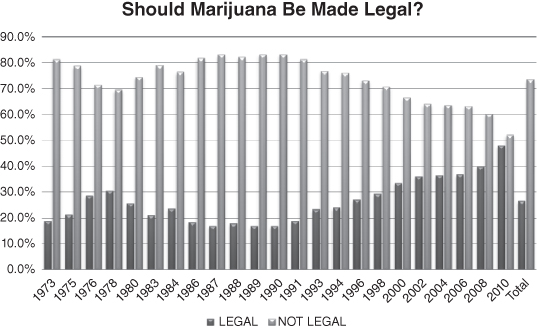
Figure 3.1. The percentage of Americans reporting marijuana should/should not be made legal.
3
OBSERVATION AND EMPIRICAL GENERALIZATION
In dealing with the building blocks of the Wheel of Science, we start with theories and hypotheses to allow us to frame research. Once theory has given us direction for research, we create hypotheses to test our theoretical propositions. When we know what concepts we’re testing and how we expect them to work together, we need to consider what research design will best test our hypotheses. Research designs give social scientists tools that help determine what observations they are going to use to test their hypotheses.
Social researchers draw on four basic research designs from which to collect data to observe the concepts they want to test: surveys, experiments, field research, and secondary sources (which include historical documents, aggregate [or comparative] data, and content analysis). We devote individual chapters to discussing five designs: surveys, experiments, field research, and two of the secondary source designs: aggregate (or comparative) and content analysis. Each research design offers researchers unique ways to collect data about people and social things. It is also quite common for researchers to combine methods in order to triangulate their data.
Designs fall into two basic types, quantitative and qualitative. Quantitative designs rely primarily on describing or measuring phenomena in quantity—generally thought of as numerical quantity. Quantitative designs employ statistics to describe large populations with survey data or to use theoretical generalizations gleaned from experiments. Quantitative designs are also used with aggregate-level measures (comparative measures) to generalize statistically to larger geographic or social units (units generally composed of multitudes of individual people or things).
Qualitative designs rely on quality of description; rather than quantifying large samples of people or units, qualitative designs rely on great detail in reporting human processes. Field research is primarily a qualitative design, where researchers go into a field setting to observe people, collecting very detailed information about some smaller group, process, and/or interaction. Content analysis is another qualitative design, where cultural artifacts are examined to provide context and derive meaning from the things that people create. Both of these designs provide a wealth of detail about social patterns.
To allow you to connect to a general understanding of the full Wheel of Science, we briefly discuss the basics of what each research design entails, to give you an overview of the five designs we explain more fully in later chapters. We’ve organized the book to reflect the grouping of quantitative and qualitative designs, to give you a sense of moving from one type of design to another. Thus we cover surveys, aggregate data, and experimental designs first, as quantitative designs, and follow up with the qualitative designs of field research and content analysis.
Everyone, it seems, has taken a survey. Surveys collect information from people using interviews or questionnaires composed of written questions. Surveys are arguably the most used tool for social scientists, market researchers, and a variety of others looking for information regarding people’s attitudes, behaviors, and experiences. Yet many surveys lack the integrity of being truly scientific. Wordings of questions, question order, and question categories are important considerations for collecting survey data.
Surveys are useful for studying the world as it is—not as we think it is, not as we think it should be, but how it actually is. As we noted in the introduction, we do not experience or observe the world randomly. Our ideas about the world are influenced by our culture and social locations. Scientific surveys should ask unbiased, valid, and reliable questions that tell us about actual patterns of people’s thinking and behaving. What is unique to surveys is their ability to ask a variety of questions to large samples of people (note: only people can take surveys). These questions can be easily replicated to the same population and/or to other populations to gauge change within populations, between populations, or over time.
In previous chapters we’ve had you visit the Association of Religion Data Archives (the ARDA) to search through various items in the 2010 General Social Survey (GSS). The GSS is a nationally representative survey designed to be part of a program of social research to monitor changes in American’s social characteristics and attitudes (ARDA 2011; GSS 2010). Funded through the National Science Foundation and administered by the National Opinion Research Center, the GSS has been administered annually or biannually since 1972. As a general survey, the GSS asks a variety of questions on a variety of topics. For the 2010 GSS, special modules (sets of questions) were asked on the subjects of aging, the Internet, gender roles, immigration, religious identity, and sexual behavior, as well as several other topics. By going to the ARDA (www.thearda.com) you can peruse the Codebook for the 2010 GSS (www.thearda.com/Archive/Files/Codebooks/GSS10PAN_CB.asp) to get a fuller sense of the types of questions a general survey asks. You can also visit the ARDA’s “Learning Center” to take a survey that allows you to compare yourself to a larger national profile. The “Compare Yourself to the Nation” survey allows you to see how you compare to others based on the results from the 2005 Baylor Religion Survey (addressing religious identity, beliefs, experiences, paranormal views, etc.).
