In this chapter we’ll be covering some advanced symmetric cryptography, and we’ll get deeper into authenticated encryption.
Let’s dive right into an example and some code using AES-GCM.
AES-GCM
Alice and Bob have had a few close calls with Eve over the past month. During that time, they have been exchanging USB drives with encrypted files. This has worked out for them so far, but they seem to have trouble remembering a handful of key things: that they should Encrypt-Then-MAC, that the MAC needs to cover unencrypted data, and that they need to have two separate keys. After some exasperation and close calls due to their understandably imperfect memory under pressure, they let HQ know that they would like something less error-prone.
As it happens, there is something new that they can use. New symmetric modes of operation are available called “authenticated encryption” (AE) and “authenticated encryption with additional data” (AEAD) . These new modes of operation provide both confidentiality and authenticity for the data. AEAD can also provide authenticity over “additional data” that is not encrypted. This is far more important than it might sound, so we’re actually going to leave AE behind and focus exclusively on AEAD.
AES-GCM
Most of this function should look familiar. Because we’re storing this data on disk, we are using Scrypt instead of HKDF, and we use this to generate a key from a password. As described in the previous chapter, because a user might use the same password across multiple files, each file needs its own salt in order to generate a per-file key. Remember, we do not want to use the same key and IV on different files or even on the same file (e.g., if we encrypt, then modify the file and encrypt again). To be extra cautious, we won’t even use the same key.
Similar to what we’ve done before, we also create a Cipher object. But instead of using CTR or CBC modes, we use GCM mode. That mode takes an IV, and we’ll talk momentarily about why it is 12 bytes instead of the 16 bytes we’ve seen in the past. The only new method on the encryptor is authenticate_additional_data. As you can probably guess, this method takes in the data that will not be encrypted, but that still needs to be authenticated.
The unencrypted data that we’re authenticating in this case is the salt and the IV. This data must be in plaintext because we can’t decrypt without it. By authenticating it, we can be certain—once the decryption is done—that nobody has tinkered with these unencrypted values.
The other unique part of this GCM operation is the encryptor.tag . This value is computed after the finalize method and is more or less the MAC over the encrypted and additional data. In our implementation, we choose to put the associated data (the salt and the IV) and the tag at the beginning of the file. Because that data (at least the tag data) won’t be available until the end of the encryption process, we preallocate several bytes (initially zeros) that we’ll overwrite when we finally have the tag at the end of the process. In some operating systems, there is no way to prepend data, so the preallocated prefix bytes ensure that we have room for the header when finished.
The function in Listing 7-2 doesn’t delete or overwrite the original file, so it’s pretty safe to play with. Use it to create an encrypted copy of a file on your system. Examine the bytes using a utility like hexdump to ensure that the data is, in fact, encrypted.
Warning: Beware the Files of Unusual Size
Do not encrypt a file greater than 64 GiB, as there are limits to GCM that we will discuss shortly.
AES-GCM Decryption
This decryption operation starts by first reading out the unencrypted salt, IV, and tag. The salt is used in conjunction with the password to derive the key. The key, the IV, and the tag are parameters to the GCM decryption process. The associated data (the salt and the IV) are also passed into the decryptor using the authenticate_additional_data function .
When the decryptor’s finalize method is called and any data has been changed, either in the ciphertext or the additional data, the method throws an invalid tag exception.
This function does not attempt to recreate the original filename. You can thus safely restore the encrypted file to a new filename and then compare the newly recovered file with the original.
Exercise 7.1. Tag! You’re It!
Artificially “damage” different parts of an encrypted file including both the actual ciphertext and the salt, IV, or tag. Demonstrate that decrypting the file throws an exception.
AES-GCM Details and Nuances
The mode both encrypts and authenticates data with a single key.
The encryption and authentication is integrated; there is no need to worry about when to do what (i.e., Encrypt-Then-MAC vs. MAC-Then-Encrypt).
AEAD includes authentication over data that is not encrypted.
You may have noticed that these features address Alice and Bob’s concerns. It significantly reduces misuse and misconfiguration, making it easier for Alice and Bob (and you) to do it right.
One element of this that deserves particular emphasis is the authentication of additional data. There have been many issues in the history of cryptography where an attacker takes data out of one context to misuse it in another. Replay attacks, for example, are classic examples of this kind of problem. In many cases, these attacks would fail if the context of the sensitive data were enforced.
In our file encryption example, we authenticated the IV and salt values, but we could have easily thrown in the filename and a timestamp. One problem with encrypted files is recognizing a replay of an older, but correctly encrypted, version of the file. If a timestamp is authenticated with a file, or alternatively a version number or other nonce is included, the encrypted file is more tightly bound to a recognizable context.
When you are encrypting data, think carefully over what data needs to be authentic, not just private. The better you can identify and secure the surrounding context of encryption, the more secure your system will be.
In terms of securing data against modification, it is important to note that the AEAD algorithm decrypts data before it knows if the data is unmodified. In your experimentation with the preceding file decryption, you may have noticed that even if the encrypted file is damaged, the decryptor will still create a decrypted file. The exception thrown by GCM is thrown after everything is decrypted and (in our implementation) written to the recovered file.
In summary, remember that the decrypted data cannot be trusted until the tag is verified!
AEAD is great, but the combined operation introduces an interesting problem. How long do you have to wait for a tag? Suppose that, instead of file decryption, Alice and Bob are using AES-GCM to send data over a network. Suppose it’s a lot of data. Suppose it will take many hours to completely transmit the data. If we encrypt this data like we encrypted the file, the tag will not be sent until the entire transmission is complete.
