Chapter 21
Managing Database Servers
Data is as important as talent, strategy, and sales, and is often central to a business's success. In fact, data is typically considered a company's most important asset. We are now in a data-driven society, and the sheer volume of useful data is growing astronomically. Protecting and managing this data provides your organization with a base for data analysis that can lead to a competitive advantage … or just plain survival.
While you may not be involved in the data analytics side of your company, as a system administrator, you are on the data management side. Whatever data your establishment decides to keep and scrutinize, it is up to you to make sure your fellow employees have fast and appropriate access to it through your administration of the database servers.
Linux Database Servers
We've looked at a lot of text files so far in this book, and they are useful for many different purposes such as storing configuration information, boot messages, Bash scripts, and so on. However, when you have complex data that needs to be stored, processed, and analyzed, simple text files don't work well. Text files are often referred to as flat files, because only basic relationships can exist between the data they contain.
Databases were created to fill the need for complex connections between individual data items. While data is the focus, there are other pieces that make up a database management system (DBMS). A DBMS typically consists of the following parts:
- Database data file(s)
- Query-language interface
- Database engine
Organizing the Data
Back in the 1970s, a database management system architecture, called a relational DBMS (RDBMS), was first conceived. This still-popular model organizes data into three levels:
- Database A database is the largest of the three levels, and it is used to group together related data. While you can have a large single database on a system, it's typical to create a database for every application on a server that needs one. Each database is required to have its own unique name, so it's wise to name the database in a way that relates to the application.
- Table There are typically multiple tables per database. This mid-level organization further refines the data's groupings. For example, if the database contains tree information for a site that sells live fruit trees through a website, one table in the database might be specifically for apple trees, another table for cherry trees, another table for pear trees, and a fourth table for orange trees. Grouping data in a database into tables is called data normalization.
- Field The finest level of detail for data in a database is the field. Using the apple tree table in our tree database as an example, the fields for a single apple tree may be item number, apple tree type, description, tree size, apple color, blooming period, pollinator group, harvest period, and growth zones.
In the apple tree table, each apple tree sold by the company would have its own record. A table record is a collection of fields about the same item. So, in our apple tree table, each type of apple tree sold would have its own record, identified by the item number. This item number is a primary key. Primary keys are used to uniquely identify each record within a table.
It's helpful to see a pictorial view of a database table. Sticking with our fruit-trees-for-sale application, a representation of the database's apple tree table is shown snipped in Figure 21.1.

FIGURE 21.1 Apple tree table representation
In the representation, each row is a record in the table, which is why sometimes database table records are called rows. Each column within the apple tree table is a field, which are why fields are sometimes called columns. Notice that some fields for the records contain the same data, while others do not. For example, item numbers 3247 and 3248 share all the same data in their record fields, except for their primary key (Item #) and TreeSize
—one record has standard (Std) in that field, and one contains Dwarf. A record in a table is a single occurrence of all the values in the record's data fields.
Fields can be different types of data. Table 21.1 shows these standard database data types for an RDBMS.
TABLE 21.1: RDBMS Data Types
| DATA TYPE | DESCRIPTION |
|---|---|
bool |
Boolean value representing either true or false |
char( n ) |
Character string of a fixed n characters in length |
date |
Date expressed in YYYY
-
MM
-
DD format |
datetime |
Date and time expressed in YYYY
-
MM
-
DD HH
:
MM
:
SS format |
float |
Floating-point number |
int |
Integer number |
text |
Character string of a variable length |
varchar( n ) |
Character string of a variable n or fewer characters in length |
These data types are slightly different depending on which RDMBS you use. Also, they may add a few additional types of data.
Querying the Data
Created in the 1970s, Structured Query Language (SQL) was declared a standard by the American National Standards Institute (ANSI) in the mid-1980s. Pronounced sequel, this language is still used to communicate with databases using an RDBMS, and the standard has continued to evolve, making it stronger and more flexible.
What's exciting about SQL is that when you learn the language's syntax, you can use it on nearly all relational databases with few modifications. So, when you have a Linux RDBMS installed on your system, you'll have a place to learn and practice using SQL.
SQL consists of specific instruction commands that are crafted into statements to interface with the database. SQL commands are typically grouped into four different categories (though some special SQL commands fall outside of these categorizations):
- Data definition language (DDL)
- Data manipulation language (DML)
- Transaction control language (TCL)
- Data control language (DCL)
We'll only be using a few basic commands in this chapter that fall into the DDL and DML categories as well as a few that don't fall into any of these groupings. Table 21.2 describes the commands.
