The process of identifying important features and removing the ones that we think are not important for our model is called recursive feature elimination (RFE). RFE can also be applied in scikit-learn and we can use this technique for calculating coefficients, such as linear, logistic regression, or with models to calculate something called feature importance. The random forests model provides us with those feature importance metrics. So, for models that don't calculate either coefficients or feature importance, these methods cannot be used; for example, for KNN models, you cannot apply the RFE technique because this begins by predefining the required features to use in your model. Using all features, this method fits the model and then, based on the coefficients or the feature importance, the least important features are eliminated. This procedure is recursively repeated on the selected set of features until the desired number of features to select is eventually reached.
There are the following few methods to select important features in your models:
- L1 feature
- Selection threshold methods
- Tree-based methods
Let's go to our Jupyter Notebook to see how we actually apply these methods in scikit-learn. The following screenshot depicts the necessary libraries and modules to import:
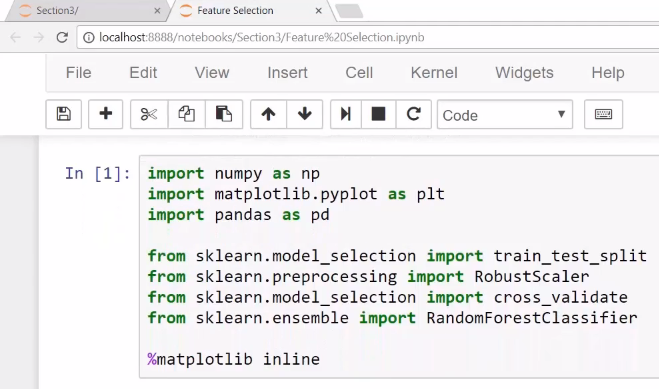
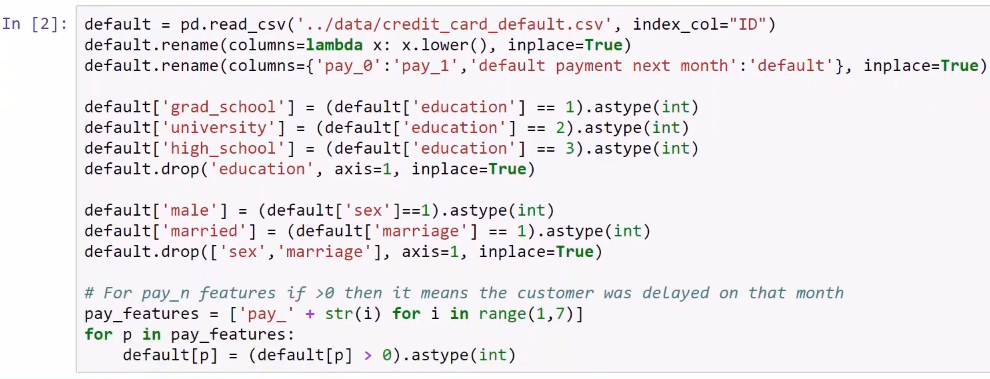
In the following screenshot, we have first used the credit card default dataset and we are applying the traditional transformations that we do to the raw data:
The following screenshot shows the dummy features that we have in our dataset and the numerical features, depending on the type of feature:

Here, we are applying the scaling operation for feature modeling:

The first method that we talked about in the presentation was removing dummy features with low variance to get the variances from our features using the var() method:

