Chapter 6
Working with the Shell
Now that you have a grasp of installing a Linux distribution and managing its software, it's time to start digging into the basics of command‐line work. As a system admin, you need to be proficient at using the Bash shell. Often this includes being fast at the CLI and knowing how to get help without engaging the Internet. In addition, understanding how variables operate in this environment and how to use special shell features, such file descriptors, will work to your advantage. These abilities not only will improve your career at the command line but will allow you to spend less time there.
Our goal in this chapter is to assist you in learning or reinforcing some basic and important skills at the command line. Knowing these basics will serve you well through the rest of this book (and your sysadmin career).
Exploring the Shell
Before the days of graphical desktops, the only way to interact with a Unix system (Linux's predecessor) was through a text command‐line interface (CLI) provided by the shell. The CLI allowed text input only and could display only text and rudimentary graphics output.
Things are significantly different in today's Linux environment. Just about every Linux desktop distribution uses some type of graphical desktop environment. However, to enter shell commands on a server Linux system that doesn't run a graphical environment, you still need a way to reach the shell's CLI.
Fortunately, you can access the Linux system via text mode. This provides nothing more than a simple shell CLI on the monitor, just like the days before graphical desktops. This mode is called the Linux console because it emulates the old days of a hardwired console terminal and is a direct interface to the Linux system.
When the Linux system starts, it automatically creates several virtual consoles. A virtual console is a terminal session that runs in Linux system memory. Instead of having several physical terminals connected to the computer, most Linux distributions start five or six (or sometimes even more) virtual consoles that you can access from a single computer keyboard and monitor.
Text mode virtual consoles use the whole screen and start with the text login screen displayed. Figure 6.1 shows an example of a text login screen from a CentOS virtual console.
FIGURE 6.1 Text mode virtual console login screen
You log into a console terminal by entering your username after the login prompt and typing your password after the Password prompt. If you have never logged in this way before, be aware that typing your password is a different experience than in a graphical environment! In a graphical environment, you may see dots or asterisks indicating the password characters as you type. However, at the virtual console, nothing is displayed when you type your password.
You'll know that you have successfully logged into the Linux system and reached the CLI when you get a shell prompt. We'll cover that next.
The Shell Prompt
Once you log in to a Linux virtual console, you get access to the shell CLI prompt. The prompt is your gateway to the shell. This is the place where you enter shell commands.
The default prompt symbol for the Bash shell is the dollar sign ($). This symbol indicates that the shell is waiting for you to enter text. Different Linux distributions use different formats for the prompt. On the Ubuntu Linux server you installed in Chapter 2, “Installing an Ubuntu Server,” the shell prompt probably looked similar to this:
sysadmin@ubuntu-server:~$whereas on the CentOS Linux server you installed in Chapter 4, “Installing a Red Hat Server,” it looked similar to this:
[sysadmin@localhost ~]$Besides acting as your access point to the shell, the prompt can provide additional helpful information. In the two preceding examples, the current user ID name, sysadmin, is shown in the prompt. Also, the name of the system is shown, ubuntu‐server on the Ubuntu system and localhost on the CentOS machine. (You may also see a ~, which is a special character that represents your home directory.) You'll learn later in this chapter about how to modify this shell prompt.
Think of the shell CLI prompt as a helpmate, assisting you with your Linux system, giving you helpful insights, and letting you know when the shell is ready for new commands. Another helpful item in the shell is the manual.
The Shell Manual
Most Linux distributions include an online manual for looking up information on shell commands, as well as lots of other GNU utilities included in the distribution. You should become familiar with the manual, because it's invaluable for working with commands, especially when you're trying to figure out various command‐line parameters.
The man command provides access to the manual pages stored on the Linux system. Entering the man command followed by a specific command name provides that utility's manual entry. Figure 6.2 shows an example of looking up the apt command's manual pages. This page was reached by typing the command man apt on an Ubuntu system.

