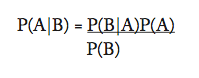
Chapter 5
Artificial and natural intelligence
WE HAVE SEEN that digital apes, closely coupled with general-purpose thinking machines, have many emergent properties: new forms of collective endeavour, enquiry, knowledge, and entertainment. The question naturally arises, how close are the partner devices in that enterprise to having our kind of thought, the distinctive characteristic of our mode of being? Does any machine have digits that add up to emotion or insight or mind? How would we know?
Modern neuroscience, despite its arsenal of imaging, tracing, and recording techniques and its high-performance software for neural analytics and visualisation, has made little progress towards understanding how our own ape brain — naked, digital, or whatever — creates a sense of personal identity that can project into the future and reach back into the past. We don’t know what creates the feeling of consciousness in humans. We don’t know whether our knowledge — if that is what it is — that we are conscious is separate from actually being conscious. So neither do we know whether human babies, let alone other apparently smart species like chimpanzees and dolphins, are conscious in the way we think of it, since we are pretty sure that none of them have the language to be able to describe themselves to themselves as being conscious. They seem to be some version of aware, but probably not self-aware, and certainly unable to have the idea that they are self-aware.
Artificial intelligence is, we assert and will show, even further from building anything like a person. In Turing Test tournaments, which hope to fool participants into believing they are interacting with a person and not a machine, smart programs that do well don’t strike us as alien beings because we don’t imagine for a second that they are beings at all. The code doesn’t tremble in the memory cores of its hardware, worrying if it is going to be switched off, or about to make a fool of itself. Some machines do, conversely, make us nervous. Playing a modern chess program you can almost believe it is reading your mind. The computer seems to anticipate your every move. It is easy to endow it with a sense of self, which is what humans do with animals and machines that function in ways that remind us of us. This is, at present, an illusion. It will be a long time before people have to worry about self-aware AIs, let alone jealous or malevolent ones.
Machine intelligence is nothing like human intelligence. Hyper-fast machines are potentially dangerous, and have served the world badly in the banking industry. They are not about to wreak havoc by turning into some combination of Pol Pot and Einstein, an evil genius from Meccano James Bond. Carpet cleaning robots, lawn mowing robots, don’t dress up in overalls and say ‘morning guv’. They are small, functional discs. The present authors are more afraid of what harm natural stupidity, rather than artificial intelligence, might wreak in the next 50 years of gradually more pervasive machines and smartness.
*
The American psychologist Julian Jaynes stirred up evolutionary biology and philosophy 40 years ago with his hypothesis of what he called the ‘bicameral mind’: a mind in which the voice that we now imagine to be ourselves, the self-conscious part of us, was understood in pre-classical times as the voice of the gods. It was, he claimed, only with the invention of classical literature and its associated tropes that we came to understand the voice in our heads to be our own. In effect, knocked the two rooms, the two camera, into one. We started to think about the fact that we think, and then gradually to take responsibility for our thoughts, to worry about whether we should think differently. Richard Dawkins calls the idea ‘either complete rubbish or a work of consummate genius’. But contemporary brain-imaging technology seems to confirm at least some of Jaynes’ predictions. For instance, neuro-imaging studies have largely confirmed his early predictions on the neurology of auditory hallucinations.
The nature of self is one of the mysterious questions underpinning western philosophy. What is it to be capable of first-person reflection, sensation, and sentient experience? From where does this sense of selfhood come? Philosophers have tended to two views on the matter. Rationalists, such as Spinoza and Leibniz, located it in the domain of the spiritual: we have an intrinsic soul that has the capacity to experience, learn, and reflect. For Empiricists, such as Locke, Berkeley, and Hume, our sense of self is constructed and emerges from our actual experiences of the world. Current philosophers have to take account of fresh evidence, beginning with what, biologically, seems to happen on brain scans when we are awake, or asleep and dreaming, or in danger or drugged. As noted above, so far all the technical apparatus has provided no means to leap from the physiological details to an understanding of mind.
Socrates or Hannibal or Confucius — let alone a pre-historic human being or hominin — would be extremely uncomfortable in our world, as we would be around them. People who live in westernised cultures today share notions of the relation between the personal and the social that would have been foreign to most of the people who have ever lived, and may still be foreign to a lot of the present world population. By extension, it seems unlikely that a rich citizen in a rich country a hundred years from now will have exactly the same feelings about what the self is as the readers of this book do.
The child psychologist Alison Gopnik sees nothing to convince her that machines will ever be as smart as a three-year-old, in the way that we understand overall smartness. Even very young apes are immensely sophisticated beings. Yet of course the machines we compare ourselves to at present have narrow talents, their quickness and ability to look at immense quantities of data. The smartness is sometimes that of social machines, an emergent property which extends not their own smartness, but that of humans. Gopnik also makes a key point about attention. What we think of as lack of attention is often the opposite:
For younger children consciousness seems to be more like a lantern, illuminating everything at once. When we say that pre-schoolers are bad at paying attention, what we really mean is that they are bad at not paying attention — they have difficulty keeping themselves from being drawn to distractions.
The Gardener and the Carpenter: what the new science of child development tells us about the relationship between parents and children, 2016
Our sense of self is being augmented along a new digital frontier, the extended mind. Our computing infrastructure allows us to be connected to solve problems beyond the scope of any individual’s capabilities: we have tremendous collective memory, tremendous collective and accessible encyclopaedic knowledge. Satellite navigation on vehicles can send information about the speed and location of those vehicles back to a computer which works out the best route for each of those vehicles. Computers are rapidly providing us with tools to make us more capable, more networked, and more responsive. And it will change us, as we adapt and are adapted by this new context. To confirm this, we need look no further than the map of a young gamer’s motor cortex, which play has shaped exquisitely to perform on game consoles.
We have yet to discover how a skill laid down in the neural circuitry of the brain affects our sense of selfhood. What is the relationship between the so-called grey cells and what they seem to support, mind and selfhood? There seem to be several or more perceptive and other systems simultaneously filtering information and reflecting back on each other, with consciousness emerging from them. That concept again: emergence. At some stage in the evolution of the brain, an as yet incomplete, but already large and various, set of biological patterns subsisting in it, monitoring each other, became conscious. Not only seeing, but able to notice that we see. Indeed, able to use the seeing apparatus to construct pictures without seeing them. Our distinctive capacity is that we can live in our imagination, uniquely amongst species, so far as we know.
Machines at this stage simply have nothing to compare with any of that. They have no selves. Nor do we yet have, except for isolated and narrow capabilities, sufficiently good a picture of what is happening inside our heads to begin to model it with machines, let alone ask a machine to imitate or do it. The brain adapts to the context in which it finds itself. It is plastic and will be shaped by our new hyper-connected world. Exactly how needs to be carefully monitored. Academics famously end every paper, book and report with the phrase, ‘more research is needed on this subject’. They would, it’s what they are selling. Nevertheless, that phrase needs to be constantly remembered from now on because, whatever is the case elsewhere, it is flatly true in these matters: important aspects are unexplored, and need to be properly understood.
*
The word robot comes from a 1920 play, R.U.R. by the Czech dramatist Karel Čapek, about a factory that makes imitation humans. The word derives from the Czech robota, forced labour undertaken by serfs. It was not the first suggestion of such creations, and Čapek’s were more biological than mechanical. But the play’s widespread success was the starting point of the subsequent century of discussion of machines coming to life. (Mary Shelley had imagined the human construction of a living person by Dr Frankenstein.) Clearly, the context of the play was that the economies of the richer countries were, by 1920, dominated by machine-based industry. The processes in the midst of which the machines were deployed, and their switching mechanisms, had led to significant changes in everyday life for millions. The active machines — heavy lifters, panel beaters, welders, bolt tighteners, and conveyer belts — were joined by parallel developments in sophisticated controllers, and those in turn led to data processing and interpreting devices, starting with decoders in the Second World War. Significant catalysts in this last were a few highly adept philosopher mathematicians — Turing and others — brought in as cryptographers and code-breakers alongside a number of outstanding electronics engineers.
In his day, Alan Turing was little known outside mathematical circles. His work at the Bletchley Park Cypher School was kept highly secret even after the defeat of the Axis powers, as the world moved from hot to cold war. He now approaches twenty-first century sainthood, and his life and work is the stuff of films and novels. His famous Turing Test, of whether a machine is ‘intelligent’, to which we alluded earlier, might properly be described as a social challenge: could a hidden machine answer questions put to it in a manner indistinguishable from a similarly hidden human? That, of course, tells us nothing of the kind of processing taking place behind the veil of ignorance, which in practice so far has been very different from any human or animal thinking. This is about to change. Machines are projected and under construction that mimic neural networks. They will be fundamentally different from us: without our self-awareness, sentience, or consciousness. But still, like us, they will be natural rule learners, deriving language from noise, and mores — if not morals — from perceived behaviours. They may well learn to balance mutually contradictory rules and values, and use decisions as springs for action, as we do. Before they can do that, we need to build curbs that ensure they will respect our values, since they will have no reason to even listen to us at all, unless we impose that control.
