6

Insights from the Human Mind
What magical trick makes us intelligent? The trick is that there is no trick. The power of intelligence stems from our vast diversity, not from any single, perfect principle.
—MARVIN MINSKY, THE SOCIETY OF MIND
In 2013, not long after the two of us started collaborating, we encountered a media frenzy that made our blood boil. Two researchers, Alexander Wissner-Gross and Cameron Freer, had written a paper proposing that intelligence of every kind was a manifestation of a very general physical process called “causal entropic forces.” In a video, Wissner-Gross claimed to show that a system built on this idea could “walk upright, use tools, cooperate, play games, make useful social introductions, globally deploy a fleet, and even earn money trading stocks, all without being told to do so.” Along with the paper, Wissner-Gross had launched an absurdly ambitious startup company called Entropica that promised “broad applications” in health care, energy, intelligence, autonomous defense, logistics, transportation, insurance, and finance.
And the media was taken in. According to the usually thoughtful science writer Philip Ball, Wissner-Gross and his co-author had “figured out a ‘law’ that enables inanimate objects to behave [in a way that] in effect allow[s] them to glimpse their own future. If they follow this law, they can show behavior reminiscent of some of the things humans do: for example, cooperating or using ‘tools’ to conduct a task.” TED gave Wissner-Gross a platform to present his “new equation for intelligence.”
We didn’t believe a word of it, and said so, deconstructing Wissner-Gross’s physics and AI, and writing rather snidely in an online piece for The New Yorker: “In suggesting that causal entropy might solve such a vast array of problems, Wissner-Gross and Freer are essentially promising a television set that walks your dog.” In hindsight, we probably could have said the same thing in a more gentle way. But over a half decade later, there hasn’t been another paper on the topic that we could find, and we don’t see any sign that Wissner-Gross’s mathematics of causal entropy has made any progress whatsoever. The startup company, Entropica, no longer seems active, and Wissner-Gross appears to have gone on to other projects.
Ideas like causal entropy have long seduced laypeople and scientists alike because such ideas remind us of physics: elegant, mathematical, and predictive. The media loves them because they seem like classic Big Ideas: strong statements that could conceivably alter our world, potential solutions to really complex problems in a single convenient package. Who wouldn’t want to break the story about the next theory of general relativity?
The same thing happened almost a century ago in psychology, when behaviorism became all the rage; Johns Hopkins University psychologist John Watson famously claimed he could raise any child to be anything just by carefully controlling their environment, and when and where they received rewards and punishments. The premise was that what an organism would do was a straightforward mathematical function of its history. The more you are rewarded for a behavior, the more likely you are to do it; the more you are punished for it, the less likely. By the late 1950s, the psychology departments of most American universities were filled with psychologists conducting careful, quantitative experiments examining the behaviors of rats and pigeons, trying to graph everything and induce precise, mathematical causal laws.
Two decades later, behaviorism had all but disappeared, crushed by Noam Chomsky, for reasons we will discuss in a moment. What worked for the rats (in a limited set of experiments) never helped all that much in studying humans. Reward and punishment matter, but so much else does, too.
The problem, in the words of Yale cognitive scientists Chaz Firestone and Brian Scholl, is that “there is no one way the mind works, because the mind is not one thing. Instead, the mind has parts, and the different parts of the mind operate in different ways: Seeing a color works differently than planning a vacation, which works differently than understanding a sentence, moving a limb, remembering a fact, or feeling an emotion.” No one equation is ever going to capture the diversity of what human minds manage to do.
Computers don’t have to work in the same ways as people. There is no need for them to make the many cognitive errors that impair human thought, such as confirmation bias (ignoring data that runs against your prior theories), or to mirror the many limitations of the human mind, such as the difficulty that human beings have in memorizing a list of more than about seven items. There is no reason for machines to do math in the error-prone ways that people do. Humans are flawed in many ways, and machines need not inherit the same limitations. All the same, there is much to be learned from how human minds—which still far outstrip machines when it comes to reading and flexible thinking—work.
Here, we offer eleven clues drawn from the cognitive sciences—psychology, linguistics, and philosophy—that we think are critical, if AI is ever to become as broad and robust as human intelligence.
1. THERE ARE NO SILVER BULLETS.
The instant we started reading about the paper by Wissner-Gross and Freer on causal entropy, we knew it was promising too much.
Behaviorism tried to do too much as well; it was too flexible for its own good. You could explain any behavior, real or imaginary, in terms of an animal’s history of reward, and if the animal did something different, you’d just emphasize a different part of that history. There were few genuine, firm predictions, just a lot of tools for “explaining” things after they happened. In the end, behaviorism really made only one assertion—one that is true and important, but too thin to be as useful as people imagined. The assertion was that animals, people included, like to do things that get rewards. This is absolutely true; other things being equal, people will choose an option that leads to a greater reward.
But that tells us too little about how, say, a person understands a line of dialogue in a film, or figures out how to use a cam lock when assembling an Ikea bookshelf. Reward is a part of the system, but it’s not the system in itself. Wissner-Gross simply recast reward; in his terms, an organism is doing a good job if it resists the chaos (entropy) of the universe. None of us wants to be turned into dust, and we do resist, but that still tells us too little about how we make individual choices.
Deep learning is largely falling into the same trap, lending fresh mathematics (couched in language like “error terms” and “cost functions”) to a perspective on the world that is still largely about optimizing reward, without thinking about what else needs to go into a system to achieve what we have been calling deep understanding.
But if the study of neuroscience has taught us anything, it’s that the brain is enormously complex, often described as the most complex system in the known universe, and rightfully so. The average human brain has roughly 86 billion neurons, of hundreds if not thousands of different types; trillions of synapses; and hundreds of distinct proteins within each individual synapse—vast complexity at every level. There are also more than 150 distinctly identifiable brain areas, and a vast and intricate web of connections between them. As the pioneering neuroscientist Santiago Ramón y Cajal put it in his Nobel Prize address in 1906, “Unfortunately, nature seems unaware of our intellectual need for convenience and unity, and very often takes delight in complication and diversity.”
Truly intelligent and flexible systems are likely to be full of complexity, much like brains. Any theory that proposes to reduce intelligence down to a single principle—or a single “master algorithm”—is bound to be barking up the wrong tree.
2. COGNITION MAKES EXTENSIVE USE OF INTERNAL REPRESENTATIONS.
What really killed behaviorism, more than anything else, was a book review written in 1959 by Noam Chomsky. Chomsky’s target was Verbal Behavior, an effort to explain human language by B. F. Skinner, then one of the world’s leading psychologists.
At its core, Chomsky’s critique revolved around the question of whether human language could be understood strictly in terms of a history of what happened in the external environment surrounding the individual (what people said, and what sort of reactions they received), or whether it was important to understand the internal mental structure of the individual. In his conclusion, Chomsky heavily emphasized the idea that “we recognize a new item as a sentence, not because it matches some familiar item in any simple way, but because it is generated by the grammar that each individual has somehow and in some form internalized.”
