YARV’s internal stack and your Ruby stack

track of your Ruby call stack.
As we’ll see in moment, YARV uses a stack internally to keep track of intermediate values, arguments and return values. YARV is a stack-oriented virtual machine.
But alongside YARV’s internal stack Ruby also keeps track of your Ruby program’s call stack: which methods called which other methods, functions, blocks, lambdas, etc. In fact, YARV is not just a stack machine – it’s a “double stack machine!” It not only has to track the arguments and return values for it’s own internal instructions; it has to do it for your Ruby arguments and return values as well.
First let’s take a look at YARV’s basic registers and internal stack:
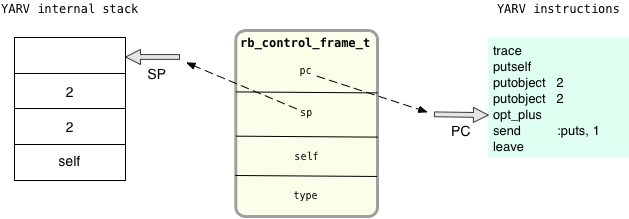
On the left I show YARV’s internal stack – SP is the “stack pointer” or location of the top of the stack. On the right are the instructions that YARV is currently executing. PC is the program counter or location of the current instruction. You can see the YARV instructions that Ruby compiled from my “puts 2+2” example from Chapter 1. YARV stores both the SP and PC registers in a C structure called rb_control_frame_t, along with a type field, the current value of Ruby’s self variable and some other values I’m not showing here.
At the same time YARV maintains another stack of these rb_control_frame structures, like this:
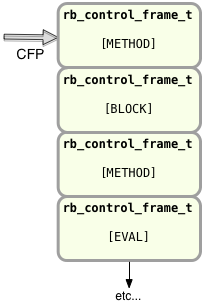
This second stack represents the path through your Ruby program YARV has taken and it’s current location. In other words, this is your Ruby call stack – what you would see if you ran “puts caller.” The CFP pointer indicates the “current frame pointer.” Each stack frame in your Ruby program stack contains, in turn, a different value for the self, PC and SP registers we saw above. The type field in each rb_control_frame_t structure indicates what type of code is running at this level in your Ruby call stack. As Ruby calls into the methods, blocks or other structures in your program the type might be set to METHOD, BLOCK or one of a few other values.
Stepping through how Ruby executes a simple script
To understand all of this better, let’s run through a couple examples. I’ll start with my simple 2+2 example:
puts 2+2
This one line Ruby script doesn’t have any Ruby call stack, so I’ll focus on the internal YARV stack only for now. Here’s how YARV will execute this script, starting with the first instruction, trace:
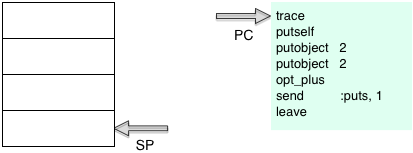
You can see here YARV starts the PC or program counter at the first instruction, and initially the stack is empty. Now YARV will execute the trace instruction, incrementing the PC register:
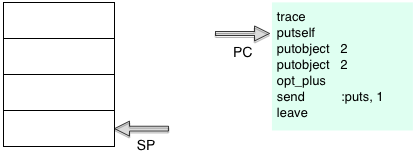
Ruby uses the trace instruction to support the set_trace_func feature: if you call set_trace_func and provide a function, Ruby will call it each time it executes a line of Ruby code, or when a few other events occur.
Next YARV will execute putself and push the current value of self onto the stack:
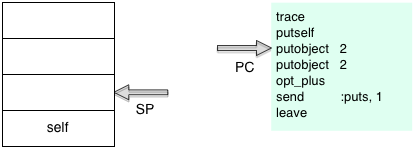
Since this simple script contains no Ruby objects or classes the self pointer will be set to the default “top self” object. This is an instance of the Object class Ruby automatically creates when YARV starts up. It serves as the receiver for method calls and the container for instance variables in the top level scope. The “top self” object contains a single, predefined to_s method which returns the string “main” – you can call this method by running this command at your console:
$ ruby -e 'puts self'
Later YARV will use this self value on the stack when it executes the send instruction – self is the receiver of the puts method, since I didn’t specify a receiver for this method call.