Do you really want to wait until the very end of those hours to finally receive the tag?
Worse, how do you calculate the “end” of a secure channel? If you have an encrypted channel open for days sending arbitrary amounts of data, at what point do you decide to stop, calculate, and send the tag?
In network protocols like TLS, which we will explore more fully in Chapter 8, each individual TLS record (a TLS packet more or less) is individually GCM-encrypted with its own individual tag. That way, malicious or accidental modifications are detected almost in real time, rather than at the end of transmission. In general, a more bite-sized approach to GCM encryption is recommended for streams.
This API is easy to use and the concept is not too difficult, but it comes with one critical security consideration: the nonce. Recall that the “C” in GCM stands for “Counter.” GCM is more or less like CTR with a tag operation integrated into it. This is important because many of the problems with counter mode that we’ve discussed previously still apply. In particular, while you should never reuse a key and IV pair in any mode of AES encryption, it is especially bad for counter mode (and GCM). Doing so makes it possible to trivially expose the XOR of the two plaintexts. The IV/nonce to GCM must never be reused.
To illustrate the issue, let’s briefly revisit how counter mode works. Remember that unlike CBC mode, AES counter mode does not actually encrypt the plaintext with AES block encryption. Rather, a monotonically increasing counter is encrypted with AES, and this stream is XORed with the plaintext. It’s worth repeating that the AES block cipher is first applied to the counter, and then to the counter +1, and then to the counter +2, and so on to generate the full stream. Reusing the nonce results in reusing the stream.
That’s important. If you are not even more careful, though, you might run into a slightly similar problem that is equally disastrous. For example, suppose that you decide to start with a nonce of 0 (16 bytes of 0) instead of picking a random IV for counter mode. You use that nonce (0) to encrypt a bunch of data (maybe a file) under a key and then you increase your nonce by 1 to initialize a new AES counter context to encrypt a new set of data (such as another file) under the same key. Your nonce is thus nothing more than an ever-incrementing counter.
The problem with this is that—even though you think you’re not reusing a nonce (it’s different every time)—counter mode works by increasing the nonce by one for each block. The first operation encrypted 0, then 1, then 2, and so forth; the second operation encrypted 1, then 2, then 3, and so forth. In other words, the second file encrypted with the second nonce repeats the same key stream after the first 128-bit block. There is a very large amount of overlap between subsequent streams.
For relatively small amounts of data like we are using in examples, using a completely random 16-byte IV is probably enough for standard counter mode. In production code, you would have to do a security analysis to determine exactly how long you have on average before you create cipher streams that overlap. This calculation is dependent on how much data you plan to encrypt under the same key. If you want to explicitly control your IVs to ensure that it is not possible to overlap a key/counter pair, there are some rules that you can follow that help.
GCM, for example, mandates a 12-byte IV to explicitly solve this problem (it does permit longer IVs, but this introduces new problems and is beyond the scope of the book). The selected 12-byte nonce is then padded with 4 zero bytes to produce a 16-byte counter. Even if a nonce is chosen that is just one more than the previous nonce, the counters will not overlap, provided you do not overflow the 4-byte block counter. A 4-byte counter on 128-bit blocks means no more than 236 bytes (or 64 GiB) of data can be encrypted before overflowing the counter, which is why 64 GiB of data is designated as an upper bound for GCM encryption.
Using 12-byte IVs and no more than 64 GiB of plaintext per key/IV pair means that there will never be any overlap. For reasons that are beyond the scope of this book, the only other requirement on GCM IVs is that they not be zero.
Let’s return to the problem of using AES-GCM to encrypt a bunch of smaller messages in a stream. How do we keep from reusing a key/IV pair? We could try to come up with a deterministic way of rotating the key on each side of the transmission, but that’s too complicated and error-prone. What we can do instead is use different IV/nonce values for each individual encryption. In a worst-case scenario, the nonce can be sent with each packet. Unlike the key, the nonce does not have to be secret, merely authentic.
Additionally, we can use certain nonce construction algorithms to help prevent reuse. It is not OK to limit the randomness of a key because the key must be secret, and any bits chosen deterministically reduce the brute-force difficulty of discovering that secret. It is acceptable to reduce the randomness of some bits in an IV so long as the IV is never reused with the same key.
For example, some number of bytes of the IV could be device-specific. This ensures that two different devices can never generate the same nonce. Alternatively—or additionally—some bytes of the IV could be inferred, reducing the amount of IV data that has to be stored or transmitted. Perhaps part of the IV for a file encryption could depend on where the file is stored on disk.
For now, we will continue to generate random IVs and transmit them as needed, but it’s good to understand some of the different ways that IVs can be generated and used.
Exercise 7.2. Chunky GCM
Modify the document encryption code from earlier in the chapter to encrypt in chunks no larger than 4096 bytes. Each encryption will use the same key, but a different nonce. This change means that rather than storing one IV and one tag at the top of the file, you will need to store an IV and a tag with each encrypted chunk.
Other AEAD Algorithms
In addition to AES-GCM mode, there are two other popular AEAD algorithms supported by the cryptography library . The first one is AES-CCM. The second is known as ChaCha.
AES-CCM is very similar to AES-GCM. Like GCM, it uses counter mode for the encryption; however, the tag is generated by a method similar to, but also superior to, CBC-MAC.
One critical difference between AES-CCM and AES-GCM is that the IV/nonce can be of variable length: between 7 and 13 bytes. The smaller the IV/nonce, the larger the data size that can be encrypted by the key/IV pair. Like GCM, this nonce is just a part of the full 16-byte counter value. Thus, the fewer of the 16 bytes used by the nonce, the more bytes that can be used by the counter before overflowing.
