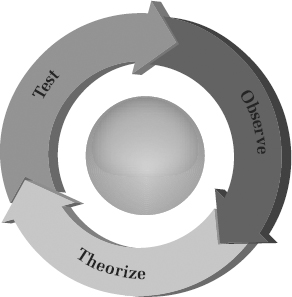
FIGURE 3.1: The scientific method, about as simplified as possible. Observations of the world are abstracted into theories, which are then tested. The results of the test constitute new observations about the world, and the cycle continues.
If it disagrees with experiment, it’s wrong. In that simple statement is the key to science. It doesn’t make a difference how beautiful your guess is, it doesn’t make a difference how smart you are, who made the guess, or what his name is. If it disagrees with experiment, it’s wrong.
—Richard Feynman 1
Imagine that an earthquake strikes your town. Your home shakes, exactly as if a giant shook it for his amusement. Windows rattle, books fall from bookshelves. You jump under a table, wondering when it will end, wondering whether your house will crash around you. At last it stops. You survey your house, call your friends and family—everyone is okay. You hear on the radio that the quake’s epicenter was actually several hundred miles away. Towns there were leveled, tens of thousands have died, hundreds of thousands have lost their homes.
How would you react? I think I would, of course, feel bad for all those suffering people, but I would also feel grateful. I’d be thanking my lucky stars that things weren’t worse where I lived. What I wouldn’t do, I would imagine, is pass rumors that another earthquake is coming, even worse this time, centered on my town.
Improbable as it seems, such rumors are relatively common after major earthquakes. This phenomenon was first noted after a large earthquake in 1934 centered in the state of Bihar in eastern India. These rumors were especially rampant more distant from the epicenter, in areas that had suffered less damage.2 Psychologists were puzzled. Why would people pass these rumors, which would serve only to increase anxiety?
This puzzle caught the attention of psychologist Leon Festinger, who turned the problem on its head. Perhaps it’s not that people were spreading rumors and thereby causing anxiety. Perhaps they were already anxious, and the rumors gave them some justification for their anxiety. And so the theory of cognitive dissonance was born.3
The core of cognitive dissonance theory is that people find it uncomfortable to hold two conflicting thoughts in mind at once. This discomfort motivates people to change one of the thoughts. People are, understandably, anxious following an earthquake, even if the damage around them was minimal. It’s unnerving to be confronted with one’s powerlessness in face of dramatic natural force.a So these people hold two seemingly conflicting thoughts: (1) I am anxious, and (2) everything is fine because I was not injured by the quake. Festinger’s theory predicts that when we hold two conflicting thoughts, we are motivated to change one. It’s not easy to make yourself less anxious, so you change the other thought—everything is not fine, because another, even larger quake is coming. People closer to the center of the quake, in contrast, have no need to justify their anxiety. They have lost property or been injured, or their friends or family have, so it’s quite clear to them why they are anxious.
Festinger subjected his idea to more careful testing in the laboratory. In one of his better-known demonstrations, he asked subjects to perform terribly boring, repetitive tasks—for example, removing and replacing pegs in a pegboard.4 After an hour of this tedium, the experimenter told the subject that the purpose was to see if people performed tasks better if they have been told that the task is interesting. The experimenter said that the next person coming needed to expect that the task would be interesting. Would the subject be willing to tell the new arrival that she was in for a treat? The crucial part of the experiment was that subjects were offered money to tell this lie: some were offered the relatively modest sum of $1, whereas others were offered $20, a tidy sum in the late 1950s when this experiment was conducted. At the end of the experiment, subjects were asked how much they had liked the pegboard task.
We normally think that paying people to do something produces better results. So we might expect that the $20 subjects would end up rating the task more interesting than the $1 subjects would. But the opposite happened. Why? By getting the $1 subjects to lie about the task, the experimenters ensured that subjects held two conflicting thoughts: (1) the task was really boring, and (2) I just told someone the task was interesting. Subjects can’t convince themselves that they didn’t just say the task was interesting, so they change the other thought: they tell themselves that the pegboard task wasn’t all that bad. The $20 subjects, in contrast, don’t really feel that mental conflict because they can justify that second thought; “I just told someone that task was interesting because I was paid twenty dollars to say it.” So when asked at the end of the experiment, they said the task was dull, dull, dull.
The story of cognitive dissonance theory illustrates how science operates. Figure 3.1 shows that it’s a cyclical process. (When I refer to this figure, I’ll call it the Science Cycle.) We start on the right, with some observations of the world. These needn’t be technical laboratory findings. They can be casual observations you make on a neighborhood walk, or in the case of psychologist Jamuna Prasad, observations he made of earthquake victims spreading rumors. Then we try to synthesize these observations into a simple summary statement—that’s the stage labeled “theory” in the Science Cycle—and, indeed, scientific theories are really just statements that summarize some aspect of the world. For example, “The planets rotate around the sun in elliptical orbits” summarizes many, many observations of the locations of planets in the night sky. Leon Festinger sought to summarize many aspects of human thought and motivation by claiming that conflicting thoughts create discomfort. Finally, we test whether the summary statement is accurate, as in Festinger’s experiment with the boring pegboard task. The test produces new observations, and so we’re back at the top of the Science Cycle.b
FIGURE 3.1: The scientific method, about as simplified as possible. Observations of the world are abstracted into theories, which are then tested. The results of the test constitute new observations about the world, and the cycle continues.
