Lambdas and Procs: treating functions as a first class citizen
in his research on Lambda Calculus
Next let’s look at a different, convoluted way of printing the same string to the console:
def message_function str = "The quick brown fox" lambda do |animal| puts "#{str} jumps over the lazy #{animal}." end end function_value = message_function function_value.call('dog')
Here you can see I’m using a lambda keyword to return a block, which I call later after message_function returns. This is an example of “treating a function as a first class citizen,” to paraphrase a commonly used computer science expression. Here I use the block as just another type of data – I return it from message_function, I save it in code_value and finally I call it explicitly using the call method. With the lambda keyword – or with the equivalent proc keyword or Proc object – Ruby allows you to convert a block into a data value like this.
In a moment, I’ll take a look inside of Ruby to see what happens when I call lambda and how Ruby converts code into data. But first: where does the word “lambda” come from? Why in the world did Ruby choose to use a Greek letter as a language keyword? Once again, Ruby has borrowed an idea from Lisp. Lambda is also a reserved keyword in Lisp; it allows Lisp programmers to create an anonymous function like this:
(lambda (arg) (/ arg 2))
Like in my Ruby example, Lisp developers can treat anonymous functions like the one above as data, passing them into other functions as arguments.
Taking a look even farther back in history, however, it turns out that the term “lambda” was introduced well before John McCarthy invented Lisp in 1958. You may have noticed that Sussman and Steele’s 1975 paper was titled Scheme: An Interpreter for Extended Lambda Calculus. Here they are referring to an area of mathematical study called “Lambda Calculus” invented by Alonzo Church in the 1930s. As part of his research, Church formalized the mathematical study of functions, and introduced the convention of using the Greek letter λ to refer to a function along with an ordered list of arguments the function uses. Later in his 1960 paper introducing Lisp, Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I , John McCarthy references Church’s work directly while discussing functions and function definitions.
Stack memory vs. heap memory
Now let’s return to my example:
def message_function str = "The quick brown fox" lambda do |animal| puts "#{str} jumps over the lazy #{animal}." end end function_value = message_function function_value.call('dog')
What happens when I call lambda? How does Ruby convert the block into a data value? What does it really mean to treat this function as a first class citizen?
Does the message_function function return an rb_block_t structure directly? Or does it return an rb_lambda_t structure? If we could look inside this, what would we see? How does it work?

Before trying to understand what Ruby does internally when you call lambda, let’s first review how Ruby handles the string value str more carefully. First imagine that YARV has a stack frame for the outer function scope but hasn't called message_function yet:
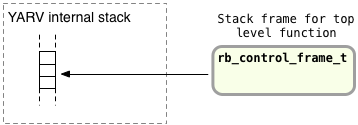
As usual you can see YARV’s internal stack on the left, and the rb_control_frame structure on the right. Now suppose Ruby executes the message_function function call:
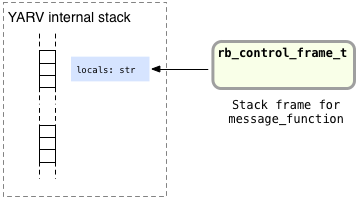
Here again we have the str variable saved in the top level stack frame used by message_function. Before going farther, let’s take a closer look at that str variable and how Ruby stores the “quick brown fox” string in it. Recall from Chapter 3 that Ruby stores each of your objects in a C structure called RObject, each of your arrays in an RArray structure, and similarly each of your strings in a structure called RString. For example, Ruby saves the quick brown fox string like this:
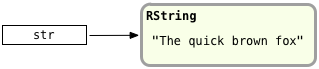
We have the actual string structure on the right, and a reference or pointer to the string on the left. When Ruby saves a string value on the YARV stack – or any object value for that matter – it actually only places the reference to the string on the stack. The actual string structure is saved in the “heap” instead:

The heap is a large area of memory that Ruby or any other C program can allocate memory from. Objects or other values that Ruby saves in the heap remain valid for as long as there is a reference to them, the str pointer in this example. Here’s a more accurate picture of what Ruby does when we create the str local variable inside of message_function:
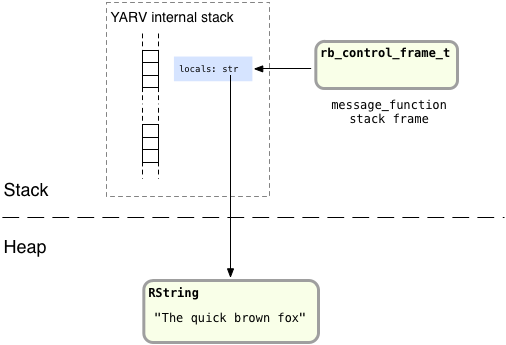
After there are no longer any pointers referencing a particular object or value in the heap, Ruby later can free it during the next run of the garbage collection system. To show this happening, let’s suppose for a moment that my example code didn’t call lambda at all, that instead it immediately returned nil after saving the str variable:
def message_function str = "The quick brown fox" nil end
After this call to message_function finishes, YARV will simply pop the str value and any other temporary values saved there off the stack and return to the original stack frame:
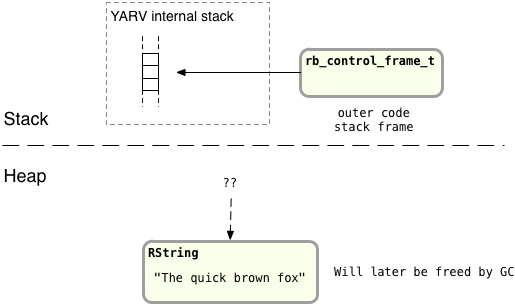
You can see there no longer is any reference to the RString structure containing the “quick brown fox” string and that Ruby will free it later.
Stepping through how Ruby creates a lambda
Now let’s return to my original example code that returns the lambda expression instead of nil:
def message_function str = "The quick brown fox" lambda do |animal| puts "#{str} jumps over the lazy #{animal}." end end function_value = message_function function_value.call('dog')
Notice that later when I actually call the lambda – the block – the puts statement inside the block is somehow able to access the str string variable from inside message_function. How can this be possible? We’ve just seen how the str reference to the RString structure is popped off the stack when message_function returns! Obviously, Ruby must do something special when you call lambda; somehow after calling lambda the value of str lives on so the block can later access it.
When you call lambda, internally Ruby copies the entire contents of the current YARV stack frame into the heap – the same place the RString structure is located. For example, here is the YARV stack again just after we call message_function:
To keep things simple, I don’t show the RString structure here, but remember the RString structure will be saved in the heap.
Next, Ruby will call lambda; here’s what happens internally:
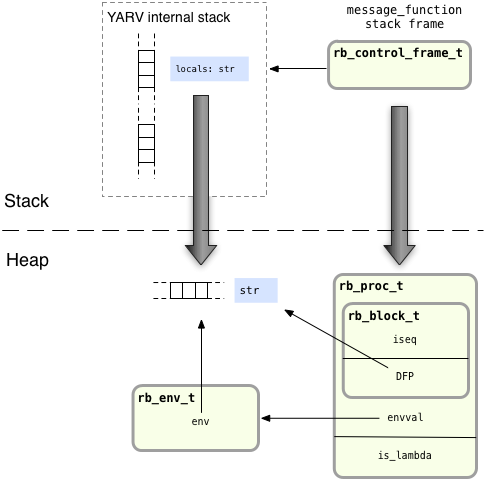
You can see Ruby has created a new copy of the stack frame for message_function in the heap. I indicate that with the horizontal stack icon that appears below the dotted line. Now there is a second reference to the str RString structure, which means Ruby won’t free it when message_function returns.
Along with the copy of the stack frame, Ruby creates two other new objects in the heap:
An internal environment object, represented by the rb_env_t C structure at the lower left. This object only exists internally inside of Ruby; you can’t access this environment directly from your Ruby code. It is essentially a wrapper for the heap copy of the stack.
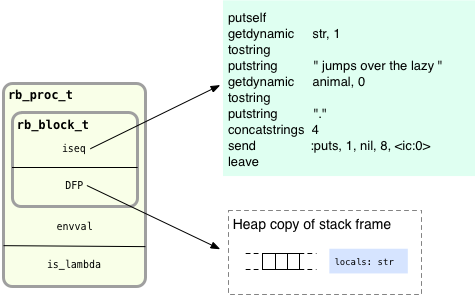
A Ruby Proc object, represented by the rb_proc_t structure. As you may know, this is the actual return value from the lambda keyword; this object is what the message_function function returns.
Note the new Proc object structure, rb_proc_t, actually contains an rb_block_t structure, including the iseq and DFP pointers. Just as with a normal block, these keep track of the block’s code and the referencing environment for the block’s closure. Ruby sets the DFP inside this block to point to the new heap copy of the stack frame. You can think of a Proc as a Ruby object that wraps up a block; technically speaking, this is exactly what it is.
Also, notice the Proc object – the rb_proc_t structure – contains an internal value called is_lambda. This will be set to true for my example since I used the lambda keyword to create the Proc. If I had created the Proc using the proc keyword instead, or by just calling Proc.new, then is_lambda would be set to false. Ruby uses this flag to produce the slight behavior differences between procs and lambdas; however, it’s best to think of procs and lambdas as essentially the same thing.
Stepping through how Ruby calls a lambda
What happens when message_function returns? Since the lambda or proc object is the return value of message_function, a reference or pointer to the lambda is saved in the stack frame for the outer function in the function_value local variable. This prevents Ruby from freeing the proc, the internal environment object and the str variable; there are now pointers referring to all of these values in the heap:
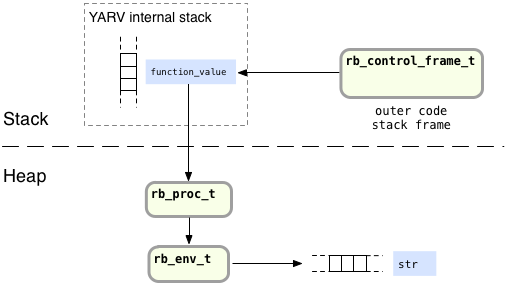
Finally, when Ruby executes the call method on the proc object returned by message_function:
function_value = message_function
function_value.call('dog')
…it finally executes the block contained in the proc:

When Ruby calls a normal block, it creates a new stack frame for the block to use, and saves the animal value – the argument passed to the block – into this new stack frame. And just as with calling a normal block, Ruby also copies the DFP pointer from the rb_block_t structure into the new stack frame.
The only real difference here is that the DFP points to the copy of the stack frame Ruby created in the heap earlier when it executed lambda. This DFP allows the code inside the block, the call to puts, to access the str value.
The Proc object
Stepping back for a moment to review, we’ve just seen that inside of Ruby there really is no structure called rb_lambda_t:
Instead, Ruby’s lambda keyword created a proc object, which internally is a wrapper for a block – the block you pass to the lambda or proc keyword:
Just like a normal block, this is a closure: it contains a function along with the environment that function was referred to or created in. You can see that in this case the environment is a persistent copy of the stack frame saved in the heap.
There’s an important difference between a normal block and a proc: procs are Ruby objects. Internally, they contain the same information that other Ruby objects contain, including the RBasic structure I discussed in Chapter 3. Above I mentioned that the rb_proc_t structure represents the Ruby proc object; it turns out this isn’t exactly the case. Internally, Ruby uses another data type called RTypedData to represent instances of the proc object:
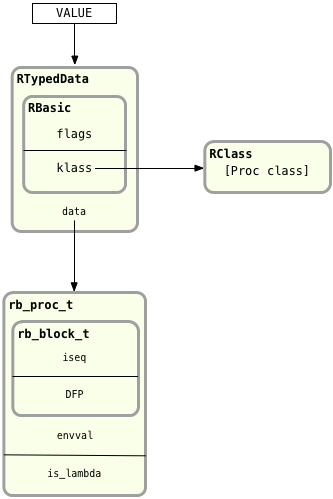
You can think of RTypedData as a trick that Ruby’s C code uses internally to create a Ruby object wrapper around some C data structure. In this case, Ruby uses RTypedData to create an instance of the Proc Ruby class that represents a single copy of the rb_proc_t structure.
Here, just as we saw in Chapter 3, the RTypedData structure contains the same RBasic information that all Ruby objects contain:
flags: some internal technical information Ruby needs to keep track of
klass: a pointer to the Ruby class this object is an instance of, in this case the Proc class.
Here’s a another look at how Ruby represents a proc object, this time shown on the right next to a RString structure:
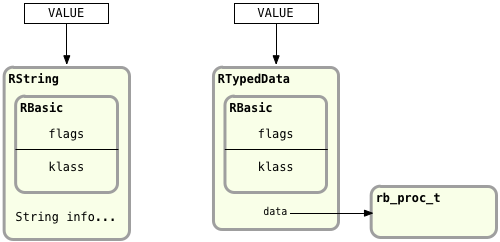
Notice how Ruby handles the string value and the proc value in a very similar way. Just like strings, for example, procs can be saved into variables or passed as arguments to a function call. Ruby uses the VALUE pointer to the proc whenever you do this.
Experiment 5-2: Changing local variables after calling lambda