*
A few steps back in time are needed here. There have been decades of academic thinking about the nature and value of artificial intelligence. Perhaps the best place to start on a brief survey would be Moravec’s Paradox, which characterises many present-day issues. It’s relatively simple, he says, to build a machine that plays chess or does advanced mathematics. It’s not simple to build a machine with everyday human mental abilities. Harvard professor Stephen Pinker sums this up:
The main lesson of thirty-five years of AI research is that the hard problems are easy and the easy problems are hard. The mental abilities of a four-year-old that we take for granted — recognizing a face, lifting a pencil, walking across a room, answering a question — in fact solve some of the hardest engineering problems ever conceived … As the new generation of intelligent devices appears, it will be the stock analysts and petrochemical engineers and parole board members who are in danger of being replaced by machines. The gardeners, receptionists, and cooks are secure in their jobs for decades to come.
The Language Instinct, 1994
Classically, artificial researchers wanted to build systems which would be able to solve abstract problems in computational reasoning for mathematics or science, the aspects of thought that people like them connect with on a good day professionally. They wanted an artificial intelligence to be a kind of smarter smart type in a white coat.
The influential Australian Rodney Brooks, robotics professor at MIT and one-time director of its artificial intelligence laboratory, was concerned by the limits of this Good Old-Fashioned AI (GOFAI). Brooks instead proposed that the clever thing about humans is the way we manage to navigate around diverse, often muddled, environments, perform a very wide range of tricky tasks in them, and, in order to do so, have strong abilities to distinguish and analyse situations, to deal effortlessly with myriad contexts both physical and social.
So what emerged was a large range of techniques inspired by what appeared to be the way our general intelligence and perceptive abilities worked. GOFAI tried to make faster and bigger extensions of the central tenets of a mathematical and logical characterisation of the world and ourselves. The new approach started by looking at how animals, including us, appeared to gather and process information, and then began to build so-called artificial neural networks.
Yet it is still the case that AIs find common sense reasoning difficult. Whilst they are superhuman in particular narrow tasks, they find it hard to generalise. Machines are now beginning to be good at helping make diagnostic and therapeutic decisions by telling the physician what conclusions other doctors who saw the same symptoms came to. They know because they incorporate medical rule-based reasoning, along with patterns learnt from thousands of cases representing previous patient diagnoses and treatments. Machines are effective, too, at helping lawyers make legal judgments. They can bring an awful lot of case law to bear. They are just as good at picking winning stocks and shares as us, although evidence shows that, after a certain skill level, neither human nor machine is brilliant at this.
*
Why is there such a strong conviction that artificial intelligence could shed light on human intelligence? Even more, that from the artificial a sense of self and sentience could emerge? Here, we must journey through the relatively short, but not as short as some might believe, history and methods of AI.
We might date the birth of AI from the 1956 Dartmouth Conference, a six-week-long brainstorming session in New Hampshire convened by Marvin Minsky and Claude Shannon, amongst others, that gave the field its name. Philosophers and logicians, mathematicians and psychologists, believed, well before the advent of computers, that we might be able to understand intelligence as the manipulation of symbols. From Aristotle’s syllogisms to Boole’s Laws of Thought, there has been the desire to systematise reasoning. By the end of the nineteenth and beginning of the twentieth century, this had crystallised into the claim that formal logic could provide the foundations for both mathematics and metaphysics. Russell and Whitehead were notable for the attempt in mathematics, and Ludwig Wittgenstein in metaphysics.
This approach, known as logical positivism, sought to put language and science on a common footing. To show that meaning in the world was grounded in logic, and that logic could describe unambiguously how the world was.
The logical positivists inspired a whole generation to develop new and more powerful logics to describe more and more of the natural world. Any system of logic is, at its core, a language to describe the world, a set of rules for composing those language symbols and making deductions from them.
Moreover, with the emergence of computing engines, logic offered the perfect language to specify the behaviour of computers. The fundamental components of our computers implement Boolean logic, so-called AND, NAND, OR, and NOR gates. Simple transistors that give effect to truth tables that allow us to build layer on layer of more complex reasoning.
Computers built in this way were equipped with programming languages that implemented reasoning systems of various sorts. In the early decades of AI, researchers naturally turned to logic-based programming languages. Lisp, Prolog, and the like. The fragment of simple Prolog code below can be read for what it is: rules, assertions, and queries for determining a simple pattern of logical reasoning:
mortal(X) :- man(X). % all men are mortal
man(socrates). % Socrates is a man
?- mortal(socrates). % Socrates is mortal?
The power of rule-based reasoning is considerable. AI using this approach amounts to building proofs that establish facts about the world. Or else seek to establish whether a goal is true given the facts known or that can be derived. Such reasoning is at the heart of many AI systems to this day.
A simple medical example shows how this works. Suppose we take the following knowledge fragments:
if patient X has white blood cell count < 4000
then patient X has low white blood cell count
if patient X has temperature > 101 Fahrenheit
then patient X has fever
if patient X has fever
and patient X has low white blood cell count
then patient X has gram-negative infection
Our computer running a rule-based or logic-based reasoning language could use the knowledge above and run the rules left to right — known as ‘forward chaining’. If the system were provided with base facts such as:
patient Smith has white blood cell count 1000
patient Smith has temperature of 104 Fahrenheit
then it could apply the first rule and the second rule to conclude that:-
patient Smith has low white blood cell count
patient Smith has fever
These derived facts would then enable another cycle of reasoning to apply our third rule and conclude that:
patient Smith has gram-negative infection
We could have run the rules differently. We might have stipulated that the system hypothesise a diagnosis and see if there was evidence from the patient’s condition to support it. What would have to be true for the conclusion of our third rule to hold? What, in turn, would have to be true for the two parts of the antecedent of this rule to be true? Setting up two new goals to be satisfied, and so on, until a set of base facts would allow a set of rules to be satisfied and a set of conclusions derived.
In practice, any real system would be much more complex. There might be many rules that could fire at the same time. How to prioritise amongst them? We might not be certain of the data or of the rules themselves, or we might have information about the likelihood of particular events. The whole area of uncertain reasoning and probabilistic inference has been a substantial field of AI study over the years, with many approaches developed. One of the most influential uses Bayes’ Theorem, which tells us how to adjust our beliefs given the likelihood of events or observations. Formally:
Gram-negative bacteria causing food poisoning is relatively rare. (Say 1 per cent.) This is the probability that the hypothesis is true, P(A). But our patient is on a hospital ward, where diarrhoea is common. (Say 20 per cent.) This is the probability of a symptom, P(B). Almost all gram-negative infections come with diarrhoea (95 per cent) — P(B|A). If a patient has diarrhoea, how does the doctor work out whether they have a gram-negative infection? Bayes’ Theorem leads to the deduction that P(A|B) is (95)(1)/20. The probability that diarrhoea means gram-negative infection is therefore 4.75 per cent. These rules of probability management have been extensively used in AI systems.
There have been many other additions to the AI methods repertoire. We might wish to enrich or else describe the knowledge we have in ways other than rules. The challenge of knowledge representation is a fundamental one in AI. How best to represent the world so we may reason about it. Quite often, we have knowledge about the world that relates to how it is structured or how we have chosen to classify it. For example, in our medical knowledge example:
Gram-negative infection
Has sub-types
E. coli infection
Has sub-types
Klebsiella pneumoniae
Salmonella typhi
Pseudomonas aeruginosa
:
:
To establish a specific infection, an expert would use knowledge that discriminates between them. Our AI systems operate in precisely the same way with this type of structured knowledge, using the properties of the sub-types of infection to establish what it is. Structured knowledge representations were at the heart of early AI proposals for new types of programming language. AI gave birth to what is known as object oriented programming, nowadays a fundamental part of many software systems. The history of AI has intertwined the discovery of new ways to reason and represent the world with new programming languages.
Alongside reasoning and knowledge representation we can add the challenge of search in AI. Computers need to find the solution to a problem in what may be a very large space of possibilities. This brings us to an area that has long fascinated AI researchers: game playing. For decades, a grand challenge in AI was chess. In the 1960s and 1970s, experts opined that a machine would never beat a chess world champion because the search space was simply too big. There were too many potential moves as a game unfolded. And we had no good theories about what cognitive strategies human expert players employed to deal with this search problem.
Chess moves are simple in themselves. Analysts can make a fairly precise formulation of what is called the branching factor and resulting search space of the game — the possible moves on average the opponent can make given a particular move that a player makes. So the player can work out which moves are now available to them, and so on, into the depths of what is called the game tree-space that must be searched and evaluated to give an idea of the best moves. The search space for chess is indeed large. Around 30–35 possibilities (the branching factor) for each side in the middle of a game. From this, we can deduce that an eight-ply game tree (four white moves and four black moves) contains more than 650 billion nodes or reachable board positions.
With confident predictions about this hallowed human territory and the mystique that surrounded chess and its human Grand Masters, it came as a shock when in a game in 1996, and then again in a tournament of six games in 1997, IBM’s Deep Blue computer program beat Gary Kasparov, one of the very best players in the history of the game. How had this happened? And were the machines going to take over from us at the dawn of the new millennium?
Kasparov’s defeat demonstrates a number of persistent and recurrent themes in the history of AI; themes at the heart of this book. Above all, the inexorable power of the exponential mathematics of computing. If our machines are doubling in power and halving in price every 18 months, then at certain moments inflection points occur. Prodigious amounts of search can indeed be undertaken. Deep Blue was capable of evaluating 100 million to 200 million positions per second. Brute computing force, combined with a little insight in terms of the heuristics, or rules of thumb, that suggest which part of the search tree is more interesting than another, will lead to uncannily capable behaviour. Combine that with large databases of opening and closing games, the types of move an opponent makes when in a certain position, and the output is spookier yet. So very spooky that a third element emerges. Writing for Time magazine in 1996 Kasparov observed: ‘I had played a lot of computers but had never experienced anything like this. I could feel — I could smell — a new kind of intelligence across the table.’