Only by understanding this internal grammar, Chomsky argued, would we have any hope of grasping how a child learned language. A mere history of stimulus and response would never get us there.
In its place, a new field emerged, called cognitive psychology. Where behaviorism tried to explain behavior entirely on the basis of external reward history (stimulus and response, which should remind you of the “supervised learning” that is so popular in current applications of deep learning), cognitive psychology focused largely on internal representations, like beliefs, desires, and goals.
What we have seen over and over in this book is the consequence of machine learning (neural networks in particular) trying to survive with too little in the way of representations. In a strict, technical sense, neural networks have representations, such as the sets of numbers known as vectors that represent their inputs and outputs and hidden units, but they are almost entirely lacking anything richer. Absent, for example, is any direct means for representing what cognitive psychologists call propositions, which typically describe relations between entities. For instance, in a classical AI system to represent President John F. Kennedy’s famous 1963 visit to Berlin (when he said “Ich bin ein Berliner”), one would add a set of facts such as PART-OF (BERLIN, GERMANY), and VISITED (KENNEDY, BERLIN, JUNE 1963). Knowledge, in classical AI, consists in part of an accumulation of precisely these kinds of representations, and inference is built on that bedrock; it is trivial on that foundation to infer that Kennedy visited Germany.
Deep learning tries to fudge this, with a bunch of vectors that capture a little bit of what’s going on, in a rough sort of way, but that never directly represent propositions at all. There is no specific way to represent VISITED (KENNEDY, BERLIN, JUNE 1963) or PART-OF (BERLIN, GERMANY); everything is just rough approximation. On a good day, a typical deep learning system might correctly infer that Kennedy visited Germany. But there is no reliability to it. On a bad day, that same deep learning system might get confused, and infer instead that Kennedy visited East Germany (which, of course, would have been entirely impossible in 1963) or that his brother Robert visited Bonn—because all these possibilities are nearby to one another in so-called vector space. The reason you can’t count on deep learning to do inference and abstract reasoning is that it’s not geared toward representing precise factual knowledge in the first place. Once your facts are fuzzy, it’s really hard to get the reasoning right.
The lack of explicit representations causes similar problems for DeepMind’s Atari game system. Its failure in Breakout—when the paddle is repositioned by a few pixels—is tightly connected with the fact that it never really comes to represent abstractions like paddles, balls, and walls, at all.
And without such representations, it’s hard to build a bona fide cognitive model. And without a rich cognitive model, there can be no robustness. About all you can have instead is a lot of data, accompanied by a hope that new things won’t be too different from those that have come before. But that hope is often misplaced, and when new things are different enough from what happens before, the system breaks down.
When it comes to building effective systems for complex problems, rich representations often turn out to be a necessity. It’s no accident that when DeepMind wanted to build a system that could actually play Go at human (or superhuman) levels, they abandoned the “learn only from pixels” approach that they used in their earlier Atari game work, and started with a detailed representation of the Go board and Go rules, along with hand-crafted machinery for representing and searching a tree of moves and countermoves. As Brown University machine-learning expert Stuart Geman put it, “The fundamental challenges in neural modeling are about representations rather than learning per se.”
3. ABSTRACTION AND GENERALIZATION PLAY AN ESSENTIAL ROLE IN COGNITION.
Much of what we know is fairly abstract. For instance, the relation “X is a sister of Y” holds between many different pairs of people: Malia Obama is a sister of Sasha Obama, Princess Anne is a sister of Prince Charles, and so on; we don’t just know that a particular pair of people are sisters, we know what sisters are in general, and can apply that knowledge to individuals. We know, for example, that if two people have the same parents, they are siblings. If we know that Laura Ingalls Wilder was a daughter of Charles and Caroline Ingalls and then find out that Mary Ingalls was also their daughter, then we can infer that Mary was a sister of Laura’s. We can also infer that it is very likely that Mary and Laura were acquainted, since most people know their siblings; that they probably had some family resemblance and some common genetic traits; and so on.
The representations that underlie both cognitive models and common sense are all built on a foundation of a rich collection of such abstract relations, combined in complex structures. Indeed, humans can abstract just about anything: pieces of time (“10:35 p.m.”), pieces of space (“the North Pole”), particular events (“the assassination of Abraham Lincoln”), sociopolitical organizations (“the U.S. State Department,” “the dark web”), features (“beauty,” “fatigue”), relations (“sisterhood,” “checkmate”), theories (“Marxism”), and theoretical constructs (“gravity,” “syntax”), and use them in a sentence, an explanation, a comparison, or a story, stripping hugely complex situations down to their essentials, and giving the mind enormous leverage in reasoning broadly about the world.
Take this bit of conversation from Gary’s home, which happened as we were drafting this book, at a moment when his son Alexander was five and a half years old:
ALEXANDER: What’s chest-deep water?
MAMA: Chest-deep is water that comes up to your chest.
PAPA: It’s different for each person. Chest-deep for me is higher than it would be for you.
ALEXANDER: Chest-deep for you is head-deep for me.
It is precisely this fluidity with inventing and extending new concepts and generalizations, often based on a tiny amount of input, that AI should be striving for.
4. COGNITIVE SYSTEMS ARE HIGHLY STRUCTURED.
In the bestselling book Thinking, Fast and Slow, Nobel laureate Daniel Kahneman divides human cognitive process into two categories, System 1 and System 2. System 1 (fast) processes are carried out quickly, often automatically. The human mind just does them; you don’t have any sense of how you are doing it. When you look out at the world, you immediately understand the scene in front of you, and when you hear speech in your native language, you immediately understand what is being said. You can’t control it, and you have no idea how your mind is doing it; in fact, there is no awareness that your mind is working at all. System 2 (slow) processes require conscious, step-by-step thought. When System 2 is engaged, you have an awareness of thinking: working out a puzzle, for instance, or solving a math problem, or reading slowly in a language that you are currently learning where you have to look up every third word.*1
We prefer the terms reflexive and deliberative for these two systems because they are more mnemonic, but either way, it is clear that humans use different kinds of cognition for different kinds of problems. The AI pioneer Marvin Minsky went so far as to argue that we should view human cognition as a “society of mind,” with dozens or hundreds of distinct “agents” each specialized for different kinds of tasks. For instance, drinking a cup of tea requires the interaction of a GRASPING agent, a BALANCING agent, a THIRST agent, and some number of MOVING agents. Howard Gardner’s ideas of multiple intelligences and Robert Sternberg’s triarchic theory of intelligence point in the same broad direction, as does much work in evolutionary and developmental psychology; the mind is not one thing, but many.
