9
Critical Slowing and Perception
9.1 Introduction
It is generally assumed that criticality and metastability underwrite the brain's dynamic repertoire of responses to an inconstant world. From perception to behavior, the ability to respond sensitively to changes in the environment – and to explore alternative hypotheses and policies – seems inherently linked to self-organized criticality. This chapter addresses the relationship between perception and criticality – using recent advances in the theoretical neuroscience of perceptual inference. In short, we will see that (Bayes) optimal inference – on the causes of sensations – necessarily entails a form of criticality – critical slowing – and a balanced synchronization between the sensorium and neuronal dynamics. This means that the optimality principles describing our exchanges with the world may also account for dynamical phenomena that characterize self-organized systems such as the brain.
This chapter considers the formal basis of self-organized instabilities that enable perceptual transitions during Bayes-optimal perception. We will consider the perceptual transitions that lead to conscious ignition [1] and how they depend on dynamical instabilities that underlie chaotic itinerancy [2] [3] and self-organized criticality [4–6]. We will try to understand these transitions using a dynamical formulation of perception as approximate Bayesian inference. This formulation suggests that perception has an inherent tendency to induce dynamical instabilities that enable the brain to respond sensitively to sensory perturbations. We review the dynamics of perception, in terms of Bayesian optimization (filtering), present a formal conjecture about self-organized instability, and then test this conjecture, using neuronal simulations of perceptual categorization.
9.1.1 Perception and Neuronal Dynamics
Perceptual categorization speaks to two key dynamical phenomena: transitions from one perceptual state to another and the dynamical mechanisms that permit this transition. In terms of perceptual transitions, perception can be regarded as the selection of a single hypothesis from competing alternatives that could explain sensations [7]. This selection necessarily entails a change in the brain's representational or perceptual state – that may be unconscious in the sense of Helmholtz's unconscious inference or conscious. The implicit transition underlies much of empirical neuroscience (e.g., event-related potentials and brain activation studies) and has been invoked to understand how sensory information “goes beyond unconscious processing and gains access to conscious processing, a transition characterized by the existence of a reportable subjective experience” [1]. Dehaene and Changeux review converging neurophysiological data, acquired during conscious and unconscious processing, that speaks to the neural signatures of conscious access: late amplification of relevant sensory activity, long-distance cortico-cortical synchronization, and ignition of a large-scale prefrontoparietal network. The notion of ignition calls on several dynamical phenomena that characterize self-organization, such as distributed processing in coupled nonlinear systems, phase transitions, and metastability: see also [8]. In what follows, we ask whether the underlying dynamical mechanisms that lead to perceptual transitions and consequent ignition can be derived from basic principles; and, if so, what does this tell us about the self-organized brain.
9.1.2 Overview
We focus on a rather elementary form of self-organized criticality; namely, the self-destruction of stable dynamics during (Bayes-optimal) perception. In brief, if neuronal activity represents the causes of sensory input, then it should represent uncertainty about those causes in a way that precludes overly confident representations. This means that neuronal responses to stimuli should retain an optimal degree of instability that allows them to explore alternative hypotheses about the causes of those stimuli. To formalize this intuition, we consider neuronal dynamics as performing Bayesian inference about the causes of sensations, using a gradient descent on a (variational free energy) bound on the surprise induced by sensory input. This allows us to examine the stability of this descent in terms of Lyapunov exponents and how local Lyapunov exponents should behave. We see that the very nature of free energy minimization produces local Lyapunov exponents that fluctuate around small (near-zero) values. In other words, Bayes-optimal perception has an inherent tendency to promote critical slowing, which may be necessary for perceptual transitions and consequent categorization.
This chapter comprises five sections. The first section reviews the mechanisms that lead to itinerant and critical dynamics, noting that they all rest upon some form of dynamical instability – that can be quantified in terms of local Lyapunov exponents. The next section then turns to Bayes-optimal inference in the setting of free energy minimization to establish the basic imperatives for neuronal activity. In the third section, we look at neuronal implementations of free energy minimization, in terms of predictive coding, and how this relates to the anatomy and physiology of message passing in the brain. In the fourth section, we consider the dynamics of predictive coding in terms of generalized synchronization and the Lyapunov exponents of the first section. This section establishes a conjecture that predictive coding will necessarily show self-organized instability. The conjecture is addressed numerically using neuronal simulations of perceptual categorization in the final section. We conclude with a brief discussion of self-organization, over different scales, in relation to the optimality principles on which this approach is based.
9.2 Itinerant Dynamics
One ubiquitous (and paradoxical) feature of self-organizing and autopoietic systems [9] is their predisposition to destroy their own fixed points. We have referred to this as autovitiation to emphasize the crucial role that self-induced instabilities play in maintaining peripatetic or itinerant (wandering) dynamics [10] [11]. The importance of itinerancy has been articulated many times in the past [12], particularly from the perspective of computation and autonomy [13]. Itinerancy provides a link between exploration and foraging in ethology [14] and dynamical systems theory approaches to the brain [15] that emphasize the importance of chaotic itinerancy [2] and self-organized criticality [6] [16, 4]. Itinerant dynamics also arise from metastability [17] and underlie important phenomena such as winnerless competition [18].
The vitiation of fixed points or attractors is a mechanism that appears in several guises and has found important applications in a number of domains. For example, it is closely related to the notion of autopoiesis and self-organization in situated (embodied) cognition [9]. It is formally related to the destruction of gradients in synergetic treatments of intentionality [19]. Mathematically, it finds a powerful application in universal optimization schemes [20] and, indeed, as a model of perceptual categorization [21]. In what follows, we briefly review the scenarios that give rise to itinerant dynamics: namely, chaotic itinerancy, heteroclinic cycling, and multistable switching.
9.2.1 Chaotic Itinerancy
Chaotic itinerancy refers to the behavior of complicated (usually coupled nonlinear) systems that possess weakly attracting sets – Milnor attractors – with basins of attraction that are very close to each other. Their proximity destabilizes the Milnor attractors to create attractor ruins, which allow the system to leave one attractor and explore another, even in the absence of noise. A Milnor attractor is a chaotic attractor onto which the system settles from a set of initial conditions with positive measure (volume). However, another set of initial conditions (also with positive measure) that belong to the basin of another attractor can be infinitely close; this is called attractor riddling. Itinerant orbits typically arise from unstable periodic orbits that connect to another attractor, or just wander out into state space and then back onto the attractor, giving rise to bubbling. This is a classic scenario for intermittency – in which the dynamics are characterized by long periods of orderly behavior – as the system approaches a Milnor attractor – followed by brief turbulent phases, when the system approaches an unstable orbit. If the number of orbits is large, then this can happen indefinitely, because the Milnor attractor is ergodic. Ergodicity is an important concept and is also a key element of the free energy principle we will call upon later. The term ergodic is used to describe a dynamical system that has the same behavior averaged over time as averaged over its states. The celebrated ergodic theorem is credited to Birkhoff [22], and concerns the behavior of systems that have been evolving for a long time: intuitively, an ergodic system forgets its initial states, such that the probability a system is found in any state becomes – for almost every state – the proportion of time that state is occupied. See [23] for further discussion and illustrations. See [24] for discussion of chaotic itinerancy and power law residence times in attractor ruins.
The notion of Milnor attractors underlies much of the technical and cognitive literature on itinerant dynamics. For example, one can explain “a range of phenomena in biological vision, such as mental rotation, visual search, and the presence of multiple time scales in adaptation” using the concept of weakly attracting sets [21]. The common theme here is the induction of itinerancy through the destabilization of attracting sets or the gradients causing them [19]. The ensuing attractor ruins or relics [25] provide a framework for heteroclinic orbits that are ubiquitous in electrophysiology [26], cognition [27], and large-scale neuronal dynamics [28].
9.2.2 Heteroclinic Cycling
In heteroclinic cycling there are no attractors, not even Milnor ones – only saddles connected one to the other by heteroclinic orbits. A saddle is a point (invariant set) that has both attracting (stable) and repelling (unstable) manifolds. A heteroclinic cycle is a topological circle of saddles connected by heteroclinic orbits. If a heteroclinic cycle is asymptotically stable, the system spends longer and longer periods of time in a neighborhood of successive saddles; producing a peripatetic wandering through state space. The resulting heteroclinic cycles have been proposed as a metaphor for neuronal dynamics that underlie cognitive processing [18] and exhibit important behaviors such as winnerless competition, of the sort seen in central pattern generators in the motor system. Heteroclinic cycles have also been used as generative models in the perception of sequences with deep hierarchical structure [29]. Both chaotic itinerancy and heteroclinic cycling can arise from deterministic dynamics, in the absence of noise or random fluctuations. This contrasts with the final route to itinerancy that depends on noise.
9.2.3 Multistability and Switching
In multistability, there are typically a number of classical attractors – stronger than Milnor attractors in the sense that their basins of attraction not only have positive measure but are also open sets. Open sets are just sets of points that form a neighborhood: in other words, one can move a point in any direction without leaving the set – similar to the interior of a ball, as opposed to its surface. These attractors are not connected, but rather separated by a basin boundary. However, they are weak in the sense that the basins are shallow (but topologically simple). System noise can then drive the system from attractor one to another to produce a succession of distinct trajectories – this is called switching. Multistability underlies much of the work on attractor network models of perceptual decisions and categorization; for example, binocular rivalry [30].
Notice that noise is required for switching among multistable attractors; however, it is not a prerequisite for chaotic itinerancy or heteroclinic cycling. In chaotic itinerancy, the role of noise is determined by the geometry of the instabilities. In heteroclinic cycles, noise acts to settle the time it takes to go around the cycle onto some characteristic time scale. Without noise, the system will gradually slow as it gets closer and closer (but never onto) the cycle.
9.2.4 Itinerancy, Stability, and Critical Slowing
All three scenarios considered rest on a delicate balance between dynamical stability and instability: chaotic itinerancy requires weakly attracting sets that have unstable manifolds; heteroclinic cycles are based on saddles with unstable manifolds and switching requires classical attractors with shallow basins. So how can we quantify dynamical stability? In terms of linear stability analysis, dynamical instability requires the principal Lyapunov exponent – describing the local exponential divergence of flow – to be greater than zero. Generally, when a negative principal Lyapunov exponent approaches zero from below, the systems approach a phase transition and exhibit critical slowing.
Lyapunov exponents are based on a local linear approximation to flow and describe the rate of exponential decay of small fluctuations about the flow. As the Lyapunov exponents approach zero, these fluctuations decay more slowly. However, at some point very near the instability, the local linearization breaks down and higher order nonlinear terms from the Taylor series expansion dominate (or at least contribute). At this stage, the system's memory goes from an exponential form to a power law and the fluctuations no longer decay exponentially but can persist, inducing correlations over large distances and timescales [31]. For example, in the brain, long-range cortico-cortical synchronization may be evident over several centimeters and show slow fluctuations [32]. This phenomenon is probably best characterized in continuous phase transitions in statistical physics, where it is referred to as criticality. The possibility that critical regimes – in which local Lyapunov exponents fluctuate around zero – are themselves attracting sets leads to the notion of self-organized criticality [33].
