9
Some Practicalities of Monetising Data
9.1 Introduction
This chapter addresses the practicalities of a company monetising their data in order to diversify. As monetising data is a new concept, you need to know your customers well to understand what they need and what will interest them, how much they will value the data and the insights it brings, how to approach and attract them and so on. Each of these aspects of the monetising process is of key strategic importance for your business. Guidelines for maximising the benefits from data analytics include communication tips, awareness of techniques for cascading the techniques to other areas, plans for ongoing data improvement, methods to sustain the gains you have made and ensuring that the business benefits continue to grow. Hence this chapter is about business opportunities and uplifting your business.
9.2 Practicalities
9.2.1 Reviewing the Market
Before any monetisation is carried out, we need to make sure we know the market: who will be interested, how they will value the insights from big data and how we can best communicate with them. There is no short cut to this understanding, and the work starts with reviewing trends and looking at what competitors are doing. It is important to realise that the company itself is an internal customer for its own data analytics.
We can think of innovative ways to find out what is going on in the market, including the web, articles, trade fairs and so on. However, trends may not necessarily be relevant to your particular customers, so you have to know them very well. To do this you may need to carry out a customer survey, either informally or formally using a survey questionnaire. You must also use all your customer data to give you clues, looking at what has sold well and in what direction the trends are. Of course, this also includes web analytics, showing who visited your website and what they were interested in.
As you can see, monetising data is no different to selling any other product and needs the same extensive preparation and research.
9.2.2 Marketing Data Services
Data as a product is currently a relatively new concept, but as people become more aware of the importance of data, they will be more likely to demand data‐driven information and services. Data becomes a resource that can be traded raw or pre‐processed, notwithstanding limitations due to local ethics and legal standards. Insight usually comes from pre‐processed, sensitively presented data with a versatile user interface. However, the following section refers to insights from either raw or processed data.
General principles of marketing apply to monetising data, and eight generic factors are generally recognised when introducing a new product:
- value for money
- brand name
- country of origin
- top of the range
- service
- selectivity
- attractiveness
- reliability.
We can interpret the eight generic factors with specific reference to monetising data:
- Value for money is particularly important with a novel product like the insights from data, since people are not sure of its worth and there is no tradition of its use. Proving the value is easier if baseline KPIs are obtained.
- Brand name refers to issues of trust. Data brokers and insight innovators need to prove their worth through professional credentials and a portfolio of previous work. They should try to be extrovert and proclaim their achievements, even though this may not come naturally.
- Country of origin refers to the relevance of the data and also if there is an influence of culture and ethics on the way the data is collected and grouped and interpreted in relation to background knowledge.
- Top of the range refers to a check that the data is in the most relevant format and units, even when sold alone or with analytical services.
- Service is the reminder that we have to provide good‐quality data and a facility for answering questions and problems that may arise when the data is used by the purchaser.
- Selectivity refers to the right data being available.
- Attractiveness is particularly important because what you are selling is unusual. To show the data in its best light, you may need to give samplers to show its potential value. The simile is product testers which are used to demonstrate the product in real life to show its strength and dimension. Good case studies need to be prepared or sourced.
- Reliability refers to the sales process as well as the product. Reliability implies trust and is particularly important with data because each item has a vital role to play and may lead to different strategic decisions. The chaotic nature of business life means that there are a lot of different noise factors influencing data. Often patterns caused by underlying systematic variations, such as seasonal changes, may be masked by the effect of an economic announcement or a competitor going bankrupt. The data is only as reliable as your knowledge of the business world. Business is reflected in its data. If the signal from underlying trends is weak then the chaotic noise can have a big influence and small changes may make a big difference to the data and to the conclusions drawn from it. Underlying patterns may be hidden whilst a model is constructed but may suddenly become more pronounced, upsetting the model and making it misleading. So data and models are subject to highly disruptive influences, and it has to be accepted that reliability cannot be assured.
9.2.3 Project Management to Achieve Data Monetisation
To achieve data monetisation and uplift a business it might be helpful to follow a step‐by‐step process, starting with asking the right questions. Even if you know that your data is valuable, you have to think about what part of it is the most valuable and whether additional data is needed. For example:
- Do you have access to all necessary analytical methods?
- What is the best level at which to analyse the data?
You have to decide how much time can be allocated to the analytical process and also what timescale is appropriate for the data in terms of granulation and time period. It might be useful to think about enriching your data by integrating it with third‐party data. This may affect the architecture, technology and methods used to analyse the data. These steps are illustrated in Figure 9.1. They follow the familiar project management process. At the end of this process you are ready to monetise your data.
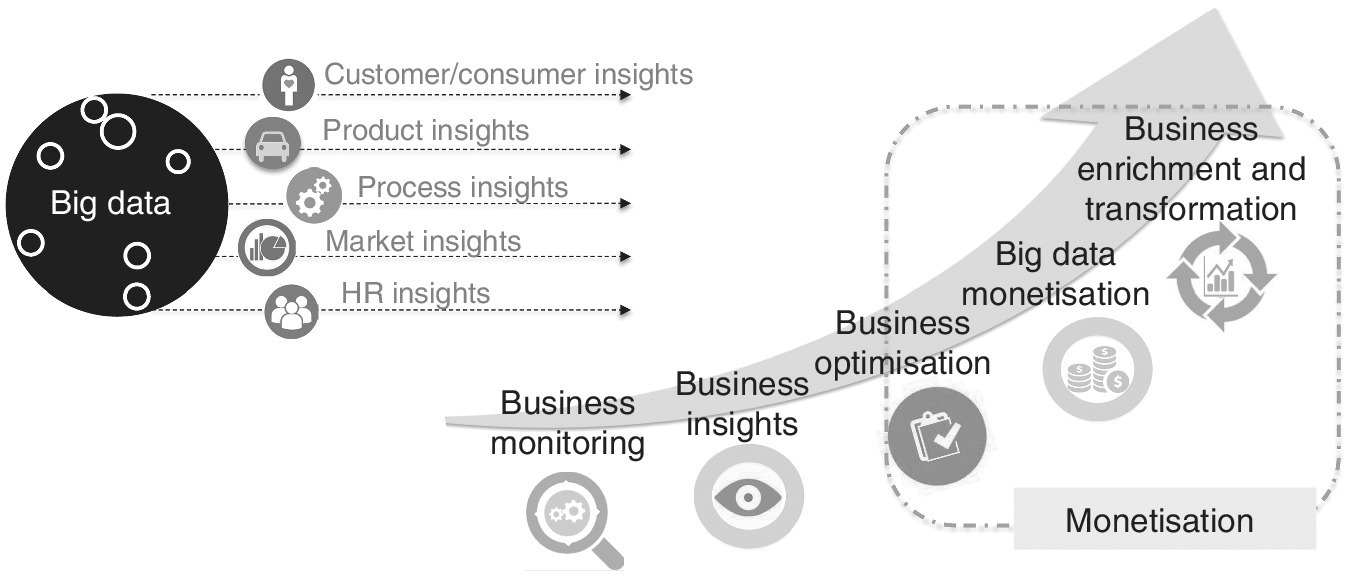
Figure 9.1 Paths to monetisation.
The monetisation offering at the end of the process has to be attractive. How do we make the customer want it? One way is to prepare examples to show potential customers. We can consider showing the data richness, quantity and quality by preparing graphs and giving data descriptions and summaries.
9.2.4 Exemplars
For example, Figure 9.2 shows the customer compliments received over a one‐year period. The horizontal axis shows the richness of the data, the vertical axis shows the numbers of compliments and the number of unclassified ‘Other’ compliments indicates the quality of the data analysis.