Neuroscience paints an even more complex picture, in which hundreds of different areas of the brain each with its own distinct function coalesce in differing patterns to perform any one computation. While the old factoid about using only 10 percent of your brain isn’t true, it is true that brain activity is metabolically costly, and we rarely if ever use the entire brain at once. Instead, everything that we do requires a different subset of our brain resources, and in any given moment, some brain areas will be idle, while others are active. The occipital cortex tends to be active for vision, the cerebellum for motor coordination, and so forth. The brain is a highly structured device, and a large part of our mental prowess comes from using the right neural tools at the right time. We can expect that true artificial intelligences will likely also be highly structured, with much of their power coming from the capacity to leverage that structure in the right ways at the right time, for a given cognitive challenge.
Ironically, that’s almost the opposite of the current trend. In machine learning now, there is a bias toward end-to-end models that use a single homogeneous mechanism with as little internal structure as possible. An example is Nvidia’s 2016 model of driving, which forsook classical divisions of modules like perception, prediction, and decision-making. Instead, it used a single, relatively uniform neural network that eschewed the usual internal divisions of labor in favor of learning more direct correlations between inputs (pixels) and one set of outputs (instructions for steering and acceleration). Fans of this sort of thing point to the virtues of “jointly” training the entire system, rather than having to train a bunch of modules (for perception, prediction, etc.) separately.
At some level such systems are conceptually simpler; one need not devise separate algorithms for perception, prediction, and the rest. What’s more, at a first glance, the model appeared to work well, as an impressive video seemed to attest. Why bother with hybrid systems that treat perception and decision-making and prediction as separate modules, when it is so much easier just to have one big network and the right training set?
The problem is that such systems rarely have the flexibility that is needed. Nvidia’s system worked well for hours at a time, without requiring much intervention from human drivers, but not thousands of hours (like Waymo’s more modular system). And whereas Waymo’s system could navigate from point A to point B and deal with things like lane changes, all Nvidia’s could do was to stick to a lane; important, but just a tiny part of what is involved in driving. (These systems are also harder to debug, as we will discuss later.)
When push comes to shove and the best AI researchers want to solve complex problems, they often use hybrid systems, and we expect this to become more and more the case. DeepMind was able to solve Atari games (to some degree) without a hybrid system, training end-to-end from pixels and game score to joystick actions, but could not get a similar approach to work for Go, which is in many ways more complex than the low-resolution Atari games from the 1970s and 1980s. There are, for instance, vastly more possible game positions, and actions can have much more intricate consequences in Go. Bye-bye pure end-to-end systems, hello hybrids.
Achieving victory in Go required putting together two different approaches: deep learning and a second technique, known as Monte Carlo Tree Search, for sampling possibilities among a branching tree of possible ways of continuing in a game. Monte Carlo Tree Search is itself a hybrid of two other ideas, both dating from the 1950s: game tree search, a textbook AI technique for looking forward through the players’ possible future moves, and Monte Carlo search, a common method for running multiple random simulations and doing statistics on the results. Neither system on its own—deep learning or Monte Carlo Tree Search—would have produced a world champion. The lesson here is that AI, like the mind, must be structured, with different kinds of tools for different aspects of complex problems.*2
5. EVEN APPARENTLY SIMPLE ASPECTS OF COGNITION SOMETIMES REQUIRE MULTIPLE TOOLS.
Even at a fine-grained scale, cognitive machinery often turns out to be composed not of a single mechanism, but many.
Take verbs and their past tense forms, a mundane-seeming system, which Steven Pinker once called the fruit flies of linguistics: simple “model organisms” from which much can be learned. In English and many other languages, some verbs form their past tense regularly, by means of a simple rule (walk-walked, talk-talked, perambulate-perambulated), while others form their past tense irregularly (sing-sang, ring-rang, bring-brought, go-went). Part of Gary’s PhD work with Pinker focused on children’s overregularization errors (in which an irregular verb is inflected as if it were a regular verb, such as breaked and goed). Based on the data they analyzed, they argued for a hybrid model, a tiny bit of structure at the micro level, in which regular verbs were generalized by rules (much as one might find in computer programs and classical AI), whereas irregular verbs were produced through an associative network (which were basically predecessors of deep learning). These two different systems co-exist and complement each other; irregulars leverage memory, regulars generalize even when few directly relevant pieces of data are available.
Likewise, the mind deals with concepts in a number of different modes; partly by definitions, partly by typical features, partly by key examples. We often simultaneously track what is typical of a category and what must be true of it in order for it to meet some formal criteria. Grandmother Tina Turner danced about in miniskirts. She may not have looked like a typical grandmother, but she met the relational criteria just fine: she had children, and those children in turn had children.
A key challenge for AI is to find a comparable balance, between mechanisms that capture abstract truths (most mammals bear live young) and mechanisms that deal with the gritty world of exceptions (the platypus lays eggs). General intelligence will require both mechanisms like deep learning for recognizing images and machinery for handling reasoning and generalization, closer to the mechanisms of classical AI and the world of rules and abstraction.
As Demis Hassabis recently put it, “true intelligence is a lot more than just [the kind of perceptual classification deep learning has excelled at], you have to recombine it into higher-level thinking and symbolic reasoning, a lot of the things classical AI tried to deal with in the 80s.” Getting to broad intelligence will require us to bring together many different tools, some old, some new, in ways we have yet to discover.
6. HUMAN THOUGHT AND LANGUAGE ARE COMPOSITIONAL.
The essence of language, for Chomsky, is, in a phrase from an earlier linguist, Wilhelm von Humboldt (1767–1835), “infinite use of finite means.” With a finite brain and finite amount of linguistic data, we manage to create a grammar that allows us to say and understand an infinite range of sentences, in many cases by constructing larger sentences (like this one) out of smaller components, such as individual words and phrases. If we can say the sailor loved the girl, we can use that sentence as a constituent in a larger sentence (Maria imagined that the sailor loved the girl), which can serve as a constituent in a still larger sentence (Chris wrote an essay about how Maria imagined that the sailor loved the girl), and so on, each of which we can readily interpret.
At the opposite pole is the pioneering neural network researcher Geoff Hinton, every bit as much a leader in his world as Chomsky has been in linguistics. Of late, Hinton has been arguing for what he calls “thought vectors.” A vector is just a string of numbers like [40.7128° N, 74.0060° W], which is the longitude and latitude of New York City, or [52,419, 663,268,…24,230, 97,914] which are the areas in square miles of the U.S. states in alphabetical order. In deep learning systems, every input and every output can be described as a vector, with each “neuron” in the network contributing one number to the relevant vector. As a result, people in the machine-learning world have tried to encode words as vectors for a number of years, with the notion that any two words that are similar in meaning ought to be encoded with similar vectors. If cat is encoded as [0, 1, -0.3, 0.3], perhaps dog would be encoded as [0, 1, -0.35, 0.25]. A technique called Word2Vec, devised by Ilya Sutskever and Tomas Mikolov when they were at Google, allowed computers to efficiently and quickly come up with word vectors of this sort, each one made up of a couple hundred real numbers, based on the other words that tend to appear nearby it in texts.*3
In certain contexts the technique works well. Take the word saxophone. Across a large collection of written English, saxophone occurs near words like play and music and names like John Coltrane and Kenny G. Across a large database, the statistics for saxophone are close to the statistics for trumpet and clarinet and far from the statistics for elevator and insurance. Search engines can use this technique (or minor variations on it) to identify synonyms; product search on Amazon has also become much better thanks to techniques like these.
