
Mark Hale
I will use the phrase ‘the Comparative Method’ (or ‘the Method’) in this chapter to refer to a fairly well-defined process of scientific hypothesis formation which leads to the reconstruction of ancestral linguistic objects, given linguistic data from a set of (sub)grouped, related ‘daughter’ languages. Like all serious scientific pursuits, the implementation of the procedure requires the careful consideration of a variety of types of evidence (in this case, directionality limitations on change events, triviality indices of change events, probability of borrowing, chance, and iconic similarities, etc.). The Method allows for (indeed, strictly speaking demands) the reconstruction of ‘intermediate’ proto-language forms (i.e., those of the ancestor of any subgroup) as well as the (ultimate) proto-language forms themselves. Since the Method produces proto-forms (including the ‘intermediate’ proto-forms of subgroups), and daughter forms are its input, it provides initial, intermediate and termination data points for (some of) the forms of the languages under investigation. It is therefore possible on the basis of the reconstructed material to construct a historical grammar of the languages, indeed, the decision about what to reconstruct is simultaneously an implicit claim as to the events which comprise that historical grammar.
Given this narrow definition of the Method, the establishment of language ‘families’ and of subgroups within those families is not, properly speaking, an aspect of the Method itself. The Method does however provide the most important tool for the assessment of claimed ‘language families’: a language family is established when it can be shown that via a set of acceptable, systematic and regular change events, a set of languages (with an imposed subgrouping) can be derived from a reconstructed ancestor. Technically, the optimal subgrouping of that set of languages is the one which provides the most plausible and simplest account of the historical grammar of the languages within the family. All possible arrangements could be tested, to see what reconstructions they would trigger (and thus what histories they would entail) – however, in practice, this is never done, nor does it seem to be necessary. Hoenigswald (1960: 144–160) presents very lucid argumentation which reveals how under certain (quite common) conditions one may use ‘shortcuts’ to avoid exhaustive comparison.
The ‘genetic hypothesis’ (a hypothesis of relatedness) is a ‘last resort’ (i.e., costly) hypothesis: it is to be invoked only when the data patterns in such a manner that less costly hypotheses (‘borrowing’, ‘chance’, and ‘iconicity’) can be safely precluded as providing an appropriate explanation for the observed similarities. Languages displaying similarities to a member of a given language family – similarities which can be most productively accounted for by the costly assumption of relatedness – are themselves members of that family. Languages which do not, are not. The Comparative Method is thus, like scientific hypothesis formation generally, a solution to an observed problem: why is there greater than chance similarity in the observed non-iconic vocabulary in a set of languages unlikely to display such similarities by reason of contact (‘borrowing’)? It follows that if, in a particular case, such similarity is not observed, or if convergence cannot be excluded, there is no ‘work’ for the Comparative Method to do for us and no need to posit a ‘language family’.1
Many problematic issues which appear in the literature on the Comparative Method appear to come about when scholars attempt to get the Comparative Method to answer questions and resolve problems in domains regarding which it has nothing directly to say (though of course it may provide data which can form part of a larger chain of reasoning). The Method tells us nothing directly about settlement history, for example: for this we need either actual historical or archaeological evidence, or a sufficiently restrictive theory of human dispersal in a particular area that the hypothesis space regarding possible settlement history is highly constrained. For example, with the Comparative Method we can establish that Malagasy and Indonesian are quite closely related (in spite of the rather large geographical discontinuity involved); but the Method simply cannot tell us from where each location was settled, nor, of course, when. Extra-linguistic evidence and reasoning must be brought to bear. The same holds for many other generally speaking ‘historical’ questions (as opposed to questions of linguistic history, narrowly construed), such as population shifts, the relationship between language transmission and gene flow, and the time-depth of separation.2 It is not that the Comparative Method cannot inform our discussion of such matters, it is just that it cannot resolve such matters, since it says nothing directly about them. This is not, contrary to a sometimes voiced opinion, a shortcoming of the Method, any more than being very poor at sawing through a board is a shortcoming of a hammer. Often discussion of the Method in terms of such issues is tied to explicit claims that the Comparative Method needs to bring ‘speakers’ back into the picture (or sometimes, more emphatically I guess, ‘real speakers’). This touches upon issues concerning the Method as traditionally practiced (or, to be precise, as traditional practitioners usually describe their practice), which we shall address in detail below.
Many of the issues which I think do represent serious matters arising from attempts to use the Comparative Method can best be seen against the backdrop of a traditional table, often used to exemplify the Method. In Table 5.1, I present tentative data from a set of languages of Vanuatu, which I will call for convenience the ‘Espiritu Santo’ languages.3 Insufficient data is presented to allow the reader to justify the proposed reconstructions on his or her own – given the purposes for which the data is being cited, this does not seem particularly problematic.