So what happens next? We make another trip around the Science Cycle, pushing the theory to make more refined predictions, and testing it in more varied circumstances. Eventually we’ll find a failure, a circumstance in which the theory predicts something other than what we observe. Finding such a failure is actually a good thing. Why? Because that’s the way science advances. Failures are the motivators of improved theories. If we develop a theory that is very hard to disprove, even after many tests, then we start to have some confidence that this theory is a good description of the world and will be of some use to us. (How we use scientific theories will be taken up in Chapter Four.)
How do you find a flaw in a theory, so that you can then go on to try to devise a better one? Criticisms might be leveled at any of the three stages in the scientific process depicted in the Science Cycle: observation, theory, or test.
1. Someone might point out that there was a problem with the observations in Festinger’s pegboard experiment. If you read the article describing the experiment, you’ll see that data from 15 percent of the subjects had to be excluded; these subjects either were suspicious about the real purpose of the experiment or refused to do some of the tasks. That’s a pretty high percentage, so I might claim that the observations from this experiment are invalid, and suggest that we need better data.
2. Someone might think that the experimental data are okay, but criticize the theory. Indeed, cognitive dissonance theory was initially criticized for being rather vague.5 For example, how much inconsistency is required before I’m motivated to change one of my thoughts? Will any type of inconsistency do? Suppose I think my physician is quite competent, but then I see him in a restaurant rudely berating a server. Will I feel dissonance? On the one hand, you can be a good clinician and still be a rude boor. On the other hand, shouldn’t a doctor be compassionate and sensitive? I might criticize the cognitive dissonance theory as being insufficiently developed if it cannot make a clear prediction in cases such as this.
3. Someone might propose a new test of the theory, drawing a new prediction from the theory that had not yet been considered. The original theory said little about how important the conflicting thoughts were to me; if there was a conflict, there was dissonance. Thus the theory seemed to predict that dissonance would arise even if the thoughts concerned minor matters. Merrill Carlsmith and his colleagues tested that prediction by repeating the boring-task experiment and showing that only face-to-face lies caused dissonance.6 When subjects wrote an essay describing the task as interesting, there was no dissonance, presumably because subjects did not really take the lie to heart. Carlsmith had no problem with the existing data or with the theory, but he proposed a new test, which then showed the theory to be wanting.
• • •
I’ve gone through this example to emphasize two things about good science. First, science is dynamic, not static. Although Enlightenment thinkers viewed the world as dynamic, their view of science was fixed. Seventeenth-century scientists thought of nature as God’s grand book to be decoded, and they expected that scientific knowledge, once gained, would be final. Newton’s laws were seen as absolute. The description of heavenly bodies was done. Many nonscientists hold this view today, a view all too often reinforced by the presentation of science in school. We learn facts and laws in textbooks as though they are unchangeable. Scientists, in contrast, view theories as provisional. That’s why Figure 3.1 depicts the scientific method as a cycle. It never stops, and the best theory we have of any phenomenon is always taken to be just that—the best theory we have now. It is expected that the theory will fail in some way and that a superior theory will eventually be proposed.
The provisional nature of scientific theory is important to keep in mind when we contemplate using scientific knowledge to improve education. We can’t change curricula and methods yearly, but we have to acknowledge that the very best scientific information we have today about how children think and learn may be out-of-date in a decade or two. The consequences of this new knowledge for an educational program may be minor, but they may not, and we would do well to bear this fact in mind when considering educational philosophies written fifty or a hundred years ago.c Piaget died thirty years ago; Vygotsky, almost eighty. Great as these minds were, they created their theories of child development in ignorance of decades of data.
The second thing to note about the cyclical nature of the scientific method is that it’s self-correcting. We not only assume that the current theory is provisional and will eventually be proven wrong; we also assume that a better theory can be and will be developed. But essential to this process is that the theory be open to criticism. That’s how we find flaws.
The whole system by which scientific theories are generated and evaluated is set up so that other people have ample opportunity to lodge criticism. The consequence of this somewhat combative nature of science is that most scientists get used to being wrong. It’s not just that scientists are wrong more often than they are right—that’s probably true in other fields too—but we get our noses rubbed in it, in public.d After a while, most scientists realize that insisting that you’re right in the face of valid criticism only makes you look stupider. You might as well admit the error, and if you find the error before someone else does, you might as well admit it before someone else points it out. Astronomer Carl Sagan put it admirably:
This is a sense in which science is radically different from other ways of understanding the world. When you’re wrong, everyone else can see it. I can modify my inaccurate theory, or I can abandon it and try something completely new. But I can’t just put my head down and pretend I don’t notice the problem, or bluster and call people names and hope to distract people from my error.
Science moves forward—that is, our understanding of natural phenomena gets deeper—as we make more circuits around the Science Cycle. Very often when people talk about “good science,” they get to the nitty-gritty of how experiments are designed, whether people use the right statistics on their data, and so forth. That’s important, but as we’ve now seen, there are two other, equally important stages where things can go right or wrong: the creation of theory and the observation of the world. Let’s look at each of the three stages more closely and examine what must be in place for each to be conducted correctly.