For reasons beyond the scope of this book, the nonce is constrained to be 15-L bytes long, where L is the size of the length field: if your data requires 2 bytes to store the length, the nonce can be up to 13 bytes. On the other hand, if the size of the data would require 8 bytes to store the length, the nonce is limited to 7 bytes. These two values represent the minimum and maximum values supported by the CCM mode.
Assuming that you want to use CCM for large amounts of data, just select a nonce of 7 bytes and move on. The security of the algorithm doesn’t change based on nonce size, so long as you do not reuse a nonce with a key.
Besides this painful nonce issue, CCM has no other API differences over GCM. In terms of performance, however, GCM is more easily parallelized. That may not make much of a difference in your python programming, but it does make a difference if you want to use your graphics card as a cryptographic accelerator.
The last AEAD mode that we’ll introduce to you is known as ChaCha20-Poly1305. This cipher is unique among the AEAD approaches discussed in this book, as it is the only AEAD algorithm not based on AES. Designed by Daniel J. Bernstein, it combines a stream cipher he designed named ChaCha20 with a MAC algorithm also designed by Bernstein named Poly1305. Bernstein is quite the cryptographer and is currently working on a number of projects related to elliptic curves, hashing, encryption, and asymmetric algorithms resistant to quantum-enabled attacks. He is also a programmer and has written a number of security-related programs.
Some in the security community worry that the popularity of AES means that if a severe vulnerability were ever found in AES, the cryptographic wheels of the Internet might grind to a halt. Establishing ChaCha as an effective alternative means that, should such a vulnerability be found, there would be a well-tested, well-established alternative already available. The fact that ChaCha20-Poly1305 is available as authenticated encryption is even better.
ChaCha20 has some other advantages. For purely software-powered implementations, ChaCha is typically faster than its peers. Moreover, it is a stream cipher by design. Whereas AES is a block cipher that can be used as a stream cipher, ChaCha is only a stream cipher. In the earlier days of the Internet, RC4 was a stream cipher that was used in a lot of security contexts including TLS and Wi-Fi. Unfortunately, it was found to have major vulnerabilities and weaknesses that have all but eliminated its use. ChaCha is seen by some as its spiritual successor.
Any of these AEAD algorithms can be used with more or less the same security guarantees. All three of them are considered to be much better than creating authenticated encryption by doing a separate cipher along with an accompanying MAC. Whenever AEAD algorithms are available, you should take advantage of them.
You may have noticed the generate_key methods for these three different modes. This is a convenience function, not a requirement. You can still use, for example, a key derivation function to create keys just as you always have. But as you can see with ChaCha, you don’t even have to specify a bit size. It just gives you an appropriately sized key, which can eliminate a common class of errors.
Exercise 7.3. Speedy Chacha
Create some speed comparison tests for AES-GCM, AES-CCM, and ChaCha20-Poly1305. Run one set of tests where a large amount of data is fed into each encrypt function exactly once. Test the speed of the decryption algorithm as well. Note that this also tests the tag check.
Run a second set of tests where large data is broken up into smaller chunks (perhaps 4 KiB each), and each chunk is individually encrypted.
Working the Network
The spies of East Antarctica are finally getting out of the stone age and have begun hooking computers up to the Internet. It’s time that Alice and Bob learned to write some network-capable code for sending their codes back and forth.
Because they’re using Python 3, Alice and Bob are going to do some asynchronous network programming using the asyncio module . If you’ve programmed with sockets before, this is going to be a little bit different.
By way of explanation, sockets are typically a blocking or synchronous approach to network communications. Sockets can be configured to be non-blocking, and in that mode you can use them with something like the select function to keep the program from getting stuck while you wait for data. Alternatively, sockets can be put in a thread to keep data flowing into the main program loop.
The asyncio module takes an asynchronous approach and attempts to model the data structure after the conceptual model of network communications. In particular, network data is processed by a Protocol object that has methods for handling connection_made, data_received, and connection_lost events. The Protocol object is plugged into an asynchronous event loop, and the Protocol’s event handlers are called when events are triggered.
Network Protocol Intro
The contract for a Protocol object is that, after construction, there will be one call to connection_made when the underlying network is ready. This event will be followed by zero or more calls to data_received, followed by a single connection_lost call when the underlying network connection is broken.
A protocol can send data to the peer by calling self.transport.write and can force the connection to close by calling self.transport.close.
It should be noted that there is exactly one protocol object created per connection: when a client makes an outbound connection, there is only ever one connection and there is only ever one protocol. But, when a server is listening for connections on a port, there are potentially many connections at one time. A server spawns connections for each incoming client, and asyncio spawns a protocol object for each new connection.
That was a really fast overview of asyncio’s network API. A more detailed explanation is beyond the scope of this book, but if you need more information, the asyncio documentation is very thorough. Also, much of this will probably become clear as you follow along with the examples. Speaking of which, let’s use what we have learned and create a “secure” echo server.
The echo protocol is the “Hello World” of network communications. Basically, a server listens on a port for client connections. When a client connects, it sends to the server a string of data (usually human readable). The server responds by mirroring back the exact same message (hence, “echo”) and closing the connection. You can find plenty of examples of this on the Web, including an example in the asyncio documentation.
We are going to add a twist. We’re going to build a variant that encrypts on transmission and decrypts on reception.
Secure Echo Server
There is a single protocol class in this file: EchoServerProtocol. For illustrative purposes, the connection_made method reports the details of the connecting client. This will typically be the client’s IP address and outbound TCP port. This is for flavor only and not essential to the operation of the server.
The real meat is in data_received method . This method receives data, decrypts it, re-encrypts it, and sends it back to the client.