FIGURE 6.2 Manual pages for the apt command
Notice the apt command's DESCRIPTION paragraph in Figure 6.2. It is rather sparse and full of technical jargon. The Bash manual is not a step‐by‐step guide, but instead a quick reference.
When you use the man command to view a command's manual, the information is displayed with something called a pager. A pager is a utility that allows you to view text a page (or a line) at a time. Thus, you can page through the man pages by pressing the spacebar, or you can go line by line using the Enter key. In addition, you can use the arrow keys to scroll forward and backward through the information. Specifically, the man pages use the less pager utility. If you'd like to find out more about less, type man less at the command line, and press Enter.
When you are finished with the man pages, press the Q key to quit. When you leave the man pages, you receive a shell CLI prompt, indicating the shell is waiting for your next command.
The manual page divides information about a command into separate sections. Each section has a conventional naming standard, as shown in Table 6.1.
TABLE 6.1: The Linux Man Page Conventional Section Names
| SECTION | DESCRIPTION |
|---|---|
| Name | Displays the command name and a short description |
| Synopsis | Shows command syntax |
| Configuration | Provides configuration information |
| Description | Describes the command generally |
| Options | Describes the command option(s) |
| Exit Status | Defines the command exit status indicator(s) |
| Return Value | Describes the command return value(s) |
| Errors | Provides command error messages |
| Environment | Describes environment variable(s) used |
| Files | Defines files used by the command |
| Versions | Describes command version information |
| Conforming To | Provides the standards that are followed |
| Notes | Describes additional helpful command material |
| Bugs | Provides the location to report found bugs |
| Example | Shows command use examples |
| Authors | Provides information on command developers |
| Copyright | Defines command code copyright status |
| See Also | Refers to similar available commands |
Not every command's man page has all the section names described in Table 6.1. Also, some commands have section names that are not listed in the conventional standard.
In addition to the conventionally named sections for a man page, there are man page section areas. Each section area has an assigned number, starting at 1 and going to 9; they are listed in Table 6.2.
TABLE 6.2: The Linux Man Page Section Areas
| SECTION NUMBER | AREA CONTENTS |
|---|---|
| 1 | Executable programs or shell commands |
| 2 | System calls |
| 3 | Library calls |
| 4 | Special files |
| 5 | File formats and conventions |
| 6 | Games |
| 7 | Overviews, conventions, and miscellaneous |
| 8 | Super user and system administration commands |
| 9 | Kernel routines |
Typically, the man utility provides the lowest numbered content area for the command. For example, looking back to Figure 6.2 where the command man apt was entered, notice that in the upper‐left and upper‐right display corners, the word APT is followed by a number in parentheses, (8). This means the man pages displayed are coming from content area 8 (super user and system administration commands).
Your Linux system may include a few nonstandard section numbers in its man pages. For example, 1p is the section covering Portable Operating System Interface (POSIX) commands, and 3n is for network functions.
Occasionally, a command has the same name as a special file or overview section in the man pages, and thus the name is listed in multiple section content areas. For example, the man pages for passwd contain information on the command as well as a file. Typically by default, the man information for the lowest section number is displayed, so if you type in man passwd, you'll see information on the passwd command from section 1. To get around the default section search order, type man section# topicname
. Thus, to see the passwd file man pages in section 5, type man 5 passwd.
You can also step through an introduction to the various section content areas by typing man 1 intro to read about section 1, man 2 intro to read about section 2, man 3 intro to read about section 3, and so on.
Now that you know how to get help, you can begin more in‐depth experimentation with various shell commands. We'll cover that topic next.
Working with Commands
Although you've already entered several Bash shell commands in the CLI so far in this book, it's a good idea to stop and examine the process. There are also several tricks and tips to explore that will help you get your shell work done faster. We'll look at those items in this section along with some rather useful, but tricky, methods to save and/or manipulate your command‐line work.