In this chapter, critical slowing is taken to mean that one or more local Lyapunov exponents approach zero from below [34]. Note that critical slowing does not imply the dynamics per se are slow; it means that unstable modes of behavior decay slowly. Indeed, as the principal Lyapunov exponent approaches zero from below, the system can show fast turbulent flow as in intermittency. In what follows, we explore the notion that any self-organizing system that maintains a homeostatic and ergodic relationship with its environment will tend to show critical slowing. In fact, we conjecture that critical slowing is mandated by the very processes that underwrite ergodicity. In this sense, the existence of a self-organizing (ergodic) system implies that it will exhibit critical slowing. Put another way, self-organized critical slowing may be a necessary attribute of open ergodic systems.
In the context of self-organized neuronal activity, this leads to the conjecture that perceptual inference mandates critical slowing and is therefore associated with phase transitions and long-range correlations – of the sort that may correspond to the ignition phenomena considered in [1]. So what qualifies the brain as ergodic? Operationally, this simply means that the probability of finding the brain in a particular state is proportional to the number of times that state is visited. In turn, this implies that neuronal states are revisited over sufficiently long periods of time. This fundamental and general form of homeostasis is precisely what the free energy principle tries to explain.
9.3 The Free Energy Principle
This section establishes the nature of Bayes-optimal perception in the context of self-organized exchanges with the world. It may seem odd to consider, in such detail, a specific function as perception to understand generic behaviors such as critical slowing. However, to understand how the brain is coupled to the sensorium, we need to carefully distinguish between the hidden states of the world and internal states of the brain. Furthermore, we need to understand the basic nature of this coupling to see how key dynamical phenomena might arise.
We start with the basic premise that underlies free energy minimization; namely, that self-organizing systems minimize the dispersion of their sensory (interoceptive and exteroceptive) states to ensure a homeostasis of their (internal and external) milieu [35]. In this section, we see how action and perception follow from this premise and the central role of minimizing free energy. This section develops the ideas in a rather compact and formal way. Readers who prefer a nonmathematical description could skip to the summary at the end of this section.
Notation and set up: We will use 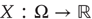 for real-valued random variables and
for real-valued random variables and 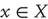 for particular values. A probability density will be denoted by
for particular values. A probability density will be denoted by 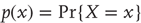 using the usual conventions and its entropy
using the usual conventions and its entropy 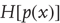 by
by 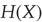 . The tilde notation
. The tilde notation 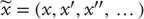 denotes variables in generalized coordinates of motion, using the LaGrange notation for temporal derivatives [36]. Finally,
denotes variables in generalized coordinates of motion, using the LaGrange notation for temporal derivatives [36]. Finally, 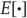 denotes an expectation or average. For simplicity, constant terms will be omitted.
denotes an expectation or average. For simplicity, constant terms will be omitted.
In what follows, we consider free energy minimization in terms of active inference: active inference rests on the tuple 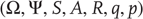 that comprises the following:
that comprises the following:
- • A sample space
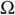 or nonempty set from which random fluctuations or outcomes
or nonempty set from which random fluctuations or outcomes 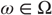 are drawn;
are drawn; - • Hidden states
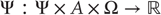 that constitute the dynamics of states of the world that cause sensory states and depend on action;
that constitute the dynamics of states of the world that cause sensory states and depend on action; - • Sensory states
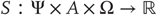 that correspond to the agent's sensations and constitute a probabilistic mapping from action and hidden states;
that correspond to the agent's sensations and constitute a probabilistic mapping from action and hidden states; - • Action
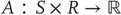 that corresponds to action emitted by an agent and depends on its sensory and internal states;
that corresponds to action emitted by an agent and depends on its sensory and internal states; - • Internal states
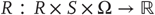 that constitute the dynamics of states of the agent that cause action and depend on sensory states;
that constitute the dynamics of states of the agent that cause action and depend on sensory states; - • Conditional density
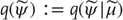 – an arbitrary probability density function over hidden states
– an arbitrary probability density function over hidden states 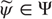 that is parameterized by internal states
that is parameterized by internal states 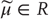 ;
; - • Generative density
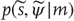 – a probability density function over external (sensory and hidden) states under a generative model denoted by
– a probability density function over external (sensory and hidden) states under a generative model denoted by 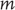 . This model specifies the Gibbs energy of any external states:
. This model specifies the Gibbs energy of any external states: 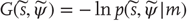 .
.
We assume that the imperative for any biological system is to minimize the dispersion of its sensory states, with respect to action: mathematically, this dispersion corresponds to the (Shannon) entropy of the probability density over sensory states. Under ergodic assumptions, this entropy is equal to the long-term time average of surprise (almost surely):
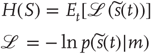
Surprise (or more formally surprisal or self-information) 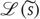 is defined by the generative density or model. This means that the entropy of sensory states can be minimized through action:
is defined by the generative density or model. This means that the entropy of sensory states can be minimized through action:
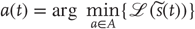
When Eq. (9.2) is satisfied, the variation of entropy in Eq. (9.1) with respect to action is zero, which means sensory entropy has been minimized (at least locally). From a statistical perspective, surprise is called negative log evidence, which means that minimizing surprise is the same as maximizing the Bayesian model evidence for the agent's generative model.
9.3.1 Action and Perception
Action cannot minimize sensory surprise directly (Eq. (9.2)) because this would involve an intractable marginalization over hidden states (an impossible averaging over all hidden states to obtain the probability density over sensory states) – so surprise is replaced with an upper bound called variational free energy [37]. This free energy is a functional of the conditional density or a function of the internal states that parameterize the conditional density. The conditional density is a key concept in inference and is a probabilistic representation of the unknown or hidden states. It is also referred to as the recognition density. Unlike surprise, free energy can be quantified because it depends only on sensory states and the internal states that parameterize the conditional density. However, replacing surprise with free energy means that internal states also have to minimize free energy, to ensure it is a tight bound on surprise:
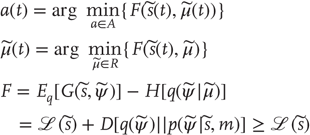
This induces a dual minimization with respect to action and the internal states. These minimizations correspond to action and perception, respectively. In brief, the need for perception is induced by introducing free energy to finesse the evaluation of surprise, where free energy can be evaluated by an agent fairly easily, given a Gibbs energy or generative model. Gibbs energy is just the surprise or improbability associated with a combination of sensory and hidden states. This provides a probabilistic specification of how sensory states are generated from hidden states. The last equality here says that free energy is always greater than surprise because the second (Kullback–Leibler divergence) term is nonnegative. This means that when free energy is minimized with respect to the internal states, free energy approximates surprise and the conditional density approximates the posterior density over hidden states:
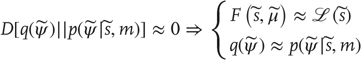
This is known as approximate Bayesian inference, which becomes exact when the conditional and posterior densities have the same form [38]. The only outstanding issue is the form of the conditional density adopted by an agent.
9.3.2 The Maximum Entropy Principle and the Laplace Assumption
If we admit an encoding of the conditional density up to second-order moments, then the maximum entropy principle [39] implicit in the definition of free energy (Eq. (9.3)) requires 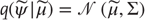 to be Gaussian. This is because a Gaussian density has the maximum entropy of all forms that can be specified with two moments. Assuming a Gaussian form is known as the Laplace assumption and enables us to express the entropy of the conditional density in terms of its first moment or expectation. This follows because we can minimize free energy with respect to the conditional covariance as follows:
to be Gaussian. This is because a Gaussian density has the maximum entropy of all forms that can be specified with two moments. Assuming a Gaussian form is known as the Laplace assumption and enables us to express the entropy of the conditional density in terms of its first moment or expectation. This follows because we can minimize free energy with respect to the conditional covariance as follows:
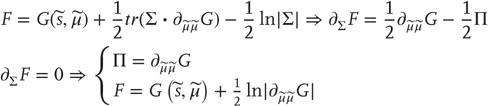
Here, the conditional precision 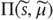 is the inverse of the conditional covariance
is the inverse of the conditional covariance 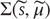 . In short, free energy is a function of the conditional expectations (internal states) and sensory states.
. In short, free energy is a function of the conditional expectations (internal states) and sensory states.
9.3.3 Summary
To recap, we started with the assumption that biological systems minimize the dispersion or entropy of sensory states to ensure a sustainable and homeostatic exchange with their environment [35]. Clearly, this entropy cannot be measured or changed directly. However, if agents know how their action changes sensations (e,g., if they know contracting certain muscle fibers will necessarily excite primary sensory afferents from stretch receptors), then they can minimize the dispersion of their sensory states by countering surprising deviations from their predictions. Minimizing surprise through action is not as straightforward as it might seem, because surprise per se is an intractable quantity to estimate. This is where free energy comes in – to provide an upper bound that enables agents to minimize free energy instead of surprise. However, in creating the upper bound, the agent now has to minimize the difference between surprise and free energy by changing its internal states. This corresponds to perception and makes the conditional density an approximation to the true posterior density in a Bayesian sense [7] [40–44]. See Figure 9.1 for a schematic summary. We now turn to neurobiological implementations of this scheme, with a special focus on hierarchical message passing in the brain and the associated neuronal dynamics.
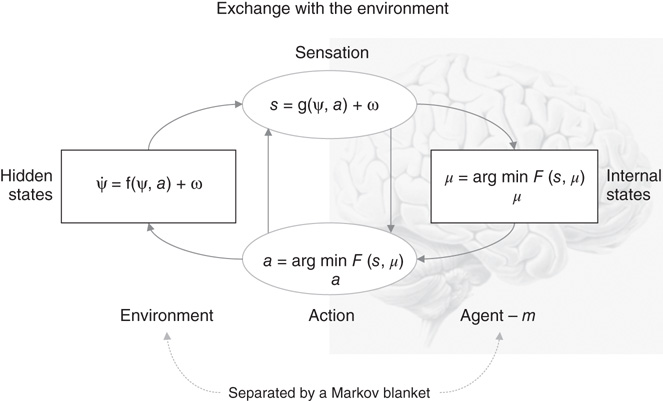
Figure 9.1 This schematic shows the dependencies among various quantities modeling exchanges of a self-organizing system such as the brain with the environment. It shows the states of the environment and the system in terms of a probabilistic dependency graph, where connections denote directed dependencies. The quantities are described within the nodes of this graph, with exemplar forms for their dependencies on other variables (see main text). Here, hidden and internal states are separated by action and sensory states. Both action and internal states encoding a conditional density minimize free energy. Note that hidden states in the real world and the form of their dynamics are different from that assumed by the generative model; this is why hidden states are in bold. See main text for details.
9.4 Neurobiological Implementation of Active Inference
In this section, we take the above-mentioned general principles and consider how they might be implemented in the brain. The equations in this section may appear a bit complicated; however, they are based on just three assumptions:
- The brain minimizes the free energy of sensory inputs defined by a generative model.
- The generative model used by the brain is hierarchical, nonlinear, and dynamic.
- Neuronal firing rates encode the expected state of the world, under this model.
The first assumption is the free energy principle, which leads to active inference in the embodied context of action. The second assumption is motivated easily by noting that the world is both dynamic and nonlinear and that hierarchical causal structure emerges inevitably from a separation of temporal scales [45] [46]. The final assumption is the Laplace assumption that, in terms of neural codes, leads to the Laplace code, which is arguably the simplest and most flexible of all neural codes [47].
Given these assumptions, one can simulate a whole variety of neuronal processes by specifying the particular equations that constitute the brain's generative model. The resulting perception and action are specified completely by these assumptions and can be implemented in a biologically plausible way as described subsequently (see Table 9.1 for a list of previous applications of this scheme). In brief, these simulations use differential equations that minimize the free energy of sensory input using a generalized gradient descent [48].
