Event sourcing is another way to implement applications using an event-driven approach, where the core of the functionality is based on the use of commands that produce events that change the system state once they have been processed.
We can think of a command as the result of a transaction executed within the system. This transaction would be different depending on factors such as the following:
- User actions
- Messages received from other applications
- Scheduled tasks performed
Applications created using an event-sourcing approach store the events associated with the executed commands. It's also worth storing the commands that produced events. This makes it possible to correlate all of them in order to get an idea of the boundaries that were created.
The main reason to store events is to use them whenever you want to rebuild the system state at any point in time. A way to make this task easier is by periodically generating backups for the database that stores the system state, which is helpful for avoiding the need to reprocess all the events that were created since the application started to work. Instead, we will just need to process the set of events that were executed after the database snapshot was generated.
Let's review the following set of diagrams to understand how this works. The first diagram shows that once Command A is executed, three Events are created, and a new State is generated after each one of them is processed:

The following diagram represents quite a similar process. In this case, two Events were created as a result of the Command B execution:
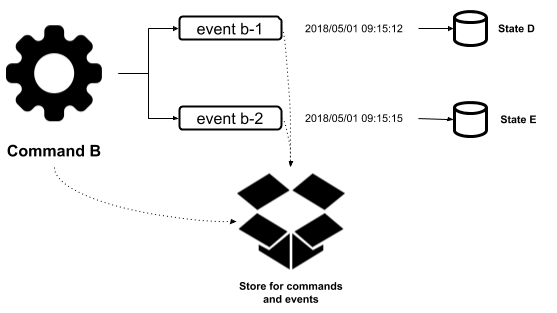
- State A
- State B
- State C
- State D
- State E
Let's say we are interested in debugging Event b-1 because, when it was executed, the application crashed. To achieve this goal, we have two options:
- Process the events one by one and study the application behavior during the Event b-1 execution, as shown in the following diagram:
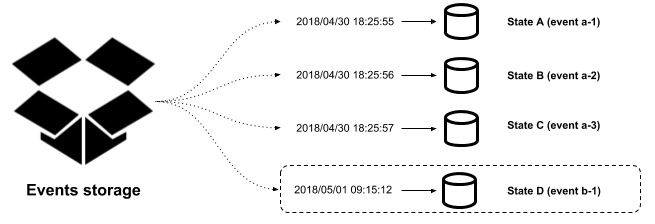
- Process the rest of the events after restoring a database snapshot and study the application behavior during the Event b-1 execution, as shown in the following diagram:
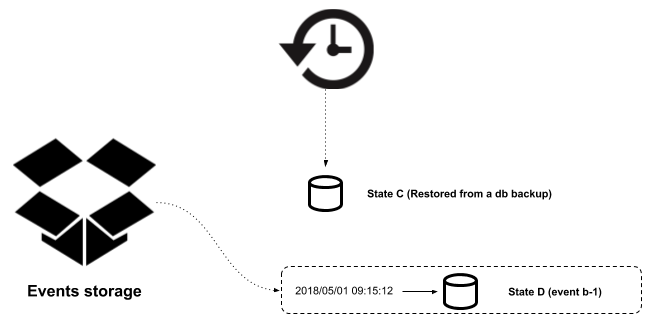
Obviously, the second approach is much more efficient. Scheduled tasks are often in charge of creating database snapshots after a certain period of time, and a policy should be established to manage the existing snapshots. For example, you can establish a policy to create a new snapshot every single day at midnight and get rid of old snapshots after the most convenient period of time for your business.
As you may have realized, the source of truth for our system is the events storage, which allows us to rebuild the application state at any time. Since the events are being used to generate the system state, we can 100% rely on the events storage. However, we should also consider the fact that an event execution within a system would also require interaction with another application. In this case, if you replay that event, you should think about how the other system(s) will be affected. Here, we would end up with one of the two following scenarios:
- The operations executed in the other application(s) are idempotent
- The other application(s) will be affected because a new transaction will be generated
In the first case, since the operations are idempotent, we don't have to be worried at all. This is because another execution will not affect the other system(s). In the second case, we should consider a way to create compensation operations or a way to ignore these interactions to avoid affecting the other systems.
The inherent benefits that we are going to have after following this approach are as follows:
- A data store that can be used for auditing purposes
- An excellent logging level
- It will be easier to debug an application
- A historic state
- The ability to go back in time to a previous version of the state
The quintessential example for event-sourcing applications is version control systems (VCS) such as Git, Apache subversion, CVS, or any other version control system where all the changes that are applied in the source code files are stored. Furthermore, the commits represent the events that allow us to undo/redo changes when required.
In order to make it as simple as possible to understand, you can think of an event-sourcing application as something that manages data changes in the same way that a version control system manages file changes. You can also think about a git push operation as a command in an event-sourcing system.
Now that we have explained the underlying concepts behind event sourcing, it's time to dive into details that will allow us to understand how to implement a system following this approach. Although there are different ways to create event-sourcing applications, I'll explain a generic way to do it here. It is important that you keep in mind that this approach should be changed depending on the particular needs or assumptions that you need for your business.