Apart from the actual survey instrument (the questions themselves), most surveys are obtained using samples of populations. Populations are the set of all the people you are interested in studying with a survey. Populations can be so large as to prohibit our ability to study all of the units (people), so social scientists select only a portion or subset of people (a sample) to observe. This gets a bit tricky, however. Just having access to a group of people does not make that group of people a scientific sample. We’ll spend a chapter talking about populations and sampling techniques, but for surveys know that generally we select a random subset of a population to take the survey. Randomness ensures that the sample is statistically representative of the population as a whole. Again, we’ll discuss what that means in Chapter 7, “Learning from Populations: Censuses and Sampling.”
An aggregate is one unit that consists of a number of smaller units. Also known in the social sciences as “comparative” data, aggregate data are based on comparing large social units, for example, countries, cities, states, schools, clubs, or churches. Calling data “comparative” is a bit confusing when you first begin to look at research design. Isn’t the entire process of science about comparing how one thing changes when something else changes? To be more clear, we use “aggregate data” to talk about this research design.
Since aggregate data are collected on large social units, rather than individual units, it’s often not data that you collect yourself (while you can write your own survey and send it out, or design your own experiment to carry out, someone else has to have counted the number of visits per national park, for example). Generally aggregate data are “secondary” data—data that are collected and recorded by some official agency or organization. For example, the U.S. Census Bureau collects data on the percentage of the national population that lives in a metropolitan area, or the percentage of the population that is under 18 years old, or the ratio of male to female in states. Since the United States has a constitutional amendment prohibiting the establishment of an official religion, organizations apart from the Census Bureau collect data on religious membership.
The Religious Congregations and Membership Study (RCMS) collects data on congregations across the United States, noting the number of congregations, membership, and adherence. One benefit of aggregate data is the fact that because each aggregate unit is made up of smaller units, statistically there is less measurement error, and the relationships are more robust; it’s rare to find a relationship between variables (or not find one) if a relationship doesn’t exist. Relying on official statistics, however, may carry some costs. When the RCMS data are collected, how do we know if each religious group counts their members the same way? Does each group count children as members, do they even have membership (nondenominational Christian churches often do not), what counts as a religious “adherent”?
Another unique issue within aggregate data is the fact that aggregate units are composed of multiple individual units; thus the aggregates themselves represent a smaller number of cases. For example, when looking at census data for the 50 U.S. states, each state is made up of millions of individuals. When analyzing data for the states, however, there are only 50 cases (because there are 50 states). With so few cases, aggregate data sometimes have outliers. An outlier is an extreme case that masks the true relationship between variables (e.g., what appears to be a significant relationship only appears that way because of an outlier). Checking for outliers is important when using aggregate data, to make sure statistical generalizations accurately reflect the data.
Whereas most people have taken a survey, few have taken part in a formal experiment. Students often ask why they can’t just experiment on each other in a research methods course. While introductory social science classes may have students perform classic norm-breaching experiments like facing the wrong way in an elevator, not standing during a standing ovation, or walking backward all day, true experiments are a bit more complicated. Experiments are a unique design in that, generally, researchers have complete control over the physical surroundings or the experimental condition. In most experiments there is only one independent variable being manipulated. The independent variable is often referred to as the stimulus, where one group of people is exposed to the stimulus (the independent variable being manipulated) while another group, the control group, is not exposed to the stimulus. The groups are then compared to discover if the independent variable/stimulus actually impacts their behavior (the dependent variable). If the stimulus indeed changes individual behavior, we expect the group exposed to the stimulus (the experimental group) to respond differently than the group who was not exposed to the stimulus or independent variable (the control group). The power of the experimental design is the manipulation of the one independent variable to pinpoint changes in behavior. True experimental designs watch the manipulation of the independent variable to see if it causes changes in the dependent variable.