Table 9.1 Processes and paradigms that have been modeled using generalized filtering.
| Domain | Process or paradigm |
| Perception | Perceptual categorization (bird songs) [49]Novelty and omission-related responses [49]Perceptual inference (speech) [29] |
| Illusions | The Cornsweet illusion and Mach bands [50] |
| Sensory learning | Perceptual learning (mismatch negativity) [51] |
| Attention | Attention and the Posner paradigm [52]Attention and biased competition [52] |
| Motor control | Retinal stabilization and oculomotor reflexes [53]Orienting and cued reaching [53]Motor trajectories and place cells [54] |
| Sensorimotor integration | Bayes-optimal sensorimotor integration [53] |
| Visual search | Saccadic eye movements [55] |
| Behavior | Heuristics and dynamical systems theory [11]Goal-directed behavior [56] |
| Action observation | Action observation and mirror neurons [54] |
| Action selection | Affordance and sequential behavior [57] |
These coupled differential equations describe perception and action, respectively, and just say that internal brain states and action change in the direction that reduces free energy. The first is known as (generalized) predictive coding and has the same form as Bayesian (e.g., Kalman–Bucy) filters used in time series analysis; see also [58]. The first term in Eq. (9.6) is a prediction based on a matrix differential operator 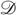 that returns the generalized motion of conditional expectations, such that
that returns the generalized motion of conditional expectations, such that 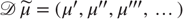 . The second term is usually expressed as a mixture of prediction errors that ensures the changes in conditional expectations are Bayes-optimal predictions about hidden states of the world. The second differential equation says that action also minimizes free energy. The differential equations are coupled because sensory input depends on action, which depends upon perception through the conditional expectations. This circular dependency leads to a sampling of sensory input that is both predicted and predictable, thereby minimizing free energy and surprise.
. The second term is usually expressed as a mixture of prediction errors that ensures the changes in conditional expectations are Bayes-optimal predictions about hidden states of the world. The second differential equation says that action also minimizes free energy. The differential equations are coupled because sensory input depends on action, which depends upon perception through the conditional expectations. This circular dependency leads to a sampling of sensory input that is both predicted and predictable, thereby minimizing free energy and surprise.
To perform neuronal simulations using this generalized descent, it is only necessary to integrate or solve Eq. (9.6) to simulate neuronal dynamics that encode the conditional expectations and ensuing action. Conditional expectations depend on the brain's generative model of the world, which we assume has the following (hierarchical) form
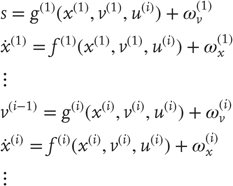
This equation is just a way of writing down a model that specifies the generative density over the sensory and hidden states, where the hidden states 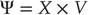 have been divided into hidden dynamic states and causes. Here,
have been divided into hidden dynamic states and causes. Here, 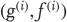 are nonlinear functions of hidden states that generate sensory inputs at the first (lowest) level, where for notational convenience,
are nonlinear functions of hidden states that generate sensory inputs at the first (lowest) level, where for notational convenience, 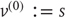 .
.
Hidden causes 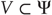 can be regarded as functions of hidden dynamic states; hereafter, hidden states
can be regarded as functions of hidden dynamic states; hereafter, hidden states 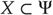 . Random fluctuations
. Random fluctuations 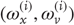 on the motion of hidden states and causes are conditionally independent and enter each level of the hierarchy. It is these that make the model probabilistic – they play the role of sensory noise at the first level and induce uncertainty about states at higher levels. The (inverse) amplitudes of these random fluctuations are quantified by their precisions
on the motion of hidden states and causes are conditionally independent and enter each level of the hierarchy. It is these that make the model probabilistic – they play the role of sensory noise at the first level and induce uncertainty about states at higher levels. The (inverse) amplitudes of these random fluctuations are quantified by their precisions 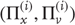 , which we assume to be fixed in this chapter (but see Section 9.7). Hidden causes link hierarchical levels, whereas hidden states link dynamics over time. Hidden states and causes are abstract quantities that the brain uses to explain or predict sensations (similar to the motion of an object in the field of view). In hierarchical models of this sort, the output of one level acts as an input to the next. This input can produce complicated (generalized) convolutions with a deep (hierarchical) structure.
, which we assume to be fixed in this chapter (but see Section 9.7). Hidden causes link hierarchical levels, whereas hidden states link dynamics over time. Hidden states and causes are abstract quantities that the brain uses to explain or predict sensations (similar to the motion of an object in the field of view). In hierarchical models of this sort, the output of one level acts as an input to the next. This input can produce complicated (generalized) convolutions with a deep (hierarchical) structure.
9.4.1 Perception and Predictive Coding
Given the form of the generative model (Eq. (9.7)), we can now write down the differential equations (Eq. (9.6)) describing neuronal dynamics in terms of (precision-weighted) prediction errors on the hidden causes and states. These errors represent the difference between conditional expectations and predicted values, under the generative model (using  and omitting higher order terms):
and omitting higher order terms):
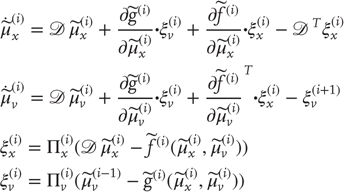
Equation (9.8) can be derived fairly easily by computing the free energy for the hierarchical model in Eq. (9.7) and inserting its gradients into Eq. (9.6). This gives a relatively simple update scheme, in which conditional expectations are driven by a mixture of prediction errors, where prediction errors are defined by the equations of the generative model.
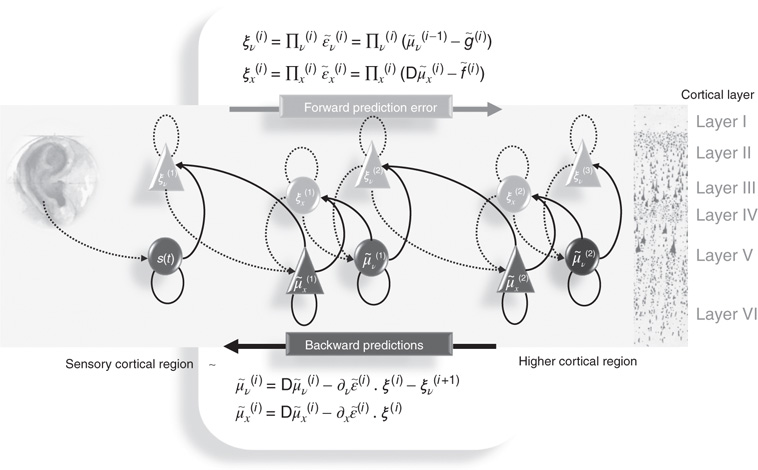
Figure 9.2 Schematic detailing a neuronal architecture that might encode conditional expectations about the states of a hierarchical model. This shows the speculative cells of origin of forward driving connections that convey prediction error from a lower area to a higher area and the backward connections that construct predictions [59]. These predictions try to explain away prediction error in lower levels. In this scheme, the sources of forward and backward connections are superficial and deep pyramidal cells respectively. The equations represent a generalized descent on free energy under the hierarchical model described in the main text: see also [36]. State units are in black and error units in gray. Here, neuronal populations are deployed hierarchically within three cortical areas (or macrocolumns). Within each area, the cells are shown in relation to cortical layers: supragranular (I–III), granular (IV), and infragranular (V–VI) layers.
It is difficult to overstate the generality and importance of Eq. (9.8): its solutions grandfather nearly every known statistical estimation scheme, under parametric assumptions about additive or multiplicative noise [36]. These range from ordinary least squares to advanced variational deconvolution schemes. The resulting scheme is called generalized filtering or predictive coding [48]. In neural network terms, Eq. (9.8) says that error units receive predictions from the same level and the level above. Conversely, conditional expectations (encoded by the activity of state units) are driven by prediction errors from the same level and the level below. These constitute bottom-up and lateral messages that drive conditional expectations toward a better prediction to reduce the prediction error in the level below. This is the essence of the recurrent message passing between hierarchical levels to optimize free energy or suppress prediction error (see [49] for a more detailed discussion). In neurobiological implementations of this scheme, the sources of bottom-up prediction errors, in the cortex, are thought to be superficial pyramidal cells that send forward connections to higher cortical areas. Conversely, predictions are conveyed from deep pyramidal cells, by backward connections, to target (polysynaptically) the superficial pyramidal cells encoding prediction error [59] [51]. Figure 9.2 provides a schematic of the proposed message passing among hierarchically deployed cortical areas. Although this chapter focuses on perception, for completeness we conclude this section by looking at the neurobiology of action.
9.4.2 Action
In active inference, conditional expectations elicit behavior by sending top-down predictions down the hierarchy that are unpacked into proprioceptive predictions at the level of the cranial nerve nuclei and spinal cord. These engage classical reflex arcs to suppress proprioceptive prediction errors and produce the predicted motor trajectory
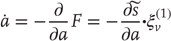
The reduction of action to classical reflexes follows because the only way that action can minimize free energy is to change sensory (proprioceptive) prediction errors by changing sensory signals; compare the equilibrium point formulation of motor control [60]. In short, active inference can be regarded as equipping a generalized predictive coding scheme with classical reflex arcs: see [53] [56] for details. The actual movements produced clearly depend on top-down predictions that can have a rich and complex structure, due to perceptual optimization based on the sampling of salient exteroceptive and interoceptive inputs.
9.4.3 Summary
In summary, we have derived equations for the dynamics of perception and action using a free energy formulation of adaptive (Bayes-optimal) exchanges with the world and a generative model that is both generic and biologically plausible. Intuitively, all we have done is to apply the principle of free energy minimization to a particular model of how sensory inputs are caused. This model is called a generative model because it can be used to generate sensory samples and thereby predict sensory inputs for any given set of hidden states. By requiring hidden states to minimize free energy, they become Bayes-optimal estimates of hidden states in the real world – because they implicitly maximize Bayesian model evidence. One simple scheme – that implements this minimization – is called predictive coding and emerges when random effects can be modeled as additive Gaussian fluctuations. Predictive coding provides a neurobiological plausible scheme for inferring states of the world that reduces, essentially, to minimizing prediction errors; namely, the difference between what is predicted – given the current estimates of hidden states – and the sensory inputs actually sampled.
In what follows, we use Eq. (9.6), Eq. (9.7), and Eq. (9.8) to treat neuronal responses in terms of predictive coding. A technical treatment of the above-mentioned material is found in [48], which provides the details of the generalized descent or filtering used to produce the simulations in the last section. Before looking at these simulations, we consider the nature of generalized filtering and highlight its curious but entirely sensible dynamical properties.
9.5 Self-Organized Instability
This section examines self-organization in the light of minimizing free energy. These arguments do not depend in any specific way on predictive coding or the neuronal implementation of free energy minimization – they apply to any self-organizing system that minimizes the entropy of the (sensory) states that drive its internal states; either exactly by minimizing (sensory) surprise or approximately by minimizing free energy. In what follows, we first look at the basic form of the dynamics implied by exposing a self-organizing system to sensory input in terms of skew product systems. A skew product system comprises two coupled systems, where the states of one system influence the flow of states in the other – in our case, hidden states in the world influence neuronal dynamics. These coupled systems invoke the notion of (generalized) synchronization as quantified by conditional Lyapunov exponents (CLEs). This is important because the dynamics of a generalized descent on free energy have some particular implications for the CLEs. These implications allow us to conjecture that the local Lyapunov exponents will fluctuate around small (near-zero) values, which is precisely the condition for chaotic itinerancy and critical slowing. By virtue of the fact that this critical slowing is self-organized, it represents an elementary form of self-organized criticality; namely, self-organized critical slowing. In the next section, we test this conjecture numerically with simulations of perception, using the predictive coding scheme of the previous section.