TABLE 21.2: A Few Basic SQL Commands
| COMMAND | CATEGORY | DESCRIPTION |
|---|---|---|
CREATE |
DDL | Creates a table, database, or user account |
DESCRIBE |
n/a | Lists a table's field definitions |
DROP |
DDL | Deletes a table, a database, or a user account |
GRANT |
DDL | Grants access to the selected item for the designated user account |
INSERT |
DML | Adds new data records to a table |
SELECT |
DML | Queries data in a table |
SHOW |
n/a | Displays the selected item |
UPDATE |
DML | Modifies current data records in a table |
USE |
n/a | Selects a database to use |
Notice that the commands are in uppercase. This is typical of most SQL commands. Be aware that with some RDBMSs, you can use either lowercase or uppercase, but good form dictates using only uppercase for SQL commands.
Controlling the Data
Access to the data that resides in the database is managed by the database engine. When an application wants to view or modify data, it has to go through the database engine to do so, as portrayed in Figure 21.2.
The database engine in some DBMSs continues to run in the background as a daemon on Linux. Daemons, covered in Chapter 10, “Booting Linux,” are programs that continue to run in the background, offering a specific service. In the case of a DBMS, that service is access to data managed by the database engine.
One nice aspect about this structure is that the application doesn't have to reside on the same computer system as the database engine. Various instances of the app could run on different systems, sending requests to the database engine on the primary database server similar to what is shown in Figure 21.3.
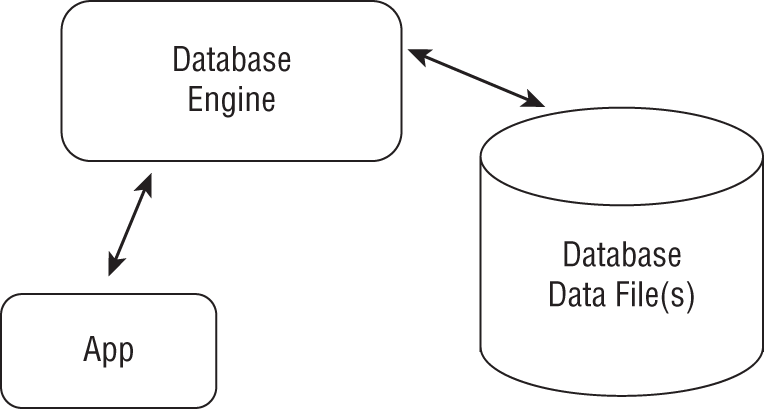
FIGURE 21.2 App using a database engine to access data stored in a database

FIGURE 21.3 Apps using a database engine to access data stored in a database across a network
The Linux RDBMSs we're going to focus on in this chapter include MySQL, MariaDB, and PostgreSQL. They each are relational and use a SQL interface.
Installing and Using MySQL/MariaDB
Released in 1996, MySQL is one of the more popular RDBMSs used for web servers on Linux. The LAMP (Linux system, Apache web server, MySQL database server, and PHP programming language) platform can be found in Linux servers around the world still today.
MySQL was revolutionary at the time of its release, because it used indexing data to speed up data queries. The MySQL developers didn't start out trying to compete with commercial databases. Instead, they just wanted to create a simple but fast database system. So, the fancy RDBMS features were left out, and speed was the focus. Because of this development emphasis, MySQL quickly became the standard RDBMS used in many high-profile Internet web applications.
Over time, while continuing to maintain the emphasis on speedy data queries, additional RDBMS features were added, which strengthened MySQL's popularity. MySQL can run on many different platforms besides Linux, can scale its processing into multiple CPUs, provides security at the user and host levels, supports many different human languages, and so on.
Conducting a MariaDB Installation
Installing MariaDB is fairly simple. You need super user privileges, of course, and the correct package name: mariadb-server. (Installing packages was covered in Chapter 3 “Installing and Maintaining Software in Ubuntu,” and Chapter 5, “Installing and Maintaining Software in Red Hat.”)