Table 5.1 Comparative Espiritu Santo (phonemic, PES = Proto-Espiritu Santo)
There are some easily established ‘sound changes’ which appear to be reflected in the table.4 In Tambotalo, in particular, we appear to be seeing the effects of the ‘dentalisation of labials’ (for the phonetic motiviation behind such developments, see Ohala 1978). PES *m shows up as Tambotalo /n/ before non-round vowels, PES *ß as /ö/ in this same context. Interestingly, Tolomako appears to share with Tambotalo the former innovation, but not the latter, preserving the voiced labial fricative as such, even in contexts in which Tambotalo has ‘dentalised’ it. We will turn momentarily to the implications of these developments for our understanding of the structure of the family, but first let us consider the contents of such tables in greater detail, for it turns out that virtually every aspect of the table gives rise to conceptual challenges.
In our investigation of the hidden complexities of this seemingly simple table, let us begin at the top row, which presents a set of ‘language’ names. What do these column labels represent? If they represent ‘languages’ in the ‘socio-political’ sense, then, for example, the Tangoa column represents the speech of some 800 people. But what if there are, for example, grammars in the head of each and every Tangoa speaker, and each of these grammars differ in some way(s), either in phonology, or morphology, or syntax. Should Tangoa get 800 columns?
Imagine that, like many (but not all) linguists, you believe that grammars are (sub) properties of individual minds/brains. The columns should represent people, then, but not even people (since we are talking about ‘subproperties’!), because of course people may control more than one linguistic system. Multiple columns per person may be required. This is of course merely one reflection of the well-known ‘language’/‘dialect’ problem – if these terms cannot be coherently defined, and their relationship to the data sets used in the Comparative Method cannot be clarified, the entire Method falls apart. Any formal procedure that does not provide clear guidance as to what data it should be applied to is in trouble.
The, in my view (for an extended discussion, see Hale 2008), unavoidable consequence of attempting to resolve this problem is that the columns in a Comparative Method table such as the one presented above should represent observed grammars, in the standard modern theoretical sense (computational systems generating linguistic output). After all, the only place in the world that we find actual phonemes, morphemes, and other reconstructable linguistic entities is in such objects. This strikes me as a positive conclusion, consistent with the established practice, if not the rhetoric, of most linguists doing comparative reconstruction. After all, the history of each individual grammar observed in the world has equal claim to diachronic explanation; the Comparative Method is an important potential tool in developing the relevant historical understanding. ‘Standard languages’ (often, for example in the Oceanic context, the dialect of the village which happens to have had a missionary station established in it) have no special linguistic status. So, while of course we do not usually have data on every grammar of every language, the data columns represent some selected grammars which will be used in the reconstruction task. These are the real linguistic objects (one might call them ‘languages’) of the Comparative Method. This point will be relevant again in the discussion below.
What about the ‘Proto-Espiritu Santo’ column – what kind of entity does the data in that column represent? There have been a variety of answers (many implicit, rather than explicitly stated) to this question in the literature on the Comparative Method, and implied by the work of its practitioners. In an important methodological paper, Lichtenberk (1994: 1–2) distinguishes between an ‘instrumentalist’ and a ‘realist’ view of the nature of proto-languages:
Do we assume that at some time in the past there really was a language that had the properties that we have reconstructed (the realist view), or is such an assumption irrelevant to our concerns (the formalist view)? […] On the realist view, reconstructed proto-languages are viewed not as formal devices but as real entities, as real as the languages around us.
Lichtenberk’s paper is an extended argument in favour of the ‘realist’ view, the orientation which is certainly dominant in contemporary reconstruction methodology. The implication of that view which he is most interested in exploring in that paper is the following: if the proto-language represents our best hypothesis about the properties of a ‘real language’, then shouldn’t our reconstructed proto-languages have dialects and show the type of variability and diversity that we find when we examine the languages around us?
Traditionally, at least in the approaches I was trained in, the answer to this question was a simple, if somewhat surprising, ‘no’. The justification for that answer was pretty straightforward: given two ‘dialects’ of some language X, the Comparative Method provides a mechanism for the reconstruction of the ancestor of those two dialects. This ancestor is the proto-language. The two ‘dialects’ are the daughters of that proto-language. Since this can be done for any dialects of any language (including alleged dialects of any earlier ‘reconstructed’ stage of a set of related languages), there is no reason to treat any dialectally-divided entity as the proto-language – the proto-language would always be, by definition, the reconstructed ancestor of that dialectally-divided entity.
We seem, then, to be left with two pretty compelling arguments: if proto-languages are languages like those around us, then they should have dialects (as the ones around us do). On the other hand, the Comparative Method itself (the only established procedure for the creation of the hypothesis we call a ‘proto-language’) would need some additional mechanism that essentially said: stop applying at this point, even though there are still observed, recoverable differences between the ‘dialects’ you have reconstructed for which you could reconstruct a ‘common ancestor’. At present, no such mechanism exists.
