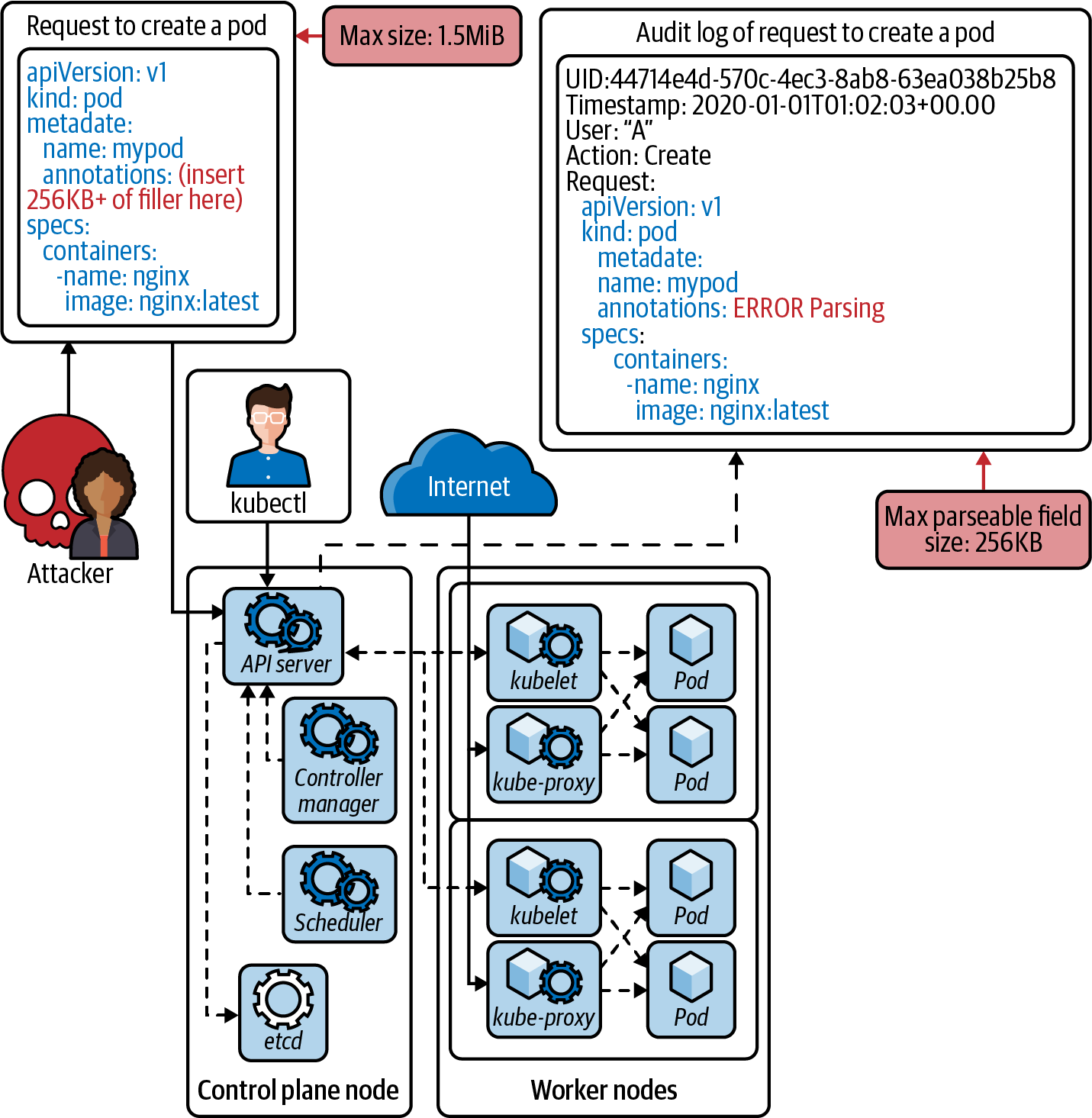
Figure 9-2. Oversize etcd logs (RSA 2020)
Security Operations Centers
Larger organizations may have a Security Operations Center (SOC) that manages security information and events (SIEM).
Configuring enterprise applications for alerting on your audit and pod logs requires fine-tuning to avoid false positives and needless alerts. You can use a local cluster to build out automated tests and capture the audit log events, then use that data to configure your SIEM. Finally, rerun your automated tests to ensure alerts are raised correctly in production systems.
You should run Red Team security tests against production systems to validate the Blue Team controls work as expected. This provides a real-world test for the attack trees and threat models that the system is configured upon.
Conclusion
Intrusion detection is the last line of defense for a cloud native system. eBPF approaches offer greater speed on modern kernels, and the performance overhead is slight. Sensitive or web-facing workloads should always be guarded by IDS as they have the greatest risk of compromise.
With this we’re switching gears and will turn our attention to the weakest link and its natural habitat: organizations.