Here is a snipped example of installing MariaDB on Ubuntu, after updating the system's package information:
$ sudo apt update[sudo] password for sysadmin:[…]Fetched 4124 kB in 22s (187 kB/s)Reading package lists… DoneBuilding dependency treeReading state information… Done[…]$$ sudo apt install mariadb-serverReading package lists… DoneBuilding dependency treeReading state information… Done[…]The following NEW packages will be installed:[…]mariadb-common mariadb-server mariadb-server-10.3 mar[…]mysql-common socat[…]Need to get 21.1 MB of archives.After this operation, 173 MB of additional disk space willbe used.Do you want to continue? [Y/n] Y[…]Fetched 21.1 MB in 39s (536 kB/s)Preconfiguring packages …Selecting previously unselected package mysql-common.[…]Unpacking mariadb-server-10.3 (1:10.3.25-0ubuntu0.20.04.1)[…]Setting up mariadb-server-10.3 (1:10.3.25-0ubuntu0.20.04.1)[…]$ dpkg -s mariadb-server | grep StatusStatus: install ok installed
Installing MariaDB on a Red Hat–based distribution is also fairly straightforward. Here is a snipped example of an installation on CentOS using the root account:
# dnf install mariadb-server[…]Last metadata expiration check: […].Dependencies resolved.[…]Installing:mariadb-server […]mariadb […]mariadb-common […][…]Installing weak dependencies:mariadb-backup […][…]Install 54 PackagesTotal download size: 43 MInstalled size: 191 MIs this ok [y/N]: yDownloading Packages:(1/54): mariadb-common-[…][…](7/54): mariadb-server-utils[…][…]Total 1.6 MB/s | 43 MB 00:27Running transaction checkTransaction check succeeded.Running transaction testTransaction test succeeded.Running transaction[…]Installed products updated.Installed:mariadb-[…]mariadb-backup[…]mariadb-common[…][…]Complete!## dnf list installed mariadb-serverInstalled Packagesmariadb-server.x86_64 […]#
Even though some distribution's installation process sets the MariaDB service to start when the system boots, it's a good idea to go ahead and enable it yourself. Also start the service as shown in this snipped example on CentOS using the root account:
# systemctl status mariadbmariadb.service - MariaDB 10.3 database serverLoaded: loaded […] disabled; vendor pr>Active: inactive (dead)Docs: man:mysqld(8)https://mariadb.com/kb/en/library/systemd/## systemctl enable mariadbCreated symlink /etc/systemd/system/mysql.service /usr/lib/systemd/system/mariadb.service.Created symlink /etc/systemd/system/mysqld.service →/usr/lib/systemd/system/mariadb.service.Created symlink /etc/systemd/system/multi-user.target.wants/mariadb.service →/usr/lib/systemd/system/mariadb.service.## systemctl start mariadb## systemctl status mariadbmariadb.service - MariaDB 10.3 database serverLoaded: loaded […] enabled; vendor pre>Active: active (running) since […] 42s agoDocs: man:mysqld(8)https://mariadb.com/kb/en/library/systemd/[…]Main PID: 27112 (mysqld)Status: "Taking your SQL requests now…"Tasks: 30 (limit: 11479)Memory: 84.7MCGroup: /system.slice/mariadb.service⌙27112 /usr/libexec/mysqld --basedir=/usr[…]lines 1-23)#
The MariaDB server is now enabled to start when the system boots. Also, it is currently active. After you've accomplished installing the server and enabling it, MariaDB is ready to start managing your data.
If you are running a Red Hat–based Linux system, the process for installation is different enough from Ubuntu that it is worth your time to try it for yourself.
Accessing a MariaDB Database
You access and manage data within the MariaDB server through database user accounts. By default, a special all-powerful account called root (sound familiar?) is installed as an account in the RDBMS. However, since this account has full access to everything in MariaDB, it is considered a poor security practice to use it for user-level access and management of data.
It's best to create a single database account for every user account that needs access. This good security practice allows you to limit a user's access to a particular application's database and protect other managed MariaDB databases from accidental or intentional disturbance.
When you've newly installed a MariaDB server, you will need to either log into the root system account or use sudo to gain super user privileges to interface with MariaDB and create the first user account. The command to access the SQL interface to MariaDB is mysql. When you are in the interface, your prompt will look like this: MariaDB [(none)]>. This is one difference between MySQL and MariaDB. For MySQL, the prompt looks like this: MySQL [(none)]>.
To create your first user account, you may want the system's hostname, which can be obtained a variety of ways, including through the hostname command. The hostname can be used within the database account username.
It's a good practice to use the same username for the database account as the Linux system account's username. The SQL interface syntax to create a database user account is as follows:
CREATE USER username@hostname IDENTIFIED BY 'password';
Notice that at the end of the SQL syntax line, there is a semicolon (;). This lets the SQL interface know that you have completed entering the syntax for this statement. That small, but important, piece of SQL syntax is easy for those who are new to SQL to miss!
An example of creating a first MariaDB database user account on an Ubuntu system using sudo to gain super user privileges is shown here:
$ hostnameubuntu-server$$ sudo mysql[sudo] password for sysadmin:Welcome to the MariaDB monitor. Commands end with ; or \g.Your MariaDB connection id is 42Server version: 10.3.25-MariaDB-0ubuntu0.20.04.1 Ubuntu 20.04Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Aband others.Type 'help;' or '\h' for help. Type '\c' to clear the currentinput statement.MariaDB [(none)]> CREATE USER 'sysadmin@ubuntu-server'-> IDENTIFIED BY 'Project42Password';Query OK, 0 rows affected (0.037 sec)MariaDB [(none)]>
You don't have to put the user account name and hostname in single quotation marks, but it's needed in this case because of the dash (-) in the hostname. Notice that you can put the SQL statement on two lines. That's because the interface doesn't care about line returns produced by the Enter key like the Bash shell does. Instead, the SQL interface is watching for a semicolon to end the statement.
After you've created a user account, you can view it as shown here:
MariaDB [(none)]> SELECT user FROM mysql.user;+------------------------+| user |+------------------------+| sysadmin@ubuntu-server || root |+------------------------+2 rows in set (0.000 sec)MariaDB [(none)]> exitBye$
Notice that the exit command (no semicolon needed) allows you to leave the SQL interface and return to the command line.