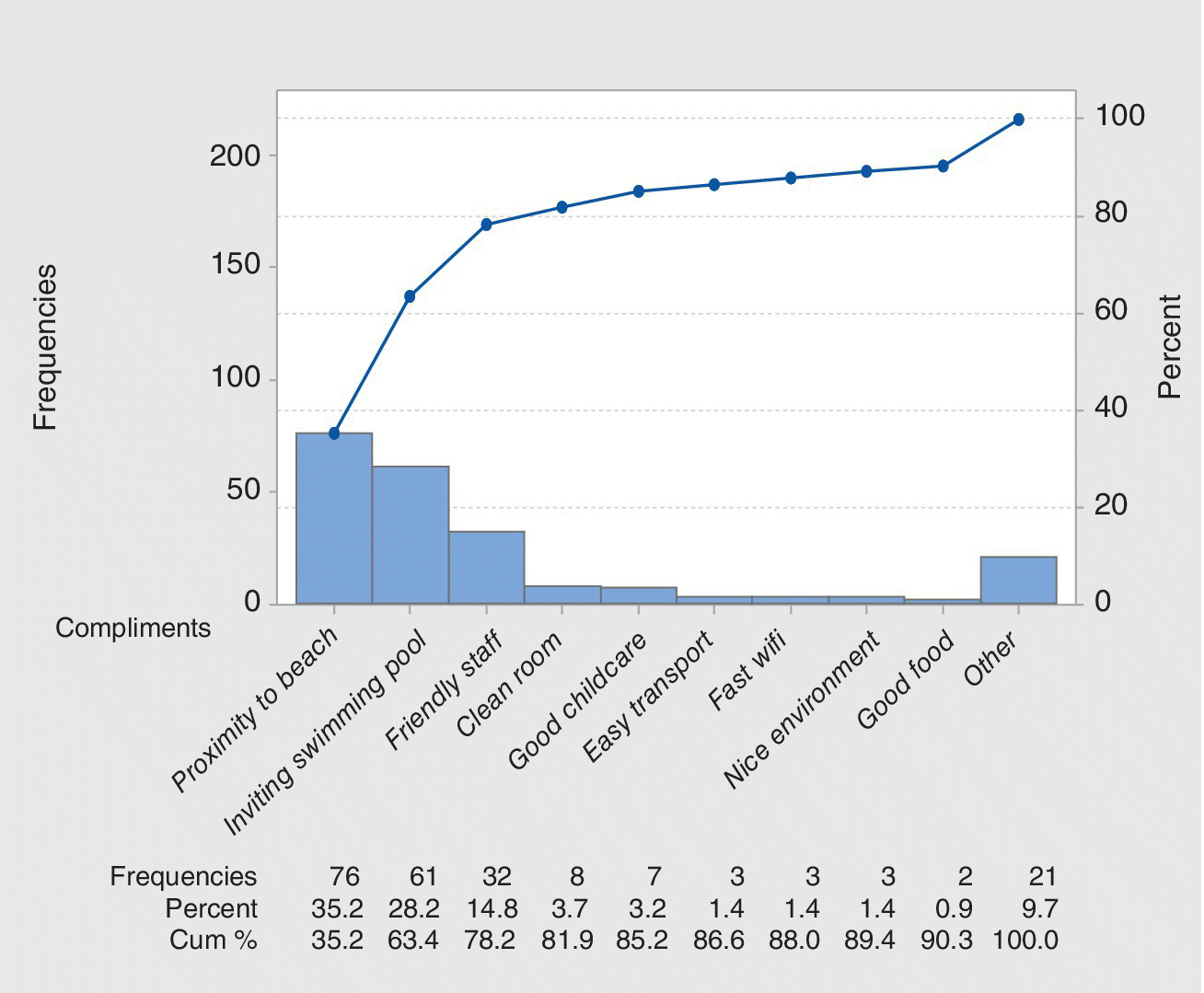
Figure 9.2 Pareto diagram of customer compliments.
There are obvious issues around preparing such sample analyses. For example, most organisations would not wish to share their data in advance of paying for data analytical services and statistical help. If we use made‐up data the chart inevitably lacks realism.
What information do you provide? It is preferable to include a narrative to bring out business insights as well as showing the data. So for Figure 9.2, the narrative should note that there are three causes of compliments that occur with high frequency and these should receive the most attention.
Exemplars need to have:
- clarity
- credibility
- consistency
- competitiveness.
The exemplars need not be just individual graphics, but can present a whole new image. For example, we can showcase the new data‐oriented approach by incorporating several ideas in a dashboard. In Figure 9.3 some of the graphics are likely to be familiar to the organisation but some are new.
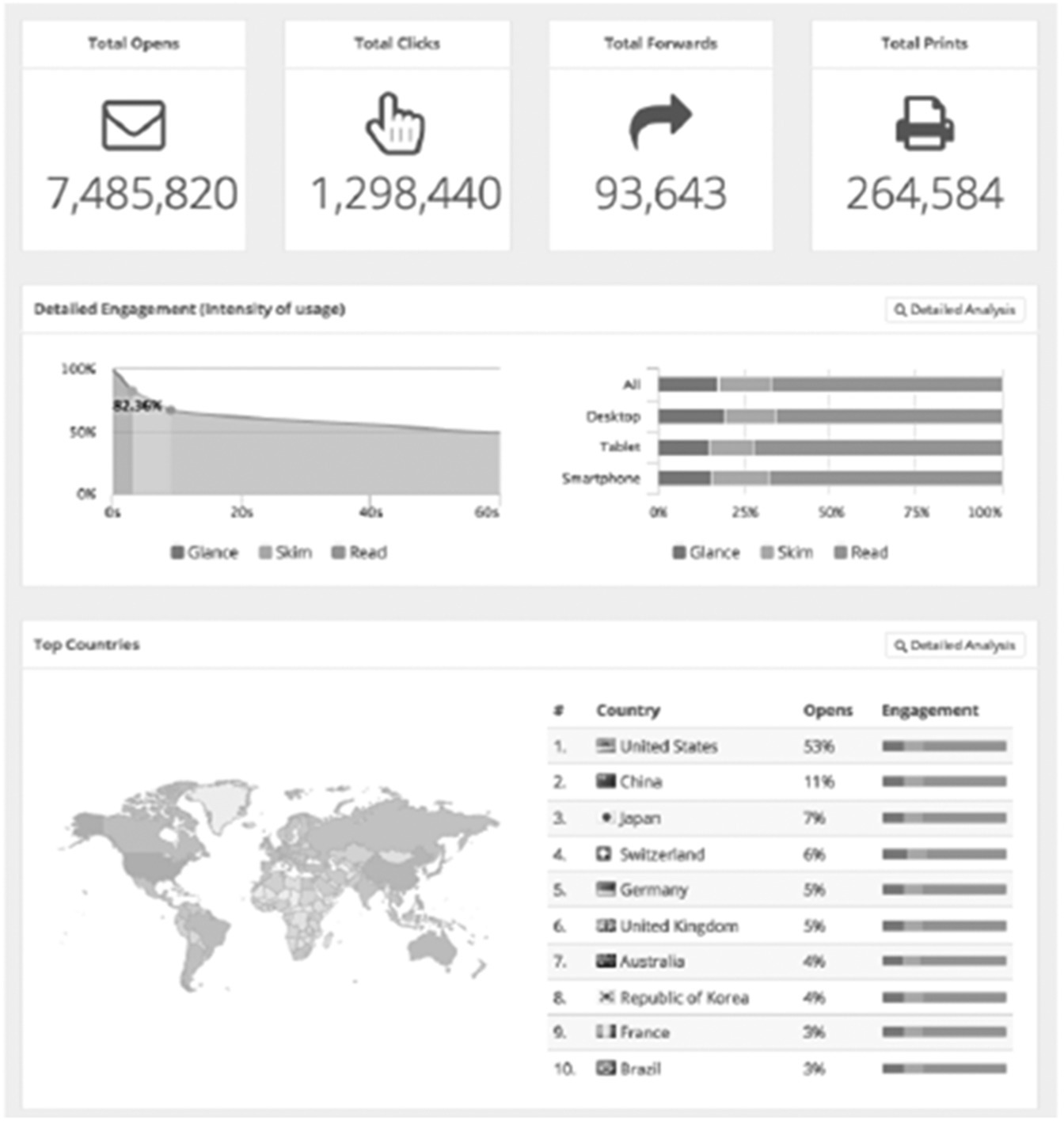
Figure 9.3 Graphical dashboard.
9.2.5 Maximising the Benefits
The more bespoke the data, the greater the potential value because it cannot be obtained by anyone else. This is especially true for data extending back historically, or arising from a specific opportunity. It may have cost a lot in time and resources to collect the data. This all adds to its uniqueness and attractiveness. The data were generally collected for another purpose and so have the disadvantages associated with secondary data. However, these disadvantages are far outweighed by the advantage of the data being readily available, and not requiring extensive effort and expense to obtain.
Value is vested in
- timescale
- specificity of the items
- uniqueness
- quality and reliability
- completeness
- permission for range of uses already granted
- barriers overcome to get the data.
It is not always clear who owns the data and whether they are likely to share it, and if not how much you would have to pay to access it.
Having made the business offering, how do you know if it met the mark? How do you know whether it is in the best format for the customer? Again, there is no substitute for hard work aimed at understanding the customer. Standard business practices are relevant, including gathering feedback and acting on it.
There are many stakeholders in a data transaction. The way that data products earn money depends on which stakeholder is buying. It is not straightforward to decide how to price the insights from data.
Data monetisation can lead to different types of profit. We can consider profit from new products, new customers, increased sales, higher‐value products, greater efficiency and utilisation of resources.
Moving on from monetising data, this new data focus and data analytical awareness has a knock‐on effect in the rest of the business. It leads to greater care and attention in ensuring the quality and completeness of data, it raises the profile of the data collectors and leads to new business ideas. Data improvements feed into the continuous cycle of improvement and help to make the business more interesting and more profitable.
