Since this is an external dataset, we have to use a data input pipeline, and TensorFlow provides different tools for getting data inside the deep learning model. Here, we create a dataset object and an iterator object with the lines of code shown in the following screenshot:
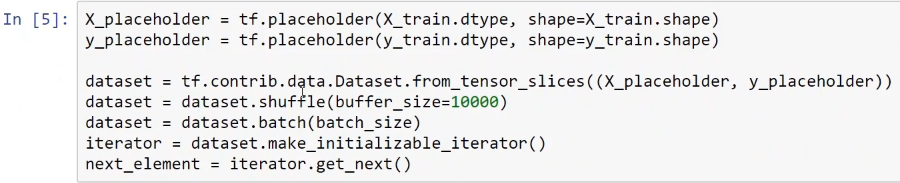
First, we produce the dataset object. Then, we pass the whole training dataset to some placeholders that we will use. Then, we shuffle the data and divide or partition the training dataset into batches of 50. Hence, the dataset object is prepared, containing all of the training samples partitioned into batches of size 50. Next, we make an iterator object. Then, with the get_next method, we create a node called next_element, which provides the batches of 50 from the training examples.