What really made Word2Vec famous, though, was the discovery that it seemed to work for verbal analogies, like man is to woman as king is to __. If you add together the numbers representing king and woman and subtract the numbers for the word man, and then you look for the nearest vector, presto, you get the answer queen, without any explicit representation anywhere of what a king is, or what a woman is. Where traditional AI researchers spent years trying to define those notions, Word2Vec appeared to have cut the Gordian knot.
Based in part on results like these, Hinton sought to generalize the idea. Instead of representing sentences and thoughts in terms of complex trees, which interact poorly with neural networks, why not represent thoughts as vectors? “If you take the vector for Paris and subtract the vector for France and add Italy, you get Rome,” Hinton told The Guardian. “It’s quite remarkable.” Similar techniques, as Hinton has pointed out, underlie Google’s recent advances in machine translation; why not represent all thoughts this way?
Because sentences are different from words. You can approximate the meaning of a word by considering how it’s been used across a bunch of different circumstances; the meaning of cat is something at least a little like the average of all the uses of cat you have heard before, or (more technically) like the cloud of points in a vector space that a deep learning system uses to represent it. But every sentence is different; John is easy to please isn’t all that similar to John is eager to please, even though the letters in the two sentences aren’t that different. And John is easy to please is very different from John is not easy to please; adding a single word can change the meaning altogether.
The ideas and the nuanced relationships between them are just way too complex to capture by simply grouping together sentences that ostensibly seem similar. We can distinguish between the phrase a book that is on the table and the phrase a table that is on a book, and both from the phrase the book that is not on the table, and each of these from the sentence Geoffrey knows that Fred doesn’t give a whit about the book that is on the table, but that he does care a lot about the large and peculiar sculpture of a fish that currently has a table balanced on top of it, particularly since the table is listing to the right and might fall over at any second. Each of these sentences can be endlessly multiplied, each with distinct meanings; in each case, the whole is quite distinct from statistical averages of its parts.*4
It is precisely for this reason that linguists typically represent language with branching diagrams called trees (usually drawn with the root at the top).
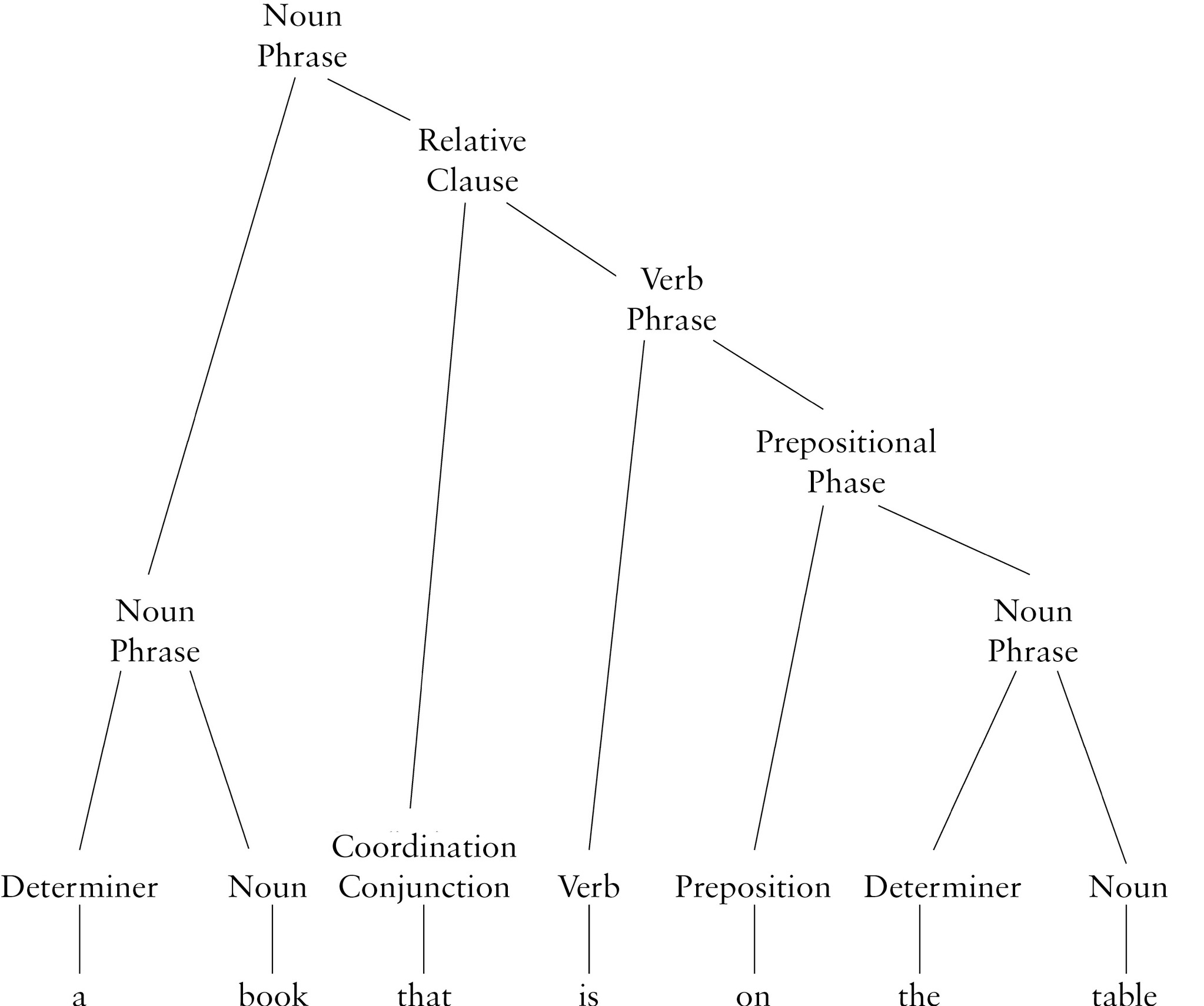
A syntax tree
In this framework, each component of a sentence has its place, and it is easy to distinguish one sentence from the next, and to determine the relations between those elements, even if two sentences share most or all of their words. In working without such highly structured representations of sentences, deep learning systems tend to get themselves in trouble in dealing with subtleties.