9.5.1 Conditional Lyapunov Exponents and Generalized Synchrony
CLEs are normally invoked to understand synchronization between two systems that are coupled, usually in a unidirectional manner, so that there is a drive (or master) system and a response (or slave) system. The conditional exponents are those of the response system, where the drive system is treated as a source of a (chaotic) drive. Synchronization of chaos is often understood as a behavior in which two coupled systems exhibit identical chaotic oscillations – referred to as identical synchronization [61] [62]. The notion of chaotic synchronization has been generalized for coupled nonidentical systems with unidirectional coupling or a skew product structure [63]:
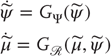
Crucially, if we ignore action, neuronal dynamics underlying perception have this skew product structure, where 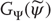 corresponds to the flow of hidden states and
corresponds to the flow of hidden states and 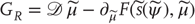 corresponds to the dynamical response. This is important because it means one can characterize the coupling of hidden states in the world to self-organized neuronal responses, in terms of generalized synchronization.
corresponds to the dynamical response. This is important because it means one can characterize the coupling of hidden states in the world to self-organized neuronal responses, in terms of generalized synchronization.
Generalized synchronization occurs if there exists a map 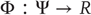 from the trajectories of the (random) attractor in the driving space to the trajectories of the response space, such that
from the trajectories of the (random) attractor in the driving space to the trajectories of the response space, such that 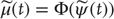 . Depending on the properties of the map
. Depending on the properties of the map 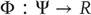 , generalized synchronization can be of two types: weak and strong. Weak synchronization is associated with a continuous
, generalized synchronization can be of two types: weak and strong. Weak synchronization is associated with a continuous 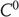 but nonsmooth map, where the synchronization manifold
but nonsmooth map, where the synchronization manifold 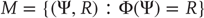 has a fractal structure and the dimension
has a fractal structure and the dimension 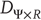 of the attractor in the full state space
of the attractor in the full state space 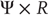 is larger than the dimension of the attractor
is larger than the dimension of the attractor 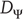 in the driving
in the driving 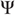 subspace – that is
subspace – that is 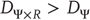 .
.
Strong synchronization implies a smooth map (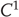 or higher) and arises when the response system does not inflate the global dimension,
or higher) and arises when the response system does not inflate the global dimension, 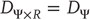 . This occurs with identical synchronization, which is a particular case
. This occurs with identical synchronization, which is a particular case 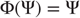 of strong synchronization. The global and driving dimensions can be estimated from the appropriate Lyapunov exponents
of strong synchronization. The global and driving dimensions can be estimated from the appropriate Lyapunov exponents 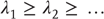 using the Kaplan–Yorke conjecture [64]
using the Kaplan–Yorke conjecture [64]
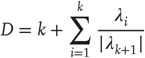
Here, 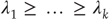 are the k largest exponents for which the sum is nonnegative. Strong synchronization requires the principal Lyapunov exponent of the response system (neuronal dynamics) to be less than the kth Lyapunov exponent of the driving system (the world), while weak synchronization just requires it to be <0.
are the k largest exponents for which the sum is nonnegative. Strong synchronization requires the principal Lyapunov exponent of the response system (neuronal dynamics) to be less than the kth Lyapunov exponent of the driving system (the world), while weak synchronization just requires it to be <0.
The Lyapunov exponents of a dynamical system characterize the rate of separation of infinitesimally close trajectories and provide a measure of contraction or expansion of the state space occupied. For our purposes, they can be considered as the eigenvalues of the Jacobian that describes the rate of change of flow, with respect to the states. The global Lyapunov exponents correspond to the long-term time average of local Lyapunov exponents evaluated on the attractor (the existence of this long-term average is guaranteed by Oseledets theorem). Lyapunov exponents also determine the stability or instability of the dynamics, where negative Lyapunov exponents guarantee Lyapunov stability (of the sort associated with fixed point attractors). Conversely, one or more positive Lyapunov exponents imply (local) instability and (global) chaos. Any (negative) Lyapunov exponent can also be interpreted as the rate of decay of the associated eigenfunction of states, usually referred to as (Oseledets) modes. This means as a (negative) Lyapunov exponent approaches zero from below, perturbations of the associated mode decay more slowly. We will return to this interpretation of Lyapunov exponents in the context of stability later. For skew product systems, the CLE correspond to the eigenvalues of the Jacobian 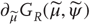 mapping small variations in the internal states to their motion.
mapping small variations in the internal states to their motion.
9.5.2 Critical Slowing and Conditional Lyapunov Exponents
This characterization of coupled dynamical systems means that we can consider the brain as being driven by sensory fluctuations from the environment. The resulting skew product system suggests that neuronal dynamics should show weak synchronization with the sensorium, which means that the maximal (principal) CLE should be <0. However, if neuronal dynamics are generating predictions, by modeling the causes of sensations, then these dynamics should themselves be chaotic – because the sensations are caused by itinerant dynamics in the world. So, how can generalized synchronization support chaotic dynamics when the principal CLE is negative?
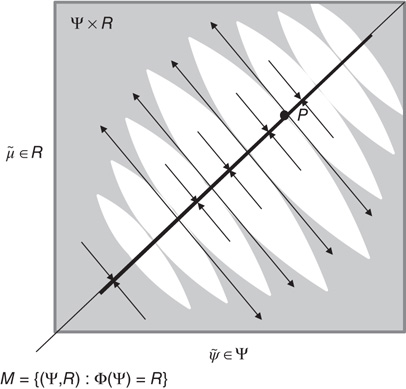
Figure 9.3 Schematic representation of synchronization manifold with weak transverse stability (Adapted from [3].): A Milnor attractor (dotted line) is contained with a synchronization manifold – here, an identity mapping. Unstable saddle points such as P are repelling in the transverse direction and create narrow tongues of repelling regions (gray regions). Other orbits are attracted toward the chaotic attractor contained within the synchronization manifold.
In skew product systems of the above-mentioned sort, it is useful to partition the Lyapunov exponents into those pertaining to tangential flow within the synchronization manifold and transverse flow away from the manifold [23]. In the full state space, the tangential Lyapunov exponents can be positive such that the motion on the synchronization manifold is chaotic, as in the driving system, while the transverse Lyapunov exponents are negative (or close to zero) so that the response system is weakly synchronized with the drive system. See Figure 9.3 for a schematic illustration of tangential and transverse stability. In short, negative transverse Lyapunov exponents ensure the synchronization manifold  is transversely stable or (equivalently), while negative CLEs ensure the synchronized manifold
is transversely stable or (equivalently), while negative CLEs ensure the synchronized manifold  is stable [63]. In the present setting, this means that the sensorium enslaves chaotic neuronal responses. See [3] for a treatment of chaotic itinerancy and generalized synchronization as the basis of olfactory perception: by studying networks of Milnor attractors, [3] shows how different sensory perturbations can evoke specific switches between various patterns of activity.
is stable [63]. In the present setting, this means that the sensorium enslaves chaotic neuronal responses. See [3] for a treatment of chaotic itinerancy and generalized synchronization as the basis of olfactory perception: by studying networks of Milnor attractors, [3] shows how different sensory perturbations can evoke specific switches between various patterns of activity.
Although generalized synchronization provides a compelling metaphor for perception, it also presents a paradox: if the CLE are negative and the synchronized manifold is stable, there is no opportunity for neuronal dynamics (conditional expectations) to jump to another attractor and explore alternative hypotheses. This dialectic is also seen in system identification, where the synchronization between an observed dynamical system and a model system is used to optimize model parameters by maximizing synchronization. However, if the coupling between the observations and the model is too strong, the variation of synchronization with respect to the parameters is too small to permit optimization. This leads to the notion of balanced synchronization that requires that the CLE “remain negative but small in magnitude” [65]. In other words, we want the synchronization between the causes of sensory input and neuronal representations to be strong but not too strong. Here, we resolve this general dialectic with the conjecture that Bayes-optimal synchronization is inherently balanced:
9.5.3 Summary
In summary, we have reviewed the central role of Lyapunov exponents in characterizing dynamics, particularly in the context of generalized (weak or strong) synchronization. This is relevant from the point of view of neuronal dynamics because we can cast neuronal responses to sensory drive as a skew product system, where generalized synchronization requires the CLE of the neuronal system to be negative. However, generalized synchronization is not a complete description of how external states entrain the internal states of self-organizing systems: entrainment rests upon minimizing free energy that, we conjecture, has an inherent instability. This instability or self-organized critical slowing is due to the fact that internal states with a low free energy are necessarily states with a low free energy curvature. Statistically, this ensures that conditional expectations maintain a conditional indifference or uncertainty that allows for a flexible and veridical representation of hidden states in the world. Dynamically, this low curvature ameliorates dissipation by reducing the (dissipative) update, relative to the (conservative) prediction. In other words, the particular dynamics associated with variational free energy minimization may have a built-in tendency to instability.
It should be noted that this conjecture deals only with dynamical (gradient descent) minimization of free energy. One could also argue that chaotic itinerancy may be necessary for exploring different conditional expectations to select the one with the smallest free energy. However, it is interesting to note that – even with a deterministic gradient descent – there are reasons to conjecture a tendency to instability. The sort of self-organized instability is closely related to, but is distinct from, chaotic itinerancy and classical self-organized criticality. Chaotic itinerancy deals with itinerant dynamics of deterministic systems that are reciprocally coupled to each other [2]. Here, we are dealing with systems with a skew product (master–slave) structure. However, it may be that both chaotic itinerancy and critical slowing share the same hallmark, namely, fluctuations of the local Lyapunov exponents around small (near-zero) values [66].
Classical self-organized criticality usually refers to the intermittent behavior of skew product systems in which the drive is constant. This contrasts with the current situation, where we consider the driving system (the environment) to show chaotic itinerancy. In self-organized criticality, one generally sees intermittency with characteristic power laws pertaining to macroscopic behaviors. It would be nice to have a general theory linking the organization of microscopic dynamics in terms of CLE to the macroscopic phenomena studied in self-organized criticality. However, work in this area is generally restricted to specific systems. For example, [67] discuss Lyapunov exponents in the setting of the Zhang model of self-organized criticality. They show that small CLE are associated with energy transport and derive bounds on the principal negative CLE in terms of the energy flux dissipated at the boundaries per unit of time. Using a finite-size scaling ansatz for the CLE spectrum, they then relate the scaling exponent to quantities such as avalanche size and duration. Whether generalized filtering permits such an analysis is an outstanding question. For the rest of this chapter, we focus on illustrating the more limited phenomena of self-organized critical slowing using simulations of perception.