As with other quantitative designs, theory and hypotheses undergird experiments—we need to know why concepts are linked in order to choose to observe people within experiments. For example, a popular experimental topic is the relationship between media exposure and cognition: how does watching television impact our ability to think and learn? Research has linked watching television with long-term attention problems in children. How might we test this experimentally? One study addressing the relationship between media exposure and learning operationalized (measured) media exposure by looking at the effects of watching the television show SpongeBob SquarePants on children’s attention and learning. The experimental design had three conditions, or ways to operationalize the independent variable. The researchers randomly assigned 60 four-year-old children into three groups: a group that watched nine minutes of SpongeBob, a group that watched nine minutes of Caillou (a PBS cartoon), and a group that spent nine minutes drawing pictures. Following these activities the children were given mental-function tests. The researchers found that the children who watched SpongeBob did worse on measures of attention and learning than the children in either of the other groups (Lillard and Peterson 2011).
So what do the results of this experiment tell us? Many take issue with the fact that there were only 60 children in the experiment, which can be a problem although these data are robust. Others may take issue with the three experimental conditions, in that the three conditions (watching two different cartoons versus drawing) were not equivalent; that was the point of the design—vary the conditions and see what happens. You may say, “SpongeBob is for older kids,” which is how Nickelodeon spokesman David Bittler responded (Tanner 2011). There are many ways we can critique the study; however, the experimental design for this study was quite strong and allows us to generalize to behavior—after watching SpongeBob, four-year-olds are more likely to show diminished attention and/or learning (Lillard and Peterson 2011).
Experiments are considered one of the strongest research designs precisely because researchers have so much control over the experimental environment and are generally manipulating just one independent variable at a time. Where surveys allow us to take data from large groups of people to determine statistical patterns, experiments allow us to determine theoretical patterns by showing a distinctively cause-and-effect relationship. In a true experiment with one variable being manipulated, observing change in the dependent variable between the experimental group “exposed” to the independent variable and the control group who aren’t “exposed” allows us to assume the difference between groups must be due to the independent variable. Depending on the type of experimental design, there are additional things to look for, including maturation effects, history effects, testing effects, and so on. We’ll go into more detail on those issues when we look specifically at experimental design in Chapter 14.
The second characteristic unique to experiments is random assignment. When we briefly looked at surveys we talked about random sampling. Sampling and assignment are different, but if both are “random,” they draw on the same mathematical theory. For surveys we are interested in randomly selecting samples from relevant populations to generalize to a whole population. Researchers doing experiments simply ask for volunteers to serve as subjects (university students are most likely to serve as subjects). Once the volunteer pool is established, researchers randomly assign people to the experimental or the control group. Using the mathematical concept of probability, random assignment creates equivalent groups. You may not have a perfectly divided set of groups (may not get a perfect 50 percent male/female, older/younger, etc.), but generally the characteristics of each group are representative of the whole group. As long as each subject is randomly assigned, you can attribute differences between experimental and control groups to the independent variable.
Experiments can be replicated, and if done using reliable and valid measures, they show us true causation—when the independent variable changes, we can see changes in the dependent variable. Unfortunately, the high level of control within experiments makes them limited. Experiments can be impractical and artificial. How often are children exposed to nine minutes of SpongeBob SquarePants and then given cognition tests? Experiments are also limited by size. It’s impractical to import significant numbers of people into an experimental setting. There are ways to get around these constraints, but they inevitably involve giving up some control for a more realistic setting. In Chapter 14, when we discuss experiments in depth, we’ll also evaluate settings outside of laboratories where experiments may be more realistic.
As noted earlier, the previous three designs—surveys, experiments, and aggregate data—are quantitative designs, which focus on using statistics to summarize what our observations tell us. The next two designs we explore are qualitative designs. Field research and content analysis are unparalleled in providing rich, descriptive data on processes. These qualitative observational designs represent unique dimensions on how we collect data on or about people.