Why is there not a scientific field called “ethicology”? Wouldn’t it be marvelous (or at least interesting) to apply the scientific method to the study of ethics? We could, over time, zero in on the one set of ethical principles that would be most fitting for humans. Why are there not university departments of ethicology, as there are of biology, chemistry, and psychology?e
The answer gets at one of the limitations of scientific observation: the scientific method is applicable only to the natural world. It is mute on matters of morality, ethics, or aesthetics. You may have strong opinions as to whether Twilight or Swann’s Way is the better novel, but your opinion is not based on science. And because science applies only to the natural world, it does not, by definition, apply to the supernatural. (The word supernatural often implies something from the occult, but I’m using the term here to include anything outside nature, including God.) As physicist Steven Hawking noted, “The usual approach of science of constructing a mathematical model cannot answer the questions of why there should be a universe for the model to describe.”8
If not all problems are amenable to scientific analysis, we had better ask whether the sorts of problems we face in education can be addressed with the scientific method. At least some of these problems would seem to be part of the natural world, so our answer would be a tentative yes. There are no supernatural forces at work when children learn to read or to work math problems, and these cognitive abilities don’t have important ethical or aesthetic components. These processes can be studied scientifically, and significant progress has been made in understanding them in the last fifty years.
There are other vital questions in education for which the scientific method is wholly inappropriate. Should we present American history so as to encourage patriotism or so as to ingrain a questioning attitude toward government and toward institutional authority in general? What is the role of the arts in K–12 education? Who is ultimately responsible for children’s education: parents, teachers, or children themselves, and does the answer to this question change as kids get older? Educating children raises dozens of questions, and, powerful as the method may be, science is applicable to just a fraction of them. Thus we have to be clear about which questions science might address and how. I’ll have much more to say about that in Chapter Four.
So the first principle of good observation in science is to pick a problem that one can observe. The second principle is that when we say “observation” we really mean “measurement.” As the great German physicist Max Planck put it, “An experiment is a question which science poses to Nature, and a measurement is the recording of Nature’s answer.”
Why is measurement so important? Suppose I have a theory about dieting. I propose that there is a consistent relationship between calorie intake and weight loss: if you reduce calories by 25 percent, you will lose 1 percent of your weight each week. So according to my theory, a two-hundred-pound person who reduces his calorie intake by 25 percent will lose two pounds every week he diets.
Now suppose that you have a different theory. You agree that a 25 percent reduction in calories will lead to a 1 percent loss in weight each week, but you think it’s 1 percent of how much you weigh at the start of the week, not when you started the diet. So the dieter will lose 2.00 pounds the first week, 1.98 pounds the second week (that is, 1 percent of the 198 pounds he weighed at the start of the second week), 1.96 pounds the third week, and so on.
Your theory of weight loss is pretty different from mine; we disagree about the basis of weight loss. But the theories make really similar predictions. At the end of twelve weeks, the predictions differ by one pound (Figure 3.2). So to determine whether your theory or my theory of weight loss is better, we’ll need a pretty accurate scale.
FIGURE 3.2: The predictions of two theories of weight loss.
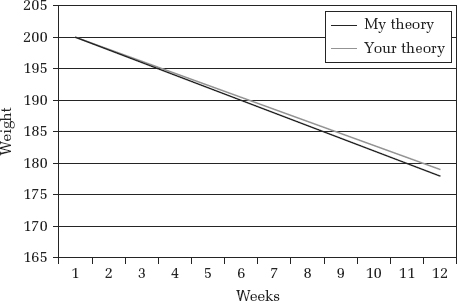
Now imagine that we don’t have scales at all. Imagine that we can judge weight only by looking at people and saying to ourselves, “Hmm, I think he looks thinner.” If that were the case, it would seem almost hopeless to determine whether your theory or my theory of weight loss is better. In fact, if there were not scales, it would be pretty hard to get past the very general, very obvious observation, “When people eat less, they tend to lose weight.”
When it comes to many of the qualities that we care about in education research, we are in a comparable position. We don’t have scales. We want kids to be creative, to be good collaborators, to be good critical thinkers. But our ability to measure these qualities is quite limited. This means that I might spin an interesting theory about what makes someone creative, but I can’t test my theory. And if you have a different theory, we can’t design an experiment to tell us which theory is better.
This problem is especially salient in light of current trends emphasizing “twenty-first-century skills” in schooling. The impetus comes from the claim forwarded by some economists that the nature of the job market is changing.9 Whereas most jobs in the latter part of the twentieth century called for repetitive physical work (for example, assembly line work in a factory) or repetitive cognitive work (for example, telephone sales), high-paying jobs in the twenty-first century are much more likely to call for nonrepetitive cognitive work—that is, jobs where people are frequently confronted with problems that they have not solved in the past. Furthermore, these problems are likely to demand different types of expertise for their solution, so people will need to pool their expertise—that is, to collaborate. Thus the prized worker would be (1) creative, (2) an effective problem solver, and (3) a good team player. So, one might argue, schooling should build those skills, to prepare our students for these jobs.
But if you’re hoping that science can help us know how to teach kids these qualities, you’ll need to be patient. Researchers are working on ways of measuring creativity10 and group cooperation,11 but this measurement problem is not easily solved. Obviously, the fact that we’re not yet very good at measuring things like creativity or morality or citizenship does not mean that we shouldn’t try to teach kids to be creative, moral, upright citizens. It means that we can’t expect science to help much in bolstering our efforts to teach these things. But again, we shouldn’t expect science to have all the answers. What’s important is clarity in our own minds about what science can and can’t do. Measurability is an important factor in how susceptible something is to scientific investigation. Measurability does not speak to importance. Importance is determined by our values.