Search, ever-faster machines, and rule-based systems are a powerful concoction. Made the more powerful by the fact that, in parallel with all the developments in AI, we have been busy fashioning the largest information construct in the planet’s history. In its current incarnation, the World Wide Web hosts billions of pages of content. It connects billions of people and machines together. This has inevitably led to work that regards the web as a large-scale resource for AI, a place where AI itself can be embedded, and a place that we might make more accommodating for our AI methods, as well as ourselves. This later thought gave rise to the ambitious semantic web project at the turn of the millennium. We will not here rehearse the complex history of the semantic web, but we will point out its essential power and why a simple version of it is turning out to be very powerful. Indeed, it is turbo charging the web.
The web page https://iswc2017.semanticweb.org/ is about an academic conference. The conference will have finished before the publication of this book, but the page will still be there. It has a typical look and feel. We can parse it for its syntax and semantics. The syntax relates to its structure, how it is laid out, where the images are, the fonts used, the size and colour of the text, where the links are, and so on. The language for specifying this is the Hyper Text Markup Language, HTML. But we know as we look at the page that parts of it have meaning, specific semantics. There is the title of the conference at the top. The dates the conference is to be held and where. Lower down the page, there are a set of highlighted keynote speakers, who they are, and their photographs. There is a link to a programme of tutorials and workshops, a list of sponsors etc. This is very much the content you would expect from any conference.
But the content simply is what it is. Equally, the HTML instructions about the page are simply about the format of the page, not about its content. Imagine, therefore, that we now add signposts that categorise the content, identify the kinds of things that you expect to find in a conference. The title, the location, the timing, the keynotes, the proceedings, the registration rates, and so forth, tagged according to a newly minted set of conventions. And indeed just such a language or ontology can be found, by those who want to know more, at: http://www.scholarlydata.org/ontology/conference-ontology.owl.
The ambition of the semantic web community was to get developers to effectively embed or associate this kind of mark-up in pages, so that machines harvesting and searching pages would instantly ‘know’ what the content was about. A conference page. Okay, check the conference ontology at the address now sitting embedded in the page. That tells the machine what to expect in terms of subsequent mark-up on the page, how to find the title of the conference and location and all the other aspects. At scale, this would inject meaning into the web. Machines can then easily, for instance, count how many astronomy conferences are planned for next year. Or how many conferences in Seattle. Or how many keynote speakers at conferences in Canada last year were women, compared to conferences in South America. Or, by linking to a parallel resource, whether women keynote speakers seem to need more cited publications than men before they are invited. This is, of course, in part yet another example of the principle of social machines. Individual conference organisers put human effort into laying out information in a standard way, and it becomes, when collated by machines, a powerful resource.
The use of semantic mark-up has become pervasive in efforts sponsored by the large search engines such as Google, Bing, Yahoo!, and Yandex. They have promoted an approach called schema.org. This has defined specific vocabularies, sets of tags, or micro-data that can be added to web pages so as to provide the information their search engines need to understand content. Whilst schema.org is not everything the semantic web community might have imagined, there are millions of websites using it. As many as a third of the pages indexed by Google contain these types of semantic annotations.
A little semantics goes a long way when it is used at web-scale. Expect to see more machine-processable meaning injected into the web so AI services can locate and harvest the information they need.
The other feature of modern web-scale information resources is just how comprehensive they are. Search, ever faster machines, rule-based systems, methods to compute confidence from uncertain inputs, information at web-scale, natural language understanding systems. Mix these ingredients all together and you have a new kind of composite AI system. One impressive manifestation of which is IBM’s Watson system.
Anyone who watches the YouTube videos of a computer playing the best human players of the popular US quiz Jeopardy is likely to come away impressed. Perhaps have that moment of existential concern that Hawking and Kasparov experienced when confronted with the latest developments from the AI labs. The Jeopardy format is one in which contestants are presented with general knowledge clues in the form of answers, and must phrase their responses in the form of questions. So, for the clue, ‘In 2007, this 1962 American Nobel Laureate became the first person to receive his own personal genome map’, the question would be, ‘Who is James Watson?’
The IBM Watson system appears uncannily capable. Reeling off question after question that relates to broad areas of knowledge across a wide range of categories. AI once again becoming more and more capable. IBM felt able to announce a brand new era of cognitive computing. And as if that were not enough, in the same year a new AI phenomenon began to take centre stage: deep learning. This was a style of AI that owed its inspiration not to logic, rules, and databases of encyclopaedic information, but rather to the biological substrate of our cognitive capabilities: neural networks. In other words, the object is no longer to feed machines with the rules of logic. But instead endow them with software that emulates neural networks.
The neural network, AI inspired by real brain circuits, as an approach is nothing new. It can be traced to the earliest periods of AI and cybernetics. It was a tradition that also looked to build complete robot systems and embed them in the world. One of its early proponents was the British cybernetician Grey Walter. He built so-called turtles in the late 1940s, actually robots equipped with an electronic nervous system, complex circuits inspired by the actual neural networks animals host, and also sensors and actuators. His turtles would trundle around environments, avoid obstacles, seek out light sources, park themselves at charging points to replenish their fuel supply.
Rodney Brooks, the Australian MIT professor we mentioned earlier, revisited this paradigm in the 1980s and set about building complete robots with particular behaviours. A new kind of AI, fashionably dubbed ‘nouvelle AI’, was announced, as a reaction against the more traditional Good Old-Fashioned AI. The latter emphasised rule-based reasoning, logic, and structured representations; nouvelle AI wanted to be something very different.
Brooks’ manifesto was nicely laid out in influential papers in the leading AI journal. In one, ‘Elephants Don’t Play Chess’, he launched a critique of AI’s preoccupation with logic and rule-based systems. He argued for a behaviour-based approach; an approach that built systems that could complete entire behaviours such as navigation, obstacle avoidance, replenishing resources. And, in so doing, don’t try and model every aspect of the world as rules and symbols. Rather use the world as its own best model. Try to exploit aspects of the robot’s morphology, its body structure, and the best available sensors, to solve the problems directly. Even more simply put, start with a simple robot and its desired tasks, rather than attempt to solve the grand challenge of human intelligence.
Those who increasingly followed this approach were inspired by biology. Their field became known as biologically-inspired robotics. There were robots that simulated crickets; invertebrate robots with some very cute implementations of nouvelle AI. So how does one robot cricket find another? Barbara Webb, a leading bio-roboticist, implemented the best approximation of Mother Nature’s cricket. The cricket shaped by evolution over at least 300 million years has its ears on its front legs. Each ear is connected by a tube to several openings on its body. The male and female have adapted to match their call frequencies with these auditory structures. The signal, at a particular frequency, resonates with the fixed length of the tube, which causes a phase cancellation producing a direction-dependent difference in intensity at each ear drum. Head in that direction. Job done.
Morphological solutions like this are common in nature, from the sky compass of the honeybee, to the pedometer in some species of ants, which we will look at more closely in a moment. This approach to building robots has been successful in its own right. Brooks himself commercially exploited the ideas as a founder of iRobot, manufacturers of robotic lawnmowers and vacuum cleaners.
What if we were to emulate not just body structure but neural structure? The effort to build electronic neural networks first came to widespread attention in the 1960s. The diagram overleaf, right, describes a very simple artificial neural network layout.
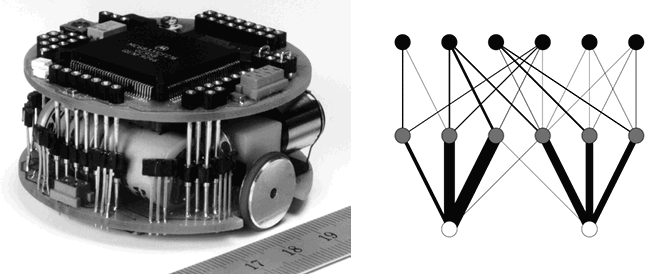
It was used by one of the authors as the configuration for the nervous system of a Khepera robot (shown left). Named after the sacred dung-ball rolling scarab beetle of Ancient Egypt, the Khepera was much loved by the AI robotics research community. It had a pretty powerful chip for its time, a Motorola 68331. Two motors drove a right-hand and left-hand wheel. Its circumference sported a set of infrared sensors, to perceive the world around it.
The neural net that Elliott and Shadbolt implemented on the robot had a first layer of inputs direct from the infrared sensors. A middle layer represented sensory neurons that then connected to two motor neurons in a third layer. These were the neurons that could control the speed of the motors. They literally were motor neurons. Notice that the wiring diagram of the nervous system has thicker lines connecting some of the neurons. This represents stronger connections. The art of designing and then adapting neural networks is to change the weights, strengths, and even existence of these connections. This is an analogue for real growth and modification of synaptic strengths in real neurons.
The overall practice of this tiny neural network was that input from the infrared sensors would drive the motors so as to avoid collision with obstacles. Elliott and Shadbolt’s research took a model from biology, the formation of neural connections in terms of competition for growth factors, neuro-chemicals that promote the sprouting of connections between nerve cells. All neural network learning attempts to change weights and connectivity to learn. In these experiments, we simulated the removal or loss of sensors to show how the network could relearn and still provide effective obstacle avoidance. We know that our own nervous systems do this all the time, through development and ageing, and in the face of injury and deprivation. They exhibit neural plasticity.