Entering Commands
Commands you enter at the command‐line prompt are actually programs. When you enter the program name at the shell prompt and press Enter, this instructs the Bash shell to run the named program. Either these programs are built into the shell or they are external and reside in the Linux virtual directory structure (the Linux directory structure is covered in more detail within Chapter 7).
These programs have a basic syntax for their use, as follows:
CommandName Option(s) Argument(s)An example is the man ‐k cp command used earlier in this chapter. The breakdown of this command syntax is as follows: man is the CommandName
, ‐k is the Option
, and cp is the Argument
. The Option(s) and Argument(s) are not required. When added, they are used to modify the behavior of the command and/or redirect on what the program is operating.
It's important to understand that commands are programs, because many of these programs have different authors. Therefore, a command may or may not use the basic syntax. For example, the type command requires that you provide it with an argument, or nothing is displayed—not even an error message!
If you are unfamiliar with a particular command, it's a good idea to view its man page. The Synopsis section will provide you with the syntax for the command, as shown in Figure 6.3 for the uname command.
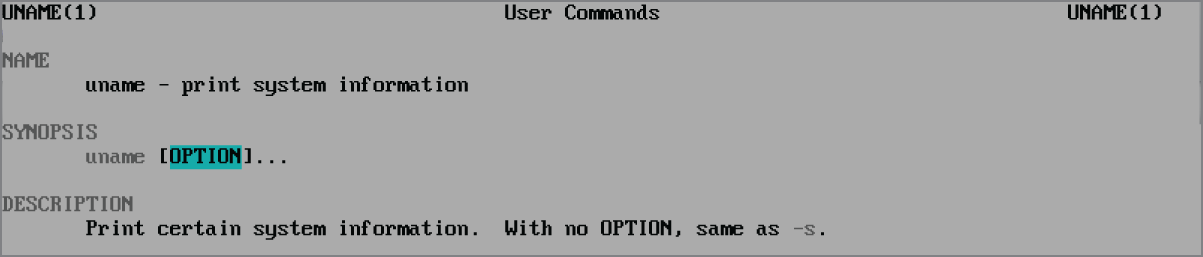
FIGURE 6.3 Manual pages for the uname command
In a command's man page Synopsis section, brackets indicate that a particular item is not required. Thus, from the information in Figure 6.3, you can successfully use the uname command without providing any options. Knowing the right syntax for a command will speed up your command‐line work.
Learning to work quickly in the Bash shell has many advantages. For instance, if there is a problem, knowing the various methods for issuing commands quickly will help in eliminating the difficulty faster. And who wouldn't like to finish work for the day a little sooner? That's another nice benefit of Bash shell command‐line speed.
Retrieving Past Commands
One method for getting things done faster is using command‐line history. All the commands you type at the prompt are stored in a history list. You can retrieve commands from this list and reissue them with minimal typing. In addition, you can modify the commands to make them operate slightly different.
To see your history list, type in the history command with no options.
$ history[…]11 exit12 man -k copy13 apropos copy[…]19 type help[…]28 cat /proc/version[…]34 history$
In this example, the listing is snipped and only some of the commands are shown. Typically, the last 1,000 commands are kept in the history list.
You can recall and reuse the last command in your history list. This can save time and typing. To recall and reuse your last command, type !! and press the Enter key.
$ type manman is /usr/bin/man$ !!type manman is /usr/bin/man$
When !! was entered, the Bash shell first displayed the command it was recalling from the shell's history list. And after the command was displayed, it was executed. You can also just press the up‐arrow key and press the Enter key to recall and reuse your last command from command history.
To recall a command that is higher up the list, type !
# and press Enter. The # is the number corresponding to the command you want to reuse.
$ history[…]12 man -k copy13 apropos copy[..]16 whatis cp[…]28 cat /proc/version[…]$$ !16whatis cpcp (1) - copy files and directories[…]$
Command 16 was pulled from the history list. Notice that similar to executing the last command in history, the Bash shell first displays the command it is recalling from the shell's history. After the command is displayed, it is executed.