I’m sure you have wondered what impact your siblings had on you, especially the impact of birth order (or of being an only child). If you’re the youngest in the family, like me, maybe you felt somewhat overshadowed by your older siblings, who had, and would forever have, the advantage of a few years on you. For their part, my older sisters always felt that my parents went kind of easy on me when it came to discipline—my sisters always said of my parents, “We broke them in for you.”
Suppose I tell you that I have a theory about birth order. I claim that the oldest child in a family is typically academically serious and is the highest achiever at school. I explain that the firstborn talks with adults more than her younger siblings do, and is under greater pressure from the parents to act like an adult from a young age. You respond with the example of your spouse’s older brother, who flunked out of school and now, at age thirty-two, lives in his parents’ basement, drinking beer and playing Xbox. I patiently explain that sometimes the child will sense the expectations of the parents and rebel, casting aside conventional marks of success and marching to his or her own drummer. Sometimes it’s even possible that the child will rebel in some parts of his life and try to live up to the parents’ expectations in others.
Now in one sense, my theory seems pretty cool. It makes a prediction, but when the prediction turns out to be wrong, my theory does a quick pivot and can still account for the data. Actually, a theory that can account for all data is not cool. In fact, able-to-account-for-all-data is not just an undesirable feature; it’s a fatal flaw. That sounds strange. Wouldn’t a theory that can account for everything be not just acceptable but desirable?
The logic here is a bit convoluted, so let’s start with a famous example, suggested by Karl Popper, the philosopher who emphasized this point.12 I start with observations in the world, so let’s suppose that I’m observing swans. I see lots of white swans and none of other colors, so I propose a theory: “All swans are white.” According to the Science Cycle, I’m supposed to test my theory. How could I verify that it is true? I don’t really get anywhere by taking you to the zoo or to a local lake and pointing out white swans. Finding some corroborating evidence for a theory is usually pretty easy. After all, I probably wouldn’t have come up with the theory in the first place if I hadn’t seen some white swans, so I’m just showing you the ones I’ve already seen. And no matter how many white swans I show you, the theory is never really proven. There might be a nonwhite swan in a spot I haven’t searched yet. Although proving my theory correct is impossible, proving it incorrect is easy. All it takes is one black swan, and we know that I’m wrong.
The problem with my birth-order theory is that I can’t test it. Firstborns are predicted to be high achievers . . . except when they are not high achievers. Show me a firstborn, and I actually can’t tell you whether he or she will be high achieving. That means I can’t generate a test of the theory and therefore can’t move around the Science Cycle. I’m stuck. And if I can’t test the theory, I can’t falsify it, and proving theories false is the main way we get to newer, better theories.
I’ve made the process sound as though there’s a “one strike and you’re out” rule. That is, I can keep piling up confirmatory evidence—that is, white swans—and it won’t mean much, but when I see one black swan, boom. Back to the drawing board. Indeed, Einstein is often quoted as having said, “No amount of experimentation can ever prove me right; a single experiment can prove me wrong.”13
It’s actually not quite that simple. For example, when asked what sort of evidence would shake his confidence in evolutionary theory, biologist J.B.S. Haldane reportedly said, “A fossil of a rabbit found in Precambrian rock.” The Precambrian period ended about 570 million years ago, a time when the only animals looked more like sponges, jellyfish, or worms, from which mammals would evolve much later.
But suppose a Precambrian rabbit fossil were found. Would biologists really conclude that evolution had been disproved? The answer is almost certainly no. Evolutionary theory provides such a good fit to so many observations in biology that it would be foolhardy to jettison the theory. Biologists would instead try to figure out how to retain the most important features of evolution that make it such a successful theory, while accounting for the Precambrian rabbit.
So wait a minute—doesn’t that make evolution an unfalsifiable theory? I find data I don’t like, so I start desperately looking for a back door? Not really. Biologists would recognize that the Precambrian rabbit posed a significant problem, but they would retain evolution as the best available theory. Sometimes a difficult-to-explain observation is later shown to fall within the predictions of the theory after all. A classic example is the observation of irregularities in the orbit of Uranus in 1845. The planet simply was not behaving as Newton’s theory predicted. One option in the face of these data would have been to abandon Newton’s theory. But the theory got so many things right that it seemed rash to discard it. Astronomers instead posited that the irregularities must be caused by another body exerting a gravitational pull on Uranus. That prediction was later confirmed, and led to the discovery of a new planet, Neptune.14
How do you know whether to hang on to a theory and hope that the anomalies will be explained later, or whether to ditch the theory? There are no hard-and-fast rules for making that decision. In general, the more data that a theory accounts for, the more willing scientists are to put up with a few things that it gets wrong. If the theory wasn’t very successful to start with and then you see observations that conflict with it, you’re less likely to continue believing it. Ultimately, it’s a judgment call. Reasonable people can differ on whether a theory ought to be abandoned or retained.
When data are mixed, they can become a Rorschach inkblot, revealing the prior beliefs of the viewer. Nowhere is that more apparent in education research today than in the evaluation of charter schools. Charter schools are public schools that have a special agreement with the state; they are subject to fewer regulations than other public schools, so teachers and administrators have more freedom to run the school as they see fit. In return, the school is subject to greater accountability to the state. The school must show that students are learning. (They also receive less money than other public schools, on average.)