Actually, we’re getting a little ahead of ourselves: for this encryption, where does the key come from? The password is a parameter to the EchoServerProtocol constructor , but if you look down at the create_server line later in the code, you will see that we are passing in a hard-coded value. In honor of the fact that “password” is still a common password, we have chosen that string as the “secret”1.
Using the password, the EchoServerProtocol derives two keys: a “read” key and a “write” key. Because we will be using randomized nonces, we could use the same key for both the client and the server, but having two separate keys is easy to do and is good practice. We use HKDF to generate 64 bytes of key material and split that into two keys: the server’s read key and the server’s write key.
Going back to the data_received method , remember that this method is called when we have received something from the client. Thus, the data variable is what the client sent us. We are assuming (without any error checking) that the client sent a 12-byte nonce followed by an arbitrary amount of ciphertext. Using that nonce and our server’s read key, we can decrypt the ciphertext. Note that the third parameter is just an empty byte string because we are not authenticating any additional data for now.
Once the data is decrypted, the recovered plaintext is re-encrypted under the server’s write key and a newly generated nonce. We could have reused the nonce because we have a different key, but using a separate nonce is good practice and keeps both sides of the transmission using the same message format. The new nonce and the re-encrypted message are then sent back to the client.
The rest of this sets up the server. You can ignore most of it, with the exception of the create_server method . This method sets up a listener on local port 8888 and associates it with an anonymous factory function. That lambda will get called each time there is a new incoming connection. In other words, for each incoming client connection, a new EchoServerProtocol object is produced.
Secure Echo Client
This code has some similarities to the server that should be readily apparent. First of all, we have the same hard-coded (really bad) password. Obviously we need the same password or the two sides wouldn’t be able to communicate with each other. We also have the same key derivation routine in the constructor.
There are important differences, though. If you look at how the key material is divided up, this time the first 32 bytes is the client’s write key and the second 32 bytes is the client’s read key. In the server code, this is of course reversed.
This is not an accident. We are dealing with symmetric keys; what the client writes, the server reads and vice versa. In other words, the client’s write key is the server’s read key. When you derive keys, you have to make sure that the order in which key material is split up is correctly managed on both sides. There were a few earlier exercises that dealt with this without so much explanation. If those exercises didn’t make as much sense at the time, now might be a good time to go revisit them.
Another way to solve this problem is to always call the derived keys the same thing on both sides. So, for example, instead of deriving a “read” key and a “write” key, you could instead choose to use the names “client write” key and a “server write” key for both the client and the server. That way, the first 32 bytes can always be the client’s write key and the second 32 bytes is the server’s write key.
Once these two keys are created, the other names are just aliases. That is, “client read” key is just an alias for “server write” key and “server read” key is just an alias for “client write” key.
Exercise 7.4. What’s In a Name?
In many circumstances, “read” and “write” are the correct names to use because despite calling one computer a client and one computer a server, they behave as equal peers.
But, if you are dealing with a context where a client only makes requests and the server only responds to requests, you can rename your keys appropriately. The echo client/server we have created is an example of this pattern.
Starting with the code in Listings 7-4 and 7-5, change all references to “read” and “write” data or keys to be “request” and “response” instead. Name them appropriately! The client writes a request and reads a response, while the server reads a request and writes a response. What happens to the relationship between client and server code?
Another difference from the server code is that we transmit data in the client’s connection_made method . This is because the server waits for the client to send something before it responds, while the client just transmits as soon as it can.
The transmission of the data itself should look familiar. A nonce is generated and the nonce and ciphertext are written using transport.write.
The server’s response is handled in data_received. This should also look familiar. The nonce is split out and the ciphertext is decrypted using the read key and the received nonce.
In the create_connection method , you will notice that we still use an anonymous lambda function to build instances of the client protocol class. This might surprise you. In the server, using a factory function makes sense because there may be multiple connections requiring multiple protocol instances. In an outbound connection, though, there is just one protocol instance and one connection. Practically speaking, the factory is unnecessary. It is used so that the APIs for create_server and create_connection are as similar as possible.
This code is a good start for playing around with network protocols that use cryptography. For real network communications, though, additional machinery is often needed. One problem that might appear in production code is messages that get split across multiple data_received calls, or multiple messages that get condensed into a single data_received call. The data_received method treats incoming data as a stream, which means that there are no guarantees on how much data will be received in a single call. The asyncio library has no idea whether the data you send is meant to be split up or not. To solve this problem, you need to be able to recognize where one message ends and another begins. That typically requires some buffering in case not all data is received at once and a protocol that indicates where to split out the individual messages.
An Introduction to Kerberos
Although PKI is widely used today for establishing and authenticating identity, there are algorithms for establishing identity and trust between two parties using only symmetric encryption. As with PKI, these algorithms require a trusted third party.
One of the most well-known protocols for authenticated communications between two parties is Kerberos. Kerberos is a type of single sign-on (SSO) service that was developed into its current (version 5) form by the early 1990s. Although it has had updates since then, the protocol has remained largely the same. It allows someone to log in to the Kerberos system first and then have access to other network resources without logging in again. What’s really cool about it is that, while extensions have been added to use PKI for certain components, the core algorithms all use symmetric cryptography.
Alice and Bob have heard that Kerberos is now being deployed on systems within certain WA networks. In order to explore various opportunities for infiltrating these systems and looking for weaknesses therein, Alice and Bob spend some time back at HQ learning how Kerberos works.