The knowledge gained from carrying out data monetisation is a valuable commodity for the organisation. It is vital to keep good records of what has been done. Experienced staff are precious; they (as all staff) need to be nurtured and kept motivated. As more and more businesses enter the data analytics field, the prospects for experts increase and the temptation to poach staff and for staff to move jobs can be a real threat, particularly to small and medium businesses. Staff turnover, however, can be positive in that new ideas come into the business and there is a chance of sharing best practice across the industry.
9.3 Special focus on SMEs
9.3.1 Context
Many small and medium enterprises (SMEs) possess large quantities of data, and are realising that, rather than being detrimental in terms of collection and storage costs, their data is valuable. SMEs are increasingly aware of the importance of big data analytics but few know how to apply analytical techniques to their own businesses.
As well as using data for operational purposes, SMEs can get financial rewards if their data is analysed, re‐processed, re‐purposed, packaged and sold for the insights it provides into customer use of products and services.
Organisations generally keep data analysis outputs in house; they don’t sell the insights, but use them to improve their own internal processes and marketing. However, SMEs can sell these data insights to relevant customers for product development or for market intelligence. The monetary value for the company therefore lies in selling the insights derived from the data, not the raw data itself.
Both data broker and insight innovator may be viable options for SMEs depending on their situation. Business models may be considered to have nine key elements:
- key partnerships
- key activities
- value propositions
- customer relationship
- customer segment
- key resources
- channels
- cost structure
- revenue stream.
These key elements are illustrated in Osterwalder’s model canvas. The business models for data brokers and insight innovators are compared and contrasted in Table 9.1. Many of the key elements are shared by both data brokers and insight innovators. The aspects that are specific to one or the other are indicated in the table.
Table 9.1 Business model canvas of the comparisons between data brokers and insight innovators.
Source: Osterwalder and Pigneur, 2013.
| Key Partnerships | Key Activities | Value Propositions | Customer Relationship | Customer Segment |
| Data holding bodies and organisations For IIs: data analytics organisations |
Data collection System creation and maintenance For IIs: data manipulation data mining and modelling |
Data full or sampled For IIs: Insight; data models; analytics |
Email Post Phone Face‐to‐face Online For IIs: Conferences and webinars |
Companies and organisations capable of handling and analysing data For DBs: insight innovators For IIs: Companies who want actionable insight, without having to analyse data |
| Key Resources Standard software Database management For IIs: Analytical software and personnel |
Channels Post Phone Face‐to‐face Online For IIs: Conferences and webinars |
|||
| Cost Structure | Revenue Stream | |||
| Hardware Software: standard/database management/ Personnel: data specialists and statisticians For IIs: Expert statisticians | Sales generated from offering data For DBs: Sales generated from offering clean and refined data to customer to analyse or for other purposes For IIs: Sales generated from offering insights and models |
|||
DBs, data brokers; IIs, insight innovators.
The growth of strategic and innovative decisions based on insight has advanced with the big data boom and increasingly, 21st‐century organisations aim to use big data as a resource to increase profits and efficiency. Computing power has grown exponentially and is increasingly accessible and cost‐effective. However, despite the availability of data manipulation tools and analytical software, SMEs report difficulty in understanding what IT would satisfy their requirements. There are other barriers such as a lack of skilled personnel, tight finance and a risk averse culture.
Being an insight innovator provides greater potential for revenue generation than merely providing raw data but requires more effort in terms of IT and data analytics. Due to advances in data analytics and having the IT means to facilitate data manipulation, access, analytics and presentation, and a far greater understanding of data, more organisations will become insight innovators.
9.3.2 Selection of Suitable IT Delivery
The question of how to create the interface between the data and the user to extract insight is quite complex. It requires controlled access to data and bespoke functionality. The company may have software in place already, or need to purchase new software or to extend the duties of IT specialists.
SMEs often have problems selecting appropriate IT and even companies that have IT resources may not understand or fully utilise its functionality. The first step therefore is to audit current software capabilities. If the company discovers that its ad hoc database structures have suitable functionality then this can be used to provide the new facilities. An alternative is to introduce new systems such as proprietary data handling software or bespoke algorithms constructed in free ware such as R. IT personnel are usually fully occupied in any business. Strategic commercial decisions are required to extend their work into providing or developing a new functionality.
To enable insights to be gained (these are different for each company) it is critical to trial offline options and to test the market. This includes obtaining motivating examples of the sort of insights that could be obtained if the company decides to go ahead with monetising its data. The next step, therefore, is for the company to construct offline insight case studies and showcase them to a variety of stakeholders to get their feedback and support. If the insight case studies are well received the company should be willing to invest in extra IT personnel and hardware to facilitate the extra data interrogation.
9.3.3 Stakeholder Analysis
Companies have a wide range of stakeholders, including customers, investors, policy makers and suppliers. Stakeholder analysis feeds into many parts of the business plan and should be carefully reviewed as part of the decision on how to monetise company data.
Any company wishing to be a data broker or an insight innovator has to evaluate and understand its data offering, and review the different stakeholders who may be interested in these different propositions. For example, customers who have purchased a bespoke product from a company may expect to see the historical trends. In addition, the company can offer comparisons with other people’s usage and only the company can provide this information and potential insight. It should be noted that if a company only has a small number of customers then sharing data across customers will not be possible because of commercial sensitivities. In this case the data can be shared within the customer's business. If there are a large number of customers, as for an expert system or advice service, then the customer data, suitably redacted, and insights from it can safely be shared.
An important stakeholder is the company itself. It is an internal customer for its own insights, which generate knowledge and understanding, increase financial growth and drive the internal business improvement process through development of new products and services.
9.3.4 Relational Matrix
The data dimensions open up a wide range of possible insight offerings for the company’s different stakeholders. Each dimension and stakeholder combination can be shown as a cell in a relational matrix. The importance of insight based on a particular data dimension for a particular stakeholder can be assessed by discussion with stakeholders and company personnel. Each cell within the relational matrix is then given a number of ticks showing the level of importance. An example is given in the case studies.
Different stakeholder groups have different requirements and preferences for how the insight should be delivered. Some may prefer reports, some an immediate, transient interaction. These preferences should be determined at this stage.
This matrix can help the company form clear data analysis priorities and strategies identifying what the data analytical focus should be in targeting any of the stakeholders. It also helps with insight evaluation, as it shows that various dimensions are more or less valuable to different stakeholders. This information helps inform the best costing methodology for the revenue to capture the most value.
The relational matrix can be used to provide a cost‐based argument and analysis of whether to become a data broker or an insight innovator. For example, too few stakeholders putting too little value on the insight could indicate the company would be better off functioning as a data broker. Alternatively, stakeholders being confused by the raw data merit being offered insight. After this key evaluation, the appropriate monetisation method for the insight can be identified.
9.3.5 Monetising the Insight
SMEs tend to be led by domain specialists, who therefore judge their success in terms of their domain rather than on their use of their data resource. They are often prone to firefighting because they have few technical staff. Data leaks are more common in SMEs because they tend to have older, less sophisticated IT systems. SMEs often have financial constraints, having a low cash flow but also finding it difficult to get funding because of asymmetric information. This is where exemplars can help because the SME can then show for what purpose they want the funding.
It can sometimes be difficult to find consultants to help. The larger consultancy companies prefer larger jobs than to deal with an SME, in the same way as it is hard to get a plumber to fix a tap when there are others wanting a whole central heating system installed. SMEs may have intrinsic conservatism and a culture that has an aversion to gimmicks and flavours of the month. As more case studies become available they are more likely to trust that there is something worth pursuing.
9.3.6 Summary
The following stepwise data analytics methodology is recommended for any SME wishing to monetise the insight from its (big) data:
- Describe the business, for example using the business model canvas.
- Consider IT options for data manipulation, access, analysis and presentation.
- Audit data, identifying data dimensions; enrich the database with publicly available data to create an integrated data resource; create exemplar insights.
- Carry out stakeholder analysis, discuss exemplar insights with stakeholders, determine appropriate reporting mechanism for each group of stakeholders.
- Construct relational matrix and tick each cell according to importance of insight.
- Determine suitable business model and revenue strategy.
- Create the insight platform.
- Monitor the usage and performance; continuously improve.
9.4 Special Focus on B2B Lead Generation
9.4.1 Context
Everyone knows that marketing processes are becoming more digital; customers and markets get smarter and more dynamic every day. All stakeholders, including companies and organisations, are leaving more and more digital data traces, which means that the available data volumes are increasing exponentially. Clearly, this development should impact on new lead generation in B2B.
In the traditional, analogue world, address lists and industry dictionaries are compiled using data from different sources. But this data is updated only at large intervals and neither represents the current interests, topics and developments nor the rapid change in the B2B market. On the other hand, the digital world offers a new universe of possibilities for collecting data and getting detailed insights that will lead to addresses that could be used to generate business leads. To exploit these possibilities needs new analytical methods, and agile communication tools united in a largely automated system.