There are two ways this situation could resolve itself, even within the almost universally accepted ‘realist’ conception of things. We could amend the Comparative Method so that it would generate ‘proto-language dialect variation’, or we can find some justification for proto-languages seeming to differ so radically from ‘observed languages’. Lichtenberk attempts the former, but I do not see that his efforts can be judged a success. I will attempt to sketch out his suggestion here.5
Lichtenberk is analysing a set of complex data from the Cristobal-Malaitan languages (whose ancestor, Proto-Cristobal-Malaitan, he calls PCM for short). The data are focused on a development which Lichtenberk calls y-prothesis, which interacts in a complex manner with y-loss in these languages.6 After an admirably careful assessment of this complex data, Lichtenberk adopts as the most likely scenario for the observed developments the following: y-prothesis takes place normally within PCM, and after that, the process of y-loss is initiated gradually, diffusing “areally, from the area where it had originated” (Lichtenberk 1994: 11).7 The key part of his argument is that:
y-loss was incomplete; it ceased to operate before affecting [.] the whole of the PCM-speaking area, thus leaving a residue. The present-day instances of the zero reflex are the result of y-loss; the full reflexes continue the residue.
(Lichtenberk 1994: 11)
Note that under this conception of things Lichtenberk does reconstruct a ‘homogenous’ PCM: before the start of the y-loss event, PCM showed y-prothesis uniformly (as near as one can tell from Lichtenberk’s discussion, and from the data). So the Method, even under Lichtenberk’s conception of things, continues to reconstruct proto-languages which lack dialects, in spite of his ‘realist’ orientation. The crucial difference between Lichtenberk’s position and the traditional approach is that after y-loss kicks in, and we get differentiation into those areas which show it and those which do not:
[t]he incompleteness of y-loss resulted in regional variation with respect to the presence and absence of *y, but this variation did not amount to dialect differentiation. There were no isoglosses dividing PCM into dialects on the basis of the fate of *y […] However, even though the result of the incomplete loss of y was not dialectal differentiation, there was areal heterogeneity. Different areas where PCM was spoken had been affected to various degrees by loss of y.
(Lichtenberk 1994: 17)
The alleged heterogeneity introduced into PCM by incomplete y-loss involved, crucially, areal differences without ‘dialect differentiation’. It is hard to see any justification for this fine distinction – areal differences are, after all, differences, no matter how one labels them – except, of course, for one: if we are looking at dialect differentiation, then the proto-language has ‘broken up’ (to use traditional terminology) and we are looking at a set of daughter languages, early in their post-break-up history. But this would mean that Lichtenberk’s scenario involves a homogeneous proto-language (PCM before y-loss), created by the Method, and a set of early daughter languages (after y-loss), areally differentiated based on a non-universally shared innovation: precisely the scenario envisioned by the traditional application of the Method.8 Since he wants to argue for ‘proto-language’ dialects as a key component of the ‘realist’ orientation, he does not want that particular result, so he relabels the results of this change as ‘areal heterogeneity’ but not ‘dialectal differentation’.
We can resolve these matters in a much more straightforward manner, I believe. As we saw with the labels across the rest of the top of the table of data above, the ‘language names’ we are used to seeing there actually represent ‘grammars’. Since it is that type of object which is being compared to create the proto-language, it would not be particularly surprising if the Method generated that same type of object: i.e., the comparison of grammar-related data allows us to reconstruct a grammar. Thus, like all the other labels at the top of the table, the Proto-Espiritu Santo label represents a grammar: presumably a real linguistic object found in the mind/brain of a real speaker (thus fully consistent with the ‘realist’ and speaker-oriented conception of the enterprise). The reason it cannot show ‘areal heterogeneity’ is now pretty simple: in linguistic space, speakers are points – it makes no sense to talk about a single grammar as being areally differentiated. This saves us from the contortions of Lichtenberk’s attempt to reconstruct heterogeneity (which don’t really succeed in avoiding reconstructed homogeneity anyway), but allows us to maintain all aspects of his actual analysis of the Cristobal-Malaitan data, reconceptualised in terms of individual grammars and their transmission history. The story is still not simple: language contact data notoriously gives rise to some of the most complex issues surrounding any individual application of the Comparative Method, but it is hard to imagine even recognising, let alone moving toward the resolution of, such issues without the homogeneity assumptions of the Comparative Method as a tool.
Let us move from the labels at the top of the table above to the data contained within the table. In the post-1950s world it is traditional to list the daughter language forms in their taxonomic phonemic form. Indeed, in modern discussions of the Method, argumentation is explicitly offered as to why this is a good idea, or perhaps even necessary. In a book on the Comparative Method, for example, Fox (1995: 38) writes the following:
[…] consider what is meant by ‘sound change’. In purely phonetic terms this can only mean that a particular articulatory gesture is replaced by another, whether in all cases where it occurs in the pronunciation of the words of the language, or just under certain conditions. From the point of view of structuralist phonology, however, this change must be evaluated differently according to whether or not it results in a change in the phonemic status of the sounds involved. If it merely affects how the allophones of a phoneme are articulated, then the change is, phonologically speaking, superficial, and indeed irrelevant; only if it affects the system of phonemes itself, or the grouping of sounds into phonemes, can it be considered a genuinely linguistic change.