Now that you've created a MariaDB user account for yourself, use it to log into the SQL interface. An example of doing this is shown here:
$ mysql --user 'sysadmin@ubuntu-server' --passwordEnter password:Welcome to the MariaDB monitor. Commands end with ; or \g.Your MariaDB connection id is 47Server version: 10.3.25-MariaDB-0ubuntu0.20.04.1 Ubuntu 20.04Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Aband others.Type 'help;' or '\h' for help. Type '\c' to clear the currentinput statement.MariaDB [(none)]>
For your MariaDB account's password, instead of entering it on the same line as the mysql command, you just use the --password option with no argument. When you do this, the SQL interface will prompt you for the password, and your password is not displayed as you type it.
Besides creating an account to access the MariaDB database server, you'll need to grant permissions to access tasks and items within MariaDB for the account. If this is not done, when the user account tries to perform a task, such as creating a database, access will be denied as shown here:
$ mysql --user 'sysadmin@ubuntu-server' --passwordEnter password:Welcome to the MariaDB monitor. Commands end with ; or \g.[…]MariaDB [(none)]> CREATE DATABASE FruitTrees;ERROR 1044 (42000): Access denied for user'sysadmin@ubuntu-server'@'%' to database 'FruitTrees'MariaDB [(none)]> exitBye$
To grant access for the first account, you'll again need to use super user privileges. The basic syntax for doing this is as follows:
GRANT access ON objects TO user;
The access is essentially commands that the user can use when dealing with the listed objects
. Wildcards are allowed when specifying objects
. For example, to allow a user to issue the SQL SELECT command on any database in the system, you'd use the GRANT SELECT ON *.* TO user
; SQL statement syntax.
In the case of granting access for the first account, assuming it is an administrative account, it's best to provide full-blown access by using ALL as the access granted, as shown snipped here:
$ sudo mysql[sudo] password for sysadmin:Welcome to the MariaDB monitor. Commands end with ; or \g.[…]MariaDB [(none)]> SHOW GRANTS FOR 'sysadmin@ubuntu-server';+--------------------------------------[…]+| Grants for sysadmin@ubuntu-server@% […]|+--------------------------------------[…]| GRANT USAGE ON *.* TO `sysadmin@ubuntu-server`@`%`IDENTIFIED BY PASSWORD '*3429168B1E2FE4[…]|+--------------------------------------[…]+1 row in set (0.000 sec)MariaDB [(none)]> GRANT ALL ON *.* TO 'sysadmin@ubuntu-server';Query OK, 0 rows affected (0.001 sec)MariaDB [(none)]> SHOW GRANTS FOR 'sysadmin@ubuntu-server';+--------------------------------------[…]+| Grants for sysadmin@ubuntu-server@% […]|+--------------------------------------[…]+| GRANT ALL PRIVILEGES ON *.* TO `sysadmin@ubuntu-server`@`%`IDENTIFIED BY PASSWORD '*3429168B1E2FE4[…]|+--------------------------------------[…]+|1 row in set (0.000 sec)MariaDB [(none)]> exitBye$
The SHOW GRANTS FOR user
; SQL statement shows the current access granted to that user. When the access was modified by the GRANT command, the user now has ALL PRIVILEGES granted.
Populating and Using MariaDB Database
After you have the database server installed and appropriate access granted, you can begin creating databases and their tables and populating them with data.
The SQL command to create a database is logically CREATE DATABASE. Using the fruit tree example from previously, an appropriately named database is created in MariaDB through the SQL interface as shown snipped here:
$ mysql --user 'sysadmin@ubuntu-server' --passwordEnter password:Welcome to the MariaDB monitor. Commands end with ; or \g.[…]MariaDB [(none)]> CREATE DATABASE FruitTrees;Query OK, 1 row affected (0.001 sec)MariaDB [(none)]> SHOW DATABASES;+--------------------+| Database |+--------------------+| FruitTrees || information_schema || mysql || performance:schema |+--------------------+4 rows in set (0.036 sec)MariaDB [(none)]>
Notice you can see all the databases within MariaDB using the SHOW DATABASES; command, including the newly created FruitTrees database.
After a database is created, assuming you have normalized your data, you are ready to begin creating tables. The USE database
; command is needed to select the database to create a table in, as shown here:
MariaDB [(none)]> USE FruitTrees;Database changedMariaDB [FruitTrees]> CREATE TABLE AppleTrees (-> item_number int not null,-> tree_type text,-> description text,-> tree_size text,-> apple_color text,-> blooming_period text,-> pollinator_group int,-> harvest_period text,-> grow_zones text,-> primary key (item_number));Query OK, 0 rows affected (0.755 sec)MariaDB [FruitTrees]>
The CREATE TABLE command starts the process of creating a designated table (AppleTrees in the example). While you could type the field information for the table all on the same line, it's easier to see what you are doing by putting a single field designation on each line. Each field designation has a name and a data type (see Table 21.1), as well as any options. Also, you have to designate a primary key, and you need to prevent that particular field from being set to blank or null. In the example, the item_number is the primary key, and it is blocked from being empty through the not null option in its field designation.
