Before moving on, there are two really important concepts to be covered for predictive analytics. Errors can be divided into the following two types:
- Reducible errors: These errors can be reduced by making certain improvements to the model
- Irreducible errors: These errors cannot be reduced at all
Let's assume that, in machine learning, there is a relationship between features and target that is represented with a function, as shown in the following screenshot:
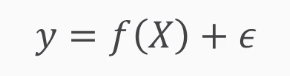
Let’s assume that the target (y) is the underlying supposition of machine learning, and the relationship between the features and the target is given by a function. Since, in most cases we consider that there is some randomness in the relationship between features and target, we add a noise term here, which will always be present in reality. This is the underlying supposition in machine learning.
In models, we try to approximate the theoretical function by using an actual function while performing feature engineering, tuning the parameters, and so on:
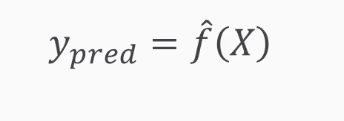
So, our predictions are the results of the application of these approximations to the conceptual or theoretical f. All that we do in machine learning is try to approximate this f function by training the model.
Training a model means approximating this function. It is possible to show mathematically that the expected error, defined as the difference between the real y and the predicted y, can be decomposed into two terms. One term is called Reducible error and the other one is called Irreducible error, as shown in the following screenshot:

Now, the Irreducible error term is the variance of this random term. You don't have any control over this term. There will always be an irreducible error component. So, your model will always make mistakes; it doesn't matter how many features and data points you have, your model cannot always be 100% correct. What we must try to do is to use better and more sophisticated methods to perform feature engineering, and try to approximate our estimation to the real function. Just because you are working with more sophisticated models or you have more data, your model will not be perfect and you will not be able to predict exactly what y is, because there is some randomness in almost all the processes that you will work with. So this is the end of a very interesting section.