You can also edit commands, before running them, which is useful for adding different options and/or arguments. However, you're forced to use the up‐arrow key to recall the command prior to modifying it.
The history list is kept in memory. But when you log out, the list is saved in a special file, the .bash_history file, which is located in each user's home directory. When you log in again, the file's contents are loaded into the history list in memory.
Table 6.3 contains a few of the more commonly used history command options. These options are useful for managing the history list as well as the history file.
TABLE 6.3: A Few history Command Options
| OPTION | DESCRIPTION |
|---|---|
‐a |
Appends the current history list to the history file |
‐c |
Clears the history list of contents |
‐n |
Appends history file commands to the current history list, but only if they have not already been put into the list |
‐w |
Writes the current history list to the history file |
If you have multiple terminal sessions open, automatically update the history lists in your other open terminal sessions by issuing the history ‐a command in the terminal session whose history you want to save. Then in the other terminal sessions, use the history ‐n command to update their history lists.
Redirecting Commands
One of the neat things you can do at the Linux CLI is redirect commands. By default, command output goes to your terminal screen, and input into the CLI comes from your keyboard or mouse. However, you can modify this behavior.
The Linux system handles every object as a file, including the input and output process. Linux identifies each file object using a file descriptor, which is an integer that uniquely identifies open files in a session. The Bash shell reserves the first three file descriptors (0, 1, and 2) for the purposes shown in Table 6.4. These three special file descriptors handle the input and output from the CLI.
TABLE 6.4: Linux Standard File Descriptors
| FILE DESCRIPTOR | ABBREVIATION | DESCRIPTION |
|---|---|---|
| 0 | STDIN |
Standard input |
| 1 | STDOUT |
Standard output |
| 2 | STDERR |
Standard error |
REDIRECTING STDOUT
We'll start with redirecting STDOUT, because it typically is the easiest one to understand (and demonstrate). Most Bash commands direct their output to the STDOUT file descriptor by default, but you can redirect that output.
Imagine you just got done issuing several new‐to‐you Bash commands, and you would like to keep a copy of all the commands you used for future study. Recall that the history command, used earlier in this chapter, displays the history list, which would contain all these commands. You can issue the history command and redirect its output this way:
[sysadmin@localhost ~]$ history > keepHistory.txt[sysadmin@localhost ~]$[sysadmin@localhost ~]$ cat keepHistory.txt1 man man2 man -k copy3 apropos copy4 whatis cp5 type man6 uname7 cat /proc/version[…]12 history > keepHistory.txt[sysadmin@localhost ~]$
By using the greater‐than symbol (>), the Bash shell's STDOUT is redirected to the file named keepHistory.txt instead of showing on the screen. To display the file's newly created contents, we used the cat command. (The cat command allows us to display a text file's contents, as was done earlier in this chapter to display the information residing in the /proc/version file.) So all the commands that were in the history list are now saved in a text file. That's useful!
The > STDOUT redirection symbol has a bit of a problem, though. If you use it to redirect output to a pre‐existing file, it will wipe the file's contents and replace it with STDOUT
! Thus, to append STDOUT data to a file, use the >> redirection symbol combination as follows:
[sysadmin@localhost ~]$ cat /proc/version >> keepHistory.txt[sysadmin@localhost ~]$[sysadmin@localhost ~]$ cat keepHistory.txt1 man man2 man -k copy3 apropos copy4 whatis cp5 type man6 uname7 cat /proc/version[…]12 history > keepHistory.txtLinux version 4.18.0-193.28.1.el8_2.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC))#1 SMP Thu Oct 22 00:20:22 UTC 2020[sysadmin@localhost ~]$
So with redirecting CLI output, you can create new files of information or add to them. This is handy, but redirection gets even better.
