 Burton H. Bloom proposed his space-efficient filter in 1970 [64] and it is commonly used in networking and database operations. The filter structure uses a set of n elements to respond to membership queries. Chapter 2 covers bloom filters in depth.
Burton H. Bloom proposed his space-efficient filter in 1970 [64] and it is commonly used in networking and database operations. The filter structure uses a set of n elements to respond to membership queries. Chapter 2 covers bloom filters in depth.
Application to Network and IOT
In recent years, networks, cloud computing, and the Internet of Things (IOT) have reshaped the world. Estimates indicate that a billion devices will be connected and generate trillions of terabytes of data by 2023. Among the applications of these systems are airline operations, the insurance industry, the media and entertainment field, and advertising and marketing of products and services.
Objective 15.1 This chapter addresses the applications of indices, skiplists, query resolution via hashing, and security issues affecting cloud computomg. networks and the IOT. Every section includes case studies. The chapter starts with use of bloom filters for click-stream processing. The remaining sections cover fast IP-address lookup and use of integrity verification for cloud and IOT data.
15.1 Click-Stream Processing Using Bloom Filters
The quick growth of online advertisement over the internet plays an important role in the success of the advertising market. One approach for generating revenue is the pay-per-click model. The advertising entity is charged for each key word click. Unfortunately, the increase of click frauds is slowly destroying the entire online advertising market. One step toward solving the problem is detection of duplicate clicks by window systems described below.
Two bloom filter-based algorithms have been proposed to detect duplicates in pay-per-click streams. The group bloom filter (GBF, also known as a jumping window) and the timing bloom filter (TBF, also known as a sliding window) process click streams via small numbers of sub-windows, use memory and computation time economically, and do not produce false negatives.
Burton H. Bloom proposed his space-efficient filter in 1970 [64] and it is commonly used in networking and database operations. The filter structure uses a set of n elements to respond to membership queries. Chapter 2 covers bloom filters in depth.
Bloom filters use windows to detect duplicates in click streams. Clicks, like cookies, have their source IP addresses. Detection of duplicate cookies by passing its identifier through a bloom filter and if the identifier already exists, the duplicate is flagged. Another approxach is to evenly divide a jumping window into sub-windows, each of which has its own bloom filter.
To reduce the complexity of the system, all bloom filters should use the same hash function. Assume a jumping window of size N is divided into Q sub-windows. The bloom filter will expire when the window is full. This means the entire memory space of the expired filter must be cleaned. Cleaning is time-consuming (it requires O(n) time). Extra queue space is required to handle new activity during the cleaning operation.
The extra space required during cleaning is provided by dividing available memory into Q + 1 pieces where Q represents bloom filter space divided by Q active sub-windows. The extra pieces serve as elements in the sub-windows during cleaning and allow more time for the cleaning operation.
GBFs were designed to fill the need for extra queue space during cleaning operations.
GBFs can significantly reduce the memory required to detect duplicates in click streams. The GBF operates by grouping bits with the same indices in bloom filters and nopt in the main memory. This allows the CPU to process the groups instead of individual bits.
For example, let Q active sub-windows = 31 bits and a word in memory = 32 bits. The 32-bit word is generated by the AND operation and held in the bloom filter. The bits constituting a word in an expired bloom filter are masked by setting corresponding bits to 0. If the value of a word is non-zero, the new element is considered a duplicate. For a zero value, set the corresponding bits to 1 and return them to memory [191].
15.2 Fast IP-Address Lookup Using Tries
With the evolution of the Internet of Things (IOT), the number of devices and Internet speed have increased exponentially. The computing world needs fast processing routers and high-speed IP address lookup engine. The role of the router has become crucial since routers forward packets to the appropriate interfaces (ports). Routing millions of packets based on addresses has become extremely difficult. The increase in traffic led to development of an efficient IP lookup algorithm derived from tree-based and trie-based structures [192].
Tree- and trie-based data structures are used in network prefixes. Both structures are discussed in Part I.
The difference between tree- and trie-based approaches is information distribution. Trees hold information by nodes; the number of nodes shows the number of network prefixes. The depth of a binary tree is log (N). Distribution of trie data occurs on the edge.
The right edge of a binary tree handles one bit; the left age is for zero bits. The path from the root to a node defines the network prefix. A prefix in a table should be labeled in a trie tree. The longest prefix indicates the depth of the table. The latency of the lookup algorithm in a binary trie is measured in amount of memory accessed which is equal to data structure depth. Disadvantages of a binary tree are rebalance overload, and smaller depth than a binary trie.
Memory consumption of tree and tries is calculated by using the number of nodes in the data structure and sizes of all nodes. Tries hold more nodes than trees since some nodes in a trie do not correspond to valid prefixes; the numbers correspond in a tree.