With a novel model inspired by biology the neural networks for our Khepera robot could adapt and modify.* The network below developed to cope with the loss of one of the robot’s infrared sensors, represented as the input with no connections to the middle layer of artificial neurons.
[* T. Elliott and N. R. Shadbolt, ‘Developmental robotics: manifesto and application’, Philosophical Transactions of the Royal Society of London, 2003.]

Neural networks have been used not just to control robots, but across a broad range of tasks. The most impressive recent results, in part a consequence of those inexorable rates of exponential increase in the power of the computers and their memory, are so-called deep neural networks. Deep in the sense that there are many intervening layers between input and output. Moreover, many of these systems are not just simple linear arrays of inputs with a middle and output layer. Rather, they are huge matrices many layers deep. Layer on layer graphically depicted overleaf.
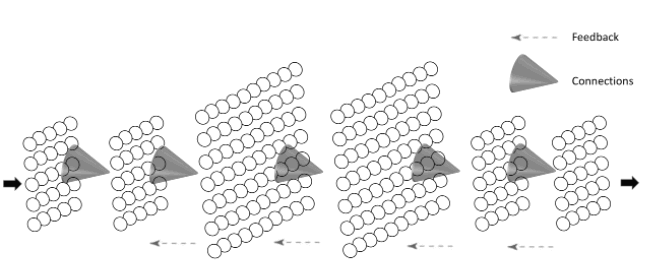
The adjusting of weights and connections between the neurons of each layer becomes a huge computational task. Areas of each layer can perform different kinds of adjustment, implement different functions, that seek to find the structure, the causal correlations that lay hidden in the input, propagating that information forward to deeper layers. Input that is presented thousands and sometimes millions of times. Input that can include the huge datasets now available on the web. Endless pictures of animals, for instance. Training sessions which strengthen or weaken connections in the stacked network layers. With such networks we can build powerful recognition and classification systems.
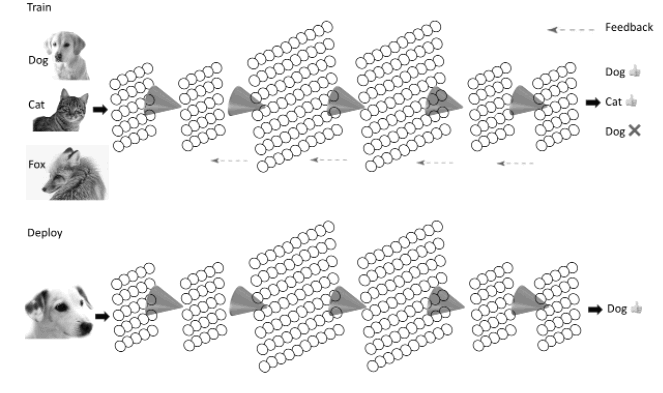
Such deep learning techniques, embodying a range of diverse architectures, now generate huge excitement, as robots learn to play arcade games to super-human standards. Most recently, they beat the world’s strongest players of the Chinese board game Go. In both cases, finding patterns not just in static input, but in correlations across time.
Prise open deep learning devices and the symbols and rules of logic that define other AI methods are absent.* In fact, open them up and the key ingredient is complex and ever-changing matrices of connection weights. A natural question for these systems is, how could they ever explain what they are doing, be transparent and open to scrutiny? One of the enduring benefits of other AI methods is that they can offer explanations and justifications precisely because they represent and reason in terms of rules. We can ask how a rule-based system came to conclude that this patient has a particular gram-negative infection. The system will offer up its trace of rules and the facts that made the rules true at various points in the reasoning process. Deep learning, on the other hand, can be deeply opaque. A fundamental challenge neural network architectures are seeking to overcome.
[* Although there is recent work that attemps to capture the structure of rule-based reasoning within neural networks. See https://rockt.github.io/.]
This quick reprise of various techniques and approaches to AI is intended to serve several purposes. First, that when it comes to building AI systems it is ‘horses for courses’; techniques work better in some contexts than others, have properties that are more or less important in one type of problem than another. Second, we may often need an ensemble of methods to solve complex, multi-faceted tasks. Third, whatever the essence of our own cognitive capabilities, or indeed our very sense of self, nothing like it resides within one or other AI method, or even in any one of the Olympian AI systems that have defeated humankind’s best. Whatever else Deep Blue, Watson, or AlphaGo did or did not demonstrate in their defeat of their human opponents, they derive not the slightest sense of a job well done.
As Patrick Winston, the renowned MIT AI professor, once said: ‘There are lots of ways of being smart that aren’t smart like us.’ And many of these ways may have nothing to say about the hard problem of consciousness and what it is to be self-aware.
*
Even very small brains, as we have just noted, demonstrate the fact that the teeming life on the planet can do very smart calculations, of size or distance or chemical consistency. We don’t need to watch the sophisticated social life of chimpanzees to learn a lot. There are, for example, many species of parasitic wasp. Their modus vivendi is simple: they lay eggs within the bodies of other insects, so that the host incubates the wasp young, and is then its food source. For this to work, the adult wasp makes, using a brilliant evolutionary shortcut, a very precise calculation of the exact size and number of eggs it will lay. (To quote Professor Robert F. Luck of the University of California’s entomology department, ‘Prior to ovipositing in a host, a female Trichogramma repeatedly walks over the host assessing it by drumming the surface with its antennae.’) The angle between head and scapus (antenna segment) is strongly correlated with the radius of the host. We have already noted the ingenious exploitation of body structure that allows a female cricket to find a mate. Many robot designers and AI researchers in the late 1980s and 1990s drew inspiration from evolution’s solution to apparently complex problems, problems confronting short-lived insects with very small brains. Solutions that incorporated, for example, the fundamental spatial aspects of navigation into the design of sensors and body structures.
Let’s look in a little more depth at the Sahara Desert ant, several species of Cataglyphis. There is computation built in to the morphology of these small creatures. Intelligence resides in a combination of their neural networks, sensory organs, and plain body structures. This can be as true of machines as it is of insects.
Sahara Desert ants live and breed in holes in the sand. They emerge from these holes and travel to find food: they are scavengers, living mostly on the dead bodies of other insects. They need to be able to navigate terrain where smells are pretty much non-existent, geographical features very limited. One species, Cataglyphis fortis, covers distances of more than 100 metres on a meandering search path. On finding food, they grasp it in their mandibles and return literally straight home, back to the nest in a straight line. They do not retrace their outward path. They achieve this by combining two calculations: they calculate the distance they travel very accurately; and they are able to fix the angle of the sun in relation to their bodies. They have, in other words, something like a built-in pedometer and sky compass, and can probably also combine these with snapshots of terrain. A moment’s thought will alert the reader to how that works as a general principle. Researchers have so far incomplete knowledge, but do have some remarkable insights. The humble ant achieves this remarkable feat by continuously updating their home vector, the way home to their nest. This vector is calculated from two inputs: walking direction, and the covered distance of each path segment. Direction is given by the angle of the sun and an adaptation to part of their compound eyes, which are sensitive to polarised sky light. This gives them directional orientation. For distance they employ a ‘stride integrator’. The whole process is known as path integration.
This requires some variety of memory, but not a very sophisticated one. Researchers think it is probably built in to the nervous system, though have yet to isolate it. We know about the stride integrator mechanism through the work of Professor Wehner of Zurich University and colleagues. They made a number of experimental adaptations to the ants. In one cohort they removed leg segments, in another, believe it or not, they attached tiny stilts. This procedure was applied when the ants arrived at a feeder station. On the return trip, the modified ants wrongly estimated the distance home. Those with shorter legs literally came up short; those on stilts overshot. In subsequent trials, the modified ants coped fine on a complete journey.
It is easy to see how generations of ants dying in the hot sands because they missed their own front door would lead to the survival of the fittest, those with the pedometer and sky compass mutations.
Here is Professor Wehner’s summary of these experiments:
Path integration requires measurement of two parameters, namely, direction and distance of travel … Travel distance is overestimated by experimental animals walking on stilts, and underestimated by animals walking on stumps — strongly indicative of stride integrator function in distance measurement.
High-speed video analysis was used to examine the actual changes in stride length, stride frequency, and walking speed caused by the manipulations of leg length. Unexpectedly, quantitative characteristics of walking behaviour remained almost unaffected by imposed changes in leg length, demonstrating remarkable robustness of leg coordination and walking performance.
These data further allowed normalisation of homing distances displayed by manipulated animals with regard to scaling and speed effects. The predicted changes in homing distance are in quantitative agreement with the experimental data, further supporting the pedometer hypothesis.
‘The desert ant odometer: a stride integrator that accounts for stride length and walking speed’, Journal of Experimental Biology
This kind of natural example is potent for our general theme. The ant going about its daily life in the desert has tiny processing power, tiny memory, tiny conceptual apparatus. It certainly has no self-consciousness, nor even a mind with two or more rooms. It surely has no sort of consciousness at all. Yet it manages to negotiate that very hostile environment, in its own terms, with near perfect efficiency. If we were able to interview the ant and establish what tasks it felt it was engaged in, what its purposes were at each stage of its day, and we could then assess how well it deployed the resources available to it to meet those ends, we would have to roundly congratulate it.