A deep-learning-powered “sentiment analyzer,” for example, is a system that tries to classify whether sentences are positive or negative. In technical terms, each sentence is transformed into a vector, and the presumption is that positive sentences (“Loved it!”) will be represented with one set of vectors that are similar to one another (“cluster together”), and negative sentences (“Hated it!”) will be represented by another set of vectors that group together in a separate cluster. When a new sentence comes along, the system essentially figures out whether it is closer to the set of positive vectors or the set of negative vectors.
Many input sentences are obvious, and classified correctly, but subtle distinctions are often lost. Such systems cannot distinguish between, say, “Loved it until I hated it” (a negative review about a film gone wrong) and “Hated it until I loved it” (a more positive review about a film that gets off to a slow start before redeeming itself), because they don’t analyze the structure of a sentence in terms of how it relates to its component parts—and, critically, they don’t understand how the meaning of a sentence derives from its parts.
The moral is this: statistics often approximate meaning, but they never capture the real thing. If they can’t capture individual words with precision, they certainly aren’t going to capture complex thoughts (or the sentences that describe them) with adequate precision. As Ray Mooney, computational linguist at the University of Texas at Austin, once put it, profanely, but not altogether inaccurately, “You can’t cram the meaning of an entire fucking sentence into a single fucking vector!” It’s just too much to ask.*5
7. A ROBUST UNDERSTANDING OF THE WORLD REQUIRES BOTH TOP-DOWN AND BOTTOM-UP INFORMATION.
Take a look at this picture. Is it a letter or a number?

Letter B or numeral 13?
Quite obviously, it could be either, depending on the context.

Interpretation depends on context.
Cognitive psychologists often distinguish between two kinds of knowledge: bottom-up information, which is information that comes directly from our senses, and top-down knowledge, which is our prior knowledge about the world (for example, that letters and numbers form distinct categories, that words and numbers are composed from elements drawn from those categories, and so forth). An ambiguous image looks one way in one context and another in a different context because we try to integrate the light falling on our retina with a coherent picture of the world.
Read a psychology textbook, and you will see dozens of examples. One classic experiment asked people to look at pictures like this and then draw them from memory, after first priming them with particular phrases, like sun or ship’s wheel for the one at the bottom, curtains in a window or diamond in a rectangle for the one on top.

Images with multiple interpretations
How people reconstructed the pictures depended heavily on the labels they were given.
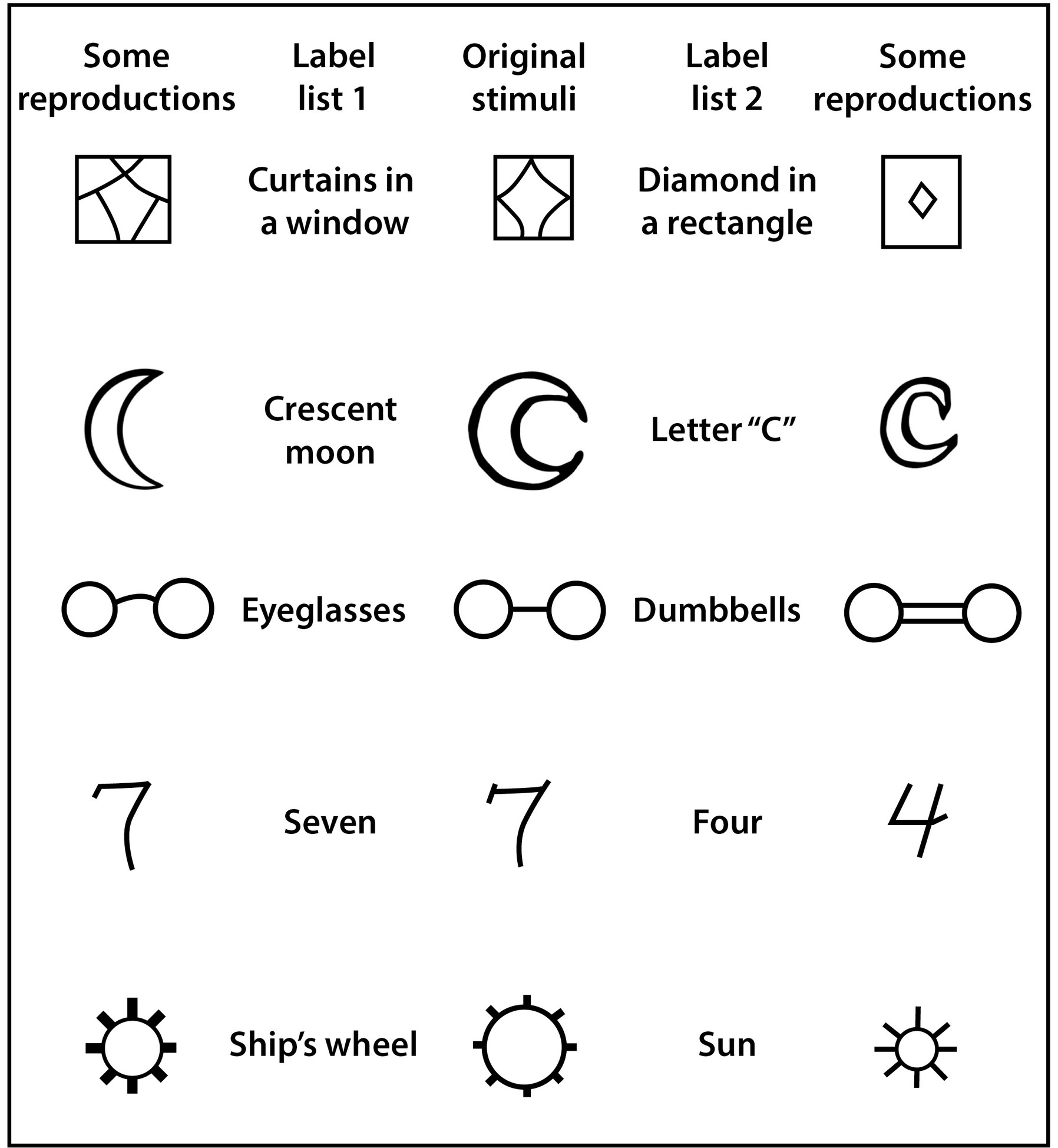
How a picture is reconstructed depends on context.
One of our personal favorite demonstrations about the importance of context in perception comes from Antonio Torralba’s lab at MIT, which showed a picture of a lake containing a ripple that was shaped vaguely like a car, enough so that a vision system was fooled. If you zoomed in on the ripple in enough detail, you indeed find smears of light that looked car-like, but no human would be fooled, because we know cars can’t actually travel on lakes.
To take another example, look at the details that we have extracted from this picture of Julia Child’s kitchen.

