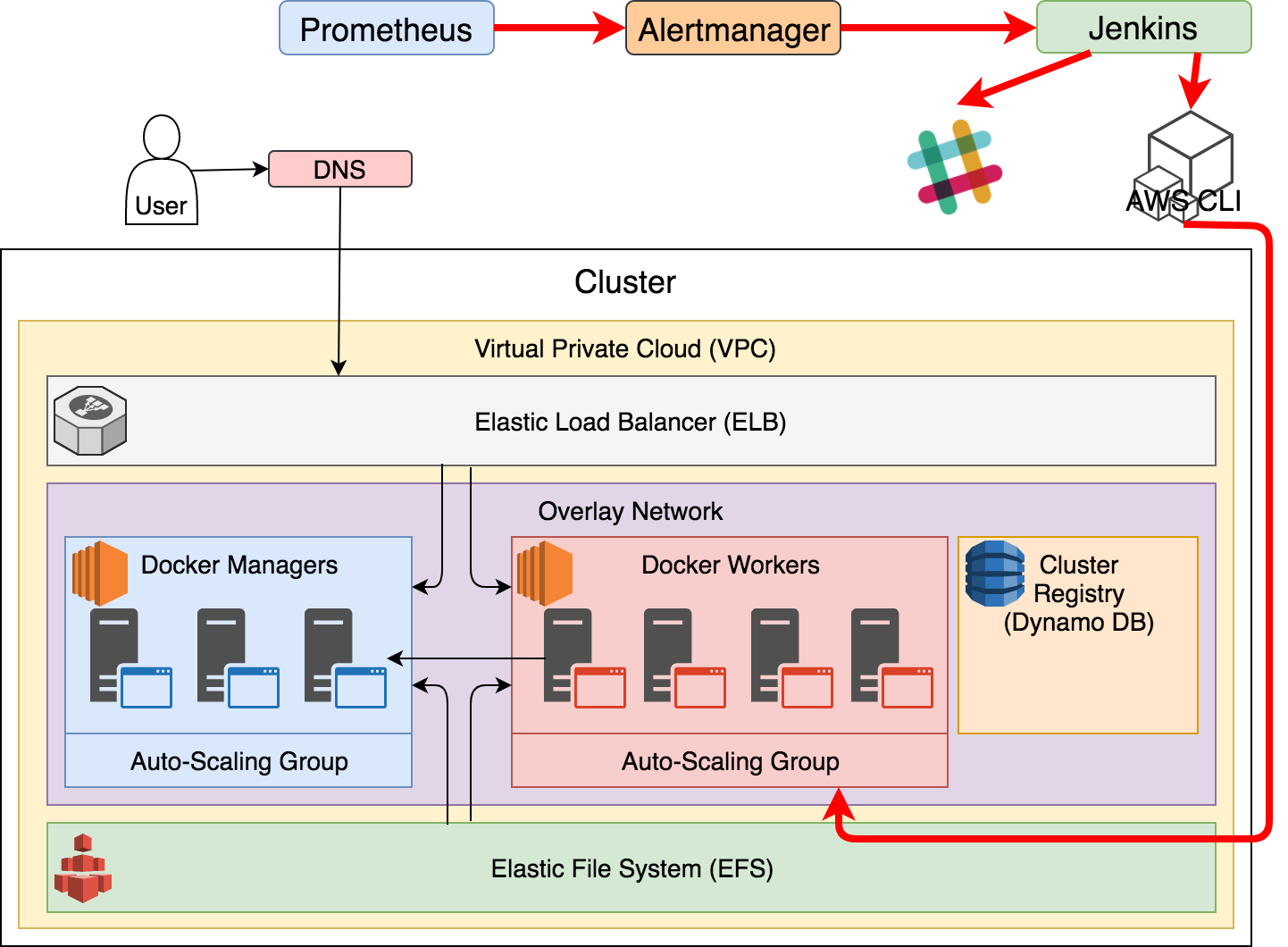
Self-adaptation applied to infrastructure is conceptually the same as the one used for services. We need to collect metrics and store them somewhere (Prometheus) and we need to define alerts and have a system that evaluates them against metrics (Prometheus). When alerts reach a threshold and a specified time passed, they need to be filtered and, depending on the problem, transformed into notifications that will be sent to other services (Alertmanager). We used Jenkins as a receptor of those notifications. If the problem can be solved by the system, pre-defined actions would be executed. Since our examples use AWS, Jenkins would run tasks through AWS CLI. When, on the other hand, alerts result in a new problem that requires a creative solution, the final receptor of the notification is a human (in our case through Slack).