We are going to help Alice and Bob create some Kerberos-like code. As with most of the examples in this book, this is not real Kerberos and the full system is beyond the scope of this book. We can still explore the basic components and get a feel for how Kerberos performs its magic using relatively simple network protocols. We will attempt to identify the more advanced and complicated pieces that we are leaving out, but if you really want to understand production Kerberos in depth, you will need to research additional sources.

The arrow you see does not represent receiving the message. Bob may never get it because of data loss or because Eve intercepts it. The arrow represents intent, so A → B means that A (Alice) intends to send a message to B (Bob). For practical purposes, however, it is sometimes simpler to just think of it as sending and receiving, so we will make that simplifying assumption as well.
The A represents Alice’s name, or identity string. Identity strings can be a lot of things. It could be Alice’s legal name, a username, a URI, or just an opaque token. Because the A in the message is not within any braces, it is plaintext. The ciphertext under KA, B is the same notation we’ve used before to represent a key shared by A and B. However, when A is sending data to B encrypted under a secret that “belongs” to B (e.g., under a key derived from a password associated with B), we will label this key as KB. Even though A knows this secret and, technically, it is a shared key, the idea is that the message is being encrypted exclusively for use by B.
Kerberos has multiple principals and the message exchange can be a little complicated. We will use this notation to help express who is sending data to whom.
Thus prepared, Alice and Bob sit down for a class on how Kerberos works. The first lesson is about how Kerberos uses a central repository of identities and passwords. Unlike a certificate authority that does not necessarily keep an online registry of all signed certificates—and certainly does not store any private keys—the Kerberos authentication server (AS) tracks every usable identity and maps it to a password. This data must be available at all times.
The Kerberos AS is a very sensitive part of the system obviously. Should the AS be compromised, the attacker gains knowledge of every password for every user. Thus, this system should be carefully guarded. Moreover, if the AS goes down, the rest of Kerberos falls apart. The AS must, therefore, be resistant to denial-of-service (DoS) attacks.
Kerberos Authentication Server
There’s nothing complicated in Listing 7-6 so far: just a username-to-password dictionary and an empty protocol class. To fill in these methods, we need to know how the AS works.
At this point, some really cool cryptography appears! How should a user log in? We definitely don’t want to send a password in the clear over the wire. The user obviously had to register with the AS in order for their password to be stored there, so should we have used that as an opportunity to create a shared encryption key?

Really? How does that work? What keeps Eve from just sending Alice’s name?
The magic is in the response. The AS is going to send back encrypted data that only the real Alice can decrypt. This assumes that Alice knows her password and nobody else does.

If Alice knows the password, she will be able to derive KA and decrypt the session key, the purpose of which we will explain in just a moment. For now, we’ll just say that it’s needed as part of the SSO operation.
Kerberos resists replay attacks by using both timestamps and nonces. While configurable, Kerberos will typically not accept messages that are more than 5 minutes old. The timestamp is also used as a nonce, meaning that the same timestamp cannot be used twice. The timestamp includes a microsecond field; it is difficult to imagine a client sending two requests within the same microsecond. The real Kerberos checks to see if, by some small chance, it is sending multiple packets with the same time (down to the microsecond). If that happens, it should artificially increase the value of the microsecond field in the timestamp by one.

Let’s update our AS to receive Alice’s message and to send back an encrypted session key. For messages we’ve sent in previous examples and exercises, we’ve just concatenated data together with enough fixed-length pieces that we could break apart all of the individual elements.
This time, we’re sending messages of less predictable length. When Alice transmits her username and timestamp, how will the AS be able to split out the two parts of the message? We could use a delimiter, such as a comma, and prohibit it from being part of a username, but we will be sending multiple encrypted values. How will we know where one ends and another begins? Delimiters can’t be used directly on raw encrypted data because that data makes use of all possible byte values.
In real network communications, this problem is solved in many ways. For example, HTTP sends metadata using delimiters (e.g., key: value<newline>), and if any data is arbitrary (and might contain the delimiter), it is either escaped or converted to ASCII using some predefined algorithm, such as Base-64 encoding. Other network packets are created by serializing all values and including a length field as part of the binary packet.
Utility Functions for JSON Handling
type: AS_REQ
principal: Alice’s username
timestamp: A current timestamp
Kerberos AS Receiver
Once the “packet” is restored, it is just a dictionary. We first check the type and make sure it is the type of packet we expected. Next, we check the timestamp. If the delta is greater than 300 seconds (5 minutes), we send back an error. Similarly, if the username is not in the password database, we also send back an error.
This error packet type is completely made up. Kerberos uses a different packet structure to report an error, but this will meet our needs.
Now we get to the fun part. Assuming the timestamp is recent and the username is in our database, we need to derive the user’s key from their password, create a session key, and send back this session key encrypted under the user’s key.
What algorithms and parameters should we use?
This is one area where the real Kerberos is significantly more complicated than what we’re going to do. The real Kerberos, like many cryptographic protocols, actually defines a suite of algorithms that can be used for its various operations. When Kerberos v5 was first deployed, the DES symmetric encryption algorithm was widely used. Now, of course, that’s largely been retired and AES has been added.
We know better by now than to think that “AES” is a complete answer. What mode of AES are we using? And where do we get the IV from?
Interestingly, Kerberos uses a mode of operation called “CTS” (ciphertext stealing). We aren’t going to spend a lot of time on this mode of operation (which is typically built on top of CBC mode), but we will briefly mention that for many Kerberos cipher suites, they are not using an IV to differentiate the messages. Instead, they use a “confounder.” A confounder is a random, block-sized plaintext message prepended to the real data. When using CBC mode, a random first block serves, in many ways, the same function as an IV.