9.4.2 Data to Think About
Firstly, we look closely at our best existing customers. However, the characterisation by industry, number of employees, sales, location and other classic company master data is no longer sufficient. In real life, relationships to real people are not formed only on the basis of profession, gender, age, family status, income and place of residence. Personal skills, values, interests, circumstances and peculiarities are also or even more important. With B2B relationships it’s the same.
Therefore, a truly complete picture of the best existing B2B customers is required and this should embrace many different aspects of the target companies and the relevant contact people (see Figure 9.4).
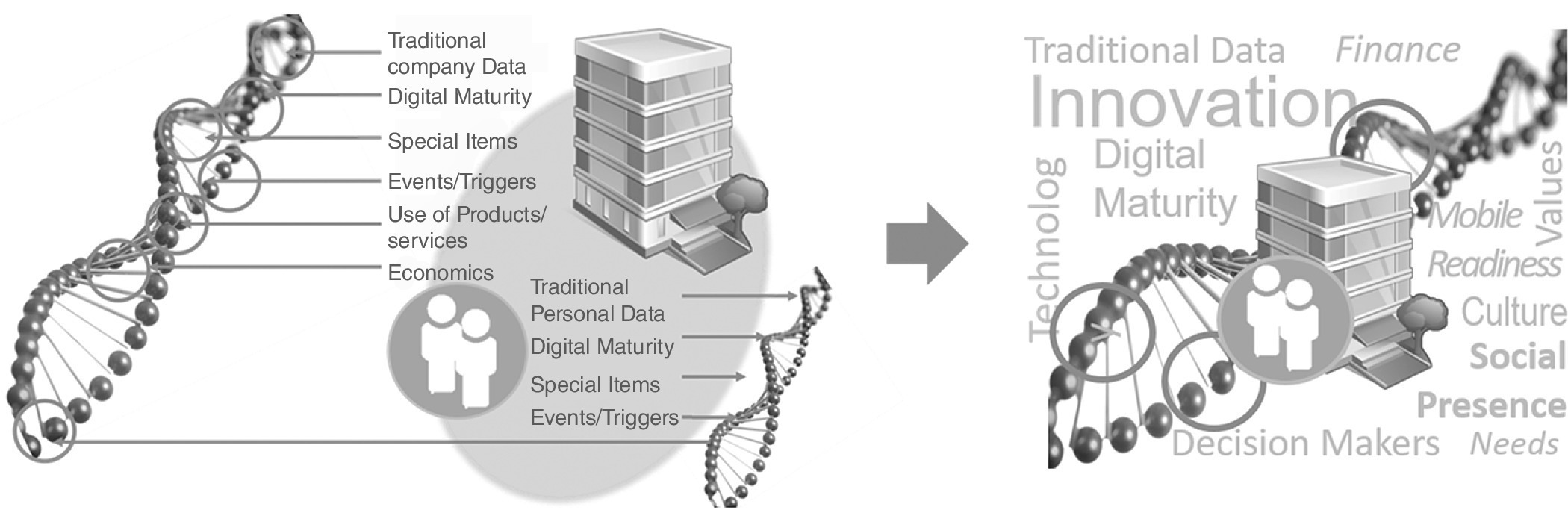
Figure 9.4 Decrypting the DNA of the best existing customers.
This complete picture should include:
- traditional data
- specific interests and topics currently motivating companies
- digital maturity of companies
- events triggering purchase decisions
- information about contact people
- use of the purchased products and services
- economics.
These aspects are now described more fully.
9.4.2.1 Traditional Company Data
Company name, organisation form, branch, location – this information can be found in official directories, at list brokers, or directly on the website of companies, as well as further information such as turnover and number of employees. Traditional data of existing customers also takes in information from the past, stored in your CRM system: prior responses to sales and marketing activities, order frequency, last advertising contact, payment behaviour and so on.
9.4.2.2 Specific Interests and Topics Currently Moving Companies
This area is where advanced analytics comes in. On their web pages, companies present their current interests. To gain valuable insights from such web pages, text mining methods including neural networks are used. During training, these methods learn the distributional representations of words and abstract their semantic sense. Words with similar meanings appear in clusters that reproduce word relationships, such as analogies. The analysis uses vector mathematics, such as in the example: ‘king – man + woman = queen’.
The insights generated allow greater granularity when determining the range of fields and activities. For example, in addition to the meta‐term ‘coatings manufacturers’, a distinction can be made between manufacturers of:
- paints for the automotive, shipping or domestic markets
- home exterior paints for the retail market
- specialist furniture coatings.
This is of great commercial interest for a manufacturer of chemical components for paints, because different product environments have specified needs and require different ingredients. By continuously updating these insights, new developments and trends in general and in specific industries as well as in individual companies can be identified early.
9.4.2.3 Digital Maturity of Companies
In order to assess the extent to which a company or organisation has advanced in digital transformation, a score for digital maturity is calculated. This key figure can be found by crawling the company’s website and social media activities. It can be used to segment companies according to the degree of their digital maturity. Factors that influence digital maturity are illustrated in Figure 9.5.

Figure 9.5 Aspects of digital maturity.
Depending on the industry a company belongs to, the digital maturity varies. The more this industry needs to be found on the web, for example by customers, as a brand or for recruiting employees, the stronger is their digital maturity. An online shop usually has a higher digital maturity than a local craft shop or a supplier of specific items as part of a supply chain.
Digital maturity also allows conclusions to be drawn about the overall degree of innovation of a company compared to its competitors. This key figure creates another valuable insight and is a strong differentiator for companies belonging to the same industry.
9.4.2.4 Events Triggering Purchase Decisions
It is illuminating to find out which events in the life of a company have had a positive impact on business. Have there been higher sales in the past round a company anniversary, a change in management, or after a company has won a prize or award? What was the impact of global or local events, legal amendments, or the hot two weeks in summer last year?
Domain knowledge and the experience of the sales team is indispensable. These industry‐dependent events and triggers can be added to data used for model building,
9.4.2.5 Information about Contact People
What applies to the company's level also applies to the level of the people belonging to the company’s purchasing function with whom we deal. They are the contacts we want to fascinate with campaigns and offers. That is why a comprehensive, dynamic picture of them has to be created too, including traditional data such as their name, gender, age, position in the company, academic titles and so on. This individual profile is enriched by information about their specific interests and topics (statements, posts on business‐related social networks, publications and so on) and individual digital maturity. If known, reactions to general and private events are included as well. For example, which head of a purchasing department is unhappy about the special offer they received following their publication of an article in a specialist magazine, or about the congratulations they received around a company or employment anniversary? In any case, this information provides very valuable insights for existing customer care.
9.4.2.6 Use of the Purchased Products or Services
Customers use our products and services – but how do they use them in detail? For example, one needs our special varnish for everyday furniture, and another uses it to seal the wooden fittings of a prestige vehicle. Or the software programmed by us – it was implemented by some existing customers in the CRM system and used by others to control newsletter campaigns.
What feedback or suggestions for improvement have existing customers given to our products and services so far? Maybe the answers to this question will open up new application possibilities and thus new target groups for our offers.
9.4.2.7 Economics
Data on the economic success of companies is readily available in a timely manner from traditional data sources, annual reports, press articles, and so on. Further indications of a company’s prosperous economic situation are, for example, stable or growing employee numbers, the current state of the technology used, the positive state of the respective industry and the positive assessment of its future development.
All the data collected and analysed so far are dynamic; that is why they must be constantly updated and re‐analysed in order to keep the profiles (the DNA) of the companies and contacts up to date. In addition, the domain knowledge and experience of a good sales team should be updated and taken into account regularly in order to derive the maximum benefit from the available data. One thing is clear: these multidimensional features can only be mastered using data analytics – in particular web mining, text mining, deep and machine learning algorithms (see Figure 9.6).