“Field” typically refers to the setting in which research takes place. For example, people can be studied in classrooms, cities, places of worship, or in coffee shops. As such, field research is research conducted in “natural” settings where people are found. By contrast, many experiments are conducted in laboratories, which are often much more artificial. Field research, or observing people as they engage in activities in their natural settings, seems to be more aligned with how people envision doing social research. When majoring in a field where the focus is studying people, we often see field research as an intuitive process—aren’t we already engaged in observing people? Like the other research designs, field research requires a systematic process of taking observations. While it may seem like common sense to generalize to a particular observed behavior, we noted in the book’s introduction that we simply do not observe the world randomly. Thus while studying people seems more in tune with social science than dealing with statistics through surveys or aggregate data, field research requires skill to recognize both the freedom and the constraints that come with direct interaction and observation of people.
Field research provides a wealth of data about smaller groups of people, giving us rich, descriptive information about people and processes. Field research is, however, limited to smaller groups of people making it generalizable only to the group you study—in effect creating a case study. Like surveys and aggregate data, field research also cannot establish causation.
Several factors should be considered when you decide to use field research. These factors include where you will be collecting data (in a public setting or a private setting), when to go into the field as a covert versus an overt researcher, and how much observation versus participation you will employ.
When developing a research question that is appropriate for field research, where the research takes place is important. The field should be a place where the observation of people in their natural setting sheds light on the research question—are observations best taken in public or private settings? For collecting observations in a public setting—where anyone has access (parks, coffee shops, malls, etc.), there are fewer hurdles. Since access is open in a public setting, researchers do not need to get specific permissions to collect observations. There is ambivalence in the field, however, about doing research in public settings: who has more rights to freedom, the researcher who should be free to observe in public spaces or the people in those spaces who are unaware they are being observed for a research project? Generally, public spaces are seen as open for research observations; keep in mind, however, that there are boundaries of what and how research in public spaces can be done.
Imagine a study where research is being conducted on behavior in public restrooms. After the study begins, the researcher realizes he can obtain greater detail about the participants if he can connect them to the cars they drive. He watches as people leave the public restroom to see which cars they drive. The researcher also realizes that while he’s connecting people to their cars, he can take down the cars’ license plate numbers and use them to track people to their home addresses. While this study may sound farfetched, it is actually a classic field research study (Tearoom Trade) that we discuss in Chapter 4 on ethics. Clearly the researcher was creative in his bid to collect more and more data on men in public restrooms; however, by taking such information about them (tracking them to their homes), he violated their rights to privacy.
When choosing a site for research that is in a private space (e.g., doing research on a club, congregation, neighborhood, organization, etc.), there are more hurdles. Researchers need to determine if they are going to go into the private space as an overt (open) or covert (hidden) researcher. Since the research will take place in a private setting, the best practice is to get permission to conduct the research whenever possible. For some studies it is appropriate for the entire group to be aware of the researcher and his or her aim; for other studies it is more appropriate if permission is granted by a group leader, rather than the whole group. For example, Lofland and Stark (1965) sought to study the process of religious conversion. Finding a religious group that was new to the United States, the researchers realized that they did not know how long the process of religious conversion might take. Keeping this in mind, they sought permission from the religious group leader, asking her if they could remain unknown to the other group members. This strategy for research was entirely suitable for their research aims. Permissions may be integral to a researcher’s ability to get access to a private space, requiring researchers to negotiate their access to the field site(s). We look at issues of access to the field in greater detail in Chapter 17.
As we just described, another conundrum related to entering the field is whether to be a covert or an overt researcher. Covert observation is when those being observed are unaware of the research. This is helpful in minimizing observer effects since researchers won’t interrupt the natural setting or arouse suspicion by their observation. Going into the field covertly, however, can also hinder research because the researcher is expected to act in accord with the larger group. Covert research can also be problematic ethically. Like collecting data in public spaces, there is a question of who has more freedom—shouldn’t those being observed have the right to refuse to be part of the research? Often the clearer choice is to go into the field as an overt researcher, where those being observed are aware they are the objects of research. Being an overt field researcher makes conducting research easier ethically, although there may be some initial issues with the Hawthorne effect—where subjects may change their behavior when they are aware of being observed. Again, we discuss these issues more thoroughly in Chapter 17.
One last issue pertaining to entering the field is choosing what level of participation to have with the group. Can the researcher simply observe without participating in the group, or is being a participant important to the researcher’s method (e.g., being fully immersed into the group)? Participant observation yields some fascinating results while also raising some questions, For example, can a participating researcher maintain objectivity, or does the researcher’s participation change the nature of the group or of an activity? What risks is the researcher prepared to accept when participating with the group? While field research allows social scientists to interact directly with people, this research design comes with a variety of decisions and constraints that researchers using other designs do not encounter.