To view any tables, use the SHOW TABLES syntax as shown in the example here:
MariaDB [FruitTrees]> SHOW TABLES IN FruitTrees;+----------------------+| Tables_in_FruitTrees |+----------------------+| AppleTrees |+----------------------+1 row in set (0.000 sec)MariaDB [FruitTrees]>
To view field description details within a particular table of a selected database, you can use the DESCRIBE command, as shown here:
MariaDB [FruitTrees]> DESCRIBE AppleTrees;+------------------+---------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+------------------+---------+------+-----+---------+-------+| item_number | int(11) | NO | PRI | NULL | || tree_type | text | YES | | NULL | || description | text | YES | | NULL | || tree_size | text | YES | | NULL | || apple_color | text | YES | | NULL | || blooming_period | text | YES | | NULL | || pollinator_group | int(11) | YES | | NULL | || harvest_period | text | YES | | NULL | || grow_zones | text | YES | | NULL | |+------------------+---------+------+-----+---------+-------+9 rows in set (0.046 sec)MariaDB [FruitTrees]>
Now that you have a table created, you can start populating it with data. Sticking with our AppleTrees table scenario, we added three data records to it in this example:
MariaDB [FruitTrees]> INSERT INTO AppleTrees VALUES (3247,-> 'Baldwin', 'Impressive American variety…',-> 'Std', 'Red and Green',-> 'Mid-Late Spring', 4, 'October', '5-8');Query OK, 1 row affected (0.067 sec)MariaDB [FruitTrees]> INSERT INTO AppleTrees VALUES (3248,-> 'Baldwin', 'Impressive American variety…',-> 'Dwarf', 'Red and Green',-> 'Mid-Late Spring', 4, 'October', '5-8');Query OK, 1 row affected (0.074 sec)MariaDB [FruitTrees]> INSERT INTO AppleTrees VALUES (3251,-> 'Redfree', 'Sweet and a little acidic…',-> 'Std', 'Red and Green',-> 'Early-Mid Spring', 4, 'August', '4-8');Query OK, 1 row affected (0.075 sec)
It's a good idea to check the data you've entered into your database tables to ensure all is well. Using the SELECT * FROM tablename
; SQL statement will allow you to view all the current data in tablename
, as shown snipped here:
MariaDB [FruitTrees]> SELECT * FROM AppleTrees;[…]| item_number | tree_type | description| tree_size | apple_color | blooming_period | pollinator_group| harvest_period | grow_zones |[…]| 3247 | Baldwin | Impressive American variety…| Std | Red and Green | Mid-Late Spring | 4| October | 5-8 || 3248 | Baldwin | Impressive American variety…| Dwarf | Red and Green | Mid-Late Spring | 4| October | 5-8 || 3251 | Redfree | Sweet and a little acidic…| Std | Red and Green | Early-Mid Spring | 4| August | 4-8 |[…]3 rows in set (0.001 sec)MariaDB [FruitTrees]>
If you find mistakes in your data or just need to update information, you can do that rather easily. Just use the UPDATE command along with the data field you'd like to change and a WHERE statement to select the record identified by its primary key (item_number in this case):
MariaDB [FruitTrees]> UPDATE AppleTrees SET-> pollinator_group=3 WHERE item_number=3248;Query OK, 1 row affected (0.120 sec)Rows matched: 1 Changed: 1 Warnings: 0MariaDB [FruitTrees]> SELECT * FROM AppleTrees;[…]| item_number | tree_type | description| tree_size | apple_color | blooming_period | pollinator_group| harvest_period | grow_zones |[…]| 3247 | Baldwin | Impressive American variety…| Std | Red and Green | Mid-Late Spring | 4| October | 5-8 || 3248 | Baldwin | Impressive American variety…| Dwarf | Red and Green | Mid-Late Spring | 4| October | 5-8 || 3251 | Redfree | Sweet and a little acidic…| Std | Red and Green | Early-Mid Spring | 3| August | 4-8 |[…]3 rows in set (0.001 sec)MariaDB [FruitTrees]> exitBye$
After your database and its tables are created and you have populated the tables and checked their data, you are ready to let your database applications roll.
Knowing how to install and use the MySQL and MariaDB databases will provide you with invaluable skills in your system administration career. However, it's always a good idea to expand your database knowledge so that your experience has some variety to it. We'll explore another RDBMS next.
Installing and Using PostgreSQL
PostgreSQL has a history that goes all the way back to the 1980s, though its current name wasn't designated until 1995. In fact, many administrators still refer to it by a variant of its previous name, Postgres.