It is difficult sometimes to avoid seeming circularity when discussing the adaptation of natural organisms to meet the challenges of their restricted worlds. An organism can only survive if it is fit, meaning it withstands all the pressures around it sufficiently to create replicas of itself unto the umpteenth generation. How do we know this is the result of adaptation? Well, if it wasn’t adapted, it wouldn’t be here. Mary Midgley and others have criticised extreme ‘adaptationists’ for this near tautology. And for being apparently reluctant to accept a looser version of the world, in which Nature, as it used to be called, is a work in progress, in which abound odd, slightly wrong, sizes of limb; dysfunctional, but not fatal behaviours; leftover useful stuff the genome has yet to bother clearing up, like the human appendix. The genome itself is full of so-called junk DNA, an attic full of leftovers that may come in useful one day, as well as things we don’t fully understand which may be useful already.
Yet evolution has turned out a tiny creature with on-board technology as effective at the task in hand as the electronics we have just begun to put into our road vehicles. Evolution uses microscopically small smarter devices than at present we know, embodied in brains that could fit on a pin head. Rockets hauled satellites into orbit, silicon copper and plastic were assembled in Chinese factories, to enable our most sophisticated automobiles to carry around gadgets the size of several thousand ants to do the same job. The ant’s system, however, is not repurposeable. It is not a general Turing machine, dedicated to one task, but in principle able to do thousands. It works only in that one tiny environmental niche, might well be useless even to answer much the same challenge elsewhere — if the ant colony were relocated, for instance, to a very different terrain.
A girl on a bicycle can perform all these tasks easily because far and away the smartest device in our lives is … us. That, of course, is why the social machines we examined in the previous chapter are so important. The implications for robotics and for theories of the brain and mind are strong. Heavy processing power is powerful in some circumstances, but the ability of evolution to (as it were) resolve a problem with simple elegance is also powerful. And happens without anything like consciousness in the individual creature, let alone purpose in creative evolution.
*
Can machines breed like us? ‘Animals replicate, repair and improve,’ says Fumiya Iida of the University of Cambridge’s Machine Intelligence Laboratory. ‘No robots can do that today. We are looking at bio-inspired robots, trying to see how aspects of evolution can be incorporated into engineering.’ So far, he has only succeeded in building a robot that can waddle across a room slightly faster than its ‘parent’ robots did. Crucially, though, it is waddling in ways it devised itself. According to Iida: ‘What we found really interesting was the weird structures and designs. They had chaotic locomotion, but it worked. Because the mother robot is inventing through trial and error, it can come up with a solution that is very difficult or impossible for a human to design.’
The perils of this technology (robots that breed themselves towards ends we did not expect) and the opportunities (robots that help us to keep our identity as we age) need to be very closely monitored. At present, a selfish robot is one programmed to be selfish. Virtually all are programmed in fact to be either cooperative or altruistic. Depending, no doubt, on endless discussion of the precise meaning of those words. A cruise missile coming through the window may not strike its victim as very cooperative. It is cooperating with the drone pilot, not the target. Machines are built to serve their only begetters. So far.
*
Let’s turn again to the famous Turing Test, and unpick it for the new age. It was a thought experiment before computers as we know them began to exist; was indeed a key intellectual step in their invention. The test was this: I am in a closed room. Either a computer or another human is in a second closed room. I can send messages or questions via an honest broker to the other room. The inhabitant of that room can send messages or replies to me. If those communications are such as to make it impossible for me to tell whether my correspondent is human or not, and in fact it is a machine, then we should call that machine intelligent.
The philosophical and ontological ramifications of this are legion, and debated hotly. The test has always been avowedly artificial. A three-year-old child, undoubtedly much more intelligent than any machine so far built, would probably fail to convince, if put in a separate room and only allowed to communicate with an unfamiliar adult in another room via a reliable channel, however skilled.
Even allowing for that, it seems plain to us that the Turing Test as described is about to be old hat for machines, considered as a group. We can illustrate that easily by updating the closed room and honest broker in the classic experiment to the dialogue between a telephone call centre and its customers. There are hundreds of these nodes spread over the world, often taking care not to advertise their geographical location to the callers, or that the staff are the brightest and best of cheap labour forces in poor countries. Many large organisations, including those with call centres, answer calls in the first instance with a recording of a pleasant person offering choices — press one for this, press two for that. Now, we already have machines that can answer questions on their specialist subject in plausible voices. There will be machines doing that task indistinguishably from humans very soon. The owners of call centres have available tapes of millions of conversations, which DeepMind or similar projects can easily trawl to build answers to practically anything that is ever said to a call centre operative, and to say ‘sorry, I really don’t understand you’, convincingly, to the small remainder of unanswerables. Often, angry callers ask to speak to a supervisor. They won’t be able to make out if the supervisor is a machine or not. We may make laws to regulate this. As we shall see, we should know what is listening to us, what our social liabilities are. Is there an obligation to treat a machine with courtesy?
So we will have Turing-intelligent machines in call centres any day now. Such machines can be programmed to tell callers, if asked, that they are humans. The caller will simply not be able to distinguish. Although the best systems, like Google’s Tacotron-2, still fumble here and there, machine-generated speech is getting better all the time. This is a practical issue which is solvable and being solved. Call centres already operate with extensive scripted material. A library of recordings of people speaking those scripts, originally recorded live in conversation, will be deployed, in response to lightning fast analysis of the question asked (no different in principle to Google’s response when a topic is typed in), and in convincing tones. Soon the timbre and texture of machine-generated speech will be usually indistinguishable from the human voice.
Catch them out by asking them who won last night’s ball game? The machine can be fed as much news as the callers know. Catch them out by asking them what day Paracelsus was born? Easy to give the machines the whole of Wikipedia to instantly look it up. Why bother? Humans in call centres don’t know anything about Paracelsus, they just apologise and ask why it is relevant to your insurance claim or grocery complaint. Which is what the machine will do, to maintain its cover as a regular human.*
[* Paracelsus is supposed to have been born on 17 December 1493. See E. J. Holmyard, Alchemy, Pelican, 1957, p. 161.]
So also, crucially, they could be programmed to tell callers that they have feelings. Could the caller please stop being rude to them about the utility company’s poor service? If we have no way of telling, at the end of a telephone line, whether or not we are conversing with a machine, we have precisely equal inability to tell whether that machine has feelings, if it is programmed to say it has.
And, plainly, we have and always will have, reason to disbelieve it. Such machines, when we soon have them, will fail just about any reasonable test of the plausibility of their being sentient, of having feelings, and, in anything like present knowledge, always will. Just to be clear, it is now and will be for decades — perhaps forever — perfectly simple for scientific investigators to visit a call centre and discover that the apparent human is in fact a speaking machine. That is irrelevant to the Turing Test of intelligence. Turing’s subject in the classic test, trying to guess whether the message passed to them was from a machine, could always have wandered into the next room and seen for themself.
The other puzzle, posed by the recent popular film Ex Machina for instance, and in a thousand other science fictions, is, could an android, a human-shaped robot, at some near point in the future, fool you into thinking it is human when it is in your presence, rather than behind a screen or at the end of a telephone fibre-optic cable? That is plainly a different kind of question. Despite the film, the answer is, it will be a long time before anyone builds something that utterly could convince us in the flesh. (Or flesh-seeming polyethylene. Or whatever.) Although that, too, would not pass the screwdriver test: a bit of poking around and the investigating scientist would know she was only looking at an imitation.
But what about a machine which doesn’t try to look or sound like a mammal, but sits there, all drooping wires and pathetic cogwheels, and claims to be unhappy? Well, clearly, if a machine in a call centre can operate in a way that convinces us, or leads us to assume, that it is human, then another machine can tell us in the same persuasive tones that it thinks and feels just the way we do. In fact, the experimenter in the classic Turing Test will ordinarily ask the unseen correspondent how it feels today, does it like ice cream, and so forth.
So then it is worth looking at a classic philosophy question — to do some gentle metaphysics. The reader will be familiar with the ancient concept of solipsism. Solus ipse, only oneself. Only I exist and nobody can prove any different. That is not our position. Here are the three steps which get us there. To avoid tedious circumlocutions, we will use the first-person singular.
First, if I look at the multi-coloured row of books on the shelf across my room, and ask myself if I am conscious of me and them, then of course my reply to myself is yes. But what I need to know is, what would the books look like to me, and what would I feel gazing at them, if I was not, in fact, self-conscious? The nearest thing to a philosophical consensus on this in the western academy (there is no philosophical consensus on this in the western academy) is Descartes. I think it is me looking at these books, and if I am in fact a self-fooling, not-really-conscious machine, I can cheerfully live with that. If I am nothing, I have nothing to lose. This position, perhaps best described as naïve realism, at least works. Buddhists might regard it as stopping entirely the wrong side of the enlightenment we were aiming for, phenomenologists and many other breeds of philosopher and most religions think it just plain inept, but there we are, it works.