Next YARV will execute “pushobject 2” and push the numeric value 2 onto the stack, and increment the PC again:
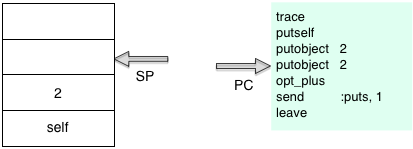
This is the first step of the receiver – arguments – operation pattern I described in Chapter 1. First Ruby pushes the receiver onto the internal YARV stack; in this example the Integer object 2 is the receiver of the message/method plus which takes a single argument, also a 2. Next Ruby will push the argument 2:
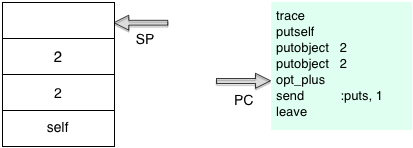
And finally it will execute the operation – in this case opt_plus is an special, optimized instruction that will add two values: the receiver and argument.
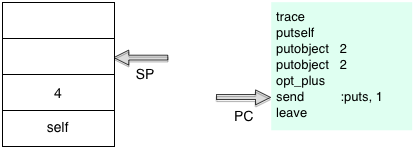
You can see the opt_plus instruction leaves the result, 4, at the top of the stack. And now, as I explained in Chapter 1, Ruby is perfectly positioned to execute the puts function call… the receiver self is first on the stack and the single argument, 4, is at the top of the stack. I’ll describe how method lookup works in Chapter 3, but for now let’s just step ahead:

Here the send instruction has left the return value, nil, at the top of the stack. Finally Ruby executes the last instruction leave, which finishes up executing our simple, one line Ruby program.
Executing a call to a block
Now let’s take a slightly more complicated example and see how the other stack – your Ruby program stack – works. Here’s a simple Ruby script that calls a block 10 times, printing out a string:
10.times do puts "The quick brown fox jumps over the lazy dog." end
Let’s skip over a few steps and start off where YARV is about to call the times method:
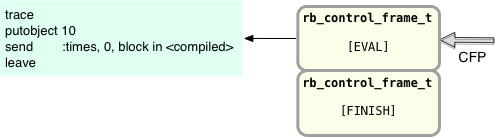
On the left are the YARV instructions Ruby is executing, and now on the right I’m showing two control frame structures. At the bottom of the stack is a control frame with the type set to FINISH – Ruby always creates this frame first when starting a new program. At the top of the stack initially is a frame of type EVAL – this corresponds to the top level or main scope of your Ruby script. Internally, Ruby uses the FINISH frame to catch any exceptions that your Ruby code might throw, or to catch exceptions generated by a break or return keyword. I’ll have more on this in section 2.3.
Next when Ruby calls the times message on the Integer object 10 the receiver of the times message, it will add a new level to the control frame stack:
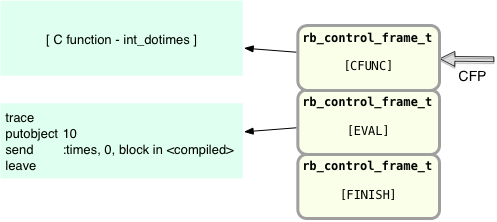
This new entry on the right represents a new level in your program’s Ruby call stack, and the CFP pointer has moved up to point at the new control frame structure. Also since the times Integer method is built into Ruby there are no YARV instructions for it. Instead, Ruby will call some internal C code that will pop the argument “10” off the stack and call the provided block 10 times. Ruby gives this control frame a type of CFUNC.
Finally, if we interrupt the program inside the inner block here’s what the YARV and control frame stacks will look like:

You can see there will now be five entries in the control frame stack on the right:
the FINISH and EVAL frames that Ruby always starts up with,
the CFUNC frame for the call to 10.times,
another FINISH frame; Ruby uses this one to catch and exceptions or calls to return or break that might occur inside the block, and
a BLOCK frame; This frame at the top of the stack corresponds to the code running inside the block.
Like most other things, Ruby implements all of the YARV instructions like putobject or send using C code which is then compiled into machine language and executed directly by your hardware. Strangely, however, you won’t find the C source code for each YARV instruction in a C source file. Instead the Ruby core team put the YARV instruction C code in a single large file called insns.def. For example, here’s a small snippet from insns.def showing how Ruby implements the putself YARV instruction internally:
/**
@c put
@e put self.
@j スタックに self をプッシュする。
*/
DEFINE_INSN
putself
()
()
(VALUE val)
{
val = GET_SELF();
}
This doesn’t look like C at all – in fact, most of it is not. Instead, what you see here is a bit of C code (“val = GET_SELF()”) that appears below a call to DEFINE_INSN. It’s not hard to figure out that DEFINE_INSN stands for “define instruction.” In fact, Ruby processes and converts the insns.def file into real C code during the Ruby build process, similar to how Bison converts the parse.y file into parse.c:
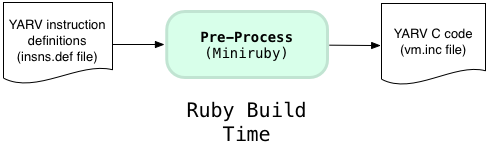
Ruby processes the insns.def file using Ruby: the Ruby build process first compiles a smaller version of Ruby called “Miniruby,” and then uses this to run some Ruby code that processes insns.def and converts it into a C source code file called vm.inc. Later the Ruby build process hands vm.inc to the C compiler which includes the generated C code in the final, compiled version of Ruby.