PostgreSQL's evolutionary life has brought about some popular features. It supports standard SQL, with a few exceptions, and has data integrity structures, such as multiversion concurrency control (MVCC), which allows each database transaction to have a copy of the data. This way, creating or modifying data does not prevent any data queries and vice versa. MVCC not only provides higher levels of data integrity, but it speeds things up.
Security-wise, PostgreSQL has the ability to provide mandatory access control (MAC) security levels similar to that of SELinux (see Chapter 18, “Exploring Red Hat Security”). In addition, it can work with several different authentication systems, such as Kerberos, Lightweight Directory Access Protocol (LDAP), pluggable authentication modules (PAM), and so on.
Conducting a PostgreSQL Installation
Installing PostgreSQL is a little different depending on the Linux distribution you are using. You need super user privileges and the correct package name, which is postgresql for Ubuntu and postgresql-server for Red Hat–based distributions.
Here is a snipped example of installing PostgreSQL on Ubuntu, after updating the system's package information:
$ sudo apt update[sudo] password for sysadmin:[…]Fetched 4124 kB in 22s (187 kB/s)Reading package lists… DoneBuilding dependency treeReading state information… Done[…]$$ sudo apt install postgresql[sudo] password for sysadmin:Reading package lists… DoneBuilding dependency treeReading state information… DoneThe following additional packages will be installed:libllvm10 libpq5 libsensors-config libsensors5postgresql-12 postgresql-client-12postgresql-client-common postgresql-commonssl-cert sysstat[…]0 upgraded, 11 newly installed, 0 to remove […]Need to get 30.6 MB of archives.After this operation, 122 MB of additional […]Do you want to continue? [Y/n] YGet:1 http://us.archive.ubuntu.com/ubuntu focal/mainamd64 libllvm10 amd64 1:10.0.0-4ubuntu1 [15.3 MB][…]Fetched 30.6 MB in 46s (659 kB/s)Preconfiguring packages …[…]Unpacking sysstat (12.2.0-2) …Setting up postgresql-client-common (214ubuntu0.1) …[…]Setting up postgresql-common (214ubuntu0.1) …Adding user postgres to group ssl-cert[…]The files belonging to this database system will be ownedby user "postgres".This user must also own the server process.[…]syncing data to disk …[…][…]Processing triggers for libc-bin […]$$ systemctl status postgresqlpostgresql.service - PostgreSQL RDBMSLoaded: loaded […] enabled; vendor pr>Active: active (exited) since […]Main PID: 2690 (code=exited, status=0/SUCCESS)Tasks: 0 (limit: 2282)Memory: 0BCGroup: /system.slice/postgresql.service[…]ubuntu-server systemd[1]: Starting PostgreSQL RDBMS…[…]ubuntu-server systemd[1]: Finished PostgreSQL RDBMS.lines 1-10/10 (END)$$ which createdb/usr/bin/createdb$
When you install PostgreSQL on Ubuntu, it is automatically enabled to start when the system boots. Also, the service is started for you. One simple check you can perform to see if PostgreSQL is installed on a system outside of package management is through the which createdb command. If you see a file when this command is issued, PostgreSQL is installed on your system, as was done in the preceding installation example.
Installing PostgreSQL on a Red Hat–based distribution is a little different. In the following snipped example, we used the su -c '
command
' syntax to issue single commands as the root user to escalate to super user privileges, when needed:
$ su -c 'dnf install postgresql-server'Password:Last metadata expiration check: […]Dependencies resolved.[…]Installing:postgresql-server […]Installing dependencies:libpq […]postgresql […]Enabling module streams:postgresql […]Transaction Summary[…]Install 3 PackagesTotal download size: 6.7 MInstalled size: 26 MIs this ok [y/N]:yDownloading Packages:[…]Running transaction checkTransaction check succeeded.Running transaction testTransaction test succeeded.Running transaction[…]Installed products updated.Installed:libpq[…]postgresql[…]postgresql-server[…]Complete!$
When you install PostgreSQL on CentOS, it is not automatically enabled or started, so you'll have to issue those systemctl commands manually. But before you do that, you have to run a PostgreSQL database initialization with super user privileges, as shown here:
$ su -c '/usr/bin/postgresql-setup --initdb'Password:* Initializing database in '/var/lib/pgsql/data'* Initialized, logs are in /var/lib/pgsql/initdb_postgresql.log$
After the database is initialized, you can enable the PostgreSQL to start during the system's boot and get the service running. The process is shown snipped in this example:
$ systemctl status postgresql• postgresql.service - PostgreSQL database serverLoaded: loaded ([…]disabled; vendor>Active: inactive (dead)$$ su -c 'systemctl enable postgresql'Password:Created symlink[…]$$ su -c 'systemctl start postgresql'Password:$$ systemctl status postgresql• postgresql.service - PostgreSQL database serverLoaded: loaded […]enabled; vendor>Active: active (running) since […][…]$
When you have your PostgreSQL RDBMS software installed and properly initialized, you can move forward on setting up proper access to it and then loading data into the database.