REDIRECTING STDERR
The shell handles error messages using the special STDERR file descriptor. This is the location where the shell sends error messages generated by the shell or programs and scripts running in the shell. By default, the STDERR file descriptor points to the same place as the STDOUT file descriptor (even though they are assigned different file descriptor values). This means that, by default, all error messages go to the terminal screen.
There may be times you want to save error messages or just not have them display. This is especially true when you run a command that you know will encounter files you don't have privileges to look at, and those error messages are annoying.
To redirect STDERR, you use the same symbol as you did with redirecting STDOUT, but add the standard error file descriptor to it, like this:
[sysadmin@localhost ~]$ hist-bash: hist: command not found[sysadmin@localhost ~]$[sysadmin@localhost ~]$ hist 2> myerr.txt[sysadmin@localhost ~]$[sysadmin@localhost ~]$ cat myerr.txt-bash: hist: command not found[sysadmin@localhost ~]$
In the preceding example, the history command was purposely misspelled, and it generated an error message. That STDERR was directed to the screen. Using the hist 2> myerr.txt command caused the error message to redirect to the myerr.txt file.
Appending an error message file operates in a similar fashion to appending the redirection of STDOUT. You just need to include the STDERR file descriptor again.
[sysadmin@localhost ~]$ hist 2>> myerr.txt[sysadmin@localhost ~]$ cat myerr.txt-bash: hist: command not found-bash: hist: command not found[sysadmin@localhost ~]$
If you don't want to save error messages and just desire not to see them, put them into what is called the black hole, which is the /dev/null file. Using the previous example, our command would now look like hist 2>> /dev/null.
If needed, you can redirect both STDERR and STDOUT to the same file. The Bash shell nicely provides a symbol for this purpose—the ampersand symbol (&). To get both STDOUT and an error message, we'll display a file that exists, /proc/version, and one that does not, NSF.txt, using the cat command.
[sysadmin@localhost ~]$ cat /proc/version NSF.txt &> newerr.txt[sysadmin@localhost ~]$ cat newerr.txtLinux version 4.18.0-193.28.1.el8_2.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC))#1 SMP Thu Oct 22 00:20:22 UTC 2020cat: NSF.txt: No such file or directory[sysadmin@localhost ~]$
So now you can redirect STDOUT and STDERR. Also, if you want, you can redirect them both to the same file. But wait! Redirection gets even better.
REDIRECTING THROUGH PIPES
Some of the most powerful things you can do with redirection involve using pipes. This is not referring that hardware that brings fresh water into your home and wastewater out. Instead, with the CLI, pipes, all you do is chain together the STDOUT of one command to the STDIN of another command. This creates a command pipeline.
The STDIN file descriptor references the standard input to the shell. For a terminal interface, the standard input is the keyboard. The shell receives input from the keyboard on the STDIN file descriptor and processes each character as you type it. The symbol to redirect STDIN for a command is the less‐than symbol (<).
However, to chain together STDOUT as STDIN, the Bash shell provides another symbol: the pipe (|). This symbol is typically located on your keyboard's backslash (\) key and looks like a long, lowercase L.
To demonstrate this, we'll use the history command again. We'll redirect its STDOUT as STDIN into the less pager utility using a pipe so you can view the history list a page at a time.
[sysadmin@localhost ~]$ history | less1 man man2 man -k copy3 apropos copy4 whatis cp5 type man6 uname7 cat /proc/version8 history9 type man[…]23 cat myerr.txt NoSuchFile.txt &> newerr.txt:
If you do use this command on your system, be aware that you can move forward or backward through the less pager utility by pressing the up‐arrow and down‐arrow keys and the Page Up and Page Down keys. However, you'll need to press the Q key to get back to the CLI prompt.
One of the neat things about redirection using pipes is that you can chain together multiple commands! You are not limited to only two commands in a pipeline.
SPLITTING THE REDIRECTION
If you want to not only view the information produced in a command pipeline but also keep a copy, you can do that too. This requires the use of a special command called tee. Like a plumber's tee that directs liquid into two different flows, the tee command will save STDOUT to a file and flow it as STDIN to the next command in the pipeline.