Here’s what the snippet above for putself looks like in vm.inc after Ruby has processed it:
INSN_ENTRY(putself){
{
VALUE val;
DEBUG_ENTER_INSN("putself");
ADD_PC(1+0);
PREFETCH(GET_PC());
#define CURRENT_INSN_putself 1
#define INSN_IS_SC() 0
#define INSN_LABEL(lab) LABEL_putself_##lab
#define LABEL_IS_SC(lab) LABEL_##lab##_##t
USAGE_ANALYSIS_INSN(BIN(putself));
{
#line 323 "insns.def"
val = GET_SELF();
#line 474 "vm.inc"
CHECK_STACK_OVERFLOW(REG_CFP, 1);
PUSH(val);
#undef CURRENT_INSN_putself
#undef INSN_IS_SC
#undef INSN_LABEL
#undef LABEL_IS_SC
END_INSN(putself);}}}
The single line “val = GET_SELF()” appears in the middle, while above and below this Ruby calls a few different C macros to do various things, like adding one to the program counter (PC) register, and pushing the val value onto the YARV internal stack. The vm.inc C source code file, in turn, is included by the vm_exec.c file, which contains the primary YARV instruction loop: the loop that steps through the YARV instructions in your program one after another and calls the C code corresponding to each one.
Experiment 2-1: Benchmarking Ruby 1.9 vs. Ruby 1.8

The Ruby core team introduced the YARV virtual machine with Ruby 1.9; before that Ruby 1.8 and earlier versions of ruby executed your program by directly stepping through the nodes of the Abstract Syntax Tree (AST). There was no compile step at all; Ruby just tokenized, parsed and then immediately executed your code. Ruby 1.8 worked just fine; in fact, for years Ruby 1.8 was the most commonly used version of Ruby. Why did the Ruby core team do all of the extra work required to write a compiler and a new virtual machine? The answer is simple: speed. Executing a compiled Ruby program using YARV is much faster than walking around the AST directly.
How much faster is YARV? Let’s take a look… in this experiment I’ll measure how much faster Ruby 1.9 is compared to Ruby 1.8 by executing this very simple Ruby script:
i = 0 while i < ARGV[0].to_i i += 1 end