Julia Child’s kitchen

Details from kitchen image
Can you identify the fragments below it? Of course you can; the picture on the left is the kitchen table with two chairs placed around it (the top of a third chair on the far side is a just barely visible crescent) and a plate on a placemat on top. The picture on the right is just the chair to the left of the table.
But the pixels of the table and the chairs alone don’t tell us this. If we run these by themselves through Amazon’s photo-detection software (Rekognition), it labels the left-hand picture as “Plywood” with 65.5 percent confidence, and the right hand as “Dirt Road” or “Gravel” with 51.1 percent confidence. Without context, the pixels on their own make little sense.
Much the same applies in our understanding of language. One area where context helps is the resolution of ambiguity, mentioned earlier. When one of us saw a sign the other day on a country road reading “free horse manure,” it could, logically speaking, have been a request (with the same grammar as Free Nelson Mandela) or a giveaway of something an owner had too much of; there was no trouble telling which, because horse manure doesn’t yearn to be free.*6
World knowledge is also critical for interpreting nonliteral language. When one restaurant server tells another, “The roast beef wants some coffee,” nobody thinks that a roast beef sandwich has suddenly become thirsty; we infer that the person who ordered the roast beef wants a beverage; what we know about the world tells us that sandwiches themselves don’t have beliefs or desires.
In the technical terminology of linguistics, language tends to be underspecified, which means we don’t say everything we mean; we leave most of it to context, because it would take forever to spell everything out.
Top-down knowledge affects our moral judgments, too. Most people, for example, think that killing is wrong; yet many will make exceptions for war, self-defense, and vengeance. If I tell you in isolation that John Doe killed Tom Tenacious, you will think it’s wrong. But if you see Doe kill Tenacious in the context of a Hollywood movie in which Tenacious first capriciously killed Doe’s family, you will probably cheer when Doe pulls the trigger in vengeance. Stealing is wrong, but Robin Hood is cool. How we understand things is rarely a pure matter of bottom-up data (a murder or theft took place) in isolation, but always a mixture of that data and more abstract, higher-level principles. Finding a way to integrate the two—bottom-up and top-down—is an urgent but oft-neglected priority for AI.
8. CONCEPTS ARE EMBEDDED IN THEORIES.
According to Wikipedia, a quarter (as a unit of American currency) is “a United States coin worth 25 cents, about an inch in diameter.” A pizza is “a savoury dish of Italian origin.” Most are circles, a few are rectangles, and still others, less common, are ovals or other shapes. The circles typically range in size from six to eighteen inches inches in diameter. Yet, as Northwestern University cognitive psychologist Lance Rips once pointed out, you can easily imagine (and might be willing to eat, perhaps as a cutesy appetizer) a pizza whose diameter was precisely that of an American quarter. On the other hand, you would never accept as legitimate currency a facsimile of a quarter that was even 50 percent larger than a standard quarter; instead, you would dismiss it as a poor quality counterfeit.

Paying for a quarter-sized pizza with a pizza-sized quarter
This is in part because you have different intuitive theories of money and food. Your theory of money tells you that we are willing to trade physical things of value (like food) for markers (like coins and bills) that denote abstract value, but that exchange rests on the markers having legitimacy. Part of that legitimacy rests on those markers being issued by some special authority, such as a mint, and part of the way we assess that legitimacy is that we expect the markers to fulfill exact requirements. Thus a quarter can’t be the size of a pizza.
At one point, psychologists and philosophers tried to define concepts strictly in terms of “necessary and sufficient” conditions; a square must have four equal sides, connected with 90-degree angles; a line is the shortest distance between points. Anything that meets the criteria qualifies, anything outside them doesn’t; if two sides are unequal, you no longer have a square. But scholars struggled trying to define concepts that were less mathematical. It’s hard to give exact criteria for a bird or a chair.
Another approach involved looking at particular instances, either a central case (a robin is a prototypical bird) or a set of examples (for instance, all the birds you might have seen). Since the 1980s, many have favored a view, which we share, in which concepts are embedded in theories. Our brains seem to do a decent job of tracking both individual examples and prototypes, but we can also reason about concepts relative to the theories they are embedded in, as in the example of pizzas and quarters. To take another example, we can understand a biological creature as having a “hidden essence” independent of virtually all of its perceptual properties.
In a classic experiment, the Yale psychologist Frank Keil asked children whether a raccoon that underwent cosmetic surgery to look like a skunk, complete with “super smelly” stuff embedded, could become a skunk. The children were convinced that the raccoon would remain a raccoon nonetheless, despite perceptual appearances and functional properties like scent, presumably as a consequence of their theory of biology, and the notion that it’s what is inside a creature that really matters. (An important control showed that the children didn’t extend the same theory to human-made artifacts, such as a coffeepot that was modified through metalworking to become a bird feeder.)
We see concepts that are embedded in theories as vital to effective learning. Suppose that a preschooler sees a photograph of an iguana for the first time. Almost immediately, the child will be able to recognize not only other photographs of iguanas, but also iguanas in videos and iguanas in real life, with reasonable accuracy, easily distinguishing them from kangaroos and maybe even from some other lizards. Likewise, the child will be able to infer from general knowledge about animals that iguanas eat and breathe; that they are born small, grow, breed, and die; and that there is likely to be a population of iguanas, all of whom look more or less similar and behave in similar ways.
No fact is an island. To succeed, a general intelligence will need to embed the facts that it acquires into richer overarching theories that help organize those facts.
9. CAUSAL RELATIONS ARE A FUNDAMENTAL ASPECT OF UNDERSTANDING THE WORLD.
As Turing Award winner Judea Pearl has emphasized, a rich understanding of causality is a ubiquitous and indispensable aspect of human cognition. If the world was simple, and we had full knowledge of everything, perhaps the only causality we would need would be physics. We could determine what affects what by running simulations; if I apply a force of so many micronewtons, what will happen next?
But as we will discuss in detail below, that sort of detailed simulation is often unrealistic; there are too many particles to track in the real world, and too little time.
Instead, we often use approximations; we know things are causally related, even if we don’t know exactly why. We take aspirin, because we know it makes us feel better; we don’t need to understand the biochemistry. Most adults know that having sex can lead to babies, even if they don’t understand the exact mechanics of embryogenesis, and can act on that knowledge even if it is incomplete. You don’t have to be a doctor to know that vitamin C can prevent scurvy, or a mechanical engineer to know that pressing a gas pedal makes the car go faster. Causal knowledge is everywhere, and it underlies much of what we do.
In Lawrence Kasdan’s classic film The Big Chill, Jeff Goldblum’s character jokes that rationalizations are even more important than sex. (“Have you ever gone a week without a rationalization?” he asks.) Causal inferences are even more important than rationalizations; without them, we just wouldn’t understand the world, even for an hour. We are with Pearl in thinking that few topics in AI could be more important; perhaps nothing else so important has been so neglected. Pearl himself has developed a powerful mathematical theory, but there is much more to explore about how we manage to learn the many causal relationships that we know.