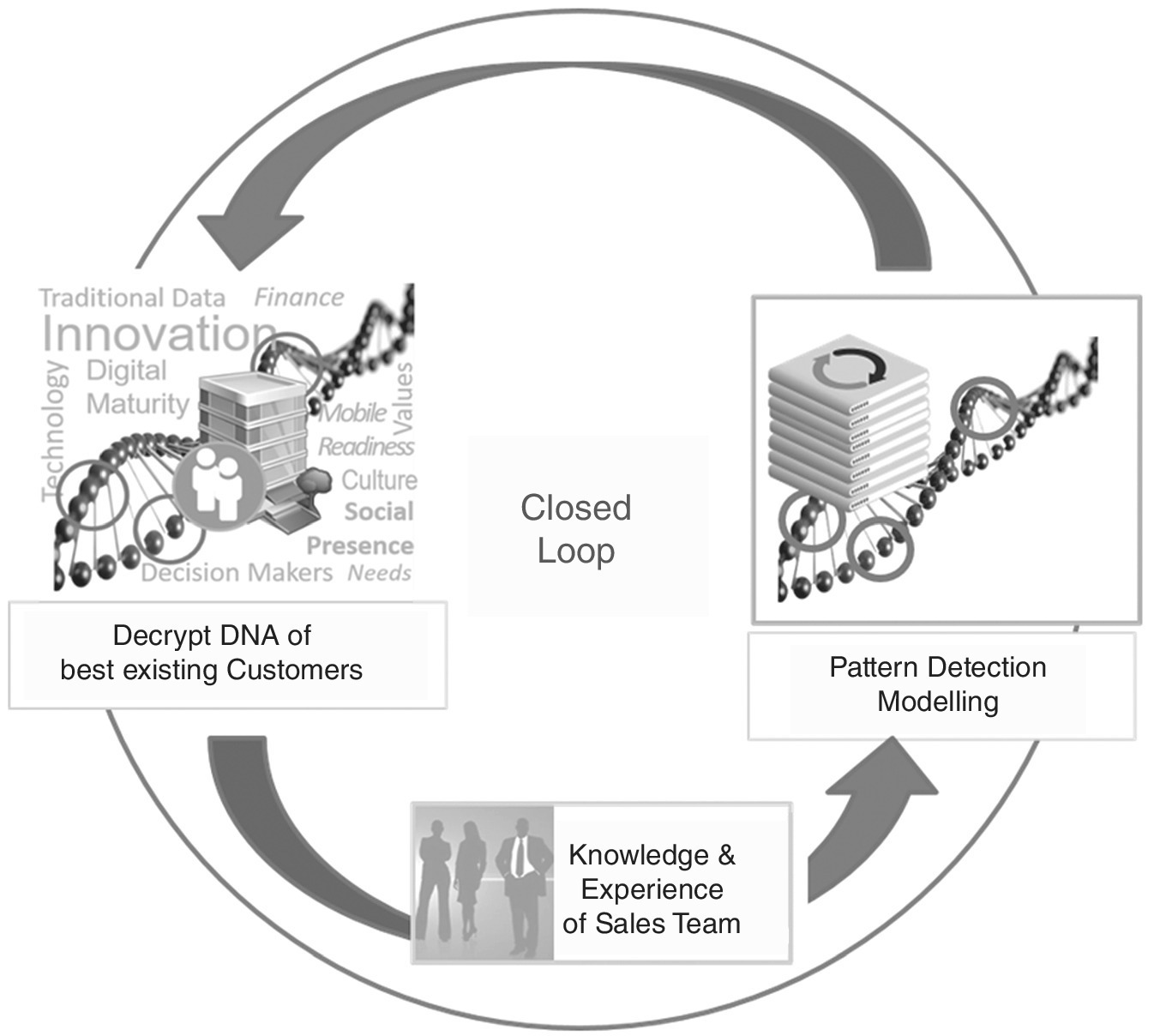
Figure 9.6 Closed loop of B2B customer profiling – continuous learning.
To keep the results reliable and current, the loop of continuous learning has to be initialised and kept constantly running.
9.4.3 Predictive Modelling
Now a predictive model is built, for example using decision trees or random forests; taking into account all these features, it can dynamically calculate a generic ‘best customer DNA’. Different samples of all existing customers are used as training quantities. These customers have to be split into at least two groups: good (best) and bad. If the model is able to detect the best existing customers among all existing customers, it is ready to search for new leads with the same DNA on the web and on social networks and to learn from experience in the process.
Figure 9.7 gives an illustration of how such an automated system might work. The left‐hand loop represents the continuous search and update of data to get the DNA of the customers and the right‐hand loop represents using this knowledge and automated predictions to find customers who resemble your existing best customers.
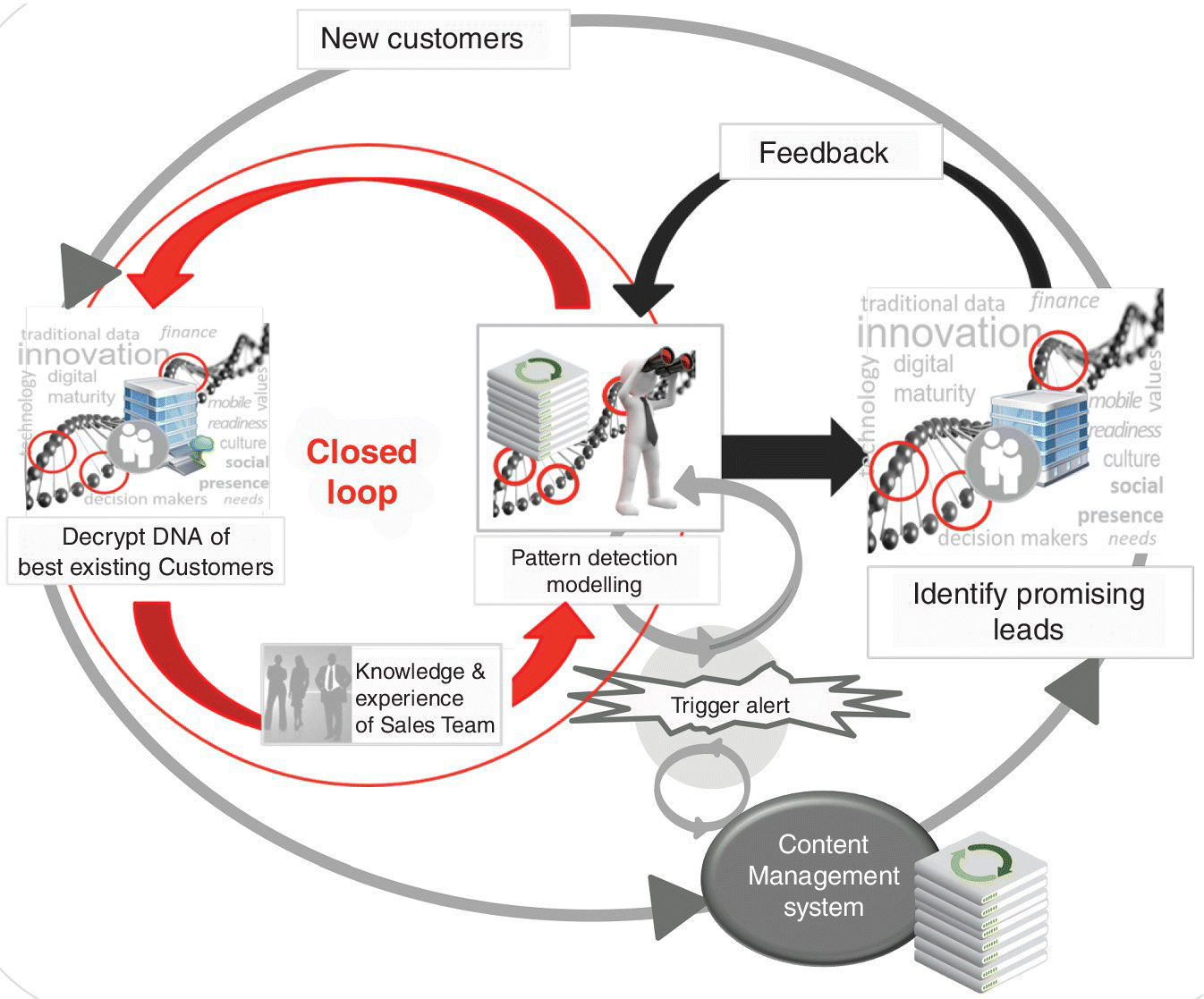
Figure 9.7 Automated B2B lead generation system.
In simple terms, as a first step data is harvested from the web and from social networks, and neural nets are used to help collect and structure as much relevant information about companies as possible. This information is combined with the tradition data to compile extended company profiles. A similar approach is carried out for company contacts.
In a second step, the information is assessed using different kinds of predictive models, which are continuously trained with different characteristics and on different samples. In our experience, the best outcome is obtained with a random forest approach. The results from these trees are aggregated into a result that can be used to create a ranking of the leads according to their conversion probability, with the best prospects first.
9.4.4 Communication
This type of lead prediction provides excellent results because the database is highly actual and comprehensive, the model learns steadily and works at the required speed. But the identification and ranking of leads alone is not enough. Now it is about addressing the highest‐ranked leads at the right time with the right content and transforming them into customers.
9.4.4.1 Timing
The analysis of existing customers shows that certain events in the life of a company or a contact person trigger purchase decisions Therefore, a well‐chosen time for an offer is essential to increase the conversion probability. Web and text mining can help.
On blogs, news channels, social media and company websites, you can find up‐to‐date information about the state and the development of companies (planned relocation, profit reporting, structural changes, changes in the assessment of their customers and so on). Also, news on relevant contact people (projects in which they are involved, publications, anniversary of employment and so on) are reported there.