He goes on to explicitly discuss the significance of this observation regarding change for the Comparative Method:
What are the implications of this for the Comparative Method and for the reconstruction of protolanguages? First, it means that since phonemes, rather than sounds, are regarded as the basic units of pronunciation, our methods of reconstruction must be geared towards determining the phonemes of the protolanguage rather than its sounds. In fact, determination of the latter is regarded as rather unimportant […]
(Fox 1995: 42)
There are two serious problems with the claims being made by Fox: the first a practical one, the second a theoretical one. Let us turn to the practical issue first.
Allophonic data may provide critical evidence as to the proper characterisation both of the proto-forms and of the phonological history of the individual daughter languages. It may also affect subgrouping directly, and since the subgrouping will normally affect the shape of reconstructed linguistic objects, it is clearly important to the enterprise (contrary to the claim of Fox cited above). This can be seen from the Espiritu Santo data presented above. Since the dentalisation of labials is a fairly unusual sound change, we would not want to assume that the dentalisation of *m took place independently in Tambotalo and Tolomako. Instead, the Method requires of us in such a situation that we establish a subgrouping of the relevant languages, which might look like this:9

The dentalisation of *m would thus have taken place in ‘Proto-Espiritu Santo B’ (i.e., during the shared history of Tolomako and Tambotalo), thus only once, easing the anxiety caused by positing parallel independent development of relatively unexpected developments. After Tolomako and Tambotalo split up, within the history of Tambotalo, the dentalisation of *ß also occurred.
It is important to understand that this subgrouping is being established on the basis of this relatively unusual sound change, but it has broad implications (if supported by remaining evidence). The subgrouping tree allows properties shared by the daughters of a subgroup to be attributed to the ancestor of that subtree, rather than to the proto-language itself. In essence, the languages of the ‘Proto-Espiritu Santo A’ each provide evidence only for ‘Proto-Espiritu Santo A’, and those of ‘Proto-Espiritu Santo B’ only for that immediate proto-language. Proto-Espiritu Santo itself is then reconstructed on the basis of its two daughters (‘PES-A’ and ‘PES-B’) only. The subgrouping, then, limits the contribution of each attested daughter in areas of phonology, morphology, syntax, etc. by only allowing some of those features (those reconstructed for the relevant intermediate proto-language) to play a role in the reconstruction of the ultimate proto-language. If we get the subgrouping wrong, we will, in all but the very most trivial cases, get the reconstruction of the proto-language wrong as well.
While the relative rarity of the dentalisation of labials may give rise to quite a bit of confidence regarding the subgrouping established on the basis of that property, it turns out that the ‘phonemic’ vs. ‘allophonic’ evidence issue can be shown to be highly relevant in an instance such as this. Below is the same table of data for Espiritu Santo, with some available allophonic information introduced into the tree. (The symbols [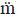 ] and [
] and [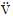 ] represent so-called ‘linguo-labials’ or ‘apico-labials’, where the apex of the tongue is used to make a closure (in the [] case) or fricative constriction (in the [] case), rather than the lower lip.)
] represent so-called ‘linguo-labials’ or ‘apico-labials’, where the apex of the tongue is used to make a closure (in the [] case) or fricative constriction (in the [] case), rather than the lower lip.)
Table 5.2 Comparative Espiritu Santo (phonetic, PES = Proto-Espiritu Santo)

Notice that at the phonetic level, Tangoa shows the very unusual development of apicolabials in precisely the same environments in which Tambotalo shows dentalisation of labials. If you articulate [rn] and [v ] for yourself, I think it will be quite clear how much like [n] and [ö] these segments are. It is almost inconceivable that these developments are unrelated to the dentalisation which we see in Tambotalo and, in the case of *m, in Tolomako.
This information about the allophonic level in Tangoa necessitates a complete change in our conception of the Proto-Espiritu Santo family tree. If, as is universally accepted among those working on the history of the languages, the apico-labials represent an intermediate stage between [m] and [n], on the one hand, and [ß] and [ö] on the other, then Tangoa belongs in what I called ‘PES-B’, not in ‘PES-A’ as the phonemic data absolutely required. In addition, our understanding of the history of ‘PES-B’ is much richer than it was in the phonemic-based tree. Here is the new tree:

In the new version of the phonological history of *m and *ß in light of the new tree we see that in the history of PES-B we cannot dentalise *m (because Tangoa does not show such dentalisation: it merely shows what we have called ‘apicalisation’). So, even though Tambotalo and Tolomako both show the dentalisation development, and we argued above that such a development was too unusual to safely assume parallel independent developments, we are now almost forced to assume that some kind of parallel independent development is involved.10 Of course, we can assume that ‘apicalisation’ took place for *m in the shared history of the daughters of PES-B, and it seems clear that the development from apico-labials to dentals is much more trivial than that of labials to dentals – so this parallel independent development no longer worries us as it did in the ‘phonemic tree’ discussion. On the way from PES-B to Proto-Tambotalo-Tangoa, apicalisation of *ß also must have taken place. Finally, as noted, in both Tambotalo and Tolomako, i.e., independently, we find the dentalisation of apico-labials (in pre-Tolomako the only apico-labial was *m, of course, so it was the only segment that ‘dentalised’).