My previous code example showed how calling lambda makes a copy of the current stack frame in the heap.
def message_function str = "The quick brown fox" lambda do |animal| puts "#{str} jumps over the lazy #{animal}." end end function_value = message_function function_value.call('dog')
Specifically, the str string value is valid here even after message_function returns. But what happens if I modify this value in message_function after calling lambda?
def message_function str = "The quick brown fox" func = lambda do |animal| puts "#{str} jumps over the lazy #{animal}." end str = "The sly brown fox" func end function_value = message_function function_value.call('dog')
Notice now I change the value of str after I create the lambda. Running this code I get:
$ ruby modify_after_lambda.rb The sly brown fox jumps over the lazy dog.
How is this possible? In the previous section I discussed how Ruby makes a copy of the current stack frame when I call lambda. In other words, Ruby copies the stack frame after running this code:
str = "The quick brown fox" func = lambda do | animal | puts "#{str} jumps over the lazy #{animal}." end

Then after this copy is made, I change str to the “sly fox” string:
str = "The sly brown fox"
Since Ruby copied the stack frame above when I called lambda, now I should be modifying the original copy of str and not the new lambda copy:
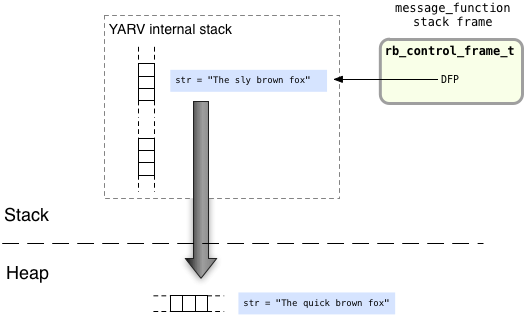
This means that the new, lambda copy of the string should have remained unmodified. Calling the lambda later I should have gotten the original “quick fox” string, not the modified “sly fox” string.
What happened here? How does Ruby support this behavior? How does Ruby allow me to modify the new, persistent copy of the stack after it’s been created by lambda?
An important detail that I left out of my diagrams in the previous section is that after Ruby creates the new heap copy of the stack – the new rb_env_t structure or internal “environment” object – Ruby also resets the DFP in the rb_control_frame_t structure to point to the copy. Here’s another view of Ruby copying the local stack frame into the heap:

The only difference here is that the DFP now points down to the heap. This means that when my code accesses or changes any local variables after calling lambda, Ruby will use the new DFP and access the value in the heap, not the original value on the stack. In this code, for example:
str = “The sly brown fox”
Ruby actually modifies the new, heap copy that will later be used when I call the lambda:

Another interesting behavior of the lambda keyword is that Ruby avoids making copies of the stack frame more than once. For example, suppose that I call lambda twice in the same scope:
i = 0 increment_function = lambda do puts "Incrementing from #{i} to #{i+1}" i += 1 end decrement_function = lambda do i -= 1 puts "Decrementing from #{i+1} to #{i}" end
Here I expect both lambda functions to operate on the local variable i in the main scope. Thinking about this for a moment, if Ruby made a separate copy of the stack frame for each call to lambda, then each function would operate on a separate copy of i – and would call my lambdas like this…
increment_function.call decrement_function.call increment_function.call increment_function.call decrement_function.call
…would yield these results:
Incrementing from 0 to 1 Decrementing from 0 to -1 Incrementing from 1 to 2 Incrementing from 2 to 3 Decrementing from -1 to -2
But instead I actually get this:
Incrementing from 0 to 1 Decrementing from 1 to 0 Incrementing from 0 to 1 Incrementing from 1 to 2 Decrementing from 2 to 1
Most of the time this is what you expect: each of the blocks you pass to the lambdas access the same variable in the parent scope. Ruby achieves this simply by checking whether the DFP already points to the heap. If it does, as it would in this example the second time I call lambda, then Ruby won't create a second copy again. It would simply reuse the same rb_env_t structure in the second rb_proc_t structure. Both lambdas would use the same heap copy of the stack.