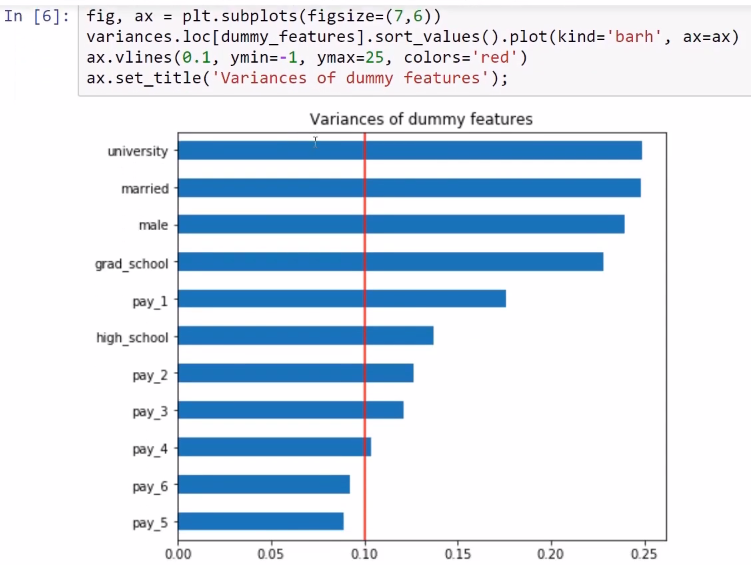
Let's see the variances only for the dummy features; for example, a threshold for the variance will consider only the dummy features with a variance over 0.1. In that case, with such a threshold of 0.1, the two candidates for elimination, pay_5 and pay_6, would be the first few unnecessary dummy features with low variance that will be removed. Take a look at the following screenshot, which depicts the candidates for elimination:
The second approach that we talked about is statistically selecting the features that are related to the target, and we have two cases, dummy features and numerical features.
Let's perform the statistical tests for the dummy features. We are going to import objects in the chi2 object from the feature_selection module in the scikit-learn library. We will also use the SelectKBest object to perform the statistical tests in all of the dummy features as shown in the following screenshot:

Here, we instantiate an object called dummy _selector and pass the required statistical test to apply to it. Here, we are passing the k ="all" argument because this statistical test is to be applied to all of the dummy features. After instantiating this object, the fit() method is called. Take a look at the following screenshot:

In the following screenshot, we have the chi-squared scores. This isn't a statistical test and, the larger the number, the stronger the relationship between the feature and the target:

Now, if you remember your statistics class, this is a hypothesis testing setting. So, we can also calculate the p values and we can say that the features where pvalues_ is greater than 0.05 are not related to the target. Now, in this case, we get very small p values for all of the features, as shown in the following screenshot:
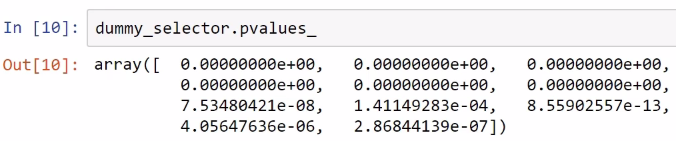
There is a relationship between the target and all of the dummy features, so under this methodology, we shouldn't eliminate any of these dummy features.
Now, we can use another statistical test called f_ classif to evaluate the relationship between numerical features and the target, as shown in the following screenshot:

Reusing this f_classif object, we will pass the required statistical tests and number of features. In this case, we want to apply the test to all numerical features and then use the fit() method again with the numerical features and the target:

The p values that we receive from the application of this statistical test are shown in the following screenshot:

We can pass the f_classif statistical test and then select the numerical features that have a p value greater than 0.05, which is the usual threshold for statistical tests; the resulting features here are bill_amt4, bill_amt5, and bill_amt6, which are likely to be irrelevant, or not related to the target:
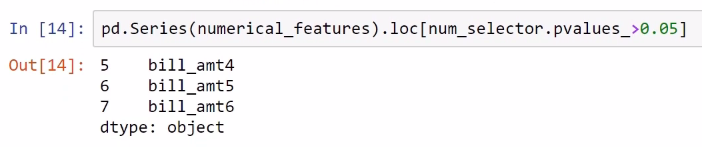
We have three candidates for elimination which can be eliminated or can be applied. We have used the second technique in the preceding steps and now we will use the third one in the following section.
The RFE is the third technique in which we will use the RandomForestClassifier model, and remember that we have 25 features here:

