Tokenization, parsing and compilation in JRuby
Although JRuby uses a completely different technical platform than MRI Ruby does - JRuby uses Java while MRI Ruby uses C - it tokenizes and parses your code in much the same way. Once your code is parsed, JRuby and MRI both continue to compile your code into byte code instructions. As I explained above, Ruby 1.9 and Ruby 2.0 compile your Ruby code into byte code instructions that Ruby’s custom YARV virtual machine executes. JRuby, however, instead compiles your Ruby code into Java byte code instructions that are interpreted end executed by the Java Virtual Machine (JVM):
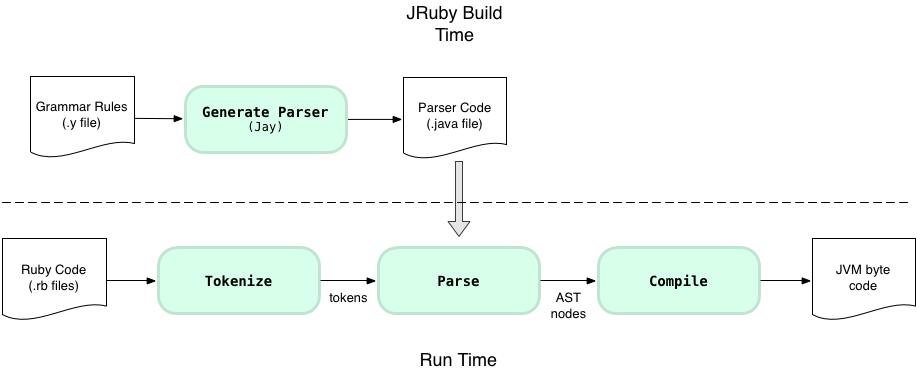
Just like with Ruby 2.0, 1.9 and 1.8, JRuby uses a two step process for tokenizing and parsing. First, ahead of time during the JRuby build process a tool called Jay generates LALR parser code based on a grammar file, in just the same way that MRI Ruby uses Bison. In fact, Jay is really just a rewrite of Bison that generates a parser that uses Java or C# code instead of C. For JRuby the grammar file is called DefaultRubyParser.y instead of parse.y and the generated parser code is saved in a file called DefaultRubyParser.java instead of parse.c. Note: if you run JRuby in 1.9 compatibility mode, the new default for the JRuby head/master build, JRuby will use a different file called Ruby19Parser.y instead. The JRuby team more or less copied over the grammar rules from MRI Ruby’s parse.y into DefaultRubyParser.y and Ruby19Parser.y - this is not a surprise since JRuby aims to implement Ruby in a completely compatible way.
Then, once you have installed JRuby on your machine including the generated parser, JRuby will run the parser to tokenize and parse your Ruby script. First JRuby will read the text from your Ruby file and generate a stream of tokens, and next the generated LALR parser will convert this stream of tokens into an AST structure. This all works essentially the same as it does in MRI Ruby.
Here’s a high level view of the different forms your Ruby code takes as you run a JRuby process:

At the top you can see JRuby converts your Ruby code into a token stream and then, in turn, into an AST structure. Next, JRuby compiles these AST nodes into Java byte code, which are later interpreted and executed by the JVM - the same VM that runs Java programs along with many other programming languages such as Clojure and Scala.
I didn’t include the “interpret” dotted line in this diagram that appears in the analogous Ruby 1.8 and Ruby 1.9 diagrams, because the JVM’s JIT (“Just In Time”) compiler actually converts some of that Java byte code - the compiled version of your Ruby program - into machine language. The JVM will take the time to do this for “hotspots” or frequently called Java byte code functions. For this reason, JRuby can often run faster than MRI Ruby even though it’s implemented in Java and not C, especially for long running processes. What this means is that it’s possible for JRuby and the JVM working together to convert part of the Ruby code you write all the way into native machine language code!
Taking a look at the JRuby tokenizing and parsing code details, the similarity to MRI is striking. The only real difference is that JRuby is written in Java instead of C. For example, here’s some of the code that JRuby uses to tokenize the stream of characters read in from the target Ruby code file - you can find this in RubyYaccLexer.java in the src/jruby/org/jruby/lexer/yacc folder.
loop: for(;;) { c = src.read(); switch(c) {
...
case ',':
return comma(c);
Just like the parser_yylex function in MRI Ruby, the RubyYaccLexer Java class uses a giant switch statement to branch based on what character is read in. Above is the start of this switch statement, which calls src.read() each time it needs a new character, and one case of the switch statement that looks for comma characters. The JRuby code is somewhat simpler and cleaner than the corresponding MRI Ruby code, since it uses object oriented Java vs. standard C. For example, tokens are represented by Java objects - here’s the comma function called from above which returns a new comma token:
private int comma(int c) throws IOException { setState(LexState.EXPR_BEG); yaccValue = new Token(",", getPosition()); return c; }
It’s a similar story for parsing: the same idea using a different programming language. Here’s a snippet from the DefaultRubyParser.y file - this implements the same method_call grammar rule that I discussed in detail earlier for MRI Ruby:
method_call :
...
| primary_value tDOT operation2 opt_paren_args {
$$ = support.new_call($1, $3, $4, null);
}
Since JRuby uses Jay instead of Bison, the code that JRuby executes when there’s a matching rule is Java and not C. But you can see Jay uses the same “$$, $1, $2, etc.” syntax to specify the return value for the grammar rule, and to allow the matching code to access the values of each of the child rules.
Again, since the matching code is written in Java and not C, it’s generally cleaner and easier to understand compared to the same code you would find in MRI Ruby. In the snippet above, you can see JRuby creates a new call AST node to represent this method call. In this case the support object, an instance of the ParserSupport class, actually creates the AST node. Instead of C structures, JRuby uses actual Java objects to represent the nodes in the AST tree.
JRuby's Ruby to JVM byte code compiler, however, doesn’t resemble the YARV compiler code I explained earlier in Chapter 1 very much. Instead, the JRuby team implemented a new, custom compiler - it walks the AST node tree in a similar way, but outputs JVM byte code instructions instead of YARV instructions. Generally these byte code instructions are more granular and low-level compared to the YARV instructions - i.e. each instruction does less and there are more of them. This is due to the nature of the JVM, which was designed to run not only Java but also many other languages. The YARV instructions, as we’ve seen, are designed specifically for Ruby. If you’re interested in exploring JRuby’s compiler, look in the org.jruby.compile package in your copy of the JRuby source tree.
The JRuby core team is also currently working on a new higher-level and less granular instruction set called “IR,” which will be specifically designed to represent Ruby programs. To learn more about the new IR instruction set see the article OSS Grant Roundup: JRuby’s New Intermediate Representation.