The consideration of allophonic evidence, then, far from being ‘unimportant’ or, indeed, ‘not linguistic’, is absolutely critical in establishing the proper subgrouping tree for a language family. Crucially, this should not surprise us, since it is clear a priori that this needs must be the case: the rules of the grammar which give rise to allophonic properties of segments must, like all aspects of the grammar, have a history. The development of these rules, like the development of all properties of the grammars being compared when applying the Comparative Method, must be subjected to an assessment as to how trivial an innovation their coming into being represents, and thus how likely it is they can have arisen independently. To exclude them from the history of languages under discussion is to act as if they do not have a history, as if they arise ex nihilo, and fall outside the scope of scientific investigation. Nothing could be farther from the truth.
As I noted above, there is also a ‘theoretical’ reason for not working from ‘taxonomic phonemic’ data as Fox (and many others) recommend. The ‘taxonomic phonemic’ level is not, for the vast majority of us, a real linguistic entity. Using such forms amounts to saying ‘imagine you were an American structuralist working in the pre-generative era, what would you have come up with for a phonemicisation of this language? Use those forms’. Surely if we are going to use phonemes (i.e., the elements of long-term mental storage), we should use what we actually, given current theory, believe are the phonemes. If using the actual phonemes seems to give undesirable results (and I believe it does, as I believe using ‘taxonomic phonemes’ does), that probably indicates that phonemes are the wrong level of representation to use as inputs to the Comparative Method.
Assuming the reader is prepared to accept, for the sake of argument at least, that the data in the table should be phonetic (i.e., output of the grammar) representations, with all of their allophonic information,11 we might ask now whether we haven’t perhaps painted ourselves into a somewhat odd corner. We have argued that the columns of the Comparative Method table represent grammars – we may include, under a sufficiently broad definition, the lexicon as well, of course. But the lexicon contains, by definition, phonemic representations, the grammar contains a set of ordered rules or constraints which allow the computation of phonetic forms from these phonemic representations, but nowhere in the speaker’s long-term stored linguistic system do we find, under standard assumptions, allophonic forms – these are created on-the-fly as needed. So, if the columns represent long-term stored linguistic ‘knowledge’ (i.e., ‘grammars’), why does the data in the columns contain short-term, temporary ‘output’ representations?
The reason for this apparent incongruence is relatively straightforward: although the stored lexical items (in phonemic form, of course) and the phonological computation system (let’s call it the ‘rule system’, with an awareness that traditional generative rules might not be the best characterisation of the device) represent, in some sense, the ‘content’ of the grammar which the column of data represents, it is not clear that that content plays a direct role in the change events which characterise the historical phonology of the grammars being compared. If we locate a significant portion of ‘phonological change’ in the acquisition process – a widespread if not universal contemporary conception of the phenomenon – then we must recognise that the acquirer has no access to the speaker’s stored lexical forms or phonological rule system.12 It is hard to imagine how these abstract properties could affect the acquisition of forms without having a reflex in the phonetic output forms themselves.
A concrete example may be helpful here: under standard analyses, a given idiolect of German may have two forms [rat], one meaning ‘advice’, the other ‘wheel’. The former of these is the reflex of /rat/, the latter of /rad/, which shows [t] in the output because of the property of that idiolect’s phonology which devoices obstruents in codas, which we can call for convenience ‘final devoicing’. The two forms thus differ in their phonemic form, and differ in whether they have been modified in their form by the process of final devoicing. In the normal course of acquisition, a child may be exposed to these two forms, but in order to converge on the analysis I have just sketched, it will not be sufficient to be exposed only to the form [rat] of each lexical item. Since the additional information the acquirer is being exposed to cannot be the speaker’s phonemic form (to which an acquirer has no access), nor the final devoicing process (ditto), it follows that the only evidence which can lead to the single input form [rat] receiving two distinct phonemic analyses (/rat/ for ‘advice’ and /rad/ for ‘wheel’) is exposure to morphologically related forms (e.g., plurals in which the final obstruent is no longer final, and thus not subject to final devoicing), coupled with the acquisition process of ‘lexicon optimisation’ whereby morphologically related forms are reduced to a single phonemic representation when possible or necessary. Therefore, the phonemic form and ‘final devoicing’ process play a role in the transmission of forms to the acquirer only in as much as they make themselves felt on the ‘phonetic’ target forms the acquirer actually gets exposed to the realisation of. They are otherwise diachronically inert.