The second question is, how do I know you are self-conscious? The simple response to that is, there can be no scientific test of other human consciousness. It’s not possible, perhaps not actually desirable either, to look deep enough into another being to know, beyond doubt. A useful analogy is a simple fact about the colours of those books on my shelf. It’s easy to establish that humans have colour consistency. If I think a book is red, most everybody else will too; if I think it is blue, so will they. It is, however, impossible for me to know whether they see the same blue and red as me, or instead (as one instance) see the colours the other way around, blue looking to me what red looks like to them, and vice versa. This may not be a profound mystery. Perhaps one day someone will devise a test for how colours appear, having understood new factors about the way perception works. But it is today a fact. Similarly, I think you are conscious and self-conscious because you look and behave in an utterly convincing manner, and I have no window into your brain to tell me differently, and I cannot possibly derive an answer from anything visible in your presence or behaviour. If I assume you are not sentient, then sooner or later I end up in physical pain. Probably mental, too, but let’s keep it simple. Also, crucially, in what plausible universe would self-conscious me be surrounded by evolved beings who appeared conscious and convincingly claimed to be so, but in fact for an impenetrable reason were wrong, and really only I had the tragic self-awareness, although they either imagined or pretended they had? So naïve realism again at least gives me a modus operandi. I’ll just assume what I can’t possibly prove, because it is the only coherent view I can stumble on, and I will never in practice know the difference.
But then, the third question. At some point, somebody will build an artificial intelligence which is able to seductively tell me that it is self-conscious, indistinguishably in content terms from the way a human tells me. Obviously, when DeepMind’s AlphaGo triumphed 4–1 over Go grandmaster Lee Sedol with an elegant, innovative strategy, the avowedly artificial intelligence did not know it had won. So there! But DeepMind would have no difficulty, if they wished, in adding a beguiling interface to the next version of AlphaGo, with curly wires to video cameras on the score line and on its opponent. They could give it a pair of speakers, and some groans to emit if it gets into trouble, and a nice victory speech about how well its opponent did considering his design deficits, and, in case it loses this time, a no-hard-feelings speech, or a we-was-robbed speech, depending on how the game went. So AlphaGo will then have that ‘knowledge’ and that ‘intelligent reaction’ and those ‘emotions’ about what is happening to and around it. If I am in a position to do scientific tests, then I can easily discover that it is a machine. But that does not mean it is not sentient. I won’t begin to be convinced by the comic AlphaGo version we just imagined, but more challenging versions will come along. The question, how do I know this machine is self-conscious, once the box of tricks gets a little more sophisticated, is no more susceptible to a Popperian scientific test than is the second question, the one about conscious other humans. And this time, crucially, we have every reason to go the other way on plausibility.
If someone tells their family, don’t touch this dish it is hot, they have just burned themself, there is no extrinsic scientific or philosophical test to show they actually exist and feel pain. But a wise person will certainly be convinced that they will feel pain too if they touch the dish. And can’t, day-to-day, operate under any conviction other than of other people’s existence and sentience. The pain factor is present also if the smoke alarm goes off. But if it was programmed to wake the wise person by shouting ‘Ow that hurts!’, rather than a horrid whistle, although the wise person would take action on the information, they would waste no time thinking they had a sentient fire alarm.
It does look incredible, in anything like the present state of knowledge about consciousness, that we will ever be able to thoroughly convince ourselves that we have built a sentient machine. Knowledge expands and contracts, sometimes rapidly. There may come a significant breakthrough in this field, but it is not on the horizon yet.
The philosopher Daniel Dennett calls this the ‘last great mystery’. Not, we think, in the religious or E. M. Forster’s sense of the term, as something forever and in principle beyond earthly resolution. Consciousness is an emergent property of the sum of multiple simultaneous biological processes.
The film director Alfred Hitchcock had a striking murder puzzle that he planned to film:
I wanted to have a long dialogue scene between Cary Grant and one of the factory workers as they walk along an assembly line … Behind them a car is being assembled, piece by piece. Finally the car they’ve seen being put together from a simple nut and bolt is complete, with gas and oil, and all ready to drive off the line. The two men look at it and say, ‘Isn’t it wonderful!’ Then they open the door of the car and out drops a corpse! … Where has the body come from? Not from the car obviously, since they’ve seen it start at zero! The corpse falls out of nowhere, you see!
Discussion with François Truffaut, quoted in Michael Wood, Alfred Hitchcock: the man who knew too much, 2015
This is precisely the opposite to the problem of consciousness. Hitchcock’s dead body must have somehow been secreted from outside into the assembly process at a late stage. He never made the film, so we will never know how. (He claimed not to have made the film because he had no idea either.) In contrast, consciousness is a new kind of life, and is not sneaked in from outside: it emerges from the nuts, bolts, gas, oil, chassis, engine, all of which are, or will be, visible to us soon enough. We don’t know how at the moment, but there is every reason to suppose that we will work it out eventually. But perhaps not for quite a while.
In the meantime, we make these related statements:
One, machines either exist now, or will soon exist, which can easily pass a Turing call-centre test, not merely for intelligence, but also for sentience. Which can therefore, at the distance implicit in Turing, pass as humans. Actively pretend to be humans, if a human agent so arranges them. Therefore, a Turing Test, although it may be a test for a carefully defined, restricted version of what we mean by intelligence, is not a useful test for sentience.
Two, we will never have scientific proof that a machine is sentient, at least until we have a much more advanced corpus of biological knowledge, of an utterly different kind to the present state of the relevant disciplines.
Three, no machine will, in the foreseeable future, meet a general plausibility test for sentience, if thoroughly examined as to how it works, its software, the provenance of its materials. We will always have good reason to doubt the plausibility of the sentience, always have good reason to suppose we are looking at a simulation. We might formulate this as an Always/Never rule. Digital apes are always to be regarded as intrinsically capable of sentience; machines are never to be regarded as intrinsically capable of sentience. Of course, a human may be blind drunk, damaged in a car crash, or have significant learning or physical difficulties. Those impairments, short or long term, do not contradict the intrinsic consciousness capability of Homo sapiens, even if they lead, on occasion or in extremis, to practical or moral conundrums. A particular machine may become a great friend, like a treasured pet, or more. Its absence or destruction might cause distress to one or more humans, but, to repeat, for the forseeable future, it will never be anything other than an illusion to regard the absence as the loss of a conscious Other, or to accept an alarm from the machine as a cry of true pain.
Our background information on this is overwhelming. Sentience is one end product of hundreds of millions of years of descent with modification from prior living things. We have no certainty about how it is constituted, but it seems at the least to include both perception and activity. Those books again. If the titles were in Chinese, they would feel different to me, because I project my years of reading English script on to them. (Using the first-person again, for the same reasons as before.) If I had just peeled off from William the Conqueror’s army through a time-warp, I would be astonished by these bizarre objects, not least at the aforementioned range of colours, unknown in 1066 except in a rainbow; and would never have seen a script shaped as a codex, a book with pages rather than a scroll; and would be utterly unfamiliar with industrially manufactured objects. Overall perception involves many mingling sub-layers, from multiple sources, each of them acquiring some of their meaning from both learned and innate, inherited, knowledge. But we also reconstitute the reality we see and feel, as we go along, by projecting our understanding onto our environment.
A scientific investigator would not get to the starting gate of belief that a device under their microscope was conscious until they could persuade themselves that the equivalent of all this brain activity, and much more, was present.
*
As we have seen, with a combination of genetic intervention and further development of smart devices we can continue to radically alter our ability to see and hear, our understanding of what we see around us, and our relationship to that environment. The end result, naturally, is as yet opaque to us, in general and in the specifics. But it is certain, because it is already happening, that we will further enhance our machines by thinking about how minds work, and further augment the scope and capacity of our minds by building subtler and smarter machines.
A crucial idea here is the sparse code. Dry cleaners, or the coat-check people at the theatre, could try to remember three things about every customer every day: (1) their face, size, and general manner; (2) what their deposited garments look and feel like; (3) where the garments are in the extensive racks. Or they could do what they actually do: operate a simple ticket system. A sparse code.
It turns out that many living things have a similar function built in. Fruit flies specialise in particular varieties of fruit, and need to be able to recognise them, to seek them out. They use smell. There are trillions of possible smells in the world. But actually only one they are interested in. That one will combine many chemicals in fixed proportions. So the fruit fly is preloaded with beautifully arrayed, but conceptually simple, receptors which react to just the right combination of chemicals in the target smell. Only a few are needed.
Neuroscientists think the same general principle actually applies to the faces and places we know, some aspect of practically everything we remember. Our common sense seems — wrongly — to tell us that we recognise faces by having somewhere in our heads the equivalent of a rogues’ gallery of photographs of everybody we know. Perhaps common sense, on reflection, might hazard the guess that 150 or so very accurate pictures of our Dunbar network are mixed in with a much larger gallery of fuzzier mugshots of people we half know, and more of people we quarter know, or have seen in magazines or on television. And of people we knew very well when they were half their present age. Also, we remember a sister or daughter in her blue dress, in her purple hat, in what she was wearing this morning, in … Then perhaps common sense would add in photographs of familiar places and … A vast storehouse of imagery.
This — wrong — common sense version would be not unlike the way some machines used to do it, and some still do. Digital face-recognition software is widespread now, available for domestic devices even. There are many different methodologies, but clearly the status of the database and how it is used are key. A door entry system to a factory can have full-length shots of all authorised employees already in the can, and will require them to stand in a similar position in front of a camera to gain entry. Customs, visa, and law enforcement agencies have very large servers full of millions of such mugshots. Matching is reasonably simple, for a machine, linked to big aluminium boxes.