In this example, we are keeping a copy of the history list in the keepHistory.txt file and viewing it through the less pager:
[sysadmin@localhost ~]$ history | tee keepHistory.txt | less1 man man2 man -k copy[…]23 cat myerr.txt NoSuchFile.txt &> newerr.txt:[sysadmin@localhost ~]$[sysadmin@localhost ~]$ cat keepHistory.txt1 man man2 man -k copy[…]23 cat myerr.txt NoSuchFile.txt &> newerr.txt24 cat newerr.txt[…]30 history | less31 history | tee keepHistory.txt | less[sysadmin@localhost ~]$
As you learn additional Bash shell commands, consider how you might redirect their STDOUT and STDERR. In addition, try them in a command pipeline. We'll continue our exploration of the Bash shell by exploring various variables.
Environment Variables
The Bash shell uses a feature called environment variables to store information about the shell session and the working environment. This feature also allows you to store data in memory that can be easily accessed by any program.
There are two environment variable types in the Bash shell: global variables and local variables. This section describes each type of environment variable and shows how to view and use them.
Global Environment Variables
The shell session that starts when a user logs into a virtual console terminal is a parent shell. When the bash command is entered at the CLI prompt, such as when running a shell script (shell scripts are covered in detail in Chapter 19, “Writing Scripts”), a new shell process is created. This is a child shell. Global environment variables are visible not only from the shell session in which they were defined, but from any spawned child subshells.
Local variables are different in that they are available only in the shell that creates them. This fact makes global environment variables useful in applications that create child subshells, which require parent shell information.
The Linux system sets several global environment variables when you start your Bash session. (More details about what variables are started at that time are covered in Chapter 13, “Managing Users and Groups.”) These system environment variables almost always use all capital letters to differentiate them from user‐defined variables.
To view all the currently set global environment variables, use the printenv or the env command, as shown in the following code snippet:
[sysadmin@localhost ~]$ env[…]HOSTNAME=localhost.localdomain[…]USER=sysadmin[…]PWD=/home/sysadminHOME=/home/sysadmin[…]SHELL=/bin/bash[…]HISTSIZE=1000[…][sysadmin@localhost ~]$
You can use the printenv or the echo command to display an individual global environment's contents as follows:
[sysadmin@localhost ~]$ printenv USERsysadmin[sysadmin@localhost ~]$ echo $HOME/home/sysadmin[sysadmin@localhost ~]$
Notice that if you use the echo command, you have to add a dollar sign ($) to the front of the global environment variable's name. The dollar sign is not required with the printenv command.
There are several default global environment variables that are potentially defined on your system(s). Table 6.5 lists a few of the more common environment variables you'll find. Because Linux distributions often add their own environment variables, you'll need to check your Linux distribution's documentation for the entire list.
TABLE 6.5: A Few Common Default Linux Global Environment Variables
| NAME | DESCRIPTION |
|---|---|
BASH |
The full pathname to execute the current instance of the Bash shell |
BASH_VERSION |
The version number of the current instance of the Bash shell |
GROUPS |
A variable array containing the list of groups of which the current user is a member |
HISTFILE |
The name of the file in which to save the shell history list (.bash_history by default) |
HISTSIZE |
The maximum number of commands stored in the history list |
HOME |
The current user's home directory |
HOSTNAME |
The name of the current host |
PATH |
A colon‐separated list of directories where the shell looks for commands |
PS1 |
The primary shell command‐line interface's prompt string |
PS2 |
The secondary shell command‐line interface's prompt string |
PWD |
The current working directory |
SHELL |
The full pathname to the Bash shell |
USER |
Username of current login session |
A couple of interesting variables in Table 6.5 involve the history command we covered earlier in this chapter. Notice the HISTFILE and HISTSIZE variables. Their current settings on this CentOS distribution are as follows:
[sysadmin@localhost ~]$ echo $HISTFILE/home/sysadmin/.bash_history[sysadmin@localhost ~]$[sysadmin@localhost ~]$ echo $HISTSIZE1000[sysadmin@localhost ~]$
You can see that this distribution stores its history list in the .bash_history file (HISTFILE), when the user either logs out of the system or directs the history command to do so. The number of commands that are allowed for the history list to contain is set to 1000 (HISTSIZE), which is more than enough for most cases.