So, let's assume that we want to select only 12 features and we want a model that uses only 12 features. So, we are using about half of the features. We can use the RFE object present in scikit-learn from the feature_selection module. We can use this to actually select these 12 features using the RFE technique. So, we instantiate this object by passing the required estimator and the number of features to select:

Now, remember that random forest provides us with a metric of feature importance, which can be used with the RFE technique:

After using the fit() method on the whole dataset, we get recursive_selector.support_ and True for the features that are included in our model, the 12 that we wanted, and we get False for the ones that should be eliminated:

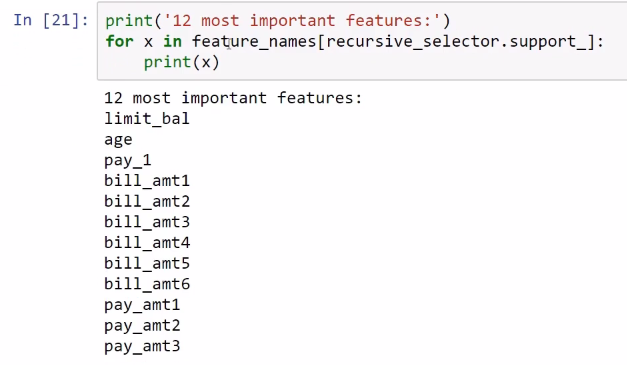
So, according to this object and method, we should include the 12 most important features in our random forest model in order to predict targets such as limit_bal, age, pay; all of the bill amounts; and pay_amt1, pay_amt2, and pay_amt3, as shown in the following screenshot:
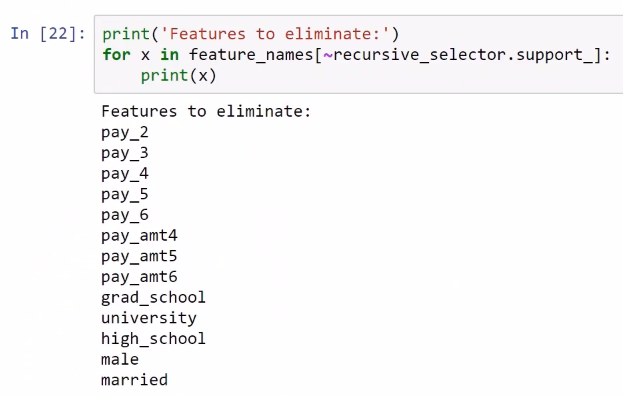
These are the features that should be eliminated because they are not very relevant according to this method and this model for predicting the target:
Now we can evaluate the simpler model, the one with the 12 features against the full model that we have been using so far, after which we can calculate the metrics using cross-validation. So, in this example, we are using 10-fold cross-validation to get an estimation of the performance of these two models. Remember, this selector model is the full model according to the RFE technique and these are the results:
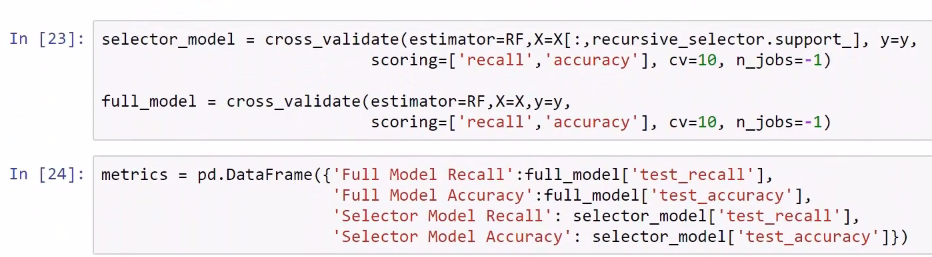
The full model has a recall of 0.361365, and the model that includes only 12 features has a recall of 0.355791. Since this model has less recall, the full model remains the best one. But if we use half of the features, the full model will also give us similar performance:

As you can see in the following screenshot, the values are really close:
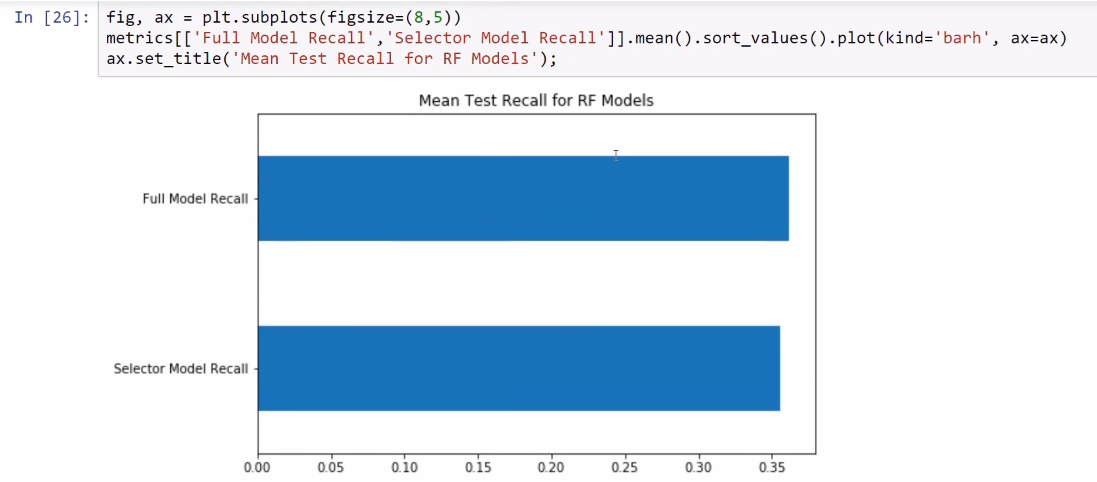
Now you can decide whether you want to use the full model or you want to use the simpler model. This is up to you, but in terms of accuracy we get almost the same, although with still a little bit more accuracy for the full model:
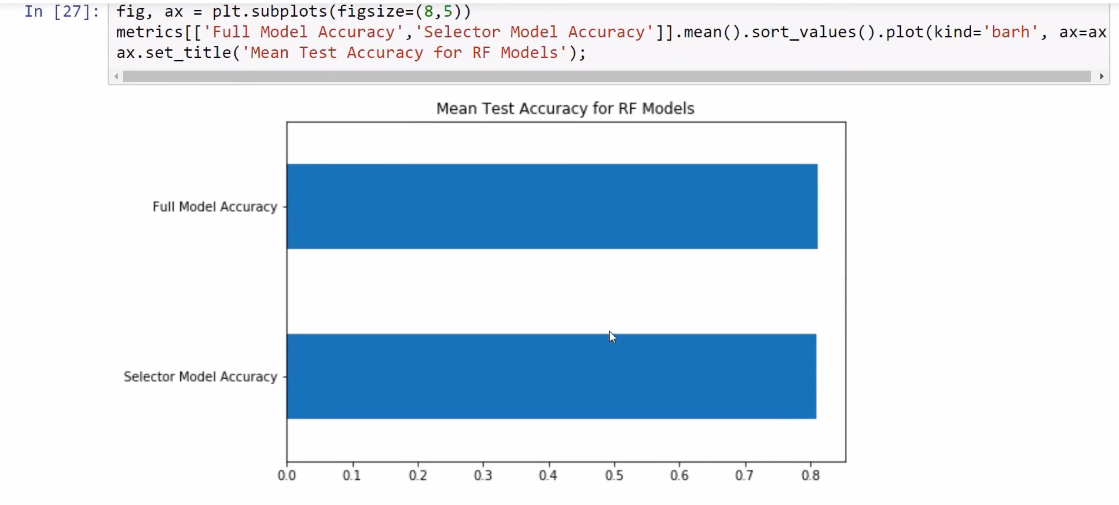
Now, you have a technique to decide whether you want to use a more complicated model that uses more features, or a simpler model.