Now if you believe that government is more often part of the problem than part of the solution, you probably believe that government regulations can’t be good for education. Thus you would deduce that charter schools, being freed from at least some regulation, will outperform other public schools. Some studies show that kids attending charter schools learn more than comparable kids attending other public schools,15 but other studies don’t show that.16 Such comparisons are complicated to conduct, for technical reasons I won’t go into here, but these technicalities give people ammunition with which to criticize studies that draw conclusions they dislike. So people looking at the same dozen or so studies draw polar opposite conclusions. And they think that the other guys ought to give up on their theory.
A final property of theories is especially important when we contemplate rejecting an old theory in favor of a new one. Good science is cumulative. That means that for a new theory to replace an old one, it must do what the old one did, and something more. Science is always supposed to move forward. That’s been one of the criticisms of pseudosciences like astrology.17 The failings of astrological theory are well known, and have been for a long time. Yet there is no attempt to use those failed observations to improve the theory. Attempts to advance astrology have been halfhearted, and the theory does not look much different from what it did hundreds of years ago.
A similar problem plagues theories in American education. Historians have pointed out that there is a pattern of education theories being tried, found wanting, and then reappearing under a different name a decade or two later.18 In the Introduction, I cited the case of whole-word reading, which was introduced in the 1920s and belatedly discredited in the 1960s. When the theory reappeared in the 1980s as “whole-language” reading, there were already ample data to show that this “new” theory was wrong. Scientific theory is supposed to be cumulative, and a new theory—which is what whole-language reading purported to be—should have been expected to account for existing data that were obviously relevant to the theory.
Earlier in this chapter, I mentioned the twenty-first-century skills movement. It provides a more recent example of theoretical retreading. The argument sounds perfectly plausible: our students spend too much time memorizing arcane bits of information. They don’t learn how to solve problems, how to be creative, how to think. Further, hasn’t anyone noticed that schooling hasn’t changed over the course of a hundred years? Kids sit at desks, lined up in rows that face the teacher standing before them. Kids today need education that is relevant in a world of Google and smartphones.
These very same concerns—that schooling must be made relevant to life and to work—have been voiced for more than a hundred years.19 In the 1920s, the idea was called progressive education. In the 1950s, it was called the Life Adjustment Movement. In the 1990s, it was the Secretary’s Commission on Achieving Necessary Skills (SCANS). As a consequence of each movement, school curricula were filled with projects that appeared to have real-world applicability, kids went on more field trips, and so forth. After about a decade, people started to notice that students lacked factual knowledge. They’d visited a sewage treatment plant and they’d created a school garden, but they couldn’t come within fifty years of the dates that the Civil War was fought. A “back to basics” movement followed, which emphasized factual knowledge and denigrated thinking skills as so much fluff. After about a decade of that, people would claim that the curriculum focused exclusively on facts and that kids didn’t know how to apply them to real-world problems. And the cycle would begin again.
Both factual knowledge and thinking skills are essential for students to be able to solve meaningful problems. Imparting both to students is difficult, there is no doubt. Unfortunately, we keep taking on this problem in the same ineffectual way. We address half of it, later despair of the other half, and then ignore what we were getting right in our rush to correct what was undone. Put this baldly, it seems incredible. Yet that has been the pattern.
The third and final aspect of the scientific process is testing a theory. We start with observations of the world, then we abstract summary statements from those observations, and then derive new predictions, things we believe that, under certain conditions, we will observe in the world. In the epigraph for this chapter, physicist Richard Feynman suggests that this step is the one that separates science from other ways of understanding the world. So what qualities do we look for in a scientific test?
Recognizing a good study versus a bad one boils down to keeping in mind a list of things that can go wrong, and successfully spotting if any of these traps or pitfalls is present. Table 3.1 is a list of the sorts of concerns one might have about a study in education research. You can skip the list if you want to. It’s really meant only to impress upon you that there are a heck of a lot of ways that you can screw up an experiment, and this list barely scratches the surface of the sort of methodological and statistical knowledge that one needs in order to conduct education research well.
TABLE 3.1: Some problems to watch for in education research studies.