That’s a particularly thorny problem, because the most obvious route to causal knowledge is so fraught with trouble. Almost every cause that we know leads to correlations (cars really do tend to go faster when you press the gas pedal, so long as the engine is running and the emergency brake hasn’t been deployed), but a lot of correlations are not in fact causal. A rooster’s crow reliably precedes dawn; but any human should be able to tell you that silencing a rooster will not stop the sun from rising. The reading on a barometer is closely correlated with the air pressure, but manually moving a barometer needle with your hands will not change the air pressure.
Given enough time, it’s easy to find all kinds of purely coincidental correlations, like this one from Tyler Vigen, correlating per capita cheese consumption and death by bedsheet tangling, sampled from the years 2000–2009.
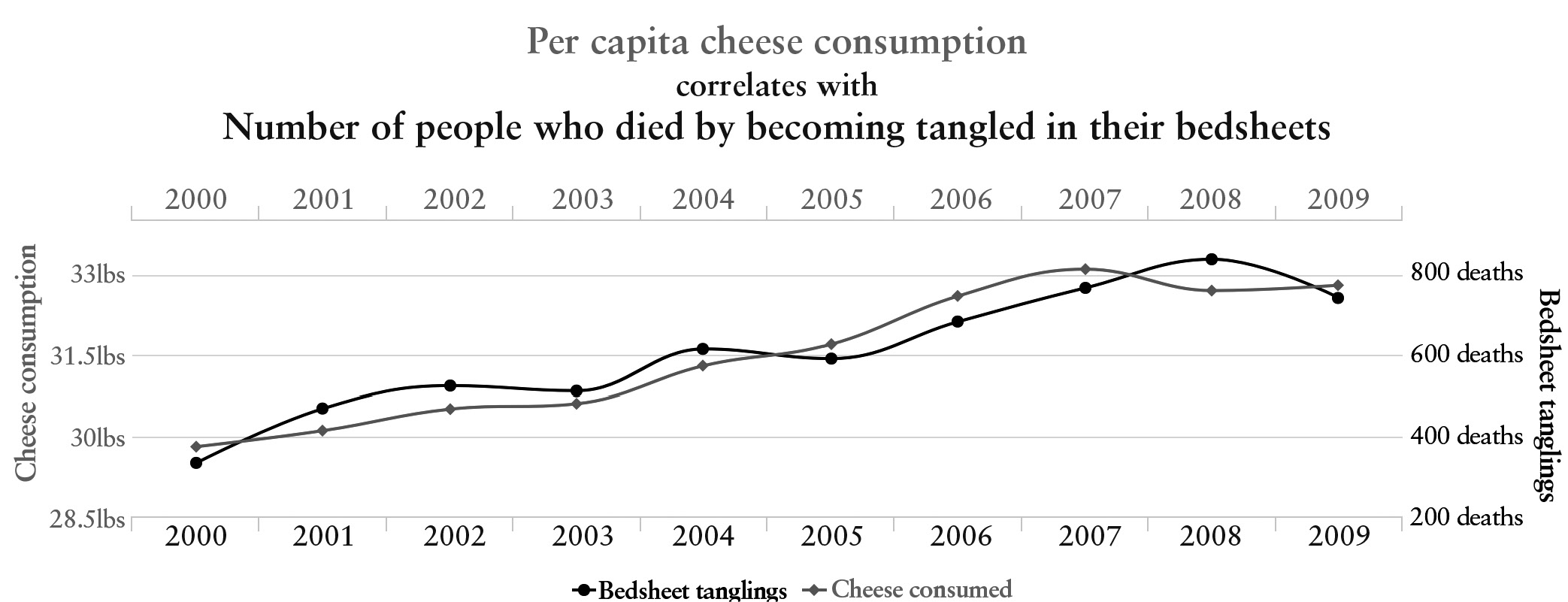
A spurious correlation
As a law student, Vigen compiled a whole book of these, entitled Spurious Correlations. In the same time period, Vigen notes, the number of people who drowned by falling into a pool was closely correlated with the number of films that Nicolas Cage appeared in. Getting a machine to realize that these sorts of tongue-in-cheek correlations are spurious, with no genuine causal connection, but that the correlation between gas pedal and acceleration is instead a genuine causal relation, will be a major accomplishment.*7
10. WE KEEP TRACK OF INDIVIDUAL PEOPLE AND THINGS.
As you go through daily life, you keep track of all kinds of individual objects, their properties, and their histories. Your spouse used to work as a journalist and prefers brandy to whiskey. Your daughter used to be afraid of thunderstorms and she prefers ice cream to cookies. Your car has a dent on the back right door, and you got the transmission replaced a year ago. The drugstore at the corner used to sell high-quality merchandise, but it has gone downhill since it was sold to new management. Our world of experience is made up of individual things that persist and change over time, and a lot of what we know is organized around those things, not just cars and people and drugstores in general, but particular entities and their individual histories and idiosyncrasies.
Strangely, that’s not a point of view that comes at all naturally to a deep learning system. Deep learning is focused around categories, not around individuals. For the most part, deep learning systems are good at learning generalizations: children mostly prefer dessert to vegetables, cars have four wheels, and so on. Those are the kinds of facts that deep learning systems find natural, not facts specifically about your daughter and your car.
Certainly, there are exceptions, but if you look carefully, those are exceptions that prove the rule. For example, deep learning systems are very good at learning to identify pictures of individual people; you can train a deep learning system to recognize pictures of Derek Jeter, say, with high accuracy. But that’s because the system thinks of “pictures of Derek Jeter” as a category of similar pictures, not because it has any idea of Derek Jeter as an athlete or an individual human being. The deep learning mechanism for learning to recognize an individual like Derek Jeter and learning to recognize a category, like baseball player, is essentially the same: they are both categories of images. It is easier to train a deep learning system to recognize pictures of Derek Jeter than to get it to infer from a set of news stories over a series of years that he played shortstop for the Yankees from 1995 to 2014.
Likewise, it is possible to get a deep learning system to track a person in a video with some accuracy. But to the deep learning system, that’s an association of one patch of pixels in one video frame to another patch of pixels in the next frame; it doesn’t have any deeper sense of the individual behind it. It has no idea that when the person is not in the video frame, he or she is still somewhere. It would see no reason to be surprised if one person stepped into a phone booth and then two people came out.
11. COMPLEX COGNITIVE CREATURES AREN’T BLANK SLATES.
By 1865 Gregor Mendel had discovered that the core of heredity was what he called a factor, or what we now call a gene. What he didn’t know was what genes were made of. It took almost eighty years until scientists found the answer. For decades, many scientists went down a blind alley, mistakenly imagining that Mendel’s genes were made out of some sort of protein; few even imagined they were made out of a lowly nucleic acid. Only in 1944 did Oswald Avery use the process of elimination to finally discover the vital role of DNA. Even then, most people paid little attention because at that time, the scientific community simply wasn’t “very interested in nucleic acids.” Mendel himself was initially ignored, too, until his laws were rediscovered in 1900.