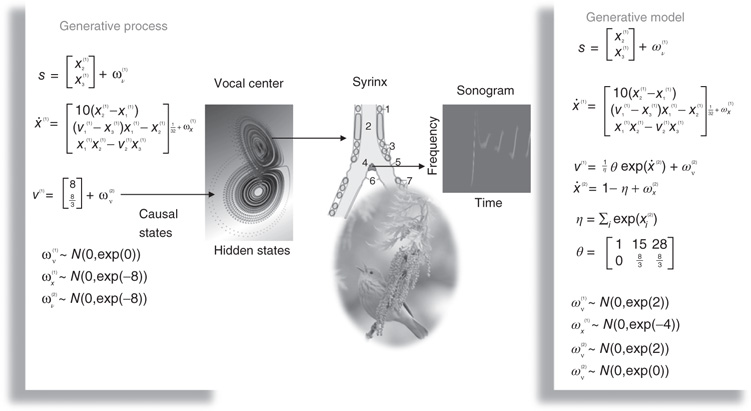
Figure 9.4 This is a schematic of stimulus generation and the generative model used for the simulations of bird song perception. In this setup, the higher vocal center of a song bird has been modeled with a Lorenz attractor from which two states have been borrowed, to modulate the amplitude and frequency of chirps by its voice box or syrinx. Crucially, the sequence of chirps produced in this way depends on the shape of the attractor, which is controlled by two hidden causes. This means that we can change the category of song by changing the two hidden causes. This provides a way of generating songs that can be mapped to a point in a two-dimensional perceptual space. The equations on the left describe the production of the stimulus, where the equations of motion for the hidden states correspond to the equations of motion with a Lorenz attractor. These hidden causes were changed smoothly after 32 (16 ms) time bins to transform the attractor from a fixed point attractor (silence) to a chaotic attractor (bird song). The resulting stimulus is shown in sonogram format with time along the x-axis and frequency over the y-axis. The equations on the right constitute the generative model. The generative model is equipped with hidden states at a higher (categorical) level that model the evolution of the hidden causes that determine the attractor manifold for the hidden (attractor) states at the first level. The function-generating hidden causes uses a softmax function of the hidden categorical states to select one of three hidden causes. The associated categories of songs correspond to silence, a quasiperiodic song, and a chaotic song. The amplitudes of the random fluctuations are determined by their variance or log precisions and are shown in the lower part of the figure. Using this setup, we can produce some fairly realistic chirps that can be presented to a synthetic bird to see if it can recover the hidden causes and implicitly categorize the song.
9.6 Birdsong, Attractors, and Critical Slowing
In this section, we illustrate perceptual ignition and critical slowing using neuronal simulations based on the predictive coding scheme of previous sections. Our purpose here is simply to illustrate self-organized instability using numerical simulations: these simulations should be regarded as a proof of principle but should not be taken to indicate that the emergent phenomena are universal or necessary for perceptual inference. In brief, we created sensory stimuli corresponding to bird songs, using a Lorenz attractor with variable control parameters (similar to the Raleigh number). A synthetic bird then heard the song and used a hierarchical generative model to infer the control parameters and thereby categorize the song. These simulations show how the stimulus induces critical slowing in terms of changes in the CLE of the perceptual dynamics. We then systematically changed the generative model by changing the precision of the motion on hidden states. By repeating the simulations, we could then examine the emergence of critical slowing (averaged over peristimulus time) in relation to changes in variational free energy and categorization performance. On the basis of the conjecture of the previous section, we anticipated that there will be a regime in which critical slowing was associated with minimum free energy and veridical categorization. In what follows, we describe the stimuli and generative model. We then describe perceptual categorization under optimal prior beliefs about precision and finally characterize the perceptual responses under different (suboptimal) priors.
9.6.1 A Synthetic Avian Brain
The example used here deals with the generation and recognition of bird songs [68] [69]. We imagine that bird songs are produced by two time-varying hidden causes that modulate the frequency and amplitude of vibrations of the syrinx of a song bird (Figure 9.4). There has been an extensive modeling effort using attractor models at the biomechanical level to understand the generation of birdsong [68]. Here, we use the attractors at a higher level to provide time-varying control over the resulting sonograms [29]. We drive the syrinx with two states of a Lorenz attractor, one controlling the frequency (between 2 and 5 kHz) and the other (after rectification) controlling the amplitude or volume. The parameters of the Lorenz attractor were chosen to generate a short sequence of chirps every second or so. These parameters correspond to hidden causes 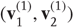 that were changed as a function of peristimulus time to switch the attractor into a chaotic state and generate stimuli. Note that these hidden causes have been written in boldface. This is to distinguish them from the hidden causes
that were changed as a function of peristimulus time to switch the attractor into a chaotic state and generate stimuli. Note that these hidden causes have been written in boldface. This is to distinguish them from the hidden causes 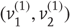 inferred by the bird hearing the stimuli.
inferred by the bird hearing the stimuli.
The generative model was equipped with prior beliefs that songs could come in one of three categories; corresponding to three distinct pairs of values for the hidden causes. This was modeled using three hidden states to model the Lorenz attractor dynamics at the first level and three hidden states to model the category of the song at the second level. The hidden causes linking the hidden states at the second level to the first were a weighted mixture of the three pairs of values corresponding to each category of song. The bird was predisposed to infer one and only one category by weighting the control values with a softmax function of the hidden states. This implements a winner-takes-all-like behavior and enables us to interpret the softmax function as a probability over the three song categories (softmax probability).
This model of an avian brain may seem a bit contrived or arbitrary; however, it was chosen as a minimal but fairly generic model for perception. It is generic because it has all the ingredients required for perceptual categorization. First, it is hierarchical and accommodates chaotic dynamics in the generation of sensory input. Here, this is modeled as a Lorenz attractor that is subject to small random fluctuations. Second, it has a form that permits categorization of stimuli that extend over (frequency) space and time. In other words, perception or model inversion maps a continuous, high-dimensional sensory trajectory onto a perceptual category or point in some perceptual space. This is implemented by associating each category with a hidden state that induces particular values of the hidden causes. Finally, there is a prior that induces competition or winner-takes-all interactions among categorical representations, implemented using a softmax function. This formal prior (a prior induced by the form of a generative model) simply expresses the prior belief that there is only one cause of any sensory consequence at any time. Together, this provides a generative model based on highly nonlinear and chaotic dynamics that allows competing perceptual hypotheses to explain sensory data.
9.6.2 Stimulus Generation and the Generative Model
Figure 9.4 shows a schematic of stimulus generation and the generative model used for categorization. The equations on the left describe the production of the stimulus, where the equations of motion for the hidden states 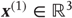 correspond to the equations of motion with a Lorenz attractor. In all the simulations that follow, the hidden causes were changed smoothly from
correspond to the equations of motion with a Lorenz attractor. In all the simulations that follow, the hidden causes were changed smoothly from 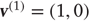 to
to 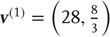 after 32 (16 ms) time bins. This changes the attractor from a fixed point attractor to a chaotic attractor and produces the stimulus onset.
after 32 (16 ms) time bins. This changes the attractor from a fixed point attractor to a chaotic attractor and produces the stimulus onset.
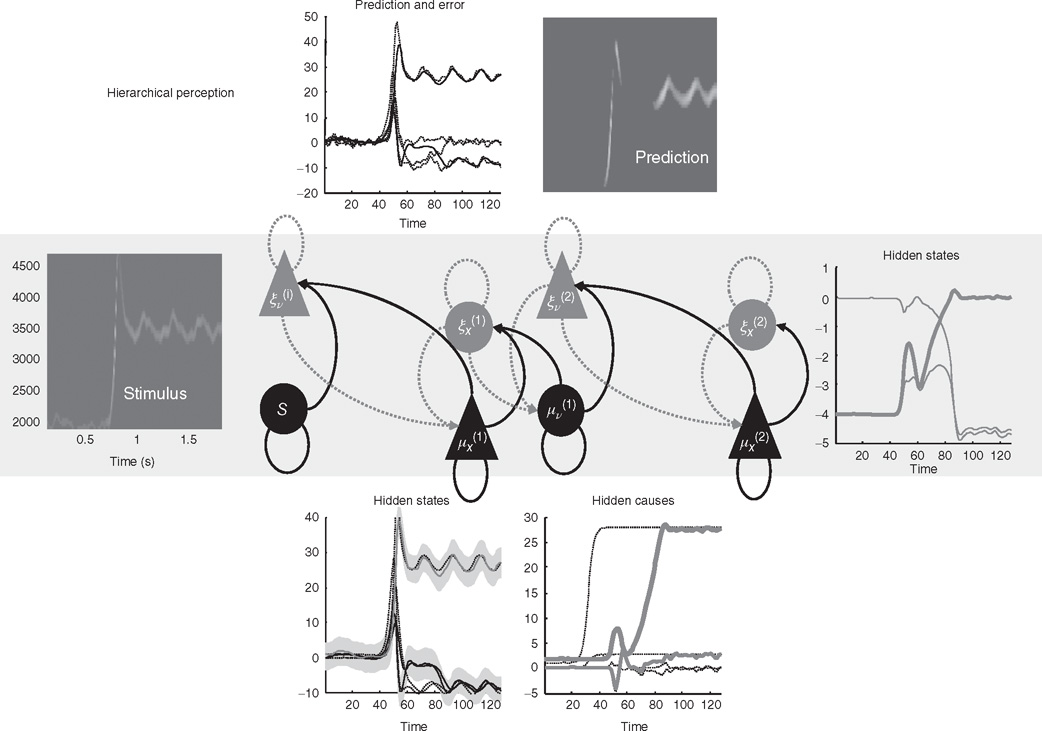
Figure 9.5 This reports an example of perceptual categorization following the format of Figure 9.2. The panel on the left shows the stimulus in sonogram format, while the corresponding conditional predictions and errors (dotted lines) are shown as functions of time (respectively a sonogram) in the upper left (respectively right) panel. These predictions are based on the expected hidden states at the first level shown on the lower left. The gray areas correspond to 90% conditional confidence intervals. It can be seen that the conditional estimate of the hidden state modulating frequency is estimated reasonably accurately (upper gray line); however, the corresponding modulation of amplitude takes a couple of chirps before it finds the right level (lower black line). This reflects changes in the conditional expectations about hidden causes and the implicit category of the song. The correct category is only inferred after about 80 time bins (thick line in the right panel), when expectations of the second level hidden states are driven by ascending prediction errors to their appropriate values.
The equations on the right constitute the generative model and have the form of Eq. (9.7). Notice that the generative model is slightly more complicated than the process generating stimuli – it is equipped with hidden states at a higher hierarchical level  that determine the values of the hidden causes, which control the attractor manifold for the hidden states
that determine the values of the hidden causes, which control the attractor manifold for the hidden states 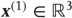 at the first level. Also note that these hidden states decay uniformly until the sum of their exponentials is equal to 1. The function-generating hidden causes implement a softmax mixture of three potential values for the hidden causes
at the first level. Also note that these hidden states decay uniformly until the sum of their exponentials is equal to 1. The function-generating hidden causes implement a softmax mixture of three potential values for the hidden causes 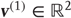 encoded in the matrix
encoded in the matrix 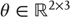 . The three categories of songs correspond to silence, a quasiperiodic song, and a chaotic song. This means that the stimulus changes from silence (the first category) to a chaotic song (the third category). The amplitudes of the random fluctuations are determined by their variance or log precisions and are shown in the lower part of Figure 9.4. Given the precise form of the generative model and a stimulus sequence, one can now integrate or solve Eq. (9.8) to simulate neuronal responses encoding conditional expectations and prediction errors.