Accessing a PostgreSQL Database
You access and manage data within the PostgreSQL server through database user accounts, which are called roles. Instead of using the root account, a special all-powerful account called postgres is a role created in this RDBMS. The postgres role has full access to everything in PostgreSQL, so it is a good security practice to create a single database role for every user account that needs access to it.
A quick check lets you determine whether your current user account has a role set up for it within a PostgreSQL server. Attempt to create a database with the createdb command. If you get a role "
username
" does not exist message when issuing the command, a role for you is not yet created:
$ createdb AppleTreescreatedb: error: could not connect to database template1:FATAL: role "sysadmin" does not exist$
To create your role, you first have to log into the postgres account. To do this, you need super user privileges as shown here:
$ sudo --login -u postgrespostgres@ubuntu-server:~$ whoamipostgrespostgres@ubuntu-server:~$postgres@ubuntu-server:~$ psqlpsql (12.6 (Ubuntu 12.6-0ubuntu0.20.04.1))Type "help" for help.postgres=#
The command to access the SQL interface to PostgreSQL is psql. When you are in the interface, your prompt will look like this: postgres=#. The name (postgres) lets you know the current role you are using in the RDBMS. The pound sign (#) indicates that this role has super user privileges within the database. A greater-than sign (>) in place of the pound sign indicates that the super user privileges are not granted for a role.
It's a good practice to use the same role name for the database account as the Linux system account's username. The SQL interface syntax to create a database user account is as follows:
CREATE ROLE role-name access;
When you create a role in PostgreSQL, you grant the allowed access for that role at the same time. The access portion of the CREATE command is what grants access, and it can be set to one or more of the items listed in Table 21.3.
TABLE 21.3: A Few PostgreSQL Role Access Settings
| ACCESS NAME | DESCRIPTION |
|---|---|
CREATEDB |
Creation of databases is permitted. |
CREATEROLE |
Creation of database roles is permitted. This is a potential security risk, because the role can create other roles with SUPERUSER access. |
LOGIN |
Sets the role as a database user. Passwords for database authentication are set with PASSWORD '
password'. |
SUPERUSER |
Grants full access to all database objects. This is a dangerous access level and should be used with caution. |
The access list in Table 21.3 is not complete, but it will get you started on your journey of exploring PostgreSQL. If you make a mistake or need to grant more privileges later, you can use the ALTER ROLE command. Use DROP ROLE if you need to remove a role from the database.
An example of creating a role for the user sysadmin in the psql SQL interface with the postgres role is shown snipped here:
$ sudo --login -u postgrespostgres@ubuntu-server:~$ psqlpsql (12.6 (Ubuntu 12.6-0ubuntu0.20.04.1))Type "help" for help.postgres=# CREATE ROLE sysadminpostgres-# CREATEDB LOGIN PASSWORD 'Project42Password';CREATE ROLEpostgres=#
To see all the roles you've created and the ones that came with the default installation, use the special psql command of \du. This command will show the role information using a pager, so you'll need to press the Q key to exit out of the display when you are done viewing the role information. A snipped example of this using this command is shown here:
postgres=# \duList of rolesRole name | Attributes […]-----------+------------------------------------[…]postgres | Superuser, Create role, Create DB, […]sysadmin | Create DB […](END)postgres=#
After you're done creating the initial role, it's a good idea to exit from the psql interface and log out of the postgres account. You can use the exit command to do both actions:
postgres=# exitpostgres@ubuntu-server:~$postgres@ubuntu-server:~$ exitlogout$ whoamisysadmin$
After a role has been created for a user and prior to them entering into the psql SQL interface for the first time, they will need to perform an initialization by issuing the createdb command with no database name listed after it. An example of this is shown here:
$ whoamisysadmin$$ createdb$$ psqlpsql (12.6 (Ubuntu 12.6-0ubuntu0.20.04.1))Type "help" for help.sysadmin=>
Notice that the SQL interface prompt in psq
l has changed. It now shows the role name of the user who is accessing the interface. When the RDBMS has been installed and an initial role is created, you're ready to start creating and using a PostgreSQL database.
Populating and Using a PostgreSQL Database
PostgreSQL generally follows standardized SQL. For example, creating a database looks the same as it did when using MariaDB:
sysadmin=> CREATE DATABASE FruitTrees;CREATE DATABASEsysadmin=>
However, you'll find that within the psql SQL interface, some SQL statements do not work, such as the SHOW DATABASES command. Instead, you need to use \l (a lowercase L) to see all the databases, as shown snipped here:
sysadmin-> \1List of databasesName | Owner | Encoding | Collate |[…]------------+----------+----------+---------+[…]fruittrees | sysadmin | UTF8 | C.UTF-8 |[…]postgres | postgres | UTF8 | C.UTF-8 |[…]sysadmin | sysadmin | UTF8 | C.UTF-8 |[…]template0 | postgres | UTF8 | C.UTF-8 |[…]template1 | postgres | UTF8 | C.UTF-8 |[…](5 rows)sysadmin->
Notice in the preceding example that even though we named our database FruitTrees when we created it, PostgreSQL changed the name to fruittrees. If you want an object name to be a different case than lowercase, you'll have to enclose it in quotation marks. This is important to note, because you have to have the right case when you use an object, such as a database name, in your SQL command syntax.