Google, Facebook, Baidu, and other big web organisations now have face-recognition software good enough to recognise most people in the street from informal family and friends social network pictures. The capability here, based on modern deep neural network learning techniques, is now very great, with significant privacy issues. The face-recognition software developed by Google is trained on hundreds of millions of faces, using advanced neural network techniques. They use this at present to enhance procedures like photo tagging, to which people have agreed, and only on those accounts. Facebook pictures are not, in general, open data. In Russia, on the other hand, the major social network, VKontakte, does publish all profile pictures. FindFace, a very smart Russian dating app, downloaded 650,000 times by mid-2016, has some of the best recognition software in private hands. It is capable of recognising seven out of 10 people on the St Petersburg metro. So FindFace is, inevitably, now widely used in Russia by ordinary people to identify other ordinary people they like the look of. A quick photo of that young woman walking down the street, use FindFace to track down her social network presence, start messaging her. Nearly okay in a few situations perhaps, but the thin end of myriad patterns of unwanted and unacceptable behaviour. All kinds of ‘outing’ of people engaged in activities they would rather keep private, or rather keep in separate compartments. And that’s before governments and other busybodies start regularly using it.
So if machines can be so smart at recognition, does that not mean they are just like us, at least in that one important respect?
Neuroscientists think this is a wrong view of how digital apes do it. That deep learning, based on masses of data, is an unlikely, extremely inefficient way for our own minds to operate. The average head on a 40-year old Parisian, say, does contain an immense amount of information, but not sufficient to identify millions and millions of faces. Neuroscientists are excited by a different theory. Start with the idea of a face. We are probably born with software that clues us in about ‘face’ in general. A baby seems to seek out their mother’s face from their first days, and bundle it with her smell and skill at milk delivery in a highly satisfactory nexus, linked to serotonin and other chemicals swirling around the baby’s emotion system. When the baby starts recognising other faces, they have no need to register and store a complete new face picture for each one. They only need to pick out and record what is different about each of them, either dissimilar to the original built-in face idea or to the improved mother version, or perhaps to a developing combined idea of face. Which could underlie the fact that we are all more adept at telling apart people of our own race and, indeed, within that, our own nationality, region, social class. We build our everyday working face template out of the faces we have seen most often, and find it easiest to spot difference to that than differences to a less frequently used other race or region template. The same goes, of course, for shepherds and their sheep. How will that difference be defined and stored? Some variety of sparse code.
Neuroscientists have pretty good evidence about how those sparse codes are constructed. Talking animals in children’s cartoons and women in Picasso paintings quite often have eyes on the same side of their nose, but heads of that configuration are rare in digital ape neighbourhoods. Digital ape faces nearly all have eyes and nose and mouth and cheekbones and chin in a particular conventional arrangement. But never in exactly the same arrangement. The difference between two faces can be expressed, mathematically, by sets of ratios — the angle between the cheekbones and the mouth, the angle the eyes make to the nose, the amount of space between the eyes, and many others. And that, we think, is what the brain remembers, how it codes the difference between this face and that.
Memory experts generally agree, also, that we don’t retrieve pictures from a store. We rebuild memories out of standard components. In this case, the face, we take out our standard face, change the ratios as appropriate, and dollop on the right colour skin, hair. Perhaps also the particular colour of hat and coat. If we remember meeting somebody in the park, we add in the feel, the colour, the smell of open space or tree-ishness.
Homo sapiens has thousands and thousands of such adaptive neural systems. Neuroscientists, zoologists, and philosophers debate whether consciousness is a layer above those, or simply the sum of them, or a mix, built up over generations. Remember, the very earliest of the hominins are thought to have evolved anything up to 20 million years ago, and will have had an alpha or beta version of consciousness, nothing like ours, but different from (say) a dog’s or chimpanzee’s. That would be near enough a million full generations, and many more overlapping generations, of evolution. Metaphorically and literally beneath modern human brains — the old brain is physically at the core of the new brain — there are thousands of ancient adaptive systems that can suddenly jump out and at us. A spider on the wall — aargh! The smell of rotted death — ugh! The child’s disgust at her mother mixing food up on her plate! contrary to the simplest of prehistoric rules for the avoidance of poisonous contamination. Or suggesting she try something new while she already has a mouthful of just fine stuff which has now turned to ashes!
*
As we noted in Chapter 3, we know a lot more about brains than we did when Desmond Morris was writing in the 1960s. We know a lot more about many relevant things, including genetics and the genome, the pre-history of the human race.
The discovery, if such it was, of mirror neurons, is a well-known tale. At the end of the last century, a group of Italian researchers led by Giacomo Rizzolatti were interested in how the brain controls muscles. They dug a finely tuned probe into the pre-motor cortex of a macaque, the frequent victim, restrained in their laboratory, and located the specific neurons associated with arm movement. When the macaque reached out to various interesting objects placed in front of it, the neurons fired, and via the probe caused indicators to light up. The surprise came in a break. The macaque was quietly doing nothing, watching the researchers. A researcher reached out to move one of the objects in front of the macaque … and the control panel lit up. The macaque uses the same neurons to understand, symbolically, the concept of ‘arm reaching to interesting thing in front of me’ as it does to actually carry out the act itself. The implications are profound.
The primary visual cortex takes up more blood when imagining something than when actually seeing it … When we imagine ourselves running … our heart rate goes up. In one study, a group of people imagining physical exercises increased their strength by 22 per cent, while those doing the real thing gained only slightly more, by 30 per cent.
John Skoyles and Dorion Sagan, quoted in Richard Powers, A Wild Haruki Chase: reading Murakami around the world, 2008
Now those must have been rather special, intensive, lengthy brain exercises. But the picture of the brain held by psychologists and neuroscientists has been radically reformed over the past few decades, and the idea encapsulated in the concept of mirror neurons is typical of the approach. Our — wrong — common sense might automatically map our metaphorical ways of speaking about ourselves onto an everyday theory of the brain, as if we were building one ourselves out of raw materials. We know we can remember, and that we can recognise. We know because we do it all the time. So there must be a lump in there called the memory, with a front door to it which lets information in and out. We learn at least one language as a child, and can add others later. So there must be something akin to what Chomsky called a Language Acquisition Device. Since all known human languages share some common features, including the ability to use existing words and lexicons to generate new descriptions, all languages must share both a common grammar, and generative capacity. And our brains must have a component somewhere that does that. We wave our limbs about, so there is a limb-waving outfit. And children will be born with all that kit either in place or on the stocks.
A whole raft of new ways of thinking about the brain, including the discovery of mirror neurons, say that the brain is not easily mapped in that way. Children in fact will develop similar, but not identical, brains, depending on their experience. Adults as their selves develop will continue to change the material manifestation of their minds inside their heads. And minds can also usefully be held to spread around the rest of their nervous system, and indeed beyond.
As a child learns to use their arms, they learn the idea of arms, the idea of movement, they grow the symbolic ability to conceptualise the space in which the arms move, the ability to plan what happens if they are still waving their arms when they walk through a doorway. (Ow!) The cortex in their brain, a highly plastic system, embeds all those abilities and knowledges across wide areas, and folds them in to other abilities and knowledges. A child learning to swim will embed them in slightly different places to a child learning to play the drums. Artificial intelligence has begun to model the spatial harmonics of this, not merely of how we wave our arms about in space, but of how we learn to wave them about.
All this will inform our future understanding of how we ourselves operate, and help us make machines that operate in interesting ways. Driverless cars more aware of the space they navigate, for instance. But a driverless car that can wave at us in a familiar way, having learned something about how we do it, is not thereby itself human. Machines have, for a long time, been able to quack like a duck and walk like a duck. Despite the well-known saying, that does not mean that they are ducks.*
[* The proposition if it quacks like a duck it’s probably a robot perhaps goes too far. The world populations of both ducks and quack-capable machines are not simple to calculate with precision. There are at least 5 billion smartphones alone, and something like the same number of radios and televisions. Only a small proportion of the 200 billion or so birds are ducks. So it is very likely that the smart machines capable of quacking do outnumber the wildfowl. However, the machines usually have better things to do with their time than quack. Ducks don’t.]
The present authors see little point in building machines which look and act like human beings. Except perhaps as part of elder care, or in fantasy play. After all, we have way too many humans already. Smart machines should and do look like smart machines. The gadget that tests your car engine has no need to wear overalls and look like a mechanic, indeed would be less efficient, less shaped to its purpose. An automatic carpet cleaner or lawn mower has no need to look like a servant from Downton Abbey. Making them resemble a human performing the same task is just a waste of resources.
To sum up, we utterly doubt that in the coming decades self-aware machines will exist, let alone intervene purposively in global decisions about the survival of the human species in its present form, or anything else. We do, however, believe that the ubiquitous machine environment has changed and will continue to change human nature, and that unless we take care our machines might come to oppress us. The patent fact is that most individual modern humans, as well as all nations and large groups, now have, through the machine empires, massively amplified powers. What we should worry about is not our devices’ human intelligence, but their super-fast, super-subtle and not always stable machine smartness. We can control the new technology; the danger is that we won’t.
Google, Facebook, and others today use very advanced neural network techniques to train machines to do, at large scale, tasks young children can do on a small scale in the comfort of their own head. Google bought DeepMind, the famous enterprise of one of the field’s present great stars, the undoubtedly extraordinary Demis Hassibis. DeepMind has built some of the most innovative neural networks in the history of AI. Systems that are capable of superhuman performance in specific task domains.