The last design we discuss is content analysis. Like aggregate data, which doesn’t directly deal with humans, content analysis is an unobtrusive measure. An unobtrusive measure is one that is inconspicuous, meaning it does not have a direct impact on people. Instead of surveying, experimenting on, or observing people in the field, content analysis is the study of cultural artifacts—things that people have created that tell us about human life. Thus comic strips, song lyrics, Web pages, blogs, films, sermons—verbal, aural, and visual data—are the materials that are coded for meanings and patterns. As a qualitative design, content analysis provides detailed and rich descriptions of phenomena: for example, is rap music more violent than heavy metal music?
Sociologist Amy Binder (1993) undertook a content analysis to study the rhetoric surrounding harm in rap music and heavy metal music. Within five years of each other, these two music genres garnered national attention. Founded by a group of Washington, D.C., wives, the Parents Music Resource Center (PMRC) testified before the U.S. Senate in 1985 on what they described as the harmful messages in heavy metal music lyrics. The PMRC claimed that heavy metal lyrics were damaging to youth (and therefore the nation) because they focused on pornography, drug use, occultism, and suicide (among other things). Five years later in 1990, another music genre came under fire when the rap group 2 Live Crew released their album As Nasty as They Want to Be, which became the first album to be declared obscene by a federal court. Band members were arrested when they tried to perform from the album, and some local record store owners were arrested when they sold the album (Binder 1993).
Drawing from these high-profile cases, Binder conducted a content analysis on the rhetoric used to construct these two music genres as harmful, finding that race made a significant difference in how the lyrics were interpreted by the mainstream media. In the rhetoric that constructed harm in “white” heavy metal music, the focus was on the “anti-authority themes” within the lyrics that were touted as harmful because adolescents would become corrupted “in their attitudes about school, parents, and sex” (Binder 1993:765). The rhetoric used to frame “black” rap music, however, focused on a general outrage at the “unprecedented explicitness of rap,” noting that rap music was harmful because it would “cause listeners to wreak havoc on police and women” (Binder 1993:765). Whereas the heavy metal genre was seen to be white, the impact of the lyrics was about individual adolescent attitudes. The rap genre, seen as black, was constructed as a threat to the whole society. Binder (1993:765) concludes that the mainstream media depictions of harm in heavy metal and rap music used “images of race and adolescence to tell separate stories of the dangers lurking in the cultural expressions of the two distinct social groups.”
Binder’s analysis addressed the rhetoric used to construct music genres as a threat. Because rhetoric does not deal directly with people, the unobtrusive nature of the analysis makes content analysis a somewhat more accessible design. Content analysis can also be a more economically feasible (i.e., cheaper) design, since it does not require a large research staff and/or any particularly specialized equipment (simply having access to the materials and a printer or photocopier is often the most access and equipment needed). Content analysis, however, has some drawbacks. For example, the design is limited to analyzing materials that have been recorded. Even when materials have been recorded, do these materials measure what you propose to analyze? Are they the appropriate materials to use for an analysis and/or are there enough of them recorded to use for analysis? If the materials are recorded, appropriate, and plentiful, how do you determine which ones to use (do you select all of the materials or do you take only a sample of the materials to analyze)? We look at these issues and others regarding content analysis in Chapter 18.
When evaluating research designs, two issues are important to assess: reliability and validity. Reliability is the extent to which a given measuring instrument produces the same result each time it’s used. Reliability is about consistency. If an independent sample of the same population is given the same survey question, we would expect to get similar results if the survey question is reliable. So in the GSS over the course of two consecutive years, we would expect that we’d have roughly the same percentage of people who feel marijuna should be made legal. If there is a significant discrepancy between the responses for year 1 and year 2, when no significant change has happened in the larger culture, then we would question the reliability of the survey item. In looking at Figure 3.1, we can see the ebb and flow of the percentage of Americans who believe majijuana should be made legal, using GSS data from 1973 to 2010.
Figure 3.1. The percentage of Americans reporting marijuana should/should not be made legal.