We’re not going to mess with these complexities. We will focus on the encryption process and how symmetric encryption is used in the protocol. So, for our simple Kerberos, we will use AES-CBC with a fixed IV full of zeros. We will also leave out the MAC operation for now. It should be obvious that this is not secure and should not be used in production environments.
Kerberos with Encryption
Notice that we used padding in order to satisfy the CBC requirements. As a side note, one reason why Kerberos uses CTS mode is because it doesn’t require padding. It’s called “stealing” because it steals some cryptographic data from the penultimate block to fill in the last block’s missing bytes.
The preceding three functions will be used in multiple scripts, so you may want to save them in a separate file and import them.
Kerberos AS Responder
That seems pretty reasonable. Now we need to write the client side of this, but before we do, it’s time to explain how the next piece of the Kerberos protocol works.
Once Alice has logged in via the AS, she next needs to talk to a different entity called the Ticket-Granting Service (TGS) . Alice will tell the TGS which service, or application, she would like to connect to. The TGS will verify that she is logged in and then provide her with the credentials to use for that service.

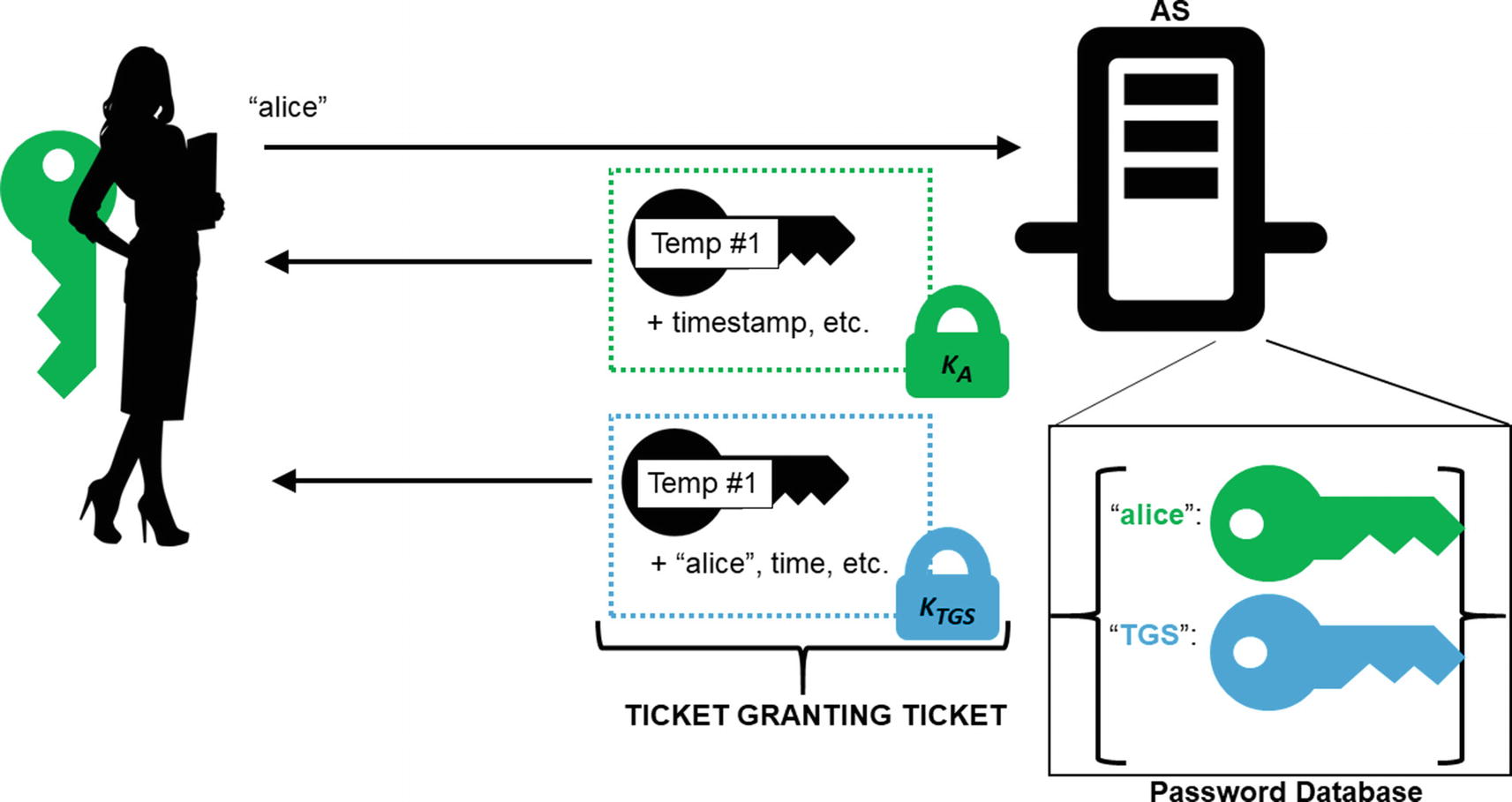
Alice initiates the Kerberos login process with a clear text message of her identity. The AS looks up her key in its database and encrypts a session key for the TGS. It also sends the TGT to Alice encrypted under the TGS’s key.

Kerberos Ticket-Granting Ticket
Let’s start working on the client now and create a protocol class for that side of the communication. First, our class (Listing 7-12) needs to be able to transmit the username to the AS, and it needs the password for deriving its own key. We’ll pass these in as parameters to the class constructor.
Kerberos Login
Kerberos Login Connection
Kerberos Login Receiver
The connection will close one way or another in Listing 7-14. When it does, we trigger our callback with the session key and TGT. If there were errors, these values will be None.