Here I’m passing in a count value on the command line via the ARGV array, and then just iterating in a while loop counting up to that value. This Ruby script is very, very simple – by measuring the time it takes to execute this script for different values of ARGV[0] I should get a good sense of whether executing YARV instructions is actually faster than iterating over AST nodes. There are no database calls or other external code involved.
By using the time Unix command I can measure how long it takes Ruby to iterate 1 time:
$ time ruby benchmark1.rb 1 ruby benchmark1.rb 1 0.02s user 0.00s system 92% cpu 0.023 total
…or 10 times:
$ time ruby benchmark1.rb 10 ruby benchmark1.rb 10 0.02s user 0.00s system 94% cpu 0.027 total
…etc…
Plotting the times on a logarithmic scale for Ruby 1.8.7 and Ruby 1.9.3, I get:
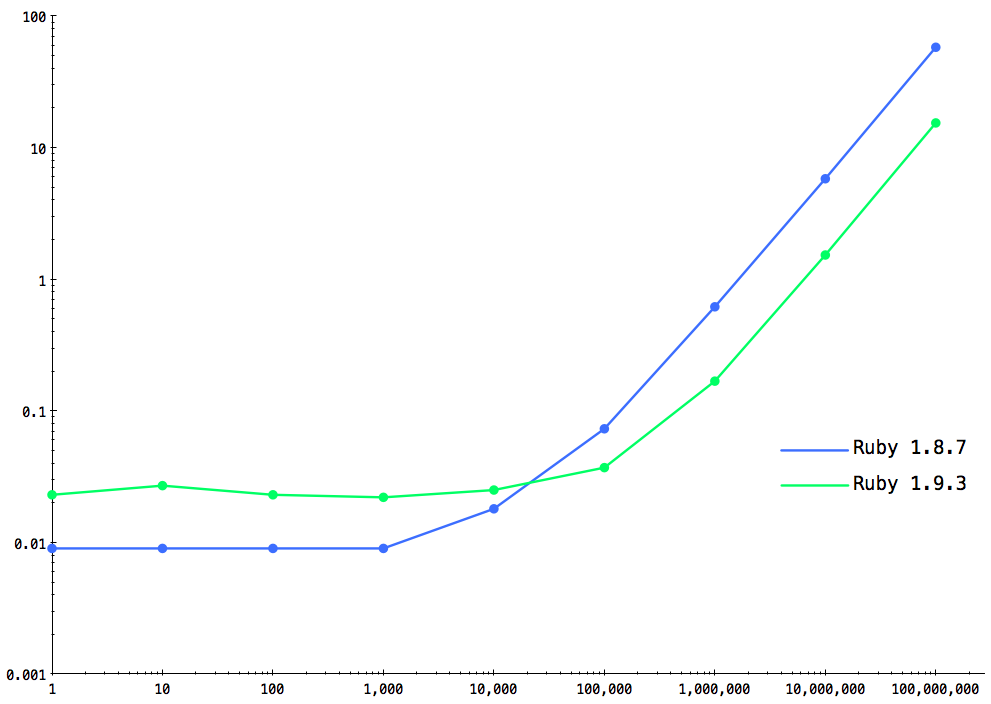
Looking at the chart, you can see that:
For short lived processes, i.e. loops with a small number of iterations shown on the left, Ruby 1.8.7 is actually faster than Ruby 1.9.3, since there is no need to compile the Ruby code into YARV instructions at all. Instead, after tokenizing and parsing the code Ruby 1.8.7 immediately executes it. The time difference between Ruby 1.8.7 and Ruby 1.9.3 at the left side of the chart, about 0.01 seconds, is how long it takes Ruby 1.9.3 to compile the script into YARV instructions.
However, after a certain point – after about 11,000 iterations – Ruby 1.9.3 is faster. This crossover occurs when the additional speed provided by executing YARV instructions begins to pay off, and make up for the additional time spent compiling.
For long lived processes, i.e. loops with a large number of iterations shown on the right, Ruby 1.9 is about 3.75 times faster!
This speed up doesn’t look like much on the logarithmic chart above, but if I redraw the right side of this chart using a linear scale:
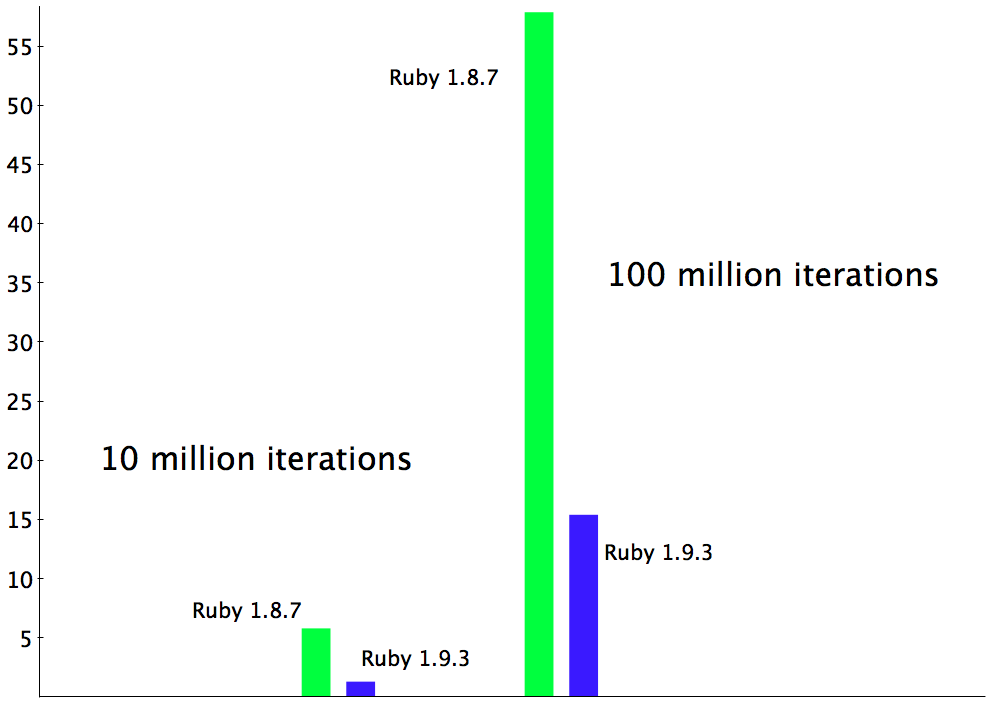
…you can see the difference is dramatic! Executing this simple Ruby script using Ruby 1.9.3 with YARV is about 3.75 times faster than it using Ruby 1.8.7 without YARV!