| Problem | Example |
| Differential attrition (dropout) rates between groups | I might compare two tutoring methods for math. After six weeks, I find that kids receiving method A are doing better in math than kids receiving method B, so it looks as though A wins. But a closer look at the data shows that lots of kids getting method A quit the experiment during the six weeks, and very few getting method B quit. So it may be that those few kids who finished method A were an especially determined bunch, and were not really comparable to the kids getting method B. |
| Simpson’s paradox | Suppose a large city has been using a reading program for ten years. I examine the reading achievement scores and see that they have dropped significantly during that time. I might conclude that the program was a failure. But then I look at the scores of wealthy, middle-class, and poor children separately, and I find that reading scores have gone up for each of the three groups! How could overall scores drop if each group is gaining? Poor kids don’t score as well as rich kids, so if the percentage of poor kids in the city increased during that decade, the average score might drop, even though each separate group is gaining. |
| Experimenter expectancy effects | When an experimenter has an expectation as to what a subject is likely to do, the experimenter can, through body language or subtle intonations in instructions, communicate that expectation without meaning to. Many subjects will perceive this expectation and will try to live up to it, either in an effort to be helpful or in an effort to appear “normal.” |
| Nonrepresentative volunteers | If you are testing children in a laboratory, you must ask yourself, “Who has the time and inclination to bring their child to my lab during working hours on a weekday? Is this family different from other families in some way?” |
| Correlation versus causation | The fact that you observe that two factors are related doesn’t mean you can draw a causal link. For example, ice cream consumption and crime are correlated, but not because ice cream makes people criminals. Hot weather makes people want ice cream, and it also makes people more short tempered, which increases violent crime. Surprisingly often, people conclude cause-and-effect relationships from correlations—for example, the relationship of race and academic performance. |
| The end of the experiment | If subjects are aware that an experiment is about to end, they will typically try a little harder, so as to “go out with a bang.” These data will not be representative of the rest of the subject’s performance. |
| Types of sampling (how you pick the subjects for an experiment) | Random sampling: from a large group, a smaller group is selected, at random, for testing. Stratified: I first divide my overall group into subgroups (for example, men and women) and then sample randomly from each subgroup. This is done to ensure proportionate representation of subgroups when that’s deemed important. Haphazard (or convenience) sampling: you select people for your experiment based on whom you can recruit. This method is very likely to bias your results. Other types of sampling: cluster, purposive, quota. |
| Carryover effects in repeated testing | If the experimenter tries more than one intervention, the influence of intervention 1 can easily “carry over” to intervention 2. For example, a teacher might try one method of classroom management and then four weeks later try another. He must recognize that the class might respond to the second method differently than they would have if they had never experienced the first classroom management method. |
| Regression toward the mean | Suppose someone scores very poorly on the SAT. She then takes a test preparation course, and her score improves. We’re likely to think that the score went up because of the course. Perhaps not. If I take the SAT, my score will vary depending on which particular set of questions appears on the test I take, whether I’m feeling especially alert that day, and so on. If I get a really low score, that probably means I’m generally not going to score that well on the SAT, but also that I had an unlucky day too. So if I took it again, it’s likely that I would have a luckier day, and my score would be at least somewhat higher. (The same logic applies to people who get a very high score; their score is likely to go down if they retake the test.) |
Spotting strengths and weaknesses in research is a narrow skill. Someone who is quite good at sizing up one type of experiment will not be nearly as good at sizing up others. For example, I’ve been reviewing articles in cognitive psychology for about twenty years. Mostly those were studies of particular aspects of learning and movement control. When I became associate editor of a cognitive psychology journal, I covered a broader array of topics, but I was still one of six associate editors, each with his or her own specialty—and the journal didn’t even cover all of cognitive psychology!
This problem—the many ways that scientific studies can go wrong—puts me in mind of a moment from the movie Body Heat. An arsonist (played by Mickey Rourke) is visited by an attorney (played by William Hurt) who has helped him out of tough spots before. Now the tables have turned, and the attorney is planning a crime. He seeks the arsonist’s advice, and the arsonist says, “Anytime you try a decent crime, you got fifty ways you can [mess] up. You think of twenty-five of them, and you’re a genius. And you ain’t no genius.” Science, like crime, is complicated, and there are many ways it can go wrong.
The advantage that scientists have over criminals is that they don’t need to keep their work secret. In fact, they are forbidden from doing so. It’s so well understood that scientists can miss things that they are required to make their work open to scrutiny, so that others can criticize it and improve on it. To appreciate the nature and importance of this feature, let’s examine one of its more celebrated failures: the story of cold fusion.
It would be great if nuclear power plants could use fusion rather than fission, as they currently do. The energy produced by fusion is enormous; the required fuel—isotopes of hydrogen—can be found in water; and the radioactivity produced by the reaction is short-lived and harmless. Unfortunately, fusion occurs under conditions of enormous heat and pressure, meaning that it requires more energy to create the reaction than is released by it. Thus it has not been a practical source of energy.
Imagine the excitement, then, when two scientists—each a professor at a respected university—reported that they had produced a fusion reaction at room temperature. Stanley Pons and Martin Fleischmann did just that at a press conference on March 23, 1989. The odd thing about the announcement, however, was that they held the press conference before the experiments were published in a scientific journal. Publication in a scientific journal is the first sense in which science must be done “publicly.” Before your work is published, it will be sent to between two and five scientists familiar with the research topic. You will have described exactly how you did the work; they will make sure that the logic of the experiment and the conclusions are sound, and they will judge the importance of your findings. That’s the process commonly called “peer review.”
Pons and Fleischmann held the press conference before others had a chance to look carefully at what they did. And the details of the methods provided at the press conference were so sketchy that other scientists were frustrated because they couldn’t fully understand the nature of the experiment.20 Ultimately, the details of the experimental method were published, and many scientists attempted to reproduce the cold fusion results and failed.21 So you could say that the truth eventually won out.
The truth won out, but a lot of time and energy was wasted in the interim. Look at these headlines from the days following the press conference:
Researchers around the world stopped what they were doing and scurried to study and reproduce Pons and Fleischmann’s experiments. It turned out that the most important part of the finding—the observations that indicated a fusion reaction—were due to errors they had made in their experiments.22
So the most basic sense in which science is “public” is the peer review process. Other people must evaluate your work before it’s published. Another sense in which science is public concerns the manner in which it’s published. You can’t provide just a thumbnail sketch of what the experiment was like. You have to describe everything: characteristics of the subjects, model numbers of lab equipment, exactly what happened in the experiment, how the data were analyzed, and so on. The goal is to write a description of the procedure that is so complete that another researcher could do the experiment herself.