The code we’ve written so far should give us a client that can connect to the AS, send an identity, and receive back an encrypted session key and TGT. Now, it’s time to create the TGS (Ticket-Granting Service)!
In many Kerberos systems, the AS and TGS are co-located on the same host. They serve similar purposes and have similar security requirements. In many cases, they may need to share database information. For our exercise, however, and in order to visualize the TGS as a separate entity, we have it run as a separate script.
When Alice is logged in and wishes to talk to a service S, Alice sends a message to the TGS with the TGT, the name of the service, and an “authenticator.” The authenticator contains Alice’s identity and a timestamp encrypted under KA,TGS, the session key generated by the AS. That same session key is within the TGT. When the TGS decrypts the TGT and obtains KA,TGS, the TGS will be able to decrypt the authenticator and verify that Alice also has the Key KA,TGS. If Alice did not have that key, she would not have been able to create the authenticator. The fact that she has that key, and that the same key is in the TGT, means that the AS authorized her for this communication.
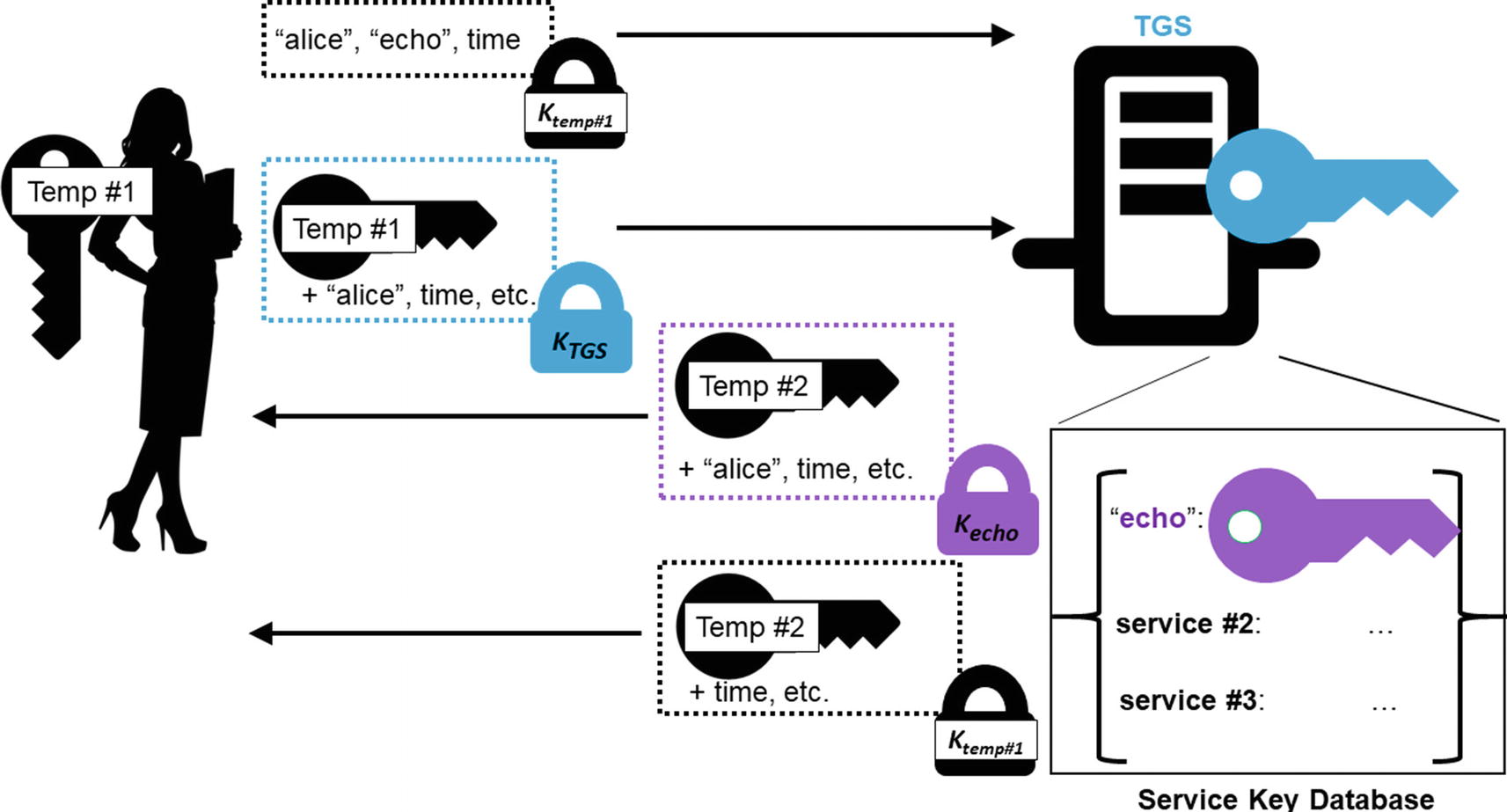
Alice uses the TGT to prove her identity and asks the TGS for a session key to communicate with the echo service. Similar to the TGT, Alice will receive an encrypted message for the echo service that she cannot open but can forward.


Figure 7-2 depicts this process.
Alice will use her session key with the TGS to decrypt the new session key for her to use with service S. But before we do that part, let’s get the TGS written.
Kerberos Ticket-Granting Service
Notice that we also handed a password to the constructor. Our SimpleKerberosTGS needs to be able to derive its key; otherwise, it wouldn’t be able to decrypt the TGT sent to it by the AS.
Kerberos TGS Receiver
Much of this looks very similar to the AS code, as we suggested it would. But there are a few key differences.