To wrap up our discussion of phonological reconstruction, the classical and standard application of the Comparative Method, I hope to have shown that the Method as traditionally described and often explicitly recommended is not typically consistent with the actual practice of reconstruction by those engaged in the process (as opposed to being engaged in the meta-discussion of how the process should be undertaken). Phonetic data has always been carefully brought to bear on aspects of the historical phonology of the languages being compared – indeed, in the case of both Indo-European and Austronesian (the two cases best known to me), the reconstruction was largely complete before the concept of the phoneme arose in linguistics, and has not been affected in any serious way by the rise of that concept. Although historical linguists talk as if ‘languages’ were what they work on, in practice, whenever identifiable dialects arise, they treat those dialects as having their own history, and write analyses of the historical grammar of those identifiable varieties. In classical applications of the Comparative Method, no proto-language dialects are reconstructed. I hope to have shown that these practices of traditional historical linguists are also the optimal theoretically-grounded approaches to these issues.
The procedures and issues which arise regarding reconstruction above the phonological level – the reconstruction of syntax, for example – fall outside the narrow scope of the present article, but the parallelism (or lack thereof) between the issues we have been considering in the phonological domain and those at higher order levels of the grammar are worth some brief comments.13 In particular, I would like to address two issues commonly overlooked in the rather extensive literature on syntactic reconstruction. The first concerns whether syntactic reconstruction is possible at all, the second the related issue of whether or not there is such a thing as ‘regular syntactic change’.
There are a variety of arguments in support of the position that syntactic reconstruction is not possible, a position famously advocated by Lightfoot in a variety of publications (e.g., Lightfoot 2002, though his position on the matter appears already in Lightfoot 1979). One of the most widely discussed is the fact that it is not at all clear that the notion of ‘syntactic cognancy’ (to parallel the notion of ‘cognate’ used in phonological reconstruction) is coherent. In spite of the popularity of this argument, it is I think quite clear that much of the reconstruction of Indo-European (for example) morphology presupposes what we must consider ‘syntactic cognancy’ across the archaic daughter languages. When we reconstruct *deywom as the accusative singular masculine of a thematic noun *deywo- ‘he who belongs to the sky; god’ we have, of course, reconstructed a phonological object and (aspects of) its semantics (e.g., that it is singular and that it means ‘god’). We have also reconstructed at least some purely morphological features of that object – e.g., that it shows thematic, as opposed to athematic, inflection and that the marker for the accusative singular in that class is *m. But, crucially, we have reconstructed at least some syntactic properties of the word form as well: for example, that it is masculine, accusative and a noun. The reconstruction of this form as ‘masculine’ directly entails for the proto-language that this lexeme entered into agreement relations with modifiers and/or antecedents – this is the sole reason to posit grammatical gender. In fact, Indo-Europeanists generally reconstruct quite specific aspects of agreement for the proto-language (in gender, number and case in some contexts, in others, only of number, for example); this is of course ‘syntactic’ reconstruction.
‘Accusative’ case-marking carries no necessary semantic interpretation, but does make certain demands on the kinds of syntactic distribution the element must have shown in the proto-language, much as its status as a noun does. We can see that this reconstruction requires first establishing ‘syntactic cognancy’ on the distribution of the accusative in the archaic daughters if we imagine an alternative data set in which a single form of the shape *deywom is found reflected in the various archaic daughters (i.e., those which maintain the contrasts between many of the PIE cases), but that in Language A the form is used only as the subject of the clause, in Language B only as the indirect object (but not as the subject), and in Language C only to express the locative function (and not in either of the functions seen in Languages A and B). We would not, given that data, reconstruct a form *deywom for the proto-language at all, unless we could provide a reasonable account of how that form came to have the diverse set of functions seen in the various daughters.
But that reasonable account would be, simply, establishing a plausible set of systematic changes which allow us to see the ‘cognancy’ of the structures into which the form *deywom enters in the daughters. In the actual case, establishing such cognancy is precisely what we have done when we engaged in the reconstruction of the syntactic features (masculine gender, accusative case, status as noun) of *deywom – as it turned out, this was not terribly difficult, as long as we accept that the syntactic functions we see *deywom fulfilling in the various daughters (e.g., complement of a set of transitive verbs) are ‘cognate’. In a simple case such as this, most diachronic syntax scholars would accept reconstruction (see Lightfoot 2002 on the special status of ‘identical structures’ in reconstruction). Crucially, in taking that step, they are acknowledging that it is possible at least in this restricted case to claim that structural relationships (‘complement of a transitive verb’) is a kind of cognacy – but they would have us believe that in any deviation from pure identity, establishment of cognancy is impossible. But this is clearly too restrictive a conception of the matter: after all, we do not find perfect identity between the set of verb forms which count as ‘transitive’ across all the Indo-European languages, and thus the set of predicates which co-occur with our reconstructed accusative case is not an identity relation, yet we are prepared to recognise that the accusative case has expanded its function (replacing lexically-specified case selection in individual predicates in individual daughters) without destroying our ability to reconstruct the accusative at all. And, since reconstruction requires cognancy relations of an appropriate type, our ability to reconstruct an accusative case (a ‘purely syntactic’ case, at least in its primary function) entails that such cognancy can be established. It remains a desideratum for someone to articulate just what the procedures are for establishing such cognacy – an examination of the highly successful reconstruction of syntactically-sensitive morphology in Indo-European and, for example, Oceanic would doubtless yield the clear outlines of an appropriate methodology.