User‐Defined Environment Variables
Local environment variables, as their name implies, are seen only in the local process in which they are defined and are not available to child subshells. The Linux system defines a few standard local environment variables for you, but when you define your own, these are called user‐defined local environment variables.
After you log in to the Linux system or spawn a child shell, you're allowed to create user‐defined local variables that are visible within your shell process. You can assign either a numeric value or a string value to a variable by using the equal sign (=). To keep from tromping on global system‐defined environment variables, it's best to name your user‐defined variables with all lowercase letters.
[sysadmin@localhost ~]$ myvar="Hello World"[sysadmin@localhost ~]$[sysadmin@localhost ~]$ echo $myvarHello World[sysadmin@localhost ~]$
After you define a user variable, any time you need to reference it, just enter its name preceded by a dollar sign, such as $myvar. When you set a user variable using this method, you are creating a user‐defined local environment variable.
If you'd like to remove the variable's value, use the unset command. Here's an example:
[sysadmin@localhost ~]$ echo $myvarHello World[sysadmin@localhost ~]$ unset myvar[sysadmin@localhost ~]$[sysadmin@localhost ~]$ echo $myvar[sysadmin@localhost ~]$
The set command displays both global and local environment variables, user‐defined variables, and local functions. It also sorts the display alphabetically. You should know that the env and printenv are different from set in that they do not sort the variables, nor do they include local environment variables, local user‐defined variables, or local shell functions.
Now you have some great tools to help in your exploration of the Linux CLI. In fact, you can change your prompt to your liking for all your future work through this book.
The Bottom Line
- Decode the shell prompt and the manual pages. The prompt is where you enter shell commands. It provides access to the utilities needed to manage a system. In addition, the shell prompt often gives additional information that can help you at the CLI.
- Master It Imagine that you recently successfully logged in to a Linux system. This particular system uses the CentOS Linux distribution. What sort of items might you see in the shell prompt?
- Decode the shell prompt and the manual pages. The man pages are an online manual that provide information on various shell utilities, special files, system administrator commands, and so on. They are a source of quick help and can be searched to determine the information you need.
- Master It You are attempting to become proficient at using the man pages. However, the pager utility it employs is causing you some frustration, so you attempt to learn more about it without leaving the CLI. How can you accomplish learning more about the pager utility used for the man pages?
- Enter, recall, and redirect shell commands. To function efficiently and effectively at the CLI, recalling shell commands is a critical task. A system admin must be proficient at quickly retrieving, potentially modifying, and using previously issued commands.
- Master It Your main production app on the server is experiencing some performance problems, and you are working as fast as possible to determine and correct the issue(s). You need to recall and reenact a command you used previously. You can see from this history list that it is command 42. What's the fastest way to recall and reuse this command?
- Enter, recall, and redirect shell commands. Being efficient and effective at the command line is more than just being fast. It also requires smart habits. One of these is using command redirection to manage
STDIN,STDOUT, andSTDERR.- Master It You created a nice pipeline of commands to filter and format some needed text file information. You want to view the information but keep a copy of it at the same time. How can you accomplish this?
- Set and use environment variables. Variables help to define your CLI environment. In addition, they allow you to store data in memory that can be easily accessed by any program. Defining a variable, removing a definition, and globalizing a variable are all important management activities.
- Master It You are creating a user‐defined environment variable for an application. Because of the nature of the application, this variable must be available in subshells. What needs to be done to ensure this happens?