First, the TGS has to decrypt the authenticator to get the timestamp. It is not sent in the clear this time, but it ensures that the encrypted data (the authenticator) is at least somewhat fresh (within the last 5 minutes). In real Kerberos, timestamps would be stored and duplicates identified and discarded.
Also note that the TGS checks that the principal is the same in the authenticator as in the TGT. It must do this check to ensure that the identity authorized by the AS is the same identity asking for a ticket.
Finally, the user’s data with the session key and so forth is not encrypted under a key derived from their password (which the TGS doesn’t have anyway). Rather, it is encrypted under the session key KA, TGS. The TGS encrypts with this key because only Alice should be able to decrypt it.
Get Kerberos Ticket

Both Alice and the echo service end up with a shared symmetric key that they can use for secure communications
This protocol, on connection, sends the TGS_REQ packet along with the encrypted authenticator, the service name, and the TGT. Remember, the TGT was transmitted by the AS, as was the session key. These pieces of data are passed to the constructor of this protocol. Once we receive the TGS_REP, we can extract the service’s session key and the ticket to send to the service. We use another callback on_ticket to process this information.
Figure 7-3 shows the rest of the protocol.
Kerberos Client
The only other part of this code worth pointing out is the use of input to get the name of the service to connect to. This is normally not the best way to use asyncio programs because it is a blocking call and prevents anything else from working. But, for our simplistic client, this is reasonable. It should be in between network communications anyway.
Note that the only service the TGS has in our example is “echo,” so this should be the service name you enter, unless you want to test the error-handling code. We also hard-coded the IP address and port of the TGS to be local port 8889. You should adjust this accordingly.
When all is said and done, and if everything was done correctly, the on_ticket callback should have a service session key and a ticket.

When this is finished, Alice and the service S know that they are communicating with the right parties (based on trust in the AS/TGT) and they have a session key to enable them to communicate.
You will notice that the session key is shown working in both directions. This is primarily for the actual authentication of the principals (Alice and service S) to one another. Once that is established, they can negotiate session keys further if necessary. The Kerberos documentation has instructions about “subkeys” that can be sent or derived as necessary.
For the actual Kerberos authentication exchange, the messages will be unique if the confounder is used, even under the same key.
To repeat once more, Kerberos itself is far more complicated than what we have illustrated here. There are various extensions, for example, for enabling PKI authentication to the AS, AEAD algorithm support, extensive options, and additional details in the core specification.
Nevertheless, this walk-through should help Alice and Bob (and you!) have a better idea of how Kerberos works specifically and how symmetric keys can be used in general to establish identity between parties.
Exercise 7.5. Kerberize The Echo Protocol
We didn’t show any code for a Kerberized echo protocol. We’ve left that for you to figure out. We have already set up some of the pieces you need, however. In real Kerberos, a Kerberized service has to register with the TGS. We have already done that. Our TGS code has “echo” in the service database with a password “sunshine”.
You will need to modify the echo client and echo server to use the session key from the TGS instead of deriving the session keys from a password. You can treat the session key from the TGS as key material and still use the HKDF to derive the write key and read key (two sub-session keys, as Kerberos would call them).
Many Kerberized implementations accept the ticket along with the request, and you can do the same here. In other words, send the Kerberos message along with the (encrypted) data to be echoed. Because you are sending a human-readable message, you can use the null terminator to indicate the end of the echo message and the beginning of the Kerberos message, if that’s easiest. Alternatively, you could do something more complicated like transmit the Kerberos message first, prepended by its length, with the human-readable echo message as a trailer.
The server will also need to be modified to accept a password for deriving its key with the TGS. The server already has a password given as a parameter. You could simply change it to derive its Kerberos key instead of the read and write keys. Also, make sure to use the appropriate derivation function. The read and write keys will need to be derived in the data_received method after the ticket is received and decrypted. You can leave out the optional Kerberos response to the echo client.
Finally, you will have to figure out a way to get the Kerberos ticket data to the echo client. You can either build the echo client protocol directly into your Kerberos client or find some other way to transfer it.
Exercise 7.6. Confounder
Check to see if any part of your encrypted packets are repeating. This will happen if the data going into the encryption routine (with a fixed IV and key) is the same at the beginning. Because dictionaries do not necessarily order their data, the username may come after the timestamp, in which case the packets may be different each time. If your packets aren’t repeating any bytes at all, perhaps fix the timestamp or otherwise force the encrypt function to encrypt the same data twice.
Once you have repeating bytes, introduce confounders into your code by prepending 16 bytes of random plaintext in front of the serialized bytes. Make sure to remove it upon decryption. Does that get rid of the repeating bytes? Would a confounder work for AES-CTR mode?
Exercise 7.7. Preventing Server Replay
The transmissions to the client from our AS and TGS do not include a timestamp. With no timestamp and no nonce, they can be completely replayed. Add timestamps into the user data structures transmitted by both servers and modify the client code to check them.
Additional Data
This section was a little simpler in terms of concepts and a little heavier in terms of engineering.
In the first place, we did introduce some new modes of operation for AES encryption and the new ChaCha encryption algorithm as well. AEAD algorithms (authenticated encryption with additional data) are largely seen as superior to doing encryption and MAC separately (e.g., using AES-CTR and HMAC). You should use these modes of operation whenever they are available.
We also introduced the Kerberos SSO service which is interesting because it is built from symmetric key algorithms. In a world where PKI is everywhere, it is nice to see that a 25-year-old (as of the time of this writing), symmetric-based system continues to be widely used.
Hopefully it was fun to get your hands dirty and actually write some client/server code. We hope so. Because the last chapter is coming up and network communications are what TLS is all about!