The second issue I would like to address concerns the regularity of syntactic change. I have argued (Hale 1998) that we might want to distinguish between the ‘sporadic change’ of syntactically-relevant lexical features on a given proto-language lexical item and the ‘more global’ surface changes which appear to be triggered by “a change in values of formal features on functional heads” (1998: 16). We can distinguish between the two phenomena fairly straightforwardly: the former gives rise to a new subcategorisation frame for a given lexeme,14 the latter to a more global change in the syntactic typology of the language. The following examples, cited in Hale (1998), makes the relevance of the latter category for the discussion of the ‘regularity’ of syntactic change clear (they are all from Archaic Latin):
| (1) | a | pater | huc | me | misit | ad | uos | oratum | meus |
| father.NOM | here | me.ACC | sent | to | you | to.speak | my.NOM | ||
| ‘my father sent me here to speak to you’ | |||||||||
(Plautus, Amphitruo 20)
| b | … | ego | … | qui | Iouis | sum | filius |
| … | I.NOM | … | who.NOM | Juppiter.GEN | am | son.NOM | |
| ‘I, who am the son of Juppiter,’ | |||||||
(Plautus, Amphitruo 30)
While it is not clear how such discontinuous constituency is to be handled in a technical sense in contemporary syntactic theory, we do know something about its diachrony. The discontinuity we see in the examples in (1) is no longer possible in contemporary Romance languages, and if we examine how this ‘change’ seems to have come about, it does not at all look as if, for example, first one ceased allowing discontinuity in phrases headed by pater, then in those headed by filius, etc. That is, it does not appear that we are dealing with a change in a lexical property of the relevant nouns: instead, the data patterns as if whole classes of types of discontinuity disappeared at the same time for all Ns. Thus, the loss of these types of ‘discontinuous constituency’ can be most plausibly analysed as having resulted from changes in the features of a functional head (probably D). This of course parallels quite closely ‘regular’ phonological change.
Thus while it is certainly true that at present those working on syntactic reconstruction cannot perhaps claim the large body of successful applications of the Method that we have seen in phonological reconstruction, we should be aware first that the reconstruction of bound morphology generally speaking directly entails the reconstruction of aspects of the syntax of the languages being compared – and thus much more syntactic reconstruction has been done than is generally acknowledged – and that doubts about the applicability of the concepts of ‘cognancy’ (sometimes called the ‘what do we compare?’ problem) and ‘regularity’ in the syntactic domain may be somewhat overstated.
Recoverable proto-language diversification can be excluded in principle under certain assumptions (which I have attempted to outline here) about the natures of: (1) the object of linguistic study (‘language’); and (2) the Comparative Method. If one doesn’t like the approach outlined here and one wants to exclude proto-language dialects (like most traditional historical linguists do), one must find some principled way to get that result. One may not simply assert that proto-language dialects are precluded.
If one wants to embrace the idea of proto-language dialects, one faces the same problems known to plague ‘wave-model’ conceptualisations of language history from the time of their first entry into the historical linguistic enterprise: the Comparative Method is not a procedure which has a coherent definition under such assumptions and no alternative procedures have ever been developed which would allow for reconstruction (or account for why ‘classical’ reconstruction has been so successful) under such assumptions. You cannot use any existing reconstructed data to argue for the view that proto-language heterogeneity existed (as Lichtenberk does, extensively) since that data can only be arrived at by the assumption of uniform objects of comparison, and uniform proto-languages. To the extent the assumption of such objects is not licit, the data you would be building your argument out of is not valid, and thus not evidence of anything.
The dramatic successes of the Comparative Method in Indo-European and Austronesian, just to take the examples with which I am most familiar, indicate that there is something fundamentally valid in the Method as traditionally practiced. I have argued here that that practice assumes a conception of the nature of ‘language’ – as individual grammars – which converges with that developed independently in modern theoretically-informed work in linguistics. It would be truly remarkable, given that the two most productive periods in the history of the study of linguistics have thus converged on very similar conceptions of the object of investigation, if that conception were to be terribly far off the mark.
1 Of course, more careful detailed observation may reveal that such similarity is present where it did not first seem to be, or, equally of course, that no such similarity is present where it was once thought to be.
2 For a consideration of these broader issues from the perspective of historical linguistics, see the chapters in this volume by Heggarty, Pakendorf, and Epps.
3 On the tentative nature of the data, see the discussion in the source, Try on (1976). The phonemicisation is not in every instance clear, though I believe it is more or less as presented in the table. It is best to see the discussion above as a ‘simplified teaching example’ which abstracts away from various complexities, rather than as an analysis of the subgrouping relationships within the languages of Espiritu Santo. For the latter purpose, the data is simply too tentative and unsure. The case is nevertheless useful in the present context because of the highly unusual nature of the phonetic developments in play.