By means of crawlers, which continuously scan these sources, messages about relevant events are sent to the system in real‐time, where they are evaluated according to their impact. As soon as the probability is very high that a company is currently reacting to a response, the system sets an alert.
9.4.4.2 Content
Content for trigger‐based, relevant communication, highly tailored to B2B leads, has to be prepared in advance. Some content sections might highlight sustainability and social engagement, others technical expertise or special offers.
The selection of the right communication for a B2B lead requires complex business rules and the capability to assign the corresponding messages in an analysis‐based way. Only a highly developed content management system can handle these demands, and then only with the help of a business rule engine that is able to:
- transform analysis results into business rules
- link a rule or rules to a template
- implement links as a default
- link rules to potential content.
To ensure usability, it is important that rules and links can be changed without extensive analysis or IT expertise, and that messages can be sent with the appropriate address of sender. In addition, a good content management system should provide the following features:
- option to enter professionally designed content
- drag and drop
- live preview
- planning tool
- authorisation concept for data access and operations
- module for ad‐hoc campaign creation
- checklist for different campaign phases
- success monitoring, reporting
- scalability.
These features will enable data‐driven, scenario‐based messaging, tailored to the local, seasonal and event‐driven circumstances of the B2B customer or lead.
9.4.5 Monetisation by Converting Leads to Customers
For a long time, B2C companies looking for new customers have included social media in their lead‐generation processes. They identify individual needs, lifestyles, values and topics that are important for potential customers. In B2B marketing, the web and social media are used to support and maintain existing customers. However, to attract new customers, many companies are still using addresses collected by traditional methods such as cold calling and assembling of address lists and information from publications. Digital channels give huge potential for new B2B customers to be identified and targeted. Text and web mining can be used to track the digital footprints of existing and potential customers in the B2B market, create intelligent profiles of companies and organisations (including profiles of the relevant contacts), and reach them at the right time with the right content (see Figure 9.8)
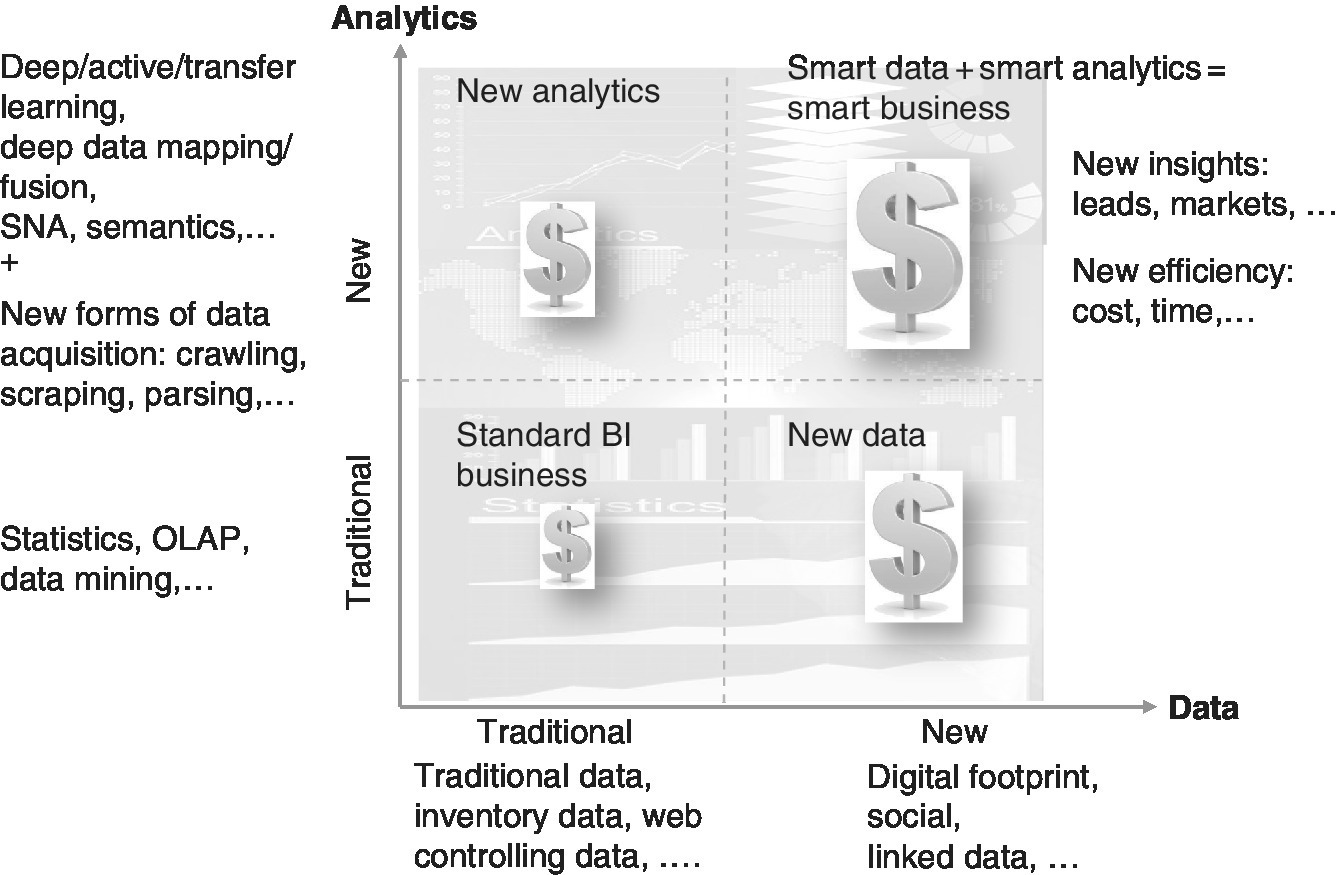
Figure 9.8 New methods, new insights, smart business.
Whether a traditional B2B company wants to expand its online business or a manufacturer of special tools is looking for new B2B marketplaces, for all companies that are searching for new B2B leads this big data analysis approach is worth considering.
9.4.6 Short Success Stories
9.4.6.1 Publisher
A large publishing house with a special interest in B2B publications has succeeded in opening up new target groups with the help of data analytics. They found a reasonable number of potential prospects they did not recognise in traditional address lists, without getting a lot of poorly matching prospects as well. The conversion rate was twice as high as on the conventional list‐broking path. Through this precisely selected target group, the advertising costs are radically reduced.
9.4.6.2 Manufacturer of Special Glass for Facades
A manufacturer of special glass for facades wanted to inform architects, developers and general contractors about new products, trends and innovations in a regular online newsletter.
The company’s existing address list was used to learn from, because these kinds of products are not relevant for all architects and not every general contractor specialises in buildings with big glass facades. The new addresses identified by analysis‐based lead prediction had an above‐average newsletter opening and item‐click behaviour. Two of the new leads for specific building projects have already made preliminary requests for sample solutions.
9.5 Legal and Ethical Issues
9.5.1 Ownership and Confidentiality
Who owns data, the collector or the subjects? For example, most social networks claim the right of ownership, but people think that the photos they have uploaded belong to them, in a similar way to our appreciation of the concept of habeas corpus, owning our own body.
You may give your data for one purpose but not want it used for another. Most people imagine that their data is confidential. Sometimes this can be a real nuisance for companies because they could do so much more, often for the good, if they could use their clients and customers’ data. But unless the data donor has specifically given permission it cannot legally be used except in an aggregate form that preserves privacy.
People are reluctant to have data used if they distrust the organisations that are asking to use it. Data protection standards require people to freely consent to their data being used, but it could be argued that there is coercion when people are edged into agreement because they want a product or service that will only be given if they consent to their data being used. Withholding consent does not solve the dilemma, because this can also be used as evidence about the person. A lot of public benefit can arise from sharing data, but everyone is wary. Most people are aware that even if their data is anonymised or redacted they can still be identified by ‘triangulation’: when anonymised datasets are combined to isolate an individual. As a simple example, if you complete a staff satisfaction survey for your employer and you are the oldest female employee with a qualification in statistics you may as well supply your name as there are unlikely to be two of you with those characteristics.
The idea of someone taking advantage of data by using it for a purpose other than the one for which it was collected has been a concern for a long time. Aristotle wrote a text entitled ‘Prior Analytics’ around 300 BC, and this included the concept of ‘post hoc propter hoc’ which means ‘after it, therefore because of it’, for example when something happens after doing something completely unrelated and the doer takes the credit for it. This concept applies also to businesses taking advantage of your data. Aristotle then wrote ‘Posterior Analytics’ as an analysis of the premises of his thinking on the prior analytics and on the nature of knowledge. The word ‘analytics’ comes from Greek meaning ‘solvable’ or ‘to loosen’.
It could be argued that a person is more than the sum of their data and so we need not fear a total loss of privacy. From the company point of view, however, a data‐driven representation of a person leads to a model and, as George Box said, ‘all models are wrong but some are useful’.