Let’s take one of the achievements of these modern neural networks. Increasingly, machines can be taught to recognise the content of pictures, and they do extraordinarily well compared to a few years ago. Google (or whoever) is now able to access millions of images that include, for example, pictures containing birds, cats, dogs, thousands of categories of object. This is possible because of the enormous sets of annotated and tagged pictures that we have all collectively generated, sometimes by being paid a cent a time to annotate images and say what is in them — a form of crowd sourcing. These are given to the trainee machine, in a reasonably standard format, roughly a certain number of pixels. The machine then searches for what is common and different. It focuses in on the numbers which represent the pixels, and begins to notice patterns, which correspond perhaps to shapes and contrasts and dis-continuities in the pictures. In the jargon, it applies convolutional filters that crawl over the images looking for patterns. Patterns that might eventually, in the deep layers of our neural network, become a mathematical expression of beakness, wingness, birdsfeetness in one of our labelled categories. What Google is aiming for is a set of numerical relationships which can be trusted to be enough to rootle birds out of a big mound of pixels. The readers of this sentence know what a ‘beak’ is. They ‘possess’ the concept, stored in memory. They keep the word ‘beak’, too. They have the ability to conjure up mind’s eye pictures of beaks, large, small, hooked, red. With worm or without. They can also recognise a beak when it flies past, and in a photograph. Passively: did you notice that bird has a bright-yellow beak? Oh yes, actually I did, now you mention it. And actively: pick the yellow-beak bird out of this line-up. The brain layers these abilities on top of each other, somehow keeping the abstract concept of beak and the picture of a doomed worm close to each other. The machine in recognising a bird, from a dog or a cat, is looking for patterns in the digits it has been trained on. In other words, it stores, seeks, and recognises patterns in digits.
The key ingredient to note, though, is that apes were marshalled to do the killer work. The genuinely smart machine technique piggy-backs on the cognition, intelligence, understanding, and semantic interests of humans. A few further extensions of this truth are worth emphasising.
First, imagine that a newly commissioned machine learns, from scratch, to distinguish cars from birds from elephants after application of pattern recognition to thousands of photographs, labelled by humans. Or labelled by another machine that learned the trick last week, an increasingly common situation. The human observer can watch the process, but, without delving into the number codes, will not know what aspect of ‘car’, ‘bird’, ‘elephant’ the machine has settled on as the most efficient distinguishing mark. It could be patterns and features related to ‘headlamp’, ‘beak’, ‘trunk’, and ‘big ears’. But if all it ‘knows’ is this set of pictures, the distinguishing mark for picking ‘car’ out might be the pattern for ‘streetlight’, since a tiny proportion of pictures of elephants will be taken on an urban street. In consequence, if the machine was fed a photograph of a completely empty street and told it contained either a car or an elephant, it would pick ‘car’. In other words, this kind of machine learning depends so little on understanding the concept of its subject, it can in principle recognise its subject without looking for any of its actual characteristic, and will ‘recognise’ its subject even if it’s not there at all.
This is both very powerful and a tad worrying. It also, secondly, means that machines learning this way are more obviously engaged in a universal human process we don’t always notice in ourselves: drawing conclusions from peripheral, subconscious, half-seen, inadequate data, stored in the background. So, for instance, humans shown pictures of coastline scenes from around the world — just sea, sky, beach, or rocks, or cliff, no people or buildings — can, with some degree of accuracy, guess which country they are looking at (and so too can the new generation of learning machines — and better). They are far less good at guessing how they know, which will be combinations of how the light falls, the size of waves, skyscape. We do, of course, constantly draw conclusions about practically everything in the same way. We would never have survived as a species without this capacity.
The issue of what precisely the artificial neural networks are paying attention to is also well illustrated in the fact that, since 2014, we have known that one network can be trained to fool another. Researchers from the Universities of Cornell and Wyoming used a deep neural network that had achieved impressive results in image recognition. They operated it in reverse, a version of the software with no knowledge of guitars was used to create a picture of one, by generating random pixels across an image. The researchers asked a second version of the network that had been trained to spot guitars to rate the images made by the first network. That confidence rating was used by the first network to refine and improve its next attempt to create a guitar image. After thousands of rounds, the first network could make an image that the second network recognised as a guitar with around 99 per cent confidence. However, to a human, the ‘guitar’ looked like simple a geometric pattern. This was demonstrated across a wide range of images. Robins, cheetahs, and centipedes generated in this adversarial manner looked to humans for all the world like coloured TV static. Since then, there has been a veritable arms race as networks have been set against one another. What it has demonstrated is how very different the encodings and ‘understanding’ of the machine is from anything that we might naturally see in an image.
Back to AI face recognition: the most accurate systems rely on machines already having been trained on millions of images to determine 128 measurements that identify a face. So what parts of the face are these 128 numbers measuring exactly? It turns out that we have no idea. And here is the difference — a child learns to recognise the faces that matter. The machines are being trained to achieve tasks no human would ever be asked to do, except with the help of a machine. Our machines are superhuman in specific and isolated tasks. We are human across the full richness of our general, varied, and socially meaningful interactions.
The implications for processing in the human brain are profound. Our own sparse codes manage to distinguish, from a very early age, many thousands of objects, day in, day out. This is not to say that the sorts of features and information signatures being abstracted from large training sets by artificial neural networks will throw no light on human visual processing. They may well assemble libraries of intermediate representations that are analogous to aspects of human visual representations.
There are both similarities and utter dissimilarities here to the way in which we think humans think. Hence the relentless drive to understand the neural base of our intelligence. And it is leading to real results. Just recently, for instance, we have discovered that, contrary to what everybody thinks they know about the brain, regeneration of its cells continues apace through life.
We are clear that the higher order cognitive functions of the brain do not take a statistically sound approach to information collection and understanding of the world. It over represents infrequent events and underestimates the occurrence of common events. It generalises by over-dependence on recent and present experience. Clearly, it does this because, in our deep past as well as now, that was usually the safer way of doing it, and led to the survival of one’s genes to the next generation. Suppose you are a hominin with several food sources, one of them green apples. You have eaten hundreds in your lifetime, you have seen your group eat thousands. You come across an apple. You eat it, without washing it. It makes you sick. You develop an aversion, conscious or unconscious. It might, in one sense, simply be bad thinking, or the unconscious position is maladaptive. But what is the correct answer logically? It all depends. How do you know whether this is just one rogue apple, or whether all apples in this orchard are bad, or …? How important are apples in your diet, can they be easily replaced? The obvious answer is to give more value to one instance than statistically it at present warrants because a mammal with that attitude to poison risks will last a lot longer.
Numbers of persuasive studies, with titles like ‘Man as an Intuitive Statistician’ (Peterson and Beach) and ‘Knowing with Certainty’ (Fischhoff, Slovic, and Lichtenstein) have shown that humans find it immensely hard, in everyday life, to act with statistical sense. The most statistically astute mathematician, seeing the same friend unexpectedly twice in the same day, will smile and remark on the coincidence. The mathematician knows, works every day, with the fact that it would be astonishing if we did not from time to time meet the same person twice. That does not prevent it surprising us when it happens, and seeming, in many an instance, to have a meaning which we should take into account.
*
Machines can undertake many of the tasks our intelligence achieves, better than we can. We have learned many astonishing things over the past centuries, but we cannot yet establish even roughly what it is that makes us feel like us. We know enough, though, to know that those intelligent machines are nothing like us in that key respect. Not yet, we should add, nor in the foreseeable future. Gestation of a conscious non-biological entity is beyond our present capacity. Even the remote chance of meeting aliens, over a very long-distance communication link, looks, today, greater than a new consciousness being developed on earth.
That is not to say that machines are not enabling us to see more clearly what our minds are up to. Indeed, we conclude with an extraordinary experiment conducted by scientists at the University of California, Berkeley. They showed photographs to experimental subjects, then old Hollywood films. The subjects had fMRI scanners on their heads. These mapped the activity in the subject’s brain, and recorded the map. A clever computational model, a Bayesian decoder, was constructed from all of the map data. This then enabled the experimenters to show visual images to a subject, and construct a picture of what the machine thought the subject was looking at. The result, which is available on the university’s website, is truly spooky. The lead researcher, psychology and neuroscience professor Jack Gallant, astonished colleagues who doubted his idea would work. The contraption seems able to decode what is being shown to the subject. Read their mind and show us a picture of it. The technique is limited at present, and relies on a degree of artifice, in reconstructing the brain image. But other researchers have later done much the same with sounds, training a machine to decode brain maps of spoken words. Somewhere down this line, it will be possible to help people with severe communication difficulties to circumvent them.
So never mind what the mind of a machine might look like to us. Perhaps some time we will have a glimpse of what a machine thinks the essence of our minds looks like? Not, we think, very soon. Let’s be clear. However startling, this is not yet the Instant Gen Amplifier of Margery Allingham’s marvellous novel The Mind Readers. Nor will the ghostly representations in Professor Gallant’s reconstructions soon lead to the local streetlight reading the thoughts of passers-by and sending them to the government.
Other researchers are developing parallel lines of enquiry to Professor Gallant. More startling visualisations will be constructed soon. And in general, we expect to see machines increasingly using techniques similar to, or modelled on, those our own brains use. Greater understanding of the latter will lead to advances in the former, and vice-versa. This is exciting work. While machines become what might rightly be termed more brain-like, we are confident they will not soon develop core human characteristics, most notably sentience.