As expected, Figure 3.1 illustrates that attitudes change slowly over time, with declining support for legalization in the mid-1980s and then gradual increasing support through 2010. Notice the marked change between the consecutive years 2008 (where 39.8 percent of Americans supported legalizing marijuana) and 2010 (where 47.9 percent of Americans supported legalizing marijuana). Generally speaking, the slow change of opinion over time illustrates the measure to be reliable. Sometimes, however, something specific happens within the cultural context that sparks marked change. For example, due to the attacks on the World Trade Center in September 2001, we might expect to see a significant change between 2000 and 2002 in response to the GSS question, “Are the following threats to the United States greater, about the same, or less today than they were 10 years ago?—Terrorism by foreignors.” Unfortunately, the question was not asked those consecutive years (a missed opportunity) in order for us to test our hypothesis.
Like reliability, validity should also be assessed. When looking at the validity of a measure, we’re interested to know if it’s accurate—in effect, does the measure measure what it’s supposed to measure (or does a variable measure what we said it does)? For example, if you wanted to know the percentage of people who voted in the last election and asked the question, “Do you remember if you voted in the last election?” with the response categories being “yes” or “no,” is that a valid measure of voting behavior? Does the question as asked actually tell us if someone voted? Although the question deals with voting behavior, it doesn’t actually measure whether or not a person voted. The question measures whether or not a person remembers voting.
It is not uncommon to see issues of validity in survey research findings. Sometimes attitude measures get confused with behavior measures. For example, the GSS sometimes asks the question, “There are different opinions as to what it takes to be a good citizen. As far as you are concerned personally, on a scale of 1 to 7, where 1 is “not important at all” and 7 is “very important,” how important is it to help people in America who are worse off than yourself?” Eighty-nine percent of Americans report that “helping people in America who are worse off than yourself” is somewhat important, important, or very important. While having nearly 90 percent of Americans find it important to help others who are worse off is impressive, we cannot assume that Americans are actually helping those who are worse off. What one thinks of helping is an attitude, not a behavior. Unfortunately, attitudes sometimes get generalized to behaviors: “A survey showed that nearly 90 percent of Americans are helping those who are worse off.”
The GSS does ask a question that better measures the behaviors of Americans helping those in need. In 2004 the GSS asked the previous question dealing with attitudes about helping others; a second question asked a behavior question: “During the past 12 months, how often have you done each of the following things? Done volunteer work for a charity.” Thirty-six percent of respondents reported that they had done volunteer work for a charity more than twice in the last 12 months, with 51 percent reporting that they had done no volunteer work for a charity within the last 12 months. While doing volunteer work for a charity may not be the most comprehensive measure of helping those who are worse off, the divergent responses between an attitudinal question versus a behavioral question are noteworthy. Attitudes do not directly measure behavior and are thus invalid measures of behavior and vice versa.
The last spoke in the Wheel of Science is empirical generalization. If “empirical” means observable and “generalization” means summary, the last spoke in the wheel allows us to summarize what we have observed. Moving around the wheel, starting at the top, you have a theory that links concepts (socioeconomic status impacts health). Once the concepts are linked, we create hypotheses telling us how these concepts vary together (the higher a person’s socioeconomic status, the better the person’s health). Based on theory and hypotheses, we choose a research design to collect observations (survey research would be an appropriate design to find indicators of socioeconomic status and health). Once the observations have been collected, we analyze them to see if there is a relationship between our concepts. The empirical generalization summarizes what the data (our observations) tell us—is our hypothesis supported or not supported by the results of the data?
Taking indicators (variables) from the GSS, we test the hypothesis that higher socioeconomic status leads to better health. Using cross-tabular analysis we operationalize socioeconomic status by using a variable that measures total family income and a subjective health variable (self-reported variable on how a person believes his or her health to be) and find the following results in Figure 3.2:
Figure 3.2. The relationship between health and income.
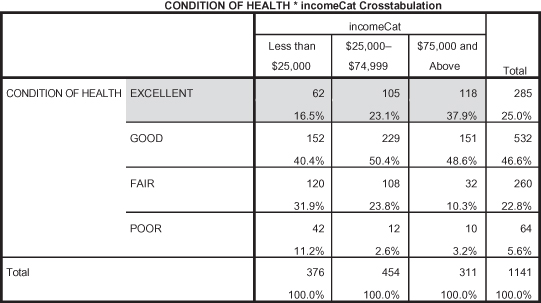
Since our hypothesis focused on people with higher socioeconomic status (the independent variable), we want to begin there. In Figure 3.2 the highest level of income is the category for those who report making $75,000 or more in total family income. We hypothesized that those making more money would report having better health. The category that reflects having the best health is that of “excellent.” We want to begin interpreting what we find based on the intersection of these two categories. If our hypothesis is correct, we expect that there will be a higher percentage of people making $75,000 or more reporting having “excellent” health than people making less than $24,999 and people making $25,000 to $74,999.