. The three categories of songs correspond to silence, a quasiperiodic song, and a chaotic song. This means that the stimulus changes from silence (the first category) to a chaotic song (the third category). The amplitudes of the random fluctuations are determined by their variance or log precisions and are shown in the lower part of Figure 9.4. Given the precise form of the generative model and a stimulus sequence, one can now integrate or solve Eq. (9.8) to simulate neuronal responses encoding conditional expectations and prediction errors.
9.6.3 Perceptual Categorization
Figure 9.5 shows an example of perceptual categorization using the format of Figure 9.2. The panel on the left shows the stimulus in sonogram format, while the corresponding conditional predictions and errors (dotted lines) are shown as functions of time (respectively a sonogram) in the upper left (respectively right) panel. These predictions are based on the expected hidden states at the first level shown on the lower left. The gray areas correspond to conditional confidence intervals of 90%. It can be seen that the conditional estimate of the hidden state modulating frequency is estimated reasonably accurately (upper gray line); however, the corresponding modulation of amplitude takes a couple of chirps before it finds the right level (lower black line). This reflects changes in the conditional expectations about hidden causes and the implicit category of the song. The correct (third) category is only inferred after about 80 time bins (thick line in the right panel), when expectations of the second level hidden states are driven by ascending prediction errors to their appropriate values.
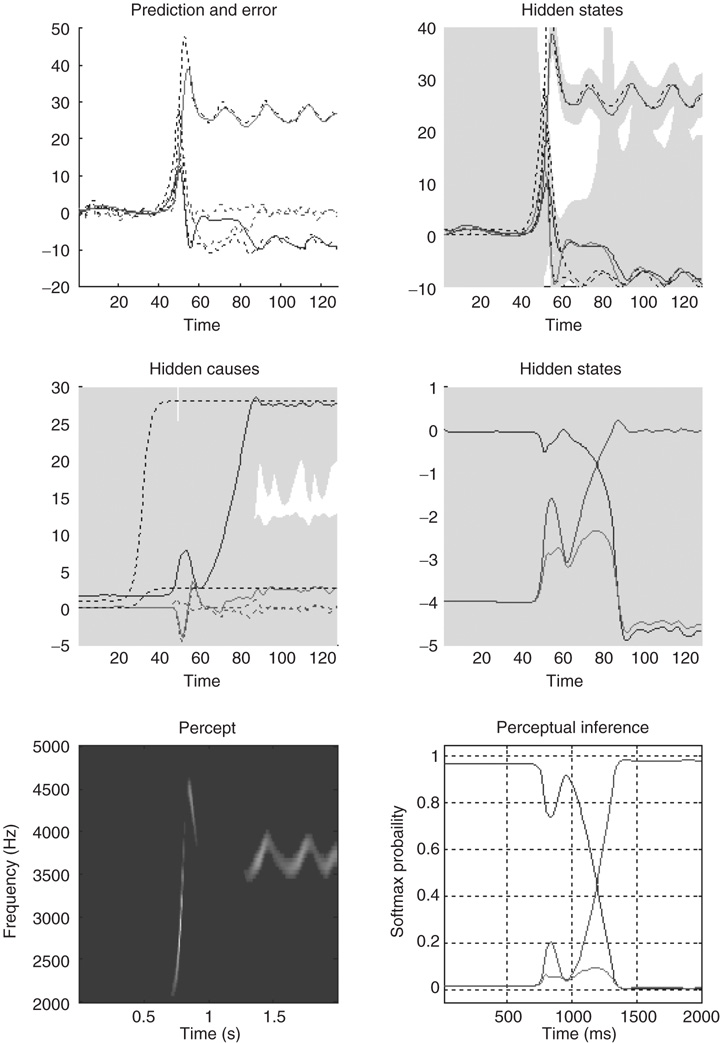
Figure 9.6 This shows the same results as in Figure 9.5, with conditional confidence intervals on all hidden states and causes and the implicit softmax probabilities based on the hidden states at the second level (lower right panel). These results illustrate switching from the first (silence) to the third (bird song) category. This switch occurs after a period of exposure to the new song and enables the stimulus to be predicted more accurately. These dynamics can also be regarded as generalized synchronization between simulated neuronal activity and the true hidden states generating the stimulus.
Figure 9.6 shows the same results with conditional confidence intervals on all hidden states and causes and the implicit softmax probabilities based on the categorical hidden states at the second level (lower right panel). Note the high degree of uncertainty about the first hidden attractor state, which can only be inferred on the basis of changes (generalized motion) in the second and third states that are informed directly by the frequency and amplitude of the stimulus. These results illustrate perceptual ignition of dynamics in higher levels of the hierarchical model that show an almost categorical switch from the first to the third category (see the lower right panel). This ignition occurs after a period of exposure to the new song and enables it to be predicted more accurately. These dynamics can also be regarded as a generalized synchronization of simulated neuronal activity, with the true hidden states generating the stimulus. So, is there any evidence for critical slowing?
9.6.4 Perceptual Instability and Switching
Figure 9.7 shows the evolution of free energy and CLE as a function of peristimulus time. Figure 9.7a shows a phasic excess of free energy at the stimulus onset (first chirp or frequency glide). This is resolved quickly by changes in conditional expectations to reduce free energy to prestimulus levels. This reduction changes the flow and Jacobian of the conditional expectations and the local CLEs as shown on Figure 9.7b. Remarkably, there is pronounced critical slowing, as quantified by Eq. (9.17) (using 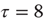 time bins or 128 ms), from the period of stimulus onset to the restoration of minimal free energy. The panels on the right show the underlying changes in the CLE – in their raw form (Figure 9.7b) and their exponentials (Figure 9.7d). The measure of critical slowing is simply the sum of these exponential CLE. It can be seen that many large negative CLE actually decrease their values, suggesting that some subspace of the generalized descent becomes more stable. However, the key change is in the CLE with small negative values, where several move toward zero (highlighted). These changes dominate the measure of critical slowing and reflect self-organized instability following stimulus onset – an instability that coincides exactly with the perceptual switch to the correct category of stimulus (see previous figure).
time bins or 128 ms), from the period of stimulus onset to the restoration of minimal free energy. The panels on the right show the underlying changes in the CLE – in their raw form (Figure 9.7b) and their exponentials (Figure 9.7d). The measure of critical slowing is simply the sum of these exponential CLE. It can be seen that many large negative CLE actually decrease their values, suggesting that some subspace of the generalized descent becomes more stable. However, the key change is in the CLE with small negative values, where several move toward zero (highlighted). These changes dominate the measure of critical slowing and reflect self-organized instability following stimulus onset – an instability that coincides exactly with the perceptual switch to the correct category of stimulus (see previous figure).
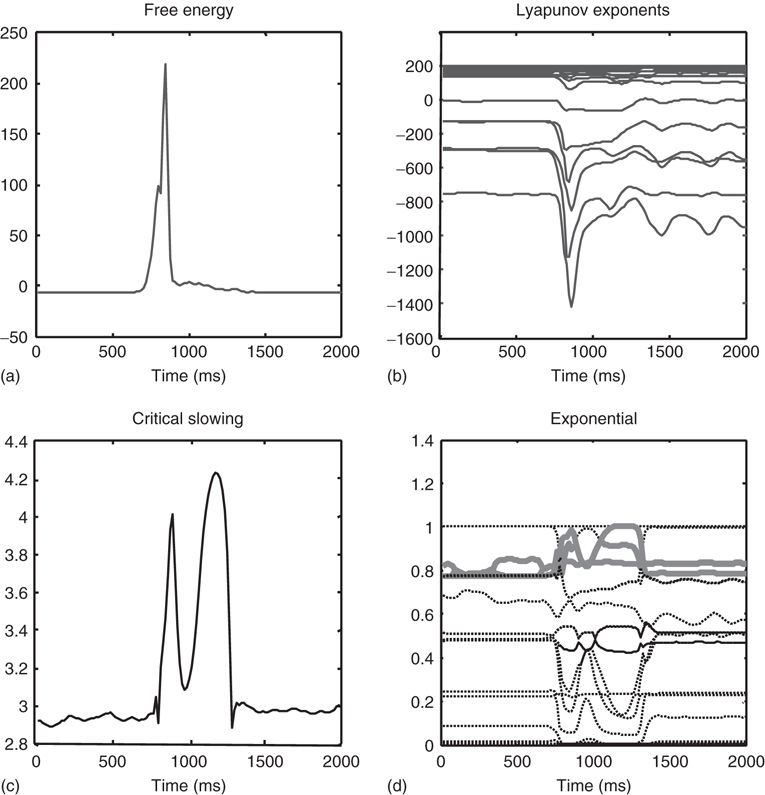
Figure 9.7 This shows the evolution of free energy and CLE over peristimulus time. (a) A phasic excess of free energy at the stimulus onset (first chirp or frequency glide). This is quickly resolved by changes in conditional expectations to reduce free energy to prestimulus levels. This reduction changes the Jacobian of the motion of internal states (conditional expectations) and the local conditional Lyapunov exponents (CLE), as shown in (b). (c) A pronounced critical slowing, as quantified by Eq. (9.17) (using  time bins or 128 ms) from stimulus onset to the restoration of minimal free energy. The panels on the right show the underlying changes in the CLE (b) and their exponentials (d). The measure of critical slowing is the sum of exponential CLE. It can be seen that several CLE with small negative values move toward zero (highlighted). These changes dominate the measure of critical slowing and reflect self-organized instability following stimulus onset – an instability that coincides with the perceptual switch to the correct stimulus category (see previous figure).
time bins or 128 ms) from stimulus onset to the restoration of minimal free energy. The panels on the right show the underlying changes in the CLE (b) and their exponentials (d). The measure of critical slowing is the sum of exponential CLE. It can be seen that several CLE with small negative values move toward zero (highlighted). These changes dominate the measure of critical slowing and reflect self-organized instability following stimulus onset – an instability that coincides with the perceptual switch to the correct stimulus category (see previous figure).
9.6.5 Perception and Critical Slowing
The changes described are over peristimulus time and reflect local CLE. Although we will not present an analysis of global CLE, we can average the local values over the second half of peristimulus time during which the chaotic song is presented. To test our conjecture that free energy minimization and perceptual inference induce critical slowing, we repeated the earlier simulations while manipulating the (prior beliefs about) precision on the motion of hidden attractor states.
Bayes-optimal inference depends on a delicate balance in the precisions assumed for the random fluctuations at each level of hierarchical models. These prior beliefs are encoded by the log precisions in Eq. (9.8). When intermediate levels are deemed too precise, top-down empirical priors overwhelm sensory evidence, resulting in illusory predictions. Furthermore, they predominate over the less precise prior beliefs at higher levels in the hierarchy. This can lead to false inference and a failure to recognize the high-level causes of sensory inputs. Conversely, when intermediate precisions are too low, the prediction errors from intermediate levels are insufficiently precise to change higher level conditional expectations. This again can lead to false perception, even if low-level attributes are represented more accurately. These failures of inference are illustrated in Figure 9.8, using the same format as Figure 9.6. The left panels show the results of decreasing the log precision on the motion of hidden states from 4 to 1, while the right panels show the equivalent results when increasing the log precision from 4 to 7. These simulations represent perceptual categorization with under- and overconfident beliefs about the chaotic motion of the hidden attractor states. In both instances, there is a failure of perception of all but the frequency glide at the onset of the song (compare the sonograms in Figure 9.8 with that in Figure 9.6). In both cases, this is due to a failure of inference about the hidden categorical states that would normally augment the predictions of hidden attractor states and subsequent sensations. In the underconfident condition, there is a slight deviation of predictions about amplitude from baseline (zero) levels – but this is not sufficiently informed by top-down empirical priors to provide a veridical prediction. Conversely, in the overconfident condition, the amplitude predictions remain impervious to sensory input and reflect top-down prior beliefs that the bird is listening to silence. Notice the shrinkage in conditional uncertainty about the first hidden attractor state in the upper right panels. This reflects the increase in precision on the motion of these hidden states.