Being public about the methods of science is important not only because it’s hard to think of every possible objection to your work but also because scientists are subject to the confirmation bias too.23 When we conduct a study, we know what we expect to find, and we are likely to (unconsciously) skew our impression of the results to confirm our expectation. Again, the ever-quotable Richard Feynman: “The first principle is you must not fool yourself, and you are the easiest person to fool.”24
So what makes good science? I’ve named seven principles (Table 3.2). Table 3.2 could have been twice as long. And recall that just one of these principles—“scientific tests are empirical”—was the basis for another list of potential problems to watch for (Table 3.1), which itself could have been ten times longer. The implication is obvious. Judging whether or not a scientific claim is well founded requires a lot of thought and a lot of expertise. That creates problems for individuals and problems for practitioners.
TABLE 3.2: Seven principles of good science
| Stage of Scientific Method That Is Affected | Principle | Implication for Education |
| Entire cycle | Science is dynamic and self-correcting. | If we use the scientific method, we can reasonably expect to develop a deeper understanding of learning in school. |
| Observation | Scientific method applies only to the natural world. | Some important questions in education do not concern the natural world; rather, they concern values. |
| Observation | Scientific method works only if the phenomenon under study can be measured. | Some important aspects of education do concern the natural world, but the phenomena are difficult to measure. |
| Theory | Theories cannot be proven true. They can only be falsified, but when to abandon a theory as false is a judgment call. | The fact that it’s a judgment call must not prevent us from rejecting poorly supported education theories so that we can seek out better ones. |
| Theory | Good theories are cumulative. | Education has a history of reintroducing theories under a different name, even though the theory has been tested and found wanting. |
| Test | Scientific tests are empirical. | Interpreting empirical tests is always difficult, and doing so is much more difficult in education, where there are so many factors that might be causal. Evaluating these tests requires considerable expertise. |
| Test | Scientific tests are public. | Because science is so difficult to evaluate, it’s crucial that science be conducted in a way that allows everyone to evaluate it. Some of education research is peer reviewed, but not all of it. |
For the individual, the obvious problem is in knowing what the scientific evidence really says on complex matters. In a few instances—notably, the safety of medications—we are protected by laws. A new medication must pass a rigorous scientific screening process (in the United States, overseen by the Food and Drug Administration) before it can be sold. There are loopholes through which charlatans enter the marketplace with snake-oil remedies, but if a nonscientist wants to know what scientists think about an issue, it’s not hard to learn. Scientific consensus views are regularly published by institutions that scientists have created. If you want to know what the medical community thinks about the link between vaccines and autism, there are Web sites (for example, www.healthfinder.gov, maintained by the U.S. Department of Health and Human Services) that publish consensus statements. If you want to know whether a particular type of psychotherapy has scientific support, you can visit the Web site of the Society of Clinical Psychology.25 If you want to know what physicists think about climate change, you’ll find a statement on the Web site of the American Physical Society (and comparable groups in other nations). I know that some people don’t really trust the scientific community. That’s a different issue. I’m talking about access to the collective view of that community, and in most cases, you can get that view pretty easily.
Practitioners face a different problem. Suppose you’re a doctor. You go through medical school and residency, learning the most up-to-date techniques and treatments. Then you go into family practice, and you’re an awesome doctor. But science doesn’t stand still once you’ve finished your training. You were up-to-date the year you graduated, but researchers keep discovering new things. How can you possibly keep up with the latest developments when, according to PubMed.gov, more than nine hundred thousand articles are published in medical journals each year?26 Medicine has solved this problem for practitioners by publishing annual summaries of research that boil down the findings to recommendations for changes in practice. Physicians can buy summary volumes that let them know whether there is substantial scientific evidence indicating that they ought to change their treatment of a particular condition. In other words, the profession does not expect that practitioners will keep up with the research literature themselves. That job goes to a small set of people who can devote the time needed to it.
In education, there are no federal or state laws protecting consumers from bad educational practices. And education researchers have never united as a field to agree on methods or curricula or practices that have sound scientific backing. That makes it very difficult for the nonexpert simply to look to a panel of experts for the state of the art in education research. There are no universally acknowledged experts, a topic I’ll discuss in some detail in Chapter Six.
Every parent, administrator, and teacher is on his or her own. That’s why I wrote this book. But before we can talk about spotting good science amid fraud, we must cover one more topic. We’ve talked about what properties scientists look for when considering whether science is well done, but we haven’t yet talked about what to do with good scientific findings. The lab, after all, is not the classroom, and how to move from one to the other is not obvious. That is the subject of Chapter Four.
a I have experienced this anxiety. There was a 5.8 magnitude earthquake in Mineral, Virginia, on August 23, 2011, about thirty miles from my home.
b This is called the hypothetico-deductive model of science because you use a theory to deduce a hypothesis, which is then tested. Philosophers of science were quick to point out that there are logical problems with this model, among them that too many theories can make the same predictions. A more constrained version of this model is called “inference to the best explanation,” in which you’re not happy with just any model that fits the data but with the simplest model that, if correct, would explain the data. These concerns are beyond our purposes here, and in point of fact most scientists don’t often think about the logical implications of the methods they use. But it should at least be acknowledged that there’s a logical issue here. For relatively readable introduction to these very complex issues, see Newton-Smith, W. H. (2001). A companion to the philosophy of science. Malden, MA: Blackwell.
c Of course, that doesn’t mean that if it’s old, it’s wrong. My colleague Angeline Lillard has argued that one hundred years ago, Maria Montessori anticipated many findings of modern science in regard to children’s cognitive development. Lillard, A. (2005). Montessori: The science behind the genius. New York: Oxford Press.
d For example, Felice Bedford, a friend and colleague at the University of Arizona, published an article in 1997, much of which argued that I had committed a logical fallacy in making a particular claim about learning. I think the claim ended up being well supported for other reasons, but she was right about the fallacy. Bedford, F. L. (1997). False categories in cognition: The not-the-liver fallacy. Cognition, 64, 231–248.
e Applying the scientific method to questions of ethics has been tried, notably by John Dewey. See, for example, Dewey, J. (1903). Logical conditions of a scientific treatment of morality. Decennial Publications of the University of Chicago (First Series), 3, 115–139.