Intentional fraud and theft can be detected with the help of big data analytics. Once patterns of behaviour are recognised then exceptions can be identified and investigated. For example, when bank cards are used in different places and for different kinds of purchases, it prompts checks by the bank.
Big data and the linking of datasets poses some fundamental dilemmas. If you have a sleep problem, for example, you could seek help at your medical centre but you run the risk of your employer finding out and using it as a criterion when selecting people for redundancy: a paranoiac’s nightmare. Sharing knowledge about yourself causes a loss of privacy, but this is different to privacy invasion, in which details are gathered behind your back. The massive power that comes from linking up data from healthcare and social networks, for example, can benefit some people but be to the detriment of others and severely impacts on their liberty. As mentioned in Section 7.4.7, a person could be claiming disability allowance because they are unable to work but may also be an active member of a tennis club or take part in extreme sports. This information link‐up will cause a problem for the claimant, but could be considered to be a positive thing for society as a whole.
Dealing with medical data is very highly regulated. The distinction between medical and other data is becoming ill‐defined, however. The internet of things, for example, includes personal sensors that collect data, varying from the fairly innocuous – say, the number of steps walked in a day – to measures such as your blood pressure and pulse rate that verge on being medical data.
Big data has the potential for highlighting a mass of correlations, some of which are purely mechanical and some of which genuinely reveal causation. The great advantage of identifying these correlations is that it provides pointers on where to do further scientific research and this can benefit everyone.
Company data is owned by companies. They can use it for internal audit purposes but they cannot disclose or publicise it or report any insight from it unless express permission has been granted.
9.5.2 Ethics vs Reproducibility
Users of public data have an ethical dilemma when trying to be transparent and credible with the models they develop. They may want to show that their algorithms and models are reproducible and yet they cannot share their data to allow their methods to be audited and verified by others. They can only share aggregated data, which may not lead to the same results.
Similarly, those dedicated to defending the effectiveness of models, often referred to as the ‘Blue team’, may make changes to models within the organisation in response to business needs and to keep the business profitable but these changes also make it difficult to reproduce the models.
9.5.3 Commercial Sensitivity
Once your company data has been monetised, how do you ensure that you retain the competitive advantage and competitors don’t steal the data or insights? Access is usually granted with conditions, including acknowledging the source of any insight. As with any ‘copyright’ material, a careful check has to be kept on who has had access to the data.
A positive way to view innovation is to share freely and be confident that if others use your idea in a new way, you can build on their idea and produce something even better. A free flow of ideas can be thought of as drawing more ideas in, leading to a more creative business world.
9.5.4 Misleading Messages
Poor graphics can have misleading messages and be interpreted as unethical use of data. This can have severe reputational effects for a company. For example, some simpler unethical methods of data exploitation include poor data cleaning, poor visualisation and misleading trend lines.
Some sleights of hand are easy to pick up. In Figure 9.9, this is not a useful trend line of shipping fuel usage; there are more questions to ask of the data. What was the mode of travel in the two parts of the data? Why are there some apparently negative fuel consumptions? Why are the data combined in the trend analysis?

Figure 9.9 Misleading scatterplots.
Figure 9.10 shows a number of interesting features. The misleading trend line masks the cyclical nature of the data and ignores the outlier points. The plot should prompt questions such as what caused the increase in fuel consumption on 6 February: was it the shipping load, the state of wind and tide or a mechanical failure? Why is there a flowing pattern to the data points in the middle of the month?
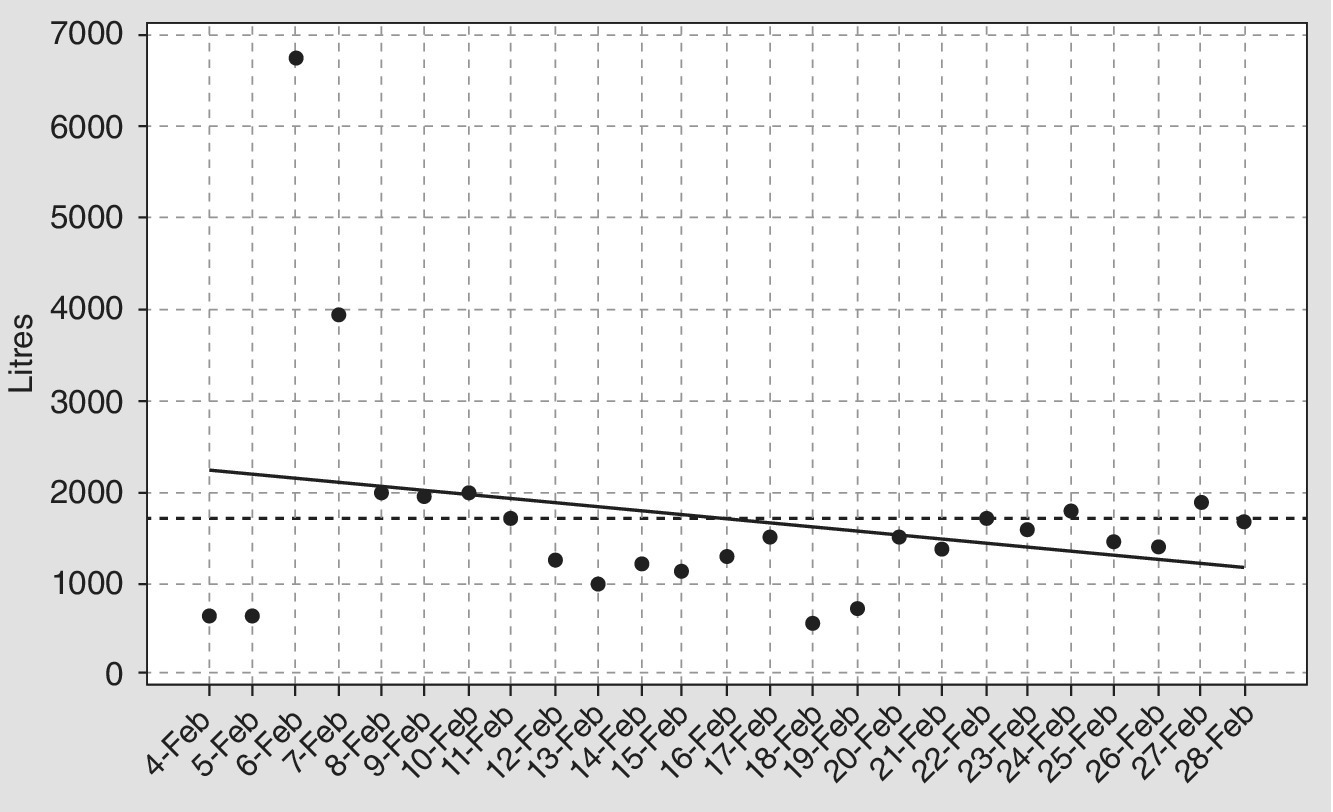
Figure 9.10 Scatterplot with multiple features.
Plots can also highlight interference with data. The disjointed symmetry of the histogram in Figure 9.11 suggests that product quality measures are being rounded down to 10, perhaps to avoid rework.

Figure 9.11 Histogram of suspicious‐quality recordings.
Misleading percentages are one of the main reasons that people are wary of statistics and is probably the background to the adage: ‘There are lies, damned lies and statistics’. For example, the denominator in a percentage may not always be clear. Consider the case where 75% of managers receive bonuses whereas only 50% of technical staff do. Is this evidence of unfairness? If the experience, length of service and range of skills in the managers group is much higher then it may be quite reasonable that they receive more bonuses. The percentages should really be calculated like‐for‐like, using subsets of staff with comparable backgrounds.
Sometimes additional data is deliberately suppressed to mislead. There are plenty of examples of this in the press. The Journal of Irreproducible Results takes a humorous look at science and has been running since 1955.
9.5.5 Privacy
It has been said of data driven business that ‘The cultural challenges are enormous, and, of course, privacy concerns are only going to become more significant’. Privacy concerns are just one of the interesting dilemmas appearing on the horizon for companies hoping to realise the potential in their big data.
Who cares if their data is public for all to see? Some people see no reason why, with so much data available, they should be targeted. Most people feel that they have nothing to hide and nothing to fear from having quantities of information about them floating around in cyberspace. The information can be used in a good way, for example when entertainment lists find you something good to watch, or in a bad way, such as when you are inundated with annoying advertisements. These are first‐world problems, however, and there are likely to be many worse intrusions in the future.
Again, many people may feel that it is not a problem for tax authorities, welfare offices and leisure service providers to share information. Unless you are defrauding the system by claiming disability benefits whilst being an active member of a sports club, then what is the problem? Is it only people who have something to hide who are at risk from the opening up of data sharing across institutions?