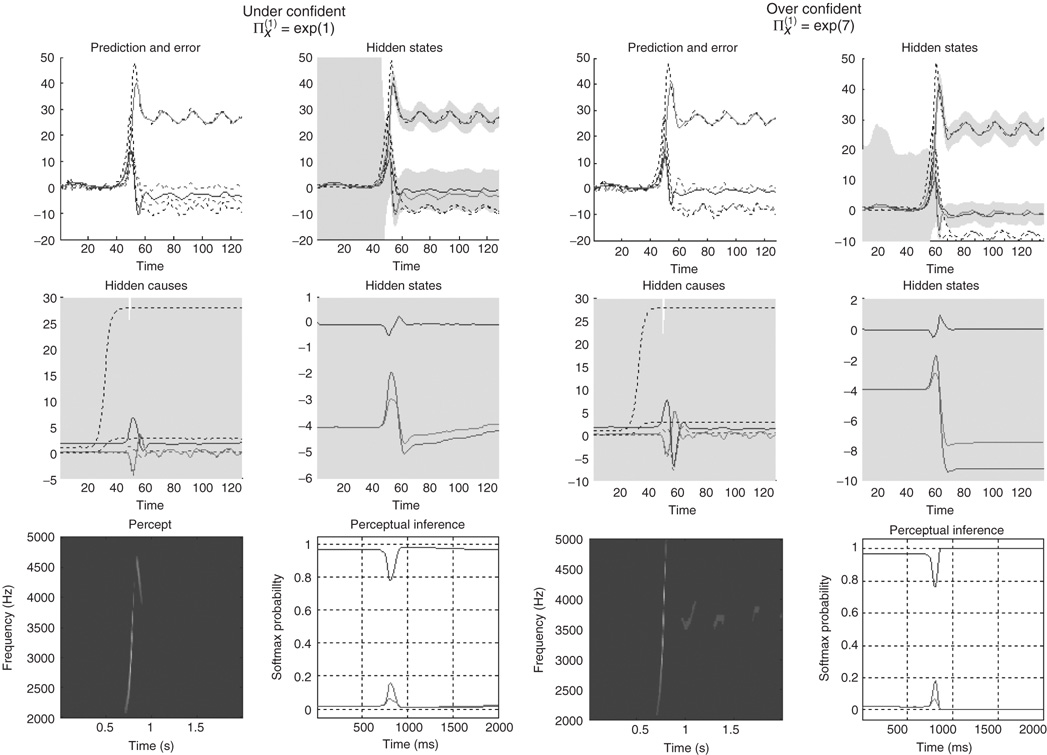
Figure 9.8 Failures of perceptual inference illustrated using the same format as Figure 9.6. The left panels show the results of decreasing the log precision on the notion of hidden states from 4 to 1; while the right panels show the equivalent results when increasing the log precision from 4 to 7. These simulations represent perceptual categorization with under- and overconfident beliefs about the motion of hidden attractor states. In both instances, there is a failure of perception of all but the frequency glide at the onset of the song (compare the sonograms in Figure 9.8 with that in Figure 9.6). In the underconfident condition, there is a slight deviation of predictions about amplitude from baseline (zero) levels – but this is not sufficiently informed by (imprecise) top-down empirical priors to provide a veridical prediction. Conversely, in the overconfident condition, the amplitude predictions are impervious to sensory input and reflect top-down prior beliefs that the bird is listening in silence.
Finally, we repeated the above-mentioned simulations for 64 values of precision on the motion of hidden attractor states from a log precision of 0 (a variance of 1) to a log precision of 7. At each value, we computed the time average of free energy, the softmax probability of the correct stimulus category, and critical slowing. In addition, we recorded the principal local CLE for each simulation. Figure 9.9 shows the interrelationships among these characterizations: Figure 9.9a shows the average probability of correctly identifying the song, which ranges from 0 in the low and high precision regime, to about 70% in the intermediate regime. The two vertical lines correspond to the onset and offset of nontrivial categorization, with a softmax probability of >0.05. The variation in these average probabilities is due to the latency of the perceptual switch to the correct song. This can be seen in Figure 9.9b, which shows the principal CLE in image format as a function of peristimulus time (columns) and precision (rows). It can be seen that the principal CLE shows fluctuations in, and only, in the regime of veridical categorization. Crucially, these fluctuations appear earlier when the categorization probabilities were higher, indicating short latency perceptual switches. Note that the principal CLE attains positive values for short periods of time. This does not necessarily mean a loss of generalized synchronization; provided the long-term time average is zero or less, when evaluated over long stimulus presentation times. Given that we are looking explicitly at stimulus responses or transients, these positive values could be taken as evidence for transient chaos.
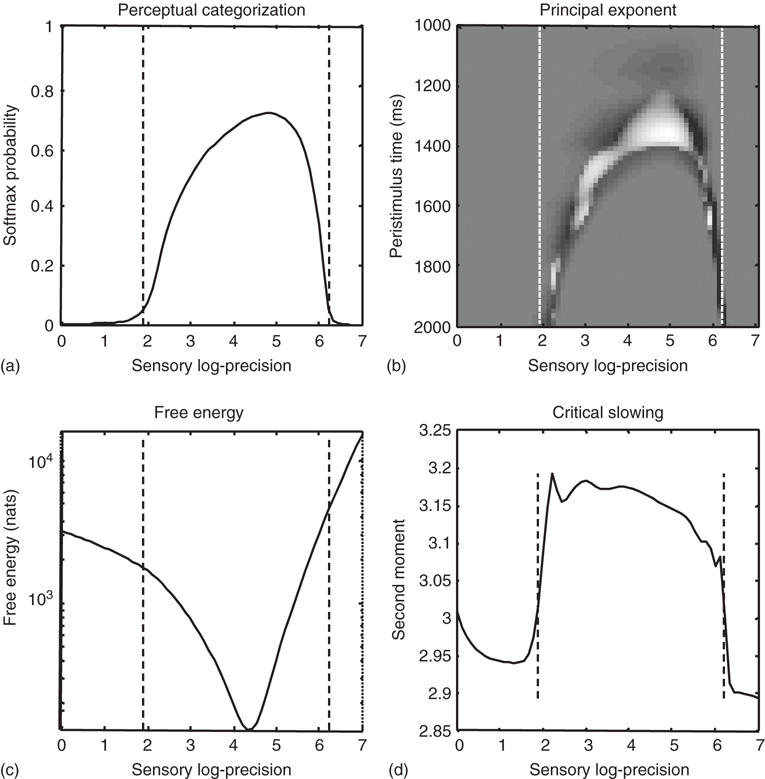
Figure 9.9 (a) The average probability (following stimulus onset) of correctly identifying a song over 64 values of precision on the motion of hidden attractor states. The two vertical lines correspond to the onset and offset of nontrivial categorization – a softmax probability of >0.05. The variation in these average probabilities is due to the latency of the perceptual switch to the correct song. This can be seen in (b) that shows the principal CLE in image format as a function of peristimulus time (columns) and precision (rows). It can be seen that the principal CLE shows fluctuations in, and only, in the regime of veridical categorization. Crucially, these fluctuations appear earlier when the categorization probabilities were higher, indicating short latency perceptual switches. (c) The time-averaged free energy as a function of precision. As one might anticipate, this exhibits a clear minimum around the level of precision that produces the best perceptual categorization. (d) Seen here is a very clear critical slowing in, and only in, the regime of correct categorization. In short, these results are consistent with the conjecture that free energy minimization can induce instability and thereby provide a more responsive representation of hidden states in the world.
Figure 9.9c shows the average free energy as a function of precision. As one might anticipate, this exhibits a clear minimum around the level of precision that produces the best perceptual categorization. The key results, from the point of view of this chapter, are presented in Figure 9.9d. This shows a very clear critical slowing in, and only in the regime of correct categorization. In short, these results are entirely consistent with the conjecture that free energy minimization induces instability or critical slowing and thereby provides a more veridical representation of hidden states in the world.
9.6.6 Summary
In summary, these simulations of perceptual transitions affirm the notion that a sensitive response to sensory perturbations from the environment is accompanied by critical slowing of representational dynamics – of the sort that would be predicted by Bayes-optimal perception and the implicit maximum entropy principle. Although we have focused on perception, the imperative to minimize free energy, in the larger setting of active inference, may mean that any self-organizing system that resists a dispersion of its (sensory) states should show the same sort of critical slowing. The perceptual categories used in this chapter to illustrate perceptual transitions were very distinct. One might imagine that the role of critical slowing and transitions may become more important when discriminating between more ambiguous stimuli; for example, those used to elicit bistable perception. In future work, we hope to look at bistable perception (binocular rivalry) and revisit our recent work in this area, in terms of critical slowing. In these models, the system works at the border of a Hopf bifurcation, where noise is more efficient in provoking perceptual transitions [30].
9.7 Conclusion
We have addressed self-organization at a number of levels. First, we have looked at self-organization in terms of the selective sampling of the environment to minimize surprise (free energy) and therefore maintain a homeostasis in the sense of Ashby [35]. Because surprise is negative log evidence in statistics, free energy minimization can also be understood as accumulating evidence for generative models of the world in a Bayes-optimal manner. Second, we have considered free energy minimization in self-organizing systems as a dynamical process that performs a (generalized) gradient descent. Statistically speaking, this corresponds to a generalized (Bayesian) filtering or deconvolution that discovers the underlying causes of sensory states. This form of dynamics has the rather curious property of self-destabilization, in the sense that the internal states of a system (as in the brain) will seek out regions of low free energy that, by definition, have a low curvature and invite relatively unstable (slow) dynamics. This form of self-organizing instability was demonstrated using neuronal simulations of perceptual categorization and a fairly minimal, but generic generative model. These demonstrations provided an example of Bayes-optimal perceptual categorization that was associated with self-organized instability or critical slowing that may be an integral part of perceptual switching or ignition. Finally, there is an important third level of self-organization that is implicit in the final simulations: at the beginning, we established that the internal states of a self-organizing system will minimize free energy. This includes posterior beliefs about (estimates of) the precision of random fluctuations. This means that had we allowed the precision on the motion of hidden attractor states to minimize free energy, it would have found the value that is in the center of the region showing critical slowing. In other words, if the system chose the level of uncertainty or confidence in its prior beliefs, it would choose a critical regime. Figure 9.9 is a good illustration of how criticality can induce self-organization in a subtle and recursive manner.
References
- 1. Dehaene, S. and Changeux, J.-P. (2011) Experimental and theoretical approaches to conscious processing. Neuron, 70, 200–227.
- 2. Tsuda, I. (2001) Toward an interpretation of dynamic neural activity in terms of chaotic dynamical systems. Behav. Brain Sci., 24 (5), 793–810.
- 3. Breakspear, M. (2001) Perception of odors by a nonlinear model of the olfactory bulb. Int. J. Neural Syst., 11 (2), 101–124.
