Hash tables in JRuby
It turns out JRuby implements hashes more or less the same way MRI Ruby does. Of course, the JRuby source code is written in Java and not C, but the JRuby team chose to use the same underlying hash table algorithm that MRI uses. Since Java is an object oriented language, unlike C, JRuby is able to use actual Java objects to represent the hash table and hash table entries, instead of C structures. Here’s what a hash table looks like internally inside of a JRuby process:
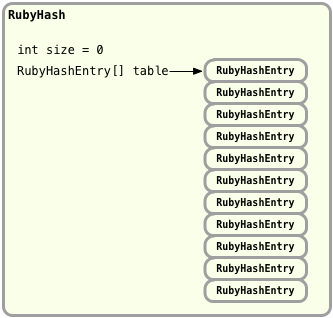
Instead of the C RHash and st_table structures, we have a Java object which is an instance of RubyHash. And instead of the bin array and st_table_entry structures we have an array of Java objects of type RubyHashEntry. The RubyHash object contains an instance variable called size which keeps track of the number of elements in the hash, and another instance variable called table, which is the RubyHashEntry array.
JRuby allocates 11 empty RubyHashEntry objects or hash table bins when you create a new hash. As you insert elements into the hash, JRuby fills in these objects them with keys and values. Inserting and retrieving elements works the same was as in MRI: JRuby uses the same formula to divide the hash value of the key by the bin count, and uses the modulus to find the proper bin:
bin_index = internal_hash_function(key) % bin_count
As you add more and more elements to the hash, JRuby forms a linked list of RubyHashEntry objects as necessary when two keys fall into the same bin - just like MRI:

JRuby also tracks the density of entries, the average number of RubyHashEntry objects per bin, and allocates a larger table of RubyHashEntry objects as necessary to rehash the entries.
If you’re interested, you can find the Java code JRuby uses to implement hashes in the src/org/jruby/RubyHash.java source code file. I found it easier to understand than the original C code from MRI, mostly because in general Java is a bit more readable and easier to understand than C is, and because it’s object oriented. The JRuby team was able to separate the hash code into different Java classes, primarily RubyHash and RubyHashEntry.
The JRuby team even used the same identifier names as MRI in some cases; for example you’ll find the same ST_DEFAULT_MAX_DENSITY value of 5, and JRuby uses the same table of prime numbers that MRI does: 11, 19, 37, etc., that fall near powers of two. This means that JRuby will show the same performance pattern MRI does for reallocating bins and redistributing the entries.