Before creating tables in your newly created database, you need to connect to it. Use the \c command to accomplish this as shown here:
sysadmin-> \c fruittrees;You are now connected to database "fruittrees" as user "sysadmin".fruittrees->
When you connect to a database, the psql prompt will change and replace your role name with the current database. Creating a table follows standard SQL syntax, as shown in this test example:
fruittrees=> CREATE TABLE test (fruittrees(> id_number int not null,fruittrees(> type text,fruittrees(> brand text,fruittrees(> primary key (id_number));CREATE TABLE
However, displaying a table is a little different. Instead of using the SHOW TABLES SQL command, you need to use the \dt command, which stands for display table:
fruittrees=> \dtList of relationsSchema | Name | Type | Owner--------+------+-------+----------public | test | table | sysadmin(1 row)fruittrees=>
After a table is created and defined, you can start populating it with data. An example of doing this is shown here:
fruittrees=> INSERT INTO test VALUES (1,'first test','data1');INSERT 0 1fruittrees=> INSERT INTO test VALUES (2,'2nd test','data2');INSERT 0 1fruittrees=>
Viewing data in a table follows standard SQL syntax, which is nice:
fruittrees=> SELECT * FROM test;id_number | type | brand-----------+------------+-------1 | first test | data12 | 2nd test | data2(2 rows)fruittrees=> exit$
When you have completed your work within the psql SQL interface, be sure to use the exit command to leave. If you need to access this database or its table again through this interface, you'll need to reconnect to the database using the \c command.
Database administration is a rather deep topic, and we've just scratched the surface. However, you've got a little experience now that will assist you as you continue your database server management journey.
The Bottom Line
- Understand basic DBMS components. A database management system typically consists of a database engine, the data files for the database, and a query-language interface, which typically uses standard SQL or something relatively compliant with standard SQL. These components assist in fulfilling the need to manage complex connections between individual data items.
- Master It You have installed an RDBMS on your Linux system. The various applications that access this database reside on different servers across your local network. However, these servers are in different buildings on your company's campus. Recently, the power was cut to the campus due to a mistake by the power utility supply company. You did not have any backup power systems in place, and all your servers went down. Now that the power has been restored and your systems are back up and running again, none of the applications can access the database. The system on which your RDBMS resides is running (the primary database server), and there are no network firewall problems. What should you investigate next to resolve this issue?
- Create user accounts within MariaDB. Managing and querying data within a MariaDB server is accomplished through database user accounts. Typically, an account is created for every user account on the Linux system that needs to manage and/or query data in the database. It is also considered a good practice to limit user access to only those databases associated with applications the user can access.
- Master It Imagine you are the system administrator on a new Linux server. You have completed the installation of MariaDB and need to create a database for the application that will be using MariaDB as its RDMS. What are the next few steps to take, after starting the MariaDB service and enabling it to start at system boot?
- Use SQL to query a MariaDB database. MariaDB uses several standard SQL commands, plus a few more, to manage databases, create tables, populate them with data, and query that data. The times that may cause you a little heartburn are when you need to use SQL commands that fall outside of the standards. However, that is fairly rare when interacting with the MariaDB SQL interface.
- Master It You have recently created a table named
ArtificialFlowerswithin theFloristdatabase. The artificial flower records listed in this table have only a few fields:ProductID(which is the primary key),FlowerName,FlowerColor, andStemColor. The store manager of the florist shop wants to check the data you've entered into this table. What steps should you take after you have logged into the MariaDB server's command line where this data exists?
- Master It You have recently created a table named
- Install PostgreSQL on Linux. The PostgreSQL (also called Postgres) RDBMS has some features that make it popular in segments of the Linux community. For instance, it has data reliability structures and generally supports standard SQL, with a few exceptions. Installing PostgreSQL can be a little tricky, as its installation process is slightly different depending on the Linux distribution you are using.
- Master It You are a system administrator for a Linux system whose customers want to use the PostgreSQL RDBMS on the system. This particular system is a Red Hat Linux distribution. What steps do you need to take to accomplish this task?
- Set up roles within PostgreSQL. Roles are used to access and manage data within a PostgreSQL server. It is considered a good practice to determine what privileges a user needs for using a PostgreSQL database and then create a role with the appropriate privileges. This structure provides protection for the data and appropriate security tracking of database users.
- Master It You are the database administrator of the PostgreSQL database on your Linux system. Your database user role is named
admin. This role has super user privileges in the database as well as the ability to create roles and databases. What, if any, changes should be made to your account to improve the security levels of administering this database?
- Master It You are the database administrator of the PostgreSQL database on your Linux system. Your database user role is named