4 I ignore for present purposes various minor or not entirely clear developments.
5 For the arguments see Lichtenberk’s original paper (Lichtenberk 1994) and the more extensive discussion of my concerns with his arguments found in Hale (2008).
6 It is, of course, not unusual for epenthesis – of which prothesis is a species – and loss to involve the same segments in a given set of languages: think of ‘linking r’ in varieties of English which show post-vocalic r-deletion.
7 I ignore here the issue of the ‘lexical diffusion’ of the change, since it does not matter overly much for our purposes whether we are dealing with a ‘sound change’ (which I, and the Method, assume to be ‘regular’) or a ‘lexical change’.
8 A key component of Lichtenberk’s argument that we are still, after y-loss, in the ‘proto-language’ stage is that there are later ‘shared innovations’, best attributed to the ‘shared entity’ the proto-language is supposed to represent. In my view, this rather undermines one of the great values of the Comparative Method, in that Lichtenberk’s move keeps us from getting a handle on what kinds of spread of change across already differentiated sets of grammars is possible. By asserting that such changes are simply to be attributed to the proto-language, even though they took place after recoverable differentiation, Lichtenberk is simplifying a problem whose complexity is, in my view, worthy of full consideration and analysis. A reviewer asks whether, in practice, when faced with many different patterns of overlapping innovations, we will always be able to separate them out in the way we have been able to do – based on Lichtenberk’s own analysis – in the case under discussion. The answer is simple: probably not. But the limits on our capacity to achieve scientific clarity on a historical question do not license changing the very nature of the objects being reconstructed. In particularly complex, or particularly data-poor, situations we may never be able to fully recover what happened. But that is the correct result: it is but cold comfort to develop a methodology which gives the illusion of avoiding this problem by pretending to provide answers when in fact such answers are not recoverable.
9 The internal structure of the PES-A branch, indeed, even whether it is appropriate to assume that these languages form a distinct subgroup, is not relevant to the methodological discussion here, which concerns itself instead only with determining who belongs in the PES-B subgroup and what that subgroup’s internal structure is. For ease of representation, I will just assume that the languages not in PES-B form a separate branch of the family. As with all aspects of this problem, this should not be taken as an actual claim about the real languages of Espiritu Santo.
10 The alternative, whereby *ß was apicalised in PES-B and came to be ‘de-apicalised’ in Tolomako, gives us a more aesthetically satisfying PES-B rule, but a *ß > *v > ß set of changes in the history of Tolomako. Such developments are strongly disfavoured by the Method when, as in this case, they leave no trace in the actual historical record.
11 By ‘phonetic representation’ and ‘allophonic information’ I am referring expressly to the variant ‘realisations’ of underlying phonemes which result from grammatical computation, not from the vagaries of physical realisation. These forms are fully determined by: (1) the underlying representations (which serve as the input to the phonological computation); and (2) the computational phonology (which, operating on those inputs, generate an output, or ‘phonetic’, representation).
12 Of course, technically they do not have direct access to the ‘phonetic’ form qua grammar output, either, but it is assumed that variation in the actual articulation of phonetic targets is something the learner is prepared to deal with, and, in any event, that such variation arises from factors too variable (passing trains, articulatory fatigue or exuberance) to systematically affect the data.
13 For more extensive discussion of syntactic change and reconstruction, see the chapters by Barödal, van Gelderen, and Frajzyngier in this volume.
14 It was this type of ‘syntactic change’ that I had in mind when I mentioned the spread of the accusative case at the expense of ‘lexically determined’ object marking for some particularly predicate in some particular daughter language above.
Durie, Mark and Malcolm Ross. 1996. The Comparative Method reviewed: regularity and irregularity in language change. New York/Oxford: Oxford University Press.
Hale, Mark. 2008. Historical linguistics: theory and method. Boston Wiley-Blackwell.
Hoenigswald, Henry M. 1960.Language change and linguistic reconstruction. Chicago: University of Chicago Press.
Fox, Anthony. 1995. Linguistic reconstruction: an introduction to theory and method. New York: Oxford University Press.
Hale, Mark. 1998. Diachronic Syntax. Syntax 1: 1–18.
——2008. Historical linguistics: theory and method. Boston: Wiley-Blackwell.
Hoenigswald, Henry M. 1960.Language change and linguistic reconstruction. Chicago: University of Chicago Press.
Lichtenberk, Frantisek. 1994. Reconstructing heterogeneity. Oceanic Linguistics 33(1): 1–36.
Lightfoot, David. 1979.Principles of Diachronic Syntax. Cambridge: Cambridge University Press.
——2002. Myths and the prehistory of grammars. Journal of Linguistics 38: 113–136.
Ohala, John. 1978. Southern Bantu vs. the world: the case of palatalization of labials.Proceedings of the Annual Meeting of the Berkeley Linguistics Society 4: 370–386.
Try on, Darrell T. 1976.New Hebrides languages: an internal classification. Canberra: Pacific Linguistics.