Finally, the update step happens when the algorithm reaches a terminal state, or when either player wins or the game culminates in a draw. For each node/state of the board that was visited during this iteration, the algorithm updates the mean reward and increments the visit count of that state. This is also called backpropagation:
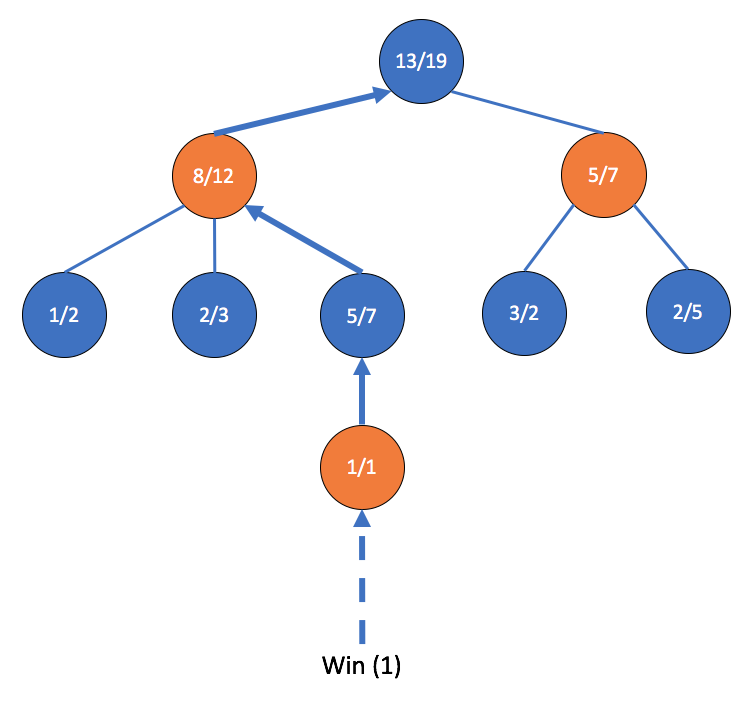
In the preceding diagram, since we reached a terminal state that returned 1 (a win), we increment the visit count and reward accordingly for each node along the path from the root node accordingly.
That concludes the four steps that occur in one MCTS iteration. As the name Monte Carlo suggests, we conduct this search multiple times before we decide the next move to take. The number of iterations is configurable, and often depends on time/resources available. Over time, the tree learns a structure that approximates a perfect tree and can be used to guide agents to make decisions.
AlphaGo and AlphaGo Zero, DeepMind's revolutionary Go playing agents, rely on MCTS to select moves. In the next section, we will explore the two algorithms to understand how they combine neural networks and MCTS to play Go at a superhuman level of proficiency.