Micro‐census data is closely guarded by national statistics institutes (NSIs). Providing census data is compulsory. NSIs are responsible for deciding who can access this data and what they can do with it. The UK is one of the most open‐data‐friendly countries in the world. Approved researchers working on approved projects are allowed access to micro‐data in a secure environment after attending a course on how to handle disclosure of their research findings. There is an ongoing debate about whether it is right to spend taxpayers money to collect census data and then not to maximise its use. The counterargument is that citizens should not be forced to give census data and then have that data made available to other people. The question is whether greater access should be allowed to the data and, if so, what the criteria for approved researcher should be. This is the classic conundrum about the balance of rights and responsibilities.
9.5.6 Intrusions
There are distinct dangers when big data analytics encounter human idleness. Most of us are willing to be hoodwinked or easily persuaded and to take the easy option. Hence, if we are presented with easy language and easy pictures, combined with the opportunity that each person gets an individually tuned version of the truth with no opposing arguments, then we can be persuaded that a policy suits us and should be supported.
There are huge numbers of posts on social media every second and there are posts from many different directions. From amongst this mass of competing input, the social media technology decides what will come within your reach and the order in which the posts are received. Clearly, a positive aspect of this is that the receiver gets what they are interested in and therefore maintains their use of this social media provider, who reinforces their interests and provides information in a convenient way. But the downside is that this approach leads to increasing narrowmindedness and enables the social media user to shut their eyes to anything they don’t want to know about, including unpleasantness and things that contradict their preconceptions. This can clearly lead to increasing reinforcement of entrenched views. Anyone can post information to all or specific people who are linked to them. Where big data comes into this is that it can be used to identify subgroups within the target population so that posts can be tuned to those sub groups. This is similar to using the old‐fashioned post, but is much more immediate and intrusive. The segmentation can also be repeated much more often and faster by big data analytics. More and more people use social media as their only information source. It is tempting for the social media user not to query and research ideas for themselves but just to accept what they read without question.
9.5.7 Ethics
It has been said that, ‘personal data is made from the compressed fragments of our personal lives’ and companies may increasingly find benefit in labelling themselves ‘data‐humane’. We can propose an ethical data charter that rewards companies that can say they will use personal data well. Companies may be required to give examples of the good things they have done with their data, for example ‘we used our expert system data to show that people with problem X find assistive equipment difficult to find and we have made suppliers aware of this gap in the market’.
Whether a particular data usage is good or not depends on whose perspective we consider. For example, fuel consumption by ships harbours lots of insight into how a ship is performing, which is good for the environment and can lead to guidelines for more efficient means of transport. It can also lead to fuel theft detection, which is good for the company and shareholders but bad for the thief. Smarter monitoring of gas, electricity and water can lead to theft and leakage detection, with all its implications for system improvement. But it can lead to lack of privacy and it isn’t always the ‘baddies’ who are caught out; such techniques could also affect the poor and marginalised members of society who have found a way to access utilities without paying.
Data‐driven analyses can also identify people and situations that are benefitting quite legitimately but disproportionately from a system. For example, a learned society finds, through data analysis, that their member services staff are spending a great deal of time servicing retired members. The need to streamline services might then mean that their special membership category would have to be discontinued. Those identified as being in the 20% of a Pareto chart may not be considered worth satisfying but they will not be very pleased if that is the case.
It will be interesting to see which happens faster: companies gaining the necessary skill to make full use of their data versus citizens becoming more aware and concerned and demanding a kitemark for the ethical data dealer. Of course, the oceans of data in existence will still be out there, waiting to be used, much like the indiscretions of 20–30‐year‐olds on archive Facebook accounts.
What can and cannot be done? Companies should be encouraged to make maximal use of their data and there are already restrictions on how the data should be reported, so that individuals cannot be identified. But there are problems due to triangulation, so the focus needs to go on reporting not just in a way that protects the identity of the individual but in a way that benefits mankind.
Who will be the judge? Those decisions are already made for official statistics and so there is a precedent. More and more datasets are open, if sufficiently anonymised. Monetisation is extracting information from data so that the data is turned into a form of money. Unlike official statistics, companies did not normally put extra effort into gathering information; it was gathered as a necessary part of their business. They need names and addresses for logistics, they need to know who bought what, when and how for their stock management, they need to know why customers bought so that new products can be developed and customer relations maintained. Sharing customer information across companies would be very fruitful. Companies need to realise the potential then work out how to share their data assets. We need a whole new battalion of data‐aware lawyers to stop small companies being exploited by larger ones. For example, a sports equipment company might share data with a health provider, but handled carelessly this exchange might drive customers away from the sports dealers giving the health provider a stranglehold.
Companies may start focusing their effort more on understanding who the customer is and what their motivation is for purchasing. They have most of the necessary data already but need the skills and the awareness to get started. The return has to be greater than the effort expended in developing the skill base. Reminiscent of Six Sigma and other management improvement initiatives, companies will buy in slowly but then the uptake will accelerate. Unfortunately, as monetising data becomes mainstream, the richness of the methodology is likely to get watered down. Only a few of the simpler techniques will survive and be widely used and these will then be all that is expected by shareholders. The ISO 5750 quality standard may have a sister in an ISO standard for data awareness.
Our ethical data charter may be: ‘every piece of data we collect is assuredly necessary and of high quality and is used for the good of the company by qualified, proficient data handlers’.
The intellectual property of a company will be part of their selling and promotional effort. They can declare, in a similar way to charities saying that 95 pence of every pound goes to the needy, that 95% of data is used for ethical causes. This statement may be part of the board’s analysis of the company: are they ethical in data exploitation as well as competent in their data management? In our increasingly digital society, it is advisable to watch out for customer dissatisfaction with how you use data and to be ready for changes in legislation that affect what can be done with it.
9.6 Payments
In the preceding chapters the different ways of monetising data were described. These can be summarised into the following general concepts:
- services as a payment for donating data
- companies benefitting from their own data, information and insight by
- selling or renting it
- improving existing business
- creating new business
- targeting specific customers
- companies generating business and product ideas from analysing other people’s data
- selling or renting the processed data and insight
- creating new business
- targeting specific customers
- consultants providing a service based on data analytics.
The payment mechanism for the first three concepts is clear. But where a consultant data scientist or statistician makes a business from providing monetisation and analytical services, the payment options are more diverse.
Consultants who advise clients on how to monetise their data have a variety of different approaches to getting paid for their services. There is often a mismatch in personality types between the statistician and the salesperson. Some consultants find bartering and closing the deal distasteful. However, clearly it makes sense to charge the right amount for a good service. It is not uncommon to find academic staff giving their services for free or for a disproportionately low reward. Examples include academics who will happily construct tables of simulation results supporting different types of quality control, or tables of extreme values that make up part of a regulatory framework, or statisticians willingly constructing multiple subtle tests for randomness to be used by statistical packages or private companies.
Assuming that payment is obtained, the level of payment can be based on an hourly rate, as often favoured by lawyers, or a per‐job rate, preferred by craftsmen, or as a proportion of increased profits. The latter is hard to obtain as it is very difficult to agree an attribution of the benefits, although this would be the most lucrative approach for talented practitioners who regularly save their clients thousands of euros.
The following are real examples where statistical thinking has saved time and resources and led to increased efficiency and profit:
- Identifying the gradual oxidation of a catalyst in a chemical process so that it can be replaced before it starts affecting the product adversely and causing a drop in quality not only prevents manufacturing sub‐standard product but also saves the time needed to re‐set a process that has gone wrong.
- Designing experiments that demonstrate the effect on the quality of output of using a different temperature, pressure or material can deliver a large improvement.
- Identifying the top 10% of sales prospects saves sending out excessive marketing materials that will fall on deaf ears.
- Producing prediction equations that help target the right purchase or promotional channel makes marketing much more efficient.
The final chapter in this book looks at case studies where monetising data has been carried out; the benefits are clearly stated and the reader can draw their own conclusions as to the value of the practitioner.
9.7 Innovation
It would not be correct to finish the main part of this book without acknowledging the relevance of innovation. We have emphasised the importance of communication and co‐operation between business people and statisticians and have described methods and practical case studies. However, this description of current practice does not mean that this is the way things should always be done. Sometimes a simple approach fits the requirements, for example when the data resource is poor or the purpose of the work is to give a signpost to further work. However, it is vital to protect statistical integrity against pressures to ignore data subtleties and make too many assumptions, in the same way as we protect our lifestyle against too much uniformity and conformity.
Data analytics cannot work on its own but requires the addition of domain knowledge to enrich the data. New data forms and increasingly unusual applications may prove intractable to current methods. The practitioner should not be bound to using established methods. If the analytical situation demands it then there is every reason to carry out new research and create new paradigms. Just make sure that you step incrementally unless you are really sure that the innovation is right and will work in all applications and not just on the dataset on which it was developed.