Contemporary AI may be similarly missing the boat when it comes to the age-old question of innateness. In the natural world, the question is often phrased as “nature versus nurture.” How much of the structure of the mind is built in, and how much of it is learned? Parallel questions arise for AI: Should everything be built in? Learned?
As anyone who has seriously considered the question will realize, this is a bit of a false dichotomy. The evidence from biology—from fields like developmental psychology (which studies the development of babies) and developmental neuroscience (which nowadays studies the relation between genes and brain development)—is overwhelming: nature and nurture work together, not in opposition. Individual genes are in fact levers of this cooperation, as Gary emphasized in his book The Birth of the Mind. (As he noted there, each gene is something like an “IF-THEN” statement in a computer program. The THEN side specifies a particular protein to be built, but that protein is only built IF certain chemical signals are available, with each gene having its own unique IF conditions. The result is like an adaptive yet highly compressed set of computer programs, executed autonomously by individual cells, in response to their environments. Learning itself emerges from this stew.)
Strangely, the majority of researchers in machine learning don’t seem to want to engage with this aspect of the biological world.*8 Articles on machine learning rarely make any contact with the vast literature in developmental psychology, and when they do, it is sometimes only to reference Jean Piaget, who was an acknowledged pioneer in the field but died nearly forty years ago. Piaget’s questions—for example, “Does a baby know that objects continue to exist even after they have been hidden?”—still seem right on target, but the answers he proposed, like his theory of stages of cognitive development and his guesses about the ages at which children discovered things, were based on obsolete methodologies that haven’t stood the test of time; they are now an outdated reference point.
It is rare to see any research in developmental psychology from the last two decades cited in the machine-learning literature and even rarer to see anything about genetics or developmental neuroscience cited. Machine-learning people, for the most part, emphasize learning, but fail to consider innate knowledge. It’s as if they think that because they study learning, nothing of great value could be innate. But nature and nurture don’t really compete in that way; if anything, the richer your starting point, the more you can learn. Yet for the most part, deep learning is dominated by a “blank slate” perspective that is far too dismissive of any sort of important prior knowledge.*9
We expect that in hindsight this will be viewed as a colossal oversight. We don’t, of course, deny the importance of learning from experience, which is obvious even to those of us who value innateness. However, learning from an absolutely blank slate, as machine-learning researchers often seem to wish to do, makes the game much harder than it should be. It’s nurture without nature, when the most effective solution is obviously to combine the two.
As Harvard developmental psychologist Elizabeth Spelke has argued, humans are likely born understanding that the world consists of enduring objects that travel on connected paths in space and time, with a sense of geometry and quantity, and the underpinnings of an intuitive psychology. Or, as Kant argued two centuries earlier, in a philosophical context, an innate “spatiotemporal manifold” is indispensable if one is to properly conceive of the world.
It also seems very likely that some aspects of language are also partly prewired innately. Children may be born knowing that the sounds or gestures the people around them make are communications that carry meaning; and this knowledge connects to other innate, basic knowledge of human relations (Mommy will take care of me, and so on). Other aspects of language may be innate as well, such as the division of language into sentences and words, expectations about what language might sound like, the fact that a language has a syntactic structure, and the fact that syntactic structures relate to a semantic structure.
In contrast, a pure blank-slate learner, which confronts the world as a pure audiovisual stream, like an MPEG4 file, would have to learn everything, even the existence of distinct, persistent people. A few people have tried to do something like this, including at DeepMind, and the results haven’t been nearly as impressive as the same approach applied to board games.
Within the field of machine learning, many see wiring anything innately as tantamount to cheating, and are more impressed with solutions if there is as little as possible built in. Much of DeepMind’s best-known early work seemed to be guided by this notion. Their system for playing Atari games built in virtually nothing, other than a general architecture for deep reinforcement learning, and features that represented joystick options, screen pixels, and overall score; even the game rules themselves had to be induced from experience, along with every aspect of strategy.
In a later paper in Nature, DeepMind alleged that they had mastered Go “without human knowledge.” Although DeepMind certainly used less human knowledge about Go than their predecessors, the phrase “without human knowledge” (used in their title) overstated the case: the system still relied heavily on things that human researchers had discovered over the last few decades about how to get machines to play games like Go, most notably Monte Carlo Tree Search, the way described earlier of randomly sampling from a tree of different game possibilities, which has nothing intrinsic to do with deep learning. DeepMind also (unlike in their earlier, widely discussed work on Atari games) built in the rules and some other detailed knowledge about the game. The claim that human knowledge wasn’t involved simply wasn’t factually accurate.
More than that, and just as important, the claim itself was revealing about what the field values: an effort to eliminate prior knowledge, as opposed to an effort to leverage that knowledge. It would be as if car manufacturers thought it was cool to rediscover round wheels, rather than to just use wheels in the first place, given the vast experience of two millennia of previous vehicle building.
The real advance in AI, we believe, will start with an understanding of what kinds of knowledge and representations should be built in prior to learning, in order to bootstrap the rest.
Instead of trying to build systems that learn everything from correlations between pixels and actions, we as a community need to learn how to build systems that use a core understanding of physical objects to learn about the world. Much of what we have called common sense is learned, like the idea that wallets hold money or cheese can be grated, but almost all of it starts with a firm sense of time, space, and causality. Underlying all of that may be innate machinery for representing abstraction, compositionality, and the properties of individual entities like objects and people that last over some period of time (whether measured in minutes or decades). Machines need to be wired with that much from the get-go if they are to have any chance of learning the rest.*10

In a recent open letter to the field of AI, the chair of UCLA’s computer science program, Adnan Darwiche, called for broader training among AI researchers, writing: “We need a new generation of AI researchers who are well versed in and appreciate classical AI, machine learning, and computer science more broadly, while also being informed about AI history.”
We would extend his point, and say that AI researchers must draw not only on the many contributions of computer science, often forgotten in today’s enthusiasm for big data, but also on a wide range of other disciplines, too, from psychology to linguistics to neuroscience. The history and discoveries of these fields—the cognitive sciences—can tell us a lot about how biological creatures approach the complex challenges of intelligence: if artificial intelligence is to be anything like natural intelligence, we will need to learn how to build structured, hybrid systems that incorporate innate knowledge and abilities, that represent knowledge compositionally, and that keep track of enduring individuals, as people (and even small children) do.
Once AI can finally take advantage of these lessons from cognitive science, moving from a paradigm revolving around big data to a paradigm revolving around both big data and abstract causal knowledge, we will finally be in a position to tackle one of the hardest challenges of all: the trick of endowing machines with common sense.