When comparing the three categories of the independent variable (less than $24,999, $25,000 to $74,999, and $75,000) across the row for “excellent,” we see that as income level increases, a higher percentage of people report having excellent health. While the pattern of the data indicates that our hypothesis is supported, there is more statistical information we need to definitively describe the relationship between income and health. We’ll go more in depth on those additional statistics as we further explore the Wheel of Science. Suffice it to say, empirical generalizations allow us to summarize what the data tell us. For our hypothesis testing the relationship between income and health, we can clearly say that as income increases, more people report having better levels of health.
Apart from survey research, you can test the relationship between socioeconomic status and health by developing other ways to operationalize variables measuring the concepts. Near our university there is a cemetery. If we sent you into a cemetery to test the relationship between socioeconomic status and health, could you find ways to operationalize the concepts? Indicators of socioeconomic status might be found from the gravestones. Larger or more ornate gravestones may indicate higher socioeconomic status. Having a family mausoleum (a small building for a whole family) or a family grave plot may also be an indicator of higher socioeconomic status. How would we measure health? Most gravestones have the dates for birth and death engraved on them. We could calculate age as a measure of health, making the assumption that the longer a person had lived, the better that person’s health. What might the results of this analysis tell us? How would you generalize what the empirical results show? Based on previous research we would expect having larger and/or more ornate headstones would be linked to having had longer lives.
Much of what we describe when we summarize the results of our analyses is based on correlation, or naturally occurring relationships. When two factors like socioeconomic status and health vary together, we sometimes assume that one (socioeconomic status) is causing changes in the other (health). We can assume that people who have higher status will be healthier. People with higher socioeconomic status tend to have more education regarding healthy practices. They have more access to better foods, health-care providers, and can afford gym memberships. If we see a correlation between socioeconomic status and health, the correlation simply shows that the two concepts are related (that they vary together either in a positive or a negative direction). It is tempting, due to our theoretical musings (those with higher status can afford better health care, etc.) to conclude that higher status causes better health. That conclusion, however, is not what the correlation tells us.
Can you make the opposite argument regarding health and socioeconomic status? In what ways might better health help to increase socioeconomic status? People who are healthier are better able to complete higher levels of education, which might then impact their economic status. People who are healthier are better able to work harder and maintain a good job history, giving them access to better opportunities and higher incomes. People who are healthy live longer and accumulate more wealth. Thus we could argue that the relationship between socioeconomic status and health is the opposite, or a relationship between health and socioeconomic status. We could also argue a third alternative, that the relationship is reflexive—both variables cause changes in the other.
Correlation research allows us to predict relationships between variables; if we know the state of one variable, we can generalize what is happening with the other variable. Correlation does not tell us if changing one variable will cause a change in the other variable. It could be that some other factor links these concepts (e.g., family of origin social status might impact both a person’s status and/or health). In his famous book How to Lie with Statistics, Darrell Huff (1982) discusses the problems encountered with a “post hoc fallacy.” Huff cites a study that found cigarette smokers had lower grades than nonsmokers. While Huff (1982:88) describes the study as being “properly” done, he also notes that “an unwarranted assumption is being made that since smoking and low grades go together, smoking causes low grades.” Like the relationship between socioeconomic status and health, couldn’t the smoking/low grades relationship go the other way? Beware of the post hoc fallacy—determining causation after the fact. Just because two variables are correlated, it does not follow that one causes the other. In fact, it could be that extroverts are more likely to smoke and less likely to get good grades (Huff 1982). The point is we simply do not know that cigarette smoking causes lower grades (or vice versa). When making empirical generalizations we need to keep in mind that finding a correlation between variables does not equate to finding causation between them. We will look more closely at the differences between correlation and causation in later chapters, to make these distinctions more clear.
