When a client tries to fetch a list of objects that run into pages, we have to think about how the server can manage to serve the clients with such a massive response without hampering its performance.
Pagination is a concept that helps in serving only part of the data as a response, however, with information about how to access all the data from the server, page by page, without much load and high computation for the server to serve the whole data.
Should we consider a page (of results) as a resource or just a representation of resources? Considering the page as a representation and not as a resource is what we are going to discuss in this section.
As we decided pagination is a resource representation, we will include the pagination information as part of the URI query, that is, xxx.api.com/stocks?page=2.
Please note that pagination as part of the URI path is not an option (as we consider that it is not a resource but resource representation), that is, xxx.api.com/stocks/page/2, as we may not be able to uniquely find the resource between calls.
One problem that we need to solve in the case of pagination for URI queries is encoding, and we can use the standard way of encoding the paging information to do this.
Before we jump into the code, let's have a look at some better API pagination examples in the industry and a few pagination types as well.
Facebook's API uses offset and limit (fields=id, message& amp;limit=5), linkedIn uses start and count (.../{service}?start=10&count=10), and Twitter uses records per page or count (api.twitter.com/2/accounts/abc1/campaigns?cursor=c-3yvu1pzhd3i7&count=50).
There are three variants of resource representation ways of pagination, and they are as follows:
- Offset-based: When a client needs responses based on page count and page number. For example, GET /investor/{id}/stocks?offset=2&limit=5 (returns stocks 2 through 7 ).
- Time-based: When a client needs responses between a specified timeframe and can have a limit as well as part of the parameter to represent the max number of results per page. For example, GET /investor/{id}/stocks?since=xxxxxx&until=yyyyy (returns stocks between a given dates).
- Cursor-based: A technique where a pointer (a built-in bookmark with breadcrumbs) reference of the remaining data is served a specific subset of data as a response and is let off. However, the rest of the data is still needed for later requests until the cursor reaches the end of the records. For example, GET slack.com/api/users.list?limit=2&token=xoxp-1234-5678-90123. The following code explains this:
@GetMapping(path = "/investors/{investorId}/stocks")
public List<Stock> fetchStocksByInvestorId(
@PathVariable String investorId,
@RequestParam
(value = "offset", defaultValue = "0") int offset,
@RequestParam
(value = "limit", defaultValue = "5") int limit) {
return investorService.fetchStocksByInvestorId(investorId, offset, limit);
}
The output of the preceding code is as follows:
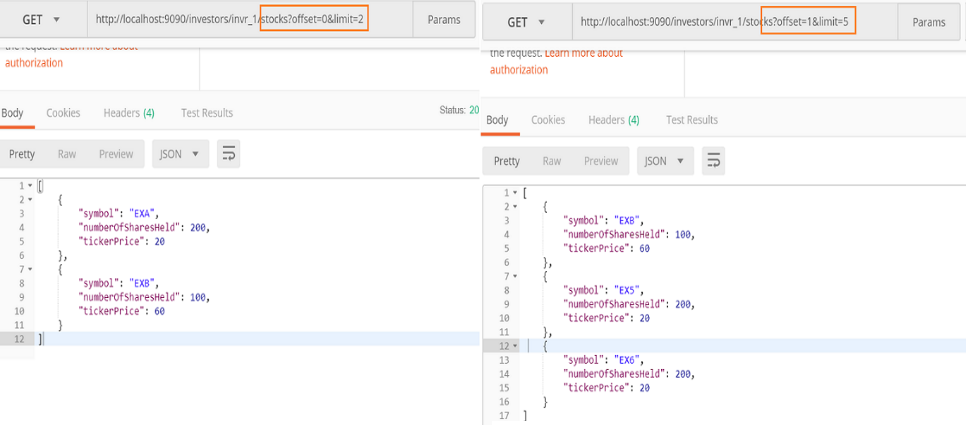
The preceding blocks shows offset-based pagination implementation within our investor service code. We will implement and touch upon other pagination methods, along with sorting and filtering in the next chapter when we discuss versioning and other patterns involving a database.