A tree may seem to require less memory than a trie, but node size is smaller in tries. A tree requires 64 bits per node; a trie requires only 32. The multibit trie is an improvement of a binary trie in that it increases speed. The Depth of Multibit tries is lesser as compared to binary tries. It makes the multibit tree faster as compare to binary tries. For example, the IP address is of 32 bit which can be represented as 192.16.73.2. The IP address segment can be represented as four octets(192,16,73,2). The depth of the tree in multibit trie is equaled to the four octets. The memory utilized in multibit tries depends on the number of octets and the length of each octet.
It is difficult to state definitive information about memory consumption of trees, tries, and multibit tries because memory consumption always depends on the memory needs of an operation.
A combination of tree and trie data structures can provide maximum compression.
Figure 15.1 compares memory consumption of a tree with the consumption achieved by a combination of a tree and a trie. The most significant 16 bits are considered at the first step; the depth of the structure should never exceed 18 bits [192, 168].
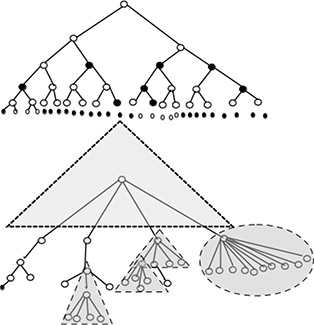
Figure 15.1: (a) Binary trie showing network prefixes in 6-bit address space; (b) Combination of tree and trie shown in (a)
15.3 Integrity Verification: Cloud and IOT Data
Data protection is vital for users. Cloud computing is effective because it provides quality service while maintaining user privacy and security. Data stored in the cloud are generated by the IOT, businesses, governments, and individuals. Data integrity is vital, especially for outsourced data [197]. Much recent research has focused on data integrity verification.
Data integrity is achieved by preventing alteration by an intruder. Proposed data integrity measures include checksums, trapdoor hash functions, message authentication codes (MACs), digital signatures and other hash-based approaches. While many methods can ensure data integrity, cloud users must still have a trusted party verify their data remotely.
A cloud server must verify data from an external party independent of the cloud service provider.
One approach is retrieving and downloading all data to be verified from its server but this approach is not feasible. The large amount of data increases time consumption and communication overheads.
An authenticated data structure based on data positions and paths from roots can be used. Two examples are the Merkle hash tree (MHT) and the rank-based authenticated skiplist (RASL).
The MHT [164] is an authentication structure used to verify dynamic data updates. It is similar to a binary tree in which each node N can have a maximum of two child nodes. Information stored in each N node in MHT T is H hash value. In a tree construction a parent of node N1 = {H1, rN1} and N2={H2, rN2} is constructed as NP={h(H1 || H2} where H1 and H2 are information pieces stored in N1 and N2 nodes respectively. Each leaf node (LN) is based on a message m1.
The RASL authenticates data content and indices of data blocks. The RASL skiplist [167] included a provable data possession (PDP) scheme to provide efficient integrity checks of outsourced data. The RASL was the first scheme to provide simultaneous authentication and public verifiability. Its logarithmic complexity is similar to that of the block system of the MHT.
Project 15.1 — Attacker tracing using packet marking. Marking schemes for network packets are used extensively for network security. They simplify the tasks of packet analysis and IP source tracking [198].
Propose a marking scheme that will provide a convenient way for a user to accurately identify an attacker. Your solution should be flexible: change as situations change and modify its marking style based on router loads. Your project should include the ability to retrace sources even during heavy router loads (hint: use hash technique).
Project 15.2 — Controlling network congestions using internet border patrolling. Congestion control is a vital factor in network implementation. The efficiency of existing algorithms in controlling congestion remains to be proven. Your project is to propose an Internet border patrol scheme [199] to perform surveillance of packets and questionable data at network borders. To increase efficiency and stabilize bandwidth flow by allocating resources, use the enhanced core stateless fair queuing (ECSFQ) algorithm [200].
Project 15.3 — Delay-tolerant networks and epidemic routing. End-to-end connections occur rarely or never in delay-tolerant networks (VANET and interplanetary networks for example). One solution [NOTE: you haven’t stated a problem that needs solution.] is to use epidemic routing [201] based on a flooding-based algorithm that replicates, stores and forwards data. Replication is achieved by exchanging summary vectors (data structures for tracking unavailable data in nodes). A normal bloom filter serves as the data structure. However, summary vectors suffer from collision. Your project is to design a modified summary vector that can accommodate large amounts of data. [Hint: Read Chapter 2.]
Project 15.4 — Network-based stock price system. Assume that a stock market needs to track and update its records constantly and these tasks require frequent server interactions. Stock prices change often so accuracy of update information is vital. Choose a data structure to design a robust price update system and explain why the chosen data structure is appropriate for this scenario.