Social scientists talk about several different types of research including “pure” research, applied research, evaluation research, and action research. While the boundaries between these types of research are somewhat blurred, the reasons why research is undertaken and the purposes for which it is used can be quite different.
Pure research, also known as basic research, is a designation identifying research performed solely to “advance knowledge” or to develop theoretical understanding. The object of pure research is not to respond to a specific research problem that requires an immediate answer. Examples in social science might be “Does religious competition help or hurt church membership?” or “How does poverty affect crime?” An additional example would be a study conducted by McKinney (2001; see also McKinney and Finke 2002) to determine how social network ties impacted clergy connection and involvement with denominations. While most clergy reported that their social networks did not impact their beliefs or involvement with the church, the results of the study showed exactly the opposite; the clergy most actively involved in denominational movements had close network ties (friends) also involved in the movements.
Since pure research does not directly address any societal need, most of this research occurs in universities or is funded through large foundations. It is not immediate in nature or focused on sales, so it is not likely to be funded commercially. The very nature of science is based on simply discovering more about the world. Sometimes, however, people see pure research as simply “duh” science at best or wasteful of resources at worst. Pure research allows scientists to address an unlimited array of research questions. Much of the knowledge gained by pure research serves as building blocks for future research that is more applied.
Applied research focuses on the actual real-world problems in a field of study. Typically, practitioners working in social science fields identify problems that need to be solved and look to researchers for assistance in ascertaining the extent of the problem and then applying solutions to it. An example might be, “Is summer learning affected by family income level?” Another example might be a study Abbott conducted several years ago in a subsidized housing project to determine the effects of community policing on drug activity. City agency leaders introduced a different model of policing than currently existed in a low-income urban housing area. Whereas previously police officers conducted typical “beat” patrols, community police officers walked among the houses, got to know residents, and relied on residents to assist police in reporting crime. In this way project leaders “experimented” by introducing community policing to see if it made an impact on incidents of drug activity. Community policing was thus being compared to the typical police patrol procedures. These newer community policing procedures were deemed successful when program leaders observed decreasing levels of crime in the low-income housing area, especially at rates compared to the city as a whole.
Some researchers and policymakers make a distinction among various types of applied research. Evaluation research is one specific type of applied research to determine whether a specific intervention was successful according to a set of criteria. This research is often found in corporate and institutional settings in which there is a concern over the impact of a specific program that has been introduced. When school districts introduce measures to lower class sizes or fund technology, for example, they are interested in what difference the program makes on some specific outcome (like student achievement) in their districts. Because of the specific nature of this type of research, it is known by many names. Prominent among these are program evaluation, effectiveness research, impact analysis, and even cost-benefit analysis.
Action research is applied research aimed at providing insights and solutions in cascading fashion. The attempt is not so much to make a pronouncement about whether a program objective had been met (as in evaluation research), but to apply research findings in order to further refine solutions for change. When a corporation, institution, or other agency employs action research, it is for the purpose of understanding a current problem, suggesting potential solutions, and then using the findings to suggest additional avenues of change. Typically, action research involves the participation of a researcher who creates findings for a research problem, works with the sponsoring group to implement new approaches, gathers further findings to develop more specific understanding, and continues to develop change processes.
An example of action research may be found most readily in the consulting world. If hospital administrators are concerned about staffing patterns in their critical care units, for example, they might hire a researcher-consultant to evaluate their current practices. The researcher might then work with a hospital committee to refine and implement a resulting staffing strategy, which will yield further information that can lead to additional change strategies.
We have now covered the four spokes of the Wheel of Science. We’ve described how theories link concepts and once linked, give direction to research by helping us create hypotheses—statements of how concepts are related. Once we have hypotheses to test, we select a particular research design to test empirically whether the hypotheses are supported or not. These research designs give us structured ways of observing the world in order for us to empirically generalize what our observations tell us. While these processes take us through the Wheel of Science, there is still one area that needs to be addressed, the ethics of social research. Social research uses people as the basis for our observations. When researching people, there are several guidelines in place to ensure the safety of human participants. We turn, in Chapter 4, to the ethical concerns related to studying human subjects.
Note
1 Joanne Viviano, “Survey Calls Ohio U Top Party School,” Seattle Times, August 1, 2011, available at http://seattletimes.nwsource.com/html/nationworld/2015790839_apuspartyschools.html.