We mentioned that an event-sourcing system should have at least two places in which to store the data. One of these will be used to save event and command information and the other one will be used to save the application state—we say at least two because more than one storage option is sometimes needed to persist the system state of an application. Since the input retrieved by the system to perform their business processes are very different from each other, we should consider using a database that supports the ability to store data using a JSON format. Following this approach, the most basic data that should be stored as part of a command that is executed within an event-sourcing system is as follows:
- Unique identifier
- Timestamp
- Input data retrieved in JSON format
- Any additional data to correlate commands
On the other hand, the recommended data that should be stored for an event is as follows:
- Unique identifier
- Timestamp
- Relevant data for the event in JSON format
- Identifier of the command that generated the event
As we mentioned earlier, depending on your business needs, you would need to add more fields, but the ones mentioned earlier are necessary in any case. The key here is to make sure that your data will be able to be processed later to recreate the application state when that's needed. Almost any NoSQL database has support to store data as JSON, but some SQL databases, such as PostgreSQL, can also deal with data in this format very well.
On the subject of the system state, the decision of choosing an SQL or NoSQL technology should completely depend on your business; you don't have to change your mind just because the application will be built using an event-sourcing approach. Furthermore, the structure of your data model should also depend on the business itself rather than on the events and commands that generate the data that will be stored there. It is also worth mentioning that one event will generate data that will be stored in one or more tables of the system state data model, and there are no restrictions at all in these terms.
When we think about commands, events, and states, a question that is usually raised is with regards to the order in which the information is persisted. This point would be an interesting discussion, but you don't have to worry too much about the order in which the data was persisted. You can choose to persist the data synchronously or asynchronously in any of the data storage instances.
An asynchronous approach sometimes leads us to think that we will end up having inconsistent information, but the truth is that both approaches could lead us to that point. Instead of thinking about synchronous or asynchronous processing, we should consider mechanisms to recover our app from these crashes, such as proper logging, for example. Good logging would be helpful for recovering the data of our systems in exactly the same way as we do for applications that are built using any approach other than event sourcing.
Now it's time to review some code to put the concepts that we discussed previously into practice. Let's build an application that allows us to open a new bank account. The input data required will be as follows:
- Customer name
- Customer last name
- An initial amount of money to open the account
- Account type (savings/current)
After creating the account, our application state should reflect one new customer and a new bank account that has been created.
As part of our application, we will have one command: CreateCustomerCommand. This will generate two events, named CustomerCreated and AccountCreated, as shown in the following diagram:
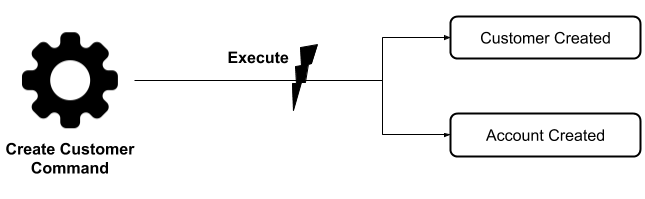
Once this command is executed, a few things need to happen:
- The command should be saved
- The aforementioned events should be created with the relevant information for them
- The events should be saved
- The events should be processed
The relevant code for this process is shown in the following code:
public class CreateCustomerCommand extends Command {
public void execute() {
String commandId = UUID.randomUUID().toString();
CommandMetadata commandMetadata
= new CommandMetadata(commandId, getName(), this.data);
commandRepository.save(commandMetadata);
String customerUuid = UUID.randomUUID().toString();
JSONObject customerInformation = getCustomerInformation();
customerInformation.put("customer_id", customerUuid);
// CustomerCreated event creation
EventMetadata customerCreatedEvent
= new EventMetadata(customerInformation, ...);
// CustomerCreated event saved
eventRepository.save(customerCreatedEvent);
// CustomerCreated event sent to process
eventProcessor.process(customerCreatedEvent);
JSONObject accountInformation = getAccountInformation();
accountInformation.put("customer_id", customerUuid);
// AccountCreated event creation
EventMetadata accountCreatedEvent
= new EventMetadata(accountInformation, ...);
// AccountCreated event saved
eventRepository.save(accountCreatedEvent);
// AccountCreated event sent to process
eventProcessor.process(accountCreatedEvent);
}
...
}
Once the events are handled, the system state should be generated. In this case, it means a new customer and a new account should be created, as shown in the following diagram:
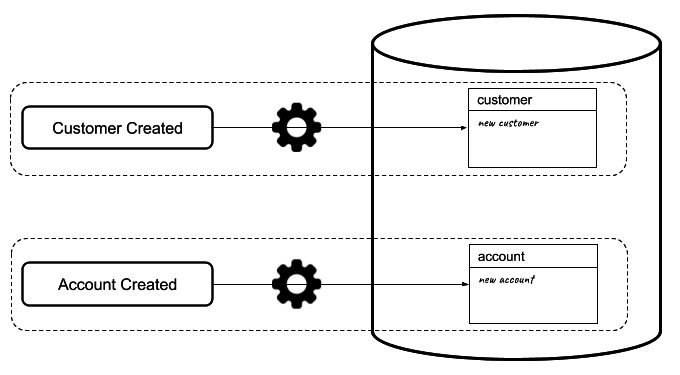
To achieve this goal, we have a pretty basic implementation that, depending on event name, executes code instructions, as shown in the following code:
@Component
public class EventProcessor {
public void process(EventMetadata event) {
if ("CustomerCreated".equals(event.getEventName())) {
Customer customer = new Customer(event);
customerRepository.save(customer);
} else if ("AccountCreated".equals(event.getEventName())) {
Account account = new Account(event);
accountRepository.save(account);
}
}
...