- 4. Shew, W.L., Yang, H., Yu, S., Roy, R., and Plenz, D. (2011) Information capacity and transmission are maximized in balanced cortical networks with neuronal avalanches. J. Neurosci., 31 (1), 55–63.
- 5. Plenz, D. and Thiagarajan, T.C. (2007) The organizing principles of neuronal avalanches: cell assemblies in the cortex? Trends Neurosci., 30 (3), 101–110.
- 6. Beggs, J.M. and Plenz, D. (2003) Neuronal avalanches in neocortical circuits. J. Neurosci., 23 (35), 11167–11177.
- 7. Gregory, R.L. (1980) Perceptions as hypotheses. Philos. Trans. R. Soc. London, Ser. B, 290, 181–197.
- 8. Fisch, L., Privman, E., Ramot, M. et al. (2009) Neural ignition: enhanced activation linked to perceptual awareness in human ventral stream visual cortex. Neuron, 64, 562–574.
- 9. Maturana, H.R. and Varela, F. (1980) Autopoiesis: the organization of the living, in Autopoiesis and Cognition (eds H.R. Maturana and F. Varela), Reidel, Dordrecht.
- 10. Friston, K. (2010) The free-energy principle: a unified brain theory? Nat. Rev. Neurosci., 11 (2), 127–138.
- 11. Friston, K. and Ao, P. (2012) Free-energy, value and attractors. Comput. Math. Meth. Med., 2012, 937860.
- 12. Nara, S. (2003) Can potentially useful dynamics to solve complex problems emerge from constrained chaos and/or chaotic itinerancy? Chaos, 13 (3), 1110–1121.
- 13. van Leeuwen, C. (2008) Chaos breeds autonomy: connectionist design between bias and baby-sitting. Cogn. Process., 9 (2), 83–92.
- 14. Ishii, S., Yoshida, W., and Yoshimoto, J. (2002) Control of exploitation-exploration meta-parameter in reinforcement learning. Neural Netw., 15 (4-6), 665–687.
- 15. Freeman, W.J. (1994) Characterization of state transitions in spatially distributed, chaotic, nonlinear, dynamical systems in cerebral cortex. Integr. Physiol. Behav. Sci., 29 (3), 294–306.
- 16. Pasquale, V., Massobrio, P., Bologna, L.L., Chiappalone, M., and Martinoia, S. (2008) Self-organization and neuronal avalanches in networks of dissociated cortical neurons. Neuroscience, 153 (4), 1354–1369.
- 17. Jirsa, V.K., Friedrich, R., Haken, H., and Kelso, J.A. (1994) A theoretical model of phase transitions in the human brain. Biol. Cybern., 71 (1), 27–35.
- 18. Rabinovich, M., Huerta, R., and Laurent, G. (2008) Neuroscience. Transient dynamics for neural processing. Science, 321 (5885), 48–50.
- 19. Tschacher, W. and Haken, H. (2007) Intentionality in non-equilibrium systems? The functional aspects of self-organised pattern formation. New Ideas Psychol., 25, 1–15.
- 20. Tyukin, I., van Leeuwen, C., and Prokhorov, D. (2003) Parameter estimation of sigmoid superpositions: dynamical system approach. Neural Comput., 15 (10), 2419–2455.
- 21. Tyukin, I., Tyukina, T., and van Leeuwen, C. (2009) Invariant template matching in systems with spatiotemporal coding: a matter of instability. Neural Netw., 22 (4), 425–449.
- 22. Birkhoff, G D. Proof of the ergodic theorem. Proc. Natl. Acad. Sci. U.S.A., 17 (1931), 656-660.
- 23. Breakspear, M. (2004) Dynamic connectivity in neural systems – theoretical and empirical considerations. Neuroinformatics, 2 (2), 205–225.
- 24. Namikawa, J. (2005) Chaotic itinerancy and power-law residence time distribution in stochastic dynamical systems. Phys. Rev. E, 72 (2), 026204.
- 25. Gros, C. (2009) Cognitive computation with autonomously active neural networks: an emerging field. Cognit. Comput., 1, 77–99.
- 26. Breakspear, M. and Stam, C.J. (2005) Dynamics of a neural system with a multiscale architecture. Philos. Trans. R. Soc. Lond. B Biol. Sci., 360 (1457), 1051–1074.
- 27. Bressler, S.L. and Tognoli, E. (2006) Operational principles of neurocognitive networks. Int. J. Psychophysiol., 60 (2), 139–148.
- 28. Werner, G. (2007) Brain dynamics across levels of organization. J. Physiol. Paris, 4-6, 273–279.
- 29. Kiebel, S.J., Daunizeau, J., and Friston, K.J. (2009) Perception and hierarchical dynamics. Front. Neuroinf., 3, 20.
- 30. Theodoni, P., Panagiotaropoulos, T.I., Kapoor, V., Logothetis, N.K., and Deco, G. (2011) Cortical microcircuit dynamics mediating binocular rivalry: the role of adaptation in inhibition. Front. Hum. Neurosci., 5, 145.
- 31. Aburn, M.J., Holmes, C.A., Roberts, J.A., Boonstra, T.W., Breakspear, M. (2012) Critical fluctuations in cortical models near instability. Front. Physio. 3, 331. doi: 10.3389/fphys.2012.00331
- 32. Breakspear, M., Heitmann, S., and Daffertshofer, A. (2010) Generative models of cortical oscillations: neurobiological implications of the kuramoto model. Front. Hum. Neurosci., 4, 190.
- 33. Bak, P., Tang, C., and Wiesenfeld, K. (1987) Self-organized criticality: an explanation of 1/f noise. Phys. Rev. Lett., 59 (4), 381–384.
- 34. Kelso, J.A.S. (2010). Instabilities and phase transitions in human brain and behavior. Front. Hum. Neurosci. 4:23.10.3389/fnhum.2010.00023
- 35. Ashby, W.R. (1947) Principles of the self-organizing dynamic system. J. Gen. Psychol., 37, 125–128.
- 36. Friston, K. (2008) Hierarchical models in the brain. PLoS Comput. Biol., 4 (11), e1000211.
- 37. Feynman, R.P. (1972) Statistical Mechanics, Benjamin, Reading, MA.
- 38. Beal, M.J. (2003) Variational algorithms for approximate bayesian inference. PhD Thesis, University College London.
- 39. Jaynes, E.T. (1957) Information theory and statistical mechanics. Phys. Rev. Ser. II, 106 (4), 620–630.
- 40. Helmholtz, H. (1866/1962) Concerning the perceptions in general, in Treatise on Physiological Optics, Dover Publications, New York.
- 41. Ballard, D.H., Hinton, G.E., and Sejnowski, T.J. (1983) Parallel visual computation. Nature, 306, 21–26.
- 42. Dayan, P., Hinton, G.E., and Neal, R.M. (1995) The Helmholtz machine. Neural Comput., 7, 889–904.
- 43. Friston, K. (2005) A theory of cortical responses. Philos. Trans. R. Soc. Lond. B Biol. Sci., 360 (1456), 815–836.
- 44. Yuille, A. and Kersten, D. (2006) Vision as Bayesian inference: analysis by synthesis? Trends Cogn. Sci., 10 (7), 301–308.
- 45. Ginzburg, V.L. and Landau, L.D. (1950) On the theory of superconductivity. Zh. Eksp. Teor. Fiz., 20, 1064.
- 46. Haken, H. (1983) Synergetics: An Introduction. Non-Equilibrium Phase Transition and Self–Selforganisation in Physics, Chemistry and Biology, Springer-Verlag, Berlin.
- 47. Friston, K. (2009) The free-energy principle: a rough guide to the brain? Trends Cogn. Sci., 13 (7), 293–301.
- 48. Friston, K., Stephan, K., Li, B., and Daunizeau, J. (2010) Generalised filtering. Math. Prob. Eng., 2010, 621670.
- 49. Friston, K. and Kiebel, S. (2009) Cortical circuits for perceptual inference. Neural Networks, 22 (8), 1093–1104.
- 50. Brown, H. and Friston, K.J. (2012) Free-energy and illusions: the cornsweet effect. Front. Psychol., 3, 43.
- 51. Friston, K.J. and Kiebel, S.J. (2009) Predictive coding under the free-energy principle. Philos. Trans. R. Soc. B, 364, 1211–1221.
- 52. Feldman, H. and Friston, K.J. (2010) Attention, uncertainty, and free-energy. Front. Hum. Neurosci., 4, 215.
- 53. Friston, K.J., Daunizeau, J., Kilner, J., and Kiebel, S.J. (2010) Action and behavior: a free-energy formulation. Biol. Cybern., 102 (3), 227–260.
- 54. Friston, K., Mattout, J., and Kilner, J. (2011) Action understanding and active inference. Biol. Cybern., 104, 137–160.
- 55. Friston, K., Adams, R., Perrinet, L., and Breakspear, M. (2012) Perceptions as hypotheses: saccades as experiments. Front. Psychol., 3, 151.
- 56. Friston, K.J., Daunizeau, J., and Kiebel, S.J. (2009) Active inference or reinforcement learning? PLoS One, 4 (7), e6421.
- 57. Friston, K.J., Shiner, T., Fitzgerald, T., Galea, J.M. et al. (2012) Dopamine, affordance and active inference. PLoS Comput. Biol., 8 (1), e1002327.
- 58. Rao, R.P. and Ballard, D.H. (1999) Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci., 2 (1), 79–87.
- 59. Mumford, D. (1992) On the computational architecture of the neocortex. II. Biol. Cybern., 66, 241–251.
- 60. Feldman, A.G. and Levin, M.F. (1995) The origin and use of positional frames of reference in motor control. Behav. Brain Sci., 18, 723–806.
- 61. Hunt, B., Ott, E., and Yorke, J. (1997) Differentiable synchronisation of chaos. Phys. Rev. E, 55, 4029–4034.
- 62. Barreto, E., Josic, K., Morales, C.J., Sander, E., and So, P. (2003) The geometry of chaos synchronization. Chaos, 13, 151–164.
- 63. Pyragas, K. (1997) Conditional Lyapunov exponents from time series. Phys. Rev. E, 56 (5), 5183–5187.
- 64. Kaplan, J. and Yorke, J. (1979) Chaotic behavior of multidimensional difference equations, in Functional Differential Equations and Approximation of Fixed Points (eds H.O. Peitgen and H.O. Walther), Springer, New York.
- 65. Abarbanel, H.D.I., Creveling, D.R., and Jeanne, J.M. (2008) Estimation of parameters in nonlinear systems using balanced synchronization. Phys. Rev. E, 77, 016208.
- 66. Tsuda, I. and Fujii, H. (2004) Computational Neuroscience: Cortical Dynamics, Lecture Notes in Computer Science, ISSU, vol. 3146, Springer, Berlin, Heidelberg, pp. 109–128.
- 67. Cessac, B., Blanchard, P., and Krüger, T. (2001) Lyapunov exponents and transport in the Zhang model of self-organized criticality. Phys. Rev. E Stat. Nonlinear Soft Matter Phys., 64 (1 Pt 2), 016133.
- 68. Perl, Y.S., Arneodo, E.M., Amador, A., Goller, F., and Mindlin, G.B. (2011) Reconstruction of physiological instructions from Zebra finch song. Phys. Rev. E, 84, 051909.
- 69. Zeigler, P. and Marler, P. (2008) Neuroscience of Birdsong, Cambridge University Press, Cambridge.