Notes
1. Feynman chaser—The key to science. [Video]. YouTube. http://www.youtube.com/watch?v=b240PGCMwV0.
2. Prasad, J. (1950). A comparative study of rumours and reports in earthquakes. British Journal of Psychology, General, 41, 129–144.
3. Festinger, L. (1957). A theory of cognitive dissonance. Evanston, IL: Row, Peterson.
4. Festinger, L., & Carlsmith, J. M. (1959). Cognitive consequences of forced compliance. Journal of Abnormal and Social Psychology, 58, 203–210.
5. Aronson, E. (1968). Dissonance theory: Progress and problems. In R. P. Abelson, E. Aronson, W. J. McGuire, T. M. Newcomb, M. U. Rosenberg, & P. H. Tannenbaum (Eds.), Theories of cognitive consistency: A sourcebook (pp. 5–28). Chicago: Rand McNally.
6. Carlsmith, J. M., Collins, B. E., & Helmreich, R. L. (1966). Studies in forced compliance: I. The effect of pressure for compliance on attitude change produced by face-to-face role playing and anonymous essay writing. Journal of Personality and Social Psychology, 4, 1–13.
7. Sagan, C. (1987). Keynote address to the Committee for the Scientific Investigation of Claims of the Paranormal (today known as the Committee for Skeptical Inquiry).
8. Hawking, S. (1988). A brief history of time. New York: Bantam.
9. Levy, F., & Murnane, R. J. (2004). The new division of labor: How computers are creating the next job market. Princeton, NJ: Princeton University Press.
10. Plucker, J. A., & Makel, M. C. (2010). Assessment of creativity. In R. J. Sternberg & J. C. Kaufman (Eds.), The Cambridge handbook of creativity (pp. 48–77). Cambridge: Cambridge University Press.
11. Cannon-Bowers, J. A., & Bowers, C. (2011). Team development and functioning. In S. Zednick (Ed.), APA handbook of industrial and organizational psychology: Vol. 1. Building and developing the organization (pp. 597–660). Washington, DC: American Psychological Association.
12. Popper, K. (1959) The logic of scientific discovery. New York: Basic Books.
13. I cannot find a source for this quotation. One author suggests that it is a paraphrase of things Einstein said in “Induction and Deduction,” a paper published in 1919. Calaprice, A. (2011). The ultimate quotable Einstein. Princeton, NJ: Princeton University Press, p. 476.
14. Grosser, M. (1962). The discovery of Neptune. Cambridge, MA: Harvard University Press.
15. For example, Hoxby, C. M., Murarka, S., & Kang, J. (2009, September). How New York City’s charter schools affect achievement. Cambridge, MA: New York City Charter Schools Evaluation Project. Available online at http://www.vanderbilt.edu/schoolchoice/documents/092209_newsitem.pdf; Sass, T. (2006). Charter schools and student achievement in Florida. Education Finance and Policy, 1, 91–122.
16. For example, Bettinger, E. P. (2005). The effect of charter schools on charter students and public schools. Economics of Education Review, 24, 133–147; Bifulco, R., & Ladd, H. F. (2006). The impacts of charter schools on student achievement: Evidence from North Carolina. Education Finance and Policy, 1, 50–90; and Zimmer, R., Gill, B., Booker, K., Lavertu, S., & Witte, J. (2012). Examining charter student achievement effects across seven states. Economics of Education Review, 31, 213–224.
17. For example, Feyerabend, P. (1978). Science in a free society. London: New Left Books.
18. Ravitch, D. (2000). Left back: A century of battles over school reform. New York: Touchstone.
19. Ravitch, D. (2009). 21st century skills: An old familiar song. Available online at http://www.commoncore.org/_docs/diane.pdf.
20. Wilford, J. N. (1989, April 24). Fusion furor: Science’s human face. New York Times. Available online at http://select.nytimes.com/gst/abstract.html?res=FA0716FE38580C778EDDAD0894D1484D81&pagewanted=2.
21. Browne, M. W. (1989, May 3). Physicists debunk claim of a new kind of fusion. New York Times. Available online at http://partners.nytimes.com/library/national/science/050399sci-cold-fusion.html.
22. Ibid.
23. For example, Kaptchuk, T. J. (2003). Effect of interpretive bias on research evidence. British Medical Journal, 326, 1453–1455; Mynatt, C. R., Doherty, M. E., & Tweney, R. D. (1977). Confirmation bias in a simulated research environment: An experimental study of scientific inference. Quarterly Journal of Experimental Psychology, 29, 85–95.
24. Feynman, R. P. (1985). Surely you’re joking, Mr. Feynman! New York: Norton, p. 343.
25. Society of Clinical Psychology. (n.d.). Psychological problems and behavioral disorders. Available online at http://www.psychology.sunysb.edu/eklonsky-/division12/disorders.html.
26. Source: PubMed.gov, accessed June 10, 2011.