}
If you want to see how the application works, you can execute the following CURL command:
$ curl -H "Content-Type: application/json" \
-X POST \
-d '{"account_type": "savings", "name": "Rene", "last_name": "Enriquez", "initial_amount": 1000}' \
http://localhost:8080/customer
You will see the following messages in the console :
COMMAND INFORMATION
id: 8782e12e-92e5-41e0-8241-c0fd83cd3194 , name: CreateCustomer , data: {"account_type":"savings","name":"Rene","last_name":"Enriquez","initial_amount":1000}
EVENT INFORMATION
id: 71931e1b-5bce-4fe7-bbce-775b166fef55 , name: CustomerCreated , command id: 8782e12e-92e5-41e0-8241-c0fd83cd3194 , data: {"name":"Rene","last_name":"Enriquez","customer_id":"2fb9161e-c5fa-44b2-8652-75cd303fa54f"}
id: 0e9c407c-3ea4-41ae-a9cd-af0c9a76b8fb , name: AccountCreated , command id: 8782e12e-92e5-41e0-8241-c0fd83cd3194 , data: {"account_type":"savings","account_id":"d8dbd8fd-fa98-4ffc-924a-f3c65e6f6156","balance":1000,"customer_id":"2fb9161e-c5fa-44b2-8652-75cd303fa54f"}
You can check the system state by executing SQL statements in the H2 web console available in the URL: http://localhost:8080/h2-console.
The following screenshot shows the result of querying the Account table:
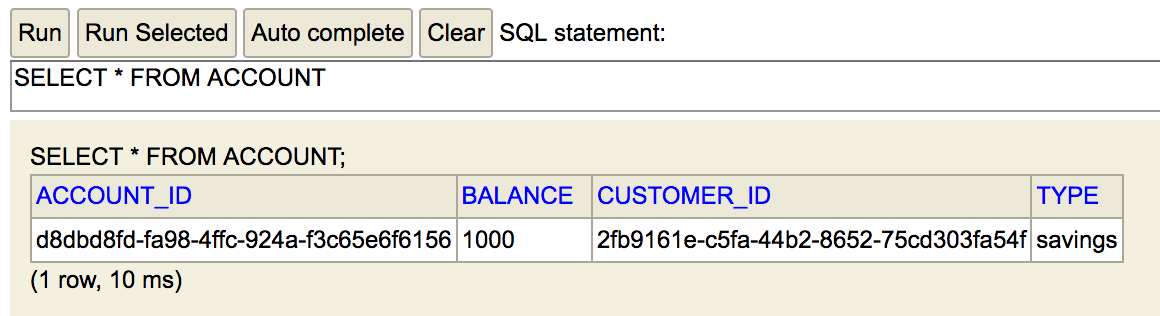
The following screenshot shows the result of querying the Customer table:
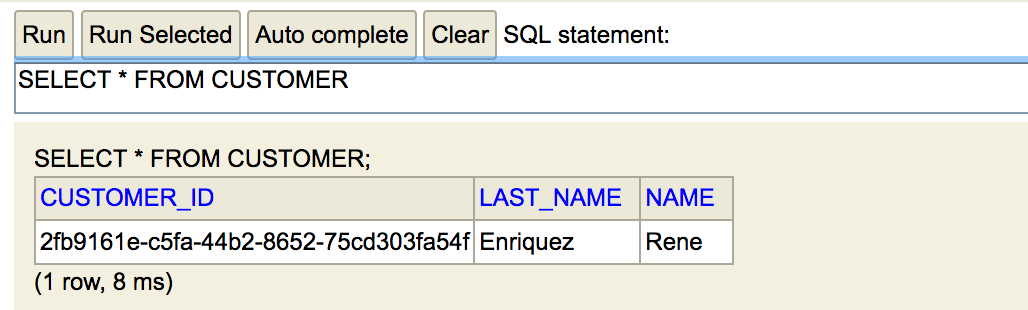
The most crucial test for an event-sourcing application is the ability to recreate the state once the data is deleted. You can run this test by deleting the data from the table using the following SQL statements:
DELETE FROM CUSTOMER;
DELETE FROM ACCOUNT;
After executing these operations in the H2 console, you can recreate the state by running the following CURL command:
$ curl -X POST http://localhost:8080/events/<EVENT_ID>
Note that you will need to replace the <EVENT_ID> listed in the preceding URL with the values listed in the console when the command was executed.